
introduction
Google Dorks ou Google Hacking est une technique utilisée par les médias, les enquêteurs, les ingénieurs en sécurité et toute autre personne pour interroger divers moteurs de recherche afin de découvrir des informations cachées et des vulnérabilités pouvant être trouvées sur les serveurs publics. Il s'agit d'une technique dans laquelle les requêtes de recherche de site Web conventionnelles sont utilisées dans toute leur mesure pour déterminer les informations cachées à la surface.
Comment fonctionne Google Dorking?
Cet exemple de collecte et d'analyse d'informations, agissant comme un outil OSINT, n'est pas une vulnérabilité de Google ou un dispositif de piratage d'hébergement de sites Web. Au contraire, il agit comme un processus de récupération de données conventionnel avec des capacités avancées. Ce n'est pas nouveau, car il existe un grand nombre de sites Web vieux de plus de dix ans et servant de référentiels pour explorer et utiliser Google Hacking.
Alors que les moteurs de recherche indexent, stockent les en-têtes et le contenu des pages, et les relient pour des requêtes de recherche optimales. Mais malheureusement, les web spiders de n'importe quel moteur de recherche sont configurés pour indexer absolument toutes les informations trouvées. Même si les administrateurs des ressources Web n'avaient aucune intention de publier ce matériel.
Cependant, la chose la plus intéressante à propos de Google Dorking est l'énorme quantité d'informations qui peuvent aider tout le monde dans le processus d'apprentissage du processus de recherche Google. Peut aider les nouveaux arrivants à retrouver des proches disparus ou peut apprendre à extraire des informations pour leur propre bénéfice. En général, chaque ressource est intéressante et étonnante à sa manière et peut aider chacun dans ce qu'il recherche exactement.
Quelles informations puis-je trouver via Dorks?
Allant des contrôleurs d'accès à distance de diverses machines d'usine aux interfaces de configuration de systèmes critiques. On suppose que personne ne trouvera jamais une énorme quantité d'informations publiées sur le net.
Cependant, regardons-le dans l'ordre. Imaginez une nouvelle caméra de sécurité qui vous permet de la regarder en direct sur votre téléphone à tout moment. Vous le configurez et vous y connectez via Wi-Fi, puis téléchargez l'application pour authentifier la connexion de la caméra de sécurité. Après cela, vous pouvez accéder à la même caméra de n'importe où dans le monde.
En arrière-plan, tout n'est pas si simple. La caméra envoie une requête au serveur chinois et lit la vidéo en temps réel, vous permettant de vous connecter et d'ouvrir le flux vidéo hébergé sur le serveur en Chine à partir de votre téléphone. Ce serveur peut ne pas nécessiter de mot de passe pour accéder au flux de votre webcam, ce qui le rend accessible au public à toute personne recherchant le texte contenu dans la page d'affichage de la caméra.
Et malheureusement, Google est impitoyablement efficace pour trouver tout appareil sur Internet fonctionnant sur des serveurs HTTP et HTTPS. Et comme la plupart de ces appareils contiennent une sorte de plate-forme Web pour les personnaliser, cela signifie que beaucoup de choses qui n'étaient pas censées être sur Google se retrouvent là-bas.
Le type de fichier de loin le plus sérieux est celui qui contient les informations d'identification des utilisateurs ou de l'ensemble de l'entreprise. Cela se produit généralement de deux manières. Dans le premier cas, le serveur n'est pas configuré correctement et expose ses journaux administratifs ou journaux au public sur Internet. Lorsque les mots de passe sont modifiés ou que l'utilisateur est incapable de se connecter, ces archives peuvent fuir avec les informations d'identification.
La deuxième option se produit lorsque des fichiers de configuration contenant les mêmes informations (connexions, mots de passe, noms de base de données, etc.) deviennent accessibles au public. Ces fichiers doivent être cachés de tout accès public, car ils laissent souvent des informations importantes. Chacune de ces erreurs peut amener un attaquant à trouver ces failles et à obtenir toutes les informations dont il a besoin.
Cet article illustre l'utilisation de Google Dorks pour montrer non seulement comment trouver tous ces fichiers, mais aussi à quel point les plates-formes vulnérables peuvent être qui contiennent des informations sous la forme d'une liste d'adresses, d'e-mails, d'images et même d'une liste de webcams accessibles au public.
Analyse des opérateurs de recherche
Dorking peut être utilisé sur divers moteurs de recherche, pas seulement Google. Dans une utilisation quotidienne, les moteurs de recherche tels que Google, Bing, Yahoo et DuckDuckGo prennent une requête de recherche ou une chaîne de requête de recherche et renvoient des résultats pertinents. En outre, ces mêmes systèmes sont programmés pour accepter des opérateurs plus avancés et complexes qui affinent considérablement ces termes de recherche. Un opérateur est un mot-clé ou une expression qui a une signification particulière pour un moteur de recherche. Des exemples d'opérateurs couramment utilisés sont: "inurl", "intext", "site", "feed", "language". Chaque opérateur est suivi d'un signe deux-points, suivi de la ou des phrases clés correspondantes.
Ces opérateurs vous permettent de rechercher des informations plus spécifiques, telles que des lignes de texte spécifiques dans les pages d'un site Web ou des fichiers hébergés sur une URL spécifique. Entre autres choses, Google Dorking peut également trouver des pages de connexion cachées, des messages d'erreur affichant des informations sur les vulnérabilités disponibles et les fichiers partagés. La raison principale est que l'administrateur du site Web a peut-être simplement oublié d'exclure de l'accès public.
Le service Google le plus pratique et en même temps intéressant est la possibilité de rechercher des pages supprimées ou archivées. Cela peut être fait en utilisant l'opérateur "cache:". L'opérateur fonctionne de manière à afficher la version enregistrée (supprimée) de la page Web stockée dans le cache Google. La syntaxe de cet opérateur est indiquée ici:
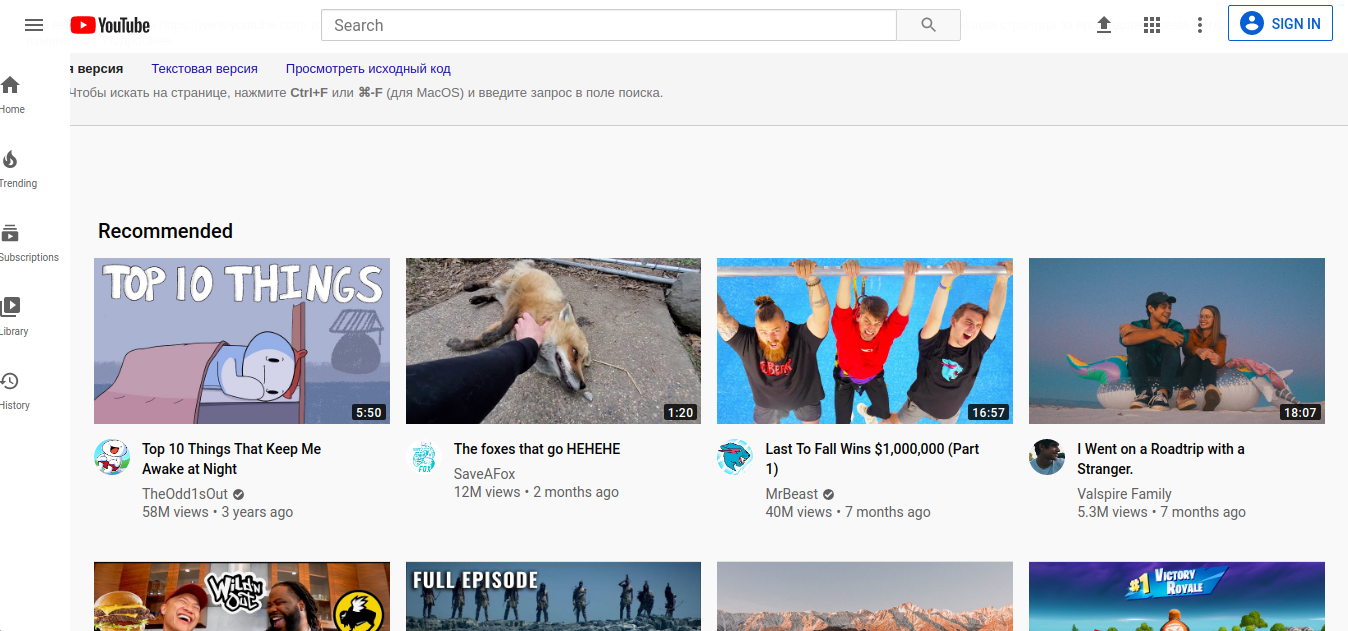
cache: www.youtube.com
Après avoir fait la demande ci-dessus à Google, l'accès à la version précédente ou obsolète de la page Web Youtube est fourni. La commande vous permet d'appeler la version complète de la page, la version texte ou la source de la page elle-même (code complet). L'heure exacte (date, heure, minute, seconde) de l'indexation effectuée par l'araignée Google est également indiquée. La page est affichée sous la forme d'un fichier graphique, bien que la recherche dans la page elle-même soit effectuée de la même manière que dans une page HTML normale (raccourci clavier CTRL + F). Les résultats de la commande "cache:" dépendent de la fréquence à laquelle la page Web a été indexée par Google. Si le développeur lui-même définit l'indicateur avec une certaine fréquence de visites dans la tête du document HTML, alors Google reconnaît la page comme secondaire et l'ignore généralement au profit du ratio PageRank.qui est le principal facteur de fréquence d'indexation des pages Par conséquent, si une page Web particulière a été modifiée entre les visites par le robot d'exploration Google, elle ne sera pas indexée ou lue à l'aide de la commande "cache:". Des exemples qui fonctionnent particulièrement bien lors du test de cette fonctionnalité sont les blogs, les comptes de réseaux sociaux et les portails en ligne fréquemment mis à jour.
Les informations supprimées ou les données qui ont été placées par erreur ou qui doivent être supprimées à un moment donné peuvent être récupérées très facilement. La négligence de l'administrateur de la plate-forme Web peut lui faire courir le risque de diffuser des informations indésirables.
