
Editeur de données
Editeur de grande valeur
Nous avons ajouté un éditeur à part entière aux cellules. Si une cellule contient une valeur longue, telle que XML ou JSON, il est pratique de l'ouvrir dans un panneau séparé. Pour ce faire, cliquez sur
Agrandir dans le menu contextuel.
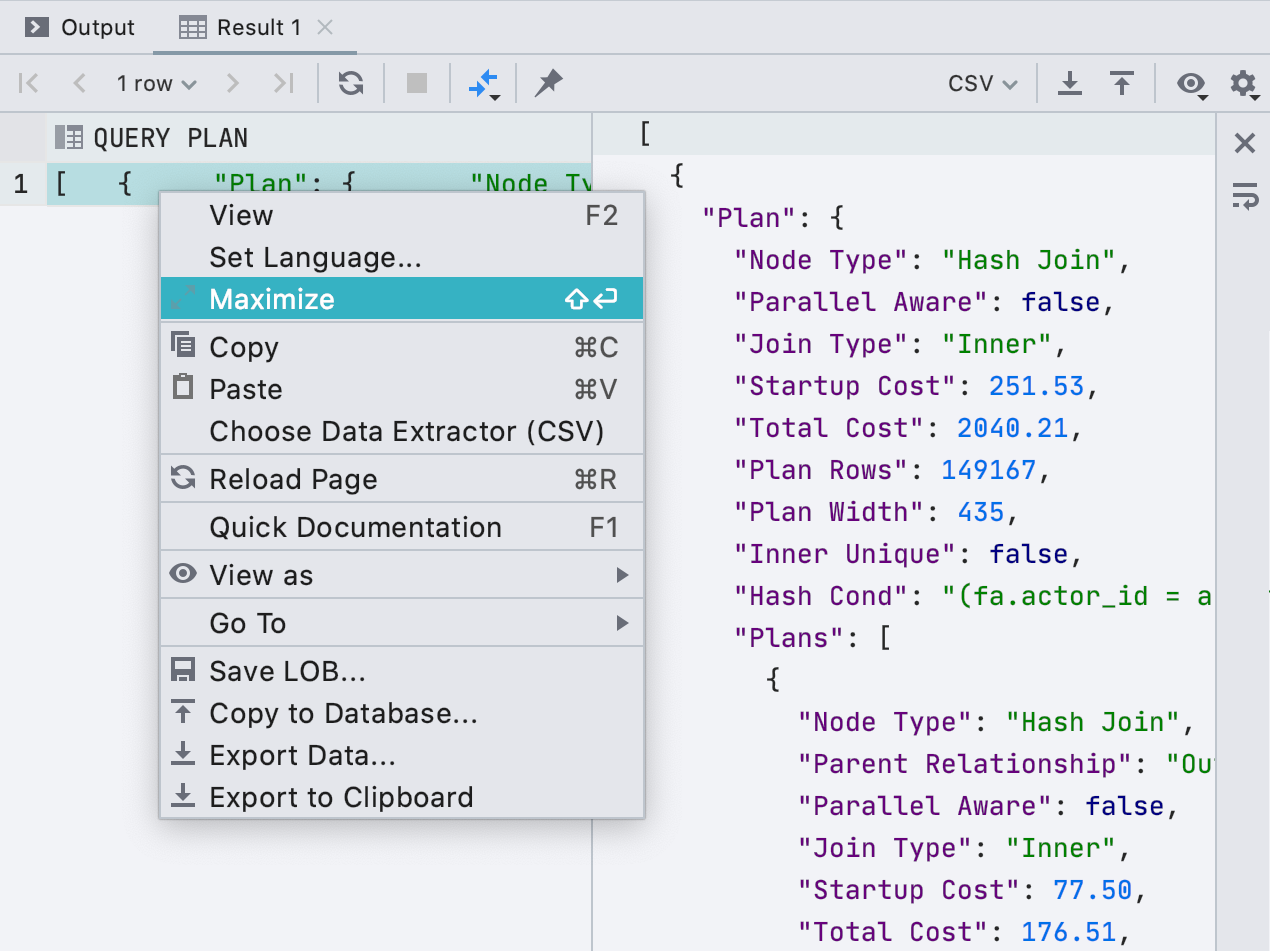
Prévisualisation d'une requête lors de l'édition
Maintenant, avant d'écrire de nouvelles valeurs dans l'éditeur de données, vous pouvez voir quelle requête sera exécutée. Pour ce faire, cliquez sur le bouton DML dans la barre d'outils.
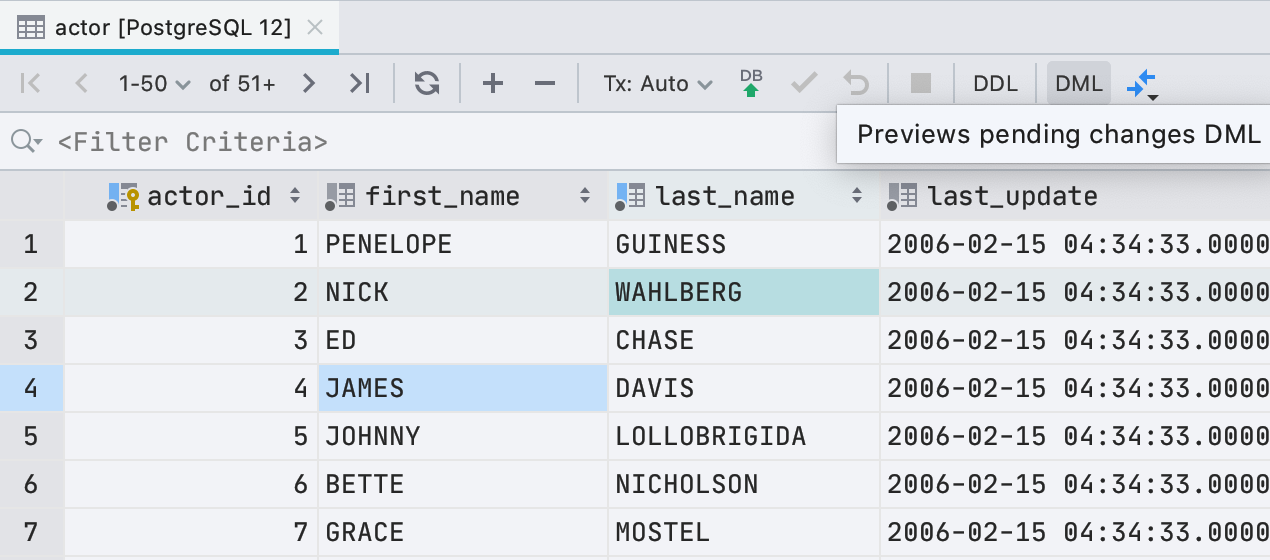
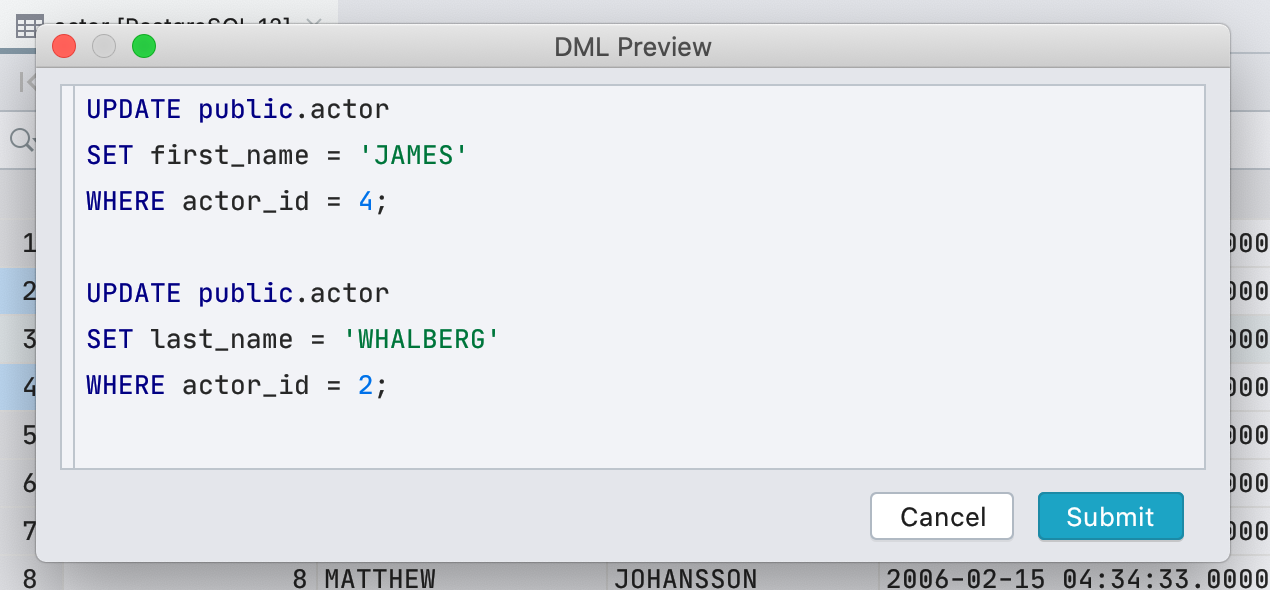
Pour être honnête, ce n'est pas seulement la requête que nous exécutons car pour éditer les données, DataGrip utilise le pilote JDBC. Mais dans la plupart des cas, ce que nous montrons coïncidera avec ce qui commence réellement.
Nouvel affichage des cellules logiques
Auparavant, nous utilisions une case à cocher pour afficher les cellules de type booléen . Ce n'était pas pratique: tout le monde ne comprenait pas comment distinguer nul de faux , et par défaut, calculé et nul étaient affichés de la même manière. Nous avons décidé de ne pas être intelligents et d'écrire le sens dans le texte.
