
Je dois dire tout de suite: je ne suis pas un informaticien, mais un passionné dans le domaine des statistiques. De plus, j'ai participé à diverses compétitions de pronostics de Formule 1 au fil des ans. D'où les tâches auxquelles mon modèle a dû faire face: émettre des prévisions qui ne seraient pas pires que celles qui sont créées "à l'oeil nu". Et idéalement, le modèle devrait bien sûr battre ses adversaires humains.
Ce modèle se concentre uniquement sur la prédiction du résultat des qualifications, car les qualifications sont plus prévisibles que les races et sont plus faciles à modéliser. Cependant, bien sûr, je prévois à l'avenir de créer un modèle qui permette de prédire les résultats des courses avec une précision suffisante.
Pour créer un modèle, j'ai résumé dans un tableau tous les résultats des pratiques et des qualifications pour les saisons 2018 et 2019.La 2018e année a servi d'échantillon de formation et la 2019e d'échantillon de test. Sur la base de ces données, nous avons construit une régression linéaire . Pour simplifier au maximum la régression, nos données sont une collection de points sur un plan de coordonnées. Nous avons tracé une ligne droite qui s'écarte le moins de la totalité de ces points. Et la fonction, dont le graphique est cette ligne - c'est notre régression linéaire.
D'après la formule connue du programme scolairenotre fonction ne se distingue que par le fait que nous avons deux variables. La première variable (X1) est le retard dans la troisième pratique, et la deuxième variable (X2) est le retard moyen dans les qualifications précédentes. Ces variables ne sont pas équivalentes et l'un de nos objectifs est de déterminer le poids de chaque variable dans la plage de 0 à 1. Plus une variable est éloignée de zéro, plus elle est importante pour expliquer la variable dépendante. Dans notre cas, la variable dépendante est le temps au tour, exprimé par le retard du leader (ou, plus précisément, à partir d'un certain «cercle idéal», puisque cette valeur était positive pour tous les pilotes).
Les fans du livre Moneyball (qui n'est pas expliqué dans le film) peuvent se rappeler qu'en utilisant la régression linéaire, ils ont déterminé que le pourcentage de base, alias OBP (pourcentage sur la base), est plus étroitement lié aux blessures gagnées que d'autres statistiques. Notre objectif est à peu près le même: comprendre quels facteurs sont les plus étroitement liés aux résultats des certifications. L'un des grands avantages de la régression est qu'elle ne nécessite pas de connaissances avancées en mathématiques: nous saisissons simplement les données, puis Excel ou un autre éditeur de feuille de calcul nous donne des coefficients prêts à l'emploi.
Fondamentalement, nous voulons savoir deux choses avec la régression linéaire. Premièrement, la mesure dans laquelle nos variables indépendantes choisies expliquent le changement de fonction. Et deuxièmement, quelle est l'importance de chacune de ces variables indépendantes. En d'autres termes, ce qui explique mieux les résultats des qualifications: les résultats des courses sur les pistes précédentes ou les résultats des entraînements sur la même piste.
Un point important doit être noté ici. Le résultat final était la somme de deux paramètres indépendants, chacun résultant de deux régressions indépendantes. Le premier paramètre est la force de l'équipe à ce stade, plus précisément le décalage entre le meilleur pilote de l'équipe et le leader. Le deuxième paramètre est la répartition des forces au sein de l'équipe.
Qu'est-ce que cela veut dire par exemple? Disons que nous remportons le Grand Prix de Hongrie 2019. Le modèle montre que Ferrari aura 0,218 seconde de retard sur le leader. Mais c'est le décalage du premier pilote, et qui ils seront - Vettel ou Leclair - et quel sera l'écart entre eux, est déterminé par un autre paramètre. Dans cet exemple, le modèle a montré que Vettel sera en avance et Leclair perdra 0,096 seconde contre lui.
