
L'apprentissage automatique passe de plus en plus de modèles conçus à la main à des pipelines automatiquement optimisés à l'aide d'outils tels que H20 , TPOT et auto-sklearn . Ces bibliothèques, ainsi que des techniques telles que la recherche aléatoire , visent à simplifier la sélection de modèles et à ajuster certaines parties de l'apprentissage automatique en trouvant le meilleur modèle pour un ensemble de données sans aucune intervention manuelle. Cependant, le développement d'objets, sans doute l' aspect le plus précieux des pipelines d'apprentissage automatique, reste presque entièrement humain.
Caractéristiques de conception ( ingénierie des fonctionnalités), également connu sous le nom de création de fonctionnalités, est le processus de création de nouvelles fonctionnalités à partir de données existantes pour entraîner un modèle d'apprentissage automatique. Cette étape peut être plus importante que le modèle réel utilisé car l'algorithme d'apprentissage automatique n'apprend que des données que nous lui fournissons, et la création de fonctionnalités pertinentes pour la tâche est absolument nécessaire (voir l'excellent article «Quelques choses utiles Choses à savoir sur l'apprentissage automatique » ).
En règle générale, le développement de fonctionnalités est un long processus manuel basé sur la connaissance du domaine, l'intuition et la manipulation des données. Ce processus peut être extrêmement fastidieux et les caractéristiques finales seront limitées à la fois par la subjectivité humaine et le temps. La conception automatique des fonctionnalités vise à aider le scientifique des données à créer automatiquement de nombreux objets candidats à partir d'un ensemble de données à partir duquel les meilleurs peuvent être sélectionnés et utilisés pour la formation.
Dans cet article, nous examinerons un exemple d'utilisation du développement automatique de fonctionnalités avec la bibliothèque Python featuretools.. Nous utiliserons un exemple de jeu de données pour montrer les bases (attention aux futurs articles utilisant des données réelles). Le code complet de cet article est disponible sur GitHub .
Principes de base du développement de fonctionnalités
Le développement de caractéristiques signifie la création de caractéristiques supplémentaires à partir de données existantes, qui sont souvent réparties sur plusieurs tables liées. Le développement de fonctionnalités nécessite d'extraire des informations pertinentes des données et de les placer dans une table unique qui peut ensuite être utilisée pour entraîner un modèle d'apprentissage automatique.
Le processus de création de caractéristiques prend beaucoup de temps, car il faut généralement plusieurs étapes pour créer chaque nouvelle caractéristique, en particulier lors de l'utilisation d'informations provenant de plusieurs tables. Nous pouvons regrouper les opérations de création d'entités en deux catégories: les transformations et les agrégations . Jetons un coup d'œil à quelques exemples pour voir ces concepts en action.
Transformationagit sur une seule table (en termes Python, une table n'est que Pandas
DataFrame), créant de nouvelles fonctionnalités à partir d'une ou plusieurs colonnes existantes. Par exemple, si nous avons le tableau des clients ci-dessous,
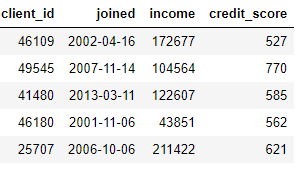
nous pouvons créer des entités en recherchant le mois dans une colonne
joinedou en prenant le logarithme naturel d'une colonne income. Ce sont deux transformations car elles n'utilisent que les informations d'une seule table.
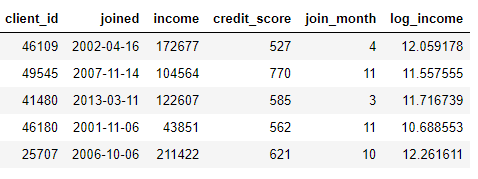
D'autre part, les agrégations sont effectuées entre les tables et utilisent une relation un-à-plusieurs pour regrouper les observations, puis calculer les statistiques. Par exemple, si nous avons un autre tableau avec des informations sur les prêts à la clientèle, où chaque client peut avoir plusieurs prêts, nous pouvons calculer des statistiques telles que les valeurs de prêt moyenne, maximale et minimale pour chaque client.