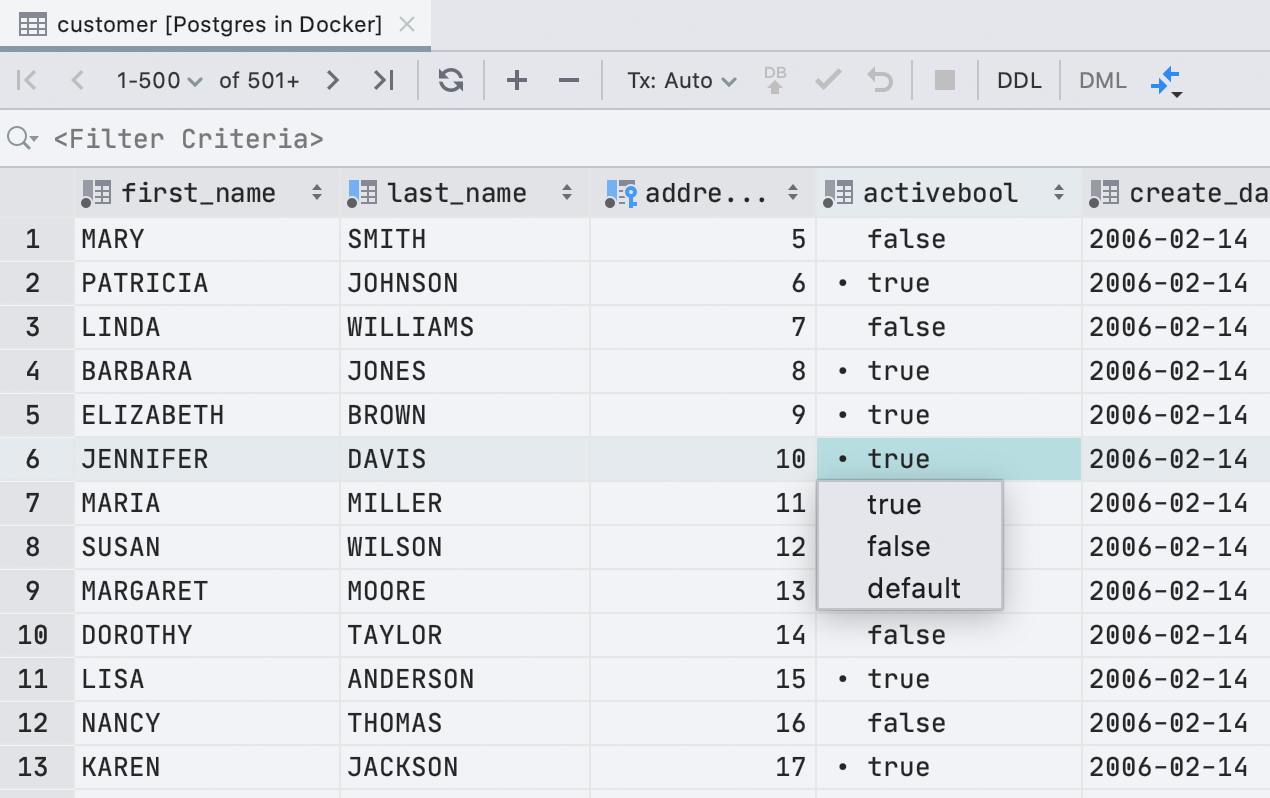
La case à cocher avait un avantage: il est facile de trouver visuellement les vraies valeurs . Dans la nouvelle interface, le point effectue cette tâche.
Nous avons de la chance: en anglais, toutes les significations possibles commencent par des lettres différentes. Par conséquent, pour modifier, appuyez simplement sur la première lettre de la valeur dont vous avez besoin: f, t, d, n, g ou c.Si nous imprimons autre chose, nous afficherons une liste déroulante. Et la barre d'espace bascule entre les valeurs disponibles.
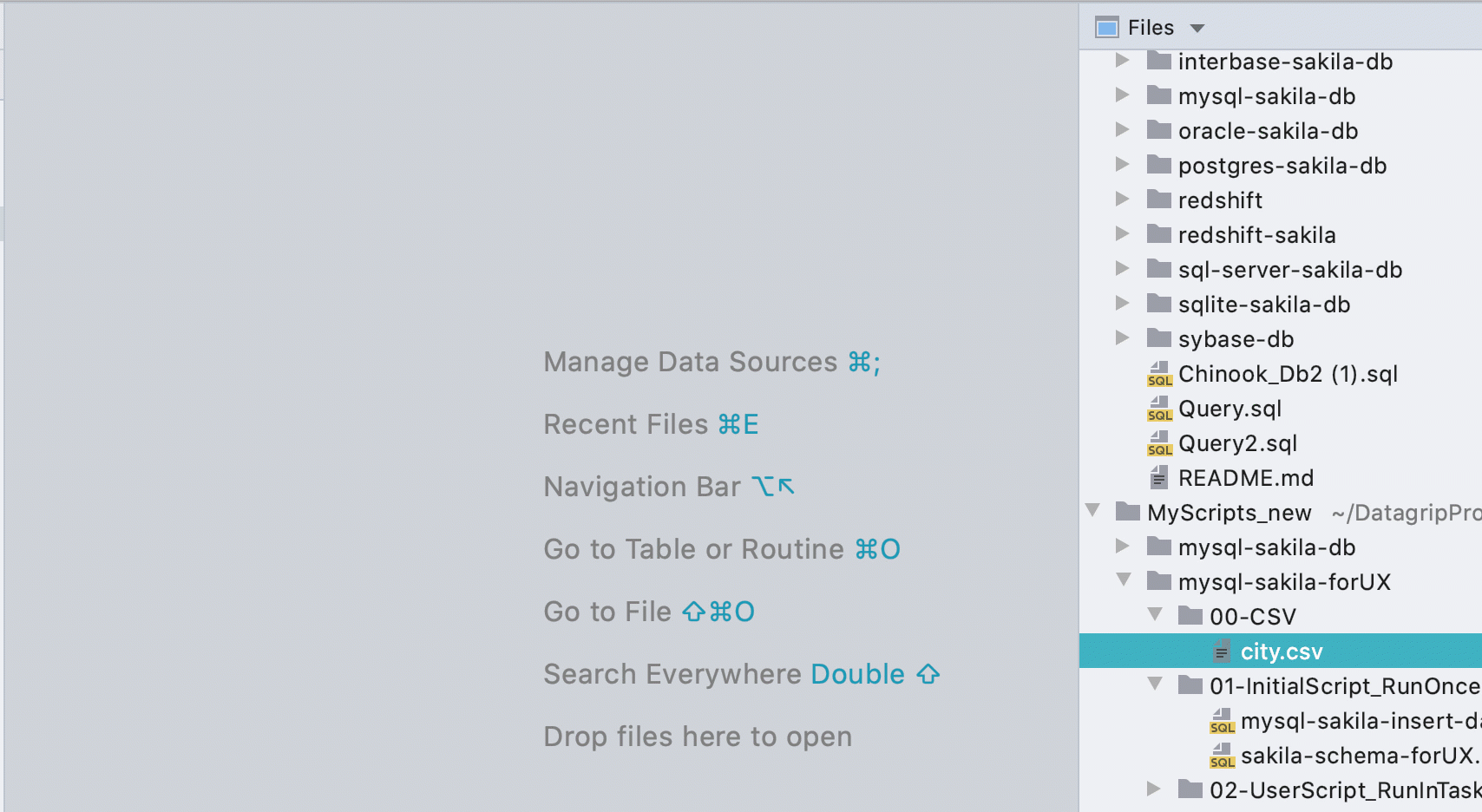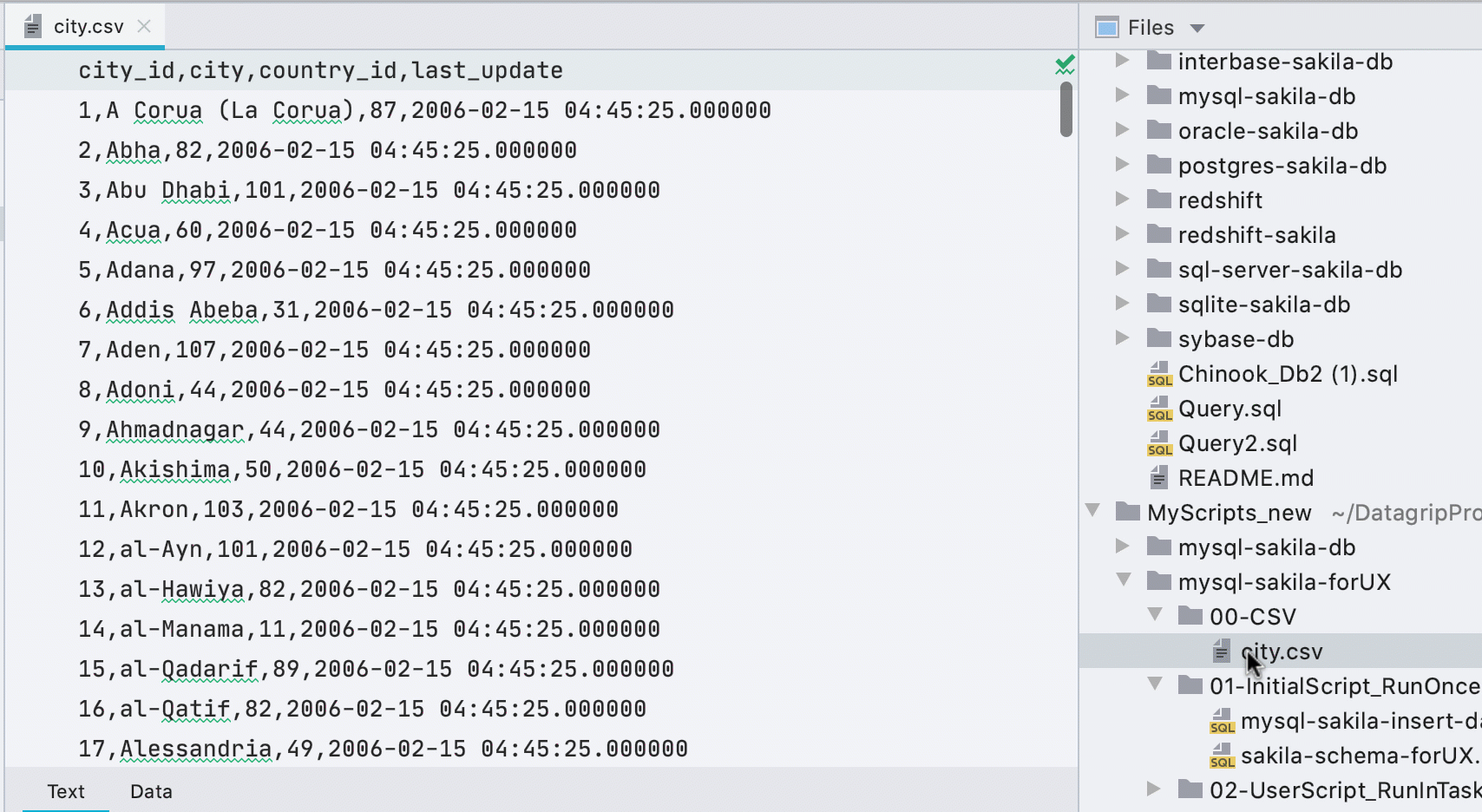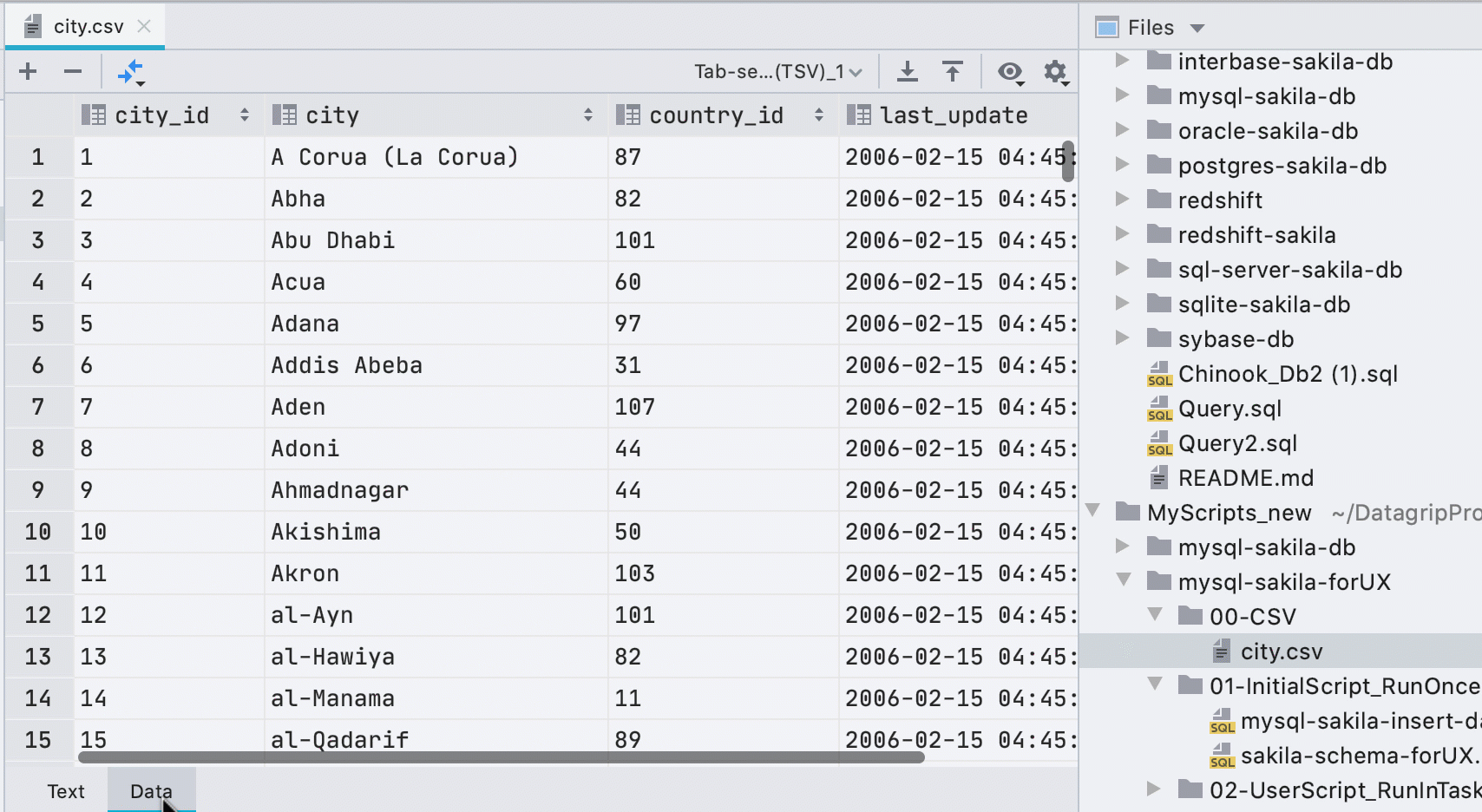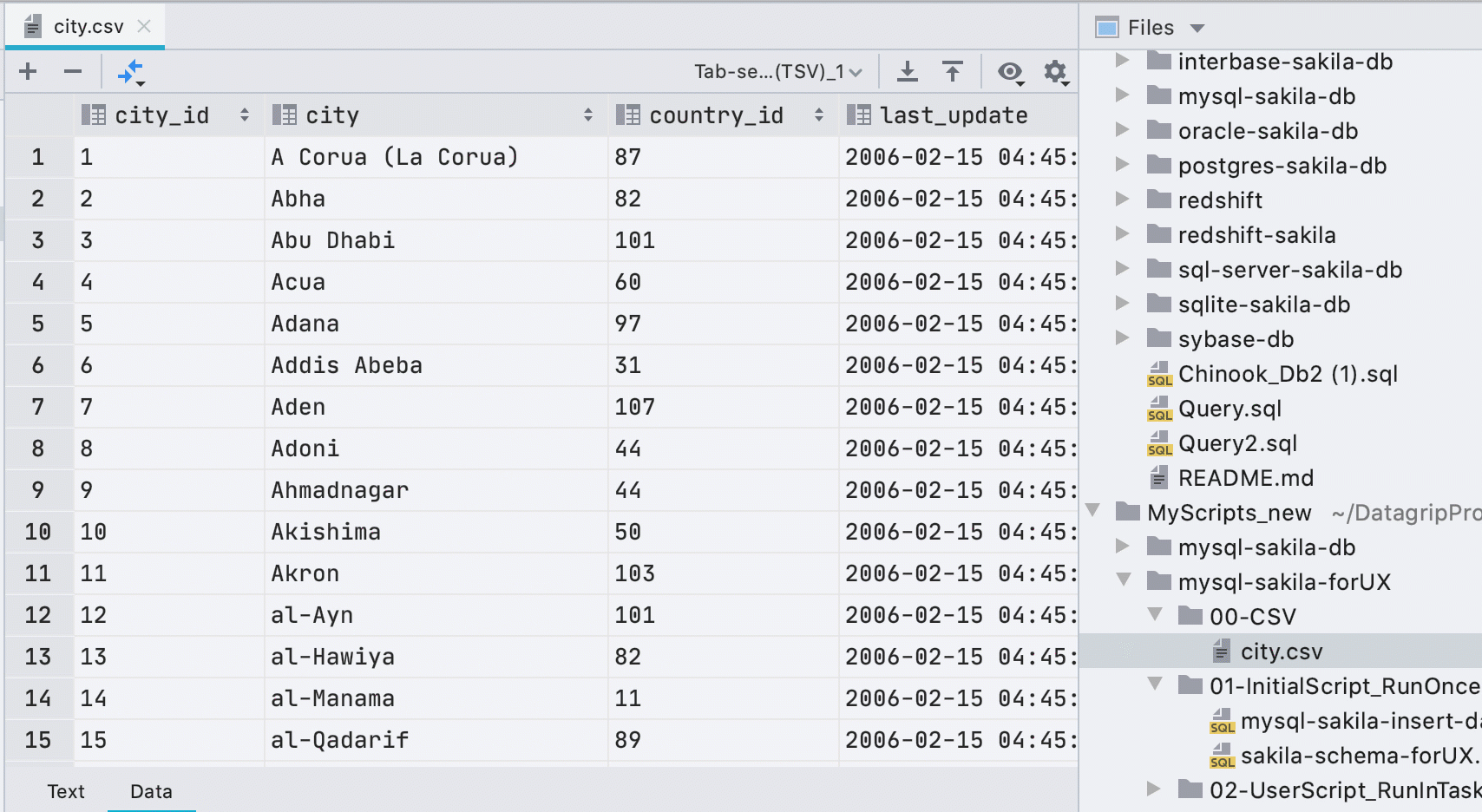
Éditeur de données automatique pour les fichiers CSV
Auparavant, vous deviez appeler l'éditeur de données depuis le menu contextuel, et une petite barre jaune annonçait un plugin tiers lors de l'ouverture des fichiers CSV. Maintenant, nous comprenons ce que nous sommes et montrons l'onglet Données pour les fichiers CSV.
