
Cet article décrit les détails techniques des problèmes qui ont provoqué le crash de Slack le 12 mai 2020. Pour en savoir plus sur le processus de réponse à cet incident, consultez la chronologie de Ryan Katkov, «Les deux mains sur la télécommande» .
Le 12 mai 2020, Slack a connu son premier crash important depuis longtemps. Bientôt, nous avons publié un résumé de l'incident , mais c'est une histoire assez intéressante, nous aimerions donc nous attarder sur les détails techniques plus en détail.
Les utilisateurs ont remarqué le temps d'arrêt à 16 h 45, heure du Pacifique, mais l'histoire a en fait commencé vers 8 h 30. L'équipe d'ingénierie de fiabilité de la base de données a reçu un avertissement concernant une augmentation significative de la charge sur une partie de l'infrastructure. Dans le même temps, l'équipe de trafic a reçu des avertissements indiquant que nous ne faisons pas certaines demandes d'API.
L'augmentation de la charge de la base de données a été causée par le déploiement d'une nouvelle configuration, ce qui a provoqué un bogue de performances de longue date. Le changement a été rapidement repéré et annulé - il s'agissait d'un indicateur pour une fonction effectuant un déploiement progressif, le problème a donc été résolu rapidement. L'incident a eu peu d'impact sur les clients, mais il n'a duré que trois minutes, et la plupart des utilisateurs ont toujours réussi à envoyer des messages pendant ce petit problème du matin.
L'une des conséquences de l'incident a été une expansion significative de notre couche principale d'application Web. Notre PDG, Stuart Butterfield, a décrit certains des effets de la quarantaine et de l'auto-isolement sur l'utilisation de Slack. En raison de la pandémie, nous avons lancé beaucoup plus d'instances au niveau des applications Web qu'en février de cette année. Nous évoluons rapidement lorsque les travailleurs sont chargés, comme cela s'est produit ici - mais les travailleurs ont attendu beaucoup plus longtemps que certaines requêtes de base de données se terminent, ce qui a entraîné une charge plus élevée. Au cours de l'incident, nous avons augmenté le nombre d'instances de 75%, ce qui s'est traduit par le plus grand nombre d'hôtes d'applications Web que nous ayons jamais exécutés jusqu'à aujourd'hui.
Tout semblait bien fonctionner pendant les huit heures suivantes - jusqu'à ce qu'un nombre inhabituellement élevé d'erreurs HTTP 503 apparaisse . Nous avons lancé un nouveau canal de réponse aux incidents, et l'ingénieur d'applications Web en service a augmenté manuellement le parc d'applications Web comme mesure d'atténuation initiale. Curieusement, cela n'aidait pas du tout. Nous avons remarqué très rapidement que certaines des instances d'applications Web étaient soumises à une charge importante, tandis que les autres ne l'étaient pas. De nombreuses études ont commencé à étudier à la fois les performances des applications Web et l'équilibrage de charge. Après quelques minutes, nous avons identifié le problème.
Derrière l'équilibreur de charge de couche 4 se trouve un ensemble d'instances HAProxy pour distribuer les demandes au niveau application Web. Nous utilisons Consul pour la découverte de services et un modèle consul pour afficher des listes de backends d'applications Web sains vers lesquels HAProxy doit acheminer les requêtes.
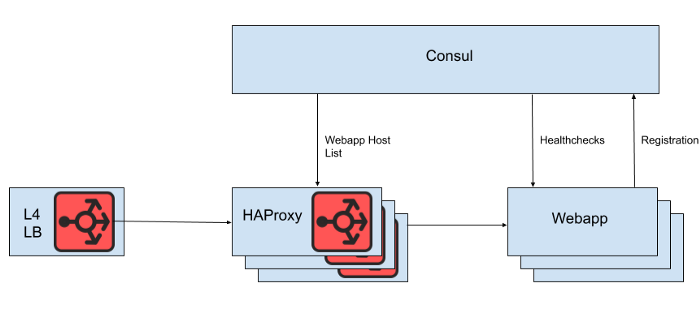
Figure. 1. Une vue de haut niveau de l'architecture d'équilibrage de charge Slack
Cependant, nous ne rendons pas la liste des hôtes d'applications Web directement à partir du fichier de configuration HAProxy, car la mise à jour de la liste dans ce cas nécessite un redémarrage de HAProxy. Le processus de redémarrage HAProxy consiste à créer un processus complètement nouveau, tout en conservant l'ancien jusqu'à ce qu'il termine le traitement des demandes en cours. Des redémarrages très fréquents peuvent entraîner l'exécution d'un trop grand nombre de processus HAProxy et de mauvaises performances. Cette limitation entre en conflit avec l'objectif de mise à l'échelle automatique du niveau de l'application Web, qui consiste à mettre en production de nouvelles instances le plus rapidement possible. Par conséquent, nous utilisons l' API HAProxy Runtimepour gérer l'état du serveur HAProxy sans redémarrer chaque fois que le serveur de niveau Web entre ou sort. Il convient de noter que HAProxy peut s'intégrer à l'interface DNS Consul, mais cela ajoute du retard dû au DNS TTL, limite la possibilité d'utiliser des balises Consul et la gestion de très grandes réponses DNS conduit souvent à des situations de bord douloureuses et des erreurs.