Ce processus comprend le regroupement de la table des prêts par client, le calcul de l'agrégation, puis la combinaison des données reçues avec les données du client. C'est ainsi que nous pourrions le faire en Python en utilisant le langage Pandas .
import pandas as pd
# Group loans by client id and calculate mean, max, min of loans
stats = loans.groupby('client_id')['loan_amount'].agg(['mean', 'max', 'min'])
stats.columns = ['mean_loan_amount', 'max_loan_amount', 'min_loan_amount']
# Merge with the clients dataframe
stats = clients.merge(stats, left_on = 'client_id', right_index=True, how = 'left')
stats.head(10)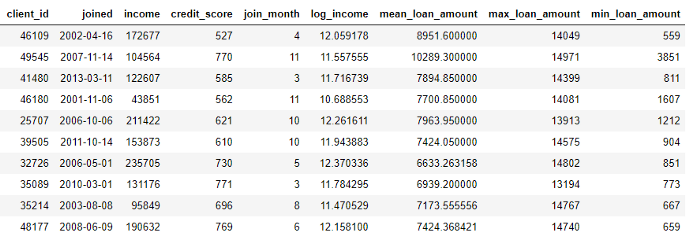
Ces opérations ne sont pas compliquées en elles-mêmes, mais si nous avons des centaines de variables dispersées sur des dizaines de tables, ce processus ne peut pas être effectué manuellement. Idéalement, nous avons besoin d'une solution capable d'effectuer automatiquement des transformations et des agrégations sur plusieurs tables et de combiner les données résultantes en une seule table. Bien que Pandas soit une excellente ressource, il reste encore de nombreuses manipulations de données que nous souhaitons effectuer manuellement! (Pour plus d'informations sur la conception manuelle des fonctionnalités, consultez l'excellent manuel Python Data Science Handbook .)
Outils en vedette
Heureusement, featuretools est exactement la solution que nous recherchons. Cette bibliothèque Python open source génère automatiquement de nombreux traits à partir d'un ensemble de tables associées. Featuretools est basé sur une technique connue sous le nom de " Deep Feature Synthesis " qui semble beaucoup plus impressionnante qu'elle ne l'est en réalité (le nom vient de la combinaison de plusieurs fonctionnalités, pas parce qu'il utilise l'apprentissage en profondeur!).
Deep Feature Synthesis combine plusieurs opérations de transformation et d'agrégation (appelées primitives de fonctionnalitédans le dictionnaire FeatureTools) pour créer des fonctionnalités à partir de données réparties sur de nombreuses tables. Comme la plupart des idées en apprentissage automatique, il s'agit d'une méthode complexe basée sur des concepts simples. En étudiant un bloc de construction à la fois, nous pouvons acquérir une bonne compréhension de cette technique puissante.
Jetons d'abord un coup d'œil aux données de notre exemple. Nous avons déjà vu quelque chose de l'ensemble de données ci-dessus, et l'ensemble complet des tables ressemble à ceci:
clients: informations de base sur les clients de l'association de crédit. Chaque client n'a qu'une seule ligne dans ce dataframe
loans: prêts aux clients. Chaque crédit n'a que sa propre ligne dans ce bloc de données, mais les clients peuvent avoir plusieurs crédits.
payments: remboursements de prêts. Chaque paiement n'a qu'une seule ligne, mais chaque prêt aura plusieurs paiements.
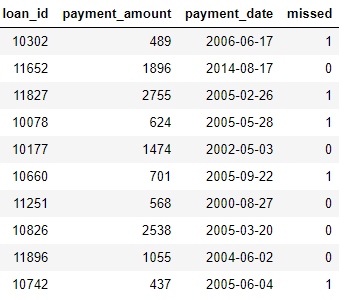
Si nous avons une tâche d'apprentissage automatique telle que prédire si un client remboursera un prêt futur, nous souhaitons regrouper toutes les informations client dans un seul tableau. Les tables sont liées (via les variables
client_idet loan_id), et nous pourrions utiliser une série de transformations et d'agrégations pour terminer manuellement le processus. Cependant, nous verrons bientôt que nous pouvons à la place utiliser featuretools pour automatiser le processus.
Entités et ensembles d'entités (entités et ensembles d'entités)
Les deux premiers concepts de featuretools sont des entités et des ensembles d' entités . L'entité n'est qu'une table (ou
DataFramesi vous pensez en Pandas). EntitySet est une collection de tables et de relations entre elles. Imagine entityset n'est qu'une autre structure de données Python avec ses propres méthodes et attributs.
