
data science Python –
Pourquoi? Les outils existants sont mal adaptés pour résoudre les problèmes liés aux séries chronologiques et ces outils sont difficiles à intégrer les uns aux autres. Les méthodes de Scikit-learn supposent que les données sont structurées dans un format tabulaire et que chaque colonne se compose de variables aléatoires indépendantes et également distribuées - des hypothèses qui n'ont rien à voir avec les données de séries chronologiques. Les packages qui ont des modules pour l'apprentissage automatique et qui fonctionnent avec des séries chronologiques, telles que les statsmodels , ne sont pas très bons les uns avec les autres. De plus, de nombreuses opérations importantes avec des séries chronologiques, telles que la division des données en ensembles d'apprentissage et de test sur des intervalles de temps, ne sont pas disponibles dans les packages existants. Sktime a
été créé pour résoudre des problèmes similaires .

Logo de la bibliothèque Sktime sur GitHub
Sktime est une boîte à outils d'apprentissage automatique open source en Python spécialement conçue pour travailler avec des séries chronologiques. Ce projet est développé et financé par la communauté par le British Council for Economic and Social Research , Consumer Data Research et l'Institut Alan Turing .
Sktime étend l'API scikit-learn pour résoudre les problèmes de séries chronologiques. Il contient tous les algorithmes et outils de transformation nécessaires pour résoudre efficacement les problèmes de régression, de prévision et de classification des séries chronologiques. La bibliothèque comprend des algorithmes d'apprentissage automatique spéciaux et des méthodes de transformation pour les séries chronologiques introuvables dans d'autres bibliothèques populaires.
Sktime a été conçu pour fonctionner avec scikit-learn, adapter facilement des algorithmes aux problèmes de séries chronologiques interdépendantes et créer des modèles complexes. Comment ça fonctionne? De nombreux problèmes de séries chronologiques sont liés les uns aux autres d'une manière ou d'une autre. Un algorithme qui peut être appliqué pour résoudre un problème peut très souvent être appliqué à la résolution d'un autre qui lui est lié. Cette idée s'appelle la réduction. Par exemple, un modèle de régression de série chronologique (qui utilise une série pour prédire une valeur de sortie) peut être réutilisé pour un problème de prévision de série chronologique (qui prédit une valeur de sortie - une valeur qui sera reçue dans le futur).
L'idée principale du projet:«Sktime offre un apprentissage automatique facile à comprendre et intégrable à l'aide de séries chronologiques. Il possède des algorithmes compatibles avec scikit-learn et des outils de partage de modèles, soutenus par une taxonomie claire des tâches d'apprentissage, une documentation claire et une communauté conviviale. "
Dans cet article, je vais mettre en évidence certaines des fonctionnalités uniques de sktime .
Corriger le modèle de données pour les séries chronologiques
Sktime utilise une structure de données imbriquée pour les séries chronologiques sous la forme de dataframes pandas .
Chaque ligne d'une base de données typique contient des variables aléatoires indépendantes et également distribuées - les observations et les colonnes - différentes variables. Pour les méthodes sktime, chaque cellule d'un dataframe Pandas peut désormais contenir une série chronologique complète. Ce format est flexible pour les données multidimensionnelles, de panel et hétérogènes, et permet la réutilisation des méthodes à la fois dans Pandas et scikit-learn .
Dans le tableau ci-dessous, chaque ligne est une observation contenant un tableau de séries chronologiques dans la colonne X et une valeur de classe dans la colonne Y. Les évaluateurs et les transformateurs sktime sont aptes à travailler avec de telles séries chronologiques.
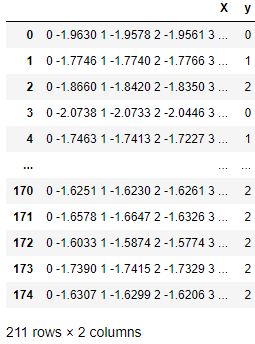
Une structure de données de série chronologique native compatible sktime.
Dans le tableau suivant, chaque élément de la série X a été déplacé vers une colonne distincte comme requis par les méthodes scikit-learn. La dimension est assez élevée - 251 colonnes! En outre, l'ordre temporel des colonnes est ignoré par les algorithmes d'apprentissage qui fonctionnent avec des valeurs tabulaires (mais utilisés par les algorithmes de classification et de régression de séries chronologiques).
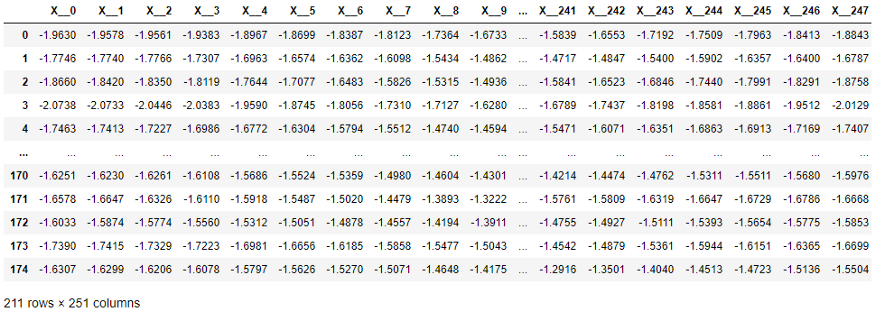
Structure de données de séries chronologiques requise par scikit-learn.
