Partie 2
Dans cet article, vous apprendrez:
- À propos du défi de reconnaissance visuelle à grande échelle ImageNet (ILSVRC)
- À propos des architectures CNN:
- LeNet-5
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- À propos des problèmes apparus avec les nouvelles architectures de réseau, comment ils ont été résolus par les suivantes:
- problème de gradient de disparition
- problème de gradient explosif
ILSVRC
Le Défi de reconnaissance visuelle à grande échelle ImageNet est un concours annuel au cours duquel les chercheurs comparent leurs grilles pour la détection et la classification d'objets dans les photographies.
Ce concours a été à l'origine du développement de:
- Architectures de réseaux neuronaux
- méthodes et pratiques personnelles utilisées à ce
jour.Ce graphique montre comment les algorithmes de classification ont évolué au fil du temps:
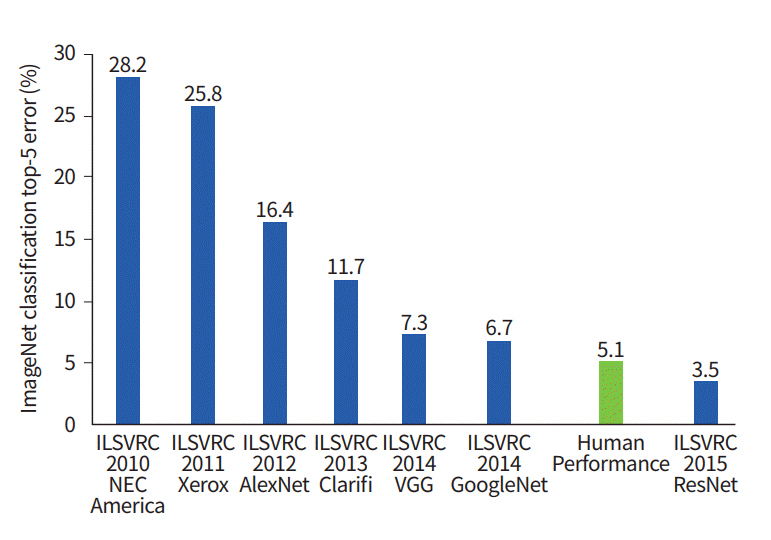
Sur l'axe des x - années et algorithmes (depuis 2012 - neurones convolutifs réseau).
L'axe des y est le pourcentage d'erreurs dans l'échantillon des 5 premières erreurs.
L'erreur Top-5 est un moyen d'évaluer le modèle: le modèle renvoie une certaine distribution de probabilité et si parmi les 5 meilleures probabilités il y a une valeur vraie (étiquette de classe) de la classe, alors la réponse du modèle est considérée comme correcte. En conséquence, (1 - erreur top-1) est la précision familière.
Architectures CNN
LeNet-5
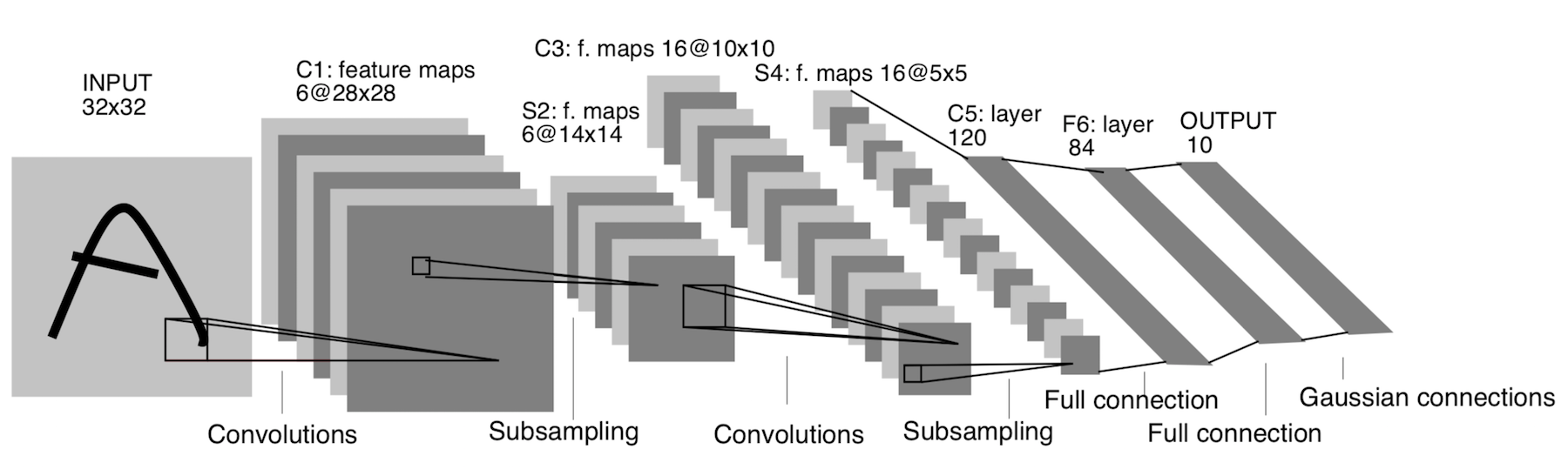
Il est apparu déjà en 1998! Il a été conçu pour reconnaître les lettres et les chiffres manuscrits. Le sous-échantillonnage fait ici référence à la couche de regroupement.
Architecture:
CONV 5x5, foulée = 1