Figure. 2. Comment un ensemble de backends d'application Web est géré sur un seul serveur Slack HAProxy
Dans notre état HAProxy, nous définissons des modèles pour les serveurs HAProxy. En fait, ce sont des «emplacements» que les backends d'applications Web peuvent occuper. Lorsqu'une instance d'une nouvelle application Web est déployée ou que l'ancienne commence à échouer, le catalogue de services Consul est mis à jour. Consul-template imprime une nouvelle version de la liste d'hôtes, et un programme haproxy-server-state-management distinct développé dans Slack lit cette liste d'hôtes et utilise l'API HAProxy Runtime pour mettre à jour l'état HAProxy.
Nous exécutons M pools d'instances HAProxy et pools d'applications Web simultanés, chacun dans une zone de disponibilité AWS distincte. HAProxy est configuré avec N "slots" pour les backends d'applications Web dans chaque AZ, ce qui donne un total de N * M backends qui peuvent être dirigés vers tous les AZ. Il y a quelques mois, ce nombre était plus que suffisant - nous n'avons jamais rien lancé d'aussi près que de nombreuses instances de notre niveau d'application Web. Cependant, après l'incident de la base de données du matin, nous avons lancé un peu plus que des instances d'application Web N * M. Si vous considérez les machines à sous HAProxy comme un jeu géant de chaises, certaines de ces instances Webapp sont laissées sans espace. Ce n'était pas un problème - nous avons une capacité de service plus que suffisante.
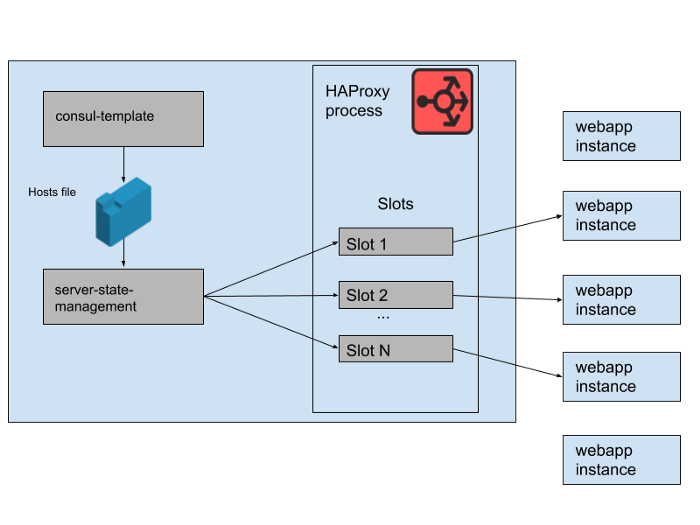
Figure. 3. "Slots" dans le processus HAProxy avec certaines instances d'application Web redondantes ne recevant pas de trafic.
Cependant, un problème est survenu pendant la journée. Il y avait un bogue dans le programme qui synchronisait la liste d'hôtes générée par le modèle consul avec l'état du serveur HAProxy. Le programme a toujours essayé de trouver un emplacement pour de nouvelles instances webapp avant de libérer des emplacements occupés par d'anciennes instances webapp qui ne fonctionnent plus. Ce programme a commencé à générer des erreurs et à se fermer tôt car il ne trouvait aucun emplacement vide, ce qui signifiait que les instances HAProxy en cours d'exécution ne mettaient pas à jour leur état. Au fur et à mesure que la journée avançait, le groupe d'autoscaling des applications Web grandissait et diminuait, et la liste des backends dans l'état HAProxy devenait de plus en plus obsolète.
