Ab Initio a de nombreuses transformations classiques et inhabituelles qui peuvent être étendues avec son propre PDL. Pour une petite entreprise, un outil aussi puissant est susceptible d'être redondant et la plupart de ses capacités peuvent être coûteuses et inutiles. Mais si votre échelle est proche de celle de Sberbank, alors Ab Initio peut vous intéresser.
Il aide l'entreprise à accumuler globalement des connaissances et à développer l'écosystème, et le développeur - à pomper ses compétences en ETL, à extraire des connaissances dans le shell, offre la possibilité de maîtriser le langage PDL, donne une image visuelle des processus de chargement, simplifie le développement en raison de l'abondance de composants fonctionnels.
Dans cet article, je parlerai des capacités d'Ab Initio et donnerai des caractéristiques comparatives de son travail avec Hive et GreenPlum.
- MDW GreenPlum
- Ab Initio Hive GreenPlum
- Ab Initio GreenPlum Near Real Time
La fonctionnalité de ce produit est très large et prend beaucoup de temps à apprendre. Cependant, avec les compétences de travail appropriées et les bons paramètres de performance, les résultats du traitement des données sont assez impressionnants. Utiliser Ab Initio pour un développeur peut lui donner une expérience intéressante. Il s'agit d'une nouvelle approche du développement ETL, un hybride entre un environnement visuel et le développement de téléchargement dans un langage de type script.
Les entreprises développent leurs écosystèmes et cet outil est plus que jamais utile. Avec l'aide d'Ab Initio, vous pouvez accumuler des connaissances sur votre entreprise actuelle et utiliser ces connaissances pour développer les anciennes et ouvrir de nouvelles entreprises. Des alternatives à Ab Initio peuvent être appelées à partir des environnements de développement visuel Informatica BDM et des environnements non visuels - Apache Spark.
Description de Ab Initio
Ab Initio, comme d'autres outils ETL, est une suite de produits.

Ab Initio GDE (Graphical Development Environment) est un environnement pour un développeur dans lequel il met en place des transformations de données et les connecte à des flux de données sous forme de flèches. Dans ce cas, un tel ensemble de transformations est appelé un graphe:

les connexions d'entrée et de sortie des composants fonctionnels sont des ports et contiennent des champs calculés dans les transformations. Plusieurs graphes reliés par des flux sous forme de flèches dans l'ordre de leur exécution sont appelés un plan.
Il existe plusieurs centaines de composants fonctionnels, ce qui est beaucoup. Beaucoup d'entre eux sont hautement spécialisés. Ab Initio propose une gamme plus large de transformations classiques que les autres outils ETL. Par exemple, Join a plusieurs sorties. En plus du résultat de la connexion des ensembles de données, vous pouvez accéder à la sortie des enregistrements des ensembles de données d'entrée, dont les clés n'ont pas pu être connectées. Vous pouvez également obtenir des rejets, des erreurs et un journal de l'opération de transformation, qui peuvent être lus dans la même colonne qu'un fichier texte et traités par d'autres transformations:

ou, par exemple, vous pouvez matérialiser le récepteur de données sous la forme d'un tableau et en lire les données dans la même colonne.
Il y a des transformations originales. Par exemple, la transformation Scan a les mêmes fonctionnalités que les fonctions analytiques. Il existe des transformations aux noms explicites: créer des données, lire Excel, normaliser, trier dans des groupes, exécuter un programme, exécuter SQL, joindre avec une base de données, etc. Les graphiques peuvent utiliser des paramètres d'exécution, y compris le transfert de paramètres du système d'exploitation ou vers le système d'exploitation ... Les fichiers avec un ensemble prêt à l'emploi de paramètres transmis au graphique sont appelés ensembles de paramètres (psets).
Comme prévu, Ab Initio GDE a son propre référentiel appelé EME (Enterprise Meta Environment). Les développeurs ont la possibilité de travailler avec des versions locales du code et d'enregistrer leurs développements dans le référentiel central.
