
Dans la première partie, j'ai parlé de ce que sont les simulateurs en général, ainsi que des niveaux de modélisation. Maintenant, sur la base de ces connaissances, je propose de plonger un peu plus profondément et de parler de simulation de plate-forme complète, comment assembler les pistes, que faire avec elles plus tard, et aussi sur l'émulation microarchitecturale basée sur le beat.
Simulateur de plate-forme complet ou "Seul sur le terrain - pas un guerrier"
Si vous devez étudier le fonctionnement d'un périphérique spécifique, par exemple une carte réseau, ou écrire un micrologiciel ou un pilote pour ce périphérique, un tel périphérique peut être modélisé séparément. Cependant, l'utiliser isolément du reste de l'infrastructure n'est pas très pratique. Pour exécuter le pilote correspondant, vous avez besoin d'un processeur central, d'une mémoire, d'un accès au bus pour le transfert de données, etc. De plus, le pilote a besoin d'un système d'exploitation (OS) et d'une pile réseau. De plus, un générateur de paquets et un serveur de réponse distincts peuvent être nécessaires.
Le simulateur de plate-forme complète crée un environnement pour exécuter une pile logicielle complète, qui comprend tout, du BIOS et du chargeur de démarrage au système d'exploitation lui-même et à ses différents sous-systèmes, tels que la même pile réseau, les pilotes et les applications de niveau utilisateur. Pour ce faire, il implémente des modèles logiciels de la plupart des périphériques informatiques: processeur et mémoire, disque, périphériques d'entrée-sortie (clavier, souris, écran), ainsi que la même carte réseau.
Voici un schéma de principe du chipset Intel x58. Dans un simulateur informatique à plate-forme complète sur ce chipset, il est nécessaire d'implémenter la plupart des périphériques répertoriés, y compris ceux situés à l'intérieur de l'IOH (concentrateur d'entrée / sortie) et de l'ICH (concentrateur de contrôleur d'entrée / sortie), qui ne sont pas dessinés en détail sur le diagramme. Bien que, comme le montre la pratique, il n'y ait pas si peu d'appareils qui ne soient pas utilisés par le logiciel que nous allons exécuter. Les modèles de tels appareils ne peuvent pas être créés.

Le plus souvent, les simulateurs de plate-forme complète sont implémentés au niveau des instructions du processeur (ISA, voir article précédent) Cela vous permet de créer le simulateur lui-même relativement rapidement et à peu de frais. Le niveau ISA est également bon en ce qu'il reste plus ou moins constant, contrairement, par exemple, au niveau API / ABI, qui change plus souvent. De plus, l'implémentation au niveau des instructions vous permet d'exécuter le logiciel binaire dit non modifié, c'est-à-dire d'exécuter le code déjà compilé sans aucune modification, exactement comme il est utilisé sur du matériel réel. En d'autres termes, vous pouvez faire une copie («dump») du disque dur, le spécifier comme image du modèle dans un simulateur de plate-forme complète, et le tour est joué! - L'OS et les autres programmes sont chargés dans le simulateur sans aucune action supplémentaire.
Performances du simulateur

Comme mentionné ci-dessus, le processus même de simulation de l'ensemble du système dans son ensemble, c'est-à-dire de tous ses appareils, est un exercice assez lent. Si vous implémentez également tout cela à un niveau très détaillé, par exemple microarchitectural ou logique, la mise en œuvre deviendra extrêmement lente. Mais le niveau des instructions est un choix approprié et permet au système d'exploitation et aux programmes de fonctionner à des vitesses suffisantes pour que l'utilisateur puisse interagir confortablement avec eux.
Ici, il sera juste pertinent d'aborder le sujet des performances du simulateur. Il est généralement mesuré en IPS (instructions par seconde), plus précisément en MIPS (millions d'IPS), c'est-à-dire le nombre d'instructions processeur exécutées par le simulateur par seconde. Dans le même temps, la vitesse de simulation dépend également des performances du système sur lequel la simulation elle-même s'exécute. Par conséquent, il peut être plus correct de parler de «ralentissement» du simulateur par rapport au système d'origine.