PISCINE 2x2, foulée = 2
CONV 5x5, foulée = 1
PISCINE 5x5, foulée = 2
FC (120, 84)
FC (84, 10)
Cette architecture n'a plus qu'une signification historique. Cette architecture est facile à implémenter manuellement dans n'importe quel framework moderne d'apprentissage en profondeur.
AlexNet

L'image n'est pas dupliquée. C'est ainsi que l'architecture est représentée, car l'architecture AlexNet ne s'intégrait pas dans un seul périphérique GPU à ce moment-là, donc «la moitié» du réseau fonctionnait sur un GPU et l'autre sur l'autre.
Il est apparu en 2012. Une percée dans le même ILSVRC a commencé avec elle - elle a vaincu tous les modèles de pointe de cette époque. Après cela, les gens ont réalisé que les réseaux de neurones fonctionnent vraiment :)
Architecture plus spécifiquement:

Si vous regardez de près l'architecture d'AlexNet, vous pouvez voir que pendant 14 ans (depuis l'apparition de LeNet-5), presque aucun changement n'est intervenu, à l'exception du nombre de couches.
Important:
- Nous prenons notre image originale de 227x227x3 et abaissons ses dimensions (en hauteur et en largeur), mais augmentons le nombre de canaux. Cette partie de l'architecture "encode" la représentation originale de l'objet (encodeur).
- ReLU. ReLu .
- 60 .
- .
:
- Local Response Norm — , . batch-normalization.
- - , — - FLOPs, .
- FC 4096 , (Fully-connected) 4096 .
- Max Pool 3x3s2 , 3x3, = 2.
- Un enregistrement comme Conv 11x11s4, 96 signifie que la couche de convolution a un filtre 11x11xNc, step = 4, le nombre de ces filtres est de 96. Maintenant, le nombre de ces filtres est le nombre de canaux pour la couche suivante (le même Nc). Nous supposons que l'image initiale a trois canaux (R, V et B).