Il est possible, pendant l'exécution ou après l'exécution du graphique, de cliquer sur n'importe quel flux reliant les transformations et de regarder les données qui sont passées entre ces transformations:

Il est également possible de cliquer sur n'importe quel flux et de voir les détails du suivi - dans combien de parallèles la transformation a fonctionné, combien de lignes et d'octets dans lequel de les parallèles sont chargés:

Il est possible de diviser l'exécution du graphe en phases et de marquer que certaines transformations doivent être effectuées en premier (en phase zéro), en suivant dans la première phase, en suivant dans la deuxième phase, etc.
Pour chaque transformation, vous pouvez choisir la soi-disant mise en page (où elle sera exécutée): sans parallèles ou en threads parallèles, dont le nombre peut être défini. Dans le même temps, les fichiers temporaires créés par Ab Initio lors du travail de transformations peuvent être placés à la fois dans le système de fichiers du serveur et dans HDFS.
Dans chaque transformation, en fonction du modèle par défaut, vous pouvez créer votre propre script dans le langage PDL, qui est un peu comme un shell.
Avec l'aide du langage PDL, vous pouvez étendre les fonctionnalités des transformations et, en particulier, générer dynamiquement (au moment de l'exécution) des fragments de code arbitraires en fonction des paramètres d'exécution.
De plus, Ab Initio a une intégration bien développée avec le système d'exploitation via le shell. Plus précisément, Sberbank utilise linux ksh. Vous pouvez échanger des variables avec le shell et les utiliser comme paramètres de graphe. Vous pouvez appeler l'exécution des graphiques Ab Initio à partir du shell et administrer Ab Initio.
En plus d'Ab Initio GDE, la livraison comprend de nombreux autres produits. Il existe un système de coopération qui prétend être appelé système d'exploitation. Il y a Control> Center où vous pouvez planifier et surveiller les flux de téléchargement. Il existe des produits pour faire du développement à un niveau plus primitif que ne le permet Ab Initio GDE.
Description du framework MDW et travail sur sa personnalisation pour GreenPlum
Avec ses produits, le fournisseur fournit le produit MDW (Metadata Driven Warehouse), qui est un configurateur de graphiques conçu pour aider aux tâches typiques de remplissage des entrepôts de données ou des coffres de données.
Il contient des analyseurs de métadonnées personnalisés (spécifiques au projet) et des générateurs de code prêts à l'emploi.
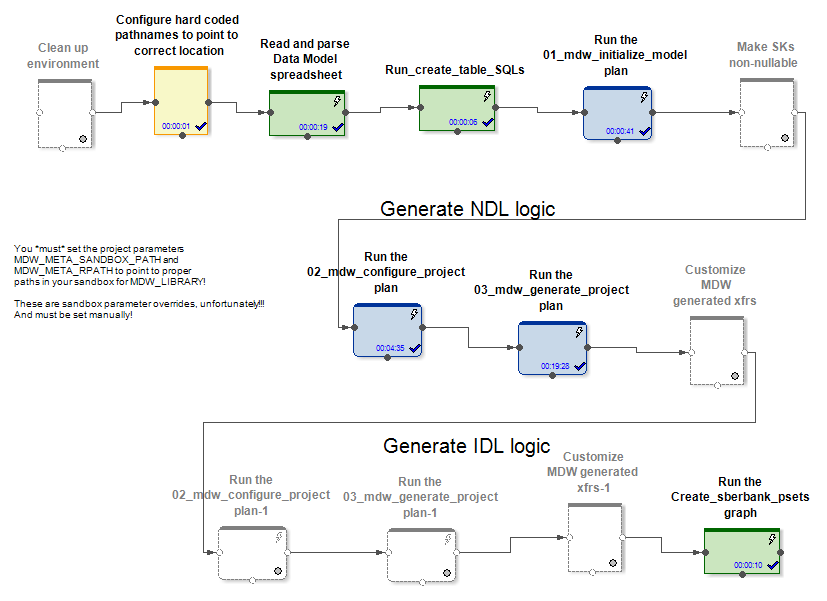
A l'entrée MDW reçoit un modèle de données, un fichier de configuration pour établir une connexion à une base de données (Oracle, Teradata ou Hive) et quelques autres paramètres. La partie spécifique au projet, par exemple, déploie le modèle dans la base de données. La partie encadrée du produit génère des graphiques et des fichiers de configuration pour eux lors du chargement des données dans les tables modèles. Cela crée des graphiques (et des psets) pour plusieurs modes d'initialisation et un travail incrémentiel sur la mise à jour des entités.
