
Aujourd'hui, nous allons vous dire, sans référence à des modèles spécifiques d'équipement réseau, comment le principe «de l'automatisation à l'autonomie» s'incarne dans les nouvelles capacités du produit FabricInsight. En effet, ces dernières années, non seulement sa composition a changé, mais aussi de nombreux nouveaux scénarios sont apparus qui permettent de déterminer l'état actuel du réseau et d'en prévoir les éventuels problèmes.
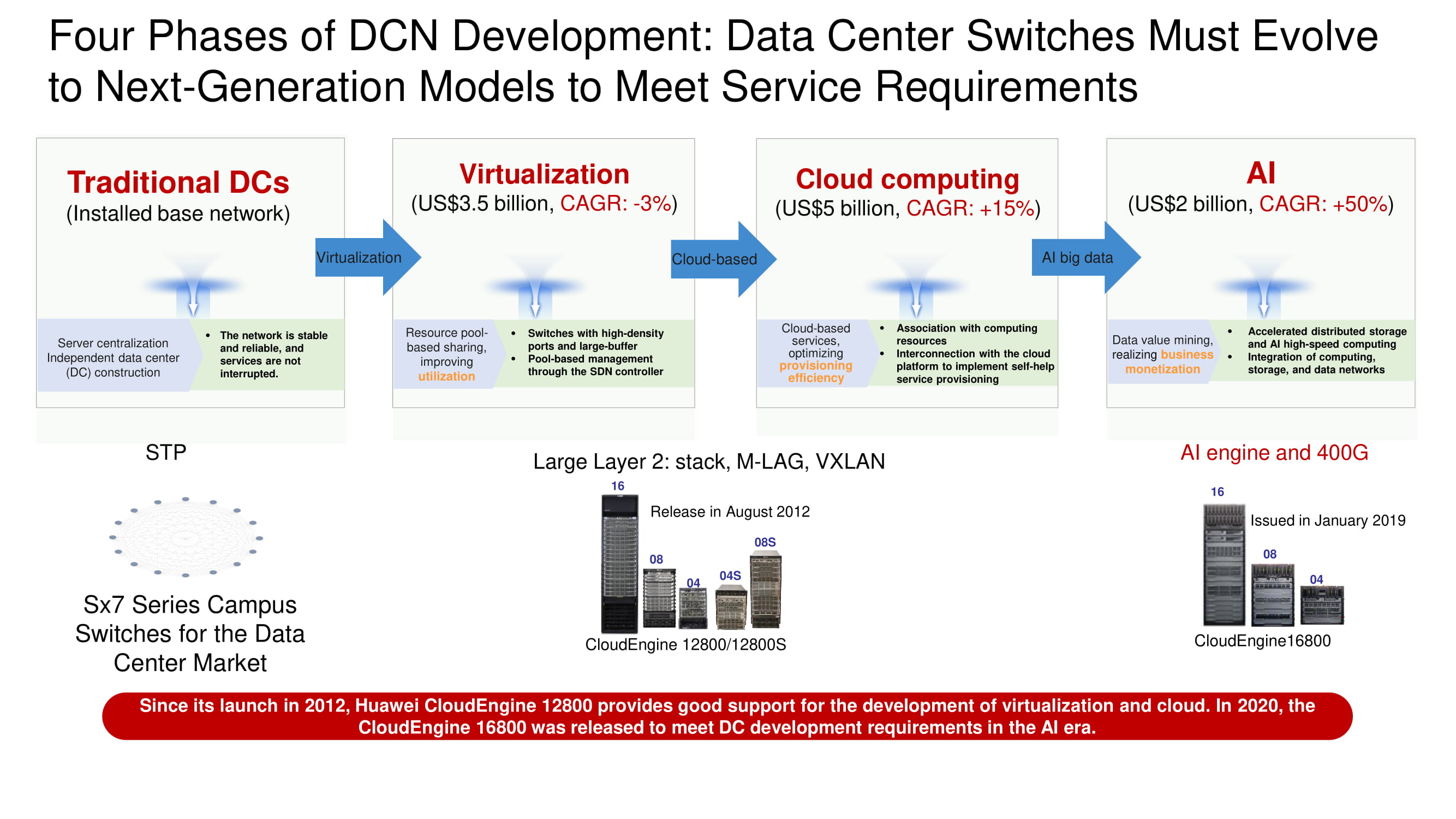
Quatre étapes de développement du centre de données
En déterminant le vecteur de développement des réseaux de datacenters, il est facile de voir comment les architectures de datacenters traditionnels sont progressivement tombées sous l'assaut des systèmes de virtualisation, puis ont connu une migration massive de ressources et de services vers les clouds, et sont désormais proches de l'introduction généralisée des systèmes d'intelligence artificielle et des interfaces haut débit 400 Gb / s. Des capacités d'IA sont nécessaires pour construire des réseaux Ethernet sans perte et créer des applications totalement insensibles à la latence.
Un autre domaine d'application de l'IA est l'analyse et la surveillance des centres de données. Il faut passer d'une idéologie qui implique un contrôle fonctionnellement limité de l'état de certaines «boîtes noires» au concept de réseaux totalement transparents dont tout est connu.

En tant que principales unités de réseau d'infrastructure pour la construction de réseaux de centres de données, Huawei propose désormais une gamme de commutateurs CloudEngine 16800 à quatre, huit et seize emplacements avec des liaisons montantes de 400 Gbps; leur sortie est prévue pour l'année en cours. Aussi, parmi les nouveaux produits, nous notons les commutateurs CloudEngine 6881 et 6863 ToR construits sur notre propre base d'éléments avec des interfaces de 10 et 25 Gbps, respectivement.

L'illustration montre les modèles de commutateurs de la gamme CloudEngine 16800 à architecture orthogonale classique, qui sont équipés d'un système de refroidissement avant-arrière, ainsi que des cartes de ligne compatibles équipées d'interfaces 10, 40 et 100 Gb / s.
Parmi les fonctions de base importantes de CloudEngine 16800, nous soulignons sa capacité à travailler avec NSH (Network Service Header), qui permet de mettre en œuvre une micro-segmentation répartie sur plusieurs commutateurs dans le centre de données (isolation au niveau de la machine virtuelle), fournissant des capacités de télémétrie étendues et analysant le trafic à la périphérie du réseau (edge intelligence ) utilisant des technologies d'intelligence artificielle basées sur des puces Huawei AI.
Le V1R19C10 sera vraiment révolutionnaire. C'est en cela que de nombreuses fonctions attendues depuis longtemps devraient être implémentées, y compris EVPN Multihoming sans "jumper" sous la forme de M-LAG (Multi-Switch Link Aggregation) basé sur les premier et quatrième types de routes dans le routage EVPN VXLAN.
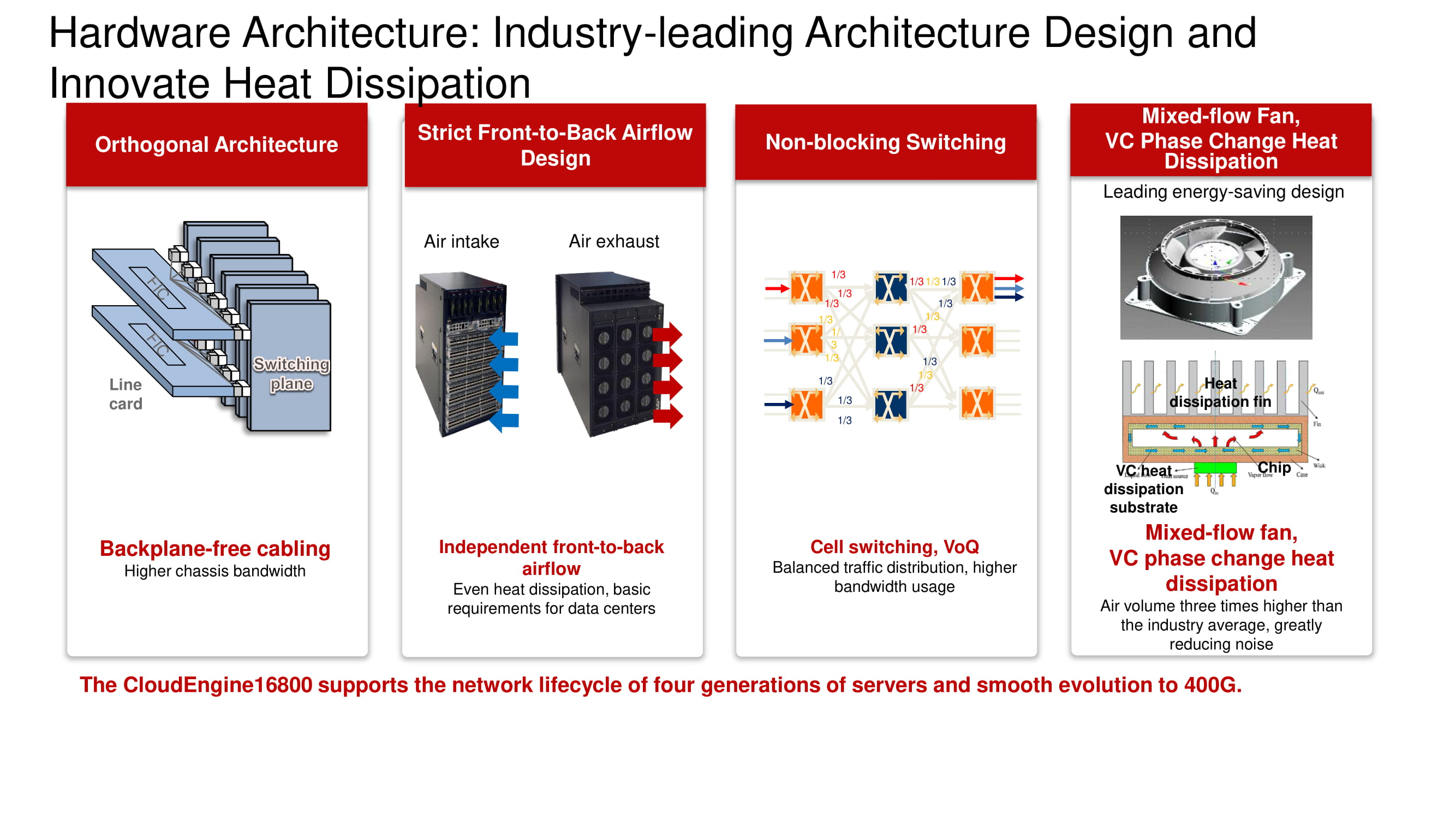
Architecture familière et nouvelles possibilités
Le diagramme montre l'architecture orthogonale familière de la commutation non bloquante «d'usine» à trois niveaux. Ses principaux avantages comprennent la disposition optimale des cartes «d'usine», des cartes de ligne, des connecteurs et un système de soufflerie basé sur des ventilateurs à vitesse variable.