VGGNet
Architecture:
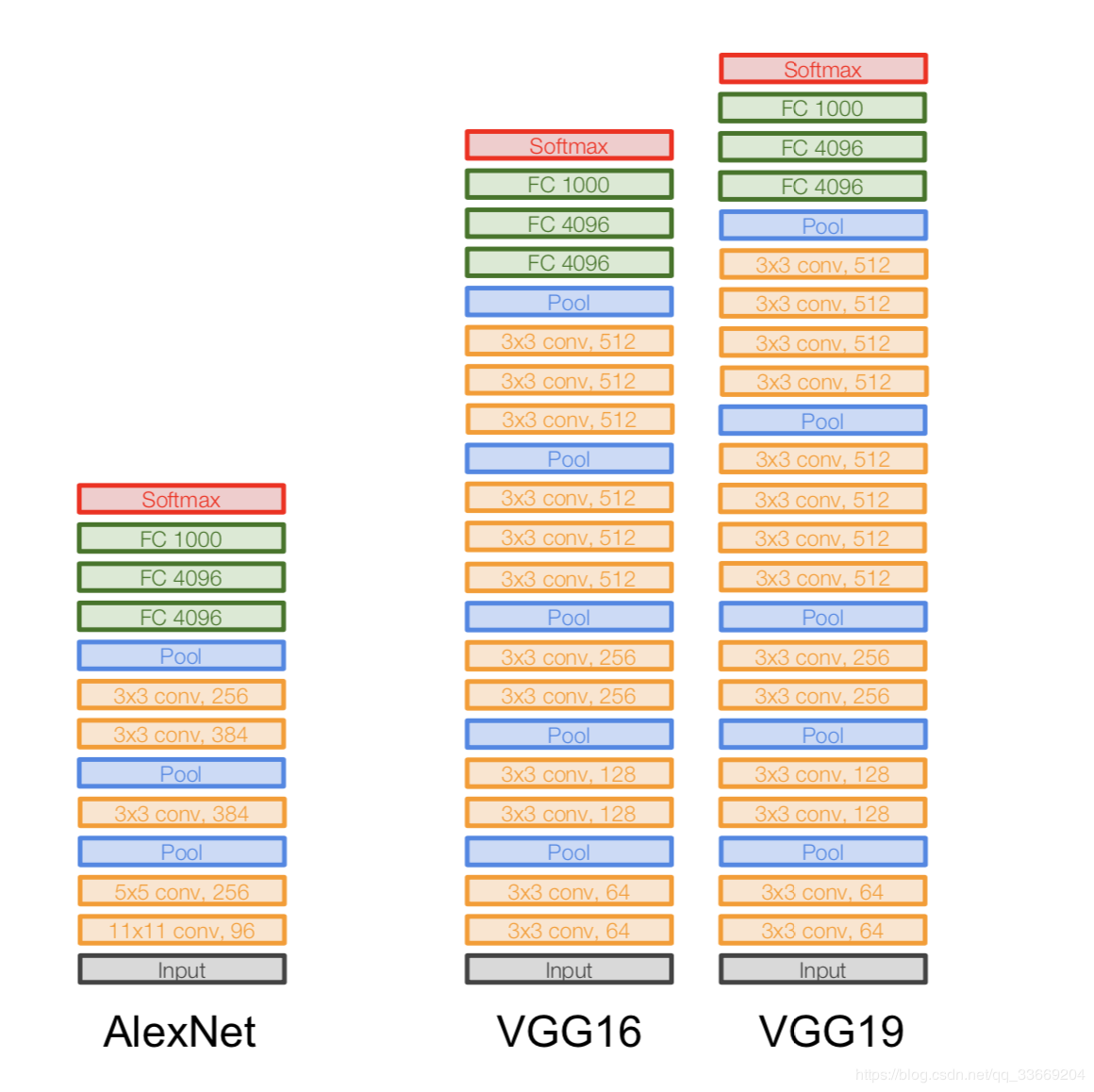
introduite en 2014.
Deux versions - VGG16 et VGG19. L'idée principale est d'utiliser des petits (3x3) au lieu de grands (11x11 et 5x5). L'intuition d'utiliser de grandes convolutions est simple - nous voulons obtenir plus d'informations à partir des pixels voisins, mais il est préférable d'utiliser plus souvent de petits filtres .
Et c'est pourquoi:
- . , . .. , , .
- => .
- — , — , — , .
