Mais le travail du Data Scientist est lié aux données, et l'un des moments les plus importants et les plus chronophages est le traitement des données avant de les soumettre à un réseau de neurones ou de les analyser d'une certaine manière.
Dans cet article, notre équipe décrira comment vous pouvez traiter rapidement et facilement les données avec des instructions et du code étape par étape. Nous avons essayé de rendre le code suffisamment flexible pour être appliqué à différents ensembles de données.
De nombreux professionnels ne trouveront peut-être rien d'extraordinaire dans cet article, mais les débutants pourront apprendre quelque chose de nouveau, et quiconque rêvait depuis longtemps de créer un cahier séparé pour un traitement rapide et structuré des données peut copier le code et le formater pour lui-même, ou en télécharger un prêt à l'emploi. cahier de Github.
Nous avons un ensemble de données. Que faire ensuite?
Donc, la norme: vous devez comprendre ce à quoi nous avons affaire, la vue d'ensemble. Nous utiliserons des pandas pour ce faire afin de définir simplement différents types de données.
import pandas as pd # pandas
import numpy as np # numpy
df = pd.read_csv("AB_NYC_2019.csv") # df
df.head(3) # 3 , , 
df.info() # 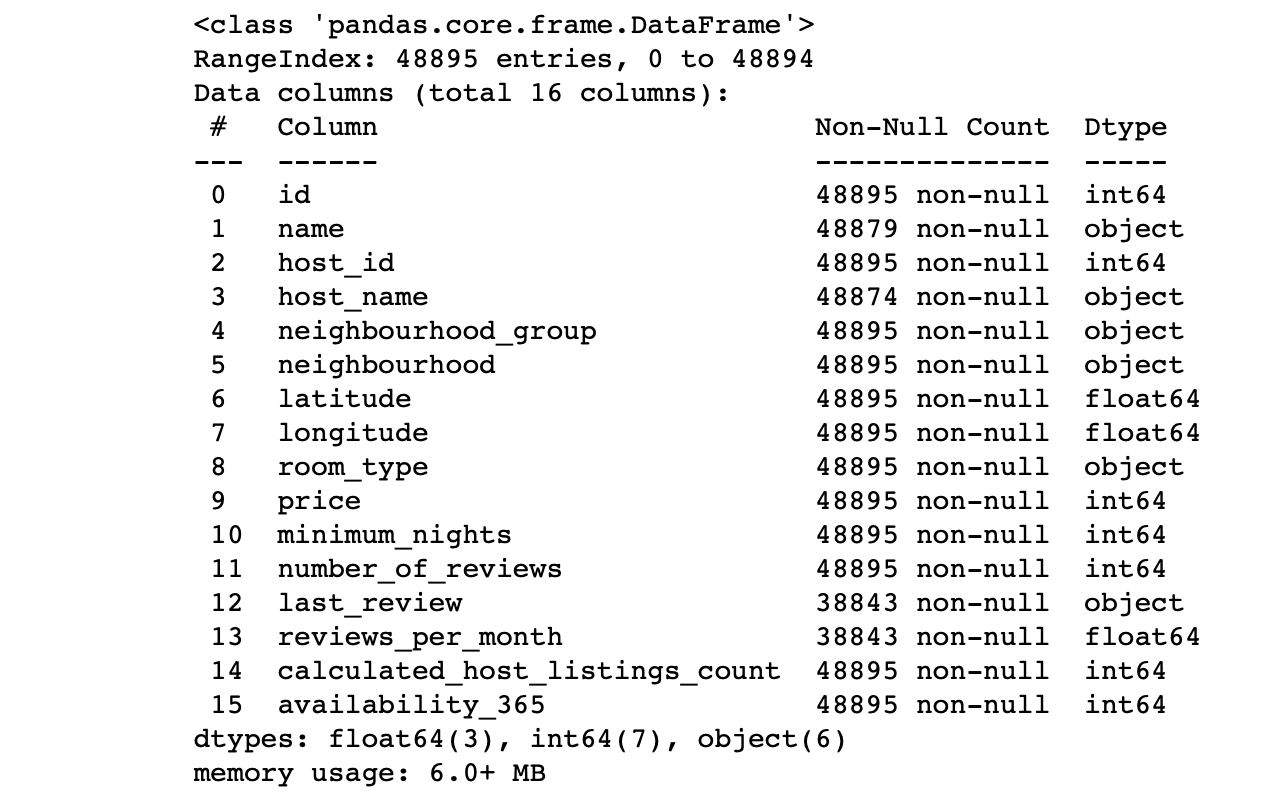
Nous regardons les valeurs des colonnes:
- Le nombre de lignes dans chaque colonne correspond-il au nombre total de lignes?