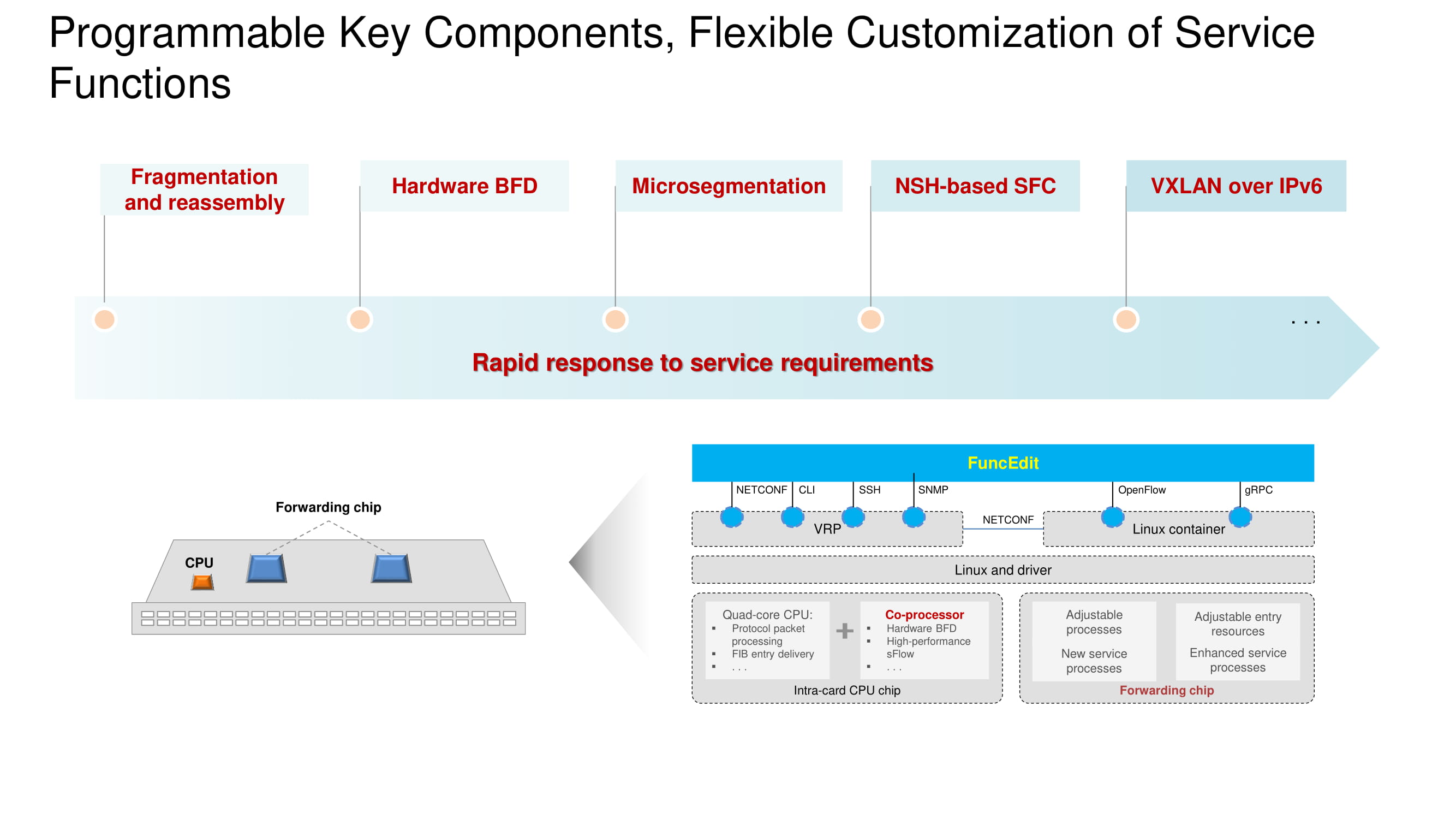
Il est important que le protocole BFD (Bidirectional Forwarding Detection) soit implémenté par le matériel sur les nouveaux modèles de commutateurs et qu'il soit possible de configurer VXLAN dans l'espace d'adressage IPv6. L'architecture de base reste la même et repose sur un processeur, un coprocesseur et une puce de transmission. La fonctionnalité de chacun des nœuds est indiquée dans le diagramme. Le principal changement en 2020 est la transition vers les propres puces de Huawei dans les commutateurs phares, en pleine concurrence avec leurs homologues de Broadcom.
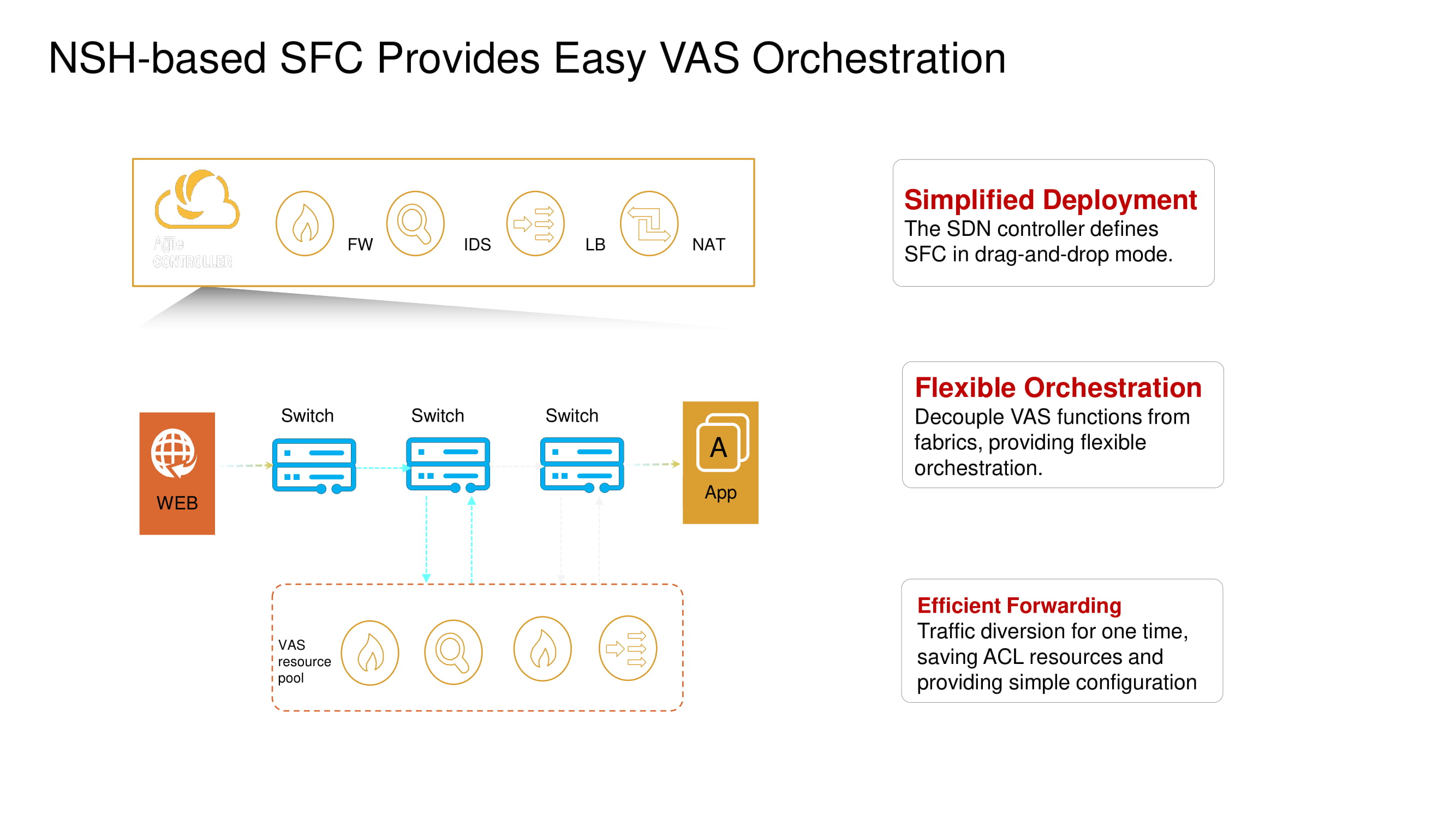
La prise en charge des opérations d'en-tête de service réseau permet aux nouveaux commutateurs de modifier les itinéraires de paquets VXLAN par défaut et d'activer des services tels que les pare-feu (FW), les systèmes de détection d'intrusion (IDS), les équilibreurs de charge (SLB) et NAT.