Important:
- Lors de la formation d'un réseau de neurones pour un algorithme de rétropropagation d'erreur, il est important de préserver les représentations d'objets (pour nous, l'image d'origine) à toutes les étapes (convolutions, pools) de propagation vers l'avant (la passe vers l'avant est lorsque nous alimentons l'image en entrée et passons à la sortie, au résultat). Cette représentation d'un objet peut être coûteuse en termes de mémoire. Jetez un œil:
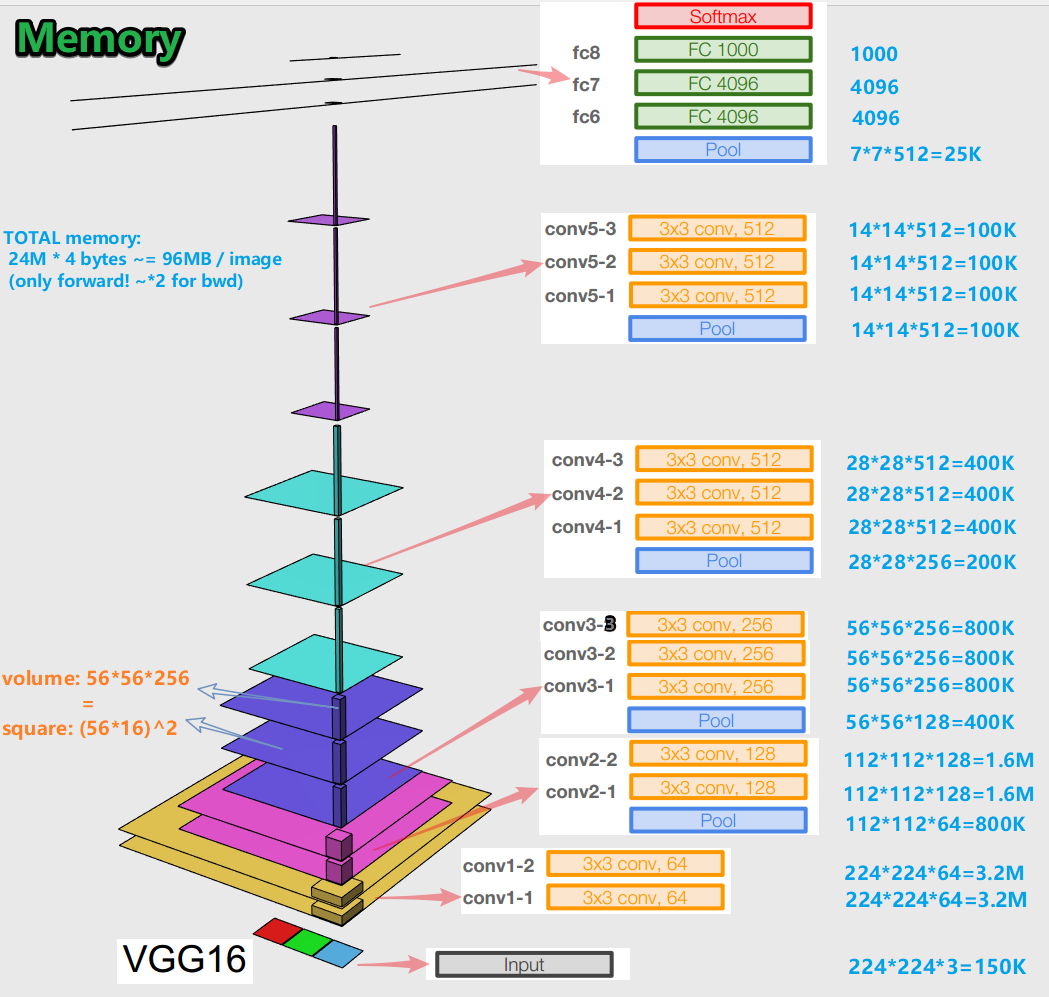
il s'avère environ 96 Mo par image - et ce n'est que pour la passe avant. Pour le passage en arrière (bwd sur l'image) - lors du calcul des dégradés - environ deux fois plus. Une image intéressante se dégage: le plus grand nombre de paramètres entraînés est situé dans des couches entièrement connectées, et la plus grande mémoire est occupée par les représentations d'objets après les couches convolutives et de pooling . C - synergie.
- Le réseau a 138 millions de paramètres entraînables dans 16 couches de variation et 143 millions de paramètres dans 19 couches de variation.
