Contexte
En tant qu'amoureux du fer rétro, j'ai acheté une fois un ZX Spectrum + à un vendeur britannique. Complet avec l'ordinateur lui-même, j'ai reçu plusieurs cassettes audio avec des jeux (dans l'emballage d'origine avec instructions), ainsi que des programmes enregistrés sur des cassettes sans aucune désignation particulière. Étonnamment, les données des cassettes de 40 ans étaient lisibles et j'ai pu télécharger presque tous les jeux et programmes à partir d'elles.

Cependant, sur certaines cassettes, j'ai trouvé des enregistrements qui n'étaient clairement pas réalisés par l'ordinateur ZX Spectrum. Ils sonnaient complètement différents et, contrairement aux enregistrements de l'ordinateur susmentionné, ne commençaient pas avec un court chargeur de démarrage BASIC, qui est généralement présent dans les enregistrements de tous les programmes et jeux.
Pendant un certain temps, j'ai été hanté par cela - je voulais vraiment savoir ce qui se cache en eux. Si vous pouviez lire le signal audio comme une séquence d'octets, vous pourriez y chercher des caractères ou quelque chose qui indique l'origine du signal. Une sorte d'archéologie rétro.
Maintenant que j'ai parcouru tout le chemin et que je regarde les étiquettes des cassettes elles-mêmes, je souris parce que
la réponse était juste devant mes yeux tout ce temps
— TRS-80, : «Manufactured by Radio Shack in USA»
(Si vous voulez garder l'intrigue jusqu'au bout, ne passez pas sous le spoiler)
Comparaison des signaux audio
La première étape consiste à numériser les enregistrements audio. Vous pouvez écouter comment cela sonne:
Et comme d'habitude, l'enregistrement de l'ordinateur ZX Spectrum retentit:
Dans les deux cas, au début de l'enregistrement, il y a une soi-disant tonalité pilote - un son d'une fréquence (sur le premier enregistrement, il est très court <1 sec, mais reconnaissable). La tonalité pilote signale à l'ordinateur de se préparer à recevoir des données. En règle générale, chaque ordinateur ne reconnaît que "sa" tonalité pilote par la forme d'onde et sa fréquence.
Je dois dire à propos de la forme du signal lui-même. Par exemple, sur le ZX Spectrum, sa forme est rectangulaire:
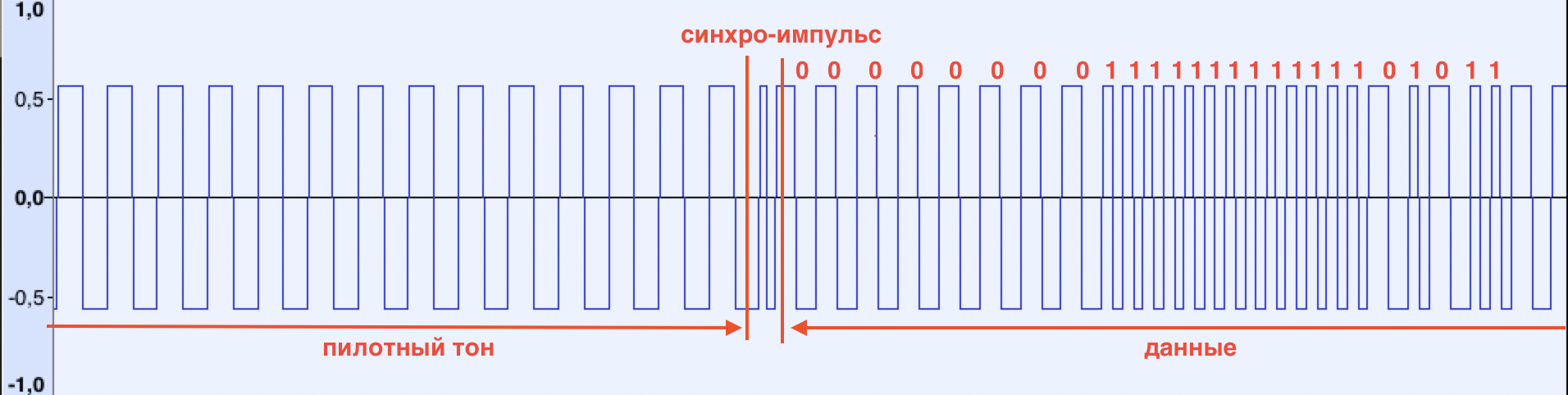
Lorsqu'une tonalité pilote est détectée, le ZX Spectrum affiche des bandes rouges et bleues en alternance sur le bord de l'écran, indiquant que le signal est reconnu. La tonalité pilote se termine par une impulsion synchro, qui signale à l'ordinateur de commencer à recevoir des données. Il se caractérise par une durée plus courte (par rapport à la tonalité pilote et aux données suivantes) (voir figure) Une
fois l'impulsion de synchronisation reçue, l'ordinateur enregistre chaque montée / descente du signal, en mesurant sa durée. Si la durée est inférieure à une certaine limite, le bit 1 est écrit en mémoire, sinon 0. Les bits sont collectés en octets et le processus est répété jusqu'à ce que N octets soient reçus. Le nombre N est généralement tiré de l'en-tête du fichier téléchargé. La séquence de démarrage est la suivante:
- tonalité pilote
- en-tête (longueur fixe), contient la taille des données chargées (N), le nom et le type de fichier
- tonalité pilote
- les données elles-mêmes
Pour s'assurer que les données sont chargées correctement, ZX Spectrum lit le dernier octet de la soi-disant parité d'octet (octet de parité), qui est calculée lorsque vous enregistrez l'opération de fichier XOR sur tous les octets des données enregistrées. Lors de la lecture du fichier, l'ordinateur calcule l'octet de parité à partir des données reçues et, si le résultat diffère de celui enregistré, affiche le message d'erreur «Erreur de chargement de la bande R». À proprement parler, l'ordinateur peut émettre ce message plus tôt si, lors de la lecture, il ne peut pas reconnaître l'impulsion (elle est manquée ou sa durée ne correspond pas à certaines limites)
Alors, voyons maintenant à quoi ressemble un signal inconnu:
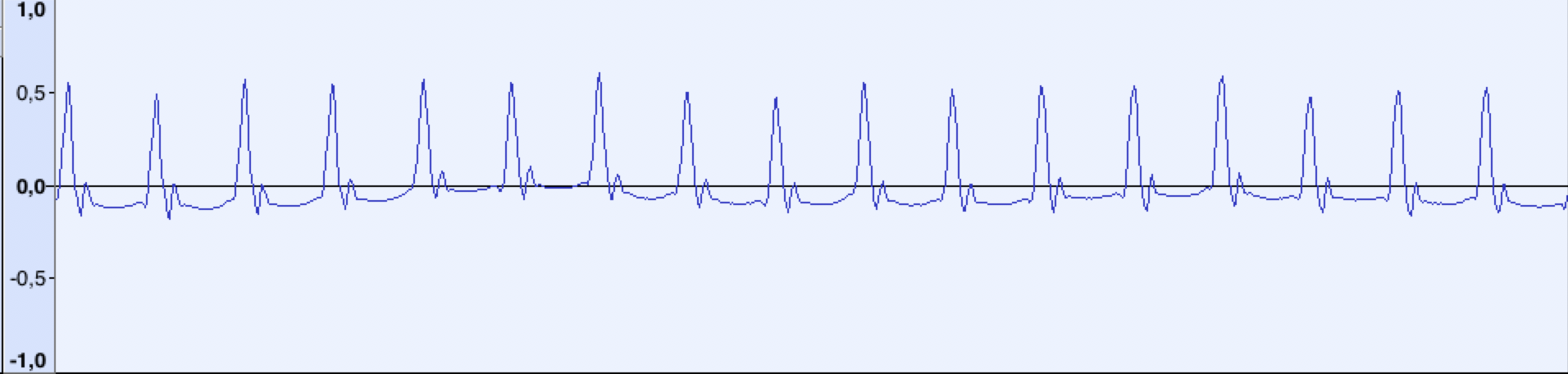
C'est une tonalité pilote. La forme d'onde est très différente, mais vous pouvez voir que le signal se compose d'impulsions courtes répétitives d'une certaine fréquence. A une fréquence d'échantillonnage de 44100 Hz, la distance entre les "pics" est d'environ 48 échantillons (ce qui correspond à une fréquence de ~ 918 Hz). Retenons ce chiffre.