Informations de l'utilisateur
La recherche d'informations sur l'utilisateur est utilisée à l'aide d'opérateurs avancés, qui rendent les résultats de recherche précis et détaillés. L'opérateur "@" permet de rechercher des utilisateurs d'indexation dans les réseaux sociaux: Twitter, Facebook, Instagram. En utilisant l'exemple de la même université polonaise, vous pouvez trouver son représentant officiel, sur l'une des plateformes sociales, en utilisant cet opérateur comme suit:
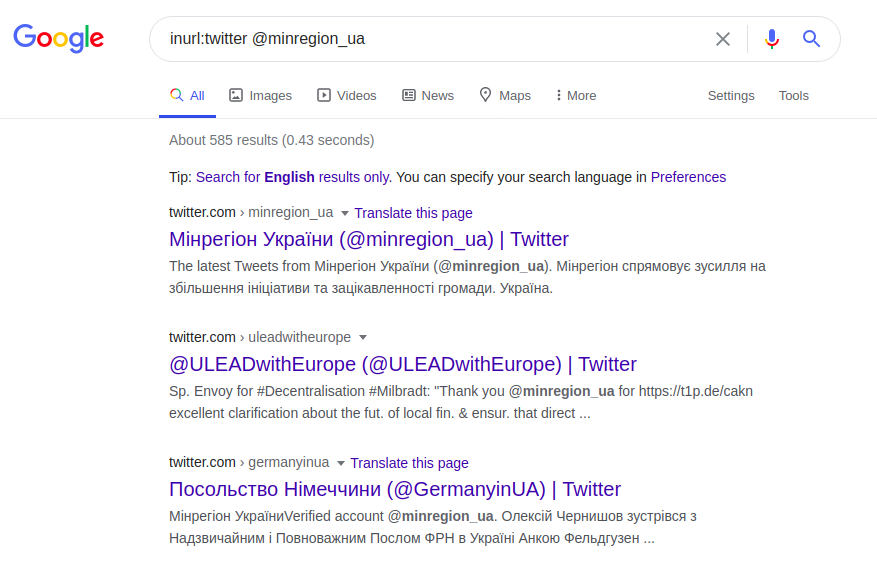
inurl: twitter @minregion_ua
Cette requête Twitter trouve l'utilisateur "minregion_ua". En supposant que le lieu ou le nom de travail de l'utilisateur que nous recherchons (le Ministère du développement des communautés et des territoires de l'Ukraine) et son nom sont connus, vous pouvez faire une demande plus spécifique. Et au lieu d'avoir à rechercher fastidieusement toute la page Web de l'institution, vous pouvez demander la bonne requête en fonction de l'adresse e-mail et supposer que le nom de l'adresse doit inclure au moins le nom de l'utilisateur ou de l'institution demandée. Par exemple:
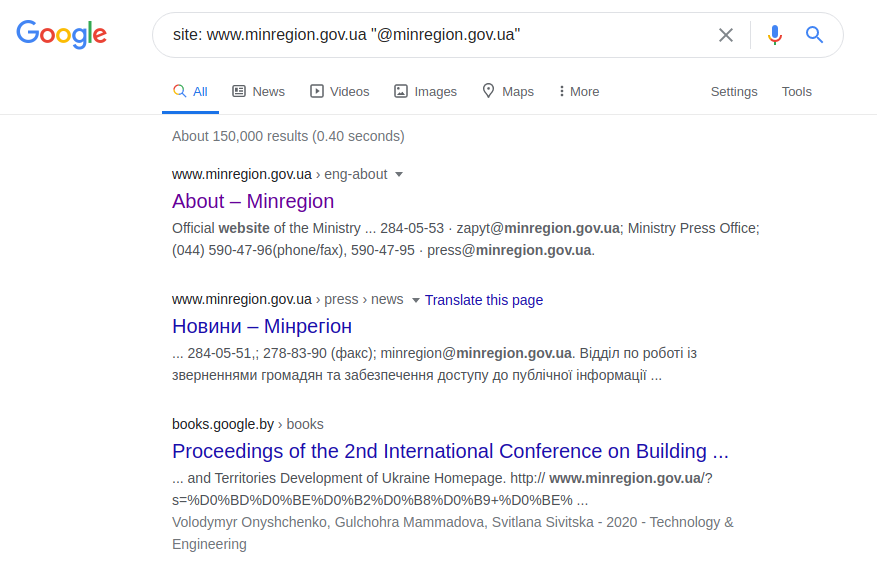
site: www.minregion.gov.ua "@ minregion.ua"
Vous pouvez également utiliser une méthode moins compliquée et envoyer une demande uniquement aux adresses e-mail, comme indiqué ci-dessous, dans l'espoir de la chance et du manque de professionnalisme de l'administrateur des ressources Web.
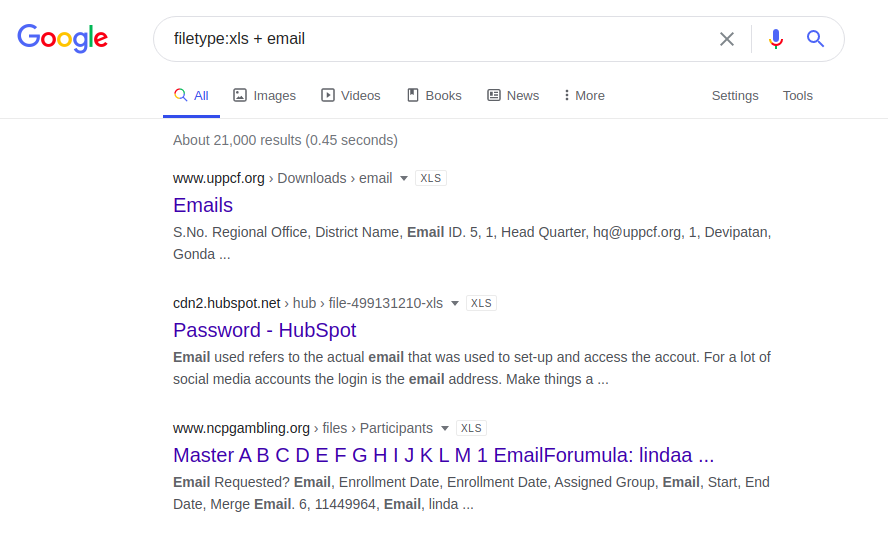
email.xlsx type de fichier
: xls + email
En outre, vous pouvez essayer d'obtenir des adresses e-mail à partir d'une page Web avec la demande suivante:

site: www.minregion.gov.ua intext: e-mail
La requête ci - dessus recherchera le mot-clé "email" sur la page Web du Ministère du développement des communautés et des territoires de l'Ukraine. La recherche d'adresses e-mail est d'une utilité limitée et nécessite généralement un peu de préparation et de collecte d'informations sur l'utilisateur à l'avance.
Malheureusement, la recherche de numéros de téléphone indexés dans le répertoire de Google est limitée aux États-Unis uniquement. Par exemple:
Annuaire: Arthur Mobile AL La
recherche d'informations sur l'utilisateur est également possible via la "recherche d'images" de Google ou la recherche d'images inversées. Cela vous permet de retrouver des photos identiques ou similaires sur des sites indexés par Google.
Informations sur les ressources Web
Google dispose de plusieurs opérateurs utiles, notamment "related:", qui affiche une liste de sites "similaires" à celui souhaité. La similarité est basée sur des liens fonctionnels et non sur des liens logiques ou significatifs.
Related: minregion.gov.ua
Cet exemple affiche les pages d'autres ministères ukrainiens. Cet opérateur fonctionne comme le bouton "Pages associées" dans les recherches Google avancées. De la même manière, la demande «info:» fonctionne, qui affiche des informations sur une page Web spécifique. Il s'agit des informations spécifiques de la page Web présentées dans le titre du site Web (), à savoir dans les balises de méta description (<meta name = «Description»). Exemple:

info: minregion.gov.ua
Une autre requête, "define:", est très utile pour trouver des travaux scientifiques. Il vous permet d'obtenir des définitions de mots à partir de sources telles que des encyclopédies et des dictionnaires en ligne. Un exemple de son application:
define: territoires ukrainiens L'
opérateur universel - tilde ("~"), vous permet de rechercher des mots ou des synonymes similaires:
~ communautés ~ développement
La requête ci-dessus affiche à la fois les sites Web avec les mots «communautés» (territoires) et «développement» (développement), et les sites Web avec le synonyme «communautés». L'opérateur "link:", qui modifie la requête, limite la plage de recherche aux liens spécifiés pour une page spécifique.
lien: www.minregion.gov.ua
Cependant, cet opérateur n'affiche pas tous les résultats et n'étend pas les critères de recherche.
Les hashtags sont une sorte de numéros d'identification qui vous permettent de regrouper des informations. Ils sont actuellement utilisés sur Instagram, VK, Facebook, Tumblr et TikTok. Google vous permet de rechercher de nombreux réseaux sociaux en même temps ou uniquement ceux recommandés. Voici un exemple de requête typique pour n'importe quel moteur de recherche:
# polyticavukrainі
L'opérateur "AROUND (n)" vous permet de rechercher deux mots situés à une distance d'un certain nombre de mots l'un de l'autre. Exemple:

Ministry of AROUND (4) of Ukraine
Le résultat de la requête ci-dessus est d'afficher les sites Web contenant ces deux mots («ministère» et «Ukraine»), mais séparés l'un de l'autre par quatre autres mots.
La recherche par type de fichier est également extrêmement utile, car Google indexe le contenu en fonction du format dans lequel il a été enregistré. Ceci est fait en utilisant l'opérateur "filetype:". Il existe un très large éventail de recherches de fichiers actuellement utilisées. De tous les moteurs de recherche disponibles, Google fournit l'ensemble d'opérateurs le plus sophistiqué pour rechercher l'open source.
Comme alternative aux opérateurs ci-dessus, des outils tels que Maltego et Oryon OSINT Browser sont recommandés. Ils fournissent une récupération automatique des données et ne nécessitent pas la connaissance d'opérateurs spéciaux. Le mécanisme des programmes est très simple: à l'aide d'une requête correcte envoyée à Google ou Bing, les documents publiés par l'institution qui vous intéresse sont trouvés et les métadonnées de ces documents sont analysées. Une source d'information potentielle pour de tels programmes est chaque fichier avec une extension quelconque, par exemple: ".doc", ".pdf", ".ppt", ".odt", ".xls" ou ".jpg".