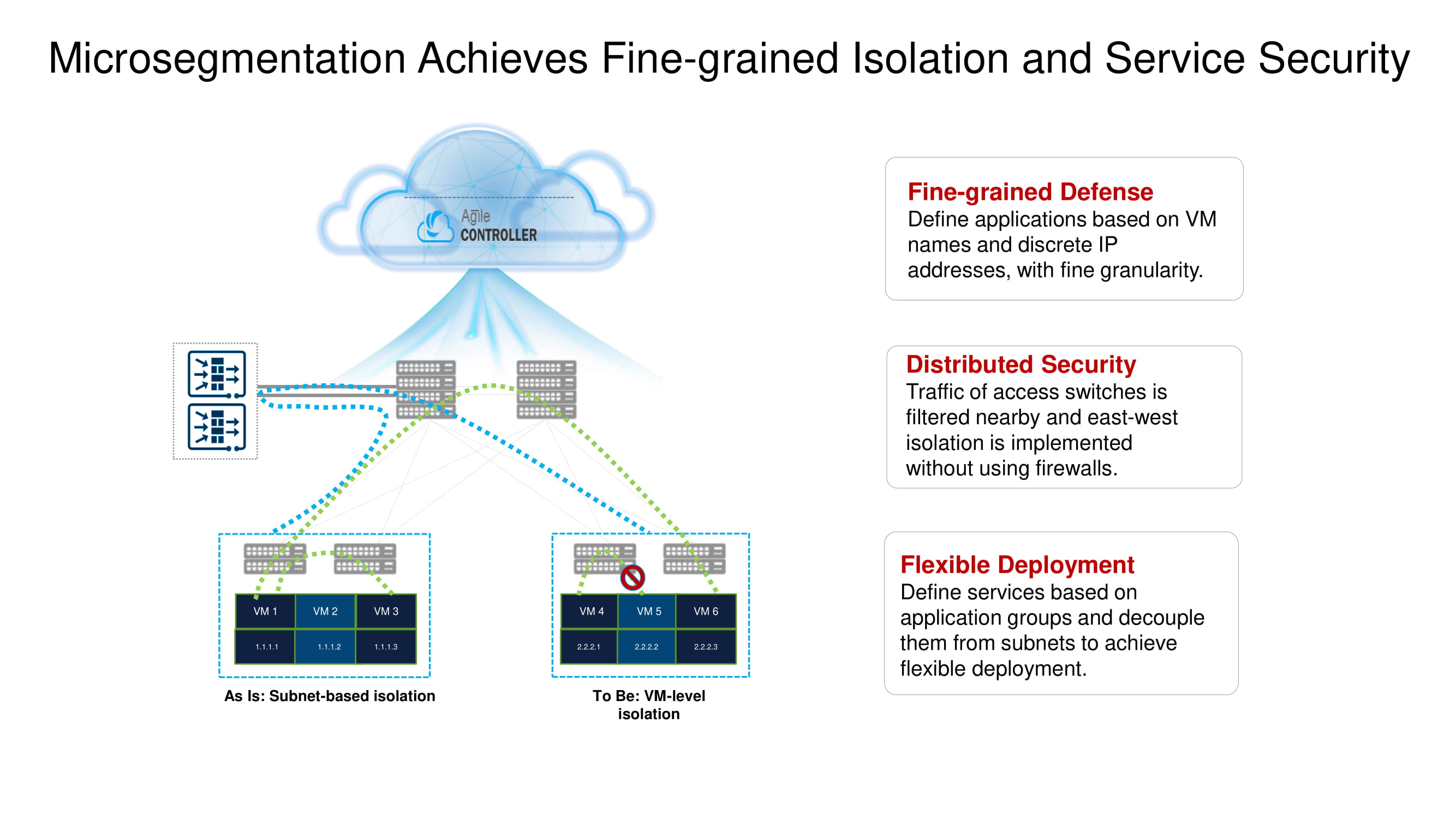
Revenons brièvement à la micro-segmentation fractionnée mentionnée précédemment. Les nouveaux commutateurs Huawei ToR avec l'aide du même NSH vous permettent d'isoler les charges de travail au niveau des noms de machines virtuelles. Ces machines peuvent être regroupées au niveau du sous-réseau en fonction des numéros de port, des protocoles supérieurs, etc., formant ainsi des groupes d'applications.
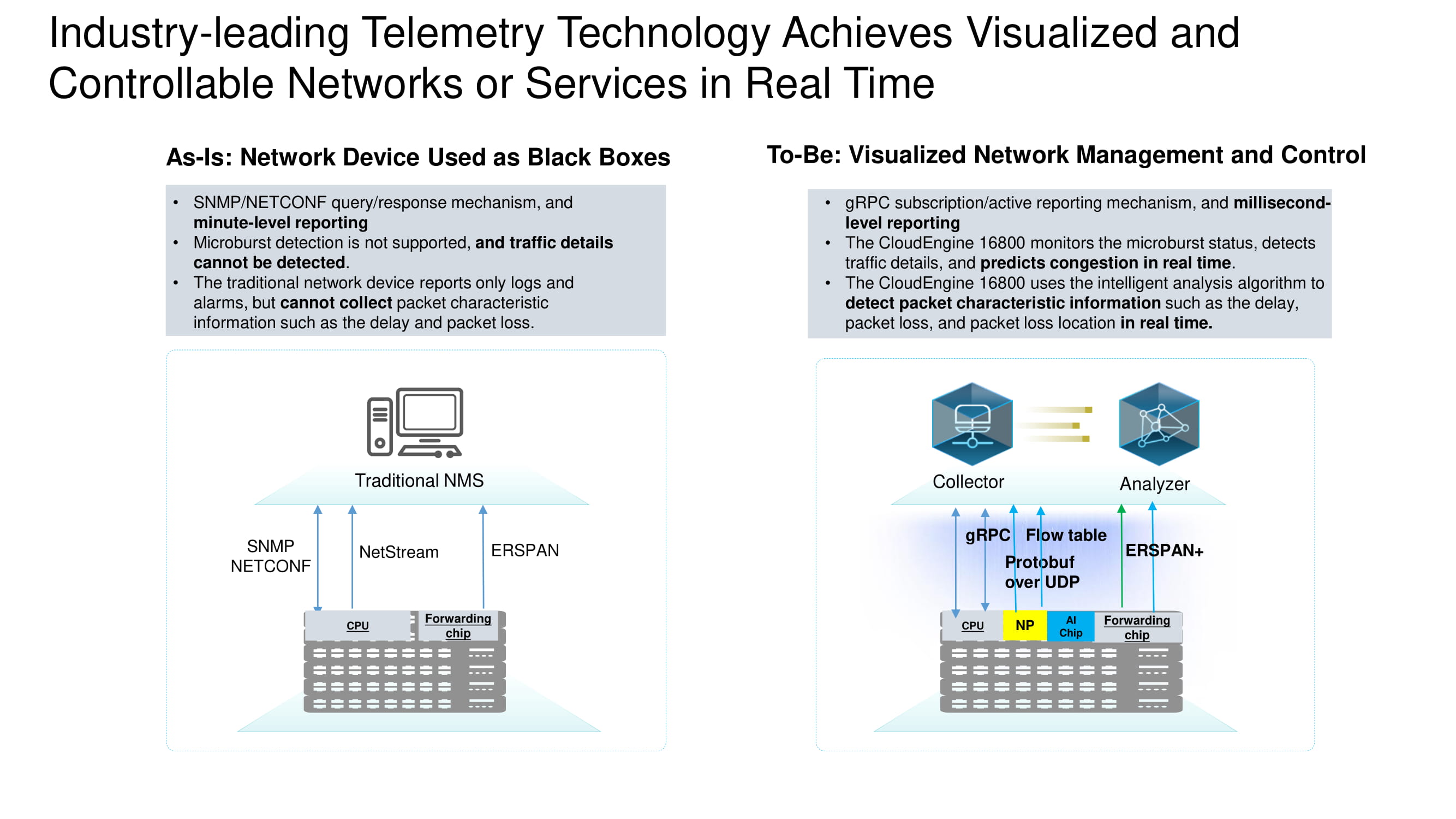
Gamme complète de données de télémétrie
Les informations des appareils sont collectées en temps réel à l'aide de plusieurs protocoles majeurs. La tâche d'ERSPAN + est de collecter les en-têtes TCP pour l'analyse détaillée ultérieure des flux TCP dans le centre de données. Des données supplémentaires sont extraites à l'aide du protocole gRPC et de la table de flux. Tout cela est collecté avec Protobuf sur UDP.
