introduction
L'architecture du réseau neuronal convolutif (CNN) RetinaNet se compose de 4 parties principales, chacune ayant son propre objectif:
a) Backbone - le réseau principal (de base) utilisé pour extraire des caractéristiques de l'image d'entrée. Cette partie du réseau est variable et peut inclure des réseaux de neurones de classification tels que ResNet, VGG, EfficientNet et autres;
b) Feature Pyramid Net (FPN) - un réseau neuronal convolutif construit sous la forme d'une pyramide, qui sert à combiner les avantages des cartes de caractéristiques des niveaux inférieur et supérieur du réseau, les premiers ont une haute résolution, mais une faible capacité de généralisation sémantique; ce dernier, au contraire;
c) Sous-réseau de classification - un sous-réseau qui extrait des informations sur les classes d'objets du FPN, résolvant le problème de classification;
d) Sous-réseau de régression - un sous-réseau qui extrait des informations sur les coordonnées des objets dans l'image à partir du FPN, résolvant le problème de régression.
En figue. 1 montre l'architecture du RetinaNet avec le réseau neuronal ResNet comme épine dorsale.
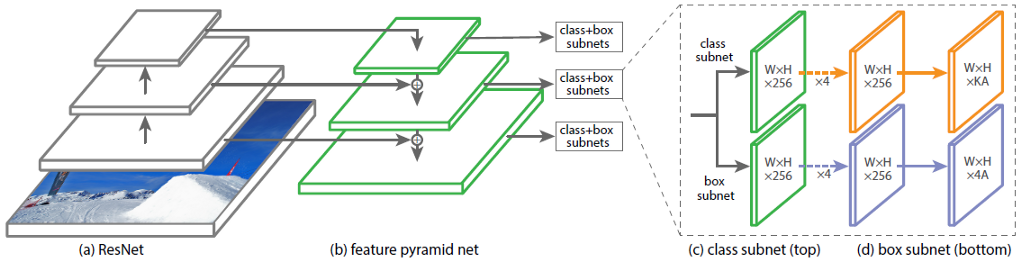
Figure 1 - Architecture RetinaNet avec backbone ResNet Analysons
en détail chacune des parties RetinaNet illustrées à la Fig. 1.
Backbone fait partie du réseau RetinaNet
Étant donné que la partie de l'architecture RetinaNet qui accepte une image comme entrée et met en évidence les caractéristiques importantes est variable et que les informations extraites de cette partie seront traitées dans les étapes suivantes, il est important de choisir un réseau dorsal approprié pour obtenir les meilleurs résultats.
Des recherches récentes sur l'optimisation CNN ont conduit au développement de modèles de classification qui surpassent toutes les architectures précédemment développées avec les meilleurs taux de précision sur l'ensemble de données ImageNet tout en améliorant l'efficacité de 10 fois. Ces réseaux ont été nommés EfficientNet-B (0-7). Les indicateurs de la famille des nouveaux réseaux sont représentés sur la Fig. 2.
