Dans cet article, je vais vous parler des principales fonctions de BigQuery et montrer leurs capacités avec des exemples spécifiques. Vous pouvez écrire des requêtes de base et les essayer sur des données de démonstration.
Qu'est-ce que SQL et quels dialectes il a
SQL (Structured Query Language) est un langage de requête structuré pour travailler avec des bases de données. Avec son aide, vous pouvez recevoir, ajouter à la base de données et modifier de grandes quantités de données. Google BigQuery prend en charge deux dialectes: SQL standard et SQL hérité.
Le dialecte à choisir dépend de vos préférences, mais Google recommande d'utiliser Standard SQL en raison d'un certain nombre d'avantages:
- Flexibilité et fonctionnalité lors de l'utilisation de champs imbriqués et répétitifs.
- Prise en charge des langages DML et DDL , qui vous permettent de modifier les données dans les tables, ainsi que de manipuler les tables et les vues dans GBQ.
- Le traitement de grandes quantités de données est plus rapide que Legasy SQL.
- Prise en charge de toutes les mises à jour actuelles et futures de BigQuery.
Vous pouvez en savoir plus sur la différence entre les dialectes dans l' aide .
Par défaut, les requêtes Google BigQuery s'exécutent sur l'ancien SQL.
Il existe plusieurs façons de passer au SQL standard:
- Dans l'interface BigQuery, dans la fenêtre d'édition des requêtes, sélectionnez "Afficher les options" et décochez la case à côté de l'option "Utiliser l'ancien SQL".

- Ajoutez la ligne #standardSQL avant la requête et démarrez la requête sur une nouvelle ligne

Où commencer
Afin que vous puissiez vous entraîner à exécuter des requêtes en parallèle avec la lecture de l'article, j'ai préparé pour vous un tableau avec des données de démonstration . Chargez les données de la feuille de calcul dans votre projet Google BigQuery.
Si vous n'avez pas encore de projet GBQ, créez-en un. Pour ce faire, vous devez disposer d'un compte de facturation actif dans Google Cloud Platform . Vous devrez lier la carte, mais à votre insu, l'argent ne sera pas débité de celle-ci.De plus, lors de votre inscription, vous recevrez 300 $ pour 12 mois , que vous pourrez consacrer au stockage et au traitement des données.
Fonctionnalités de Google BigQuery
Les groupes de fonctions les plus couramment utilisés lors de la création de requêtes sont la fonction d'agrégation, la fonction de date, la fonction de chaîne et la fonction de fenêtre. Maintenant, plus sur chacun d'eux.
Fonction d'agrégation
Les fonctions d'agrégation vous permettent d'obtenir des valeurs récapitulatives sur l'ensemble du tableau. Par exemple, calculez le chèque moyen, le revenu mensuel total ou mettez en surbrillance le segment d'utilisateurs qui ont effectué le nombre maximal d'achats.
Voici les fonctionnalités les plus populaires de cette section:
| SQL hérité | SQL standard | Que fait la fonction |
|---|---|---|
| AVG (champ) | AVG ([DISTINCT] (champ)) | Renvoie la moyenne de la colonne de champ. En SQL standard, lors de l'ajout de la clause DISTINCT, la moyenne est calculée uniquement pour les lignes avec des valeurs uniques (non dupliquées) de la colonne de champ |
| MAX (champ) | MAX (champ) | Renvoie la valeur maximale de la colonne de champ |
| MIN (champ) | MIN (champ) | Renvoie la valeur minimale de la colonne de champ |
| SUM (champ) | SUM (champ) | Renvoie la somme des valeurs de la colonne de champ |
| COUNT (champ) | COUNT (champ) | Renvoie le nombre de lignes dans le champ de colonne |
| EXACT_COUNT_DISTINCT (champ) | COUNT ([DISTINCT] (champ)) | Renvoie le nombre de lignes uniques dans la colonne de champ |
Vous pouvez trouver une liste de toutes les fonctions dans l'aide: Legacy SQL et Standard SQL .