- Quelle est l'essence des données de chaque colonne?
- Pour quelle colonne voulons-nous que la cible fasse des prédictions?
Les réponses à ces questions vous permettront d'analyser l'ensemble de données et de dessiner grossièrement un plan pour les prochaines étapes.
De plus, pour un examen plus approfondi des valeurs de chaque colonne, nous pouvons utiliser la fonction pandas describe (). Cependant, l'inconvénient de cette fonction est qu'elle ne fournit pas d'informations sur les colonnes avec des valeurs de chaîne. Nous les traiterons plus tard.
df.describe()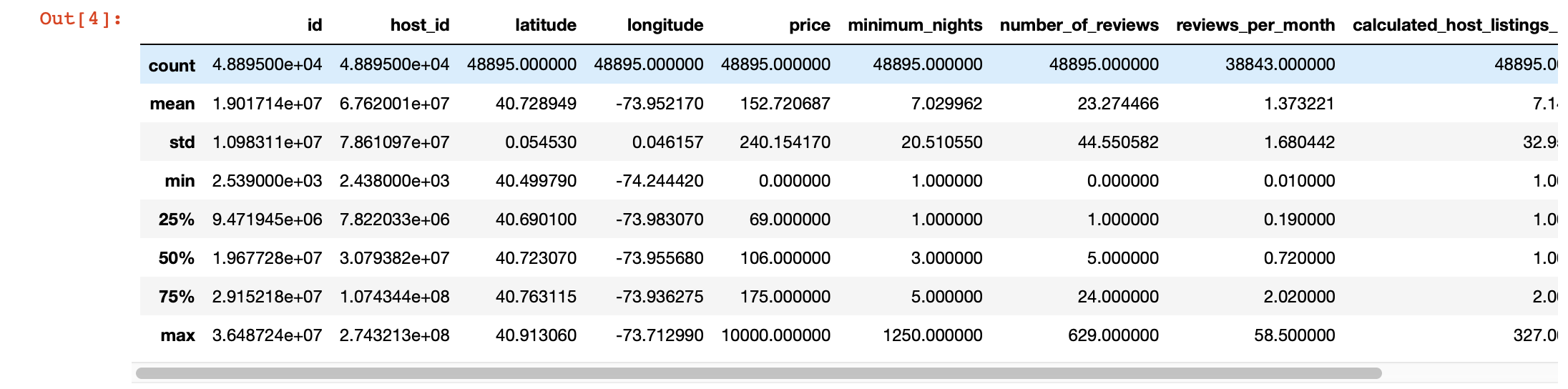
Visualisation magique
Regardons là où nous n'avons aucune valeur du tout:
import seaborn as sns
sns.heatmap(df.isnull(),yticklabels=False,cbar=False,cmap='viridis')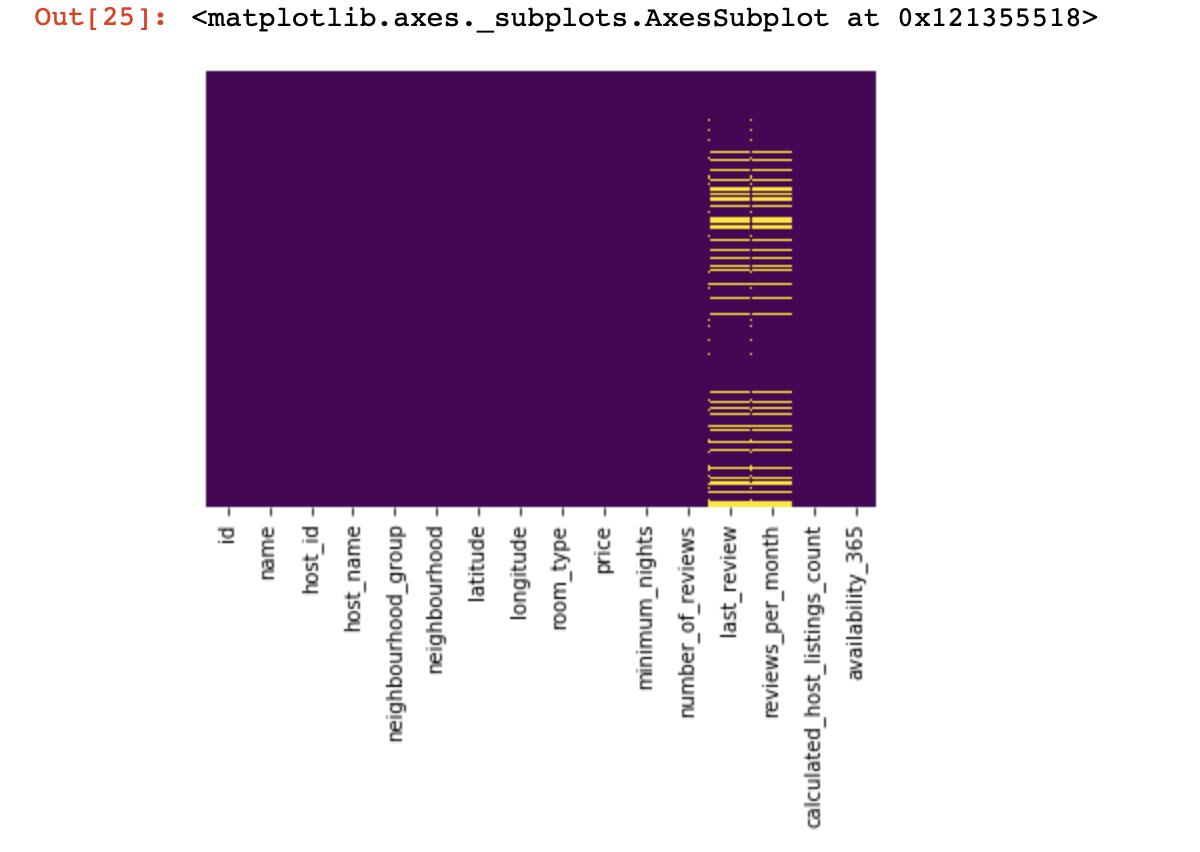
C'était un petit coup d'œil d'en haut, maintenant nous allons passer à des choses plus intéressantes.Essayons
de trouver et, si possible, de supprimer les colonnes qui n'ont qu'une seule valeur dans toutes les lignes (elles n'affecteront en rien le résultat):
df = df[[c for c
in list(df)
if len(df[c].unique()) > 1]] # , , Désormais, nous nous protégeons et la réussite de notre projet des lignes dupliquées (lignes qui contiennent les mêmes informations dans le même ordre que l'une des lignes existantes):
df.drop_duplicates(inplace=True) # , .