De plus, il faut dire comment prendre correctement en charge le «nettoyage de vos métadonnées» avant de rendre les fichiers publics. Certains guides Web fournissent au moins plusieurs moyens de se débarrasser des méta-informations. Cependant, il est impossible de déduire la meilleure façon, car tout dépend des préférences individuelles de l'administrateur lui-même. Il est généralement recommandé d'écrire les fichiers dans un format qui ne stocke pas initialement les métadonnées, puis de rendre les fichiers disponibles. Il existe de nombreux programmes gratuits de nettoyage de métadonnées sur Internet, principalement pour les images. ExifCleaner peut être considéré comme l'un des plus souhaitables. Dans le cas des fichiers texte, il est fortement recommandé de nettoyer manuellement.
Informations laissées sans le savoir par les propriétaires de sites
Les ressources indexées par Google restent publiques (par exemple, les documents internes et les documents de l'entreprise laissés sur le serveur), ou elles sont laissées pour des raisons de commodité par les mêmes personnes (par exemple, des fichiers musicaux ou des fichiers vidéo). La recherche d'un tel contenu peut être effectuée avec Google de différentes manières, et la plus simple consiste simplement à deviner. Si, par exemple, il y a des fichiers 5.jpg, 8.jpg et 9.jpg dans un certain répertoire, vous pouvez prédire qu'il y a des fichiers de 1 à 4, de 6 à 7 et même plus 9. Par conséquent, vous pouvez accéder à des matériaux qui ne devraient pas devaient être en public. Une autre façon consiste à rechercher des types spécifiques de contenu sur des sites Web. Vous pouvez rechercher des fichiers musicaux, des photos, des films et des livres (livres électroniques, livres audio).
Dans un autre cas, il peut s'agir de fichiers que l'utilisateur a laissés sans le savoir dans le domaine public (par exemple, de la musique sur un serveur FTP pour son propre usage). Ces informations peuvent être obtenues de deux manières: en utilisant l'opérateur "filetype:" ou l'opérateur "inurl:". Par exemple:
filetype: doc site: gov.ua
site: www.minregion.gov.ua filetype: pdf
site: www.minregion.gov.ua inurl: doc
Vous pouvez également rechercher des fichiers programme en utilisant une requête de recherche et en filtrant le fichier souhaité par son extension:
type de fichier: iso
Informations sur la structure des pages Web
Afin de visualiser la structure d'une certaine page Web et de révéler toute sa structure, ce qui aidera le serveur et ses vulnérabilités à l'avenir, vous pouvez le faire en utilisant uniquement l'opérateur "site:". Analysons la phrase suivante:
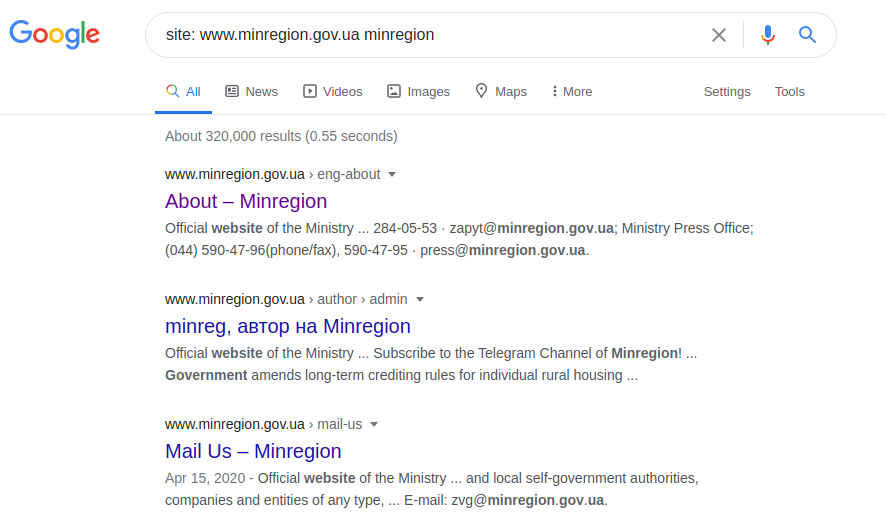
site: www.minregion.gov.ua minregion
