Vous pouvez le faire manuellement, mais il existe également des frameworks et des bibliothèques pour cela qui rendent ce processus plus rapide et plus facile. Aujourd'hui, nous allons parler
de l'un d'entre eux, des outils de fonctionnalités , ainsi que de l'expérience pratique de son utilisation.

Le pipeline le plus en vogue
salut! Je suis Alexander Loskutov, je travaille chez Leroy Merlin en tant qu'analyste de données, ou, comme il est à la mode de l'appeler maintenant, en tant que data scientist. Mes responsabilités incluent le travail avec les données, en commençant par les requêtes analytiques et le déchargement, en terminant par la formation du modèle, en l'enveloppant, par exemple, dans un service, en configurant la livraison et le déploiement du code et en surveillant son travail.
Undo Prediction est l'un des produits sur lesquels je travaille.
Objectif du produit: prédire la probabilité qu'un client annule une commande en ligne. Avec l'aide d'une telle prédiction, nous pouvons déterminer lequel des clients qui ont passé une commande doit être appelé en premier pour demander de confirmer la commande, et qui peut ne pas être appelé du tout. Premièrement, le fait même d'un appel et de la confirmation d'une commande d'un client par téléphone réduit la probabilité d'annulation, et deuxièmement, si nous appelons et que la personne refuse, nous pouvons économiser des ressources. Plus de temps sera libéré pour les employés, qu'ils auraient passé à récupérer la commande. De plus, de cette façon, le produit restera sur les étagères, et si à ce moment le client du magasin en a besoin, il pourra l'acheter. Et cela réduira le nombre de marchandises qui ont été collectées lors de commandes annulées ultérieurement et qui n'étaient pas présentes sur les étagères.
Précurseurs
Pour le pilote de produit, nous prenons uniquement les commandes postpayées pour le ramassage dans plusieurs magasins.
Une solution toute faite fonctionne comme ceci: une commande nous parvient, avec l'aide d'Apache NiFi, nous enrichissons les informations dessus - par exemple, en extrayant des données sur les marchandises. Ensuite, tout cela est transféré via le courtier de messages Apache Kafka vers le service écrit en Python. Le service calcule les caractéristiques de la commande, puis un modèle d'apprentissage automatique est utilisé pour celles-ci, ce qui donne la probabilité d'annulation. Après cela, conformément à la logique métier, nous préparons une réponse pour savoir si nous devons appeler le client maintenant ou non (par exemple, si la commande a été passée avec l'aide d'un employé à l'intérieur du magasin ou si la commande a été passée la nuit, vous ne devez pas appeler).
Il semblerait, qu'est-ce qui empêche d'appeler tout le monde d'affilée? Le fait est que nous disposons d'un nombre limité de ressources pour les appels, il est donc important de comprendre qui doit absolument appeler et qui récupérera définitivement sa commande sans appel.
Développement d'un modèle
J'étais engagé dans le service, le modèle et, par conséquent, le calcul des caractéristiques du modèle, qui seront discutés plus loin.
Lors du calcul des fonctionnalités pendant l'entraînement, nous utilisons trois sources de données.
- Plaque avec les méta-informations de la commande: numéro de commande, horodatage, appareil client, mode de livraison, mode de paiement.
- Plaque avec positions dans les reçus: numéro de commande, article, prix, quantité, quantité de marchandises en stock. Chaque position va sur une ligne distincte.
- Tableau - un livre de référence de produits: article, plusieurs champs avec une catégorie de produits, unités de mesure, description.
En utilisant les méthodes Python standard et la bibliothèque pandas, vous pouvez facilement combiner toutes les tables en une seule grande, après quoi, en utilisant groupby, vous pouvez calculer toutes sortes d'attributs tels que des agrégats par ordre, historique par produit, par catégorie de produit, etc. Mais il y a plusieurs problèmes ici.
- Parallélisme des calculs. Le groupby standard fonctionne dans un seul thread, et sur le Big Data (jusqu'à 10 millions de lignes), une centaine de fonctionnalités est considérée comme inacceptable, tandis que la capacité des cœurs restants est inactive.
- La quantité de code: chaque demande de ce type doit être écrite séparément, vérifiée pour son exactitude, puis tous les résultats doivent encore être collectés. Cela prend du temps, en particulier compte tenu de la complexité de certains calculs - par exemple, calculer le dernier historique d'un article dans un reçu et agréger ces caractéristiques pour une commande.
- Vous pouvez faire des erreurs si vous codez tout à la main.
