
Qui suis je
Je m'appelle Dmitry Ivanov. Je suis étudiante de deuxième cycle en économie au HSE de Saint-Pétersbourg. Je travaille dans le groupe de recherche « Systèmes d'agents et apprentissage par renforcement » de JetBrains Research , ainsi qu'au Laboratoire international de théorie des jeux et de prise de décision à l'École supérieure d'économie . En plus de l'apprentissage PU, je m'intéresse à l'apprentissage par renforcement et à la recherche à l'intersection de l'apprentissage automatique et de l'économie.
Préambule
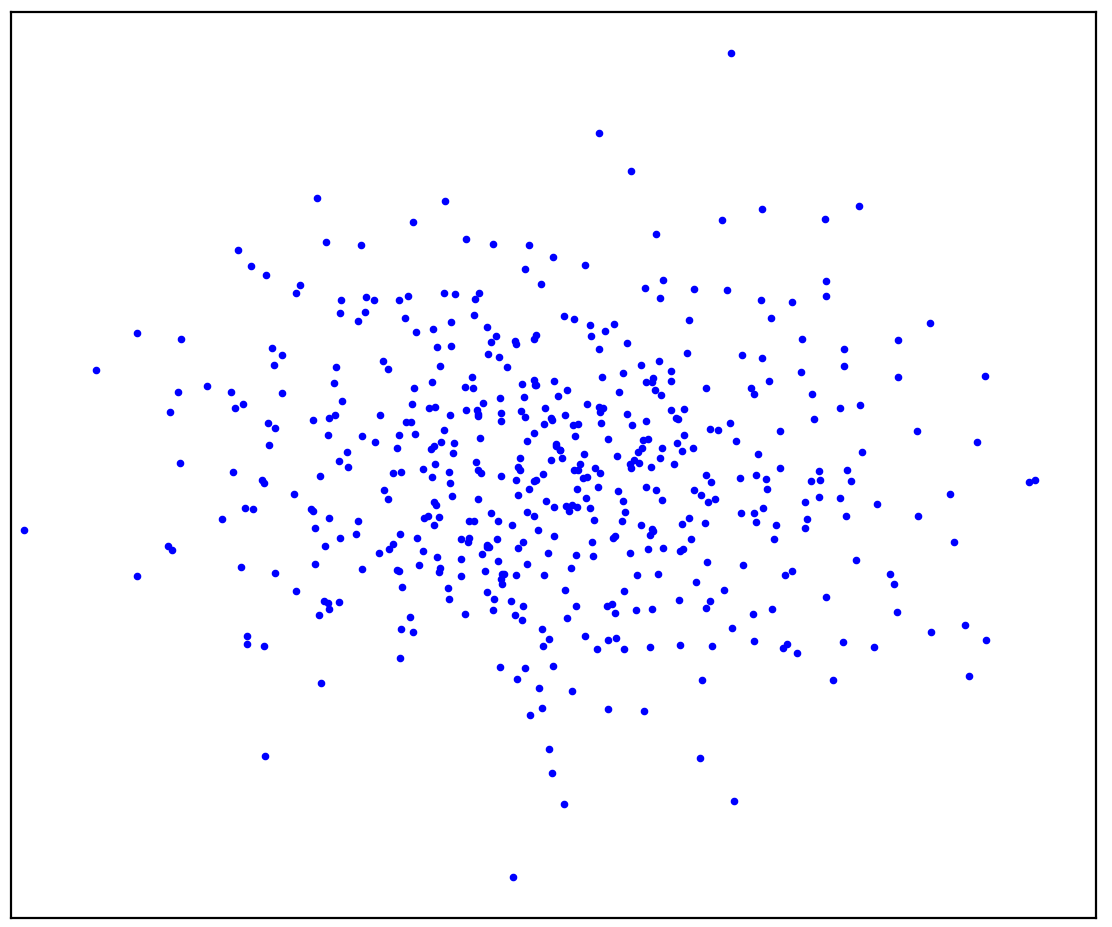
Figure: 1a. Données positives La
figure 1a montre un ensemble de points générés par une certaine distribution, que nous appellerons positifs. Tous les autres points possibles qui n'appartiennent pas à la distribution positive seront appelés négatifs. Essayez de tracer mentalement une ligne séparant les points positifs présentés de tous les points négatifs possibles. En passant, cette tâche est appelée "détection d'anomalies".