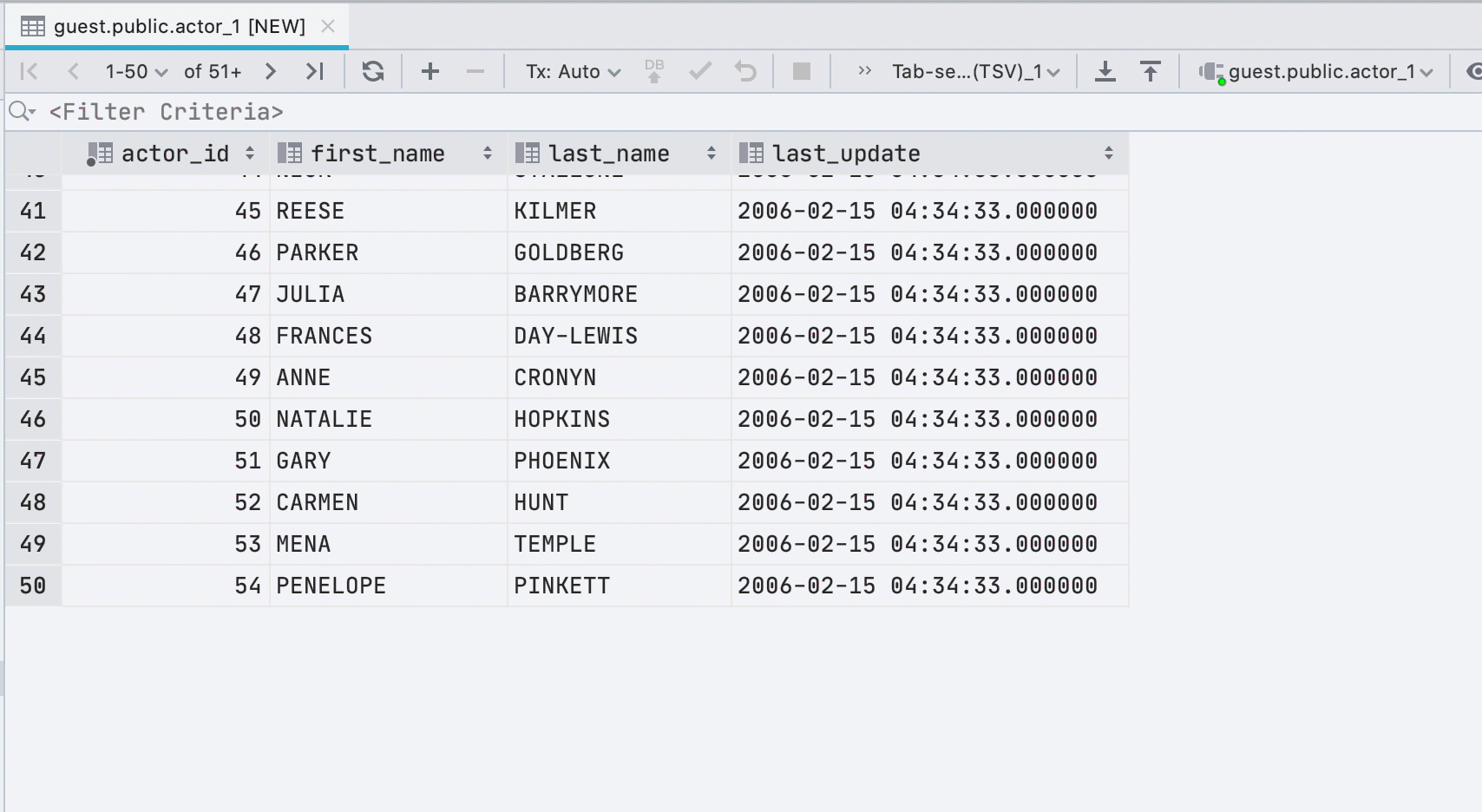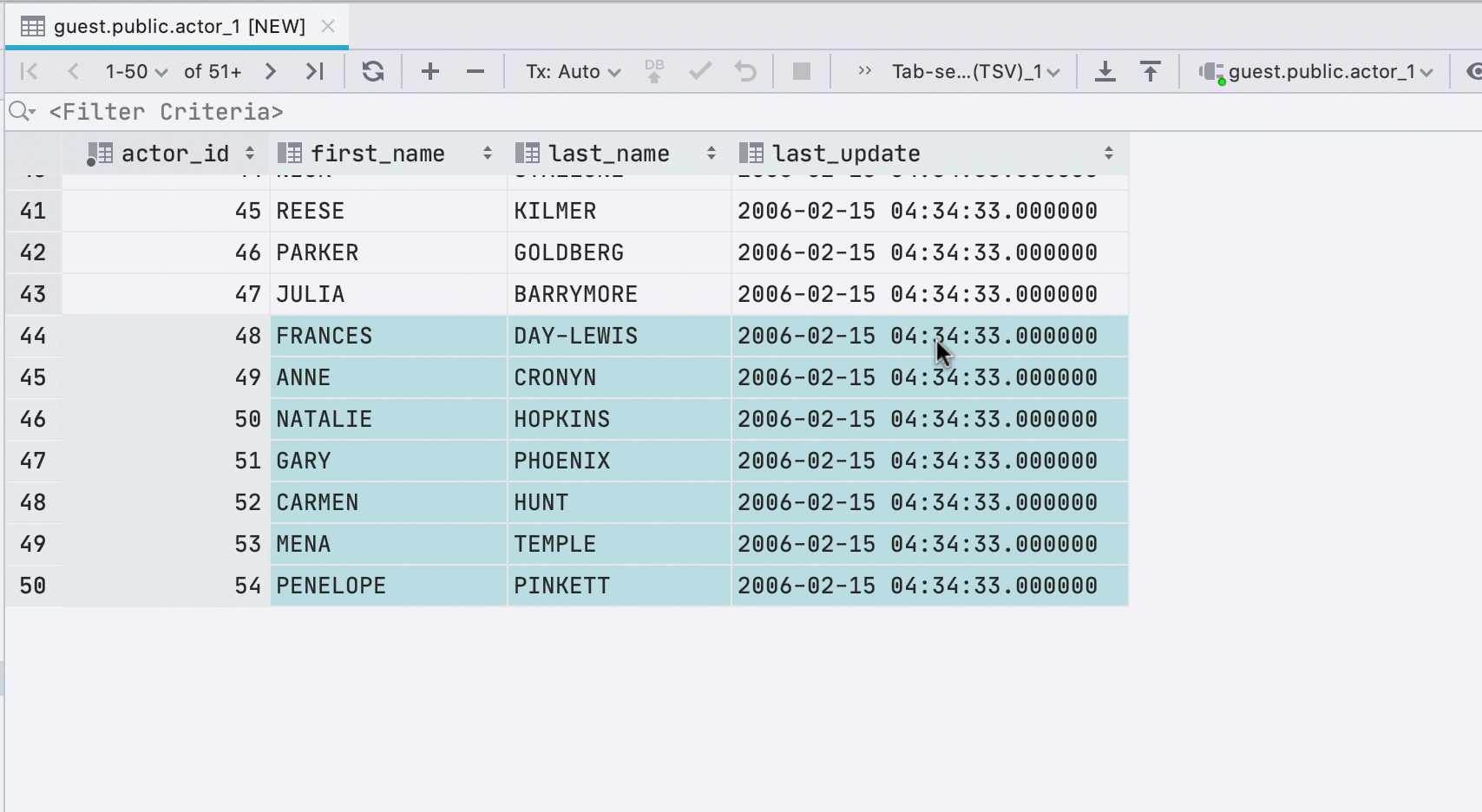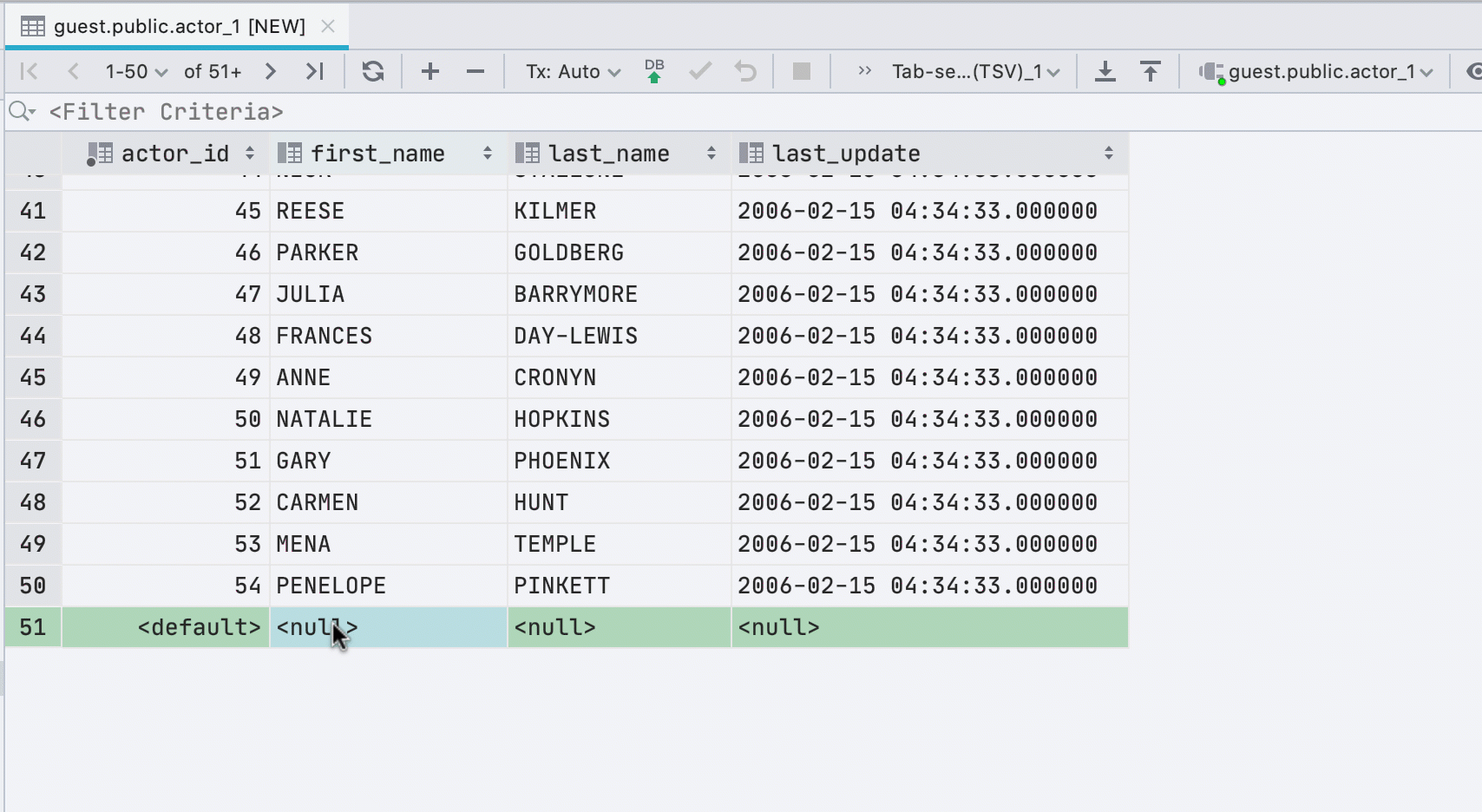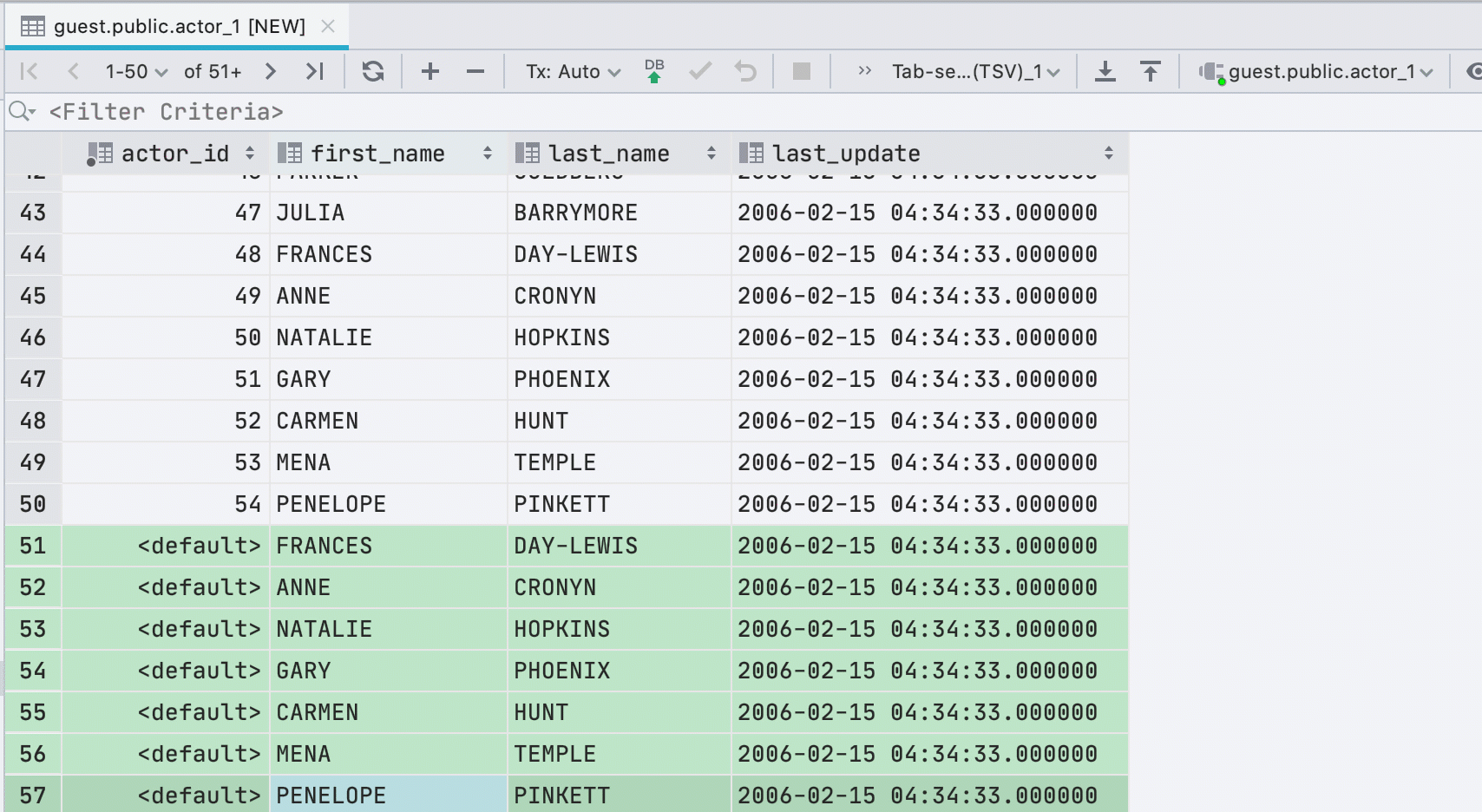
Nouvelles lignes lors du collage de valeurs
Si vous collez des données dans une table à partir du presse-papiers, nous créerons automatiquement le nombre requis de nouvelles lignes.
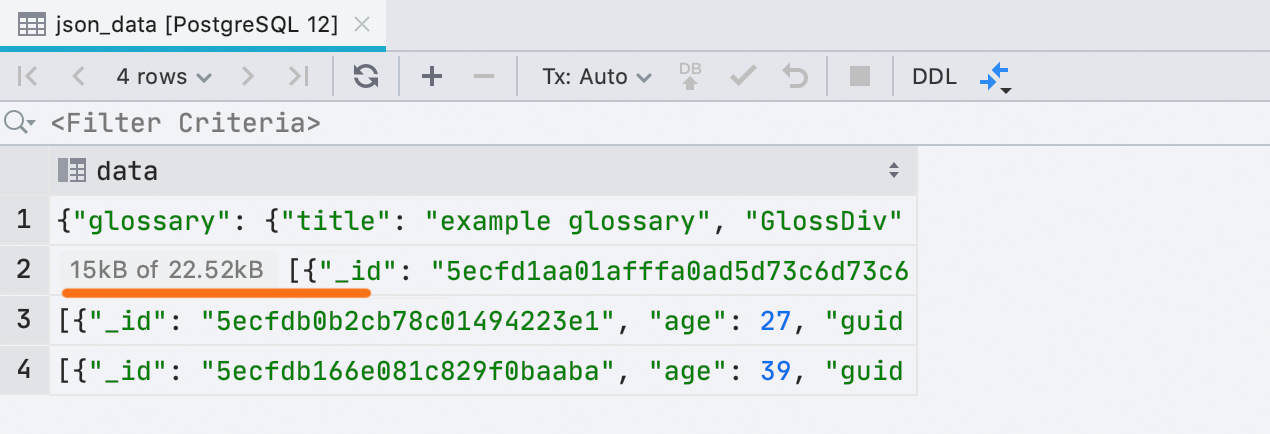
Nouvelle interface pour les données sous-
chargées Parfois, DataGrip ne peut pas charger toutes les données dans une cellule si elle prend beaucoup de mémoire. Ceci est déterminé par la base de données | Vues de données | Longueur maximale du LOB.Auparavant, nous insérions du texte à ce sujet directement dans la valeur de la cellule, ce qui n'est pas pratique. Maintenant, c'est une petite plaque séparée:
Exporter dans le presse-papiers à partir du menu contextuel
Dans la dernière version, nous avons créé une boîte de dialogue pour l'exportation, en laissant de côté un petit cas: il est devenu moins pratique de copier tout le résultat dans le presse-papiers avec la souris. Maintenant, cela peut être fait à partir du menu contextuel.

