bayt.
Pourquoi moi ceci devrait s'inquiéter
Les données sont stockées en mémoire sous forme de structures de données, telles que des objets, des listes, des tableaux, etc. Mais si vous voulez envoyer des données sur le réseau ou dans un fichier, vous devez les encoder comme une séquence de baytov. les représentations en mémoire dans une séquence d'octets sont appelées codage, et la transformation inverse - dekodirovaniem. éventuellement, le diagramme de données traité par l'application, ou stocké en mémoire peut évoluer, de nouveaux champs peuvent être ajoutés ou supprimés. Par conséquent, Used encoding doit have as reverse (nouveau code doit be capable read data write old code), so et direct (l'ancien code doit être capable read data wrotenewcode) compatibility.
Dans
cet article, nous discuterons d'une variété de formats de codage, découvrirons pourquoi le codage binaire est meilleur que JSON, XML, et aussi que les méthodes de codage binaire prennent en charge les changements de schémas
dannyh.
Types codage de formats
Ilexiste deux types de formats d'encodage:
- Texte formats
- Binaire formats
Text formats
Lesformats de texte Des exemples de formats courants sont JSON, CSV et XML. Les formats de texte sont faciles à utiliser et à comprendre, mais ils présentent certains problèmes:
- . , XML CSV . JSON , , . . , , 2^53 Twitter, 64- . JSON, API Twitter, ID — JSON- – - , JavaScript- .
- CSV , .
- Les formats de texte prennent plus d'espace que l'encodage binaire. Par exemple, l'une des raisons est que JSON et XML sont sans schéma et doivent donc contenir des noms de champ.
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}Le codage JSON de cet exemple prend 82 octets une fois que tous les espaces ont été supprimés.
Encodage binaire
Pour l'analyse des données qui n'est utilisée qu'en interne, vous pouvez choisir un format plus léger ou plus rapide. Bien que JSON soit moins verbeux que XML, les deux prennent encore beaucoup de place par rapport aux formats binaires. Dans cet article, nous aborderons trois formats d'encodage binaire différents:
- Épargne
- Tampons de protocole
- Avro
Tous fournissent une sérialisation efficace des données à l'aide de schémas et disposent d'outils pour générer du code, ainsi que d'un support pour travailler avec différents langages de programmation. Ils prennent tous en charge l'évolution des schémas, offrant à la fois une compatibilité ascendante et ascendante.
Tampons d'épargne et de protocole
Thrift est développé par Facebook et Protocol Buffers est développé par Google. Dans les deux cas, un schéma est nécessaire pour encoder les données. Thrift définit un schéma en utilisant son propre langage de définition d'interface (IDL).
struct Person {
1: string userName,
2: optional i64 favouriteNumber,
3: list<string> interests
}
Schéma équivalent pour les tampons de protocole:
message Person {
required string user_name = 1;
optional int64 favourite_number = 2;
repeated string interests = 3;
}Comme vous pouvez le voir, chaque champ a un type de données et un numéro d'étiquette (1, 2 et 3). Thrift a deux formats d'encodage binaire différents: BinaryProtocol et CompactProtocol. Le format binaire est simple comme indiqué ci-dessous et prend 59 octets pour encoder les données ci-dessus.
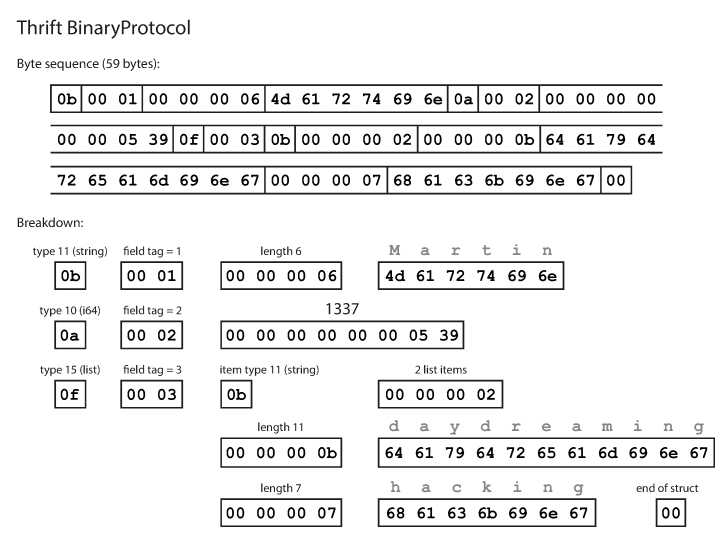
Encodage à l'aide du protocole binaire Thrift Le protocole
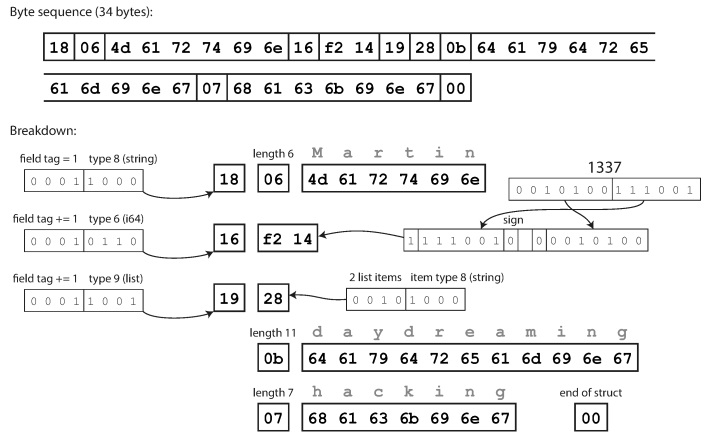
compact est sémantiquement équivalent au binaire, mais regroupe les mêmes informations en seulement 34 octets. Des économies sont réalisées en regroupant le type de champ et le numéro d'étiquette dans un octet.