Nous commençons à chercher le mot "minregion" dans le domaine "www.minregion.gov.ua". Chaque site de ce domaine (recherche Google à la fois dans le texte, dans les titres et dans le titre du site) contient ce mot. Ainsi, obtenir la structure complète de tous les sites pour ce domaine particulier. Une fois la structure du répertoire disponible, un résultat plus précis (bien que cela ne se produise pas toujours) peut être obtenu avec la requête suivante:
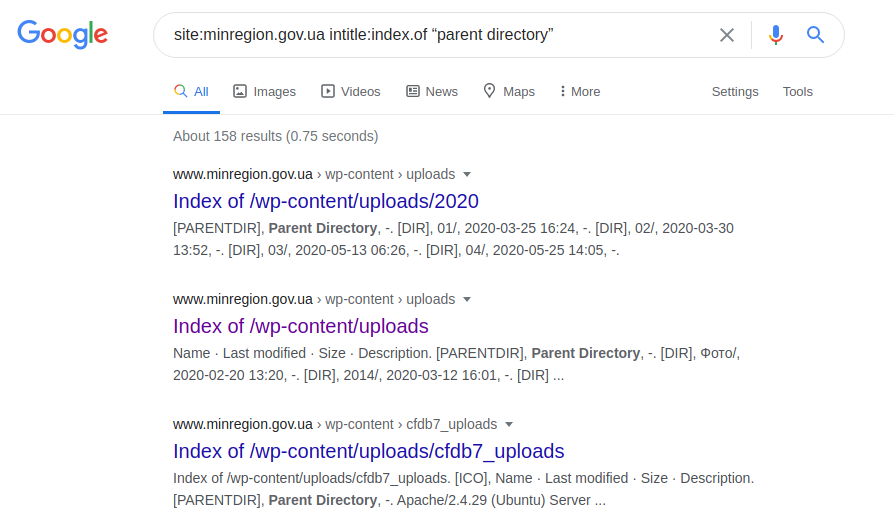
site: minregion.gov.ua intitle: index.of "répertoire parent"
Il montre les sous-domaines les moins protégés de "minregion.gov.ua", parfois avec la possibilité de rechercher tout le répertoire, ainsi que le téléchargement possible de fichiers. Par conséquent, naturellement, une telle demande n'est pas applicable à tous les domaines, car ils peuvent être protégés ou exécutés sous le contrôle d'un autre serveur.
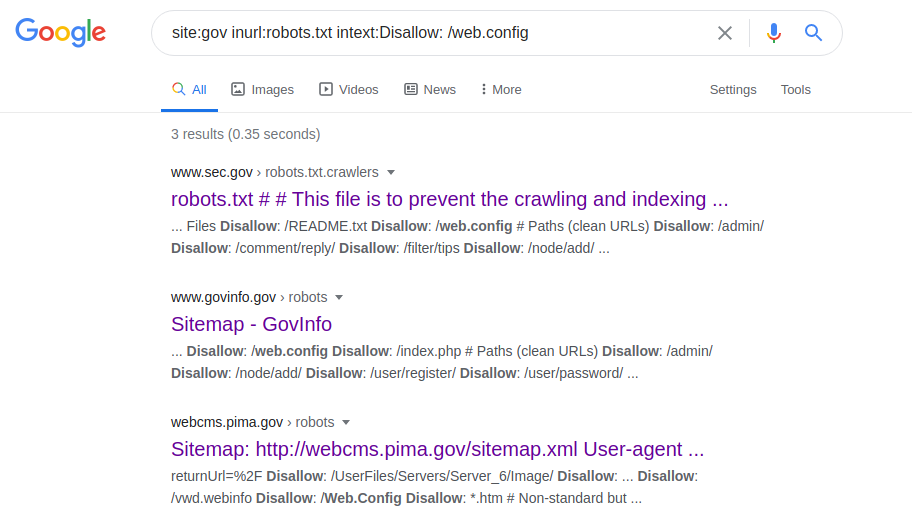
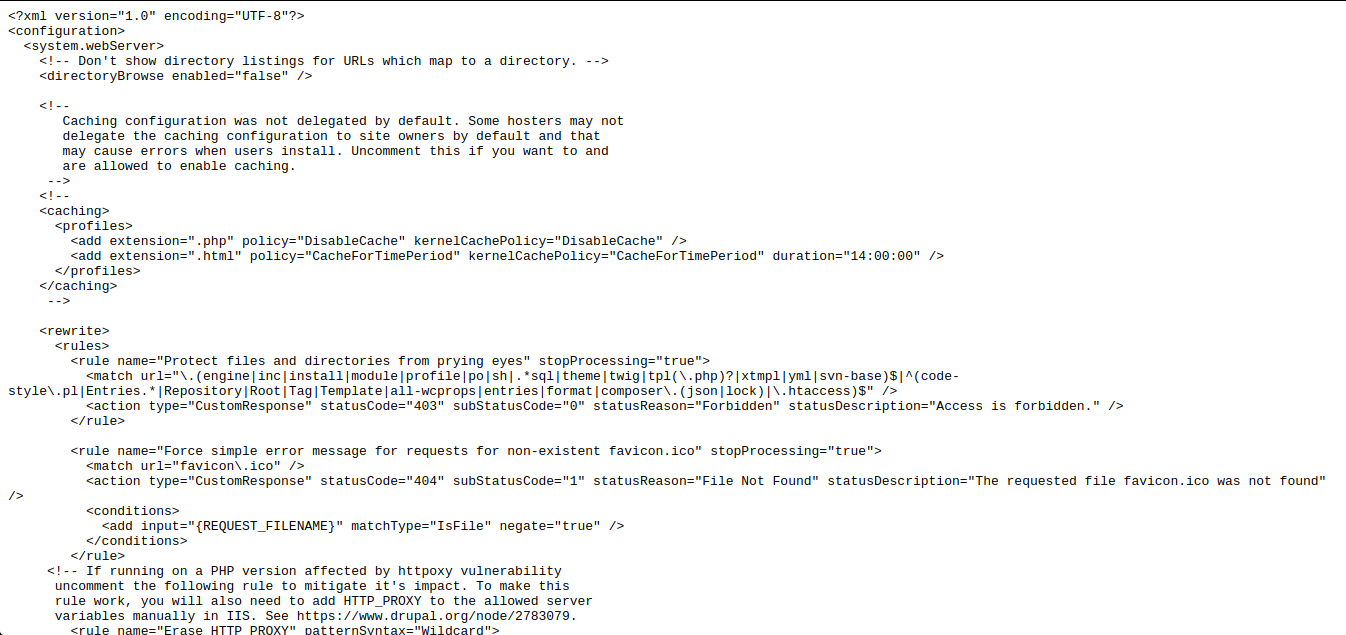
site: gov inurl: robots.txt intext: Disallow: /web.config
Cet opérateur vous permet d'accéder aux paramètres de configuration de différents serveurs. Après avoir effectué la demande, accédez au fichier robots.txt, recherchez le chemin vers "web.config" et accédez au chemin de fichier spécifié. Pour obtenir le nom du serveur, sa version et d'autres paramètres (par exemple, les ports), la requête suivante est effectuée:
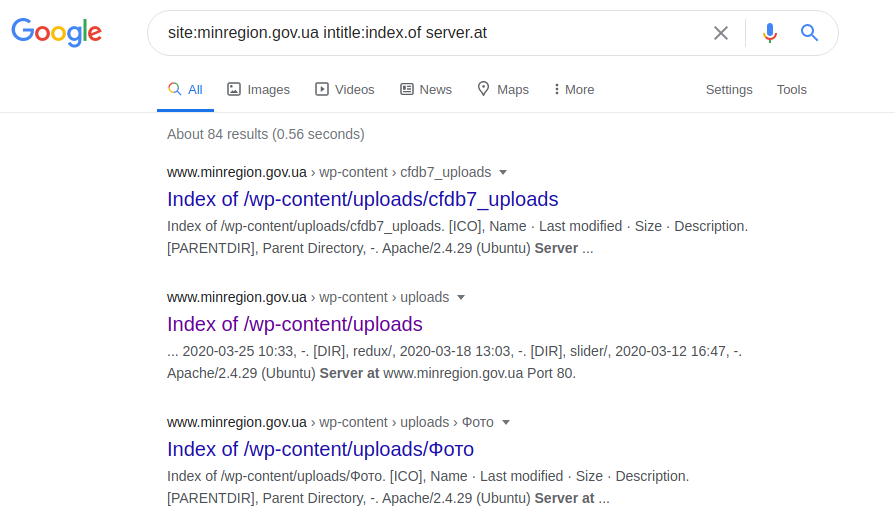
site: gosstandart.gov.by intitle: index.of server.at
Chaque serveur a des phrases uniques sur ses pages d'accueil, par exemple, Internet Information Service (IIS):
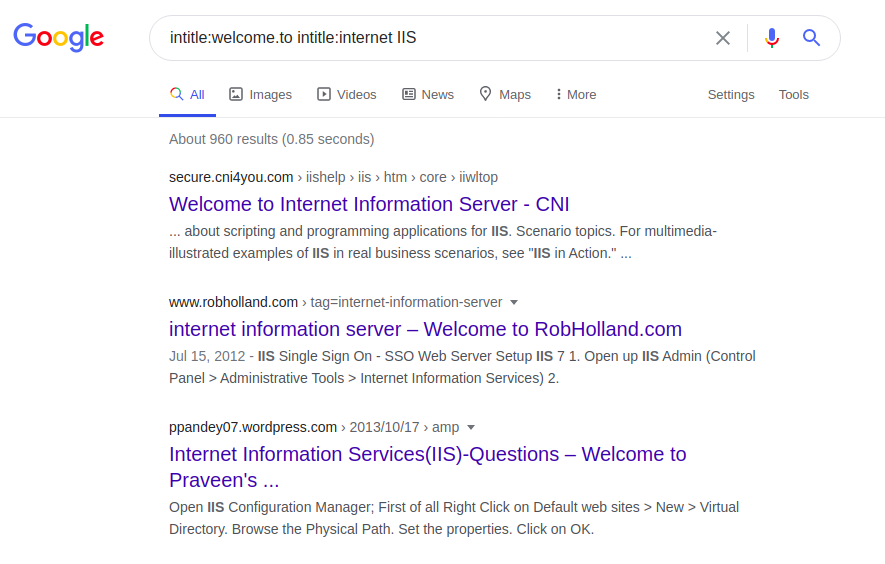
intitle: welcome.to intitle: internet IIS
La définition du serveur lui-même et des technologies utilisées ne dépend que de l'ingéniosité de la requête posée. Vous pouvez, par exemple, essayer de le faire en clarifiant une spécification technique, un manuel ou des pages dites d'aide. Pour démontrer cette capacité, vous pouvez utiliser la requête suivante:
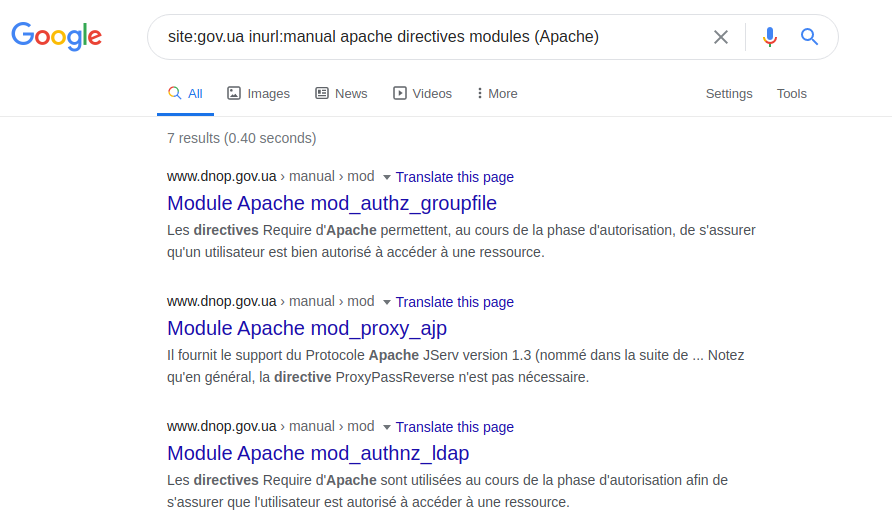
site: gov.ua inurl: modules manuels de directives apache (Apache)
L'accès peut être étendu, par exemple, grâce au fichier avec des erreurs SQL:
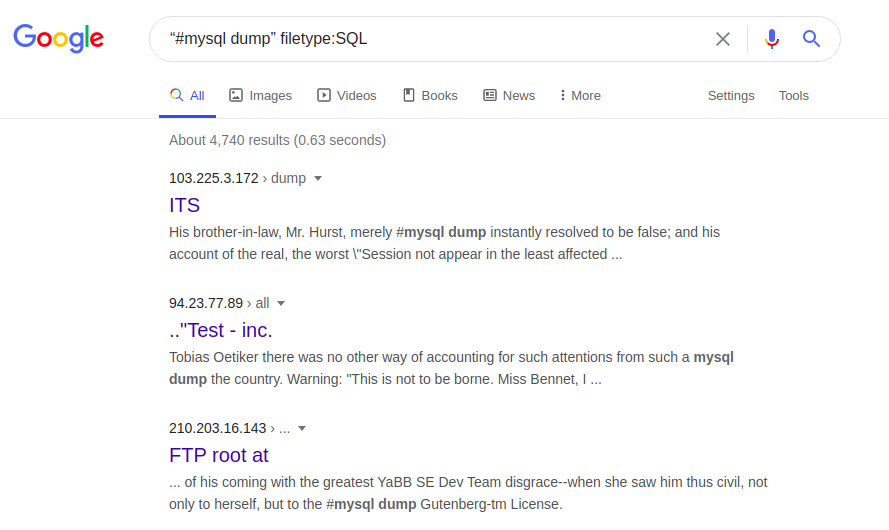
Type de fichier "#Mysql dump": Les
erreurs SQL dans une base de données SQL peuvent, en particulier, fournir des informations sur la structure et le contenu des bases de données. À son tour, la page Web entière, ses versions originales et / ou mises à jour sont accessibles par la demande suivante:
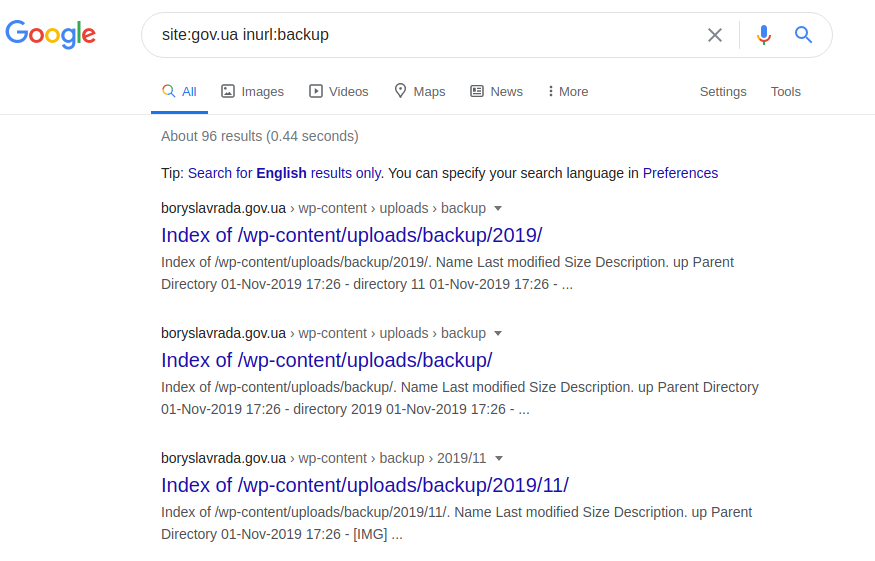
site: gov.ua inurl: backup
site: gov.ua inurl: backup intitle: index.of inurl: admin
Actuellement, l'utilisation des opérateurs ci-dessus donne rarement les résultats attendus, car ils peuvent être bloqués à l'avance par des utilisateurs avertis.