La réponse est ici

. 1.
. 1.
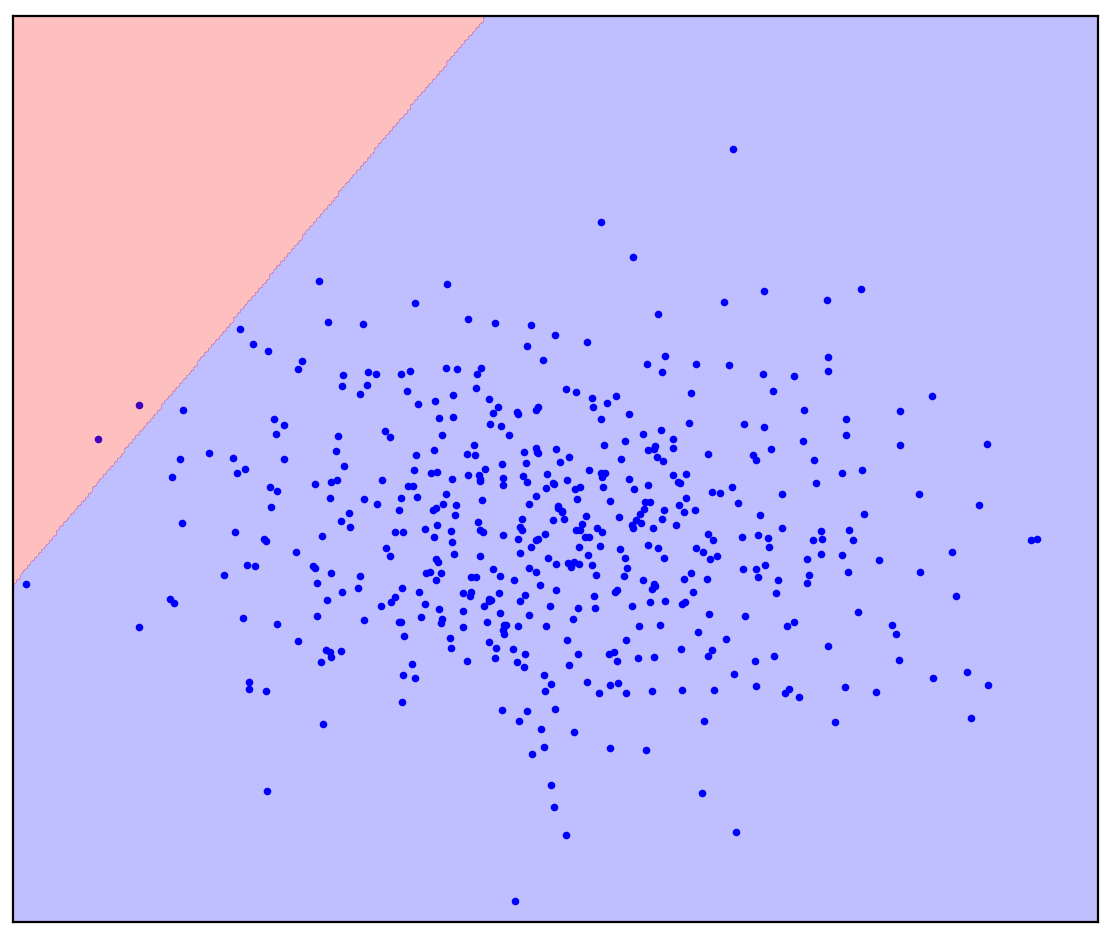
Vous avez peut-être imaginé quelque chose comme la figure 1b: encerclé les données dans une ellipse. En fait, c'est le nombre de méthodes de détection d'anomalies qui fonctionnent.