Les simulateurs de plate-forme complète les plus courants du marché, comme QEMU, VirtualBox ou VmWare Workstation, ont de bonnes performances. L'utilisateur peut même ne pas remarquer que le travail est en cours dans le simulateur. Cela est dû à la fonctionnalité de virtualisation spéciale implémentée dans les processeurs, aux algorithmes de traduction binaire et à d'autres choses intéressantes. C'est tout le sujet d'un article séparé, mais si brièvement, la virtualisation est une caractéristique matérielle des processeurs modernes qui permet aux simulateurs de ne pas simuler des instructions, mais de les exécuter directement dans un vrai processeur, à moins, bien sûr, que les architectures du simulateur et du processeur soient similaires. La traduction binaire est la traduction du code de la machine invitée en code hôte et son exécution ultérieure sur un processeur réel. En conséquence, la simulation n'est que légèrement plus lente, une fois tous les 5-10,et fonctionne souvent généralement à la même vitesse que le système réel. Bien que cela soit influencé par de nombreux facteurs. Par exemple, si nous voulons simuler un système avec plusieurs dizaines de processeurs, alors la vitesse chutera immédiatement plusieurs dizaines de fois. D'un autre côté, les simulateurs comme Simics dans les versions récentes prennent en charge le matériel hôte multiprocesseur et parallélisent efficacement les cœurs simulés aux cœurs de processeur réels.les simulateurs comme Simics dans les dernières versions prennent en charge le matériel hôte multiprocesseur et parallélisent efficacement les cœurs simulés aux cœurs de processeur réels.les simulateurs comme Simics dans les dernières versions prennent en charge le matériel hôte multiprocesseur et parallélisent efficacement les cœurs simulés aux cœurs de processeur réels.
Si nous parlons de la vitesse de la simulation microarchitecturale, alors elle est généralement de plusieurs ordres de grandeur, environ 1000-10000 fois plus lente que l'exécution sur un ordinateur ordinaire, sans simulation. Et les implémentations au niveau des éléments logiques sont plus lentes de plusieurs ordres de grandeur. Par conséquent, FPGA est utilisé comme émulateur à ce niveau, ce qui peut augmenter considérablement les performances.
Le graphique ci-dessous montre la dépendance approximative de la vitesse de simulation sur les détails du modèle.
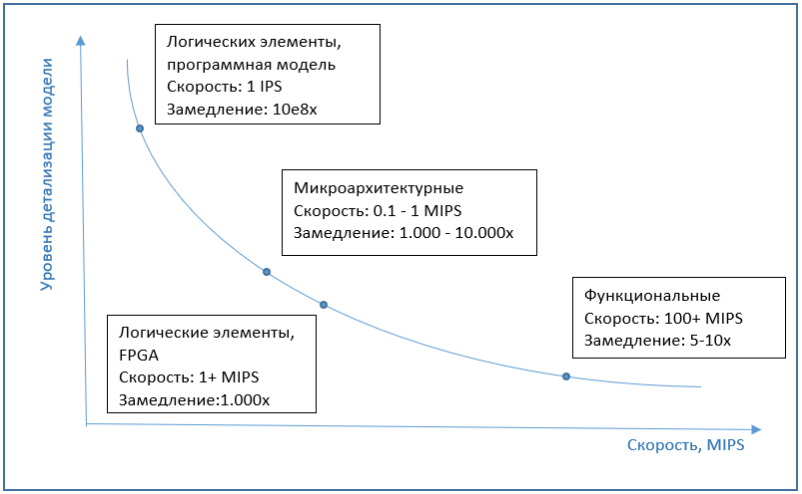
Simulation de résultat
Malgré la faible vitesse d'exécution, les simulations microarchitecturales sont assez courantes. La modélisation des blocs internes du processeur est nécessaire pour simuler avec précision le temps d'exécution de chaque instruction. Cela peut conduire à un malentendu - car il semblerait, pourquoi ne pas simplement choisir et programmer le temps d'exécution pour chaque instruction. Mais un tel simulateur fonctionnera de manière très imprécise, car le temps d'exécution de la même instruction peut différer d'un appel à l'autre.