# .Nous divisons l'ensemble de données en deux: l'un avec des valeurs qualitatives et l'autre avec des valeurs quantitatives
Ici, nous devons apporter une petite clarification: si les lignes avec des données manquantes dans les données qualitatives et quantitatives ne sont pas fortement corrélées les unes aux autres, il sera alors nécessaire de prendre une décision sur ce que nous sacrifions - toutes les lignes avec des données manquantes, seulement une partie d'entre elles ou certaines colonnes. Si les lignes sont liées, nous avons le droit de diviser l'ensemble de données en deux. Sinon, vous devrez d'abord traiter les lignes qui ne corrèlent pas les données manquantes en termes qualitatifs et quantitatifs, puis diviser ensuite l'ensemble de données en deux.
df_numerical = df.select_dtypes(include = [np.number])
df_categorical = df.select_dtypes(exclude = [np.number])Nous faisons cela pour nous faciliter le traitement de ces deux types de données - plus tard, nous comprendrons à quel point cela simplifie notre vie.
Nous travaillons avec des données quantitatives
La première chose que nous devons faire est de déterminer s'il existe des «colonnes d'espionnage» dans les données quantitatives. Nous appelons ces colonnes ainsi parce qu'elles prétendent être des données quantitatives et qu'elles fonctionnent elles-mêmes comme des données qualitatives.