Dans les cas Hive et RDBMS, différents graphiques d'initialisation et d'actualisation incrémentielle des données sont générés.
Dans le cas de Hive, les données delta entrantes sont jointes par Ab Initio Join aux données qui se trouvaient dans la table avant la mise à jour. Les chargeurs de données dans MDW (à la fois dans Hive et dans SGBDR) insèrent non seulement de nouvelles données du delta, mais clôturent également les périodes de validité des données pour les clés primaires dont le delta a été reçu. De plus, vous devez réécrire la partie inchangée des données. Mais cela doit être fait, car Hive n'a pas d'opérations de suppression ou de mise à jour.
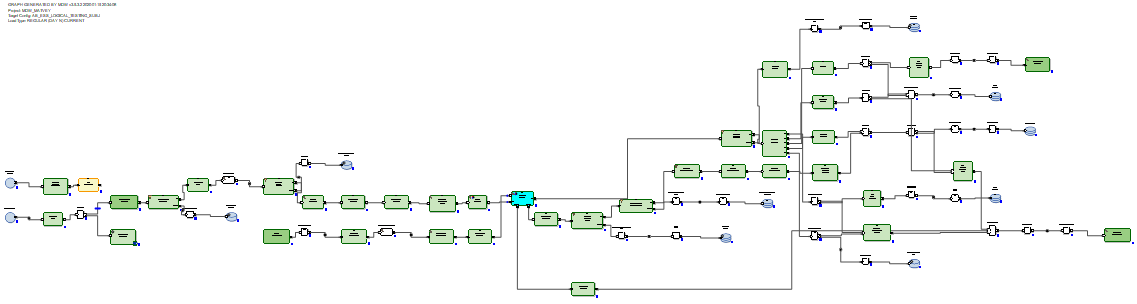
Dans le cas du SGBDR, les graphiques de mise à jour incrémentielle des données semblent plus optimaux car les SGBDR ont de réelles capacités de mise à jour.
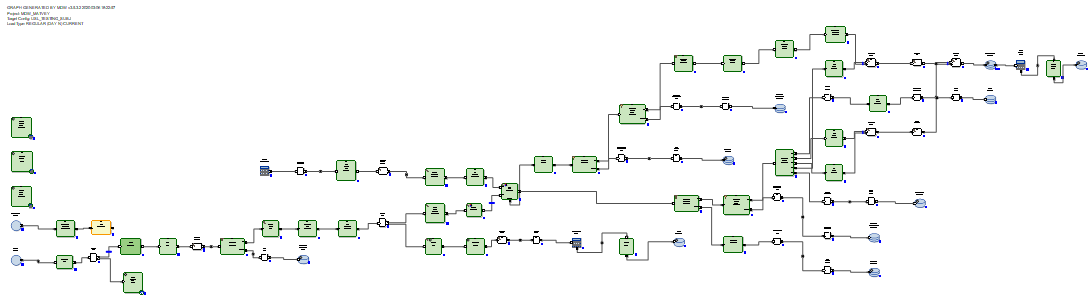
Le delta reçu est chargé dans une table intermédiaire de la base de données. Après cela, le delta est connecté aux données qui étaient dans la table avant la mise à jour. Et cela se fait au moyen de SQL via la requête SQL générée. Ensuite, à l'aide des commandes SQL delete + insert, de nouvelles données du delta sont insérées dans la table cible et les périodes de pertinence des données sont fermées, selon les clés primaires dont le delta a été reçu.
Il n'est pas nécessaire de réécrire les données inchangées.
Ainsi, nous sommes arrivés à la conclusion que dans le cas de Hive, MDW devrait aller réécrire la table entière, car Hive n'a pas de fonction de mise à jour. Et rien de mieux qu'une réécriture complète des données lorsque la mise à jour n'est pas inventée. Dans le cas du SGBDR, au contraire, les créateurs du produit ont jugé nécessaire de confier la connexion et la mise à jour des tables en utilisant SQL.
Pour un projet chez Sberbank, nous avons créé une nouvelle implémentation réutilisable du chargeur de base de données GreenPlum. Cela a été fait en fonction de la version générée par MDW pour Teradata. C'est Teradata, et non Oracle, qui est venu le mieux et le plus proche pour cela. est également un système MPP. La façon de travailler, ainsi que la syntaxe de Teradata et GreenPlum, se sont avérées similaires.