Nous pouvons créer un ensemble vide d'entités dans featuretools en utilisant ce qui suit:
import featuretools as ft
# Create new entityset
es = ft.EntitySet(id = 'clients')Maintenant, nous devons ajouter des entités. Chaque entité doit avoir un index, qui est une colonne avec tous les éléments uniques. Autrement dit, chaque valeur de l'index ne doit apparaître qu'une seule fois dans la table. L'index dans le bloc de données
clientsest client_iddû au fait que chaque client n'a qu'une seule ligne dans ce bloc de données. Nous ajoutons une entité avec un index existant à l'ensemble d'entités en utilisant la syntaxe suivante:
# Create an entity from the client dataframe
# This dataframe already has an index and a time index
es = es.entity_from_dataframe(entity_id = 'clients', dataframe = clients,
index = 'client_id', time_index = 'joined')La trame de données
loansa également un index unique loan_idet la syntaxe pour l'ajouter à un ensemble d'entités est la même que pour clients. Cependant, il n'existe pas d'index unique pour la trame de données de paiement. Lorsque nous ajoutons cette entité à l'ensemble d'entités, nous devons passer un paramètre make_index = Trueet spécifier le nom de l'index. De plus, bien que featuretools infère automatiquement le type de données de chaque colonne d'une entité, nous pouvons le remplacer en passant un dictionnaire de types de colonne au paramètre variable_types.
# Create an entity from the payments dataframe
# This does not yet have a unique index
es = es.entity_from_dataframe(entity_id = 'payments',
dataframe = payments,
variable_types = {'missed': ft.variable_types.Categorical},
make_index = True,
index = 'payment_id',
time_index = 'payment_date')Pour cette base de données, même s'il
misseds'agit d'un entier, ce n'est pas une variable numérique car elle ne peut prendre que 2 valeurs discrètes, nous demandons donc à featuretools de la traiter comme une variable catégorielle. Après avoir ajouté les cadres de données à l'ensemble d'entités, nous examinons l'un d'entre eux:
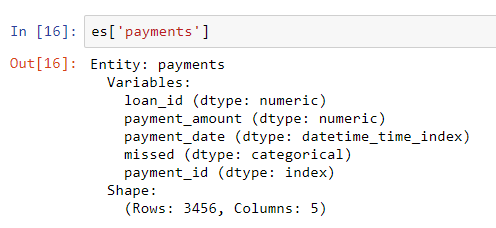
Les types de colonnes ont été déduits correctement avec la révision spécifiée. Ensuite, nous devons indiquer comment les tables de l'ensemble d'entités sont liées.
Relations entre les tables
La meilleure façon de représenter la relation entre deux tables consiste à utiliser une analogie parent-enfant . Relation un-à-plusieurs: chaque parent peut avoir plusieurs enfants. Dans la zone de table, la table parent a une ligne pour chaque parent, mais la table enfant peut avoir plusieurs lignes correspondant à plusieurs enfants du même parent.
Par exemple, dans notre jeu de données, le
clientscadre est le parent du loanscadre. Chaque client n'a qu'une seule ligne clients, mais peut avoir plusieurs lignes loans. De même, loansles parentspaymentsparce que chaque prêt aura plusieurs paiements. Les parents sont liés à leurs enfants par une variable commune. Lorsque nous faisons l'agrégation, nous regroupons la table enfant par la variable parent et calculons des statistiques sur les enfants de chaque parent.
Pour formaliser la relation dans featuretools , il suffit de spécifier une variable qui relie les deux tables ensemble.
clientset la table est loansassociée à la variable client_id, et loans, et payments- à l'aide de loan_id. La syntaxe pour créer une relation et l'ajouter à un ensemble d'entités est indiquée ci-dessous:
# Relationship between clients and previous loans
r_client_previous = ft.Relationship(es['clients']['client_id'],
es['loans']['client_id'])
# Add the relationship to the entity set
es = es.add_relationship(r_client_previous)
# Relationship between previous loans and previous payments
r_payments = ft.Relationship(es['loans']['loan_id'],
es['payments']['loan_id'])
# Add the relationship to the entity set
es = es.add_relationship(r_payments)
es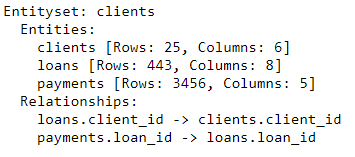
L'ensemble d'entités contient désormais trois entités (tables) et relations qui lient ces entités entre elles. Après avoir ajouté des entités et formalisé les relations, notre ensemble d'entités est complet et nous sommes prêts à créer des fonctionnalités.
