
Auto-identification
Je m'appelle Alexander, je développe la direction de l'analyse des données et de la technologie aux fins de l'audit interne du groupe Rosbank. Mon équipe et moi utilisons l'apprentissage automatique et les réseaux de neurones pour identifier les risques dans le cadre des audits internes. Nous avons un serveur ~ 300 Go de RAM et 4 processeurs avec 10 cœurs dans notre arsenal. Pour la programmation algorithmique ou la modélisation, nous utilisons Python.
introduction
Nous avons été confrontés à la tâche d'analyser des photographies (portraits) de clients prises par des employés de banque lors de l'enregistrement d'un produit bancaire. Notre objectif est d'identifier les risques précédemment découverts à partir de ces photographies. Pour identifier le risque, nous générons et testons un ensemble d'hypothèses. Dans cet article, je décrirai les hypothèses que nous avons formulées et comment nous les avons testées. Pour simplifier la perception du matériau, j'utiliserai la Joconde - la norme du genre portrait.

Vérifier la somme
Dans un premier temps, nous avons adopté une approche sans apprentissage automatique ni vision par ordinateur, en comparant simplement les sommes de contrôle des fichiers. Pour les générer, nous avons pris l'algorithme md5 largement utilisé de la bibliothèque hashlib.
Implémentation Python *:
#
with open(file,'rb') as f:
#
for chunk in iter(lambda: f.read(4096),b''):
#
hash_md5.update(chunk)
Lors de la formation de la somme de contrôle, nous vérifions immédiatement les doublons à l'aide d'un dictionnaire.
#
for file in folder_scan(for_scan):
#
ch_sum = checksum(file)
#
if ch_sum in list_of_uniq.keys():
# , , dataframe
df = df.append({'id':list_of_uniq[chs],'same_checksum_with':[file]}, ignore_index = True)
Cet algorithme est incroyablement simple en termes de charge de calcul: sur notre serveur 1000 images sont traitées en pas plus de 3 secondes.
Cet algorithme nous a aidés à identifier les photos en double parmi nos données et, par conséquent, à trouver des endroits pour une amélioration potentielle du processus commercial de la banque.
Points clés (vision par ordinateur)
Malgré le résultat positif de la méthode de la somme de contrôle, nous avons parfaitement compris que si au moins un pixel de l'image est modifié, sa somme de contrôle sera radicalement différente. En tant que développement logique de la première hypothèse, nous avons supposé que l'image pouvait être modifiée en structure binaire: subir une nouvelle sauvegarde (c'est-à-dire une recompression de jpg), redimensionner, recadrer ou faire pivoter.
Pour la démonstration, recadrons les bords le long du contour rouge et faisons pivoter la Joconde de 90 degrés vers la droite.