Voyons comment les fonctions répertoriées fonctionnent avec un exemple de démonstration de données. Calculons le revenu moyen des transactions, des achats avec le montant le plus élevé et le plus bas, le revenu total et le nombre de toutes les transactions. Pour vérifier si les achats sont dupliqués, nous calculerons également le nombre de transactions uniques. Pour ce faire, nous écrivons une requête dans laquelle nous indiquons le nom de notre projet, ensemble de données et table Google BigQuery.
#legasy SQL
SELECT
AVG(revenue) as average_revenue,
MAX(revenue) as max_revenue,
MIN(revenue) as min_revenue,
SUM(revenue) as whole_revenue,
COUNT(transactionId) as transactions,
EXACT_COUNT_DISTINCT(transactionId) as unique_transactions
FROM
[owox-analytics:t_kravchenko.Demo_data]# SQL standard
SELECT
AVG(revenue) as average_revenue,
MAX(revenue) as max_revenue,
MIN(revenue) as min_revenue,
SUM(revenue) as whole_revenue,
COUNT(transactionId) as transactions,
COUNT(DISTINCT(transactionId)) as unique_transactions
FROM
`owox-analytics.t_kravchenko.Demo_data`En conséquence, nous obtenons les résultats suivants:
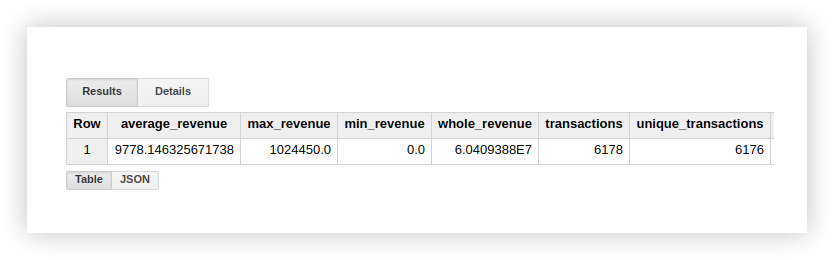
Vous pouvez vérifier les résultats du calcul dans le tableau d'origine avec des données de démonstration en utilisant les fonctions standard de Google Sheets (SUM, AVG et autres) ou des tableaux croisés dynamiques.
Comme vous pouvez le voir sur la capture d'écran ci-dessus, le nombre de transactions et de transactions uniques est différent.
Cela suggère qu'il y a 2 transactions dans notre table qui ont une transactionId en double:
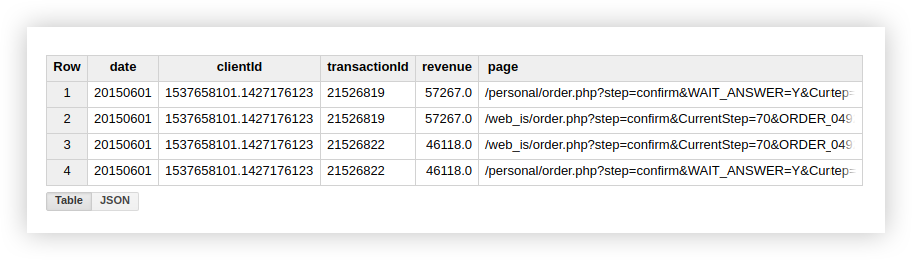
Par conséquent, si vous êtes intéressé par des transactions uniques, utilisez la fonction qui compte les lignes uniques. Vous pouvez également regrouper les données à l'aide d'une clause GROUP BY pour supprimer les doublons avant d'utiliser la fonction d'agrégation.
Fonctions pour travailler avec les dates (fonction Date)
Ces fonctions permettent de traiter les dates: modifier leur format, sélectionner la partie souhaitée (jour, mois ou année), décaler la date d'un certain intervalle.
Ils peuvent vous être utiles dans les cas suivants:
- Lors de la configuration d'analyses de bout en bout - pour regrouper les dates et heures de différentes sources dans un seul format.