Regardons maintenant le fragment avec les données:
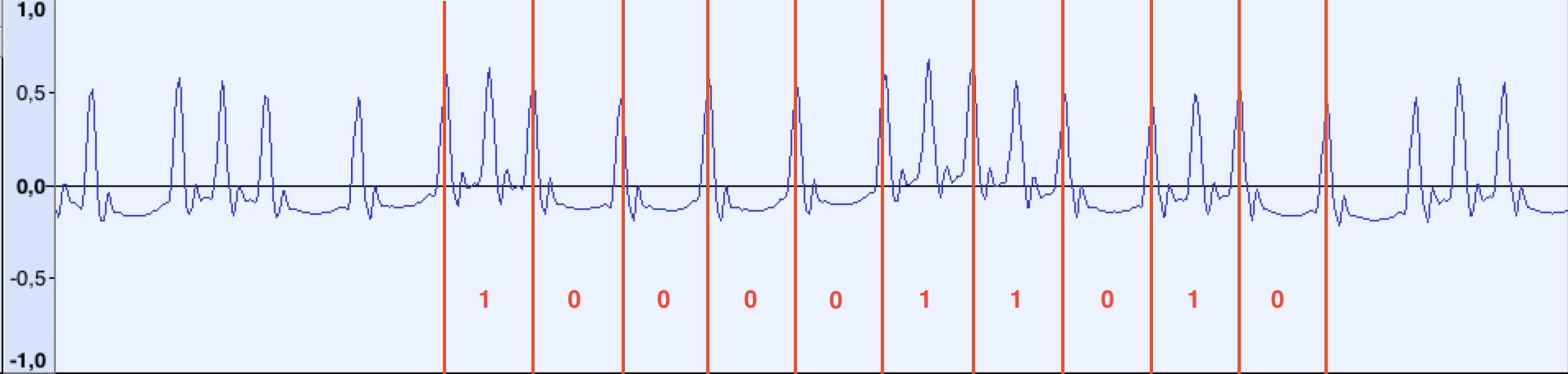
si nous mesurons la distance entre les impulsions individuelles, il s'avère que la distance entre les impulsions «longues» est toujours ~ 48 échantillons, et entre les impulsions courtes - ~ 24. En courant un peu plus loin, je dirai qu'au final, il s'est avéré que des impulsions "de référence" avec une fréquence de 918 Hz se succédaient en continu, du début à la fin du fichier. On peut supposer que lors de la transmission de données, si une impulsion supplémentaire se produit entre les impulsions de référence, on la considère comme le bit 1, sinon 0.
Qu'est-ce que l'impulsion synchro? Regardons le début des données:
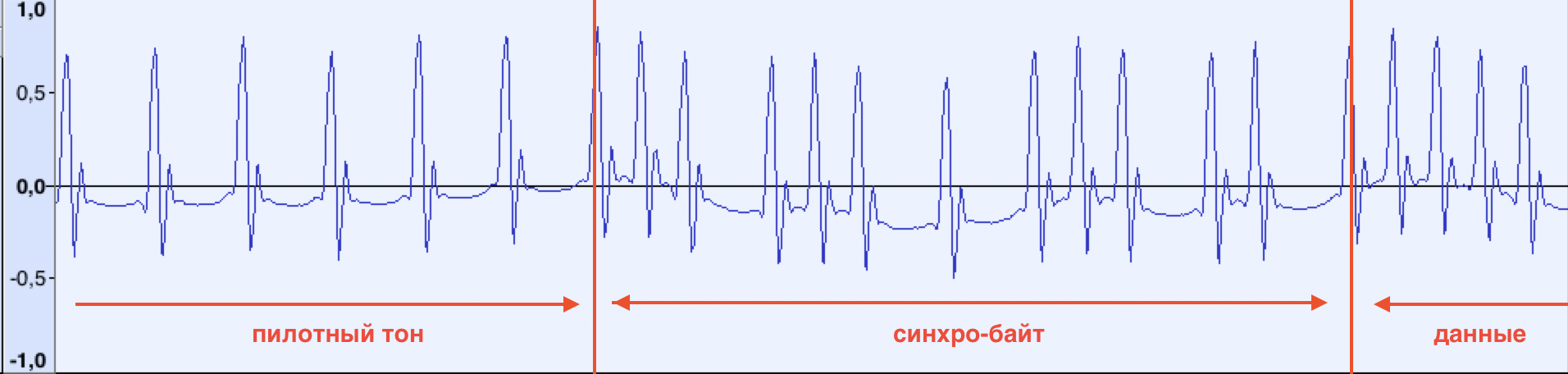
la tonalité pilote se termine et les données commencent immédiatement. Un peu plus tard, après avoir analysé plusieurs enregistrements audio différents, nous avons découvert que le premier octet de données est toujours le même (10100101b, A5h). L'ordinateur peut commencer à lire les données après les avoir reçues.