Maintenant, changeons un peu le problème: ayons des informations supplémentaires qu'une ligne droite devrait séparer les points positifs des points négatifs. Essayez de le dessiner dans votre esprit.
La réponse est ici
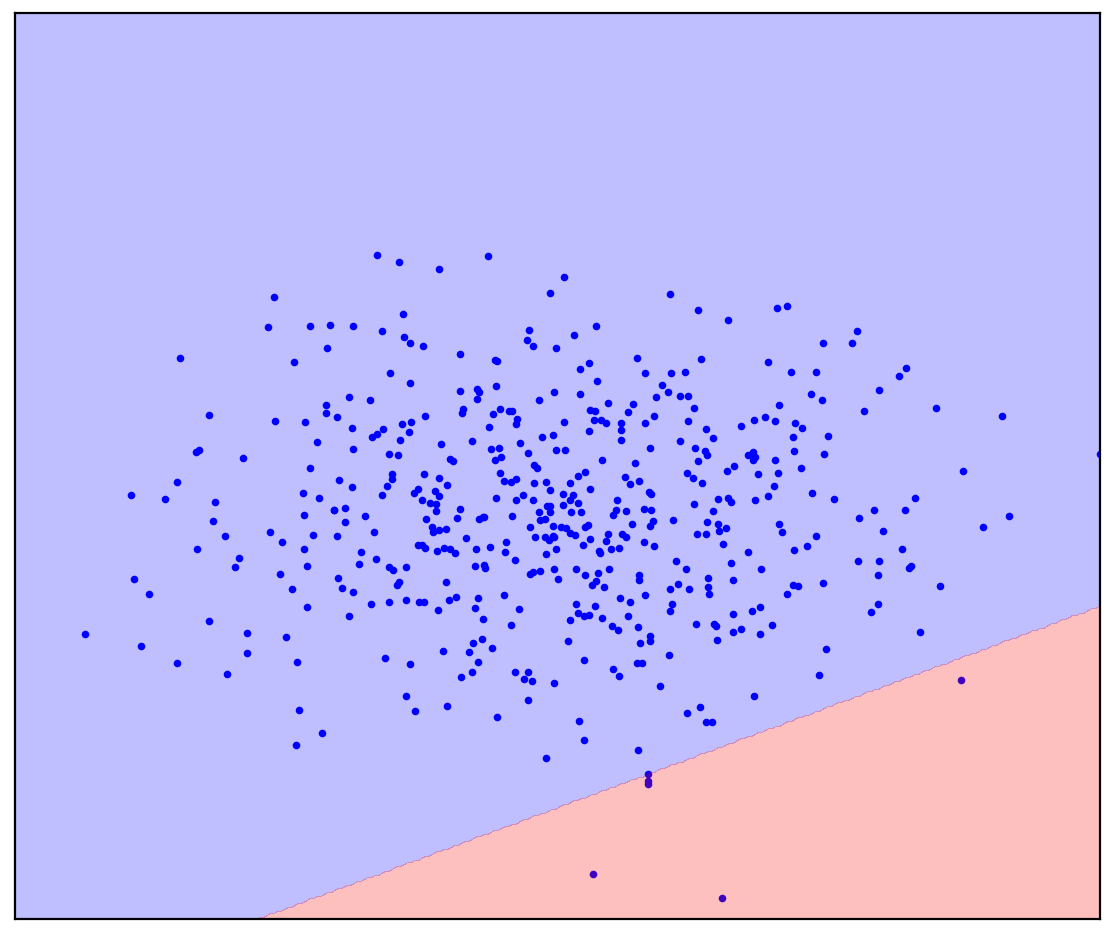
. 1. ( One-Class SVM)
. 1. ( One-Class SVM)
Dans le cas d'une ligne de démarcation droite, il n'y a pas de réponse unique. On ne sait pas dans quelle direction tracer une ligne droite.