Rappelez-vous que cette action copie l'intégralité du résultat ou de la table. Et Ctrl / Cmd + C ou l'action
Copier copie uniquement la sélection.
Améliorations du filtrage pour MongoDB
Outre ObjectId et ISODate , vous pouvez désormais filtrer par UUID , NumberDecimal , NumberLonget
BinData . De plus, si vous avez une valeur appropriée pour UUID / ObjectId / ISODate dans votre presse-papiers, DataGrip vous proposera de l'utiliser pour le filtrage.
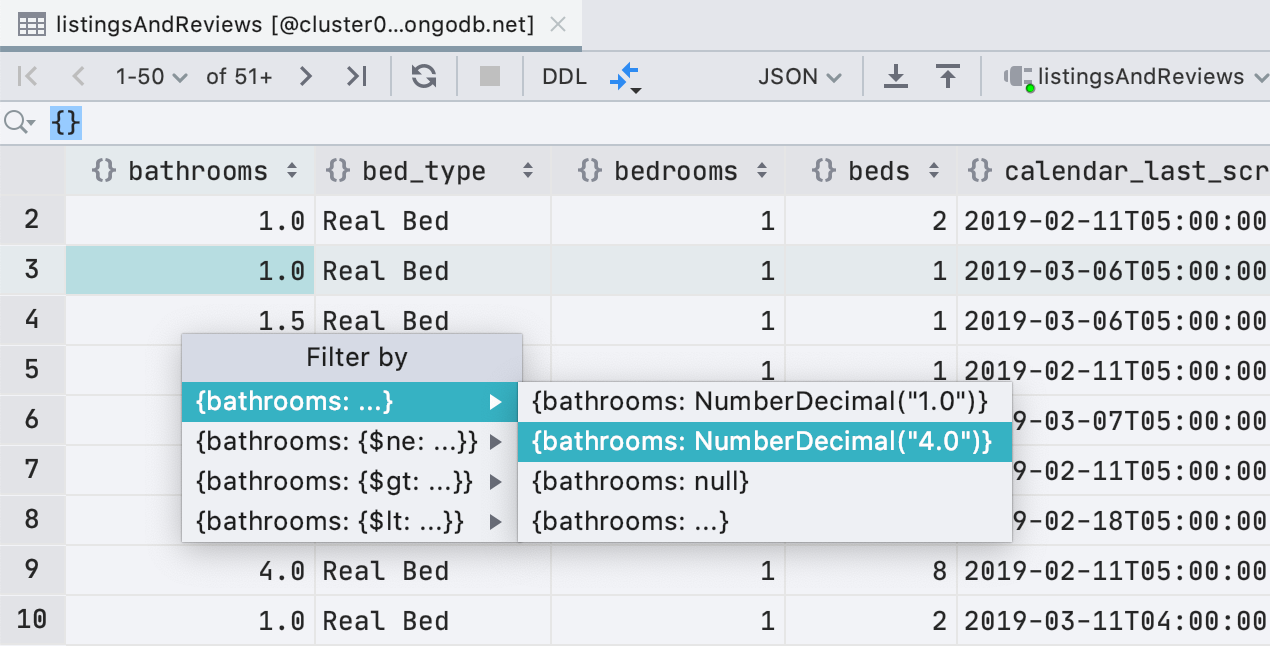
Nous avons également ajouté des expressions régulières aux conditions de filtre afin de ne pas manquer trop de
LIKE du filtre dans les bases de données relationnelles.

