
Vous trouverez ici une liste des documents publiés en juin en anglais. Tous sont écrits sans académisme excessif, contiennent des exemples de code et des liens vers des référentiels non vides. La plupart des technologies mentionnées sont du domaine public et ne nécessitent pas de matériel lourd pour les tests.
Image GPT
Open AI a décidé que, comme un modèle de transformateur entraîné sur du texte peut générer des phrases complètes cohérentes, si le modèle est entraîné sur des séquences de pixels, il peut générer des images augmentées. L'IA ouverte démontre comment un échantillonnage de haute qualité et une classification d'image précise permettent au modèle généré de rivaliser avec les meilleurs modèles convolutifs dans des environnements d'apprentissage non supervisés.

Dépixelizer de visage Il y a
un mois, nous avons eu l'opportunité de jouer avec l' outil, qui utilise un modèle d'apprentissage automatique pour transformer les portraits en un magnifique pixel art. C'est amusant, mais il est encore difficile d'imaginer l'utilisation généralisée de cette technologie. Mais l'outil qui produit l'effet inverse s'est immédiatement intéressé au public. Avec l'aide d'un dépixeliseur de visage, en théorie, il sera possible d'établir l'identité d'une personne par enregistrement vidéo à partir de caméras de surveillance extérieures.

DeepFaceDrawing
Si travailler avec des images en pixels ne suffit pas et que vous devez composer une photographie avec un portrait d'une personne à partir d'un croquis primitif, alors un outil basé sur DNN est déjà apparu pour cela. Tel que conçu par les créateurs, seuls des contours généraux sont nécessaires, et non des croquis professionnels - le modèle restaurera alors lui-même le visage de la personne, qui coïncidera avec le croquis. Le système a été créé en utilisant le framework Jittor, comme le promettent les créateurs, le code source de Pytorch sera bientôt ajouté au référentiel du projet.
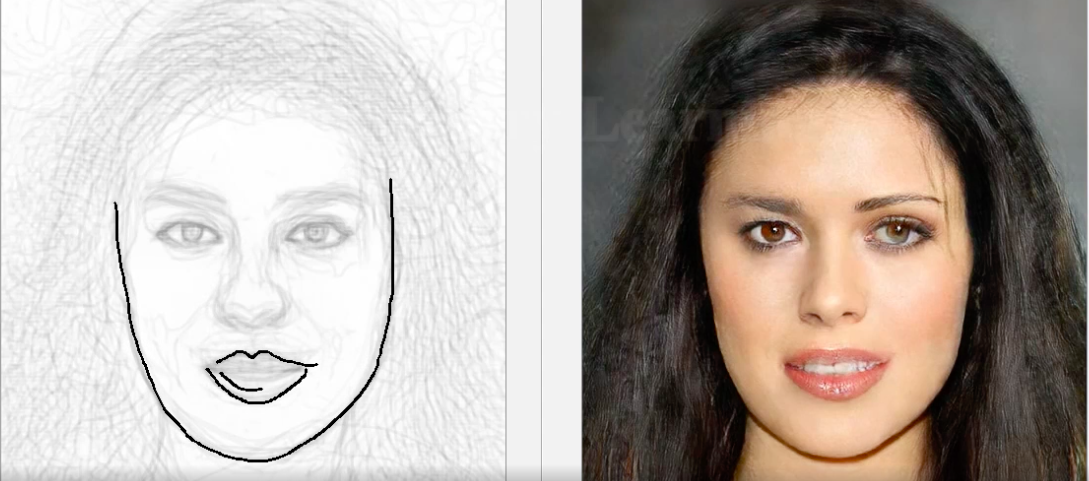
PIFuHD
Avec les reconstructions faciales triées, qu'en est-il du reste du corps? Grâce au développement de DNN, il est devenu possible de modéliser en 3D une figure humaine à partir d'une photo en deux dimensions. La principale limitation était due au fait que des prévisions précises nécessitent une analyse d'un contexte plus large et des données sources en haute résolution. L'architecture en couches du modèle et les capacités d'apprentissage de bout en bout aideront à résoudre ce problème. Au premier niveau, pour économiser les ressources, l'image entière est analysée en basse résolution. Le contexte est alors formé, et à un niveau plus détaillé, le modèle évalue la géométrie en analysant l'image haute résolution.