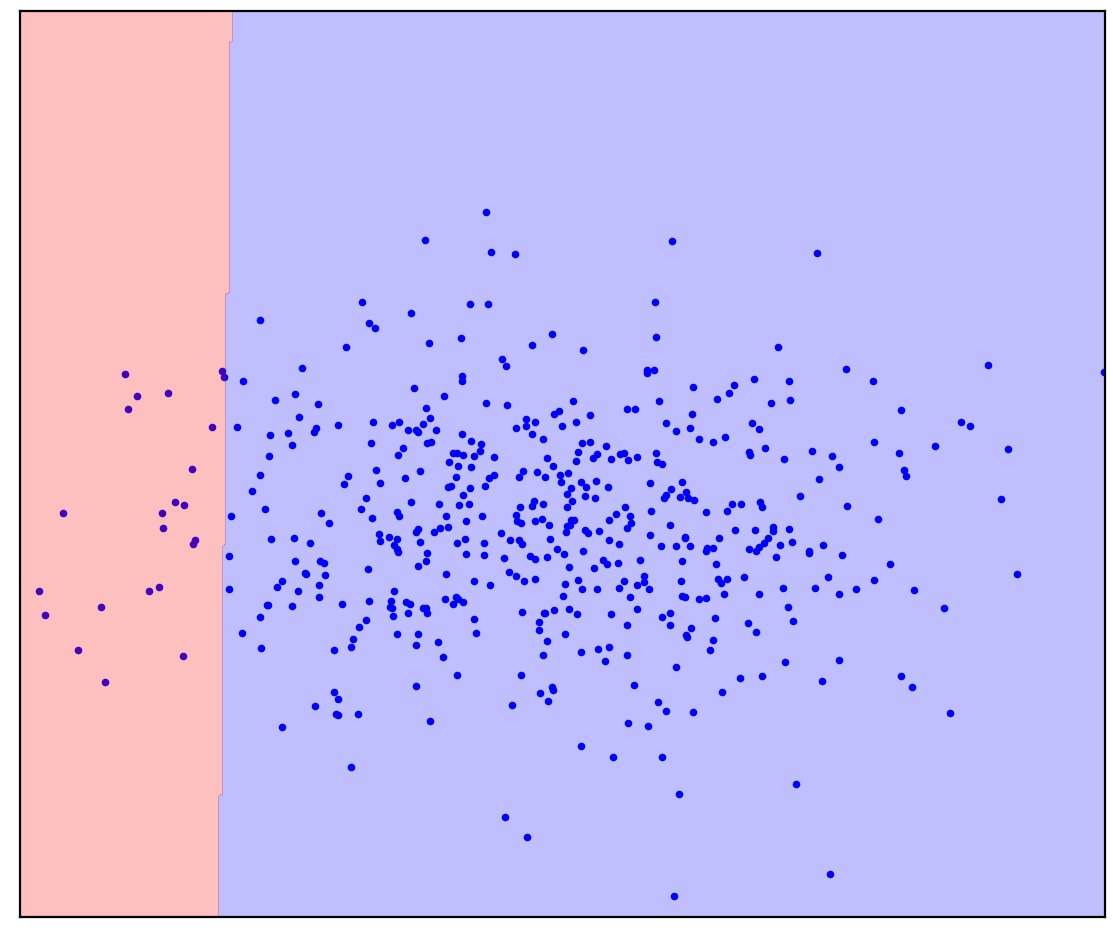
Maintenant, je vais ajouter quelques points non alloués à la figure 1d qui contiennent un mélange de positif et de négatif. Pour la dernière fois, je vais vous demander de faire un effort mental et d'imaginer une ligne séparant les points positifs et négatifs. Mais cette fois, vous pouvez utiliser des données non étiquetées!