Vous pouvez également faire attention au décalage de la première impulsion de référence immédiatement après la dernière 1 dans le synchrobyte. Il a été découvert beaucoup plus tard dans le processus de développement d'un programme de reconnaissance de données, lorsque les données au début du fichier ne pouvaient pas être lues de manière stable.
Essayons maintenant de décrire un algorithme qui traitera un fichier audio et chargera des données.
Chargement des données
Tout d'abord, examinons quelques hypothèses pour ne pas compliquer l'algorithme:
- Nous considérerons uniquement les fichiers au format WAV;
- Le fichier audio doit commencer par une tonalité pilote et ne doit pas contenir de silence au début
- Le fichier source doit avoir une fréquence d'échantillonnage de 44100 Hz. Dans ce cas, la distance entre les impulsions de référence de 48 échantillons a déjà été déterminée et nous n'avons pas besoin de la calculer par programme;
- Le format de l'échantillon peut être n'importe quel (8/16 bits / virgule flottante) - car lors de la lecture, nous pouvons le convertir en celui souhaité;
- Nous supposons que le fichier d'origine est normalisé en amplitude, ce qui devrait stabiliser le résultat;
L'algorithme de lecture sera le suivant:
- Nous lisons le fichier en mémoire, en même temps nous convertissons le format de l'échantillon en 8 bits;
- Déterminez la position de la première impulsion dans les données audio. Pour ce faire, vous devez calculer le numéro de l'échantillon avec l'amplitude maximale. Pour plus de simplicité, comptons-le manuellement une fois. Sauvegardons-le dans la variable prev_pos;
- Ajouter 48 à la position de la dernière impulsion (pos: = prev_pos + 48)
- 48 , ( , ), pos. (pos-8;pos+8) . , , pos. 8 = 48/6 — , , . , 48, , ;
- , . , , . , , . , . 2 : , . ;
- ( 0 1), (prev_pos;pos) middle_pos middle_pos := (prev_pos+pos)/2 middle_pos (middle_pos-8;middle_pos+8) . 10, 1 0. 10 — ;
- prev_pos (prev_pos := pos)
- 3, ;
- . - , 8, . - 8 . . A5h,
Ruby,
Ruby, .. . , .
# gem 'wavefile'
require 'wavefile'
reader = WaveFile::Reader.new('input.wav')
samples = []
format = WaveFile::Format.new(:mono, :pcm_8, 44100)
# WAV , Mono, 8 bit
# samples 0-255
reader.each_buffer(10000) do |buffer|
samples += buffer.convert(format).samples
end
# ( 0)
prev_pos = 0
#
distance = 48
#
delta = (distance / 6).floor
# "0" "1"
bits = ""
loop do
#
pos = prev_pos + distance
#
break if pos + delta >= samples.size
# pos [pos - delta;pos + delta]
(pos - delta..pos + delta).each { |p| pos = p if samples[p] > samples[pos] }
# [prev_pos;pos]
middle_pos = ((prev_pos + pos) / 2).floor
#
sample = samples[middle_pos - delta..middle_pos + delta]
# "1" 10
bit = sample.max - sample.min > 10
bits += bit ? "1" : "0"
end
# - 256 ( )
bits.gsub! /^[01]*?10100101/, ("0" * 256) + "10100101"
# ,
File.write "output.cas", [bits].pack("B*")
Ayant essayé plusieurs variantes de l'algorithme et des constantes, j'ai eu la chance d'obtenir quelque chose d'extrêmement intéressant:
donc, à en juger par les chaînes de caractères, nous avons un programme pour tracer des graphiques. Cependant, il n'y a pas de mots clés dans le texte du programme. Tous les mots-clés sont codés en octets (chaque valeur> 80h). Nous devons maintenant déterminer quel ordinateur des années 80 pourrait enregistrer des programmes dans ce format.
C'est en fait très similaire à un programme BASIC. Dans à peu près le même format, l'ordinateur ZX Spectrum stocke en mémoire et enregistre les programmes sur bande. Juste au cas où, j'ai vérifié les mots-clés par rapport au tableau . Cependant, le résultat était évidemment négatif.
J'ai également vérifié les mots-clés BASIC des ordinateurs Atari alors populaires, le Commodore 64 et plusieurs autres, pour lesquels j'ai réussi à trouver de la documentation, mais en vain - ma connaissance des types d'ordinateurs rétro n'était pas si large.