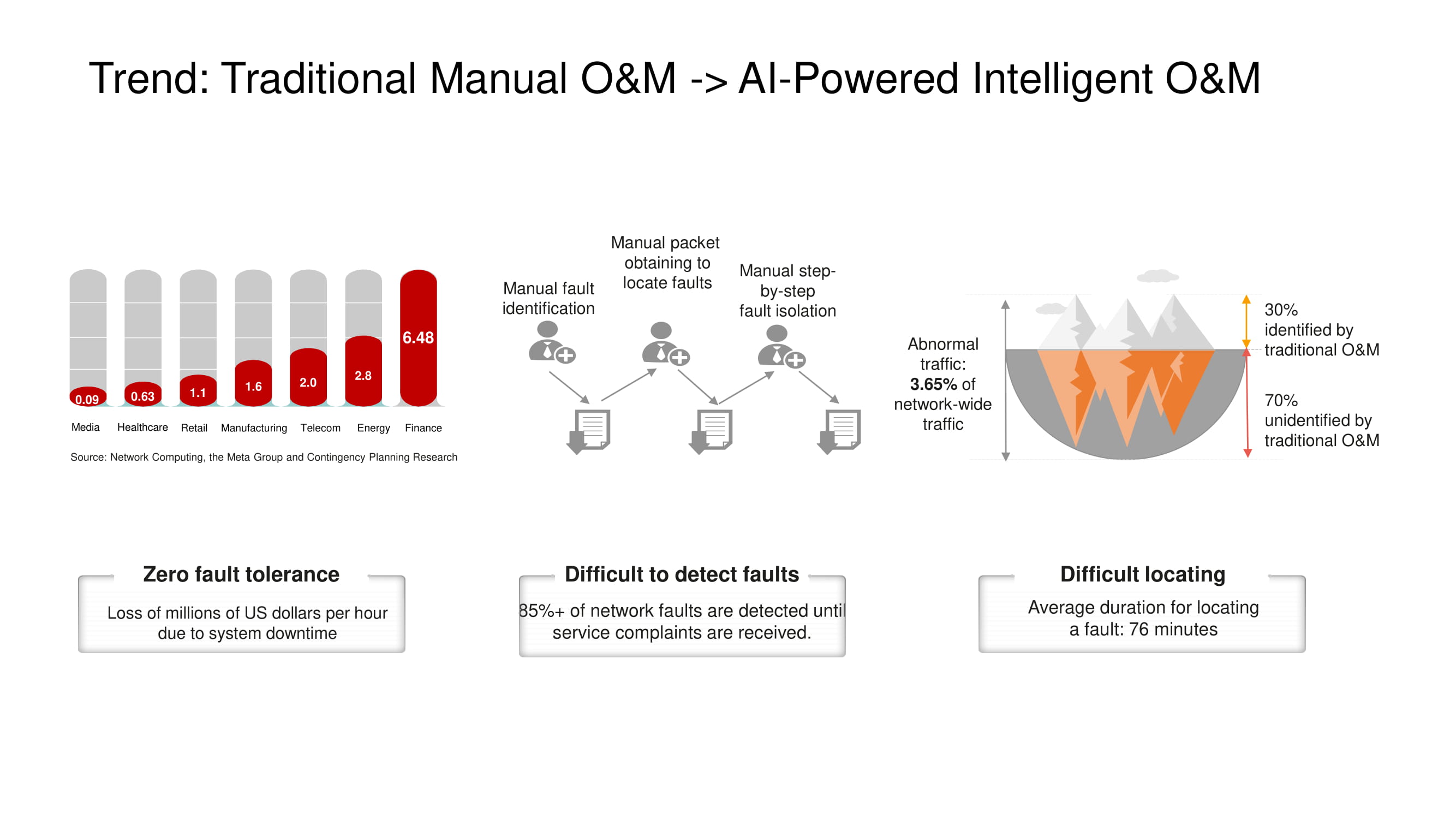
La principale direction du développement des outils O&M chez Huawei est le passage d'un contrôle de réseau manuel ou semi-automatique à un contrôle de réseau entièrement automatique , basé sur des technologies d'intelligence artificielle. Un système de télémétrie complet d'un site assez grand produit d'énormes quantités de données, dont l'analyse en peu de temps n'est possible qu'avec l'utilisation de l'IA. Ceci est particulièrement important dans ces centres de données, où les pannes et les temps d'arrêt sont tout simplement inacceptables.
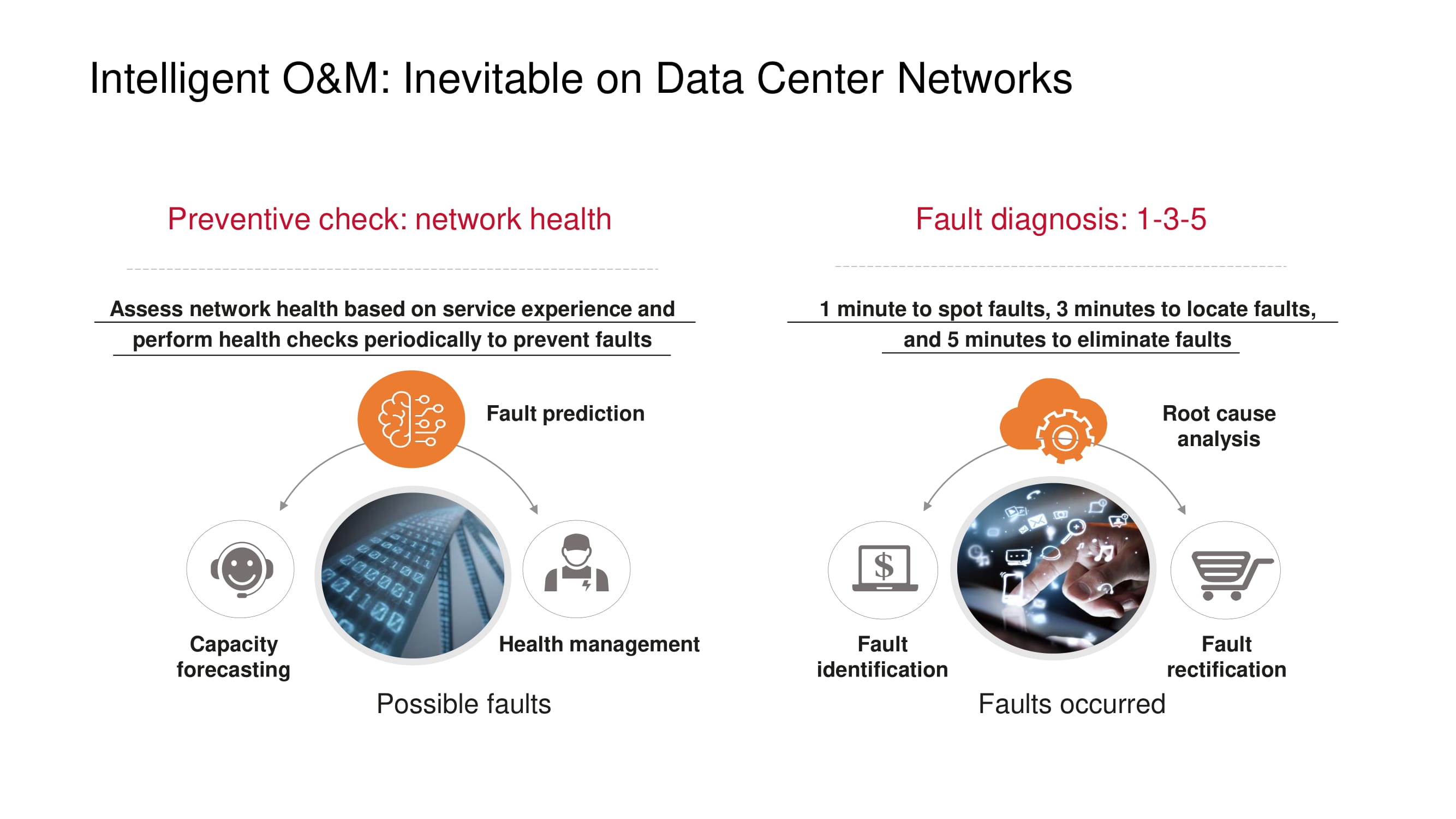
Les mesures préventives destinées à éviter que des problèmes de réseau ne surviennent comprennent tout d'abord la surveillance de la «santé» du réseau: surveillance de la charge des canaux, identification des causes de perte de paquets (par exemple, recherche d'une corrélation avec l'heure ou les périodes de fonctionnement d'une application), détection " goulots d'étranglement (prévision de capacité), etc.
Si des problèmes persistent, le principe 1-3-5 mis en avant par Huawei permet de minimiser le temps de diagnostic et de récupération: une minute pour rechercher, trois minutes pour localiser, cinq minutes pour éliminer le problème. Afin de rester dans ce cadre, les produits Huawei prennent en charge une liste toujours plus longue de défauts typiques détectés automatiquement.

Modèle V100R019C10 pour les petits centres de données
L'une des principales innovations de la V100R019C10 est la prise en charge de la visualisation basée sur des données de télémétrie dans tous les types de scénarios. En fait, nous parlons d'un affichage visuel de tout changement dans le réseau. De plus, l'appareil est désormais capable d'identifier plus de 75 causes profondes de certains problèmes et aide à définir des actions pour les éliminer (lancement de scripts, etc.).
Une nouvelle importante a été l'émergence de la version autonome, qui comprend à la fois iMaster NCE et FabricInsight et est principalement destinée aux petits centres de données qui ne nécessitent pas plusieurs serveurs pour gérer le réseau.
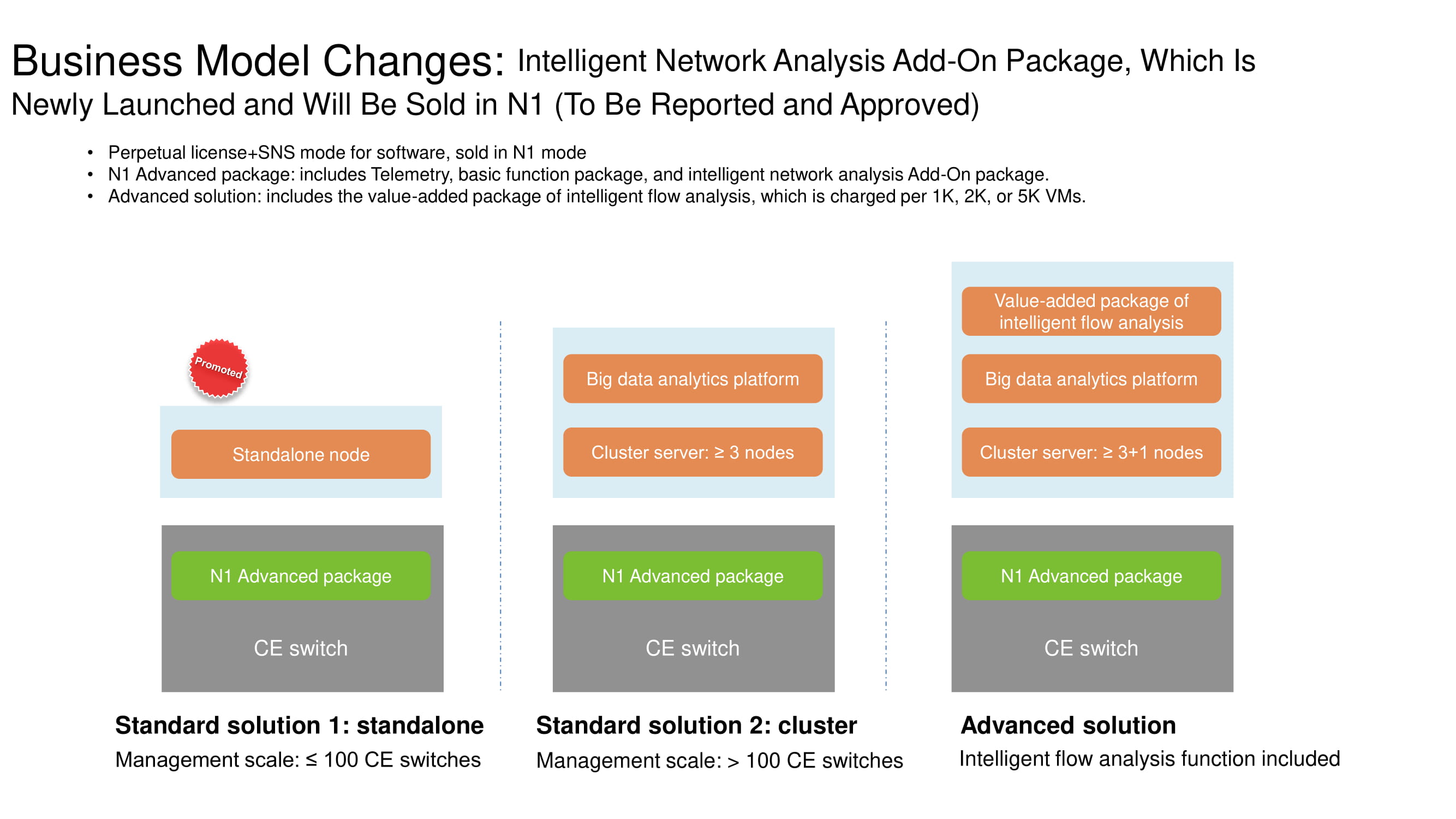
Modifications du système de licence
Pour une meilleure compréhension des fonctionnalités fonctionnelles de FabricInsight, il convient d'expliquer les changements intervenus dans le modèle commercial de distribution des produits réseau Huawei. Si le nombre de commutateurs n'atteint pas des centaines, cette option est classée en édition autonome et implique une licence N1. Un cluster de trois serveurs ou plus est déjà fourni avec une plate-forme d'analyse Big Data. La solution Advanced, qui comprend plusieurs centaines de commutateurs, est recommandée pour être associée à des outils d'analyse des flux réseau. Les trois options autorisent les capacités FabricInsight avec une licence N1.