Figure: 1d. Points positifs (bleus) et non étiquetés (rouges). Les points non marqués sont composés de points positifs et négatifs
La réponse est ici

. 1.
. 1.
C'est devenu plus facile! Bien que nous ne sachions pas à l'avance comment chaque point non marqué est généré, nous pouvons grossièrement les marquer en les comparant avec des points positifs. Les points rouges qui ressemblent à du bleu sont probablement positifs. Au contraire, les dissemblables sont probablement négatifs. En conséquence, bien que nous ne disposions pas de données négatives «propres», des informations à leur sujet peuvent être obtenues à partir du mélange non étiqueté et utilisées pour une classification plus précise. C'est ce que font les algorithmes d'apprentissage Positive-Unlabeled, dont je veux parler.
introduction
L'apprentissage positif-non étiqueté (PU) peut être traduit par «apprendre à partir de données positives et non étiquetées». En fait, l'apprentissage PU est un analogue d'une classification binaire pour les cas où il y a des données étiquetées d'une seule des classes, mais un mélange non étiqueté de données des deux classes est disponible. Dans le cas général, nous ne savons même pas combien de données dans le mélange correspondent à une classe positive et combien à une classe négative. Sur la base de tels ensembles de données, nous voulons construire un classificateur binaire: le même qu'en présence de données pures des deux classes.
Comme exemple de jouet, considérons un classificateur pour les photos de chats et de chiens. Nous avons quelques photos de chats et bien d'autres photos de chats et de chiens. En sortie, nous voulons obtenir un classificateur: une fonction qui prédit pour chaque image la probabilité qu'un chat soit représenté. En même temps, le classificateur peut marquer notre mélange existant d'images pour chats et chiens. Dans le même temps, il peut être difficile / coûteux / long / impossible de marquer manuellement des images pour entraîner le classificateur, vous voulez le faire sans lui.
L'apprentissage PU est une tâche assez naturelle. Les données trouvées dans le monde réel sont souvent sales. La capacité d'apprendre à partir de données sales semble être un hack de vie utile de qualité relativement élevée. Malgré cela, j'ai rencontré paradoxalement peu de personnes qui ont entendu parler de l'apprentissage PU, et encore moins qui auraient connu des méthodes spécifiques. J'ai donc décidé de parler de ce domaine.

Figure: 2. Jürgen Schmidhuber et Yann LeCun, NeurIPS 2020
Application de l'apprentissage PU
Je diviserai de manière informelle les cas dans lesquels l'apprentissage PU peut être utile en trois catégories.
La première catégorie est probablement la plus évidente: l'apprentissage PU peut être utilisé à la place de la classification binaire habituelle. Dans certaines tâches, les données sont intrinsèquement légèrement sales. En principe, cette contamination peut être ignorée et un classificateur conventionnel peut être utilisé. Mais il est possible de modifier très peu la fonction de perte lors de l'entraînement du classificateur (Kiryo et al., 2017) ou même les prédictions elles-mêmes après l'entraînement (Elkan & Noto, 2008) , et la classification devient plus précise.
À titre d'exemple, considérons l'identification de nouveaux gènes responsables du développement des gènes de la maladie. L'approche standard consiste à traiter les gènes de la maladie déjà trouvés comme positifs et tous les autres gènes comme négatifs. Il est clair que des gènes de maladie non encore trouvés peuvent être présents dans ces données négatives. De plus, la tâche elle-même est de trouver ces gènes de maladies parmi les données «négatives». Cette contradiction interne est remarquée ici: (Yang et al., 2012) . Les chercheurs se sont écartés de l'approche standard et ont considéré les gènes non liés à des gènes de maladies déjà découverts comme un mélange non marqué, puis ont appliqué des méthodes d'apprentissage PU.