Comment les définissons-nous? Bien sûr, tout dépend de la nature des données que vous analysez, mais en général, ces colonnes peuvent avoir peu de données uniques (dans la région de 3 à 10 valeurs uniques).
print(df_numerical.nunique())Après avoir défini les colonnes d'espionnage, nous les déplacerons des données quantitatives aux données qualitatives:
spy_columns = df_numerical[['1', '2', '3']]# - dataframe
df_numerical.drop(labels=['1', '2', '3'], axis=1, inplace = True)#
df_categorical.insert(1, '1', spy_columns['1']) # -
df_categorical.insert(1, '2', spy_columns['2']) # -
df_categorical.insert(1, '3', spy_columns['3']) # - Enfin, nous avons complètement séparé les données quantitatives des données qualitatives et vous pouvez désormais les utiliser correctement. Le premier est de comprendre où nous avons des valeurs vides (NaN, et dans certains cas 0 sera considéré comme des valeurs vides).
for i in df_numerical.columns:
print(i, df[i][df[i]==0].count())À ce stade, il est important de comprendre dans quelles colonnes les zéros peuvent signifier des valeurs manquantes: est-ce lié à la manière dont les données ont été collectées? Ou pourrait-il être lié à des valeurs de données? Ces questions doivent être répondues au cas par cas.
Donc, si nous décidons néanmoins de ne pas avoir de données où il y a des zéros, nous devrions remplacer les zéros par NaN, afin qu'il soit plus facile de travailler avec ces données perdues plus tard:
df_numerical[[" 1", " 2"]] = df_numerical[[" 1", " 2"]].replace(0, nan)Voyons maintenant où nous avons des données manquantes:
sns.heatmap(df_numerical.isnull(),yticklabels=False,cbar=False,cmap='viridis') # df_numerical.info()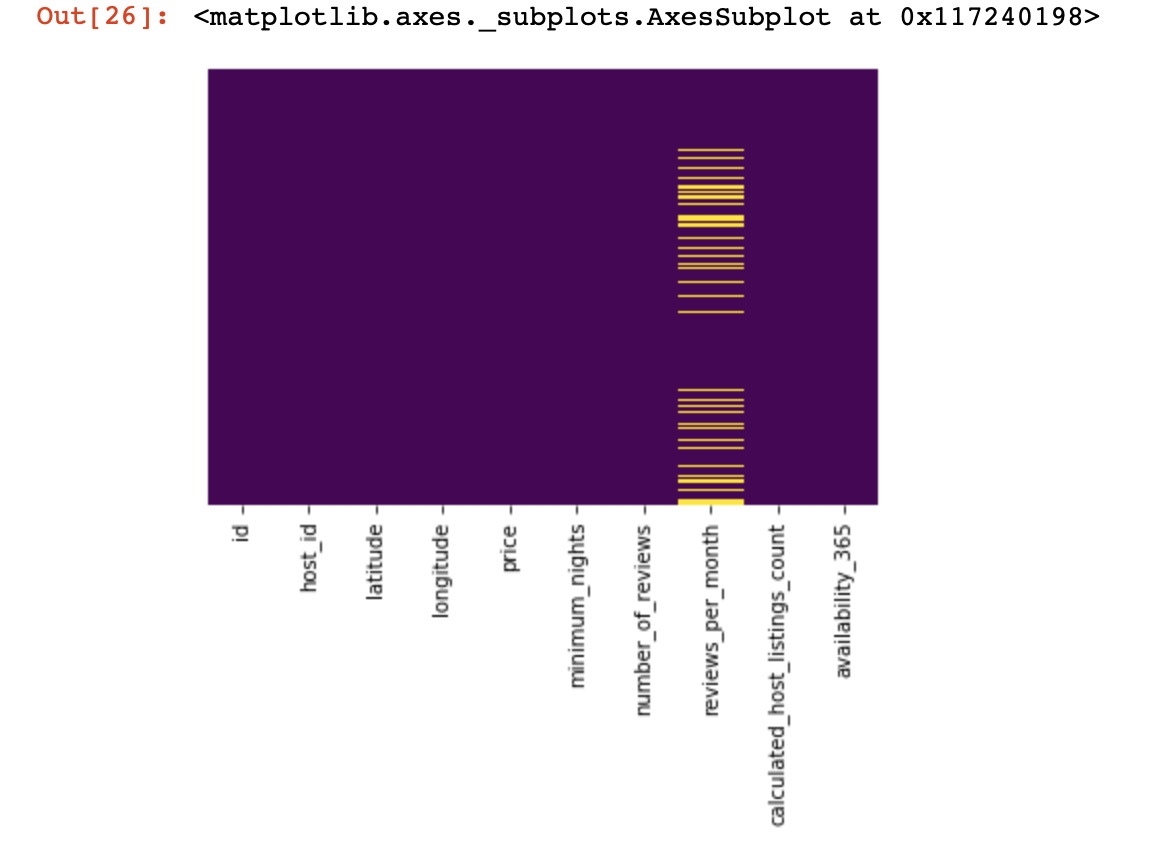
Ici, les valeurs manquantes dans les colonnes doivent être marquées en jaune. Et le plaisir commence maintenant - comment se comporter avec ces valeurs? Supprimer les lignes avec ces valeurs ou colonnes? Ou remplir ces valeurs vides avec d'autres?