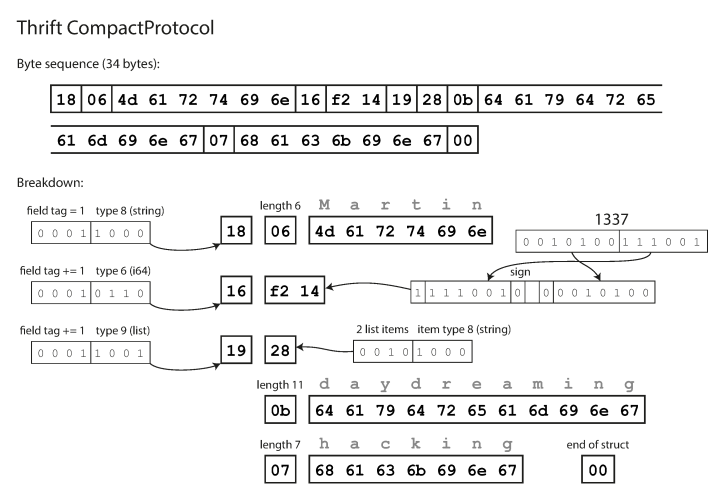
L'encodage à l'aide des
tampons de protocole compacts Thrift encode les données d'une manière similaire au protocole compact de Thrift, et après l'encodage, les mêmes données sont de 33 octets.
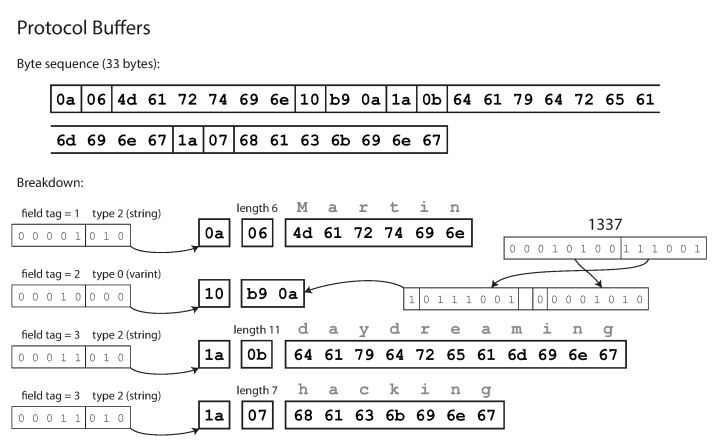
Encodage à l'aide de tampons de protocole
Les numéros de balises prennent en charge l'évolution des schémas dans les tampons Thrift et Protocol. Si l'ancien code essaie de lire les données écrites avec le nouveau schéma, il ignorera simplement les champs avec les nouveaux numéros d'étiquette. De même, le nouveau code peut lire les données écrites dans l'ancien schéma en marquant les valeurs comme nulles pour les numéros de balise manquants.
Avro
Avro est différent de Protocol Buffers et Thrift. Avro utilise également un schéma pour définir les données. Le schéma peut être défini à l'aide de l'Avro IDL (format lisible par l'homme):
record Person {
string userName;
union { null, long } favouriteNumber;
array<string> interests;
}
Ou JSON (un format plus lisible par machine):
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favouriteNumber", "type": ["null", "long"]},
{"name": "interests", "type": {"type": "array", "items": "string"}}
]
}
Notez que les champs n'ont pas de numéros d'étiquette. Les mêmes données encodées avec Avro ne prennent que 32 octets.