Des exemples de différences critiques pour MDW entre différents SGBDR sont les suivants. Dans GreenPlum, contrairement à Teradata, lors de la création de tables, vous devez écrire une clause
distributed byTeradata écrit
delete <table> all, et dans GreenePlum ils écrivent
delete from <table>Oracle écrit à des fins d'optimisation
delete from t where rowid in (< t >), et Teradata et GreenPlum écrivent
delete from t where exists (select * from delta where delta.pk=t.pk)Nous notons également que pour qu'Ab Initio fonctionne avec GreenPlum, il était nécessaire d'installer le client GreenPlum sur tous les nœuds du cluster Ab Initio. En effet, nous nous sommes connectés simultanément à GreenPlum depuis tous les nœuds de notre cluster. Et pour que la lecture depuis GreenPlum soit parallèle et que chaque thread Ab Initio parallèle lise sa propre portion de données depuis GreenPlum, il était nécessaire de mettre une construction comprise par Ab Initio dans la section «où» des requêtes SQL
where ABLOCAL()et déterminer la valeur de cette construction en spécifiant le paramètre lu dans la base de données de transformation
ablocal_expr=«string_concat("mod(t.", string_filter_out("{$TABLE_KEY}","{}"), ",", (decimal(3))(number_of_partitions()),")=", (decimal(3))(this_partition()))»qui compile à quelque chose comme
mod(sk,10)=3, c'est à dire. vous devez indiquer à GreenPlum un filtre explicite pour chaque partition. Pour les autres bases de données (Teradata, Oracle), Ab Initio peut effectuer cette parallélisation automatiquement.
Caractéristiques de performances comparatives d'Ab Initio pour travailler avec Hive et GreenPlum
Une expérience a été menée à la Sberbank pour comparer les performances des graphes générés par MDW par rapport à Hive et par rapport à GreenPlum. Dans le cadre de l'expérience, dans le cas de Hive, il y avait 5 nœuds sur le même cluster qu'Ab Initio, et dans le cas de GreenPlum, il y avait 4 nœuds sur un cluster séparé. Ceux. Hive avait un avantage matériel par rapport à GreenPlum.
Nous avons examiné deux paires de graphiques qui effectuent la même tâche de mise à jour des données dans Hive et GreenPlum. Les graphiques générés par le configurateur MDW ont été lancés:
- initialisation de la charge + chargement incrémentiel de données générées aléatoirement dans la table Hive
- initialisation de la charge + chargement incrémentiel de données générées aléatoirement dans la même table GreenPlum
Dans les deux cas (Hive et GreenPlum) ont lancé des téléchargements dans 10 threads parallèles sur le même cluster Ab Initio. Ab Initio a enregistré des données intermédiaires pour les calculs en HDFS (en termes d'Ab Initio, la mise en page MFS utilisant HDFS a été utilisée). Une ligne de données générées aléatoirement occupait 200 octets dans les deux cas.
Le résultat est comme ceci:
Hive:
| Initialisation du chargement dans Hive | |||
| Lignes insérées | 6 000 000 | 60 000 000 | 600 000 000 |
| Durée de l'initialisation de la
charge en secondes |
41 | 203 | 1 601 |
| Chargement incrémentiel dans Hive | |||
| Le nombre de lignes dans la
table cible au début de l'expérience |
6 000 000 | 60 000 000 | 600 000 000 |
| Nombre de lignes delta appliquées à la
table cible pendant le test |
6 000 000 | 6 000 000 | 6 000 000 |
| Durée de
téléchargement incrémentielle en secondes |
88 | 299 | 2541 |
GreenPlum:
| GreenPlum | |||
| 6 000 000 | 60 000 000 | 600 000 000 | |
|
|
72 | 360 | 3 631 |
| GreenPlum | |||
| ,
|
6 000 000 | 60 000 000 | 600 000 000 |
| ,
|
6 000 000 | 6 000 000 | 6 000 000 |
|
|
159 | 199 | 321 |
Nous voyons que la vitesse d'initialisation du téléchargement dans Hive et GreenPlum dépend linéairement de la quantité de données et, pour des raisons de meilleur matériel, elle est un peu plus rapide pour Hive que pour GreenPlum.