- Lors de la création de rapports mis à jour automatiquement ou de mailings déclenchés. Par exemple, lorsque vous avez besoin de données pour les 2 dernières heures, une semaine ou un mois.
- Lors de la création de rapports de cohorte dans lesquels il est nécessaire d'obtenir des données dans le contexte de jours, semaines, mois.
Fonctions de date les plus couramment utilisées:
| SQL hérité | SQL standard | Que fait la fonction |
|---|---|---|
| DATE ACTUELLE () | DATE ACTUELLE () | Renvoie la date actuelle au format% AAAA-% MM-% JJ |
| DATE (horodatage) | DATE (horodatage) | Convertit une date au format% AAAA-% MM-% JJ% H:% M:% S. au format% AAAA-% MM-% JJ |
| DATE_ADD (horodatage, intervalle, interval_units) | DATE_ADD(timestamp, INTERVAL interval interval_units) | timestamp, interval.interval_units.
Legacy SQL YEAR, MONTH, DAY, HOUR, MINUTE SECOND, Standard SQL — YEAR, QUARTER, MONTH, WEEK, DAY |
| DATE_ADD(timestamp, — interval, interval_units) | DATE_SUB(timestamp, INTERVAL interval interval_units) | timestamp, interval |
| DATEDIFF(timestamp1, timestamp2) | DATE_DIFF(timestamp1, timestamp2, date_part) | timestamp1 timestamp2.
Legacy SQL , Standard SQL — date_part (, , , , ) |
| DAY(timestamp) | EXTRACT(DAY FROM timestamp) | timestamp. 1 31 |
| MONTH(timestamp) | EXTRACT(MONTH FROM timestamp) | timestamp. 1 12 |
| YEAR(timestamp) | EXTRACT(YEAR FROM timestamp) | timestamp |
Pour obtenir la liste de toutes les fonctionnalités, consultez l'aide de Legacy SQL et de SQL standard .
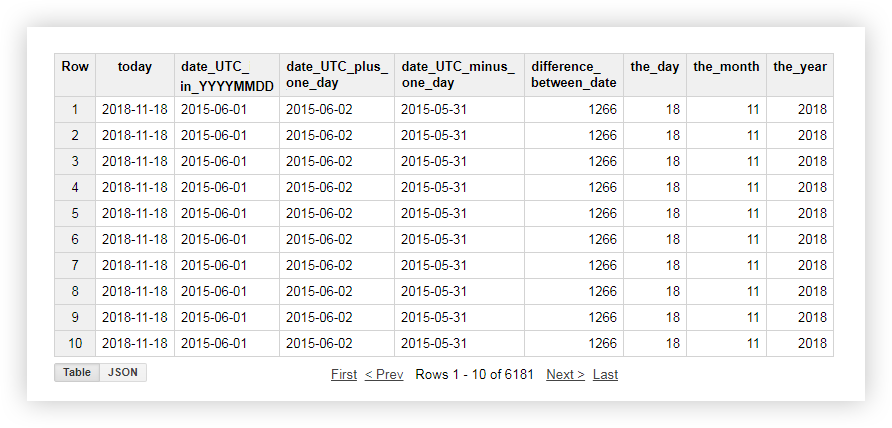
Regardons une démo des données, comment chacune des fonctions ci-dessus fonctionne. Par exemple, nous obtenons la date actuelle, apportons la date de la table d'origine au format% AAAA-% MM-% JJ, soustrayons et ajoutons un jour. Ensuite, nous calculons la différence entre la date actuelle et la date de la table d'origine et divisons la date actuelle séparément en année, mois et jour. Pour ce faire, vous pouvez copier les exemples de requêtes ci-dessous et remplacer le nom du projet, de l'ensemble de données et de la table de données par le vôtre.