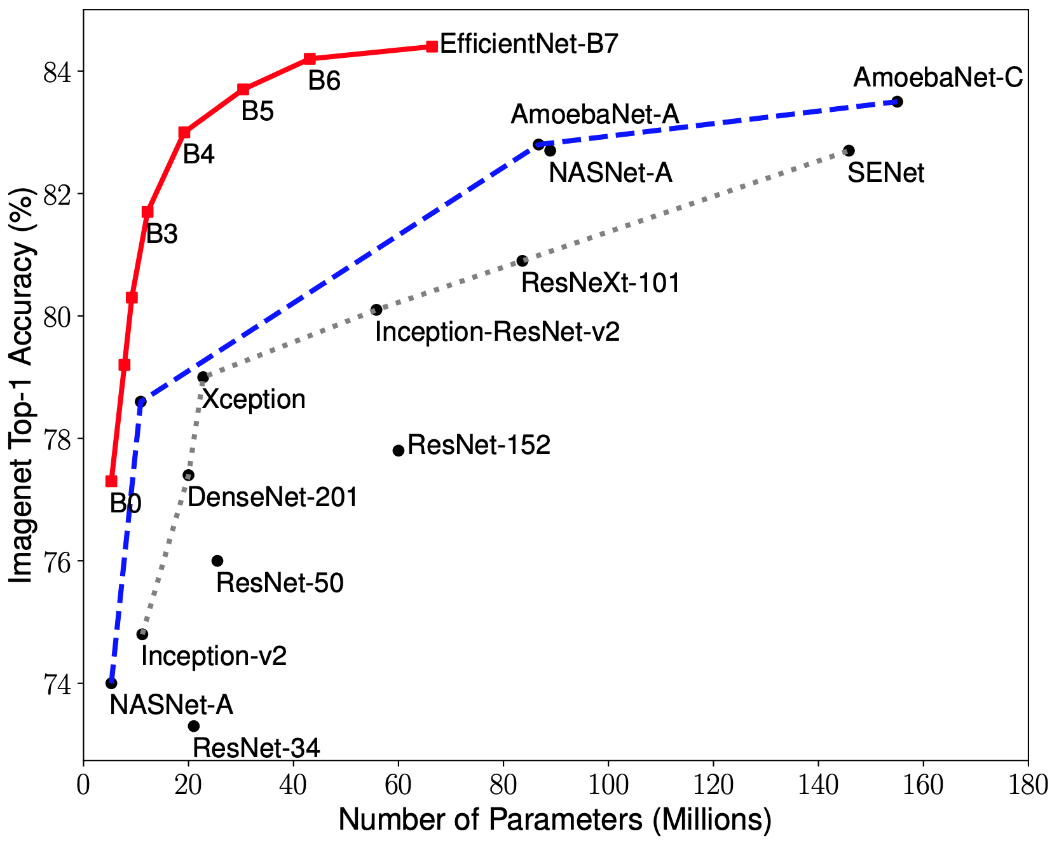
Figure 2 - Graphique de la dépendance de l'indicateur de précision le plus élevé sur le nombre de poids de réseau pour diverses architectures
La pyramide des signes
Le réseau de pyramides d'objets se compose de trois parties principales: la voie ascendante, la voie descendante et les connexions latérales.
Le chemin ascendant est une sorte de «pyramide» hiérarchique - une séquence de couches convolutives de dimension décroissante, dans notre cas - un réseau fédérateur. Les couches supérieures du réseau convolutif ont une signification plus sémantique, mais une résolution plus faible, et les couches inférieures, au contraire (Fig. 3). La voie ascendante présente une vulnérabilité dans l'extraction de caractéristiques - la perte d'informations importantes sur un objet, par exemple, en raison du bruit d'un objet petit mais significatif en arrière-plan, car à la fin du réseau, les informations sont fortement compressées et généralisées.
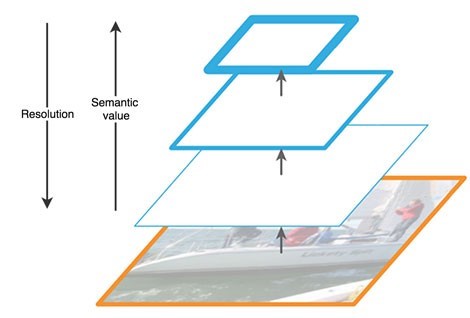
Figure 3 - Caractéristiques des cartes de caractéristiques à différents niveaux du réseau neuronal
Le chemin descendant est aussi une "pyramide". Les cartes de caractéristiques de la couche supérieure de cette pyramide ont la taille des cartes de caractéristiques de la couche supérieure de bas en haut de la pyramide et sont doublées par la méthode du plus proche voisin (Fig. 4) vers le bas.
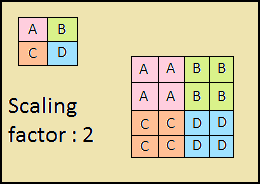
Figure 4 - Augmentation de la résolution d'image par la méthode du plus proche voisin
Ainsi, dans le réseau descendant, chaque carte de caractéristiques de la couche sus-jacente est augmentée à la taille de la carte sous-jacente. De plus, des connexions latérales sont présentes dans FPN, ce qui signifie que les cartes de caractéristiques des couches correspondantes de bas en haut et de haut en bas des pyramides sont ajoutées par élément, et les cartes de bas en haut sont pliées 1 * 1. Ce processus est illustré schématiquement sur la Fig. 5.