Éditeur SQL
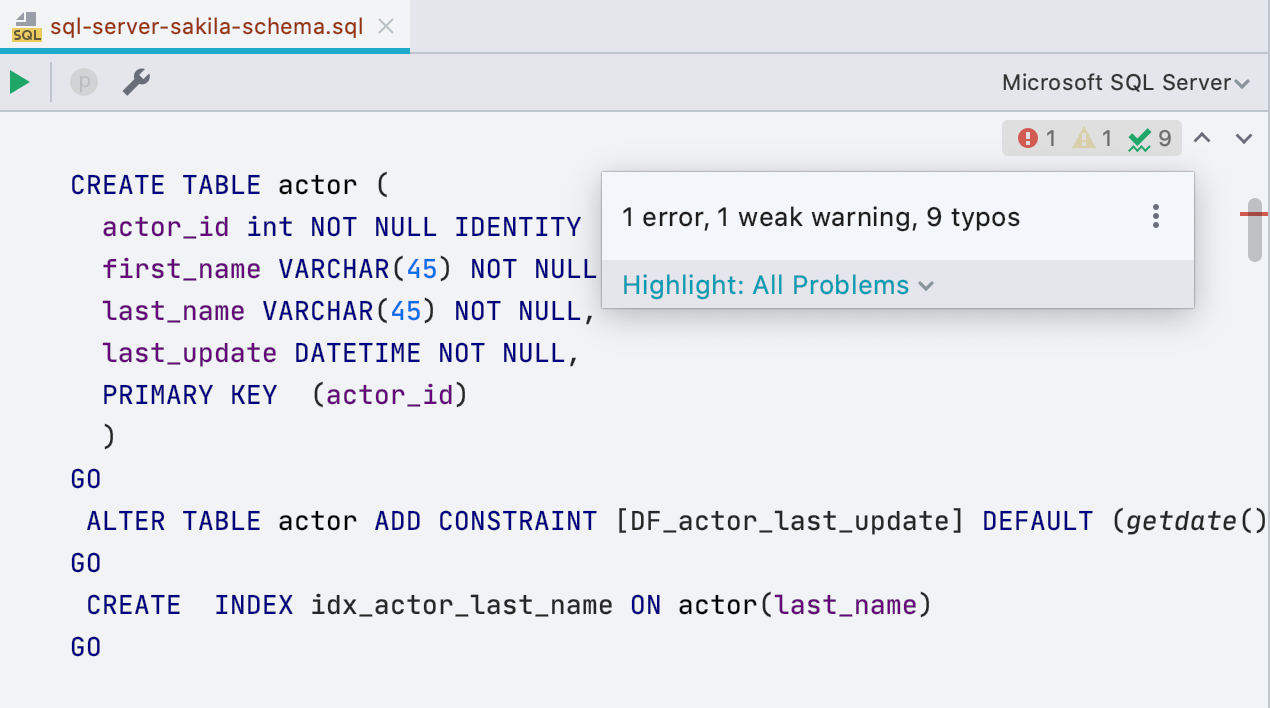
Nouveau widget avec inspections
Un petit panneau est apparu à droite de l'éditeur - il vous indiquera combien d'erreurs dans le script et combien d'endroits sont suspects. À partir de là, vous pouvez naviguer ou choisir ce qu'il faut mettre en évidence ou non. Le raccourci clavier F2 fonctionne toujours pour la même chose.
Suggestion de renommer
Cela est apparu dans beaucoup de nos IDE: si vous avez renommé quelque chose n'utilisant pas le refactoring intégré, mais que vous avez changé le nom dans le code, vous serez invité à refactoriser et renommer et toutes les utilisations. Par exemple, voici comment cela fonctionne avec les alias: La