Le chargement incrémentiel dans Hive dépend également de manière linéaire de la quantité de données précédemment chargées dans la table cible et est plutôt lent à mesure que la quantité augmente. Cela est dû à la nécessité d'écraser complètement la table cible. Cela signifie que l'application de petites modifications à d'énormes tables n'est pas un bon cas d'utilisation pour Hive.
Le chargement incrémentiel dans GreenPlum dépend faiblement de la quantité de données précédemment chargées disponibles dans la table cible et est assez rapide. Cela s'est produit grâce aux jointures SQL et à l'architecture GreenPlum, qui permet l'opération de suppression.
Ainsi, GreenPlum injecte delta à l'aide de la méthode delete + insert, tandis que Hive n'a pas d'opérations de suppression ou de mise à jour, de sorte que l'ensemble du tableau de données a été forcé de réécrire l'ensemble du tableau de données lors d'une mise à jour incrémentielle. La plus indicative est la comparaison des cellules mises en évidence en gras, car elle correspond à la variante la plus fréquente du fonctionnement des téléchargements gourmands en ressources. On voit que GreenPlum a gagné 8 fois sur Hive dans ce test.
Ab Initio avec GreenPlum en temps quasi réel
Dans cette expérience, nous testerons la capacité d'Ab Initio à mettre à jour la table GreenPlum avec des morceaux de données générés aléatoirement en temps quasi réel. Prenons la table GreenPlum dev42_1_db_usl.TESTING_SUBJ_org_finval, avec laquelle nous allons travailler.
Nous utiliserons trois graphiques Ab Initio pour travailler avec lui:
1) Graphique Create_test_data.mp - crée des fichiers avec des données en HDFS pour 6 000 000 lignes dans 10 flux parallèles. Les données sont aléatoires, leur structure est organisée pour être

insérée dans notre table 2) Graphique mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset - graphique MDW généré pour l'initialisation de l'insertion de données dans notre table en 10 threads parallèles (les données de test générées par le graphique (1) sont utilisées)

3) Graphique mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset - Graphique généré par MDW pour la mise à jour incrémentielle de notre table dans 10 threads parallèles en utilisant une partie de nouvelles données entrantes (delta) générées par le graphique (1)

Exécutons le script suivant en mode NRT:
- générer 6 000 000 lignes de test
- faire l'initialisation de la charge insérer 6 000 000 lignes de test dans une table vide
- répéter 5 fois le téléchargement incrémentiel
- générer 6 000 000 lignes de test
- faire une insertion incrémentielle de 6 000 000 lignes de test dans la table (dans ce cas, les anciennes données sont marquées de l'heure d'expiration valid_to_ts et des données plus récentes avec la même clé primaire sont insérées)
Un tel scénario émule le mode de fonctionnement réel d'un certain système d'entreprise - une assez grande partie de nouvelles données apparaît en temps réel et se déverse immédiatement dans GreenPlum.
Voyons maintenant le journal du script:
Démarrez Create_test_data.input.pset à 2020-06-04 11:49:11
Terminez Create_test_data.input.pset à 2020-06-04 11:49:37
Démarrez mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset à 2020-06-04 11:49:37
Terminer mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset à 2020-06-04 11:50:42
Démarrer Create_test_data.input.pset à 2020-06-04 11:50:42
Terminer Create_test_data.input.pset à 2020-06-04 11:51:06
Démarrer mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset à 2020-06-04 11:51:06
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:53:41
Start Create_test_data.input.pset at 2020-06-04 11:53:41
Finish Create_test_data.input.pset at 2020-06-04 11:54:04
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:54:04
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:56:51
Start Create_test_data.input.pset at 2020-06-04 11:56:51
Finish Create_test_data.input.pset at 2020-06-04 11:57:14
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:57:14
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:59:55
Commencez Create_test_data.input.pset à 2020-06-04 11:59:55
Terminez Create_test_data.input.pset à 2020-06-04 12:00:23