À 16 h 45, la plupart des instances HAProxy ne pouvaient envoyer des requêtes qu'à l'ensemble des backends disponibles le matin, et cet ensemble d'anciens backends webapp était désormais minoritaire. Nous fournissons régulièrement de nouvelles instances HAProxy, il y en avait donc quelques nouvelles avec la configuration correcte, mais la plupart d'entre elles avaient plus de huit heures et étaient donc bloquées avec un état de backend complet et obsolète. Finalement, le service s'est écrasé. Cela s'est produit à la fin d'un jour ouvrable aux États-Unis, car c'est à ce moment-là que nous commençons à faire évoluer le niveau de l'application Web à mesure que le trafic diminue. La mise à l'échelle automatique arrêterait les anciennes instances webapp en premier lieu, ce qui signifiait qu'il n'y en avait pas assez dans l'état du serveur de HAProxy pour répondre à la demande.
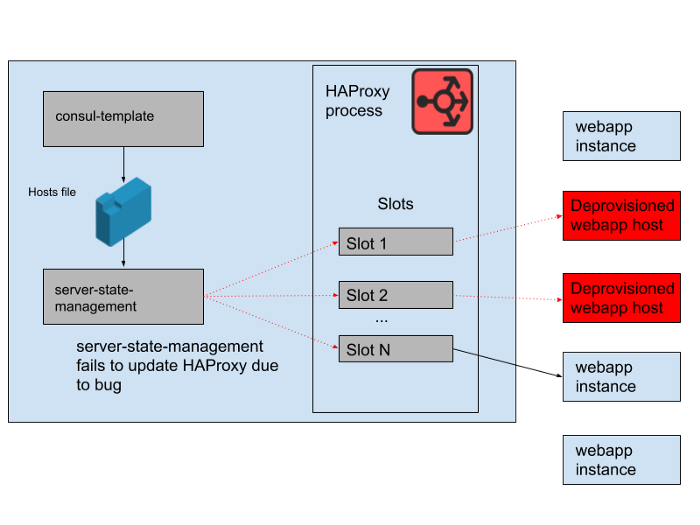
Figure. 4. L'état de HAProxy a changé au fil du temps et les slots ont commencé à se référer principalement aux hôtes distants.
Une fois que nous avons découvert la cause de la panne, elle a été rapidement corrigée par un redémarrage en douceur de la flotte HAProxy. Après cela, nous avons immédiatement posé une question: pourquoi la surveillance n'a pas détecté ce problème. Nous avons un système d'alerte pour cette situation particulière, mais malheureusement cela n'a pas fonctionné comme prévu. L'échec de la surveillance n'a pas été remarqué, en partie parce que le système «a simplement fonctionné» pendant une longue période et n'a nécessité aucune modification. Le déploiement plus large de HAProxy dont cette application fait partie est également relativement statique. À un rythme de changement lent, moins d'ingénieurs interagissent avec l'infrastructure de surveillance et d'alerte.
Nous n'avons pas beaucoup retravaillé cette pile HAProxy, car nous déplaçons progressivement tout l'équilibrage de charge vers Envoy (nous y avons récemment transféré le trafic Websocket). HAProxy a bien servi et de manière fiable pendant de nombreuses années, mais il a des problèmes opérationnels comme dans cet incident. Nous remplacerons le pipeline complexe de gestion de l'état du serveur HAProxy par notre propre intégration d'Envoy avec le plan de contrôle xDS pour la découverte des points finaux. Les versions les plus récentes de HAProxy (depuis la version 2.0) résolvent également nombre de ces problèmes opérationnels. Néanmoins, nous faisons confiance à Envoy avec le maillage de service interne depuis un certain temps maintenant, nous nous efforçons donc de lui transférer également l'équilibrage de charge. Notre test initial d'Envoy + xDS à grande échelle semble prometteur, et cette migration devrait améliorer les performances et la disponibilité à l'avenir.La nouvelle architecture d'équilibrage de charge et de découverte de services est immunisée contre le problème à l'origine de cet échec.
Nous nous efforçons de garder Slack accessible et fiable, mais dans ce cas, nous avons échoué. Slack est un outil essentiel pour nos utilisateurs, c'est pourquoi nous nous efforçons d'apprendre de chaque incident, que les clients l'aient remarqué ou non. Nous sommes désolés pour les inconvénients causés par cet échec. Nous nous engageons à utiliser ces connaissances pour améliorer nos systèmes et nos processus.