L'avantage de l'approche «nous écrivons tout à la main» est bien sûr une totale liberté d'action, vous pouvez laisser libre cours à votre imagination.
La question se pose: comment optimiser cette partie du travail. Une solution consiste à utiliser la bibliothèque featuretools .
Ici, nous passons déjà à l'essence de cet article, à savoir la bibliothèque elle-même et la pratique de son utilisation.
Pourquoi featuretools?
Considérons divers cadres d'apprentissage automatique sous la forme d'une plaque (l'image elle-même est honnêtement volée à partir d'ici , et très probablement pas tous y sont indiqués, mais quand même):
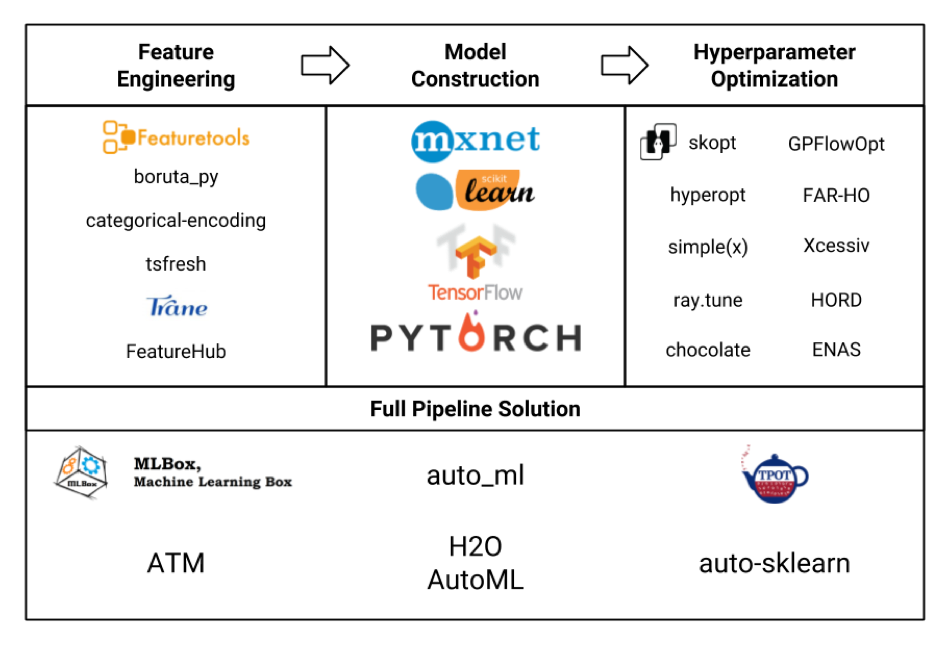
Nous sommes principalement intéressés par le bloc Feature Engineering. Si nous regardons tous ces frameworks et packages, il s'avère que featuretools est le plus sophistiqué d'entre eux, et il inclut même les fonctionnalités de certaines autres bibliothèques comme tsfresh .
En outre, les avantages des featuretools (pas de publicité du tout!) Comprennent:
- calcul parallèle prêt à l'emploi
- disponibilité de nombreuses fonctionnalités prêtes à l'emploi
- flexibilité dans la personnalisation - des choses assez complexes peuvent être envisagées
- prise en compte des relations entre différentes tables (relationnelles)
- moins de code
- moins susceptible de faire une erreur
- tout seul, tout est gratuit, sans inscription et sans SMS (mais avec pypi)
Mais ce n'est pas si simple.
- Le cadre nécessite un certain apprentissage et une maîtrise complète prendra un temps décent.
- Il n'a pas une communauté aussi grande, bien que les questions les plus populaires continuent de bien sur Google.
- L'utilisation elle-même nécessite également des précautions afin de ne pas gonfler inutilement l'espace des fonctionnalités et de ne pas augmenter le temps de calcul.
Entraînement
Je vais donner un exemple de la configuration des featuretools.
Ensuite, il y aura un code avec de brèves explications, plus en détail sur featuretools, ses classes, méthodes, capacités, que vous pouvez lire, y compris dans la documentation sur le site Web du framework. Si vous êtes intéressé par des exemples d'application pratique avec une démonstration de certaines possibilités intéressantes dans des tâches réelles, écrivez dans les commentaires, peut-être que j'écrirai un article séparé.
Alors.
Tout d'abord, vous devez créer un objet de la classe EntitySet, qui contient des tables avec des données et connaît leur relation les unes avec les autres.