Ensuite j'ai décidé de parcourir la liste , puis mes yeux sont tombés sur le nom du fabricant de Radio Shack et de l'ordinateur TRS-80. Ces noms étaient inscrits sur les étiquettes des cassettes qui se trouvaient sur ma table! Après tout, je ne connaissais pas ces noms auparavant et je ne connaissais pas l'ordinateur TRS-80.Il me semblait donc que Radio Shack était un fabricant de cassettes audio, telles que BASF, Sony ou TDK, et TRS-80 était la durée de lecture. Pourquoi pas?
Ordinateur Tandy / Radio Shack TRS-80
Il est très probable que l'enregistrement audio en question, que j'ai donné en exemple au début de l'article, ait été réalisé sur un tel ordinateur:

il s'est avéré que cet ordinateur et ses variantes (Model I / Model III / Model IV, etc.) étaient très populaires dans leur temps (bien sûr, pas en Russie). Il est à noter que le processeur utilisé est également le Z80. Beaucoup d'informations peuvent être trouvées sur cet ordinateur sur Internet . Dans les années 80, des informations sur l'ordinateur ont été diffusées dans des magazines . Pour le moment, il existe plusieurs émulateurs informatiques pour différentes plates-formes.
J'ai téléchargé l'émulateur trs80gpet pour la première fois, j'ai pu voir comment cet ordinateur fonctionnait. Bien sûr, l'ordinateur ne prenait pas en charge la sortie couleur, la résolution de l'écran n'était que de 128x48 pixels, mais de nombreuses extensions et modifications pouvaient augmenter la résolution de l'écran. Il y avait aussi de nombreuses options pour les systèmes d'exploitation pour cet ordinateur et des options pour implémenter le langage BASIC (qui, contrairement au ZX Spectrum, dans certains modèles n'était même pas "flashé" dans la ROM et toute option pouvait démarrer à partir d'une disquette, ainsi que le système d'exploitation lui-même)
. J'ai trouvé un utilitaire pour convertir les enregistrements audio au format CAS, qui est pris en charge par les émulateurs, mais pour une raison quelconque, je ne pouvais pas lire les enregistrements de mes cassettes en les utilisant.
Après avoir déterminé le format du fichier CAS (qui s'est avéré être juste une copie au niveau du bit des données de la bande, que j'avais déjà entre les mains, à l'exception de l'en-tête avec la présence d'un octet de synchronisation), j'ai apporté plusieurs modifications à mon programme et j'ai pu obtenir un fichier CAS fonctionnel à la sortie, ce qui il a fonctionné dans l'émulateur (TRS-80 Model III):
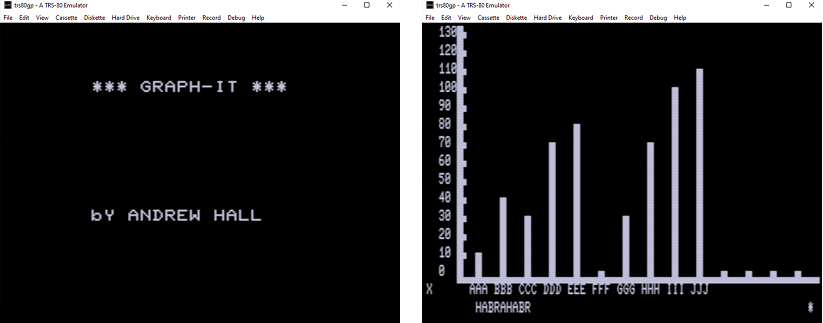
La dernière version de l'utilitaire de conversion avec détection automatique de la première impulsion et de la distance entre les impulsions de référence que j'ai conçu comme un package GEM, le code source est disponible sur Github .
Conclusion
Le chemin parcouru s'est avéré être un voyage passionnant dans le passé, et je suis heureux d'avoir finalement trouvé une solution. Entre autres, je:
- J'ai compris le format de sauvegarde des données dans le ZX Spectrum et étudié les routines ROM intégrées pour sauvegarder / lire des données à partir de bandes audio
- Je me suis familiarisé avec l'ordinateur TRS-80 et ses variétés, j'ai étudié le système d'exploitation, j'ai regardé des exemples de programmes et j'ai même eu l'occasion de déboguer dans les codes machine (après tout, tous les mnémoniques Z80 me sont familiers)
- J'ai écrit un utilitaire à part entière pour convertir des enregistrements audio au format CAS, qui peut lire des données qui ne sont pas reconnues par l'utilitaire "officiel"