L'exemple le plus simple est une instruction d'accès à la mémoire. Si l'emplacement mémoire demandé est disponible dans le cache, le temps d'exécution sera minimal. S'il n'y a pas de telles informations dans le cache ("cache miss", cache miss), alors cela augmentera considérablement le temps d'exécution de l'instruction. Ainsi, un modèle de cache est requis pour une simulation précise. Cependant, le modèle de cache n'est pas limité à cela. Le processeur n'attendra pas seulement que les données soient reçues de la mémoire si elles ne sont pas dans le cache. Au lieu de cela, il commencera à exécuter les instructions suivantes, en choisissant celles qui sont indépendantes du résultat de la lecture de la mémoire. C'est ce qu'on appelle l'exécution dans le désordre (OOO) nécessaire pour minimiser les temps d'arrêt du processeur. La prise en compte de tout cela lors du calcul du temps d'exécution des instructions aidera à modéliser les unités de processeur correspondantes. Parmi ces instructions en cours d'exécution,en attendant le résultat de la lecture en mémoire, une opération de branchement conditionnelle peut se produire. Si le résultat de la réalisation de la condition est inconnu pour le moment, alors à nouveau, le processeur n'arrête pas l'exécution, mais fait une «hypothèse», effectue la transition correspondante et continue d'exécuter de manière préventive les instructions à partir du lieu de transition. Un tel bloc, appelé prédicteur de branche, doit également être implémenté dans un simulateur microarchitectural.
L'image ci-dessous montre les principaux blocs du processeur, il n'est pas nécessaire de le connaître, il est montré uniquement pour montrer la complexité de la mise en œuvre microarchitecturale.
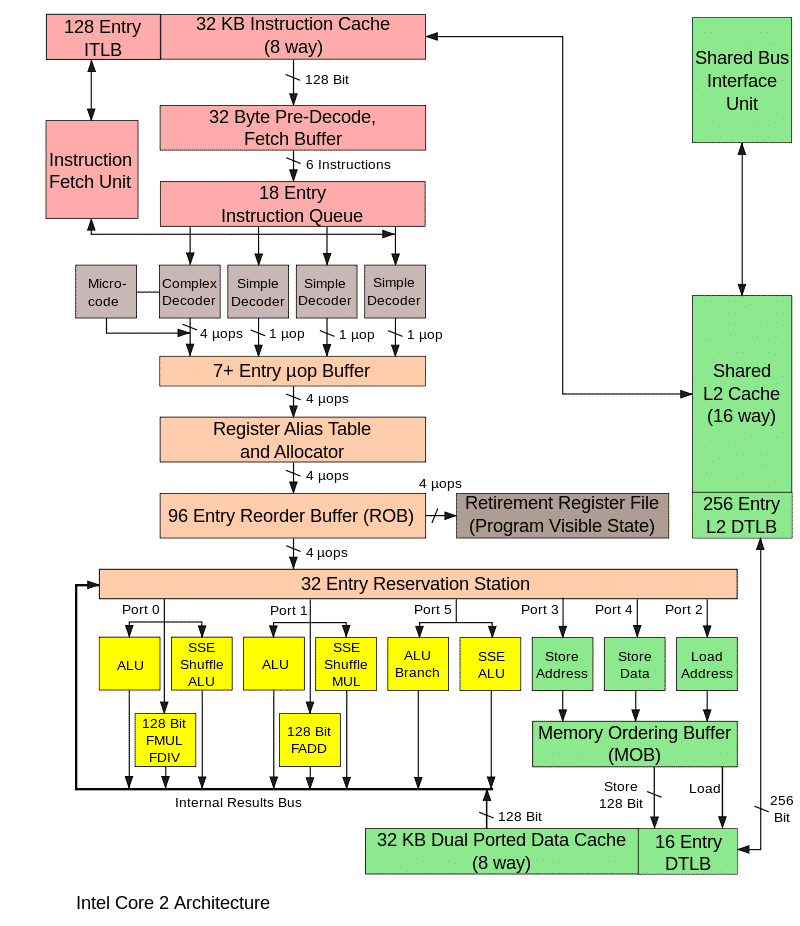
Le fonctionnement de tous ces blocs dans un processeur réel est synchronisé avec des signaux d'horloge spéciaux, et la même chose se produit dans le modèle. Ce simulateur microarchitectural est appelé cycle précis. Son objectif principal est de prédire avec précision les performances du processeur en cours de développement et / ou de calculer le temps d'exécution d'un certain programme, par exemple un benchmark. Si les valeurs sont inférieures à ce qui est nécessaire, il sera alors nécessaire d'affiner les algorithmes et les blocs de processeur ou d'optimiser le programme.