#legasy SQL
SELECT
CURRENT_DATE() AS today,
DATE( date_UTC ) AS date_UTC_in_YYYYMMDD,
DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day,
DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day,
DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date,
DAY( CURRENT_DATE() ) AS the_day,
MONTH( CURRENT_DATE()) AS the_month,
YEAR( CURRENT_DATE()) AS the_year
FROM
[owox-analytics:t_kravchenko.Demo_data]
# SQL standard
SELECT
today,
date_UTC_in_YYYYMMDD,
DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day,
DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day,
DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date,
EXTRACT(DAY FROM today ) AS the_day,
EXTRACT(MONTH FROM today ) AS the_month,
EXTRACT(YEAR FROM today ) AS the_year
FROM (
SELECT
CURRENT_DATE() AS today,
DATE( date_UTC ) AS date_UTC_in_YYYYMMDD
FROM
`owox-analytics.t_kravchenko.Demo_data`)
Après avoir appliqué la demande, vous recevrez le rapport suivant:
Fonctions pour travailler avec des chaînes (fonction String)
Les fonctions de chaîne vous permettent de former une chaîne, de mettre en évidence et de remplacer des sous-chaînes, de calculer la longueur de la chaîne et l'index ordinal de la sous-chaîne dans la chaîne d'origine.
Par exemple, avec leur aide, vous pouvez:
- Créez des filtres dans le rapport par balises UTM qui sont transmises à l'URL de la page.
- Apportez les données dans un format unifié si les noms des sources et des campagnes sont écrits dans des registres différents.
- Remplacez les données incorrectes dans le rapport, par exemple, si le nom de la campagne a été envoyé avec une faute de frappe.
Les fonctions les plus populaires pour travailler avec des chaînes:
| SQL hérité | SQL standard | Que fait la fonction |
|---|---|---|
| CONCAT ('str1', 'str2') ou 'str1' + 'str2' | CONCAT ('str1', 'str2') | Concatène plusieurs chaînes 'str1' et 'str2' en une seule |
| 'str1' CONTIENT 'str2' | REGEXP_CONTAINS('str1', 'str2') 'str1' LIKE ‘%str2%’ | true 'str1' ‘str2’.
Standard SQL ‘str2’ re2 |
| LENGTH('str' ) | CHAR_LENGTH('str' )
CHARACTER_LENGTH('str' ) |
'str' ( ) |
| SUBSTR('str', index [, max_len]) | SUBSTR('str', index [, max_len]) | max_len, index 'str' |
| LOWER('str') | LOWER('str') | 'str' |
| UPPER(str) | UPPER(str) | 'str' |
| INSTR('str1', 'str2') | STRPOS('str1', 'str2') | Renvoie l'index de la première occurrence de la chaîne 'str2' dans la chaîne 'str1', sinon - 0 |
| REMPLACER ('str1', 'str2', 'str3') | REMPLACER ('str1', 'str2', 'str3') | Remplace dans la chaîne «str1» la sous-chaîne «str2» par la sous-chaîne «str3» |
Plus de détails - dans l'aide: Legacy SQL et Standard SQL .
Analysons comment utiliser les fonctions décrites en utilisant l'exemple des données de démonstration. Supposons que nous ayons 3 colonnes distinctes qui contiennent les valeurs du jour, du mois et de l'année:
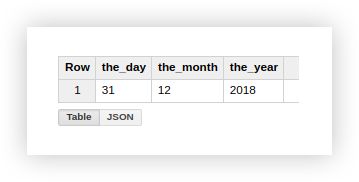
travailler avec une date dans ce format n'est pas très pratique, nous allons donc la combiner en une seule colonne. Pour ce faire, utilisez les requêtes SQL ci-dessous et n'oubliez pas d'inclure le nom de votre projet, de l'ensemble de données et de la table Google BigQuery.
#legasy SQL
SELECT
CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1,
the_day+'-'+the_month+'-'+the_year AS mix_string2
FROM (
SELECT
'31' AS the_day,
'12' AS the_month,
'2018' AS the_year
FROM
[owox-analytics:t_kravchenko.Demo_data])
GROUP BY
mix_string1,
mix_string2
# SQL standard
SELECT
CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1
FROM (
SELECT
'31' AS the_day,
'12' AS the_month,
'2018' AS the_year
FROM
`owox-analytics.t_kravchenko.Demo_data`)
GROUP BY
mix_string1
Après avoir exécuté la demande, nous recevrons la date dans une colonne:

Souvent, lors du chargement d'une page spécifique sur le site, l'URL contient les valeurs des variables que l'utilisateur a sélectionnées. Cela peut être un mode de paiement ou de livraison, un numéro de transaction, un index d'un magasin physique où un client souhaite récupérer un article, etc. En utilisant une requête SQL, vous pouvez extraire ces paramètres de l'adresse de la page.