Pour les tâches de modélisation de plusieurs séries conjointes, une structure de données de série chronologique native compatible avec sktime est idéale. Les modèles entraînés sur les données tabulaires attendues par scikit-learn s'enliseront dans de nombreuses fonctionnalités.
Que peut faire sktime ?
Selon la page GitHub , sktime fournit actuellement les fonctionnalités suivantes:
- Algorithmes modernes pour la classification des séries chronologiques, l'analyse de régression et la prévision (portés de la boîte
tsmlà outils vers Java); - Transformateurs de séries chronologiques: transformations de séries uniques (par exemple, décroissance ou désaisonnalisation), transformations de séries en tant que caractéristiques (par exemple, extraction de caractéristiques) et outils de partage de plusieurs transformateurs.
- Pipelines pour transformateurs et modèles;
- Mise en place du modèle;
- Ensemble de modèles, par exemple, forêt aléatoire entièrement personnalisable pour la classification et la régression de séries chronologiques, ensemble pour les problèmes multidimensionnels.
API sktime
Comme mentionné précédemment, sktime prend en charge les méthodes de base API scikit-learn pour les classes
fit, predictet transform.
Pour les classes d'évaluateurs (ou modèles), sktime fournit une méthode
fitpour entraîner le modèle et une méthode predictpour générer de nouvelles prédictions.
Les évaluateurs de sktime développent les covariables et les classificateurs scikit-learn, fournissant des analogues de ces méthodes, capables de travailler avec des séries chronologiques.
Pour les classes sktime transformer fournit des méthodes
fitet transformpour convertir les données de série. Il existe plusieurs types de transformations disponibles:
- , , ;
- , (, );
- (, );
- , , , (, ).
L'exemple suivant est une adaptation du guide de prévision de GitHub . La série de cet exemple (l'ensemble de données de la compagnie aérienne Box-Jenkins) montre le nombre de passagers aériens internationaux par mois de 1949 à 1960.
Tout d'abord, chargez les données et divisez-les en suites d'entraînement et de tests, puis créez un graphique. Dans sktime ont deux fonctionnalités pratiques pour une exécution facile de ces tâches -
temporal_train_test_splitforqui sont séparées par un ensemble de données et de temps plot_ys, tracées sur la base du test et de l'échantillon d'apprentissage.
from sktime.datasets import load_airline
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.utils.plotting.forecasting import plot_ys
y = load_airline()
y_train, y_test = temporal_train_test_split(y)
plot_ys(y_train, y_test, labels=["y_train", "y_test"])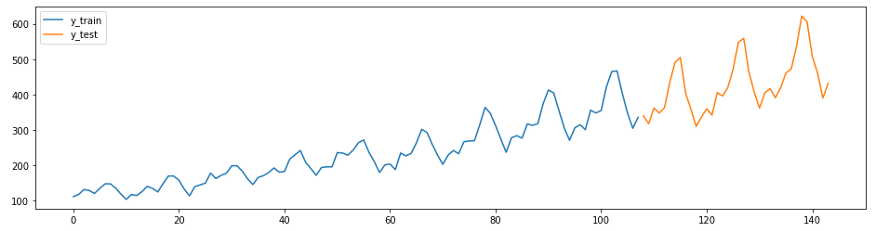
Avant de faire des prévisions complexes, il est utile de comparer votre prévision avec les valeurs obtenues à l'aide d'algorithmes bayésiens naïfs. Un bon modèle doit dépasser ces valeurs. Dans sktime, ayez une méthode
NaiveForecasteravec différentes stratégies pour créer des projections de base.
Le code et le diagramme ci-dessous montrent deux prédictions naïves. Forecaster c
strategy = “last”prédira toujours la dernière valeur de la série.
Forecaster s
strategy = “seasonal_last”prédit la dernière valeur de la série pour la saison donnée. La saisonnalité dans l'exemple est définie comme “sp=12”, c'est-à-dire 12 mois.