Dans ce cas, les doublons doivent être recherchés par le contenu visuel de l'image. Pour cela, nous avons décidé d'utiliser la librairie OpenCV, une méthode pour construire les points clés d'une image et trouver la distance entre les points clés. En pratique, les points clés peuvent être des coins, des dégradés de couleurs ou des jogs de surface. Pour nos besoins, l'une des méthodes les plus simples a été mise au point - Brute-Force Matching. Pour mesurer la distance entre les points clés de l'image, nous avons utilisé la distance de Hamming. L'image ci-dessous montre le résultat de la recherche de points clés sur les images originales et modifiées (les 20 points clés les plus proches des images sont dessinés).
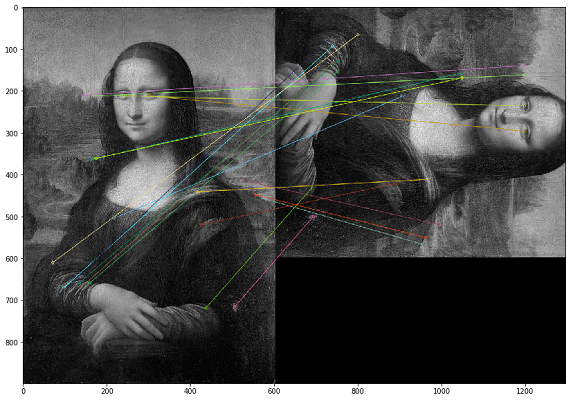
Il est important de noter que nous analysons les images dans un filtre noir et blanc, car cela optimise la durée d'exécution du script et donne une interprétation plus claire des points clés. Si une image est avec un filtre sépia et l'autre est dans un original couleur, alors lorsque nous les convertissons en un filtre noir et blanc, les points clés seront identifiés indépendamment du traitement des couleurs et des filtres.
Exemple de code pour comparer deux images *
img1 = cv.imread('mona.jpg',cv.IMREAD_GRAYSCALE) #
img2 = cv.imread('mona_ch.jpg',cv.IMREAD_GRAYSCALE) #
# ORB
orb = cv.ORB_create()
# ORB
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)
# Brute-Force Matching
bf = cv.BFMatcher(cv.NORM_HAMMING, crossCheck=True)
# .
matches = bf.match(des1,des2)
# .
matches = sorted(matches, key = lambda x:x.distance)
# 20
img3 = cv.drawMatches(img1,kp1,img2,kp2,matches[:20],None,flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
plt.imshow(img3),plt.show()
En testant les résultats, nous avons réalisé que dans le cas d'une image inversée, l'ordre des pixels dans le point clé change et que ces images ne sont pas identifiées comme étant les mêmes. En guise de compensation, vous pouvez dupliquer vous-même chaque image et analyser le double du volume (voire le triple), ce qui est beaucoup plus cher en puissance de calcul.
Cet algorithme a une complexité de calcul élevée et la plus grande charge est créée par l'opération de calcul de la distance entre les points. Puisque nous devons comparer chaque image avec chacune, alors, comme vous le comprenez, le calcul d'un tel ensemble cartésien nécessite un grand nombre de cycles de calcul. Lors d'un audit, un calcul similaire a pris plus d'un mois.
Un autre problème avec cette approche était la mauvaise interprétabilité des résultats des tests. On obtient le coefficient des distances entre les points clés des images, et la question se pose: "Quel seuil de ce coefficient faut-il choisir suffisant pour considérer les images dupliquées?"
Grâce à la vision par ordinateur, nous avons pu trouver des cas non couverts par le premier test de somme de contrôle. Dans la pratique, il s’est avéré qu’il s’agissait de fichiers jpg sur-enregistrés. Nous n'avons pas identifié de cas plus complexes de changements d'image dans l'ensemble de données analysé.
Checksum VS points clés
Après avoir développé deux approches radicalement différentes pour trouver des doublons et les réutiliser dans plusieurs contrôles, nous sommes arrivés à la conclusion que pour nos données, la somme de contrôle donne un résultat plus tangible dans un temps plus court. Par conséquent, si nous avons suffisamment de temps pour vérifier, nous faisons une comparaison par points clés.
Rechercher des images anormales
Après avoir analysé les résultats du test pour les points clés, nous avons remarqué que les photographies prises par un employé ont à peu près le même nombre de points clés proches. Et c'est logique, car s'il communique avec les clients sur son lieu de travail et prend des photos dans la même pièce, le fond de toutes ses photos sera le même. Ce constat nous a amené à penser que nous pourrions trouver des photos d'exception qui ne ressemblent pas à d'autres photographies de cet employé, qui auraient pu être prises à l'extérieur du bureau.
Revenant à l'exemple avec Mona Lisa, il s'avère que d'autres personnes apparaîtront dans le même contexte. Mais, malheureusement, nous n'avons pas trouvé de tels exemples, donc dans cette section, nous montrerons les métriques de données sans exemples. Pour augmenter la vitesse de calcul dans le cadre du test de cette hypothèse, nous avons décidé d'abandonner les points clés et d'utiliser des histogrammes.
La première étape consiste à traduire l'image en un objet (histogramme) que nous pouvons mesurer afin de comparer les images par la distance entre leurs histogrammes. Fondamentalement, un histogramme est un graphique qui donne une vue d'ensemble de l'image. Il s'agit d'un graphique avec des valeurs de pixels sur l'axe des abscisses (axe X) et le nombre correspondant de pixels dans l'image le long de l'axe des ordonnées (axe Y). Un histogramme est un moyen simple d'interpréter et d'analyser une image. En utilisant l'histogramme d'une image, vous pouvez avoir une idée intuitive du contraste, de la luminosité, de la distribution d'intensité, etc.
Pour chaque image, nous créons un histogramme à l'aide de la fonction calcHist d'OpenCV.
histo = cv2.calcHist([picture],[0],None,[256],[0,256])
Dans les exemples donnés pour trois images, nous les avons décrites en utilisant 256 facteurs le long de l'axe horizontal (tous types de pixels). Mais nous pouvons également réorganiser les pixels. Notre équipe n'a pas fait beaucoup de tests dans cette partie car le résultat était plutôt bon en utilisant 256 facteurs. Si nécessaire, nous pouvons modifier ce paramètre directement dans la fonction calcHist.
Après avoir créé des histogrammes pour chaque image, nous pouvons simplement former le modèle DBSCAN sur des images pour chaque employé qui a photographié le client. Le point technique ici est de sélectionner les paramètres DBSCAN (epsilon et min_samples) pour notre tâche.
Après avoir utilisé DBSCAN, nous pouvons effectuer un clustering d'images, puis appliquer la méthode PCA pour visualiser les clusters résultants.