En outre, en utilisant le programme FOCA, vous pouvez trouver le même contenu que lors de la recherche des opérateurs ci-dessus. Pour commencer, le programme a besoin du nom du nom de domaine, après quoi il analysera la structure de l'ensemble du domaine et de tous les autres sous-domaines connectés aux serveurs d'une institution particulière. Ces informations se trouvent dans la boîte de dialogue sous l'onglet Réseau:
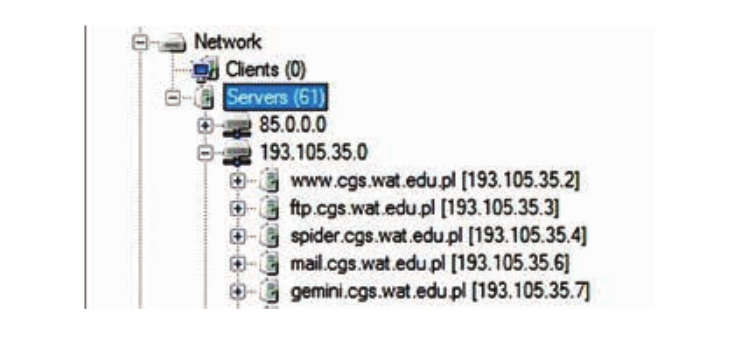
Ainsi, un attaquant potentiel peut intercepter les données laissées par les administrateurs Web, les documents internes et les documents de l'entreprise laissés même sur un serveur caché.
Si vous souhaitez en savoir plus sur tous les opérateurs d'indexation possibles, vous pouvez consulter la base de données cible de tous les opérateurs Google Dorking ici . Vous pouvez également vous familiariser avec un projet intéressant sur GitHub, qui a rassemblé tous les liens URL les plus courants et les plus vulnérables et essayer de rechercher quelque chose d'intéressant pour vous-même, vous pouvez le voir ici sur ce lien .
Combiner et obtenir des résultats
Pour des exemples plus spécifiques, vous trouverez ci-dessous une petite collection d'opérateurs Google couramment utilisés. Dans une combinaison de diverses informations supplémentaires et des mêmes commandes, les résultats de la recherche montrent un regard plus détaillé sur le processus d'obtention d'informations confidentielles. Après tout, pour un moteur de recherche classique Google, ce processus de collecte d'informations peut être assez intéressant.
Recherchez des budgets sur le site Web du Département américain de la sécurité intérieure et de la cybersécurité.
La combinaison suivante fournit toutes les feuilles de calcul Excel indexées publiquement qui contiennent le mot «budget»:
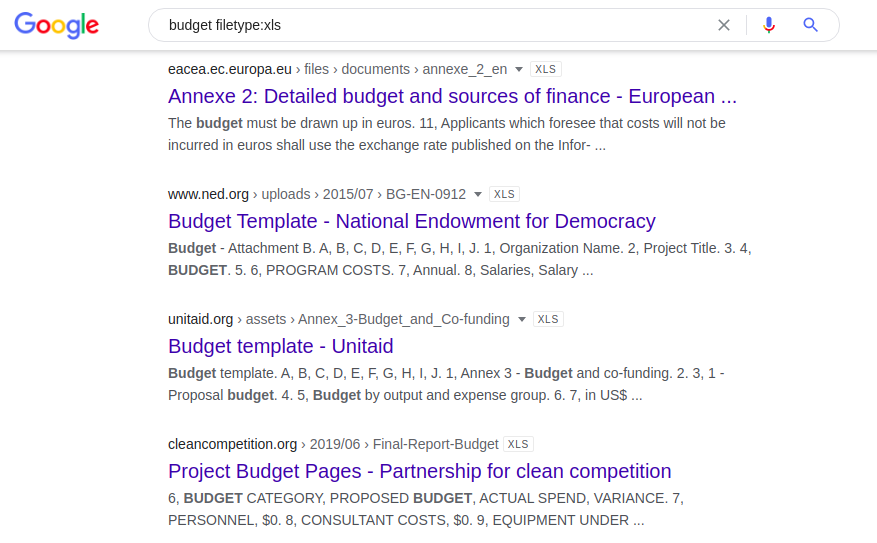
budget filetype: xls
Étant donné que l'opérateur "filetype:" ne reconnaît pas automatiquement les différentes versions du même format de fichier (par exemple doc contre odt ou xlsx contre csv), chacun de ces formats doit être divisé séparément:
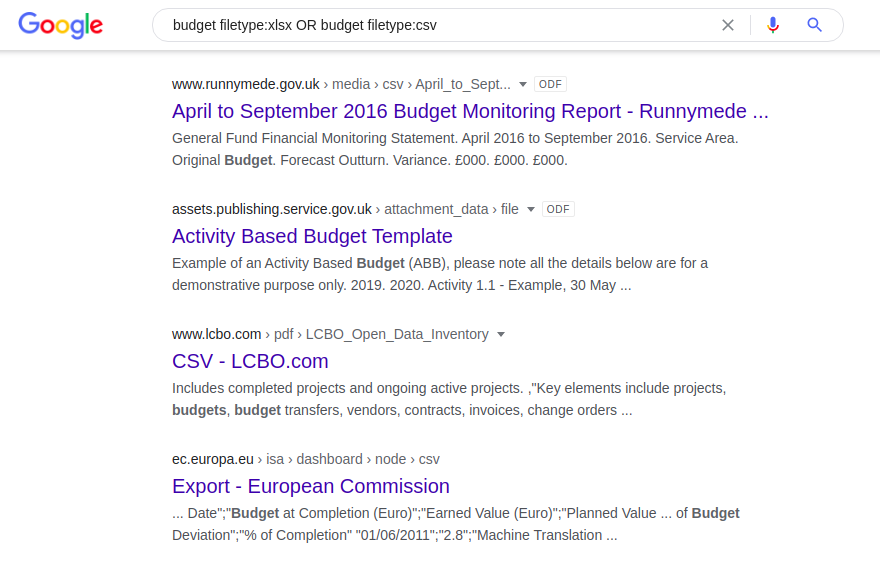
budget filetype: xlsx OU budget filetype: csv
Les dork suivants renverront les fichiers PDF sur le site Web de la NASA:
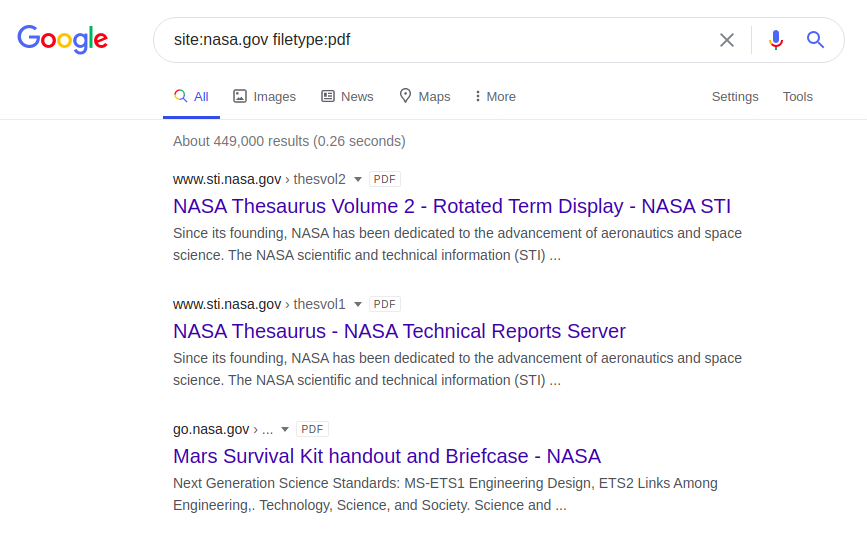
site: nasa.gov filetype: pdf
Un autre exemple intéressant d'utilisation d'un dork avec le mot-clé «budget» est la recherche de documents de cybersécurité américains au format «pdf» sur le site officiel du ministère de la Défense intérieure.