from sktime.forecasting.naive import NaiveForecaster
naive_forecaster_last = NaiveForecaster(strategy="last")
naive_forecaster_last.fit(y_train)
y_last = naive_forecaster_last.predict(fh)
naive_forecaster_seasonal = NaiveForecaster(strategy="seasonal_last", sp=12)
naive_forecaster_seasonal.fit(y_train)
y_seasonal_last = naive_forecaster_seasonal.predict(fh)
plot_ys(y_train, y_test, y_last, y_seasonal_last, labels=["y_train", "y_test", "y_pred_last", "y_pred_seasonal_last"]);
smape_loss(y_last, y_test)
>>0.231957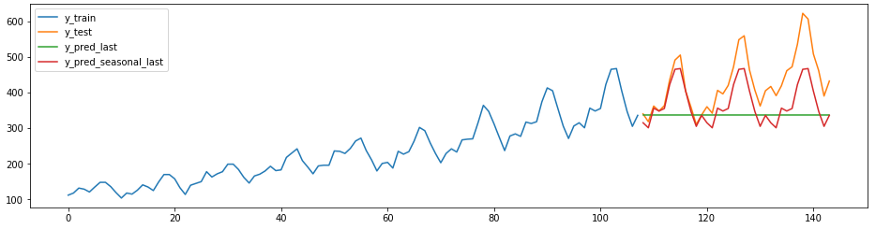
L'extrait de prédiction suivant montre comment les régresseurs sklearn existants peuvent être facilement, correctement et avec un minimum d'effort adaptés pour les tâches de prévision. Vous trouverez ci-dessous une méthode
ReducedRegressionForecasterde sktime qui prédit une série à l'aide d'un modèle sklearnRandomForestRegressor. Sous le capot, sktime divise les données d'entraînement en fenêtres de 12 afin que le régresseur puisse continuer l'entraînement.
from sktime.forecasting.compose import ReducedRegressionForecaster
from sklearn.ensemble import RandomForestRegressor
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.performance_metrics.forecasting import smape_loss
regressor = RandomForestRegressor()
forecaster = ReducedRegressionForecaster(regressor, window_length=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_ys(y_train, y_test, y_pred, labels=['y_train', 'y_test', 'y_pred'])
smape_loss(y_test, y_pred)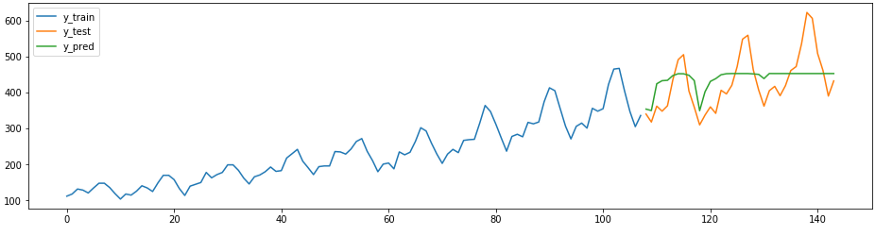
Dans sktime ont également leurs propres méthodes de prévision, par exemple
AutoArima.
from sktime.forecasting.arima import AutoARIMA
forecaster = AutoARIMA(sp=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_ys(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"]);
smape_loss(y_test, y_pred)
>>0.07395319887252469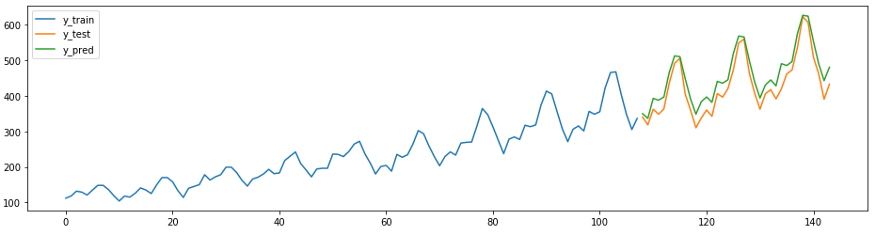
Pour approfondir la fonctionnalité de prévision sktime , consultez le didacticiel ici .
Classification des séries chronologiques
Il
sktimepeut également être utilisé pour classer les séries chronologiques en différents groupes.
Dans l'exemple de code ci-dessous, la classification de séries chronologiques uniques est aussi simple que la classification dans scikit-learn. La seule différence est la structure de données de séries temporelles imbriquées dont nous avons parlé ci-dessus.
from sktime.datasets import load_arrow_head
from sktime.classification.compose import TimeSeriesForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X, y = load_arrow_head(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y)
classifier = TimeSeriesForestClassifier()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
accuracy_score(y_test, y_pred)
>>0.8679245283018868L'exemple est tiré de pypi.org/project/sktime
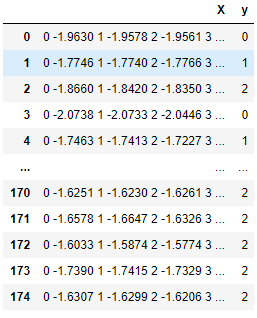
Données transmises à TimeSeriesForestClassifier
Pour en savoir plus sur la classification des séries, consultez les didacticiels de classification univariée et multidimensionnelle de sktime .
Ressources sktime supplémentaires
Pour en savoir plus sur Sktime, consultez les liens suivants pour obtenir de la documentation et des exemples.
- Description détaillée de l'API: sktime.org
- sktime GitHub ( );
- ;
- Sktime: Markus Löning, Anthony Bagnall, Sajaysurya Ganesh, Viktor Kazakov, Jason Lines, Franz Király (2019): “sktime: A Unified Interface for Machine Learning with Time Series”
. .