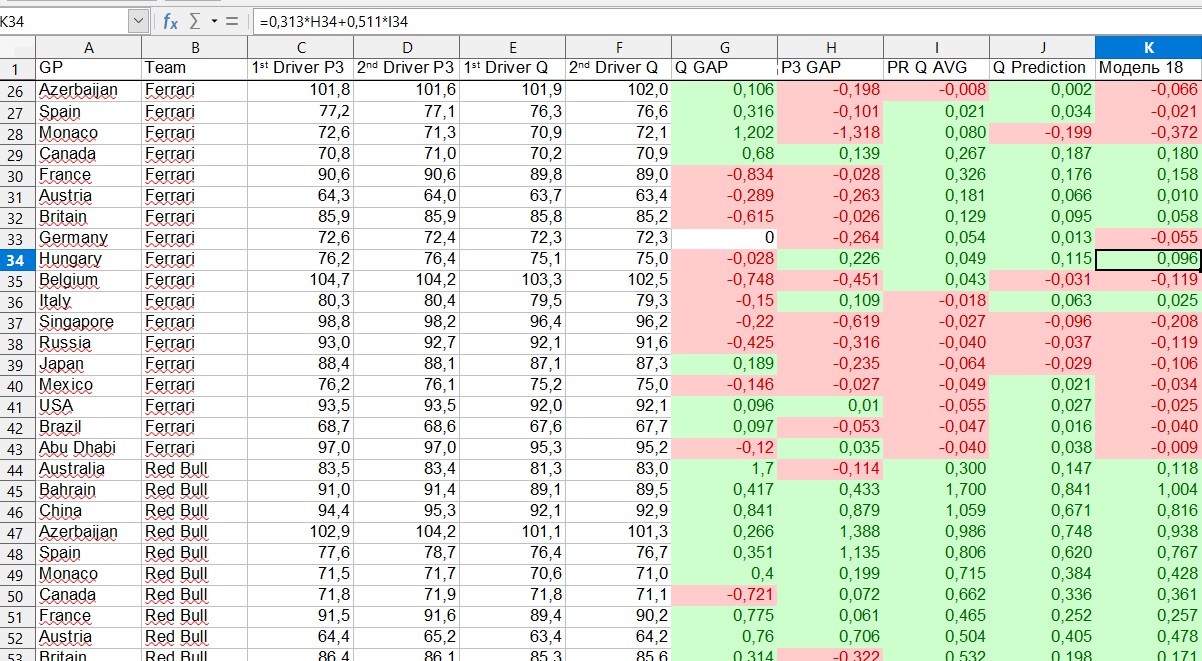
Pourquoi de telles difficultés? N'est-il pas plus facile de considérer chaque pilote séparément au lieu de cette répartition entre le décalage de l'équipe et le décalage du premier pilote par rapport au second au sein de l'équipe? C'est peut-être le cas, mais mes observations personnelles montrent qu'il est beaucoup plus fiable de regarder les résultats de l'équipe que les résultats de chaque pilote. Un pilote peut faire une erreur, ou voler hors de la piste, ou il aura des problèmes techniques - tout cela apportera le chaos au modèle, à moins que vous ne suiviez manuellement chaque situation de force majeure, ce qui prend trop de temps. L'influence de la force majeure sur les résultats de l'équipe est bien moindre.
Mais revenons au point où nous voulions évaluer dans quelle mesure les variables explicatives choisies expliquent le changement de fonction. Cela peut être fait en utilisant le coefficient de détermination... Il démontrera dans quelle mesure les résultats de la qualification sont expliqués par les résultats des stages et des qualifications antérieures.
Puisque nous avons construit deux régressions, nous avons également deux coefficients de détermination. La première régression est responsable du niveau de l'équipe au stade, la seconde de la confrontation entre les pilotes d'une même équipe. Dans le premier cas, le coefficient de détermination est de 0,82, c'est-à-dire que 82% des résultats des qualifications sont expliqués par les facteurs que nous avons choisis, et encore 18% - par d'autres facteurs que nous n'avons pas pris en compte. C'est un très bon résultat. Dans le second cas, le coefficient de détermination était de 0,13.
Ces mesures, en substance, signifient que le modèle prédit assez bien le niveau de l'équipe, mais a du mal à déterminer l'écart entre les coéquipiers. Cependant, pour l'objectif final, nous n'avons pas besoin de connaître l'écart, nous avons juste besoin de savoir lequel des deux pilotes sera le plus élevé, et le modèle y fait essentiellement face. Dans 62% des cas, le modèle a obtenu un meilleur classement que le pilote qui était vraiment plus haut dans la qualification.
Dans le même temps, lors de l'évaluation de la force de l'équipe, les résultats de la dernière formation étaient une fois et demie plus importants que les résultats des qualifications précédentes, mais dans les duels intra-équipes, c'était l'inverse. La tendance s'est manifestée dans les données de 2018 et 2019.
La formule finale ressemble à ceci:
Premier pilote:
Deuxième pilote:
Permettez-moi de vous rappeler que X1 est le retard dans la troisième pratique, et X2 est le retard moyen dans les qualifications précédentes.
Que signifient ces chiffres. Ils signifient que le niveau de l'équipe dans la qualification est de 60% déterminé par les résultats de la troisième pratique et de 40% - par les résultats des qualifications aux étapes précédentes. En conséquence, les résultats de la troisième pratique sont un facteur une fois et demie plus important que les résultats des qualifications précédentes.
Les fans de Formule 1 connaissent probablement la réponse à cette question, mais pour le reste, vous devriez expliquer pourquoi j'ai pris les résultats de la troisième pratique. Il y a trois pratiques en Formule 1. Cependant, c'est dans ces derniers que les équipes forment traditionnellement des qualifications. Cependant, dans les cas où la troisième pratique échoue en raison de la pluie ou d'un autre cas de force majeure, j'ai pris les résultats de la deuxième pratique. Autant que je me souvienne, en 2019, il n'y avait qu'un seul cas de ce genre - au Grand Prix du Japon, lorsque, en raison d'un typhon, l'étape s'est déroulée dans un format raccourci.