Regardons deux exemples de comment et pourquoi faire cela.
Exemple 1 . Disons que nous voulons connaître le nombre d'achats auquel les utilisateurs récupèrent des articles dans des magasins physiques. Pour ce faire, vous devez compter le nombre de transactions envoyées depuis les pages dont l'URL contient la sous-chaîne shop_id (index du magasin physique). Nous faisons cela en utilisant les requêtes suivantes:
#legasy SQL
SELECT
COUNT(transactionId) AS transactions,
check
FROM (
SELECT
transactionId,
page CONTAINS 'shop_id' AS check
FROM
[owox-analytics:t_kravchenko.Demo_data])
GROUP BY
check
# SQL standard
SELECT
COUNT(transactionId) AS transactions,
check1,
check2
FROM (
SELECT
transactionId,
REGEXP_CONTAINS( page, 'shop_id') AS check1,
page LIKE '%shop_id%' AS check2
FROM
`owox-analytics.t_kravchenko.Demo_data`)
GROUP BY
check1,
check2
A partir du tableau résultant, nous voyons que 5502 transactions ont été envoyées à partir des pages contenant le shop_id (check = true):
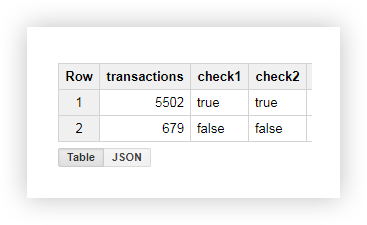
Exemple 2 . Supposons que vous ayez attribué votre delivery_id à chaque méthode de livraison et que vous écriviez la valeur de ce paramètre dans l'URL de la page. Pour savoir quelle méthode de livraison l'utilisateur a choisie, sélectionnez delivery_id dans une colonne distincte.
Nous utilisons les requêtes suivantes pour cela:
#legasy SQL
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
selected_delivery_id,
REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id
FROM (
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id
FROM (
SELECT
page_lower_case,
LENGTH(page_lower_case) AS page_length,
INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id
FROM (
SELECT
LOWER( page) AS page_lower_case,
UPPER( page) AS page_upper_case
FROM
[owox-analytics:t_kravchenko.Demo_data])))
ORDER BY
page_lower_case ASC
# SQL standard
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
selected_delivery_id,
REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id
FROM (
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id
FROM (
SELECT
page_lower_case,
CHAR_LENGTH(page_lower_case) AS page_length,
STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id
FROM (
SELECT
LOWER( page) AS page_lower_case,
UPPER( page) AS page_upper_case
FROM
`owox-analytics.t_kravchenko.Demo_data`)))
ORDER BY
page_lower_case ASC
En conséquence, nous obtenons le tableau suivant dans Google BigQuery:

Fonctions pour travailler avec des sous-ensembles de données ou des fonctions de fenêtre (fonction Fenêtre)
Ces fonctions sont similaires aux fonctions d'agrégation décrites ci-dessus. Leur principale différence est que les calculs ne sont pas effectués sur l'ensemble complet de données sélectionnées à l'aide d'une requête, mais sur une partie de celui-ci - un sous-ensemble ou une fenêtre.
À l'aide des fonctions de fenêtre, vous pouvez agréger des données par groupes sans utiliser l'opérateur JOIN pour combiner plusieurs requêtes. Par exemple, calculez le revenu moyen par campagnes publicitaires, le nombre de transactions par appareil. En ajoutant un autre champ au rapport, vous pouvez facilement connaître, par exemple, la part des revenus d'une campagne publicitaire le Black Friday ou la part des transactions effectuées depuis une application mobile.