Voici un diagramme approximatif qui peut vous aider à décider ce que vous pouvez faire essentiellement avec des valeurs vides:
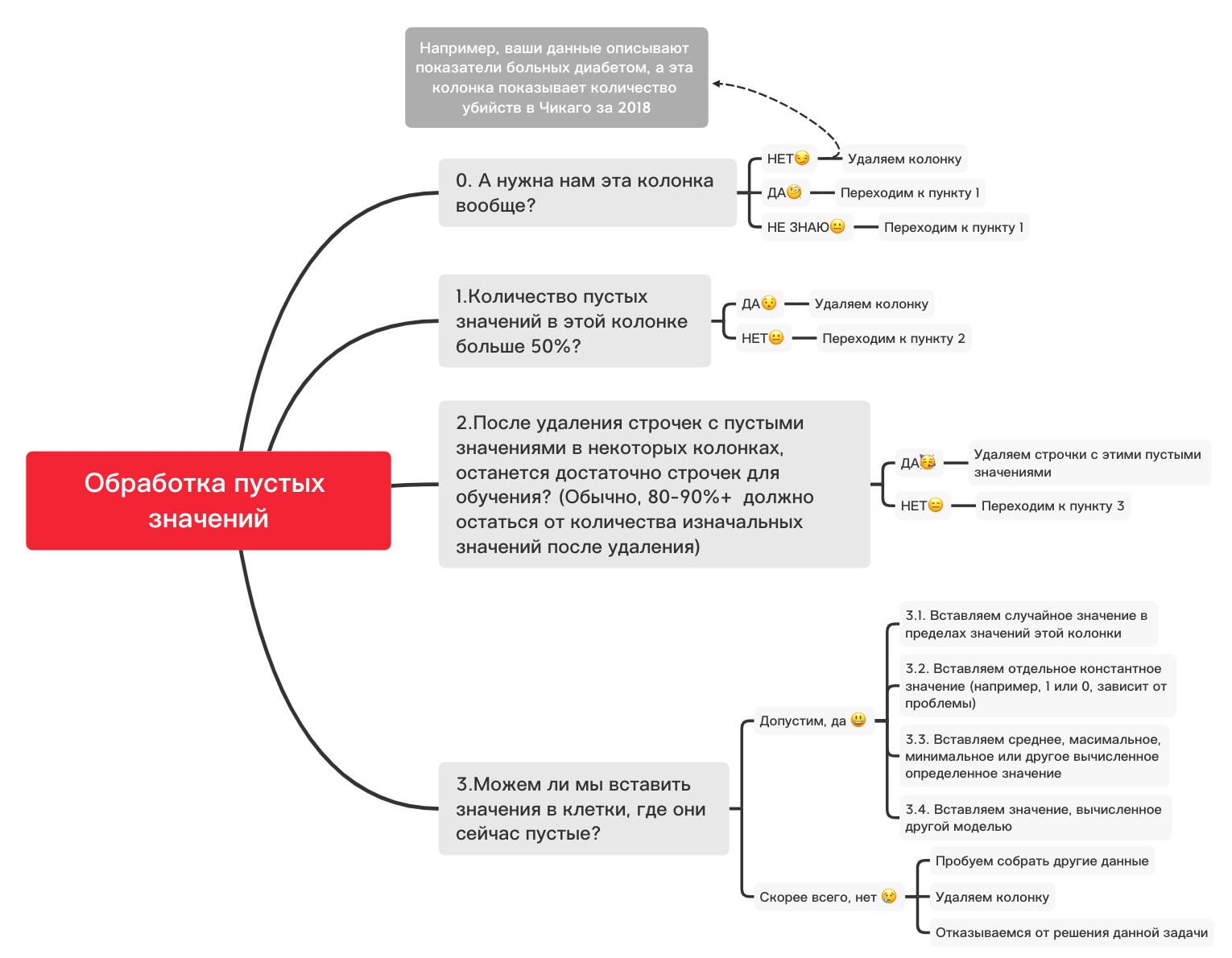
0. Supprimez les colonnes inutiles
df_numerical.drop(labels=["1","2"], axis=1, inplace=True)1. Y a-t-il plus de 50% de valeurs vides dans cette colonne?