Primitives de fonctionnalité
Avant de pouvoir entrer pleinement dans la synthèse profonde des traits, nous devons comprendre les primitifs des traits . Nous savons déjà ce qu'ils sont, mais nous les appelons simplement par des noms différents! Ce ne sont que les opérations de base que nous utilisons pour créer de nouvelles fonctionnalités:
- Agrégations: opérations effectuées sur une relation parent-enfant (un-à-plusieurs) qui sont regroupées par parent et calculent des statistiques pour les enfants. Un exemple est groupait une table
loansparclient_idet déterminer le montant maximal du prêt pour chaque client. - Conversions: opérations effectuées d'une table vers une ou plusieurs colonnes. Les exemples incluent la différence entre deux colonnes dans le même tableau ou la valeur absolue d'une colonne.
De nouvelles fonctionnalités sont créées dans featuretools en utilisant ces primitives, seules ou en tant que primitives multiples. Vous trouverez ci-dessous une liste de certaines des primitives dans featuretools (nous pouvons également définir des primitives personnalisées ):
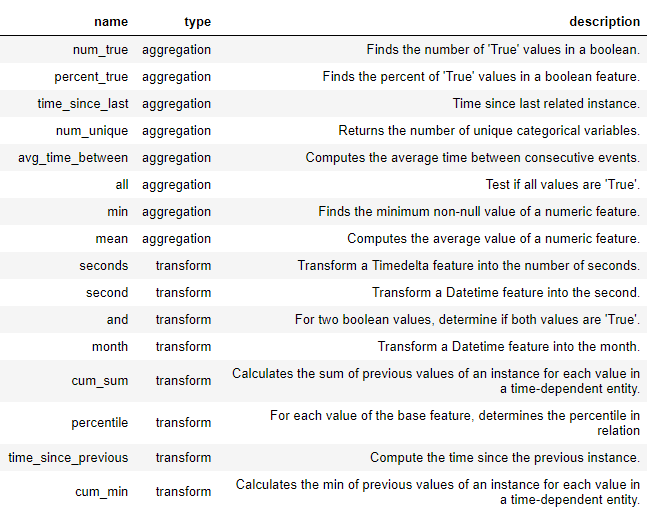
Ces primitives peuvent être utilisées seules ou combinées pour créer des entités. Pour créer des fonctionnalités avec les primitives spécifiées, nous utilisons une fonction
ft.dfs(signifie synthèse de fonctionnalités approfondie). On passe un ensemble d'entités target_entity, qui est une table à laquelle on veut ajouter les fonctionnalités sélectionnées trans_primitives(transformations) et agg_primitives(agrégats):
# Create new features using specified primitives
features, feature_names = ft.dfs(entityset = es, target_entity = 'clients',
agg_primitives = ['mean', 'max', 'percent_true', 'last'],
trans_primitives = ['years', 'month', 'subtract', 'divide'])Le résultat est un dataframe de nouvelles fonctionnalités pour chaque client (parce que nous avons fait des clients
target_entity). Par exemple, nous avons un mois dans lequel chaque client a rejoint, qui est une primitive de transformation:
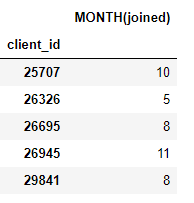
Nous avons également un certain nombre de primitives d'agrégation telles que les montants de paiement moyens pour chaque client:
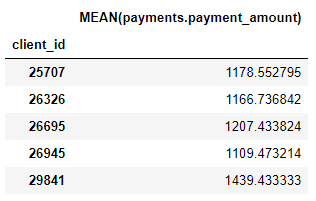
Même si nous n'avons spécifié que quelques primitives, featuretools a créé de nombreuses nouvelles fonctionnalités en combinant et en empilant ces primitives.
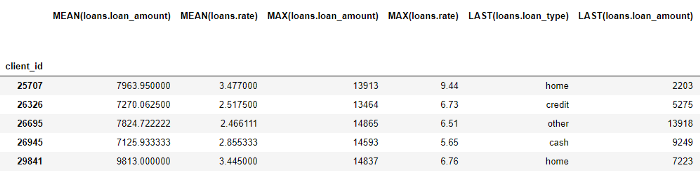
Le bloc de données complet contient 793 colonnes de nouvelles fonctionnalités!
Synthèse profonde des signes
Nous avons maintenant tout pour comprendre la synthèse de fonctionnalités approfondie (dfs). En fait, nous avons déjà fait dfs dans l'appel de fonction précédent! Un trait profond est simplement un trait composé d'une combinaison de plusieurs primitives, et dfs est le nom du processus qui crée ces traits. La profondeur d'une entité profonde est le nombre de primitives nécessaires pour créer une entité.