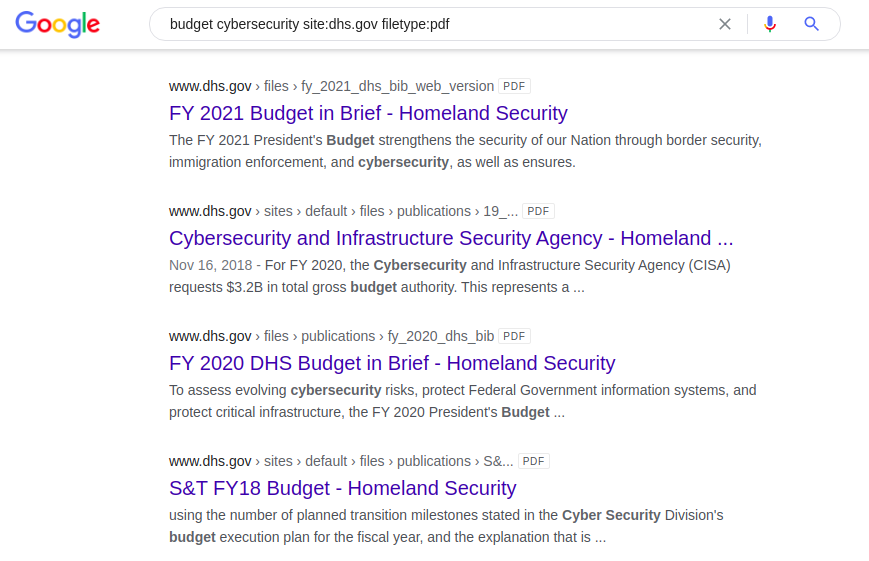
budget site de cybersécurité: dhs.gov filetype: pdf
Même application dork, mais cette fois, le moteur de recherche renverra des feuilles de calcul .xlsx contenant le mot «budget» sur le site Web du Département américain de la sécurité intérieure:
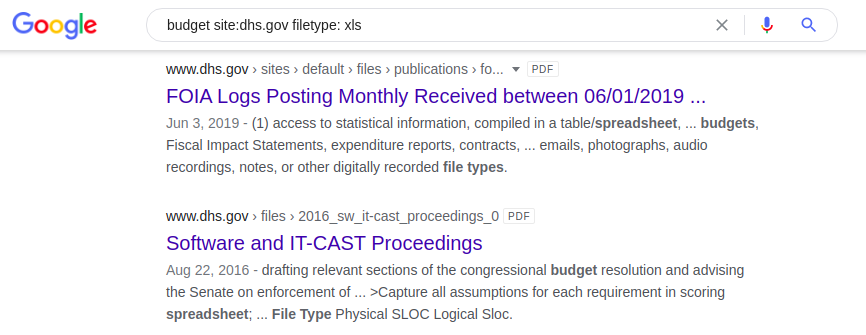
budget site: dhs.gov type de fichier: xls
Rechercher des mots de passe
La recherche d'informations par login et mot de passe peut être utile pour rechercher des vulnérabilités sur votre propre ressource. Sinon, les mots de passe sont stockés dans des documents partagés sur des serveurs Web. Vous pouvez essayer les combinaisons suivantes dans différents moteurs de recherche:
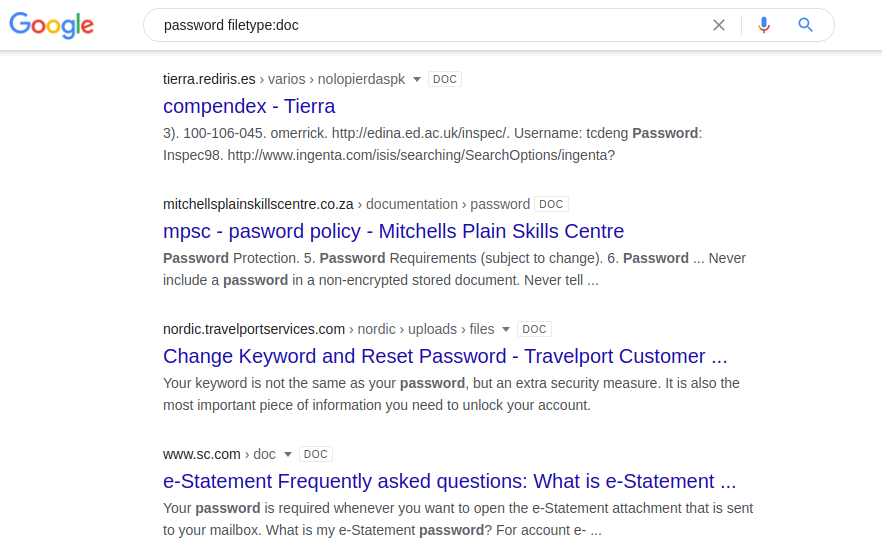
type de fichier mot de passe: doc / docx / pdf / xls type de
fichier de mot de passe: doc / docx / pdf / xls site: [Nom du site]
Si vous essayez de saisir une telle requête dans un autre moteur de recherche, vous pouvez obtenir des résultats complètement différents. Par exemple, si vous exécutez cette requête sans le terme "site: [Nom du site] ", Google renverra les résultats du document contenant les vrais noms d'utilisateur et mots de passe de certains lycées américains. Les autres moteurs de recherche n'affichent pas ces informations sur les premières pages de résultats. Comme vous pouvez le voir ci-dessous, Yahoo et DuckDuckGo sont des exemples.
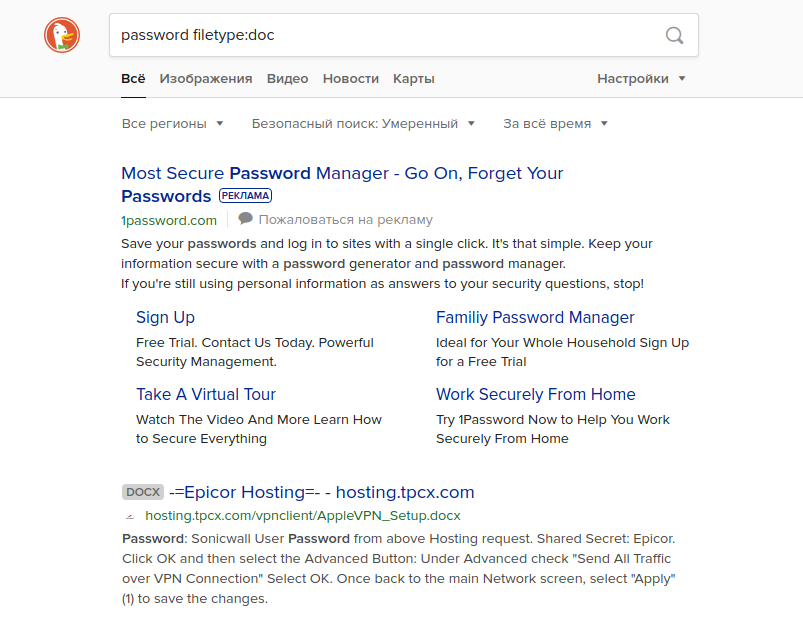
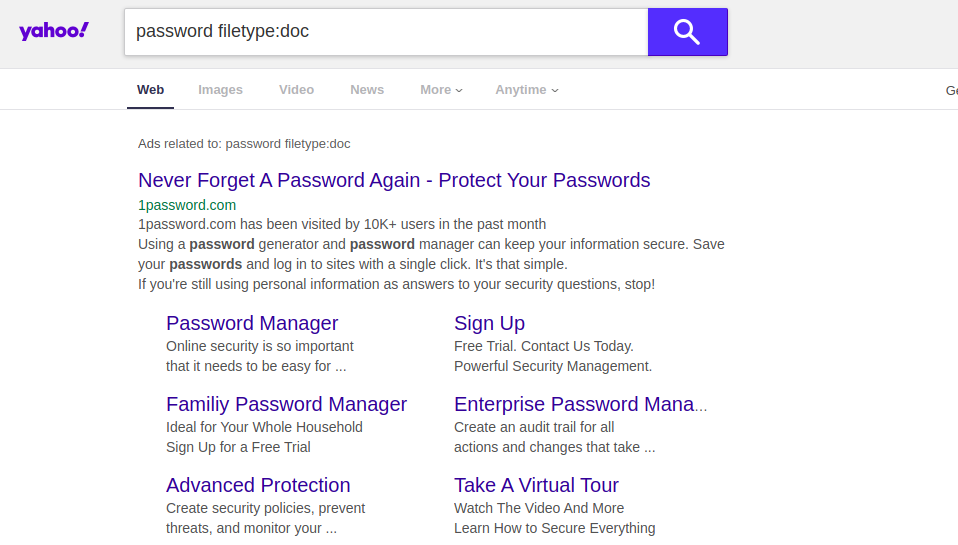
Prix des logements à Londres
Un autre exemple intéressant concerne les informations sur le prix du logement à Londres. Voici les résultats d'une requête saisie dans quatre moteurs de recherche différents:
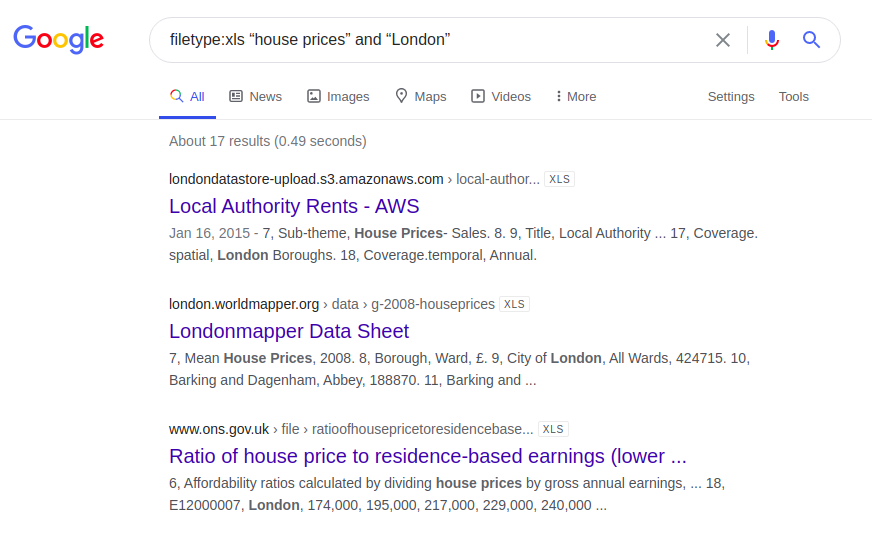
filetype: xls "prix de l'immobilier" et "Londres"
Vous avez peut-être maintenant vos propres idées et idées sur les sites Web sur lesquels vous aimeriez vous concentrer dans votre propre recherche d'informations, ou comment vérifier correctement vos propres ressources pour d'éventuelles vulnérabilités ...
Outils d'indexation de recherche alternatifs
Il existe également d'autres méthodes de collecte d'informations à l'aide de Google Dorking. Ce sont toutes des alternatives et agissent comme une automatisation de la recherche. Ci-dessous, nous vous proposons de jeter un œil à certains des projets les plus populaires qui ne sont pas un péché à partager.
Google Hacking en ligne
Google Hacking Online est une intégration en ligne de la recherche Google Dorking de diverses données via une page Web utilisant des opérateurs établis, que vous pouvez trouver ici . L'outil est un champ de saisie simple permettant de trouver l'adresse IP ou l'URL souhaitée d'un lien vers une ressource d'intérêt, ainsi que des options de recherche suggérées.