Un autre exemple est l'apprentissage par renforcement basé sur des démonstrations d'experts. Le défi est de former l'agent à agir de la même manière qu'un expert. Ceci peut être réalisé en utilisant la méthode d'apprentissage par imitation et confrontation générative (GAIL). GAIL utilise une architecture de type GAN (réseaux antagonistes génératifs): l'agent génère des trajectoires pour que le discriminateur (classifieur) ne puisse pas les distinguer des démonstrations de l'expert. Des chercheurs de DeepMind ont récemment remarqué que dans GAIL, le discriminateur résout le problème d'apprentissage PU (Xu & Denil, 2019)... Habituellement, le discriminateur considère les données expertes comme positives et les données générées comme négatives. Cette approximation est suffisamment précise au début de l'entraînement lorsque le générateur est incapable de produire des données qui semblent positives. Cependant, à mesure que l'apprentissage progresse, les données générées ressemblent davantage à des données d'experts jusqu'à ce qu'elles deviennent indiscernables pour le discriminateur à la fin de l'apprentissage. Pour cette raison, les chercheurs (Xu et Denil, 2019) considèrent les données générées comme des données non étiquetées avec un rapport de mélange variable. Plus tard, le GAN a été modifié de la même manière lors de la génération d'images (Guo et al., 2020) .

Figure: 3. L'apprentissage PU comme un analogue de la classification PN standard
Dans la deuxième catégorie, l' apprentissage PU peut être utilisé pour la détection d'anomalies comme un analogue de la classification à une classe (OCC). Nous avons déjà vu dans le préambule comment des données non étiquetées exactement peuvent aider. Toutes les méthodes OSS, sans exception, sont obligées de faire une hypothèse sur la distribution des données négatives. Par exemple, il est sage d'encercler les données positives dans une ellipse (une hypersphère dans le cas multidimensionnel), en dehors de laquelle tous les points sont négatifs. Dans ce cas, nous supposons que les données négatives sont uniformément réparties (Blanchard et al., 2010)... Au lieu de faire de telles hypothèses, les méthodes d'apprentissage PU peuvent estimer la distribution des données négatives sur la base des données non étiquetées. Ceci est particulièrement important si les distributions des deux classes se chevauchent fortement (Scott et Blanchard, 2009) . Un exemple de détection d'anomalies à l'aide de l'apprentissage PU est la détection de faux avis (Ren et al., 2014) .

Figure: 4. Un exemple de faux avis
Détection de la corruption dans les enchères de marchés publics russes
La troisième catégorie d'apprentissage PU peut être attribuée à des problèmes dans lesquels ni la classification binaire ni la classification à classe unique ne peuvent être utilisées. À titre d'exemple, je vais vous parler de notre projet de détection de la corruption dans les enchères des marchés publics russes (Ivanov & Nesterov, 2019) .
Selon la législation, des données complètes sur toutes les enchères de marchés publics sont accessibles au public pour tous ceux qui souhaitent passer un mois à les analyser. Nous avons collecté des données de plus d'un million d'enchères organisées de 2014 à 2018. Qui a mis, quand et combien, qui a gagné, pendant quelle période l'enchère a eu lieu, qui a tenu, ce qui a acheté - tout cela est dans les données. Mais, bien sûr, il n'y a pas d'étiquette «la corruption est ici», donc vous ne pouvez pas construire un classificateur ordinaire. Au lieu de cela, nous avons appliqué l'apprentissage PU. Hypothèse de base: les participants bénéficiant d'un avantage injuste gagneront toujours. En utilisant cette hypothèse, les perdants des enchères peuvent être considérés comme équitables (positifs) et les gagnants comme potentiellement malhonnêtes (non marqués).Lorsqu'elles sont configurées de cette manière, les méthodes d'apprentissage PU peuvent trouver des modèles suspects dans les données en fonction de différences subtiles entre les gagnants et les perdants. Bien sûr, dans la pratique, des difficultés surgissent: une conception précise des caractéristiques du classificateur, une analyse de l'interprétabilité de ses prédictions et une vérification statistique des hypothèses sur les données sont nécessaires.