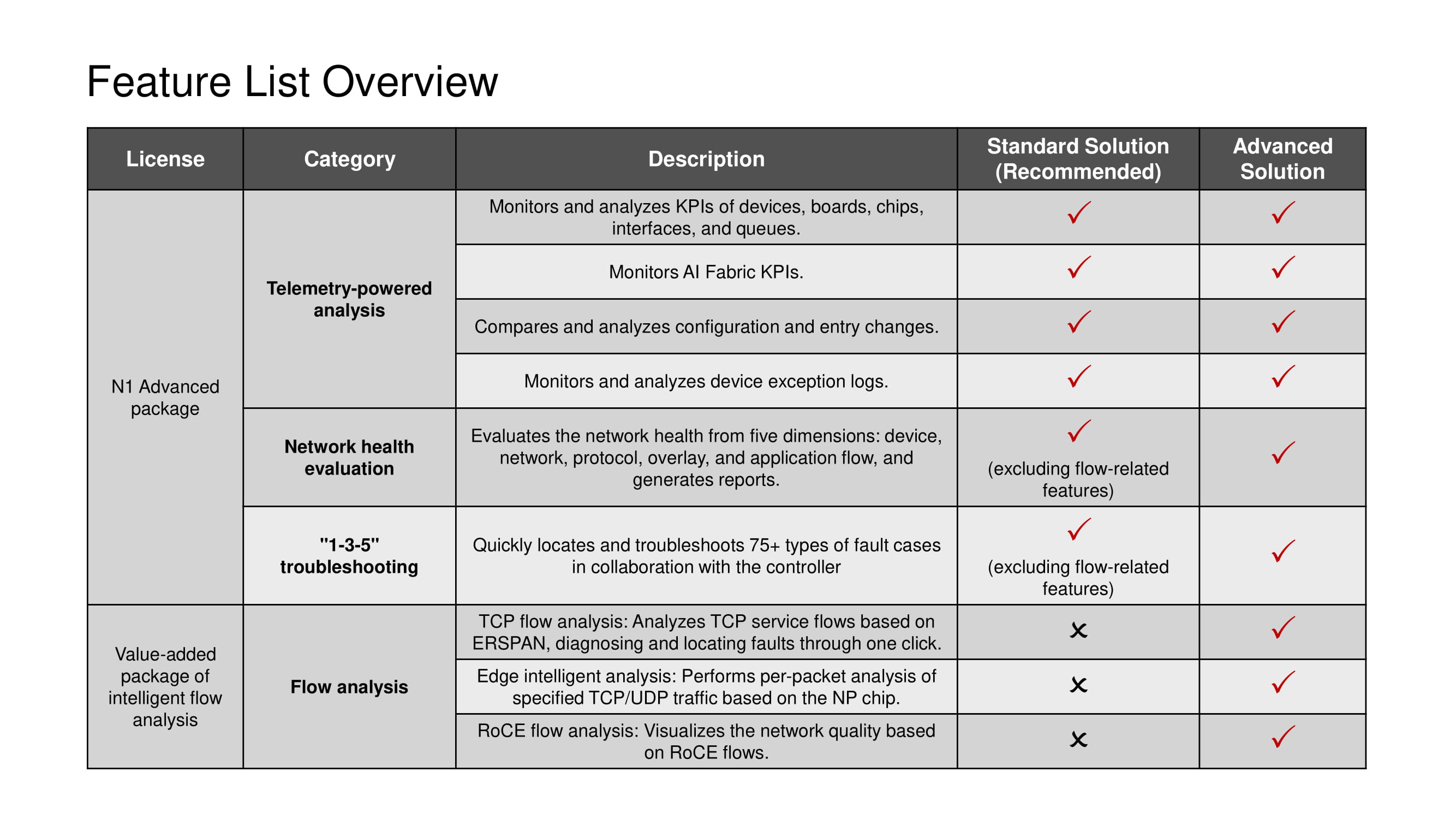
Toute licence implique l'utilisation de l'ensemble complet des outils de télémétrie et des scénarios 1-3-5, à l'exception des outils d'analyse de flux TCP disponibles uniquement dans la solution Advanced.
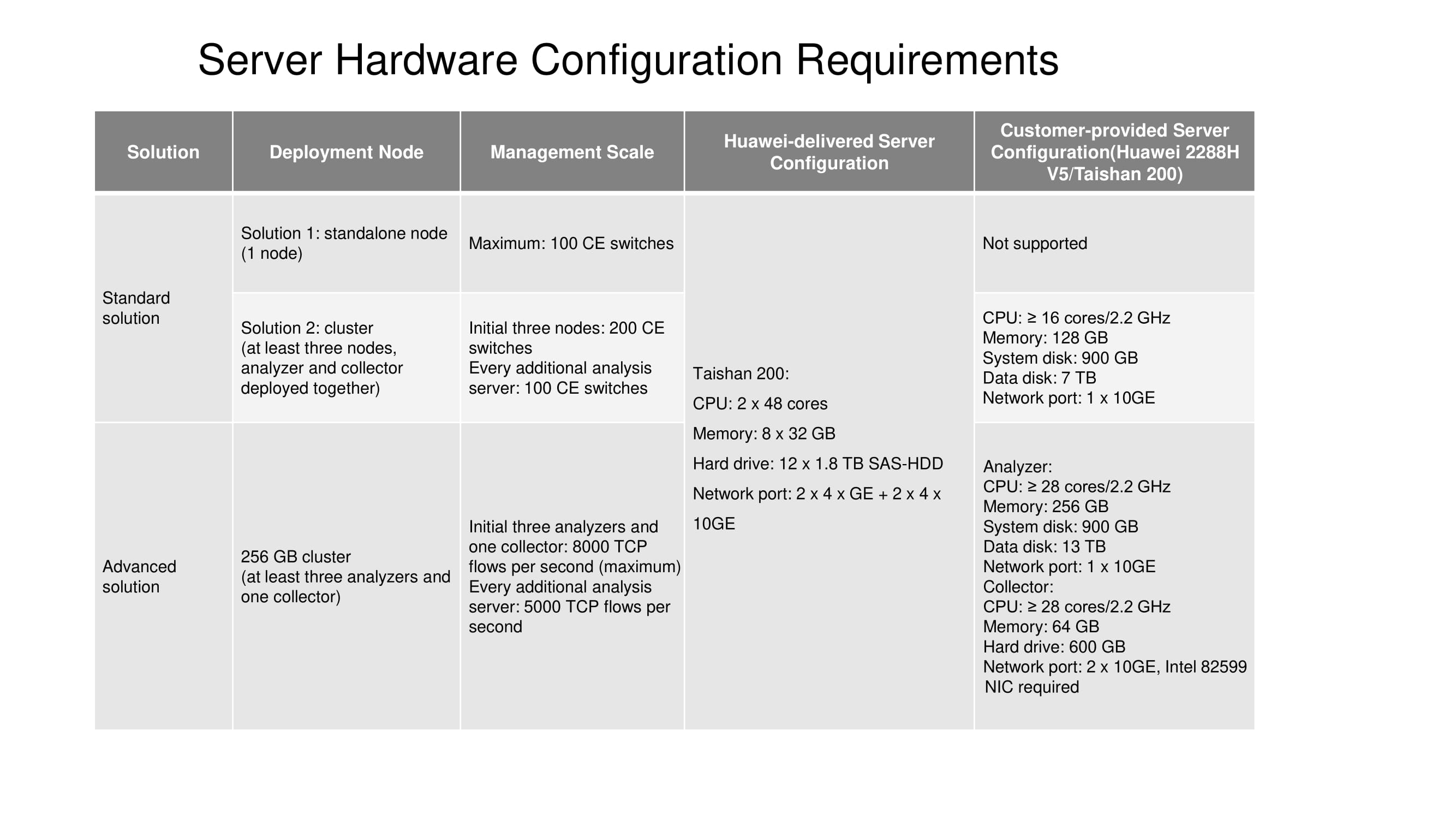
Il reste à vous parler des configurations de serveur conçues pour les solutions Standard et Avancées. Actuellement, un nœud autonome (un nœud) n'est disponible que sur le serveur Taishan 200. Un cluster à trois nœuds nécessite au moins 16 cœurs de calcul, 128 Go de RAM, etc. (voir schéma). La taille du disque de données dépend directement de la durée pendant laquelle les statistiques doivent être stockées.