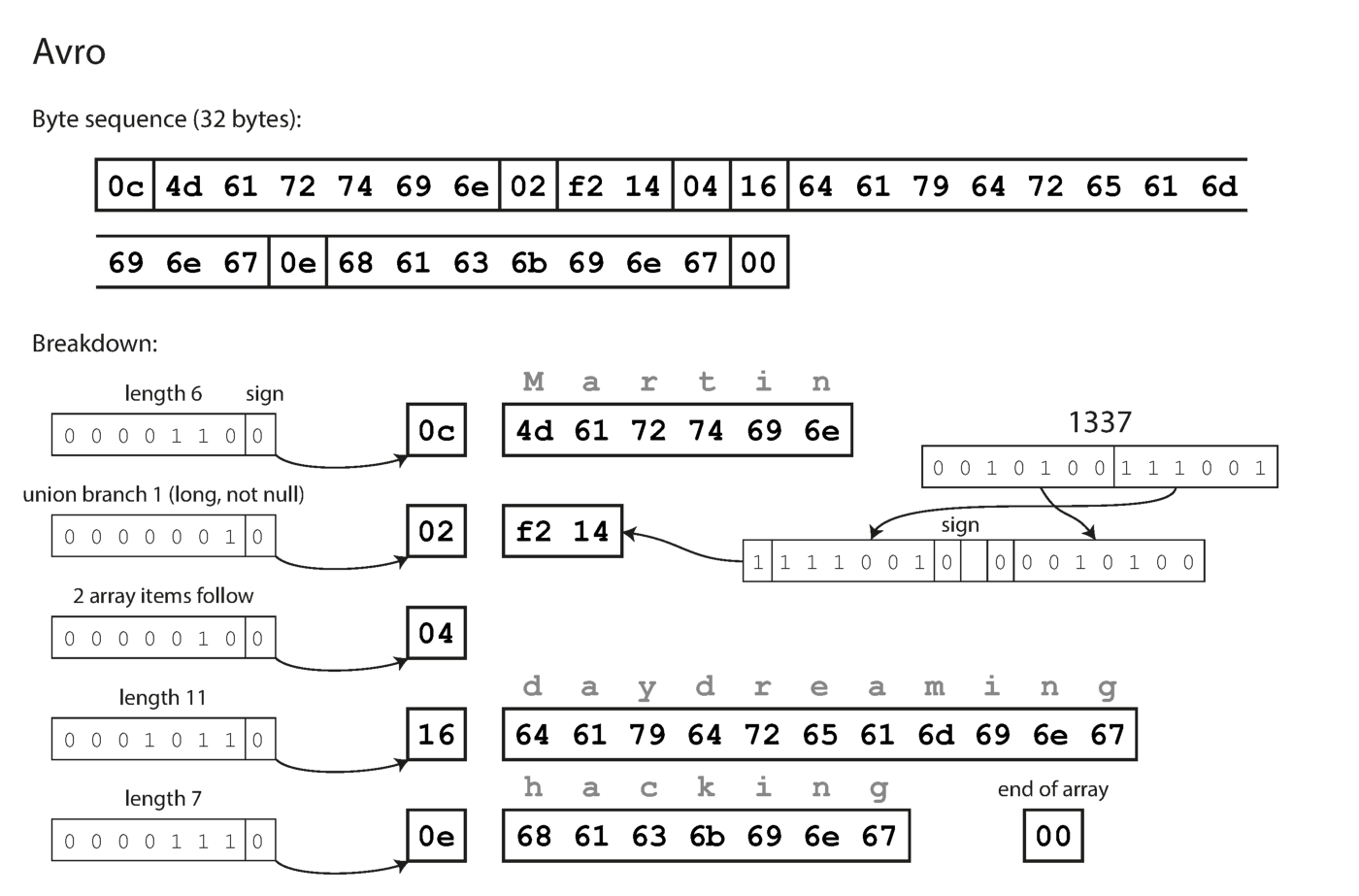
Codage avec Avro.
Comme vous pouvez le voir à partir de la séquence d'octets ci-dessus, les champs ne peuvent pas être identifiés (dans Thrift et Protocol Buffers des étiquettes avec des nombres sont utilisés pour cela), il est également impossible de déterminer le type de données du champ. Les valeurs sont simplement rassemblées. Cela signifie-t-il que toute modification du circuit pendant le décodage générera des données incorrectes? L'idée clé d'Avro est que le schéma d'écriture et de lecture ne doit pas nécessairement être le même, mais il doit être compatible. Lorsque les données sont décodées, la bibliothèque Avro résout ce problème en examinant les deux circuits et en traduisant les données du circuit enregistreur vers le circuit lecteur.