Comme le montre la distribution des images analysées, nous avons deux amas bleus prononcés. Il s'est avéré qu'à des jours différents, un employé peut travailler dans différents bureaux - les photographies prises dans l'un des bureaux créent un groupe distinct.
Alors que les points verts sont des photos d'exception où le fond est différent de ces clusters.
Après une analyse détaillée des photographies, nous avons trouvé de nombreuses photos faussement négatives. Les cas les plus courants sont des photographies soufflées ou des photographies dans lesquelles une grande partie de la zone est occupée par le visage du client. Il s'avère que cette méthode d'analyse nécessite une intervention humaine obligatoire pour valider les résultats.
En utilisant cette approche, vous pouvez trouver des anomalies intéressantes sur la photo, mais il faudra un investissement de temps pour analyser manuellement les résultats. Pour ces raisons, nous effectuons rarement de tels tests dans le cadre de nos audits.
Y a-t-il un visage sur la photo? (Détection facial)
Ainsi, nous avons déjà testé notre jeu de données de différents côtés et, continuant à développer la complexité des tests, nous passons à l'hypothèse suivante: y a-t-il un visage du client potentiel sur la photo? Notre tâche est d'apprendre à identifier les visages dans les images, à donner des fonctions à l'entrée d'une image et à obtenir le nombre de visages en sortie.
Ce type d'implémentation existe déjà, et nous avons décidé de choisir MTCNN (Multitasking Cascade Convolutional Neural Network) pour notre tâche à partir du module FaceNet de Google.
FaceNet est une architecture d'apprentissage automatique en profondeur qui se compose de couches convolutives. FaceNet renvoie un vecteur de 128 dimensions pour chaque face. En fait, FaceNet, c'est plusieurs réseaux de neurones et un ensemble d'algorithmes pour préparer et traiter les résultats intermédiaires de ces réseaux. Nous avons décidé de décrire plus en détail la mécanique de la recherche de visage par ce réseau de neurones, car il n'y a pas beaucoup de matériaux à ce sujet.
Étape 1: prétraitement
La première chose que fait MTCNN est de créer plusieurs tailles de notre photo.
Le MTCNN essaiera de reconnaître les visages dans un carré de taille fixe dans chaque photo. Utiliser cette reconnaissance sur la même photo de différentes tailles augmentera nos chances de reconnaître correctement tous les visages de la photo.