Avec chaque fonction, une expression OVER doit être écrite dans la requête, qui définit les limites de la fenêtre. OVER contient 3 composants avec lesquels vous pouvez travailler:
- PARTITION BY - définit l'attribut par lequel vous diviserez les données source en sous-ensembles, par exemple PARTITION BY clientId, DayTime.
- ORDER BY - définit l'ordre des lignes dans le sous-ensemble, par exemple ORDER BY hour DESC.
- WINDOW FRAME - vous permet de traiter les lignes dans un sous-ensemble selon une caractéristique spécifique. Par exemple, vous pouvez calculer la somme de toutes les lignes de la fenêtre, mais uniquement des cinq premières avant la ligne actuelle.
Ce tableau résume les fonctions de fenêtre les plus couramment utilisées:
| SQL hérité | SQL standard | Que fait la fonction |
|---|---|---|
| AVG (champ)
COUNT (champ) COUNT (champ DISTINCT) MAX () MIN () SUM () |
AVG ([DISTINCT] (champ))
COUNT (champ) COUNT ([DISTINCT] (champ)) MAX (champ) MIN (champ) SUM (champ) |
, , , field .
DISTINCT , () |
| 'str1' CONTAINS 'str2' | REGEXP_CONTAINS('str1', 'str2') 'str1' LIKE ‘%str2%’ | true 'str1' ‘str2’.
Standard SQL ‘str2’ re2 |
| DENSE_RANK() | DENSE_RANK() | |
| FIRST_VALUE(field) | FIRST_VALUE (field[{RESPECT | IGNORE} NULLS]) | field .
field . RESPECT IGNORE NULLS , NULL |
| LAST_VALUE(field) | LAST_VALUE (field [{RESPECT | IGNORE} NULLS]) | field .
field . RESPECT IGNORE NULLS , NULL |
| LAG(field) | LAG (field[, offset [, default_expression]]) | field .
Offset , . . Default_expression — , , |
| LEAD(field) | LEAD (field[, offset [, default_expression]]) | field .
Offset , . . Default_expression — , , |
Vous pouvez voir une liste de toutes les fonctions dans l'aide pour Legacy SQL et pour SQL standard: fonctions analytiques agrégées , fonctions de navigation .
Exemple 1. Disons que nous voulons analyser l'activité des clients pendant les heures de travail et les heures non travaillées. Pour ce faire, il est nécessaire de diviser les transactions en 2 groupes et de calculer les métriques qui nous intéressent:
- Groupe 1 - achats pendant les heures d'ouverture de 9h00 à 18h00.
- Groupe 2 - achats en dehors des heures de travail de 00h00 à 9h00 et de 18h00 à 00h00.
En plus des heures de travail et non travaillées, un autre signe pour la formation d'une fenêtre sera le clientId, c'est-à-dire que pour chaque utilisateur, nous aurons deux fenêtres:
| Sous-ensemble (fenêtre) | identité du client | Jour |
|---|---|---|
| 1 fenêtre | clientId 1 | Temps de travail |
| 2 fenêtre | clientId 2 | Heures non ouvrées |
| 3 fenêtre | clientId 3 | Temps de travail |
| 4 fenêtre | clientId 4 | Heures non ouvrées |
| Fenêtre N | clientId N | Temps de travail |
| Fenêtre N + 1 | clientId N + 1 | Heures non ouvrées |
Calculons le revenu moyen, maximum, minimum et total, le nombre de transactions et le nombre de transactions uniques pour chaque utilisateur pendant les heures de travail et non travaillées sur les données de démonstration. Les requêtes ci-dessous nous aideront à le faire.