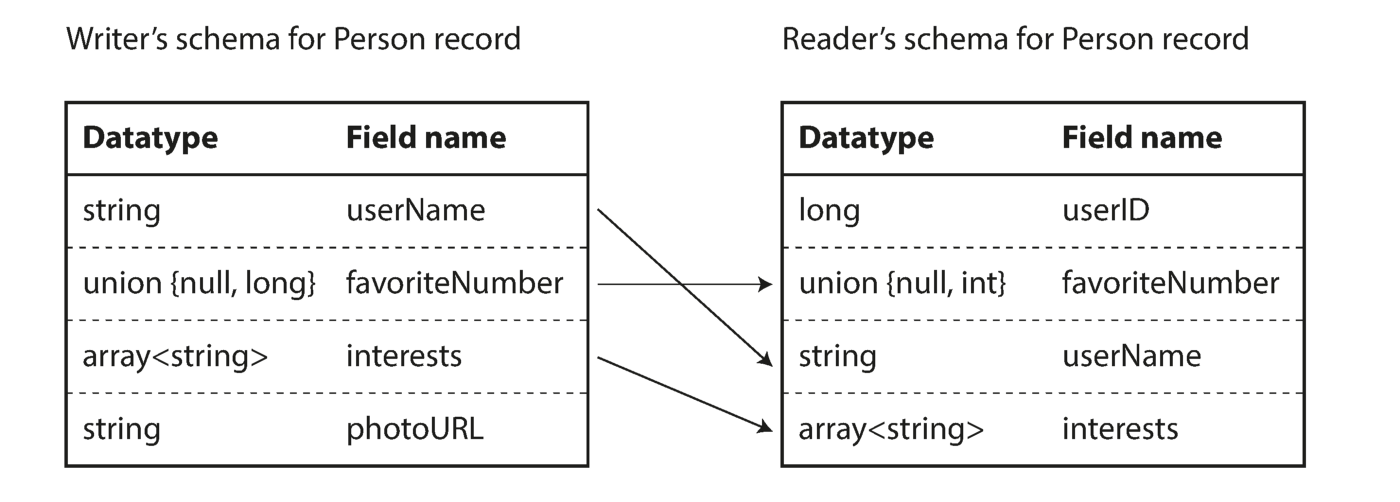
Élimination de la différence entre les circuits du lecteur et de l'écrivain
Vous pensez probablement à la manière dont le lecteur découvre les circuits de l'écrivain. Tout dépend du scénario d'utilisation de l'encodage.
- Lors du transfert de fichiers ou de données volumineux, l'enregistreur peut inclure une fois le circuit au début du fichier.
- Dans une base de données avec des enregistrements individuels, chaque ligne peut être écrite avec son propre schéma. La solution la plus simple consiste à inclure un numéro de version au début de chaque entrée et à conserver une liste de schémas.
- Pour envoyer un enregistrement sur le réseau, le lecteur et l'écrivain peuvent s'entendre sur un schéma lorsque la connexion est établie.
L'un des principaux avantages de l'utilisation du format Avro est la prise en charge des schémas générés dynamiquement. Étant donné qu'aucune balise numérotée n'est générée, vous pouvez utiliser un système de contrôle de version pour stocker différentes entrées codées avec différents schémas.
Conclusion
Dans cet article, nous avons examiné les formats de texte et de codage binaire, expliqué comment les mêmes données peuvent occuper 82 octets avec le codage JSON, 33 octets avec les tampons Thrift et Protocol et seulement 32 octets avec le codage Avro. Les formats binaires offrent plusieurs avantages distincts par rapport à JSON lors du transfert de données sur le réseau entre des services back-end.
Ressources
Pour en savoir plus sur l'encodage et la conception d'applications gourmandes en données, je vous recommande vivement de lire Designing Data-Intensive Applications par Martin Kleppman.

Apprenez comment obtenir une profession recherchée à partir de zéro ou augmenter vos compétences et votre salaire en suivant des cours en ligne payés par SkillFactory:
- Cours d'apprentissage automatique (12 semaines)
- Apprendre la science des données à partir de zéro (12 mois)
- Profession analytique avec n'importe quel niveau de départ (9 mois)
- Cours Python pour le développement Web (9 mois)
Lire la suite
- Tendances de la science des données 2020
- La science des données est morte. Vive la science des affaires
- Les scientifiques de données cool ne perdent pas de temps sur les statistiques
- Comment devenir un Data Scientist sans cours en ligne
- 450 cours gratuits de l'Ivy League
- Data Science : «data»
- Data Sciene : Decision Intelligence