Permettez-moi de vous rappeler que nous avons trois tableaux avec des données:
- orders_meta (méta-informations de commande)
- orders_items_lists (informations sur les articles dans les commandes)
- articles (référence des articles et de leurs propriétés)
Nous écrivons (de plus, les données de seulement 3 magasins sont utilisées):
import featuretools as ft
es = ft.EntitySet(id='orders') # EntitySet
# pandas.DataFrame- (ft.Entity)
es = es.entity_from_dataframe(entity_id='orders_meta',
dataframe=orders_meta,
index='order_id',
time_index='order_creation_dt')
es = es.entity_from_dataframe(entity_id='orders_items',
dataframe=orders_items_lists,
index='order_item_id')
es = es.entity_from_dataframe(entity_id='items',
dataframe=items,
index='item',
variable_types={
'subclass': ft.variable_types.Categorical
})
#
# -,
# -
relationship_orders_items_list = ft.Relationship(es['orders_meta']['order_id'],
es['orders_items']['order_id'])
relationship_items_list_items = ft.Relationship(es['items']['item'],
es['orders_items']['item'])
#
es = es.add_relationship(relationship_orders_items_list)
es = es.add_relationship(relationship_items_list_items)

Hourra! Nous avons maintenant un objet qui nous permettra de compter toutes sortes de signes.
Je vais donner un code pour calculer des caractéristiques assez simples: pour chaque commande, nous calculerons diverses statistiques sur les prix et la quantité de marchandises, ainsi que quelques caractéristiques par temps et les produits et catégories de marchandises les plus fréquents dans la commande (les fonctions qui effectuent diverses transformations avec des données sont appelées primitives dans featuretools) ...
orders_aggs, orders_aggs_cols = ft.dfs(
entityset=es,
target_entity='orders_meta',
agg_primitives=['mean', 'count', 'mode', 'any'],
trans_primitives=['hour', 'weekday'],
instance_ids=[200315133283, 200315129511, 200315130383],
max_depth=2
)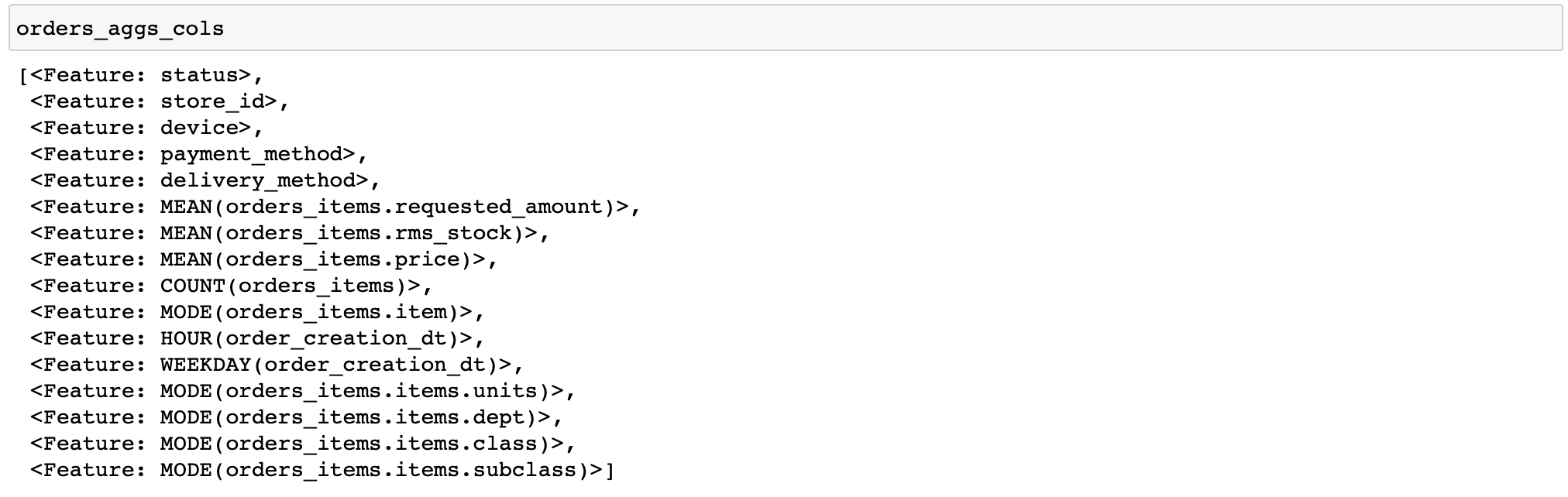

Il n'y a pas de colonnes booléennes dans les tables, donc la primitive any n'a pas été appliquée. En général, il est pratique que featuretools analyse lui-même le type de données et n'applique que les fonctions appropriées.