Selon notre estimation très prudente, environ 9% des ventes aux enchères dans les données sont corrompues, ce qui fait que l'État perd environ 120 millions de roubles par an. Les pertes peuvent ne pas sembler très importantes, mais les enchères que nous étudions n'occupent qu'environ 1% du marché des marchés publics.


Figure: 5. La part des enchères de marchés publics corrompus dans différentes régions de Russie (Ivanov et Nesterov, 2019)
Remarques finales
Afin de ne pas donner l'impression que l'UP est la solution à tous les problèmes de l'humanité, je mentionnerai les écueils. Dans une classification conventionnelle, plus nous avons de données, plus le classificateur peut être précis. De plus, en augmentant la quantité de données à l'infini, nous pouvons approcher le classificateur idéal (selon la formule bayésienne). Ainsi, le principal inconvénient de l'apprentissage PU est qu'il s'agit d'un problème mal posé, c'est-à-dire d'un problème qui ne peut pas être résolu sans ambiguïté même avec une quantité infinie de données. La situation s'améliore si la proportion de deux classes dans les données non étiquetées est connue, mais la détermination de cette proportion est également un problème mal posé (Jain et al., 2016)... Le mieux que nous puissions définir est l'espacement de la proportion. De plus, les méthodes d'apprentissage PU n'offrent souvent pas de moyens d'estimer cette proportion et de la considérer comme connue. Il existe des méthodes distinctes pour l'estimer (la tâche est appelée Estimation de la proportion de mélange), mais elles sont souvent lentes et / ou instables, en particulier lorsque les deux classes sont très inégalement représentées dans le mélange.
Dans cet article, j'ai parlé de la définition intuitive et de l'application de l'apprentissage PU. De plus, je peux parler de la définition formelle de l'apprentissage PU avec des formules et de leurs explications, ainsi que des méthodes d'apprentissage PU classiques et modernes. Si cet article suscite l'intérêt, j'écrirai une suite.
Bibliographie
Blanchard, G., Lee, G., & Scott, C. (2010). Semi-supervised novelty detection. Journal of Machine Learning Research, 11(Nov), 2973–3009.
Elkan, C., & Noto, K. (2008). Learning classifiers from only positive and unlabeled data. Proceeding of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining — KDD 08, 213. https://doi.org/10.1145/1401890.1401920
Guo, T., Xu, C., Huang, J., Wang, Y., Shi, B., Xu, C., & Tao, D. (2020). On Positive-Unlabeled Classification in GAN. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8385–8393.
Ivanov, D. I., & Nesterov, A. S. (2019). Identifying Bid Leakage In Procurement Auctions: Machine Learning Approach. ArXiv Preprint ArXiv:1903.00261.
Jain, S., White, M., Trosset, M. W., & Radivojac, P. (2016). Nonparametric semi-supervised learning of class proportions. ArXiv Preprint ArXiv:1601.01944.
Kiryo, R., Niu, G., du Plessis, M. C., & Sugiyama, M. (2017). Positive-unlabeled learning with non-negative risk estimator. Advances in Neural Information Processing Systems, 1675–1685.
Ren, Y., Ji, D., & Zhang, H. (2014). Positive Unlabeled Learning for Deceptive Reviews Detection. EMNLP, 488–498.
Scott, C., & Blanchard, G. (2009). Novelty detection: Unlabeled data definitely help. Artificial Intelligence and Statistics, 464–471.
Xu, D., & Denil, M. (2019). Positive-Unlabeled Reward Learning. ArXiv:1911.00459 [Cs, Stat]. http://arxiv.org/abs/1911.00459
Yang, P., Li, X.-L., Mei, J.-P., Kwoh, C.-K., & Ng, S.-K. (2012). Positive-unlabeled learning for disease gene identification. Bioinformatics, 28(20), 2640–2647.