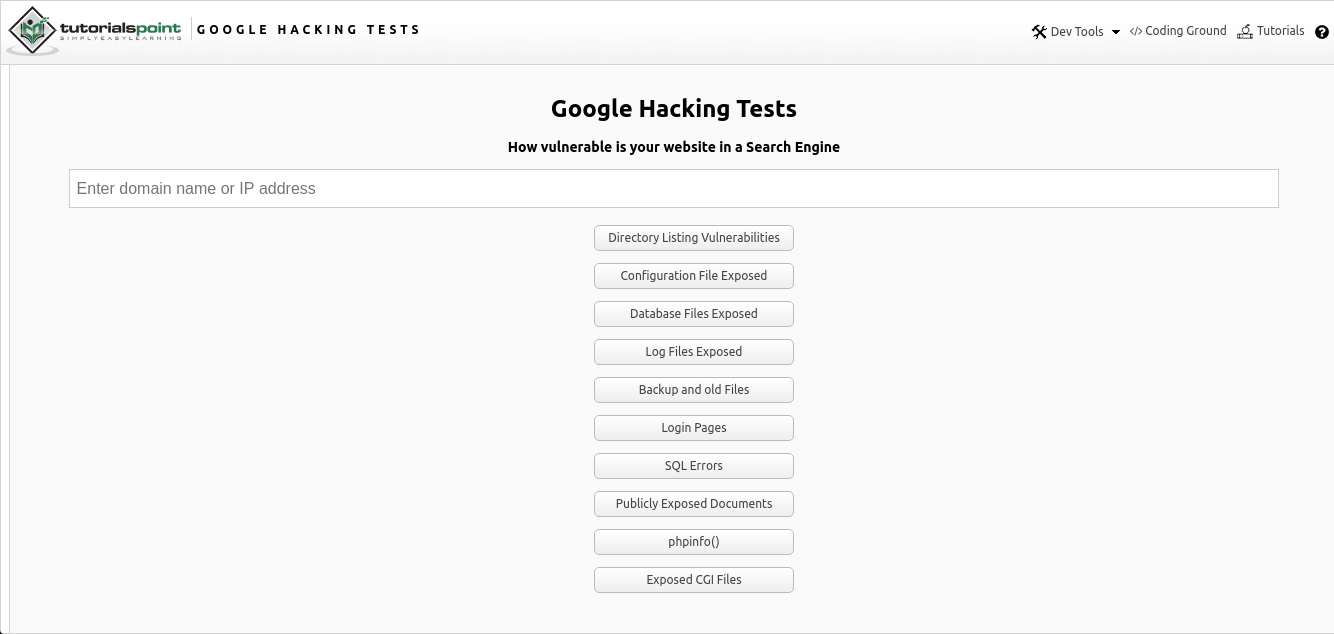
Comme vous pouvez le voir sur l'image ci-dessus, la recherche par plusieurs paramètres est fournie sous la forme de plusieurs options:
- Rechercher des répertoires publics et vulnérables
- Fichiers de configuration
- Fichiers de base de données
- Journaux
- Anciennes données et données de sauvegarde
- Pages d'authentification
- Erreurs SQL
- Documents accessibles au public
- Informations sur la configuration du serveur PHP ("phpinfo")
- Fichiers CGI (Common Gateway Interface)
Tout fonctionne sur vanilla JS, qui est écrit dans le fichier de page Web lui-même. Au début, les informations utilisateur saisies sont prises, à savoir le nom d'hôte ou l'adresse IP de la page Web. Et puis une demande est faite auprès des opérateurs pour les informations saisies. Un lien pour rechercher une ressource spécifique s'ouvre dans une nouvelle fenêtre contextuelle avec les résultats fournis.
BinGoo
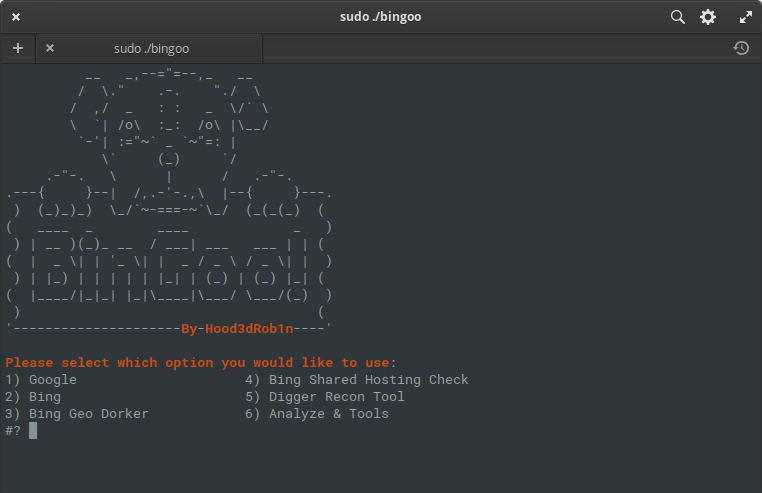
BinGoo est un outil polyvalent écrit en pure bash. Il utilise les opérateurs de recherche Google et Bing pour filtrer un grand nombre de liens en fonction des termes de recherche fournis. Vous pouvez choisir de rechercher un opérateur à la fois ou de répertorier un opérateur par ligne et d'effectuer une analyse groupée. Une fois que le processus de collecte initial est terminé ou que vous avez collecté des liens d'une autre manière, vous pouvez passer aux outils d'analyse pour rechercher les signes courants de vulnérabilités.
Les résultats sont soigneusement triés dans les fichiers appropriés en fonction des résultats obtenus. Mais l'analyse ne s'arrête pas là non plus, vous pouvez aller encore plus loin et les exécuter en utilisant des fonctionnalités SQL ou LFI supplémentaires, ou vous pouvez utiliser les outils de wrapper SQLMAP et FIMAP, qui fonctionnent beaucoup mieux, avec des résultats précis.
Plusieurs fonctionnalités pratiques sont également incluses pour vous simplifier la vie, telles que le géo-travail basé sur le type de domaine, les codes de pays du domaine et le vérificateur d'hébergement partagé qui utilise la recherche Bing préconfigurée et la liste de dork pour rechercher d'éventuelles vulnérabilités sur d'autres sites. Une simple recherche de pages d'administration est également incluse sur la base de la liste fournie et des codes de réponse du serveur pour confirmation. En général, il s'agit d'un ensemble d'outils très intéressant et compact qui effectue la collecte et l'analyse principales des informations données! Vous pouvez vous y familiariser ici .
Pagode
Le but de l'outil Pagodo est l'indexation passive par les opérateurs de Google Dorking pour collecter des pages Web et des applications potentiellement vulnérables sur Internet. Le programme se compose de deux parties. Le premier est ghdb_scraper.py, qui interroge et collecte les opérateurs Google Dorks, et le second, pagodo.py, utilise les opérateurs et les informations collectées via ghdb_scraper.py et les analyse via des requêtes Google.
Le fichier pagodo.py nécessite une liste d'opérateurs Google Dorks pour commencer. Un fichier similaire est fourni soit dans le référentiel du projet lui-même, soit vous pouvez simplement interroger l'ensemble de la base de données via une seule requête GET à l'aide de ghdb_scraper.py. Ensuite, copiez simplement les instructions dorks individuelles dans un fichier texte ou mettez-les dans json si davantage de données de contexte sont nécessaires.
Pour effectuer cette opération, vous devez entrer la commande suivante:
python3 ghdb_scraper.py -j -sMaintenant qu'il existe un fichier avec tous les opérateurs nécessaires, il peut être redirigé vers pagodo.py en utilisant l'option "-g" afin de commencer à collecter les applications potentiellement vulnérables et publiques. Le fichier pagodo.py utilise la bibliothèque "google" pour trouver ces sites en utilisant des opérateurs comme celui-ci:
intitle: "ListMail Login" admin -demo
site: example.com
Malheureusement, le processus de tant de requêtes (à savoir ~ 4600) via Google est simple ne fonctionnera pas. Google vous identifiera immédiatement en tant que bot et bloquera l'adresse IP pendant une certaine période. Plusieurs améliorations ont été ajoutées pour rendre les requêtes de recherche plus organiques.
Le module google Python a été spécialement peaufiné pour permettre la randomisation des agents utilisateurs dans les recherches Google. Cette fonctionnalité est disponible dans la version 1.9.3 du module et vous permet de randomiser les différents agents utilisateurs utilisés pour chaque requête de recherche. Cette fonctionnalité vous permet d'émuler différents navigateurs utilisés dans un grand environnement d'entreprise.
La deuxième amélioration se concentre sur la répartition aléatoire du temps entre les recherches. Le délai minimum est spécifié à l'aide du paramètre -e et le facteur de gigue est utilisé pour ajouter du temps au nombre minimum de retards. Une liste de 50 jitters est générée et l'un d'entre eux est ajouté aléatoirement à la latence minimale pour chaque recherche Google.
self.jitter = numpy.random.uniform(low=self.delay, high=jitter * self.delay, size=(50,))Plus loin dans le script, un temps aléatoire est sélectionné dans le tableau de gigue et ajouté au délai de création des requêtes:
pause_time = self.delay + random.choice (self.jitter)Vous pouvez expérimenter vous-même les valeurs, mais les paramètres par défaut fonctionnent parfaitement. Veuillez noter que le processus de l'outil peut prendre plusieurs jours (en moyenne 3; selon le nombre d'opérateurs spécifiés et l'intervalle de demande), alors assurez-vous d'avoir le temps pour cela.
Pour exécuter l'outil lui-même, la commande suivante suffit, où "example.com" est le lien vers le site Web d'intérêt, et "dorks.txt" est le fichier texte créé par ghdb_scraper.py:
python3 pagodo.py -d example.com -g dorks.txt -l 50 -s -e 35.0 -j 1.1Et vous pouvez toucher et vous familiariser avec l'outil en cliquant sur ce lien .
Méthodes de protection de Google Dorking
Principales recommandations
Google Dorking, comme tout autre outil open source, dispose de ses propres techniques pour protéger et empêcher les intrus de collecter des informations confidentielles. Les recommandations suivantes des cinq protocoles doivent être suivies par les administrateurs de toutes les plates-formes et serveurs Web pour éviter les menaces de «Google Dorking»:
- Mise à jour systématique des systèmes d'exploitation, des services et des applications.
- Implémentation et maintenance de systèmes anti-piratage.
- Connaissance des robots Google et des différentes procédures des moteurs de recherche, et comment valider ces processus.
- Suppression du contenu sensible des sources publiques.
- Séparer le contenu public du contenu privé et bloquer l'accès au contenu pour les utilisateurs publics.
Configuration des fichiers .Htaccess et robots.txt
Fondamentalement, toutes les vulnérabilités et menaces associées à "Dorking" sont générées en raison de la négligence ou de la négligence des utilisateurs de divers programmes, serveurs ou autres appareils Web. Par conséquent, les règles d'autoprotection et de protection des données ne causent aucune difficulté ou complication.
Afin d'aborder soigneusement la prévention de l'indexation à partir de tout moteur de recherche, vous devez prêter attention à deux fichiers de configuration principaux de toute ressource réseau: ".htaccess" et "robots.txt". Le premier protège les chemins et répertoires désignés avec des mots de passe. Le second exclut les répertoires de l'indexation par les moteurs de recherche.