complétion JOIN vient de s'améliorer
Auparavant, pour que nous puissions offrir une condition JOIN complète, nous devions taper ce mot-clé. Nous comprenons maintenant ce dont vous avez besoin dès que vous avez tapé
'J'.

Nous avons également appris à offrir des conditions doubles si les clés de table sont définies de cette façon.

Actualiser les informations de la base de données
Si DataGrip ne sait rien des objets de vos requêtes, il vous en informera. Parfois, cela se produit si vous venez de vous sceller. Il arrive également que le fichier soit associé à la mauvaise source de données. Une autre raison d'un tel événement est que l'objet est déjà apparu, mais DataGrip n'a pas reçu d'informations à son sujet de la base de données. Pour ce faire, nous avons ajouté la possibilité de démarrer la mise à jour de la structure de la base de données depuis l'éditeur si l'objet est inconnu.

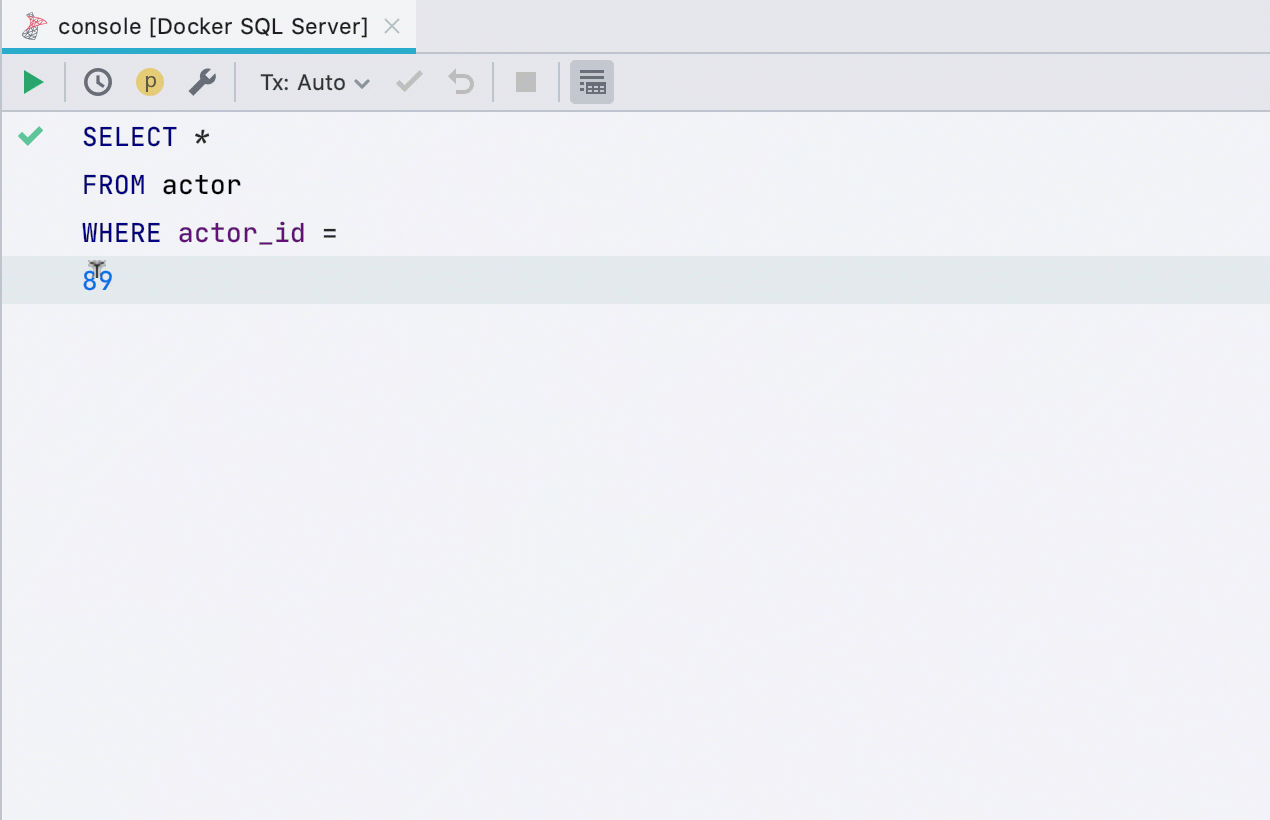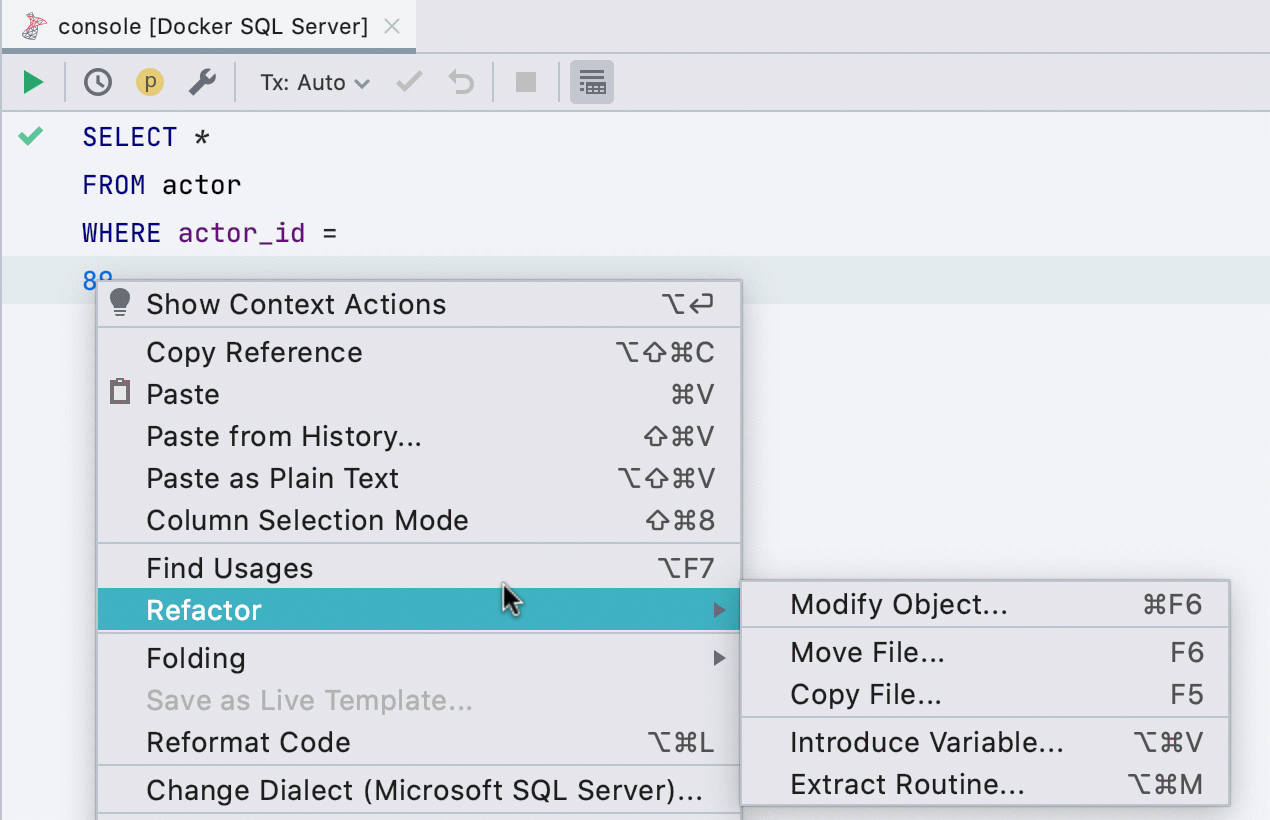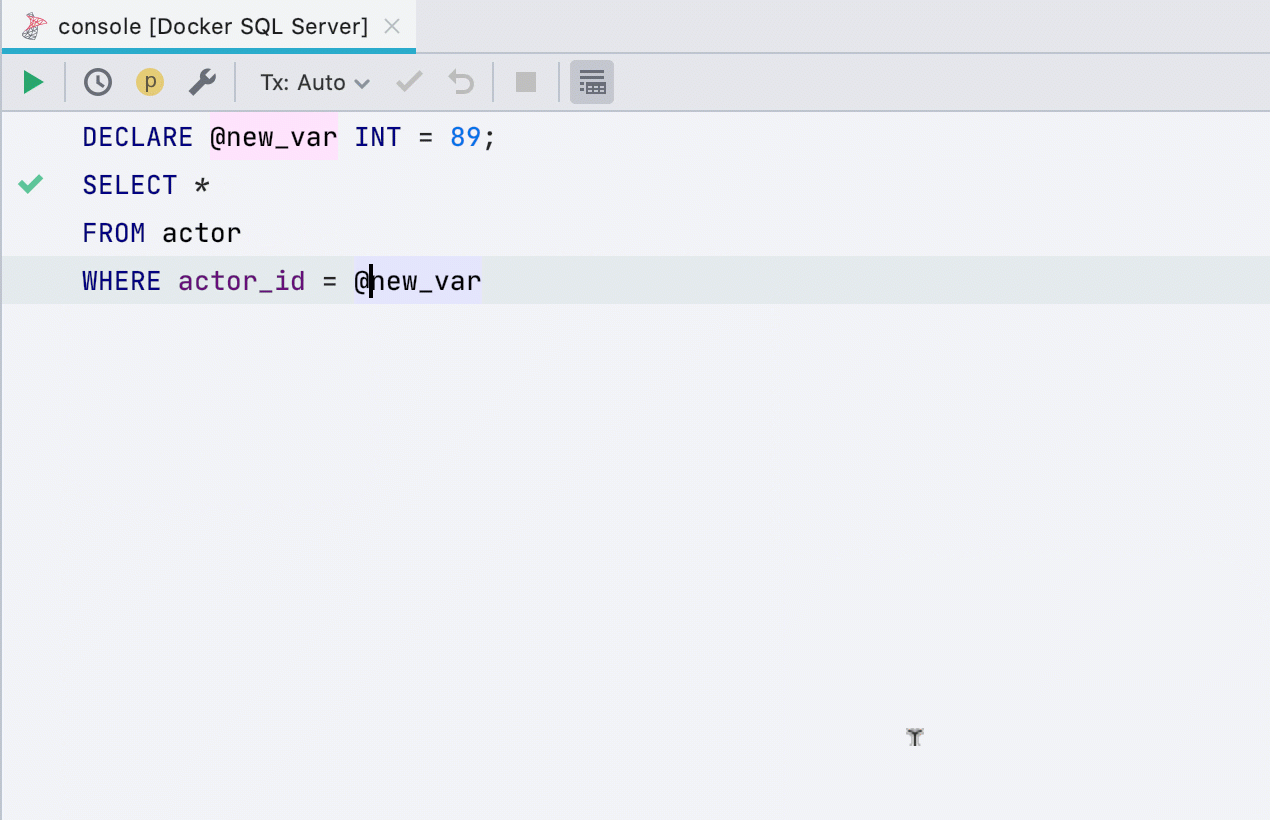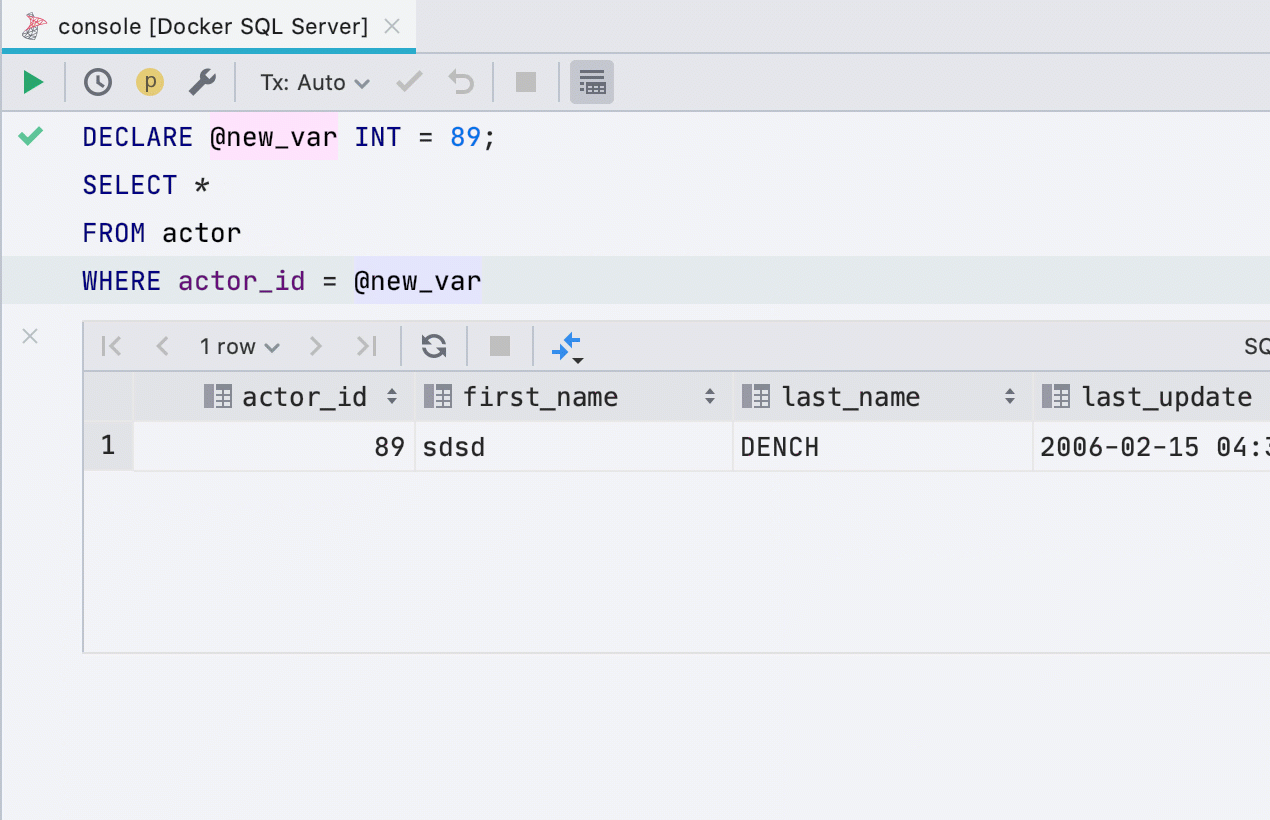
Allouer la variable
Cette refactorisation ne fonctionnait pas auparavant pour toutes les bases de données, fonctionne désormais dans SQL Server, Db2, Exasol, HSQL, Redshift et Sybase .
Mise en évidence de Google BigQuery
Ajout de nouveaux dialectes: Google BigQuery. Jusqu'à présent, il ne s'agit pas d'un support de base de données à part entière, mais uniquement d'une mise en évidence correcte du code. En conséquence, vous n'avez pas besoin de sélectionner du code pour exécuter des requêtes, nous déterminerons nous-mêmes ce qu'il faut exécuter.