print(df_numerical.isnull().sum() / df_numerical.shape[0] * 100)df_numerical.drop(labels=["1","2"], axis=1, inplace=True)#, - 50 2. Supprimer les lignes avec des valeurs vides
df_numerical.dropna(inplace=True)# , 3.1. Insérer une valeur aléatoire
import random # random
df_numerical[""].fillna(lambda x: random.choice(df[df[column] != np.nan][""]), inplace=True) # 3.2. Insérer une valeur constante
from sklearn.impute import SimpleImputer # SimpleImputer,
imputer = SimpleImputer(strategy='constant', fill_value="< >") # SimpleImputer
df_numerical[["_1",'_2','_3']] = imputer.fit_transform(df_numerical[['1', '2', '3']]) #
df_numerical.drop(labels = ["1","2","3"], axis = 1, inplace = True) # 3.3. Insérez la valeur moyenne ou la valeur la plus fréquente
from sklearn.impute import SimpleImputer # SimpleImputer,
imputer = SimpleImputer(strategy='mean', missing_values = np.nan) # mean most_frequent
df_numerical[["_1",'_2','_3']] = imputer.fit_transform(df_numerical[['1', '2', '3']]) #
df_numerical.drop(labels = ["1","2","3"], axis = 1, inplace = True) # 3.4. Insertion d'une valeur calculée par un autre modèle
Parfois, les valeurs peuvent être calculées à l'aide de modèles de régression à l'aide de modèles de la bibliothèque sklearn ou d'autres bibliothèques similaires. Notre équipe consacrera un article séparé sur la manière dont cela peut être fait dans un proche avenir.
Ainsi, alors que le récit sur les données quantitatives sera interrompu, car il existe de nombreuses autres nuances sur la façon de mieux faire la préparation et le prétraitement des données pour différentes tâches, et les éléments de base pour les données quantitatives ont été pris en compte dans cet article, et il est maintenant temps de revenir aux données qualitatives. que nous avons séparé quelques pas du quantitatif. Vous pouvez changer ce bloc-notes à votre guise, en l'ajustant pour différentes tâches, de sorte que le prétraitement des données se fasse très rapidement!
Données qualitatives
Fondamentalement, pour les données de qualité, la méthode One-hot-encoding est utilisée afin de les formater d'une chaîne (ou d'un objet) à un nombre. Avant de passer à ce point, utilisons le diagramme et le code ci-dessus pour traiter les valeurs vides.
df_categorical.nunique()sns.heatmap(df_categorical.isnull(),yticklabels=False,cbar=False,cmap='viridis')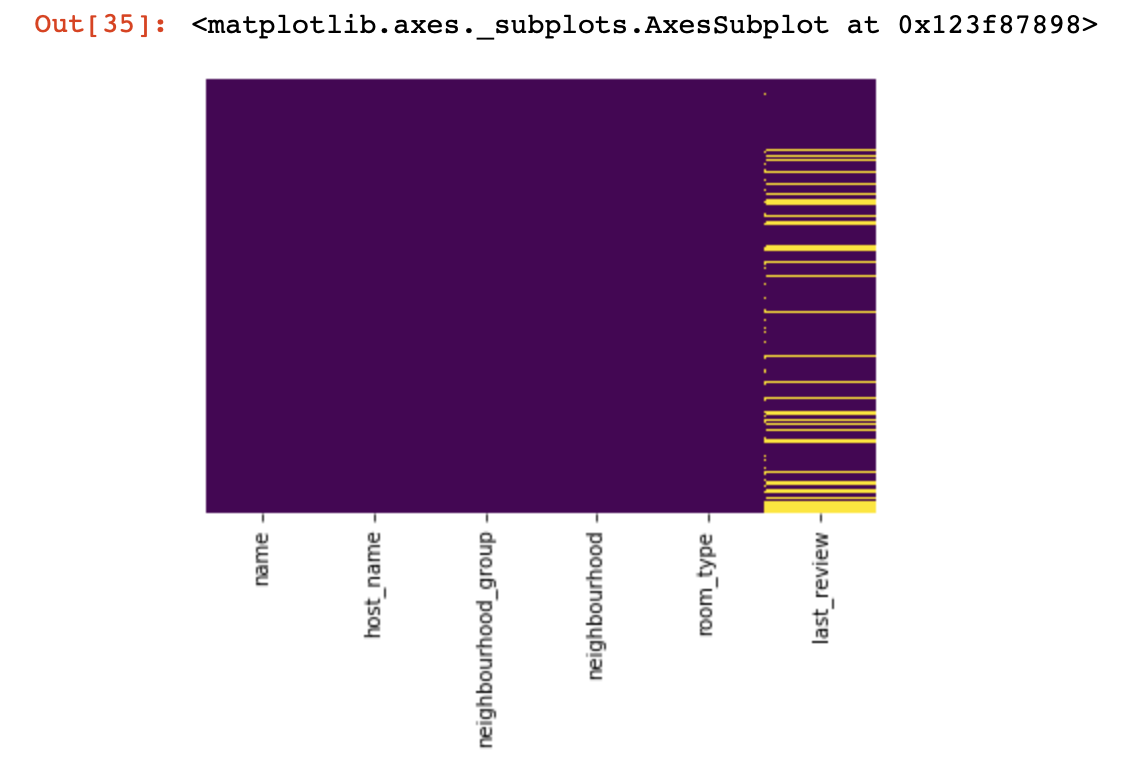
0. Suppression des colonnes inutiles