GoogLeNet
Architecture:
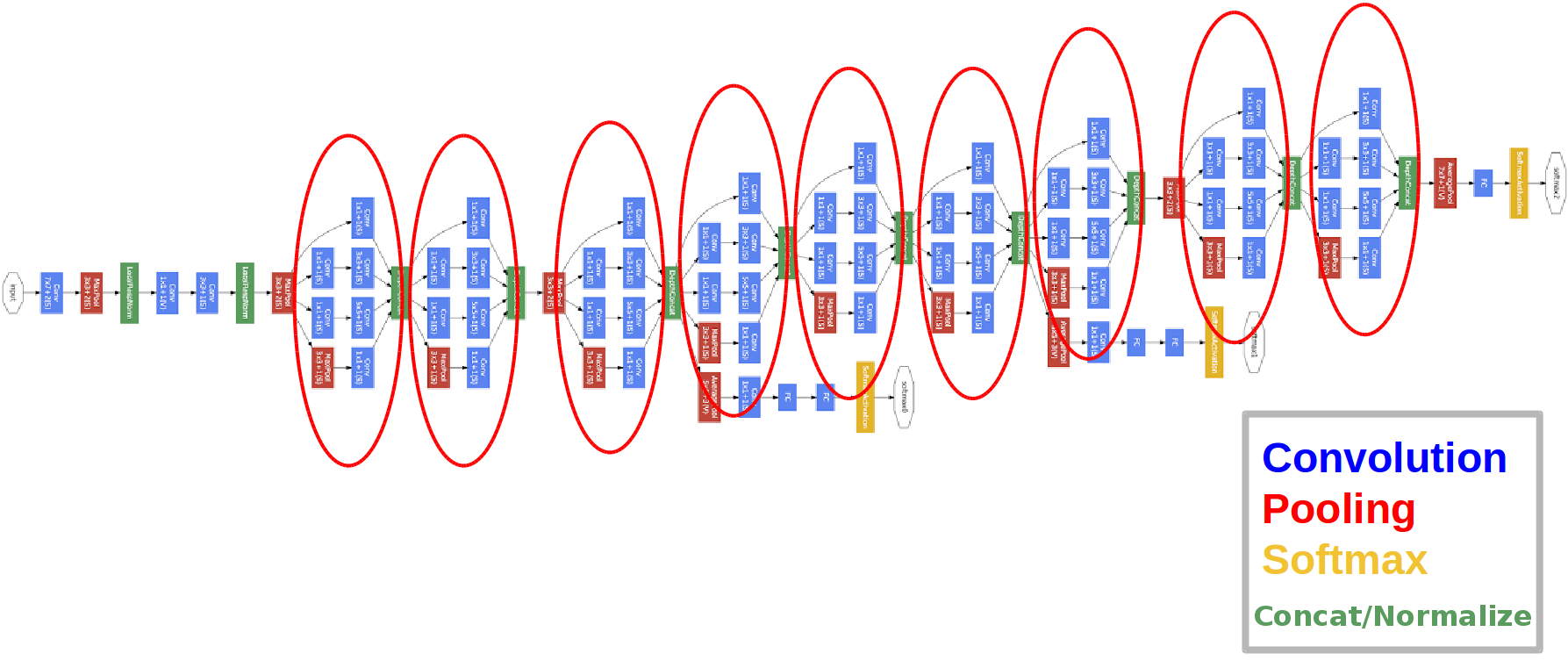
introduite en 2014.
Les cercles rouges sont ce que l'on appelle le module Inception.