#legasy SQL
SELECT
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
FROM (
SELECT
date,
clientId,
DayTime,
AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue,
MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue,
MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue,
SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue,
COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions,
COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
[owox-analytics:t_kravchenko.Demo_data]))
GROUP BY
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
ORDER BY
transactions DESC
# SQL standard
SELECT
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
FROM (
SELECT
date,
clientId,
DayTime,
AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue,
MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue,
MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue,
SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue,
COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions,
COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
`owox-analytics.t_kravchenko.Demo_data`))
GROUP BY
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
ORDER BY
transactions DESC
Voyons ce qui s'est passé en conséquence, en utilisant l'exemple de l'un des utilisateurs avec clientId = '102041117.1428132012 ′. Dans le tableau d'origine de cet utilisateur, nous avions les données suivantes:
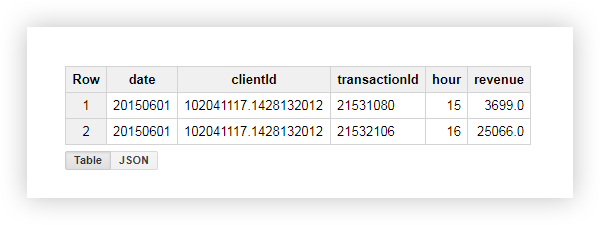
En appliquant la requête, nous avons reçu un rapport contenant le revenu moyen, minimum, maximum et total de cet utilisateur, ainsi que le nombre de transactions. Comme vous pouvez le voir dans la capture d'écran ci-dessous, l'utilisateur a effectué les deux transactions pendant les heures ouvrables:

Exemple 2 . Maintenant, compliquons un peu la tâche:
- Inscrivons les numéros de série de toutes les transactions dans la fenêtre, en fonction de l'heure de leur exécution. Rappelons que nous définissons la fenêtre par utilisateur et temps de travail / non-travail.
- Affichons le revenu de la transaction suivante / précédente (par rapport à la transaction actuelle) dans la fenêtre.
- Affichons le revenu de la première et de la dernière transaction dans la fenêtre.
Pour cela, nous utilisons les requêtes suivantes:
#legasy SQL
SELECT
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
FROM (
SELECT
date,
clientId,
DayTime,
hour,
DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank,
revenue,
LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue,
LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue,
FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour,
LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
[owox-analytics:t_kravchenko.Demo_data]))
GROUP BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
ORDER BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
# SQL standard
SELECT
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
FROM (
SELECT
date,
clientId,
DayTime,
hour,
DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank,
revenue,
LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue,
LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue,
FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour,
LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
`owox-analytics.t_kravchenko.Demo_data`))
GROUP BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
ORDER BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
Vérifions les résultats du calcul en utilisant l'exemple d'un utilisateur déjà familier avec clientId = '102041117.1428132012 ′:

De la capture d'écran ci-dessus, nous voyons que:
- La première transaction a eu lieu à 15h00 et la seconde à 16h00.
- Après la transaction en cours à 15h00, il y a eu une transaction à 16h00, dont le revenu est de 25066 (colonne lead_revenue).
- Avant la transaction en cours à 16h00, il y avait une transaction à 15h00 avec un chiffre d'affaires de 3699 (colonne lag_revenue).
- La première transaction dans la fenêtre était une transaction à 15h00, dont le revenu est de 3699 (colonne first_revenue_by_hour).
- La demande traite les données ligne par ligne, donc pour la transaction en question, ce sera la dernière de la fenêtre et les valeurs des colonnes last_revenue_by_hour et revenue seront les mêmes.
conclusions
Dans cet article, nous avons couvert les fonctions les plus populaires des sections Fonction d'agrégation, fonction de date, fonction de chaîne, fonction de fenêtre. Cependant, Google BigQuery propose de nombreuses autres fonctionnalités utiles, par exemple:
- Fonctions de diffusion - vous permettent de diffuser des données dans un format spécifique.
- Fonctions génériques de table - vous permettent d'accéder à plusieurs tables à partir d'un ensemble de données.
- Fonctions d'expression régulière - vous permettent de décrire le modèle d'une requête de recherche, et non sa valeur exacte.
Écrivez dans les commentaires s'il est judicieux d'écrire dans les mêmes détails à leur sujet.