Surveillance des KPI
Examinons de plus près la surveillance des KPI. Pour l'utiliser, il suffit de définir un intervalle de temps et des valeurs de seuil spécifiques, dont la réalisation sera vérifiée en fonction des données de télémétrie reçues. Il existe de nombreux types de métriques disponibles, notamment:
- Utilisation du processeur et de la mémoire;
- utilisation de FIB / MAC;
- utilisation de la mémoire associative ternaire (TCAM) de la puce;
- paramètres de port;
- la taille du tampon de la file d'attente;
- différentes métriques AI Fabric;
- niveau de signal, température et autres paramètres du module optique;
- perte de paquets.
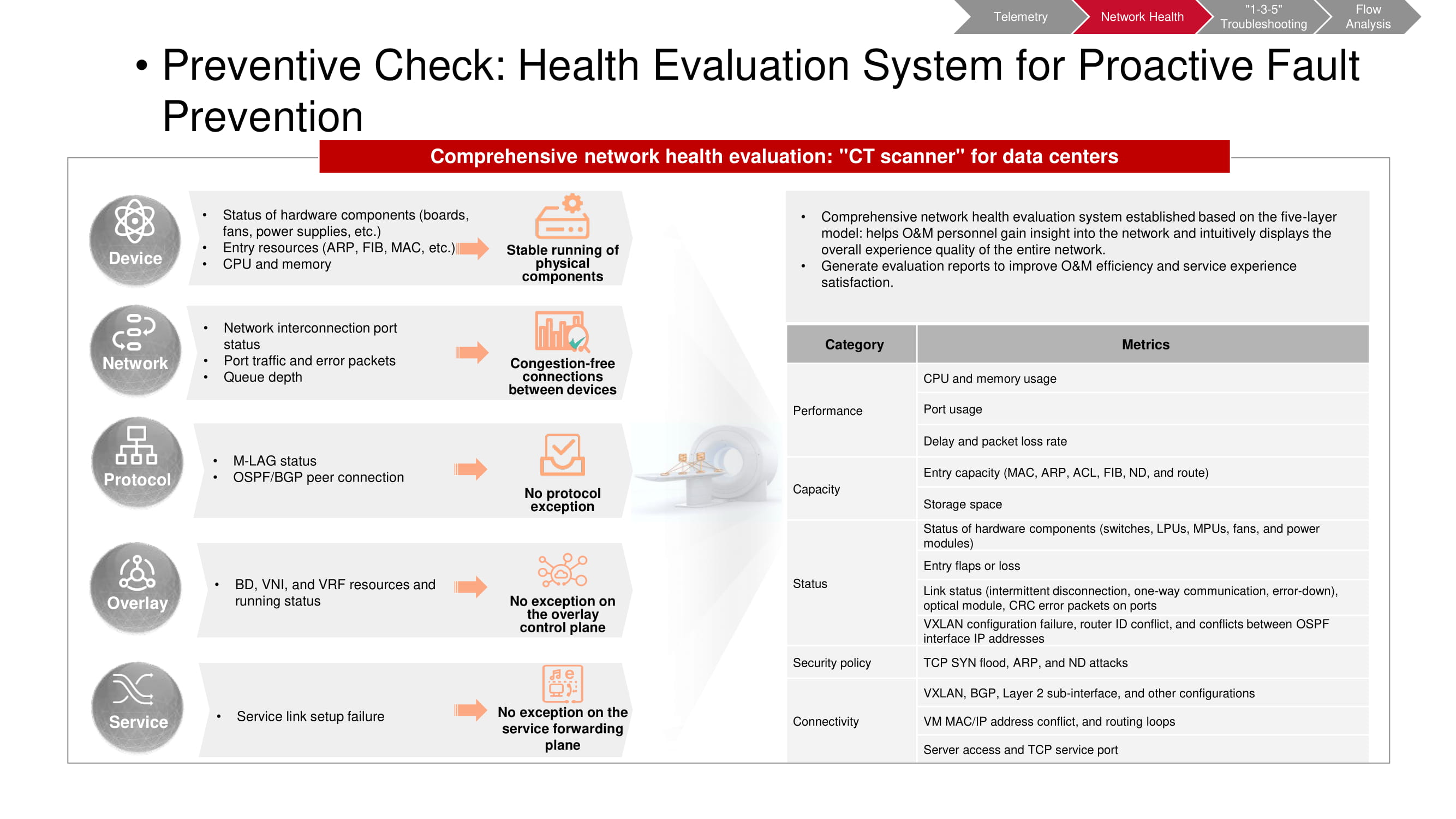
Contrôle préliminaire
L'outil de pré-validation fonctionne également sur les données de télémétrie. Le scanner CT vous permet de comprendre si certains événements indésirables se sont produits sur le réseau. Certaines métriques coïncident avec les métriques de surveillance des KPI de «l'usine» (principalement liées à la capacité et aux performances). Le reste est basé sur les résultats de l'analyse de haut niveau (VXLAN, BGP, etc.) et de l'analyse de configuration. Après avoir démarré le scanner CT, il recueille les informations nécessaires et génère un rapport complet sur l'état du réseau.
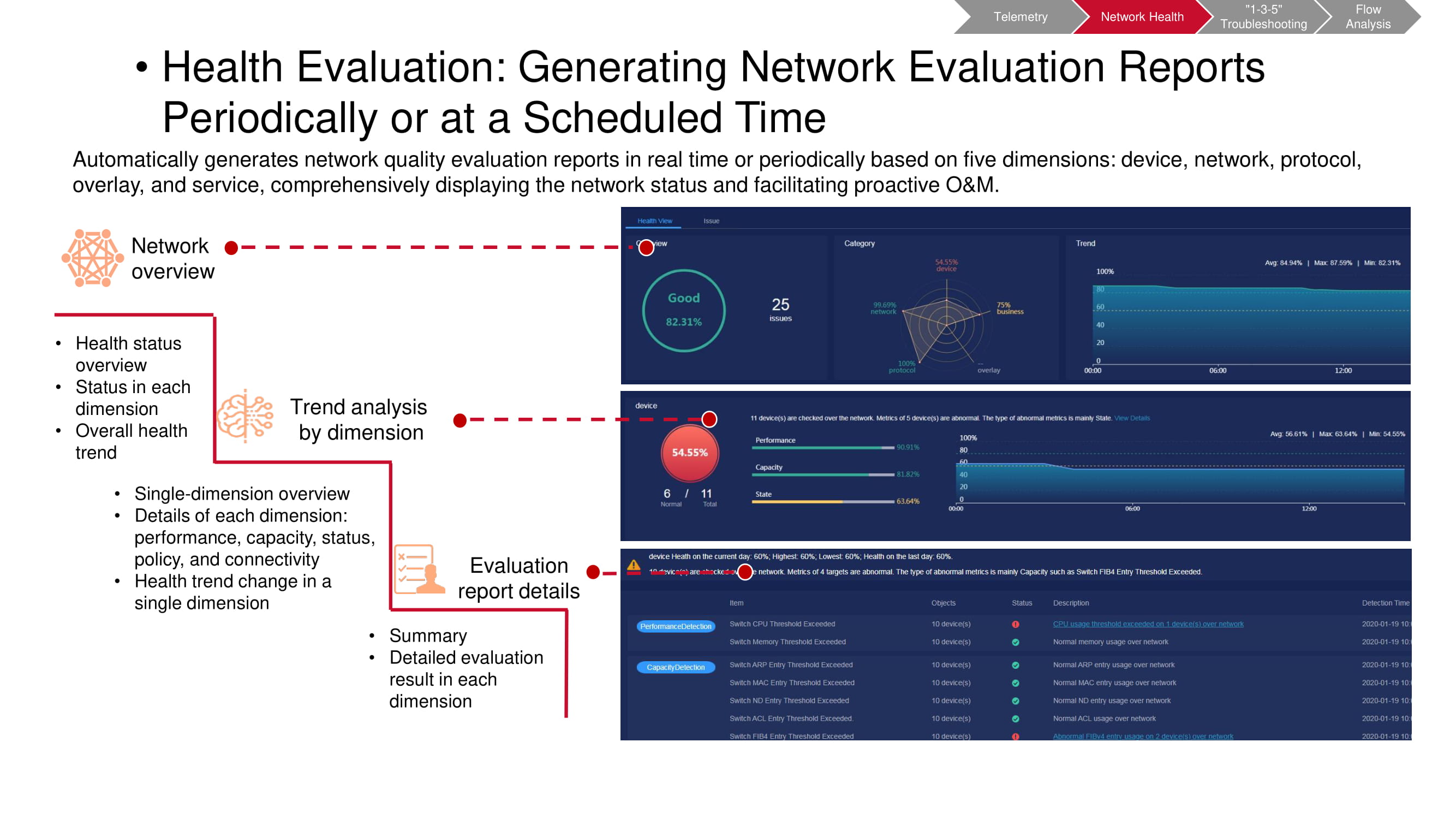
Il est nécessaire d'effectuer de tels contrôles régulièrement, après avoir prédéterminé les intervalles de temps entre eux. Cela permet de repérer plus facilement les tendances émergentes dans le réseau à temps, y compris les changements périodiques et non périodiques. Cela vous permet de comprendre beaucoup plus complètement et rapidement ce qui se passe exactement. De plus, tout paramètre présentant un intérêt particulier peut être sélectionné pour un suivi plus détaillé.