Examinons cela de plus près:
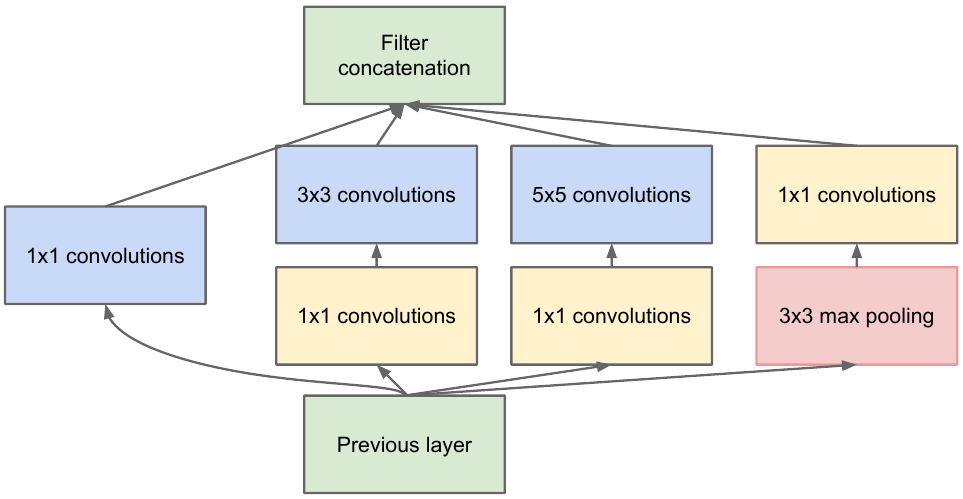
nous prenons une carte d'entités de la couche précédente, nous lui appliquons un certain nombre de convolutions avec différents filtres, puis nous concaténons celle qui en résulte. L'intuition est simple: nous voulons obtenir différentes représentations de notre carte des caractéristiques à l'aide de filtres de différentes tailles. Les convolutions 1x1 sont utilisées pour ne pas augmenter autant le nombre de canaux après chaque bloc de lancement. Ceux. lorsque la carte d'entités comporte un grand nombre de canaux et qu'ils souhaitent réduire ce nombre sans modifier la hauteur et la largeur de la carte d'entités, utilisez la convolution 1x1.
Il y a aussi trois blocs classificateurs dans le réseau, voici à quoi ressemble l'un d'eux (celui de droite pour nous):

Avec cette construction, le gradient «mieux» atteint les couches de sortie vers les couches d'entrée lors de la rétropropagation de l'erreur.
Pourquoi avons-nous besoin de deux sorties réseau supplémentaires? Tout est question du soi-disant problème du gradient de disparition :
l'essentiel est que lors de la rétropropagation d'une erreur, le gradient a tendance à être trivialement à zéro. Plus le réseau est profond, plus il est sensible à ce phénomène. Pourquoi ça arrive? Quand on passe en arrière, on passe de la sortie à l'entrée, en calculant les gradients de fonctions complexes. Dérivée d'une fonction complexe ( règle de chaîne) Est essentiellement une multiplication. Ainsi, en multipliant certaines valeurs en cours de route de la sortie à l'entrée, nous rencontrons des nombres proches de zéro et, par conséquent, les poids du réseau de neurones ne sont pratiquement pas mis à jour. Ceci est en partie un problème avec les fonctions d'activation sigmoïde qui ont leur sortie dans une plage fixe. Eh bien, ce problème est partiellement résolu en utilisant la fonction d'activation ReLu. Pourquoi partiellement? Parce que personne ne donne de garanties pour les valeurs des paramètres entraînés et la représentation de l'objet d'entrée dans toutes les cartes d'entités.
Important:
- Le réseau a 22 couches (c'est légèrement plus que le réseau précédent).
- Le nombre de paramètres entraînés est égal à cinq millions, ce qui est plusieurs fois moins que dans les deux réseaux précédents.
- L'apparence du bundle 1x1.
- Les blocs de lancement sont utilisés.
- Au lieu de couches entièrement connectées, maintenant des convolutions 1x1, qui abaissent la profondeur et, par conséquent, réduisent la dimension des couches entièrement connectées et le regroupement global des avegare (vous pouvez en savoir plus ici ).
- L'architecture a 3 sorties (la réponse finale est pesée).