De plus, je n'ai spécifié manuellement que quelques commandes pour le calcul. Cela vous permet de déboguer rapidement vos calculs (que faire si vous avez configuré quelque chose de mal).
Ajoutons maintenant quelques agrégats supplémentaires à nos fonctionnalités, à savoir les centiles. Mais les featuretools n'ont pas de primitives intégrées pour les calculer. Vous devez donc l'écrire vous-même.
from featuretools.variable_types import Numeric
from featuretools.primitives.base.aggregation_primitive_base import make_agg_primitive
def percentile05(x: pandas.Series) -> float:
return numpy.percentile(x, 5)
def percentile25(x: pandas.Series) -> float:
return numpy.percentile(x, 25)
def percentile75(x: pandas.Series) -> float:
return numpy.percentile(x, 75)
def percentile95(x: pandas.Series) -> float:
return numpy.percentile(x, 95)
percentiles = [percentile05, percentile25, percentile75, percentile95]
custom_agg_primitives = [make_agg_primitive(function=fun,
input_types=[Numeric],
return_type=Numeric,
name=fun.__name__)
for fun in percentiles]
Et ajoutez-les au calcul:
orders_aggs, orders_aggs_cols = ft.dfs(
entityset=es,
target_entity='orders_meta',
agg_primitives=['mean', 'count', 'mode', 'any'] + custom_agg_primitives,
trans_primitives=['hour', 'weekday'],
instance_ids=[200315133283, 200315129511, 200315130383],
max_depth=2
)Alors tout est pareil. Jusqu'à présent, tout est assez simple et facile (relativement, bien sûr).
Que faire si nous voulons enregistrer notre calculateur de fonctionnalités et l'utiliser au stade de l'exécution du modèle, c'est-à-dire dans le service?
Outils en vedette au combat
C'est là que commencent les principales difficultés.
Pour calculer les caractéristiques d'une commande entrante, vous devrez refaire toutes les opérations avec la création de l'EntitySet. Et si pour les grandes tables, il semble tout à fait normal de lancer des objets pandas.DataFrame dans l'EntitySet, puis de faire des opérations similaires pour les DataFrames à partir d'une ligne (il y en a plus dans la table avec des vérifications, mais en moyenne 3,3 positions par vérification, ce n'est pas suffisant) - pas beaucoup. Après tout, la création de tels objets et calculs avec leur aide contient inévitablement une surcharge, c'est-à-dire un nombre inamovible d'opérations nécessaires, par exemple, pour l'allocation de mémoire et l'initialisation lors de la création d'un objet de n'importe quelle taille ou le processus de parallélisation lui-même lors du calcul de plusieurs entités simultanément.
Par conséquent, dans le mode de fonctionnement "une commande à la fois" dans nos fonctionnalités de produit, les outils ne montrent pas la meilleure efficacité, prenant en moyenne 75% du temps de réponse du service (en moyenne 150-200 ms selon le matériel). À titre de comparaison: le calcul d'une prédiction à l'aide de catboost sur des fonctionnalités prêtes à l'emploi prend 3% du temps de réponse du service, c'est-à-dire pas plus de 10 ms.
En outre, il existe un autre écueil associé à l'utilisation de primitives personnalisées. Le fait est que nous ne pouvons pas simplement enregistrer dans pickle un objet de la classe contenant les primitives que nous avons créées, puisque ces dernières ne sont pas pickle.
Alors pourquoi ne pas utiliser la fonction intégrée save_features (), qui peut enregistrer une liste d'objets FeatureBase, y compris les primitives que nous avons créées?
Cela les sauvera, mais il ne sera pas possible de les lire plus tard en utilisant la fonction load_features () si nous ne les recréons pas à l'avance. Autrement dit, les primitives que nous, en théorie, devrions lire à partir du disque, nous les créons d'abord à nouveau afin de ne plus jamais les utiliser.