De plus, quelqu'un a probablement remarqué que le modèle utilise le décalage moyen des qualifications précédentes. Mais qu'en est-il de la première étape de la saison? J'ai utilisé les décalages de l'année précédente, mais je ne les ai pas laissés tels quels, mais je les ai ajustés manuellement en fonction du bon sens. Par exemple, en 2019, Ferrari était en moyenne 0,3 seconde plus rapide que Red Bull. Cependant, il semble que l'équipe italienne n'aura pas un tel avantage cette année, ou peut-être qu'elle sera complètement derrière. Par conséquent, pour la première étape de la saison 2020, le Grand Prix d'Autriche, j'ai rapproché manuellement le Red Bull de la Ferrari.
De cette façon, j'ai obtenu le retard de chaque pilote, classé les pilotes par retard et obtenu la prédiction finale pour la qualification. Il est important de comprendre, cependant, que les premier et deuxième pilotes sont de pures conventions. Revenant à l'exemple avec Vettel et Leclair, au Grand Prix de Hongrie, le mannequin a considéré Sébastien comme le premier pilote, mais à bien d'autres étapes, elle a préféré Leclair.
résultats
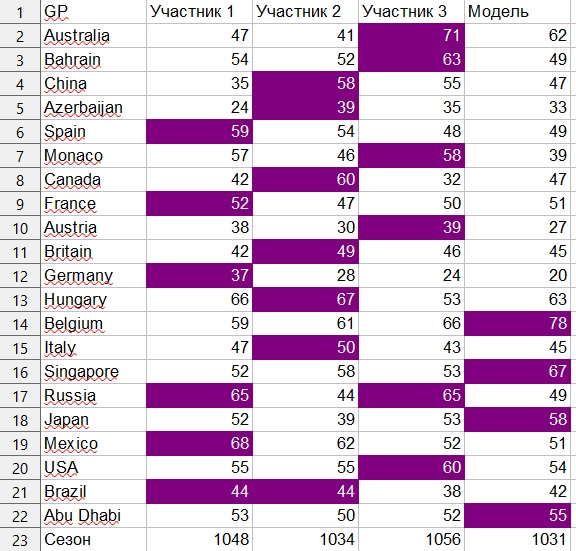
Comme je l'ai dit, la tâche était de créer un modèle qui permettrait de prédire aussi bien que les gens. Comme base, j'ai pris mes pronostics et les pronostics de mes coéquipiers, qui ont été créés "à l'oeil nu", mais avec une étude attentive des résultats des pratiques et des discussions communes.
Le système de notation était le suivant. Seuls les dix premiers pilotes ont été pris en compte. Pour un coup sûr, le pronostic a reçu 9 points, pour un raté en position 1, 6 points, pour un raté en position 2, 4 points, pour un raté en position 3, 2 points, et pour un raté en position 4, 1 point. Autrement dit, si dans les prévisions, le pilote est à la 3e place, et en conséquence il a pris la pole position, alors les prévisions ont reçu 4 points.
Avec ce système, le nombre maximum de points pour 21 Grand Prix est de 1890.
Les participants humains ont marqué respectivement 1056, 1048 et 1034 points.
Le modèle a marqué 1031 points, bien qu'avec une légère manipulation des coefficients, j'ai également reçu 1045 et 1053 points.
Personnellement, je suis satisfait des résultats, car c'est ma première expérience dans la construction de régressions, et cela a conduit à des résultats tout à fait acceptables. Bien sûr, je voudrais les améliorer, car je suis sûr qu'avec l'aide de la construction de modèles, même aussi simples que celui-ci, vous pouvez obtenir de meilleurs résultats qu'une simple évaluation des données "à l'œil nu". Dans le cadre de ce modèle, il serait possible, par exemple, de prendre en compte le fait que certaines équipes sont faibles en pratique, mais «tirent» en qualifications. Par exemple, il y a une observation que Mercedes n'était souvent pas la meilleure équipe lors de la formation, mais a beaucoup mieux performé en qualifications. Cependant, ces observations humaines ne sont pas reflétées dans le modèle. Donc dans la saison 2020, qui commence en juillet (si rien d'inattendu ne se produit), je souhaite tester ce modèle dans une compétition contre des prévisionnistes en direct et aussi trouver,comment il peut être amélioré.
De plus, j'espère entrer en résonance avec la communauté des fans de Formule 1 et je crois que grâce à l'échange d'idées, nous pouvons mieux comprendre ce qui constitue les résultats des qualifications et des courses, et c'est finalement le but de toute personne qui fait des prédictions.