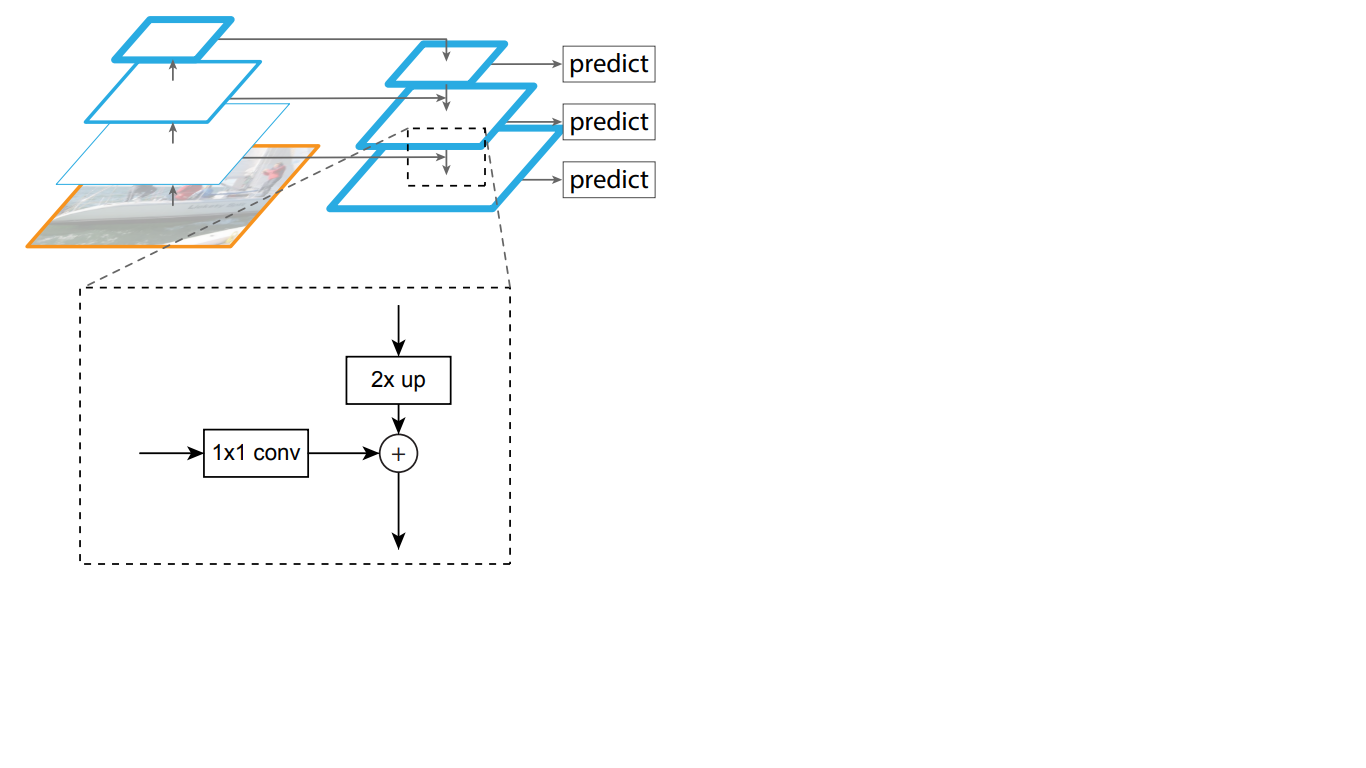
Figure 5 - La structure de la pyramide des signes
Les connexions latérales résolvent le problème de l'atténuation des signaux importants en cours de passage à travers les couches, combinant des informations sémantiquement importantes reçues à la fin de la première pyramide et des informations plus détaillées obtenues plus tôt.
En outre, chacune des couches résultantes dans la pyramide descendante est traitée par deux sous-réseaux.
Sous-réseaux de classification et de régression
La troisième partie de l'architecture RetinaNet comprend deux sous-réseaux: la classification et la régression (Figure 6). Chacun de ces sous-réseaux forme en sortie une réponse sur la classe de l'objet et son emplacement sur l'image. Voyons comment chacun d'eux fonctionne.
Figure 6 - Sous-réseaux RetinaNet
La différence dans les principes des blocs considérés (sous-réseaux) ne diffère pas jusqu'à la dernière couche. Chacun d'eux se compose de 4 couches de réseaux convolutifs. 256 cartes d'entités sont formées dans la couche. Sur la cinquième couche, le nombre de cartes d'entités change: le sous-réseau de régression a 4 cartes d'entités * A, le sous-réseau de classification a K * A cartes d'entités, où A est le nombre de cadres d'ancrage (description détaillée des cadres d'ancrage dans la sous-section suivante), K est le nombre de classes d'objets.
Dans la dernière, sixième couche, chaque carte d'entités est transformée en un ensemble de vecteurs. Le modèle de régression en sortie a pour chaque boîte d'ancrage un vecteur de 4 valeurs indiquant le décalage de la boîte de vérité terrain par rapport à la boîte d'ancrage. Le modèle de classification a un vecteur one-hot de longueur K en sortie pour chaque trame d'ancrage, dans lequel l'index avec la valeur 1 correspond au numéro de classe que le réseau neuronal a attribué à l'objet.