Un visage peut ne pas être reconnu dans une taille d'image normale, mais il peut être reconnu dans une image de taille différente dans un carré de taille fixe. Cette étape est effectuée de manière algorithmique sans réseau de neurones.
Étape 2: P-Net
Après avoir créé différentes copies de notre photo, le premier réseau de neurones, P-Net, entre en jeu. Ce réseau utilise un noyau 12x12 (bloc) qui numérisera toutes les photos (copies de la même photo, mais de tailles différentes), en partant du coin supérieur gauche, et se déplacera le long de l'image en utilisant un pas de 2 pixels.

Après avoir numérisé toutes les images de différentes tailles, MTCNN standardise à nouveau chaque photo et recalcule les coordonnées du bloc.
Le P-Net donne les coordonnées des blocs et les niveaux de confiance (la précision de cette face) par rapport à la face qu'il contient pour chaque bloc. Vous pouvez laisser des blocs avec un certain niveau de confiance à l'aide du paramètre de seuil.
Dans le même temps, nous ne pouvons pas simplement sélectionner les blocs avec le niveau de confiance maximal, car l'image peut contenir plusieurs faces.
Si un bloc chevauche un autre et couvre presque la même zone, ce bloc est supprimé. Ce paramètre peut être contrôlé lors de l'initialisation du réseau.

Dans cet exemple, le bloc jaune sera supprimé. Fondamentalement, le résultat du P-Net est des blocs de faible précision. L'exemple ci-dessous montre les résultats réels de P-Net:

Étape 3: R-Net
R-Net effectue une sélection des blocs les plus appropriés formés à la suite du travail de P-Net, qui dans le groupe est très probablement une personne. R-Net a une architecture similaire à P-Net. À ce stade, des couches entièrement connectées sont formées. La sortie de R-Net est également similaire à la sortie de P-Net.

Étape 4: O-Net
Le réseau O-Net est la dernière partie du réseau MTCNN. En plus des deux derniers réseaux, il forme cinq points pour chaque visage (yeux, nez, coins des lèvres). Si ces points tombent complètement dans le bloc, alors il est déterminé comme contenant le plus probablement la personne. Les points supplémentaires sont marqués en bleu:

En conséquence, nous obtenons un dernier bloc indiquant l'exactitude du fait qu'il s'agit d'un visage. Si le visage n'est pas trouvé, nous obtiendrons un nombre nul de blocs de visage.
En moyenne, le traitement de 1000 photos par un tel réseau prend 6 minutes sur notre serveur.
Nous avons utilisé à plusieurs reprises ce réseau de neurones lors de contrôles, et cela nous a aidés à identifier automatiquement les anomalies parmi les photographies de nos clients.
À propos de l'utilisation de FaceNet, je voudrais ajouter que si, au lieu de Mona Lisa, vous commencez à analyser les toiles de Rembrandt, les résultats ressembleront à l'image ci-dessous, et vous devrez analyser la liste entière des personnes identifiées:

Conclusion
Ces hypothèses et approches de test démontrent qu'avec absolument n'importe quel ensemble de données, vous pouvez effectuer des tests intéressants et rechercher des anomalies. De nombreux auditeurs tentent maintenant de développer des pratiques similaires, j'ai donc voulu montrer des exemples pratiques d'utilisation de la vision par ordinateur et de l'apprentissage automatique.
Je voudrais également ajouter que nous avons considéré la reconnaissance faciale comme la prochaine hypothèse de test, mais jusqu'à présent, les données et les détails du processus ne fournissent pas une base raisonnable pour l'utilisation de cette technologie dans nos tests.
En général, c'est tout ce que je voudrais vous dire sur notre façon de tester les photos.
Je vous souhaite de bonnes analyses et des données étiquetées!
* L' exemple de code provient de sources ouvertes.