Mise en évidence de TextMate
Comme nos autres IDE, DataGrip peut désormais mettre en évidence du code à l'aide du plugin TextMate. Cela peut être utile si vous avez des scripts en Python, lua, javascript. Une liste complète des langues est disponible dans Paramètres / Préférences | Rédacteur | Bundles TextMate .

SQL 2016 en tant que dialecte <Generic>
Si vous travaillez avec une base de données que nous ne prenons pas en charge, les requêtes sont analysées et mises en surbrillance avec le dialecte < Generic >. Auparavant, c'était SQL 92, maintenant SQL 2016. Le plus important est que maintenant nous traitons correctement les requêtes avec un bloc WITH, respectivement, ils ne sont pas seulement correctement mis en évidence, mais vous pouvez également les exécuter sans mettre en évidence le code.
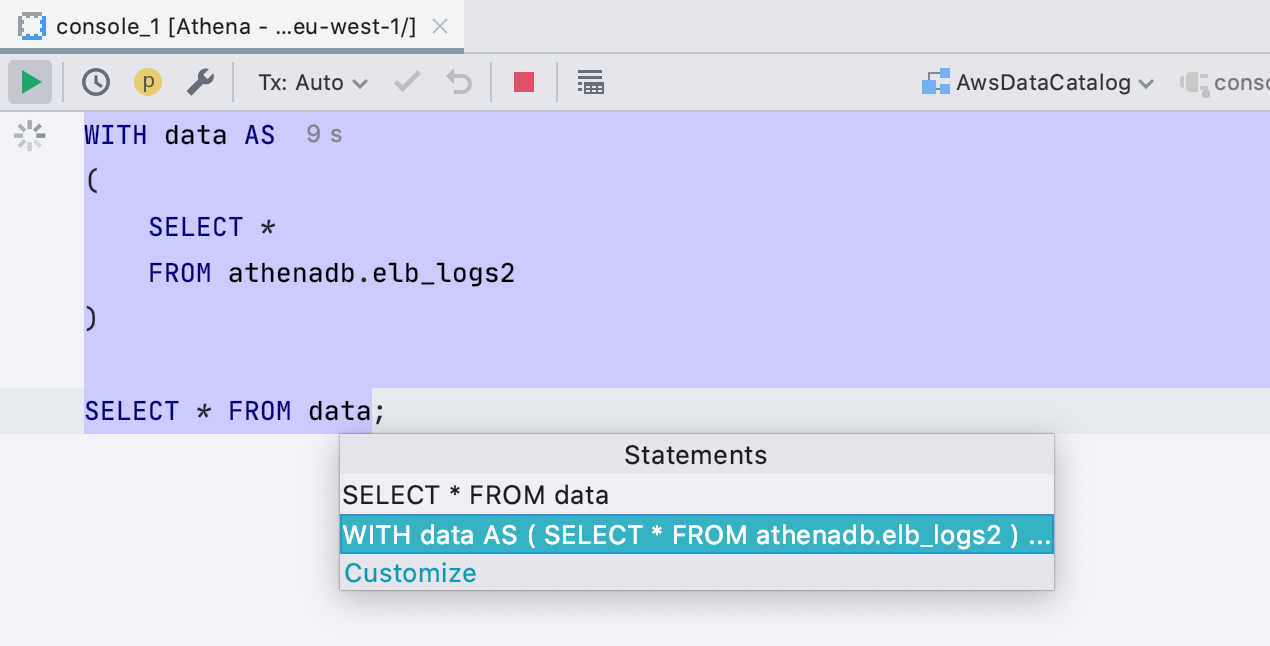
Cas des noms d'objets dans la mise en forme
Dans les paramètres de mise en forme, il y avait trois paramètres pour les noms des objets de base de données - majuscules , minuscules ou non modifiés . Mais il s'est avéré qu'il y avait un quatrième cas: les utilisateurs veulent utiliser le cas qui a été utilisé lors de la création de l'objet dans le script. Nous avons soutenu cela.

Dans l'exemple, la table Actor a été créée avec la première lettre majuscule et, lors de l'utilisation, nous avons converti le nom de la table dans la même casse.

Nous recherchons uniquement les scripts de création dans le même fichier où le formatage a lieu. Si vous souhaitez que le formateur trouve la déclaration d'objet dans un fichier voisin, créez une source de données DDL à partir de vos fichiers .
Plusieurs carets dans une sélection
Vous pouvez maintenant sélectionner un morceau de code et mettre un signe d'insertion sur chaque ligne de celui-ci. Pour cela, utilisez l'action Ajouter des points d'insertion aux extrémités des lignes sélectionnées ou le raccourci clavier Maj + Alt + G

Explorateur de base de données
Toutes les bases et schémas de l'arborescence
Par défaut, nous affichons dans l'arborescence uniquement les bases et schémas que vous avez sélectionnés vous-même. L'arbre n'est pas paresseux, et toutes les méta-informations sur les objets sont utilisées pour le travail ultérieur de l'EDI. Par conséquent, nous ne téléchargeons que ce qui est nécessaire pour ne pas s'accrocher accidentellement à une base géante.
Cependant, beaucoup sont habitués à des outils qui montrent toujours tous les objets, et les personnes qui ne sont pas familières avec notre concept peuvent perdre de vue les bases et les diagrammes. Par conséquent, nous avons défini le paramètre Afficher tous les espaces de noms et , lorsqu'il est activé, toutes les bases de données et tous les schémas seront affichés dans l'arborescence, même si les informations sur leurs objets ne sont pas chargées. Ces schémas et bases sont marqués en gris.

Interface de création de vues
On dit généralement que la fonction de génération de code dans l'éditeur (Alt + Ins ou Cmd + N ) couvre de nombreux besoins de création d'objets du développeur, mais parfois c'est encore moins pratique. Par conséquent, nous avons commencé à ajouter des interfaces pour créer des objets: dans la nouvelle version, vous pouvez créer des vues.

Fichiers de script dans le panneau Fichiers
Si vous avez créé une source de données DDL, ces fichiers seront automatiquement placés dans le panneau
Fichiers . Il vous sera donc pratique de les visualiser et de les modifier.