Cadres d'ancrage
Dans la dernière section, le terme cadres d'ancrage a été utilisé. La boîte d'ancrage est un hyperparamètre de détecteurs de réseaux neuronaux, un rectangle de délimitation prédéfini par rapport auquel le réseau fonctionne.
Disons que le réseau a une carte de caractéristiques 3 * 3 en sortie. Dans RetinaNet, chaque cellule dispose de 9 boîtes d'ancrage, chacune avec une taille et un rapport hauteur / largeur différents (Figure 7). Pendant la formation, les cadres d'ancrage sont mis en correspondance avec chaque image cible. Si leur valeur IoU a une valeur de 0,5, alors le cadre d'ancrage est attribué à la cible, si la valeur est inférieure à 0,4, alors il est considéré comme l'arrière-plan, dans d'autres cas, le cadre d'ancrage sera ignoré pour l'apprentissage. Le réseau de classification est formé par rapport à l'affectation assignée (classe d'objet ou arrière-plan), le réseau de régression est formé par rapport aux coordonnées du cadre d'ancrage (il est important de noter que l'erreur est calculée par rapport au cadre d'ancrage, mais pas au cadre cible).
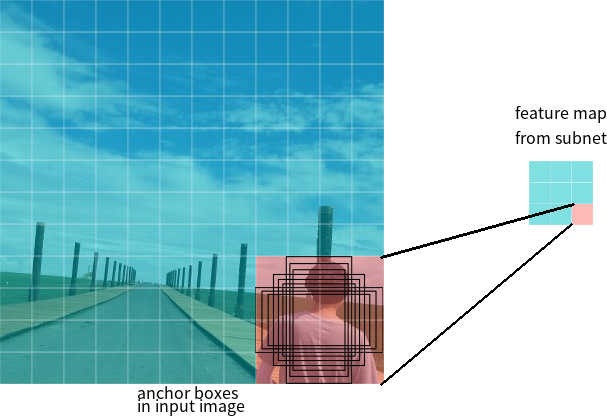
Figure 7 - Cadres d'ancrage pour une cellule de la carte des caractéristiques d'une taille de 3 * 3
Fonctions de perte
Les pertes RetinaNet sont composites, elles sont composées de deux valeurs: l'erreur de régression ou de localisation (notée Lloc ci-dessous) et l'erreur de classification (notée Lcls ci-dessous). La fonction de perte générale peut être écrite comme suit:
Où λ est un hyperparamètre qui contrôle l'équilibre entre les deux pertes.
Considérons plus en détail le calcul de chacune des pertes.
Comme décrit précédemment, chaque image cible se voit attribuer une ancre. Désignons ces paires par (Ai, Gi) i = 1, ... N, où A représente l'ancre, G est la trame cible et N est le nombre de paires appariées.
Pour chaque ancre, le réseau de régression prédit 4 nombres, qui peuvent être notés Pi = (Pix, Piy, Piw, Pih). Les deux premières paires représentent la différence prédite entre les coordonnées des centres de l'ancre Ai et le cadre cible Gi, et les deux dernières représentent la différence prédite entre leur largeur et leur hauteur. En conséquence, pour chaque image cible, Ti est calculé comme la différence entre les images d'ancrage et cible:
Où smoothL1 (x) est défini par la formule ci-dessous:
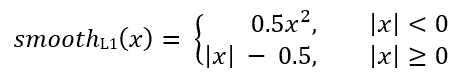
La perte de problème de classification RetinaNet est calculée à l'aide de la fonction de perte focale.
où K est le nombre de classes, yi est la valeur cible de la classe, p est la probabilité de prédire la i-ème classe, γ est le paramètre de focalisation, α est le coefficient de biais. Cette fonction est une fonction d'entropie croisée avancée. La différence réside dans l'ajout du paramètre γ∈ (0, + ∞), qui résout le problème du déséquilibre de classe. Pendant la formation, la plupart des objets traités par le classificateur sont l'arrière-plan, qui est une classe distincte. Par conséquent, un problème peut survenir lorsque le réseau neuronal apprend à mieux déterminer l'arrière-plan que les autres objets. L'ajout d'un nouveau paramètre a résolu ce problème en réduisant la valeur d'erreur pour les objets facilement classifiés. Les graphiques des fonctions d'entropie focale et croisée sont illustrés à la Fig.8.