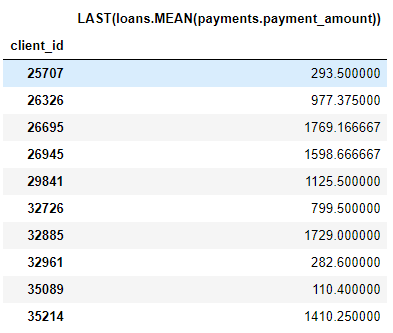
Par exemple, une colonne
MEAN (payment.payment_amount)est une fonction profonde avec une profondeur de 1 car elle a été créée à l'aide d'une seule agrégation. Voici un élément d'une profondeur de deux LAST(loans(MEAN(payment.payment_amount)). Cela se fait en combinant deux agrégations: LAST (la plus récente) au-dessus de MOYEN. Cela représente le paiement moyen du prêt le plus récent pour chaque client.
Nous pouvons composer des fonctionnalités à n'importe quelle profondeur que nous voulons, mais en pratique je n'ai jamais dépassé la profondeur 2. Après ce point, les fonctionnalités sont difficiles à interpréter, mais j'invite toute personne intéressée à essayer «d'aller plus loin» .
Nous n'avons pas besoin de spécifier manuellement les primitives, mais à la place, nous pouvons laisser les featuretools sélectionner automatiquement les fonctionnalités pour nous. Pour cela, nous utilisons le même appel de fonction
ft.dfs, mais nous ne transmettons aucune primitive:
# Perform deep feature synthesis without specifying primitives
features, feature_names = ft.dfs(entityset=es, target_entity='clients',
max_depth = 2)
features.head()
Featuretools a créé de nombreuses nouvelles fonctionnalités pour nous. Bien que ce processus crée automatiquement de nouveaux traits, il ne remplacera pas un Data Scientist car nous devons encore déterminer quoi faire avec tous ces traits. Par exemple, si notre objectif est de prédire si un client remboursera un prêt, nous pourrions rechercher les signes les plus pertinents pour un résultat particulier. De plus, si nous avons une connaissance du domaine, nous pouvons l'utiliser pour sélectionner des primitives spécifiques de caractéristiques ou pour une synthèse approfondie des caractéristiques candidates .
Prochaines étapes
La conception automatisée des fonctionnalités a résolu un problème, mais en a créé un autre: trop de fonctionnalités. Bien qu'il soit difficile de dire lesquelles de ces fonctionnalités seront importantes avant d'ajuster un modèle, elles ne seront probablement pas toutes pertinentes pour la tâche sur laquelle nous voulons former notre modèle. De plus, trop de fonctionnalités peuvent dégrader les performances du modèle car les fonctionnalités moins utiles supplantent celles qui sont plus importantes.
Le problème du trop grand nombre d'attributs est connu comme la malédiction de la dimension . À mesure que le nombre de caractéristiques (dimension des données) augmente dans le modèle, il devient plus difficile d'étudier la correspondance entre les caractéristiques et les objectifs. En fait, la quantité de données requise pour que le modèle fonctionne correctement estévolue de manière exponentielle avec le nombre d'entités .
La malédiction de la dimensionnalité est combinée à la réduction des caractéristiques (également appelée sélection de caractéristiques) : le processus de suppression des caractéristiques inutiles. Cela peut prendre plusieurs formes: analyse en composantes principales (PCA), SelectKBest, utilisant les valeurs de caractéristiques d'un modèle, ou codage automatique à l'aide de réseaux de neurones profonds. Cependant, la réduction des fonctionnalités est une rubrique distincte pour un autre article. À ce stade, nous savons que nous pouvons utiliser featuretools pour créer de nombreuses fonctionnalités à partir de nombreuses tables avec un minimum d'effort!
Production
À l'instar de nombreux sujets liés à l'apprentissage automatique, la conception automatique de fonctionnalités avec featuretools est un concept complexe basé sur des idées simples. En utilisant les concepts d'ensembles d'entités, d'entités et de relations, featuretools peut effectuer une synthèse de fonctionnalités approfondie pour créer de nouvelles fonctionnalités. La synthèse approfondie des fonctionnalités, à son tour, combine des primitives - des agrégats qui fonctionnent via des relations un-à-plusieurs entre les tables et des transformations , des fonctions appliquées à une ou plusieurs colonnes dans une table - pour créer de nouvelles fonctionnalités à partir de plusieurs tables.

Découvrez comment obtenir une profession de haut niveau à partir de zéro ou augmenter vos compétences et votre salaire en suivant les cours en ligne rémunérés de SkillFactory:
- Cours d'apprentissage automatique (12 semaines)
- Data Science (12 )
- (9 )
- «Python -» (9 )
- DevOps (12 )
- - (8 )