ResNet
Architecture (variante ResNet-34): introduite
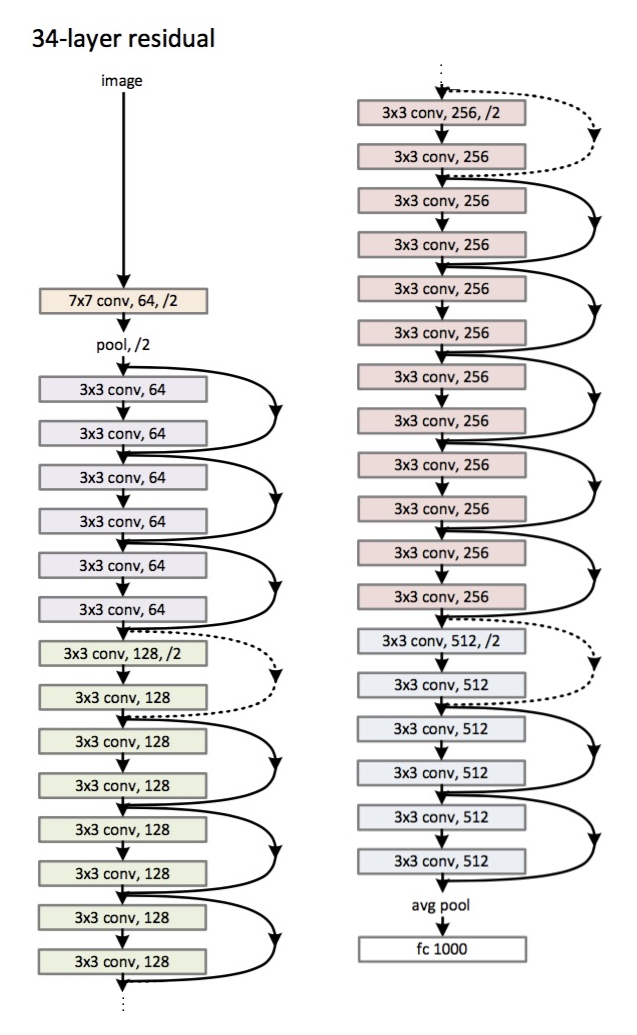
en 2015.
La principale innovation est un grand nombre de couches et de blocs dits résiduels. Ces blocs sont utilisés pour lutter contre le problème du gradient de décoloration. La connexion entre ces blocs résiduels est appelée un raccourci (flèches dans l'image). Maintenant, en utilisant ces raccourcis, le gradient atteindra tous les paramètres nécessaires, entraînant ainsi le réseau :)
Important:
- Au lieu de couches entièrement connectées - mise en commun globale moyenne.
- Blocs résiduels.
- Le réseau a surpassé les humains dans la reconnaissance des modèles sur l'ensemble de données ImageNet (erreur top-5).
- La normalisation par lots a été utilisée pour la première fois.
- La technique d'initialisation des poids est utilisée (intuition: à partir d'une certaine initialisation des poids, le réseau converge (apprend) plus vite et mieux).
- La profondeur maximale est de 152 couches!
Une petite digression
Le problème du gradient de fading est pertinent pour tous les réseaux de neurones profonds.
Il y a aussi son antagoniste - le problème du gradient explosif, qui est également pertinent pour tous les réseaux de neurones profonds. La ligne du bas est claire à partir du nom - le dégradé devient trop grand, ce qui provoque NaN (pas un nombre, l'infini). La solution est évidente - limiter la valeur du gradient, sinon - réduire sa valeur (normaliser). Cette technique est appelée "détourage".
Conclusion
En 2019, un article est paru sur une nouvelle famille d'architectures - EfficientNet.
Je recommande de suivre les dernières tendances dans diverses tâches et domaines liés à l'apprentissage automatique ici . Sur cette ressource, vous pouvez sélectionner une tâche (par exemple, la classification d'images) et un ensemble de données (par exemple, ImageNet) et regarder la qualité de certaines architectures, des informations supplémentaires à leur sujet. Par exemple, la grille FixEfficientNet-L2 prend la première place honorable dans la classification des images sur l'ensemble de données ImageNet (précision top-1).
Dans les prochains articles, nous parlerons de l'apprentissage par transfert, de la détection d'objets, de la segmentation.