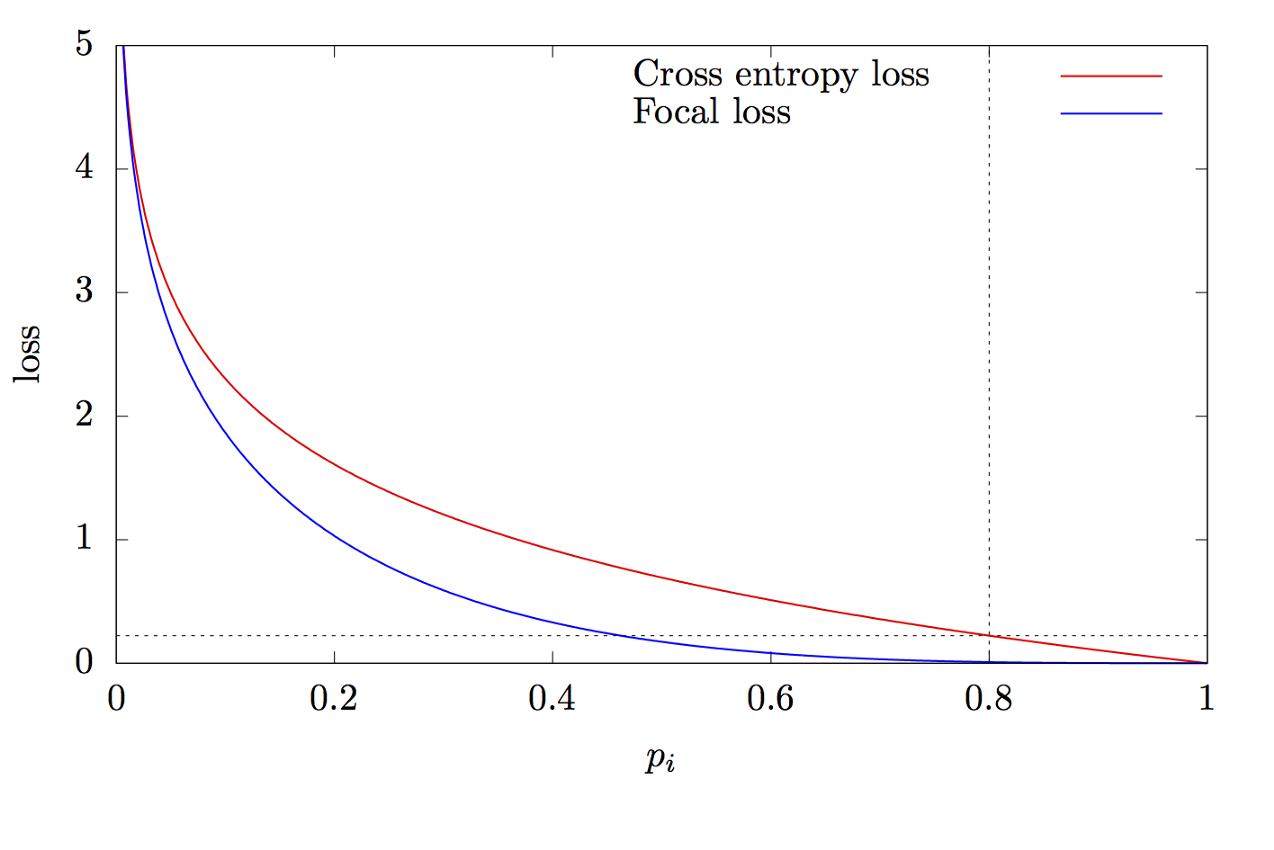
Figure 8 - Graphiques des fonctions d'entropie focale et croisée
Merci d'avoir lu cet article!
Liste des sources:
- Tan M., Le Q. V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. 2019. URL: arxiv.org/abs/1905.11946
- Zeng N. RetinaNet Explained and Demystified [ ]. 2018 URL: blog.zenggyu.com/en/post/2018-12-05/retinanet-explained-and-demystified
- Review: RetinaNet — Focal Loss (Object Detection) [ ]. 2019 URL: towardsdatascience.com/review-retinanet-focal-loss-object-detection-38fba6afabe4
- Tsung-Yi Lin Focal Loss for Dense Object Detection. 2017. URL: arxiv.org/abs/1708.02002
- The intuition behind RetinaNet [ ]. 2018 URL: medium.com/@14prakash/the-intuition-behind-retinanet-eb636755607d