Problèmes de périphérique
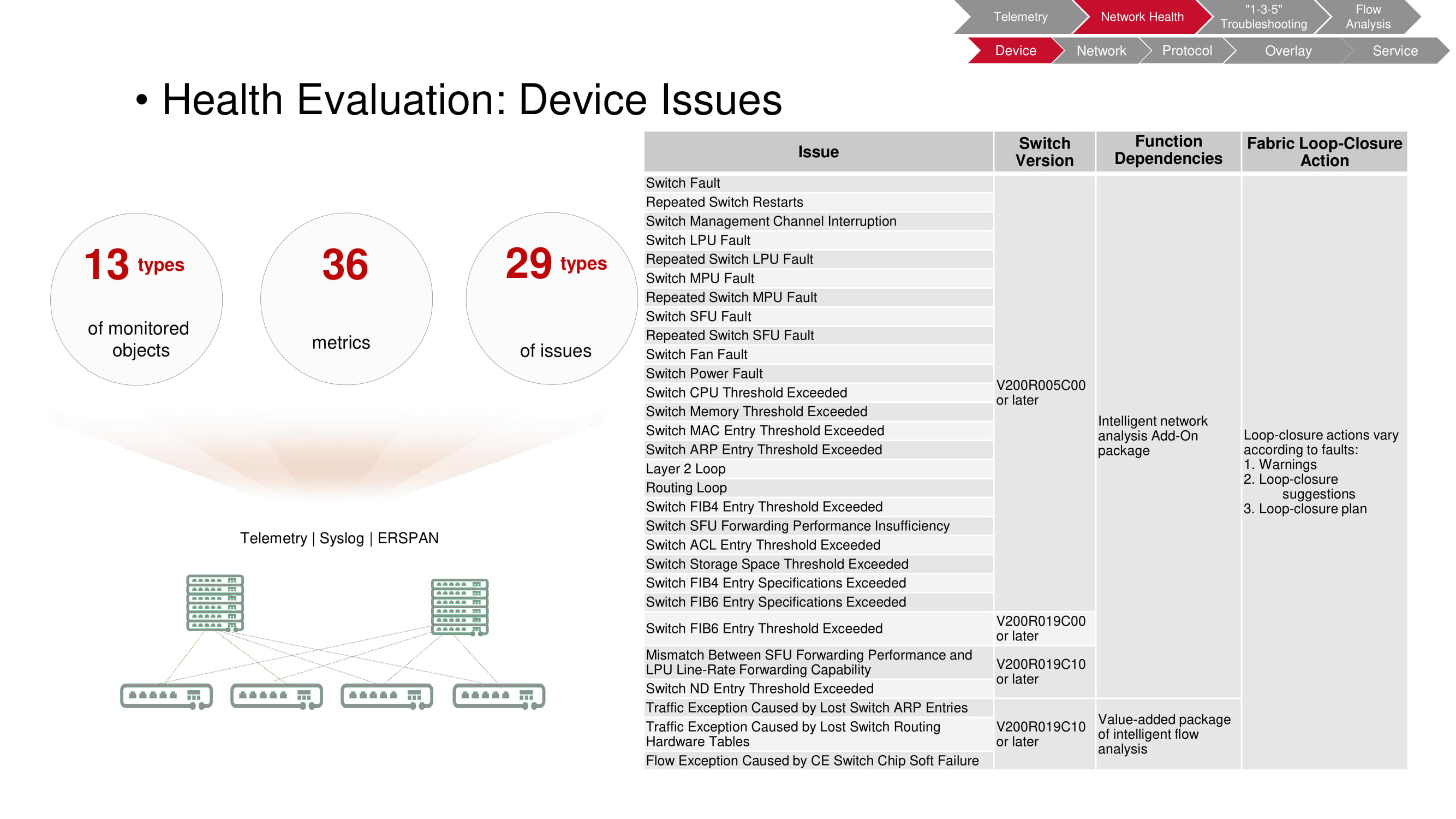
La surveillance vous permet d'identifier une grande variété de problèmes qui surviennent au niveau de l'appareil. Dans ce cas, l'objet de la vérification est un interrupteur dont 36 des paramètres de fonctionnement enregistrés permettent de détecter 29 types de défauts.
Le tableau sur le diagramme répertorie les types de défauts; changer de modèle qui permet à FabricInsight de détecter le problème; fonctions utilisées par FabricInsight; actions automatiques prises lorsque des problèmes sont détectés (avertissements, recommandations, lancement de script).
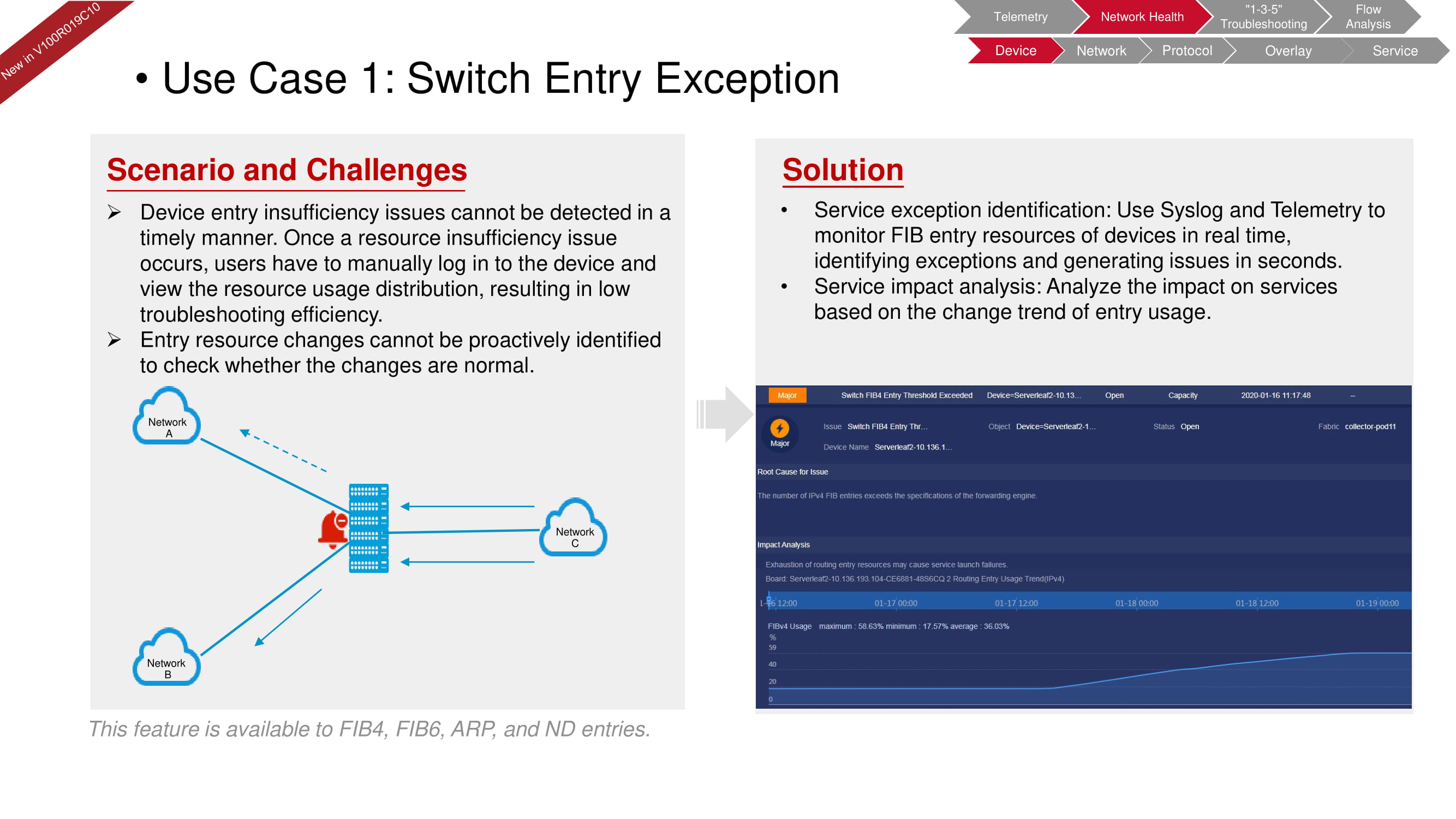
Disons que l'appareil a un manque de ressources conduisant à une baisse du niveau de service. Les données du journal système, associées aux données de télémétrie des ressources FIB, vous permettent d'évaluer rapidement la situation en mode de vérification manuelle.