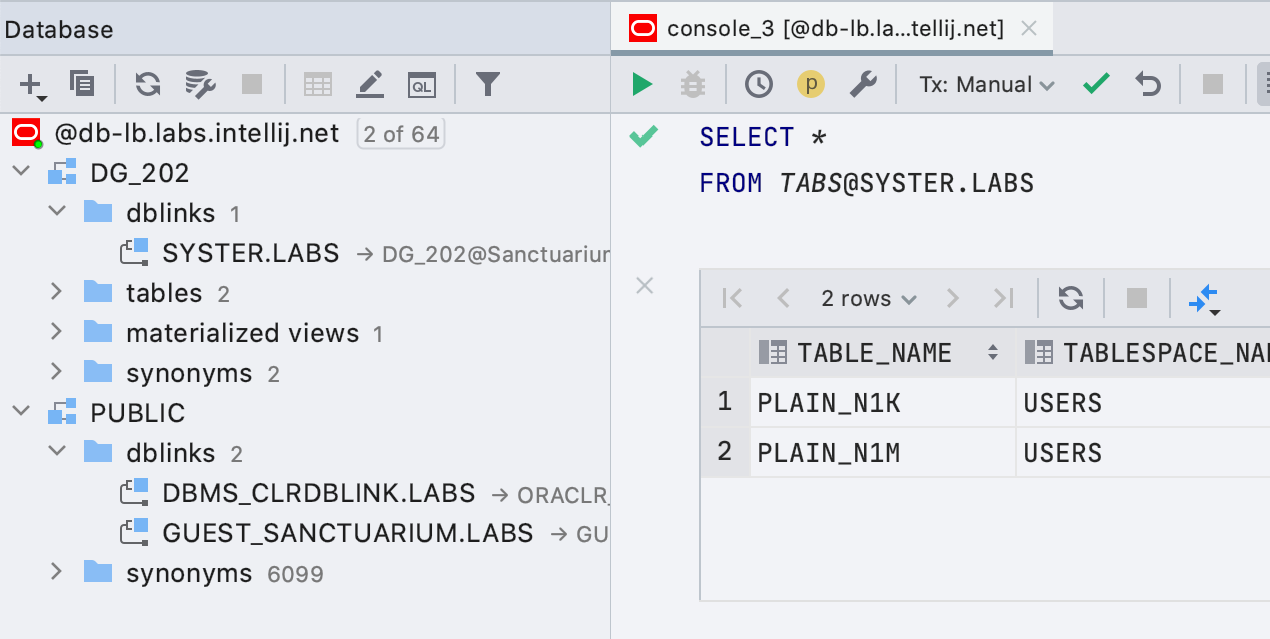
Les
liens de base de données de prise en charge des liens de base de données Oracle simples sont désormais affichés dans l'Explorateur et les requêtes qui les utilisent sont correctement mis en surbrillance.
Général
Plus de noms d'onglets longs
Vous vous êtes souvent plaint que les onglets deviennent incontrôlables .

À partir de maintenant:
- Database | General | Always show qualified names for database objects , , .
- 20 , .
- , .
- — 36 , .
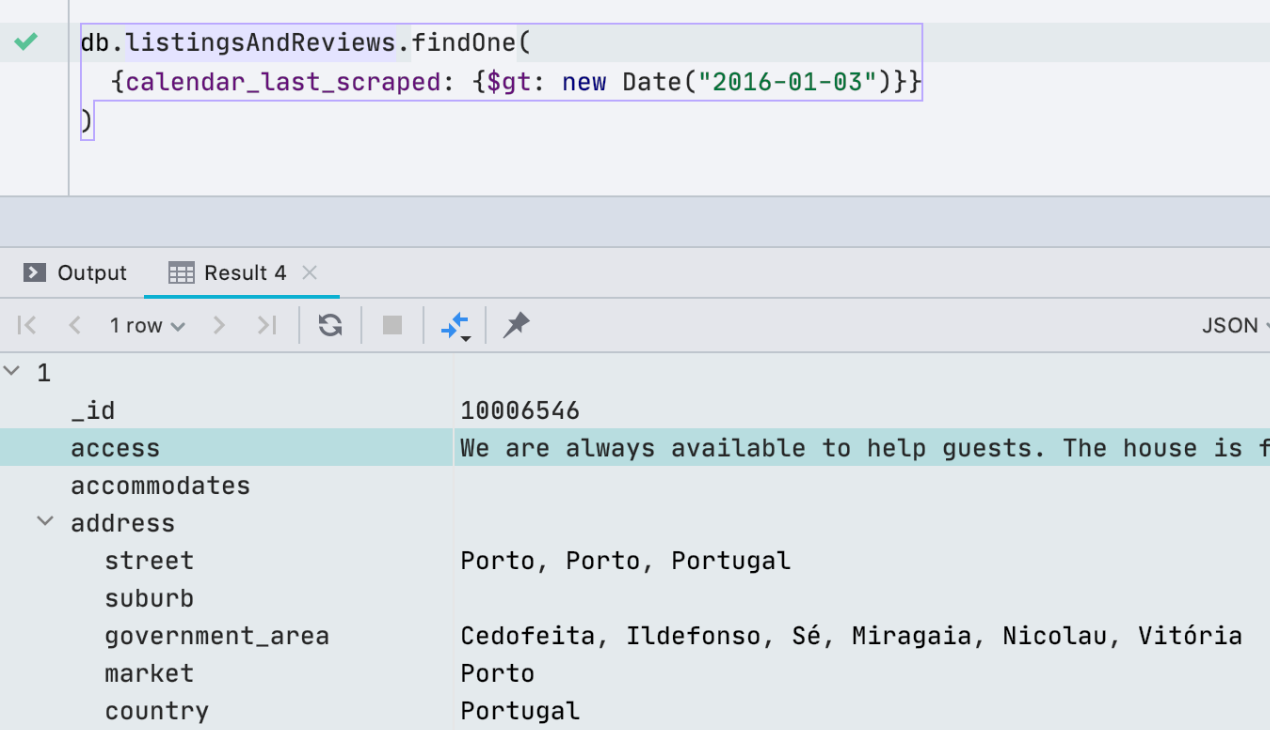
Prise en charge du shell MongoDB
Il y a un mois, nous avons mis à jour le pilote que nous utilisons pour nous connecter à MongoDB afin de prendre en charge le shell MongoDB. Cela signifie que de nouvelles commandes et méthodes ont fonctionné, telles que help, db.getCollectionInfos (), db.getCollectionNames (), db.collection.remove () et autres. Article détaillé en anglais sur le support du shell MongoDB ici .
Bibliothèques natives dans les paramètres du pilote
Vous pouvez désormais spécifier le chemin d'accès à la bibliothèque native dont le pilote a besoin. Voici quelques fois où vous pourriez en avoir besoin.

- SQL Server mssql-jdbc_auth-<version>-<arch>.dll SSO, . , SSO .
- Oracle ocijdbc, OCI .
- SQLite, ,
, , .
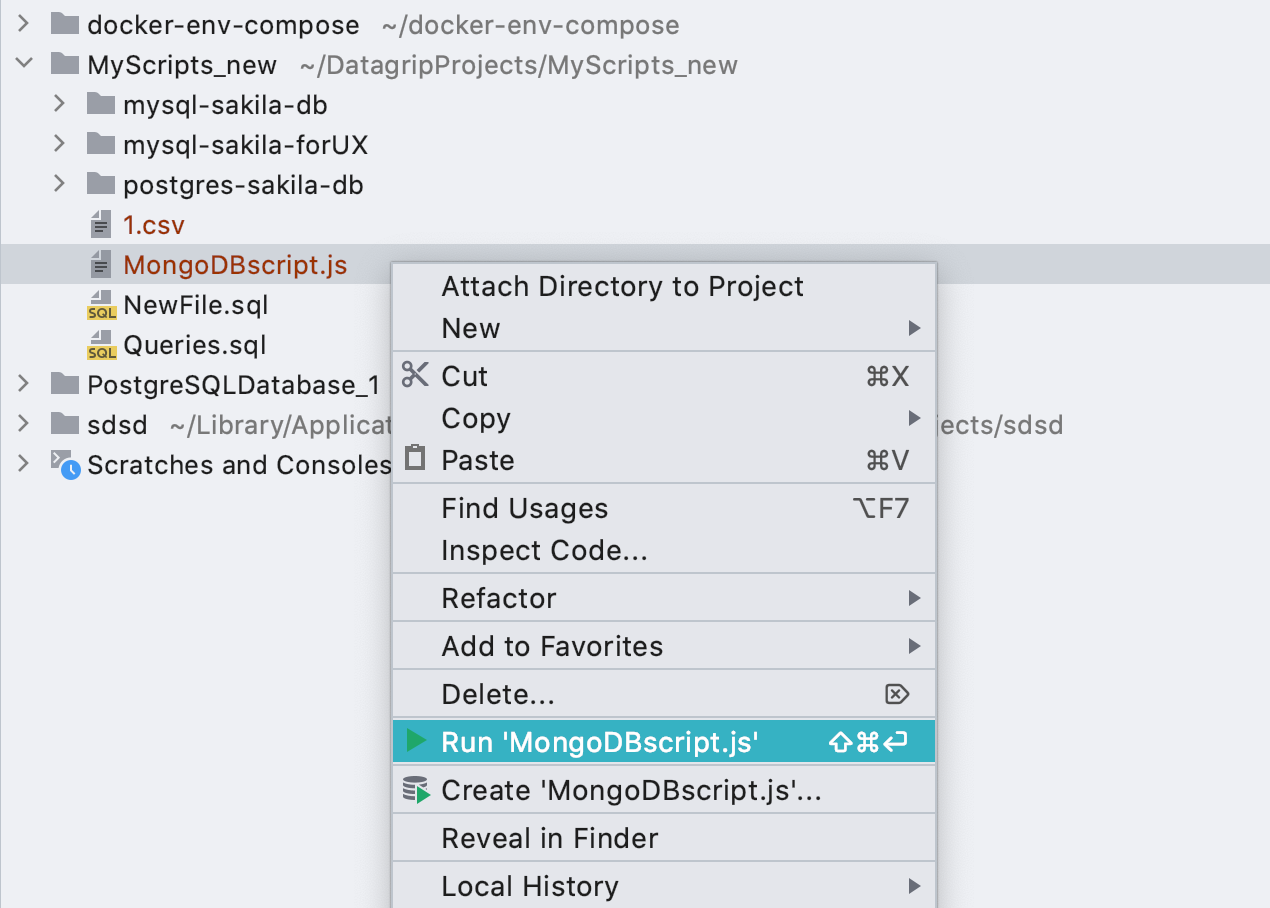
Lancer les configurations pour les fichiers * .js Les
configurations de lancement fonctionnent désormais également pour les scripts MongoDB .
L'intégration avec Git et Github fonctionne hors de la boîte
Notre enquête a montré que bon nombre de personnes stockent des scripts dans des systèmes de contrôle de version, nous avons donc décidé d'empaqueter deux des plugins les plus populaires dans ce domaine.

Merci de votre attention! Rappelons que nous avons notre propre chaîne dans Telegram , où vous pouvez poser des questions et partager vos expériences. Mais si vous trouvez un bug, il est préférable d'écrire immédiatement dans le tracker pour qu'il ne se perde pas. Eh bien, ici, bien sûr, écrivez également des commentaires :)
C'est tout!
Équipe DataGrip