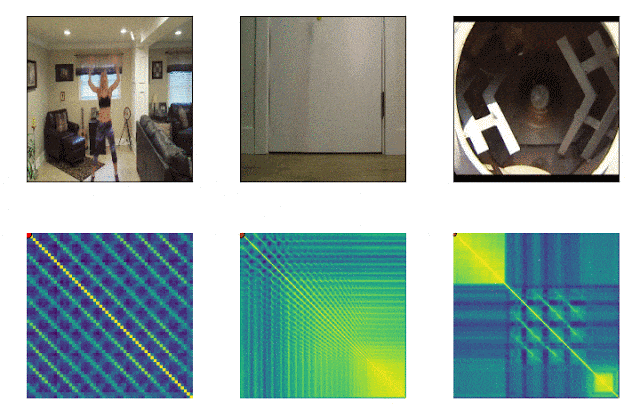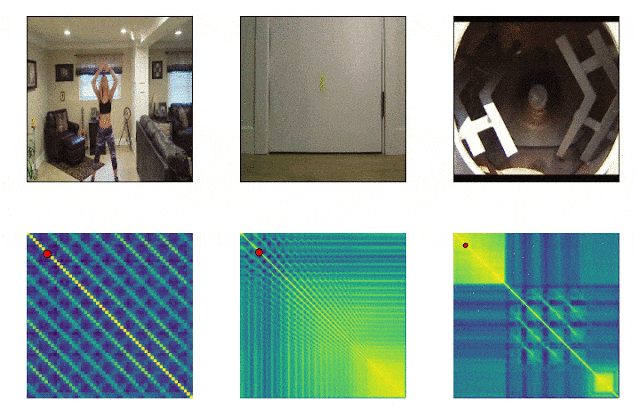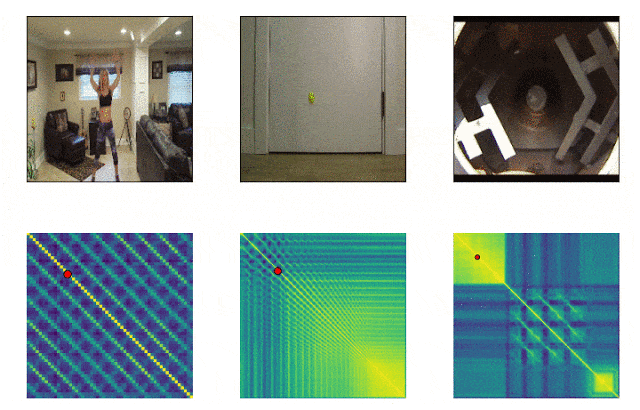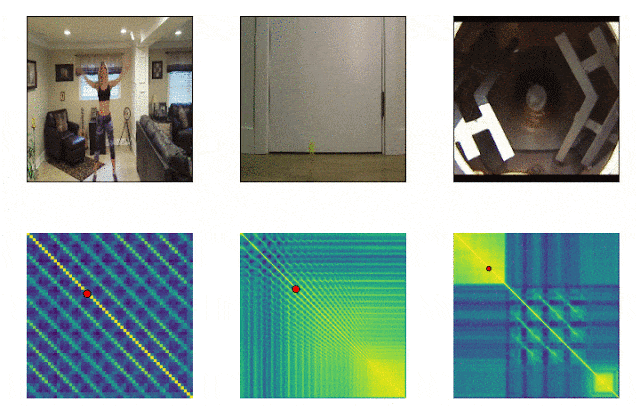
RepNet
Beaucoup de choses qui nous entourent consistent en des cycles de fréquences différentes. Souvent, pour comprendre l'essence d'un phénomène, il est nécessaire d'analyser des informations sur ses manifestations récurrentes. Compte tenu des possibilités de tournage vidéo, il n'est plus difficile de fixer les répétitions, le problème était de les compter. La méthode de comparaison image par image de la densité de pixels dans l'image n'était souvent pas adaptée en raison du bougé de l'appareil photo ou de l'obstruction par des objets, ainsi que d'une nette différence d'échelle et de forme lors d'un zoom avant et arrière. Un modèle développé par Google résout désormais ce problème. Il identifie les actions répétitives dans la vidéo, y compris celles qui n'ont pas été utilisées lors de la formation. En conséquence, le modèle renvoie des données sur la fréquence des actions répétées reconnues dans la vidéo. Colab est déjà disponible .
Modèle SPICE
Auparavant, vous deviez vous fier à des algorithmes sophistiqués de traitement du signal pour déterminer la hauteur. Le plus grand défi était de séparer le son étudié du bruit de fond ou du son des instruments d'accompagnement. Un modèle pré-entraîné est maintenant disponible pour cette tâche qui détecte les hautes et basses fréquences. Le modèle est disponible pour une utilisation sur le Web et les appareils mobiles.
Détecteur de distance sociale
Le cas de la création d'un programme avec lequel vous pouvez suivre si les gens observent une distanciation sociale. L'auteur raconte en détail comment il a choisi un modèle pré-formé, comment il a fait face à la tâche de reconnaissance des personnes et comment, à l'aide d'OpenCV, il a transformé l'image en projection orthographique afin de calculer la distance entre les personnes. Vous pouvez également vous familiariser avec le code source du projet.

Reconnaissance de documents types
Aujourd'hui, il existe des milliers de variantes des modèles de documents les plus courants tels que les reçus, les factures et les chèques. Systèmes automatisés existants conçus pour fonctionner avec un type de modèle très limité. Google suggère d'utiliser l'apprentissage automatique pour cela. L'article traite de l'architecture du modèle et des résultats des données obtenues. L'outil fera bientôt partie du service Document AI .
Comment créer un pipeline évolutif pour le développement et le déploiement d'algorithmes d'apprentissage automatique pour la vente au détail sans contact
La startup israélienne Trigo partage son expérience de l'utilisation de l'apprentissage automatique et de la vision par ordinateur pour la vente au détail à emporter. L'entreprise est fournisseur d'un système permettant aux magasins de fonctionner sans caisse enregistreuse. Les auteurs racontent à quelles tâches ils ont été confrontés et expliquent pourquoi ils ont choisi PyTorch comme cadre d'apprentissage automatique et Allegro AI Trains pour l'infrastructure et comment ils ont réussi à établir le processus de développement.
C'est tout, merci pour votre attention!