df_categorical.drop(labels=["1","2"], axis=1, inplace=True)1. Y a-t-il plus de 50% de valeurs vides dans cette colonne?
print(df_categorical.isnull().sum() / df_numerical.shape[0] * 100)df_categorical.drop(labels=["1","2"], axis=1, inplace=True) #, -
# 50% 2. Supprimer les lignes avec des valeurs vides
df_categorical.dropna(inplace=True)# ,
# 3.1. Insérer une valeur aléatoire
import random
df_categorical[""].fillna(lambda x: random.choice(df[df[column] != np.nan][""]), inplace=True)3.2. Insérer une valeur constante
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='constant', fill_value="< >")
df_categorical[["_1",'_2','_3']] = imputer.fit_transform(df_categorical[['1', '2', '3']])
df_categorical.drop(labels = ["1","2","3"], axis = 1, inplace = True)Donc, enfin, nous avons traité des valeurs vides dans les données de qualité. Il est maintenant temps d'encoder à chaud les valeurs qui se trouvent dans votre base de données. Cette méthode est très souvent utilisée pour s'assurer que votre algorithme peut s'entraîner avec des données de qualité.
def encode_and_bind(original_dataframe, feature_to_encode):
dummies = pd.get_dummies(original_dataframe[[feature_to_encode]])
res = pd.concat([original_dataframe, dummies], axis=1)
res = res.drop([feature_to_encode], axis=1)
return(res)features_to_encode = ["1","2","3"]
for feature in features_to_encode:
df_categorical = encode_and_bind(df_categorical, feature))Donc, enfin, nous avons fini de traiter séparément les données qualitatives et quantitatives - il est temps de les combiner
new_df = pd.concat([df_numerical,df_categorical], axis=1)Après avoir fusionné les ensembles de données en un seul, nous pouvons à la fin utiliser la transformation de données à l'aide de MinMaxScaler de la bibliothèque sklearn. Cela rendra nos valeurs comprises entre 0 et 1, ce qui aidera lors de la formation du modèle à l'avenir.
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
new_df = min_max_scaler.fit_transform(new_df)Ces données sont désormais prêtes à tout - pour les réseaux de neurones, les algorithmes de ML standard, et ainsi de suite!
Dans cet article, nous n'avons pas pris en compte le travail avec des données liées aux séries chronologiques, car pour de telles données, vous devez utiliser des techniques de traitement légèrement différentes, en fonction de votre tâche. À l'avenir, notre équipe consacrera un article distinct à ce sujet, et nous espérons qu'elle pourra apporter quelque chose d'intéressant, de nouveau et d'utile dans votre vie, comme celui-ci.