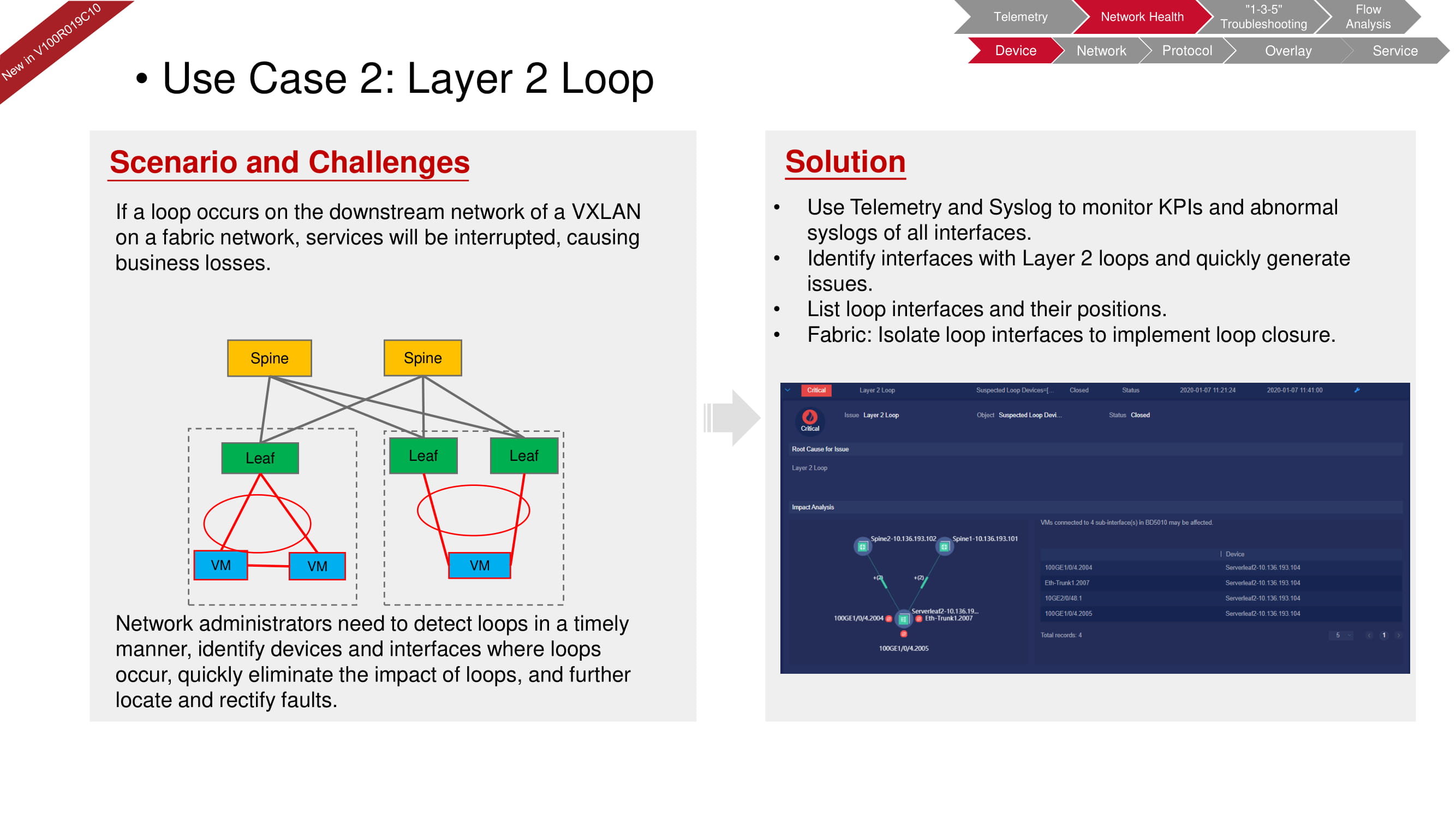
Il n'est tout simplement pas possible qu'une boucle se produise au niveau matériel, car le périphérique ne permettra pas qu'une telle erreur soit introduite dans la configuration. Cependant, une boucle peut se produire, par exemple, au deuxième niveau (au niveau de la machine virtuelle) en raison d'un commutateur logiciel mal configuré, comme dans le schéma ci-dessus. Avec FabricInsight, vous pouvez non seulement détecter un problème, mais également isoler la section souhaitée du réseau pour éliminer son impact sur le fonctionnement de l'ensemble de la «structure».

Problèmes de réseau
Sur la base de 18 métriques disponibles pour l'analyse, FabricInsight identifie 10 types de problèmes de réseau. Le diagramme fournit une liste complète d'entre eux, ainsi que - comme dans le cas de problèmes de périphérique - les modèles de commutateurs qui permettent à FabricInsight de détecter le problème, les fonctions utilisées et les actions automatiques disponibles.

Supposons que la dégradation ou le dysfonctionnement d'un module optique entraîne une détérioration de ses performances: la liaison devient instable. Ces situations se produisent de manière irrégulière et sont difficiles à reproduire. Cela peut prendre beaucoup de temps pour trouver le problème. Avec FabricInsight, vous pouvez immédiatement remarquer une baisse du niveau du signal ou un changement de tension à travers un module.
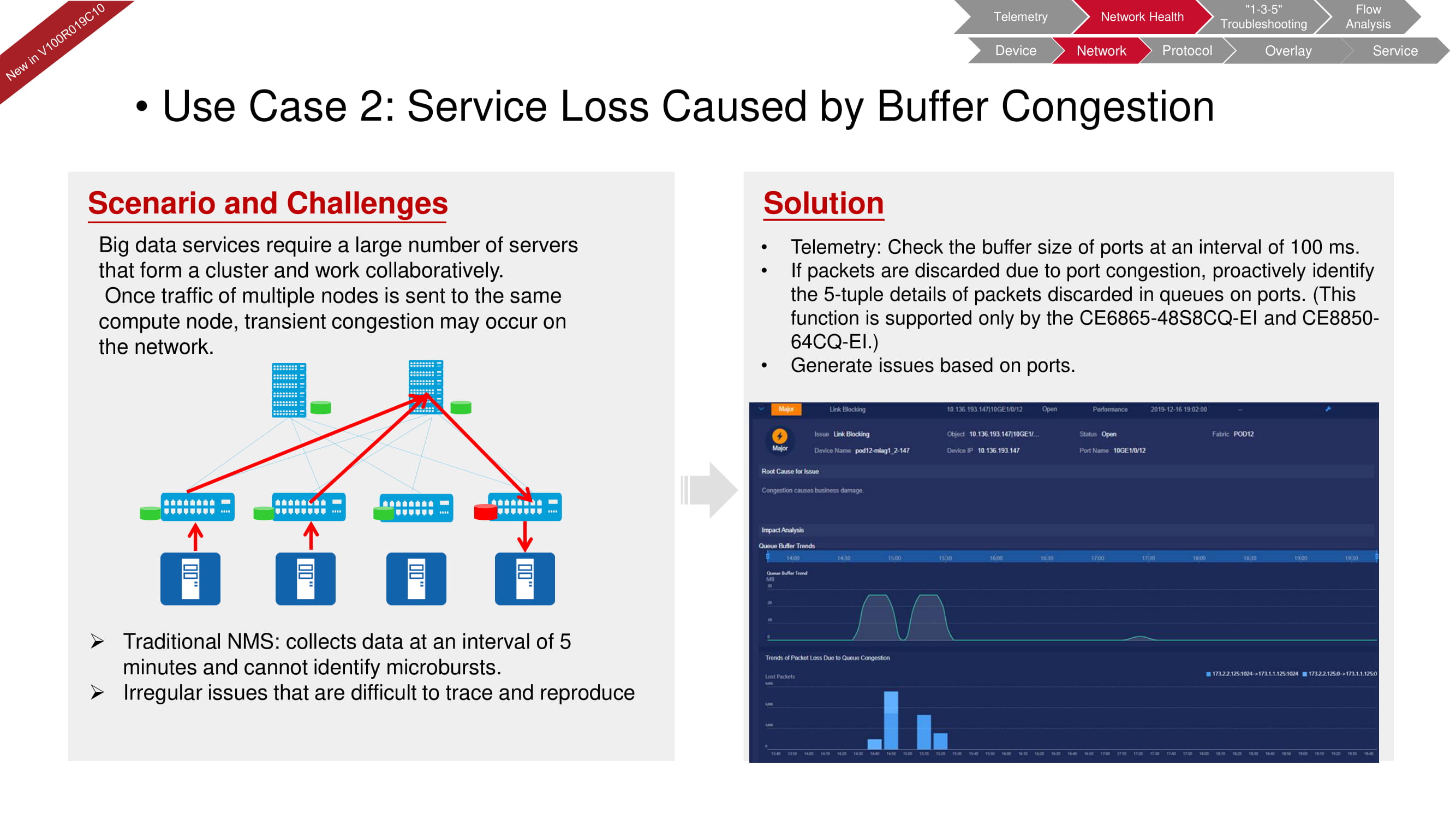
Les diagnostics de réseau FabricInsight peuvent également identifier rapidement les problèmes de tampon qui se produisent souvent dans les systèmes avec un grand nombre de serveurs dédiés au traitement du Big Data. Le NMS (Network Management System) traditionnel vérifie les paramètres liés à la mémoire tampon toutes les cinq minutes. Les capacités de télémétrie FabricInsight peuvent réduire ces intervalles à 100 ms et détecter même les micro-incidents les plus courts.

Problèmes au niveau du protocole
Ici, FabricInsight peut identifier six types de problèmes, y compris un conflit entre deux commutateurs principaux dans le M-LAG; problèmes d'interaction avec les commutateurs voisins, etc. Cette fonctionnalité est disponible lors de l'utilisation des commutateurs V200R005C00 et plus récents.

Considérez le conflit des commutateurs principaux. Avec tous les avantages de la technologie M-LAG, en cas de rupture de liaison et de panne de réseau peer-to-peer, deux commutateurs maîtres apparaissent dans le système. FabricInsight est capable de réagir de manière proactive à une telle situation en surveillant en permanence l'état du peer-link et du DFS.

Superposer les problèmes de réseau
Sept types de problèmes de réseau de superposition peuvent être identifiés en surveillant dix mesures différentes. FabricInsight peut vérifier l'état de la licence VXLAN, trouver des erreurs de configuration, détecter les pannes de sous-interface, etc. Les options de réponse sont similaires à celles décrites précédemment.

Problèmes de service
Sept mesures sont surveillées pour identifier six types de problèmes de niveau de service. Des conflits d'adresses IP, des problèmes de connexion, des attaques TCP SYN flood, etc. peuvent être détectés. Veuillez noter que pour prendre en charge ces fonctionnalités de FabricInsight, vous aurez peut-être besoin d'un analyseur de flux TCP.
En adoptant une vision plus large du dépannage, FabricInsight est plus qu'un simple collecteur de périphériques, mais une bibliothèque extensible de scripts qui répondent à une grande variété de types de problèmes.

De l'automatisation à l'autonomie
En résumé, nous dirons que l'idéologie du réseau axé sur l'intention est basée sur un modèle de réponse en trois étapes, qui comprend la collecte d'informations, son analyse à l'aide de l'IA et des propositions de changement d'état du réseau, y compris en mode automatique.
***
Nous vous rappelons que nos experts organisent régulièrement des webinaires sur les produits Huawei et les technologies qu'ils utilisent. Une liste des webinaires pour les semaines à venir est disponible ici .