Cela ressemble à ceci:
from __future__ import annotations
import multiprocessing
import pickle
from typing import List, Optional, Any, Dict
import pandas
from featuretools import EntitySet, dfs, calculate_feature_matrix, save_features, load_features
from featuretools.feature_base.feature_base import FeatureBase, AggregationFeature
from featuretools.primitives.base.aggregation_primitive_base import make_agg_primitive
# -
# ,
#
#
# ( ),
# ,
class AggregationFeaturesCalculator:
def __init__(self,
target_entity: str,
agg_primitives: List[str],
custom_primitives_params: Optional[List[Dict[str, Any]]] = None,
max_depth: int = 2,
drop_contains: Optional[List[str]] = None):
if custom_primitives_params is None:
custom_primitives_params = []
if drop_contains is None:
drop_contains = []
self._target_entity = target_entity
self._agg_primitives = agg_primitives
self._custom_primitives_params = custom_primitives_params
self._max_depth = max_depth
self._drop_contains = drop_contains
self._features = None # ( ft.FeatureBase)
@property
def features_are_built(self) -> bool:
return self._features is not None
@property
def features(self) -> List[AggregationFeature]:
if self._features is None:
raise AttributeError('features have not been built yet')
return self._features
#
def build_features(self, entity_set: EntitySet) -> None:
custom_primitives = [make_agg_primitive(**primitive_params)
for primitive_params in self._custom_primitives_params]
self._features = dfs(
entityset=entity_set,
target_entity=self._target_entity,
features_only=True,
agg_primitives=self._agg_primitives + custom_primitives,
trans_primitives=[],
drop_contains=self._drop_contains,
max_depth=self._max_depth,
verbose=False
)
# ,
#
@staticmethod
def calculate_from_features(features: List[FeatureBase],
entity_set: EntitySet,
parallelize: bool = False) -> pandas.DataFrame:
n_jobs = max(1, multiprocessing.cpu_count() - 1) if parallelize else 1
return calculate_feature_matrix(features=features, entityset=entity_set, n_jobs=n_jobs)
#
def calculate(self, entity_set: EntitySet, parallelize: bool = False) -> pandas.DataFrame:
if not self.features_are_built:
self.build_features(entity_set)
return self.calculate_from_features(features=self.features,
entity_set=entity_set,
parallelize=parallelize)
#
# ,
# save_features()
#
@staticmethod
def save(calculator: AggregationFeaturesCalculator, path: str) -> None:
result = {
'target_entity': calculator._target_entity,
'agg_primitives': calculator._agg_primitives,
'custom_primitives_params': calculator._custom_primitives_params,
'max_depth': calculator._max_depth,
'drop_contains': calculator._drop_contains
}
if calculator.features_are_built:
result['features'] = save_features(calculator.features)
with open(path, 'wb') as f:
pickle.dump(result, f)
#
@staticmethod
def load(path: str) -> AggregationFeaturesCalculator:
with open(path, 'rb') as f:
arguments_dict = pickle.load(f)
# ...
if arguments_dict['custom_primitives_params']:
custom_primitives = [make_agg_primitive(**custom_primitive_params)
for custom_primitive_params in arguments_dict['custom_primitives_params']]
features = None
#
if 'features' in arguments_dict:
features = load_features(arguments_dict.pop('features'))
calculator = AggregationFeaturesCalculator(**arguments_dict)
if features:
calculator._features = features
return calculatorDans la fonction load (), vous devez créer des primitives (en déclarant la variable custom_primitives) qui ne seront pas utilisées. Mais sans cela, le chargement de fonctionnalités supplémentaires à l'endroit où la fonction load_features () est appelée échouera avec le RuntimeError: Primitive "percentile05" dans le module "featuretools.primitives.base.aggregation_primitive_base" introuvable .
Cela ne s'avère pas très logique, mais cela fonctionne, et vous pouvez enregistrer à la fois la calculatrice déjà liée à un format de données spécifique (puisque les fonctionnalités sont liées à l'EntitySet pour lequel elles ont été calculées, bien que sans les valeurs elles-mêmes), et la calculatrice uniquement avec une liste donnée de primitives.
Peut-être que dans le futur cela sera corrigé et il sera possible de sauvegarder commodément un ensemble arbitraire d'objets FeatureBase.
Pourquoi l'utilisons-nous alors?
Car du point de vue du temps de développement, il est bon marché, alors que le temps de réponse sous la charge existante s'inscrit dans notre SLA (5 secondes) avec une marge.
Cependant, vous devez être conscient que pour un service qui doit répondre rapidement aux demandes fréquemment reçues, utiliser des outils fonctionnels sans "squats" supplémentaires comme les appels asynchrones sera problématique.
C'est notre expérience d'utilisation des outils de fonctionnalités aux stades d'apprentissage et d'inférence.
Ce cadre est très bon comme outil pour calculer rapidement un grand nombre de fonctionnalités pour la formation, il réduit considérablement le temps de développement et réduit la probabilité d'erreurs.
Le fait de l'utiliser au stade du retrait dépend de vos tâches.