Comme indiqué ci-dessus, la simulation cycle par cycle est très lente, elle n'est donc utilisée que lors de l'examen de certains points de fonctionnement du programme, où il est nécessaire de connaître la vitesse réelle d'exécution du programme et d'estimer les performances futures de l'appareil dont le prototype est simulé.
Dans ce cas, un simulateur fonctionnel est utilisé pour simuler le reste de l'exécution du programme. Comment cette utilisation combinée se produit-elle réellement? Tout d'abord, un simulateur fonctionnel est lancé, sur lequel l'OS et tout le nécessaire pour exécuter le programme à l'étude sont chargés. Après tout, nous ne sommes intéressés ni par le système d'exploitation lui-même, ni par les étapes initiales du lancement du programme, sa configuration, etc. Cependant, nous ne pouvons pas non plus sauter ces parties et passer directement à l'exécution du programme à partir du milieu. Par conséquent, toutes ces étapes préliminaires sont exécutées sur un simulateur fonctionnel. Une fois le programme exécuté jusqu'au moment qui nous intéresse, il y a deux options. Vous pouvez remplacer le modèle par un modèle cycle par cycle et poursuivre l'exécution. Mode de simulation, dans lequel un code exécutable est utilisé (c'est-à-dire des fichiers programmes compilés réguliers),appelée simulation pilotée par l'exécution. Il s'agit de l'option de simulation la plus courante. Une autre approche est également possible - la simulation basée sur les traces.
Simulation basée sur les traces
Il comporte deux étapes. À l'aide d'un simulateur fonctionnel ou sur un système réel, un journal des actions du programme est collecté et écrit dans un fichier. Un tel journal est appelé une trace. En fonction de ce qui est étudié, la trace peut inclure des instructions exécutables, des adresses mémoire, des numéros de port, des informations sur les interruptions.
L'étape suivante consiste à "lire" la trace, lorsque le simulateur cycle par horloge lit la trace et exécute toutes les instructions qui y sont écrites. À la fin, nous obtenons le temps d'exécution de cette partie du programme, ainsi que diverses caractéristiques de ce processus, par exemple, le pourcentage de hit dans le cache.
Le déterminisme est une caractéristique importante du travail avec les pistes, c'est-à-dire qu'en démarrant la simulation comme décrit ci-dessus, nous reproduisons encore et encore la même séquence d'actions. Cela permet, en modifiant les paramètres du modèle (la taille du cache, des tampons et des files d'attente) et en utilisant divers algorithmes internes ou en les ajustant, d'étudier comment un paramètre particulier affecte les performances du système et quelle option donne les meilleurs résultats. Tout cela peut être fait avec un modèle d'appareil prototype avant de créer un véritable prototype matériel.
La complexité de cette approche réside dans la nécessité de pré-exécuter l'application et de collecter la trace, ainsi que la taille énorme du fichier avec la trace. Les avantages incluent le fait qu'il suffit de simuler uniquement la partie de l'appareil ou de la plate-forme d'intérêt, alors que la simulation d'exécution nécessite généralement un modèle complet.
Ainsi, dans cet article, nous avons examiné les fonctionnalités de la simulation de plate-forme complète, parlé de la vitesse des implémentations à différents niveaux, de la simulation de battement et des traces. Dans le prochain article, je décrirai les principaux scénarios d'utilisation des simulateurs, à la fois à des fins personnelles et du point de vue du développement dans les grandes entreprises.