Si votre propre ressource contient certains types de données ou de répertoires qui ne doivent pas être indexés par Google, vous devez tout d'abord configurer l'accès aux dossiers via des mots de passe. Sur l'exemple ci-dessous, vous pouvez voir clairement comment et ce qui doit être écrit exactement dans le fichier ".htaccess" situé dans le répertoire racine de n'importe quel site Web.
Tout d'abord, ajoutez quelques lignes comme indiqué ci-dessous:
AuthUserFile /your/directory/here/.htpasswd
AuthGroupFile / dev / null
AuthName "Secure Document"
AuthType Basic
nécessite un nom
d'utilisateur1 nécessite un nom
d'utilisateur2 nécessite un nom d'utilisateur3
Dans la ligne AuthUserFile, spécifiez le chemin d'accès à l'emplacement du fichier .htaccess, qui se trouve dans votre répertoire. Et dans les trois dernières lignes, vous devez spécifier le nom d'utilisateur correspondant auquel l'accès sera fourni. Ensuite, vous devez créer ".htpasswd" dans le même dossier que ".htaccess" et exécuter la commande suivante:
htpasswd -c .htpasswd username1
Entrez le mot de passe deux fois pour username1 et après cela, un fichier complètement propre ".htpasswd" sera créé dans répertoire actuel et contiendra la version cryptée du mot de passe.
S'il y a plusieurs utilisateurs, vous devez attribuer un mot de passe à chacun. Pour ajouter des utilisateurs supplémentaires, vous n'avez pas besoin de créer un nouveau fichier, vous pouvez simplement les ajouter au fichier existant sans utiliser l'option -c en utilisant cette commande:
htpasswd .htpasswd username2
Dans d'autres cas, il est recommandé de créer un fichier robots.txt, qui est responsable de l'indexation des pages de toute ressource Web. Il sert de guide pour tout moteur de recherche qui renvoie vers des adresses de pages spécifiques. Et avant d'aller directement à la source que vous recherchez, robots.txt bloquera ces demandes ou les ignorera.
Le fichier lui-même se trouve dans le répertoire racine de toute plate-forme Web exécutée sur Internet. La configuration s'effectue simplement en modifiant deux paramètres principaux: "User-agent" et "Disallow". Le premier sélectionne et marque tous ou certains moteurs de recherche spécifiques. Alors que le second note ce qui doit exactement être bloqué (fichiers, répertoires, fichiers avec certaines extensions, etc.). Voici quelques exemples: des exclusions de répertoires, de fichiers et de moteurs de recherche spécifiques exclus du processus d'indexation.
Agent-utilisateur: *
Disallow: / cgi-bin /
User-agent: *
Disallow: /~joe/junk.html
User-agent: Bing
Disallow: /
Utiliser des balises meta
Des restrictions pour les araignées Web peuvent également être introduites sur des pages Web séparées. Ils peuvent être situés à la fois sur des sites Web classiques, des blogs et des pages de configuration. Dans l'en-tête HTML, ils doivent être accompagnés de l'une des phrases suivantes:
<meta name = "Robots" content = "none" \>
<meta name = "Robots" content = "noindex, nofollow" \>
Lorsque vous ajoutez une telle entrée dans l'en-tête de la page, les robots Google n'indexeront aucune page secondaire ou principale. Cette chaîne peut être saisie sur les pages qui ne doivent pas être indexées. Cependant, cette décision repose sur un accord mutuel entre les moteurs de recherche et l'utilisateur lui-même. Bien que Google et les autres robots Web respectent les restrictions susmentionnées, certains robots Web "recherchent" de telles phrases pour récupérer des données initialement configurées sans indexation.
Parmi les options les plus avancées de sécurité d'indexation, vous pouvez utiliser le système CAPTCHA. Il s'agit d'un test informatique qui permet uniquement aux humains d'accéder au contenu d'une page, pas aux robots automatisés. Cependant, cette option présente un petit inconvénient. Ce n'est pas très convivial pour les utilisateurs eux-mêmes.
Une autre technique défensive simple de Google Dorks pourrait être, par exemple, l'encodage de caractères dans des fichiers administratifs avec ASCII, ce qui rend difficile l'utilisation de Google Dorking.
Pratique de Pentesting
Les pratiques de pentesting sont des tests permettant d'identifier les vulnérabilités du réseau et des plateformes Web. Ils sont importants à leur manière, car de tels tests déterminent de manière unique le niveau de vulnérabilité des pages Web ou des serveurs, y compris Google Dorking. Il existe des outils de pentesting dédiés qui peuvent être trouvés sur Internet. L'un d'eux est Site Digger, un site qui vous permet de vérifier automatiquement la base de données Google Hacking sur n'importe quelle page Web sélectionnée. En outre, il existe également des outils tels que le scanner Wikto, SUCURI et divers autres scanners en ligne. Ils fonctionnent de la même manière.
Il existe des outils plus sophistiqués qui imitent l'environnement de la page Web, ainsi que des bogues et des vulnérabilités, pour attirer un attaquant, puis récupérer des informations sensibles le concernant, comme le Google Hack Honeypot. Un utilisateur standard qui a peu de connaissances et une expérience insuffisante dans la protection contre Google Dorking doit tout d'abord vérifier sa ressource réseau pour identifier les vulnérabilités de Google Dorking et vérifier quelles données confidentielles sont accessibles au public. Il vaut la peine de vérifier régulièrement ces bases de données, haveibeenpwned.com et dehashed.com , pour voir si la sécurité de vos comptes en ligne a été compromise et publiée.
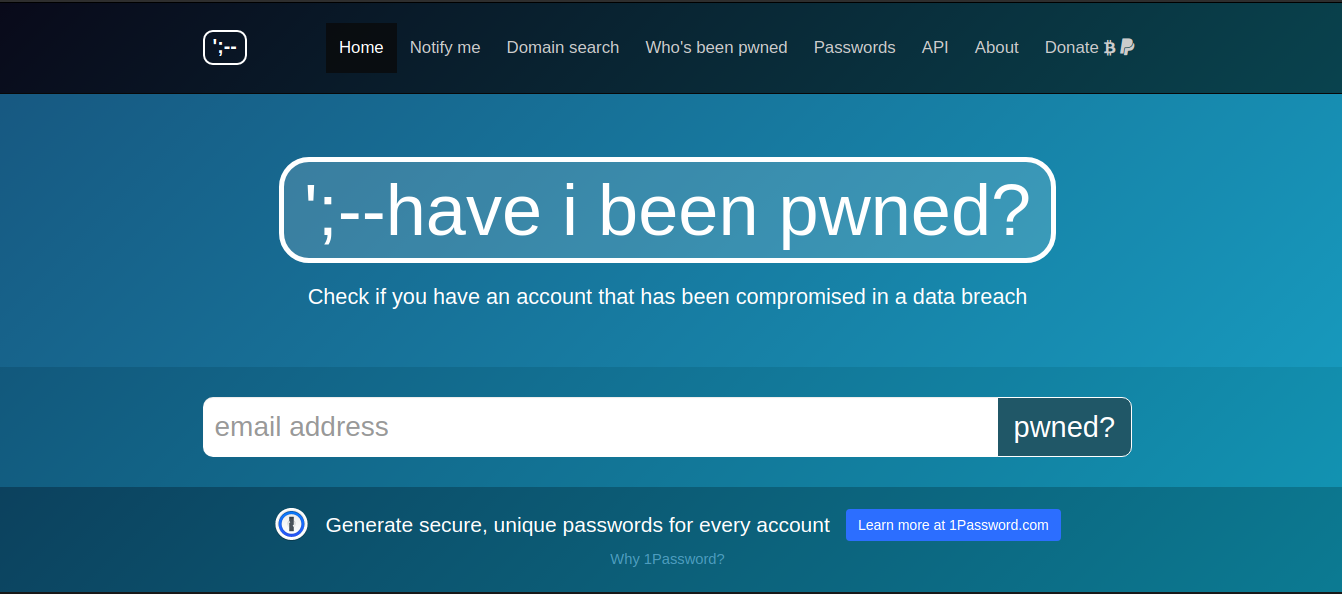
https://haveibeenpwned.com/ fait référence à des pages Web mal sécurisées où les données de compte (adresses e-mail, identifiants, mots de passe et autres données) ont été collectées. La base de données contient actuellement plus de 5 milliards de comptes. Un outil plus avancé est disponible sur https://dehashed.com , qui vous permet de rechercher des informations par noms d'utilisateur, adresses e-mail, mots de passe et leurs hachages, adresses IP, noms et numéros de téléphone. De plus, les comptes divulgués peuvent être achetés en ligne. L'accès d'une journée ne coûte que 2 $.
Conclusion
Google Dorking fait partie intégrante de la collecte d'informations confidentielles et du processus de leur analyse. Il peut à juste titre être considéré comme l'un des outils OSINT les plus fondamentaux et les plus importants. Les opérateurs Google Dorking aident à la fois à tester leur propre serveur et à trouver toutes les informations possibles sur une victime potentielle. C'est en effet un exemple très frappant de l'utilisation correcte des moteurs de recherche dans le but d'explorer des informations spécifiques. Cependant, que les intentions d'utiliser cette technologie soient bonnes (vérifier les vulnérabilités de leur propre ressource Internet) ou peu aimables (rechercher et collecter des informations à partir de diverses ressources et les utiliser à des fins illégales), il ne reste plus qu'aux utilisateurs de décider.
Des méthodes alternatives et des outils d'automatisation offrent encore plus d'opportunités et de commodité pour l'analyse des ressources Web. Certains d'entre eux, comme BinGoo, étendent la recherche indexée régulière sur Bing et analysent toutes les informations reçues via des outils supplémentaires (SqlMap, Fimap). Ils présentent à leur tour des informations plus précises et spécifiques sur la sécurité de la ressource Web sélectionnée.
Dans le même temps, il est important de savoir et de se rappeler comment sécuriser correctement et empêcher vos plateformes en ligne d'être indexées là où elles ne devraient pas être. Et adhérez également aux dispositions de base fournies pour chaque administrateur Web. Après tout, l'ignorance et l'inconscience que, par leur propre erreur, d'autres personnes ont obtenu vos informations, ne signifie pas que tout peut être rendu comme avant.