Démarrez mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset à 2020-06-04 12:00:23
Terminer mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset à 2020-06-04 12:03:23
Démarrer Create_test_data.input.pset à 2020-06-04 12:03:23
Terminer Create_test_data.input.pset à 2020-06-04 12:03:49
Début mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset à 2020-06-04 12:03:49
Terminer mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset à 2020-06-04 12:03:49 Terminer mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset à 2020-06-04 12:03:49 : 46 L'
image ressemble à ceci:
| Graphique | Heure de début | Heure de fin | Longueur |
|---|---|---|---|
| Create_test_data.input.pset | 06/04/2020 11:49:11 | 06/04/2020 11:49:37 | 00:00:26 |
| mdw_load.day_one.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:49:37 | 06/04/2020 11:50:42 | 00:01:05 |
| Create_test_data.input.pset | 06/04/2020 11:50:42 | 06/04/2020 11:51:06 | 00:00:24 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:51:06 | 06/04/2020 11:53:41 | 00:02:35 |
| Create_test_data.input.pset | 06/04/2020 11:53:41 | 06/04/2020 11:54:04 | 00:00:23 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:54:04 | 06/04/2020 11:56:51 | 00:02:47 |
| Create_test_data.input.pset | 06/04/2020 11:56:51 | 06/04/2020 11:57:14 | 00:00:23 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:57:14 | 04/06/2020 11:59:55 | 00:02:41 |
| Create_test_data.input.pset | 04/06/2020 11:59:55 | 06/04/2020 12:00:23 | 00:00:28 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 12:00:23 | 04.06.2020 12:03:23 | 00:03:00 |
| Create_test_data.input.pset | 04.06.2020 12:03:23 | 04.06.2020 12:03:49 | 00:00:26 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
04.06.2020 12:03:49 | 04.06.2020 12:06:46 | 00:02:57 |
On voit que 6 000 000 de lignes incrémentielles sont traitées en 3 minutes, ce qui est assez rapide.
Les données de la table cible se sont avérées être réparties comme suit:
select valid_from_ts, valid_to_ts, count(1), min(sk), max(sk) from dev42_1_db_usl.TESTING_SUBJ_org_finval group by valid_from_ts, valid_to_ts order by 1,2;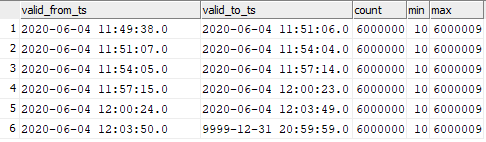
Vous pouvez voir la correspondance des données insérées avec les moments du lancement du graphique.
Cela signifie que vous pouvez démarrer le chargement incrémentiel des données dans GreenPlum dans Ab Initio avec une fréquence très élevée et observer une vitesse élevée d'insertion de ces données dans GreenPlum. Bien sûr, il ne sera pas possible de démarrer une fois par seconde, car Ab Initio, comme tout outil ETL, met du temps à «basculer» au démarrage.
Conclusion
Désormais, Ab Initio est utilisé dans Sberbank pour construire la couche de données sémantique unifiée (ESS). Ce projet consiste à construire une version unique de l'état des différentes entités bancaires. Les informations proviennent de diverses sources, dont des répliques sont préparées sur Hadoop. En fonction des besoins de l'entreprise, un modèle de données est préparé et les transformations de données sont décrites. Ab Initio télécharge des informations sur l'ECC et les données chargées ne présentent pas seulement un intérêt pour l'entreprise en soi, mais servent également de source pour la création de data marts. Dans le même temps, la fonctionnalité du produit vous permet d'utiliser divers systèmes (Hive, Greenplum, Teradata, Oracle) en tant que récepteur, ce qui permet de préparer sans effort des données pour l'entreprise dans les différents formats dont elle a besoin.
Les capacités d'Ab Initio sont larges, par exemple, le cadre MDW inclus permet de créer des données historiques techniques et commerciales prêtes à l'emploi. Pour les développeurs, Ab Initio donne la possibilité de «ne pas réinventer la roue», mais d'utiliser de nombreux composants fonctionnels disponibles, qui sont en fait des bibliothèques nécessaires pour travailler avec des données.
L'auteur est un expert de la communauté professionnelle de Sberbank SberProfi DWH / BigData. La communauté professionnelle SberProfi DWH / BigData est responsable du développement des compétences dans des domaines tels que l'écosystème Hadoop, Teradata, Oracle DB, GreenPlum, ainsi que les outils BI Qlik, SAP BO, Tableau, etc.