Je voudrais partager l'expérience de la mise en œuvre de réseaux de neurones à la mode dans notre entreprise. Tout a commencé lorsque nous avons décidé de créer notre propre Service Desk. Pourquoi et pourquoi le vôtre, vous pouvez lire mon collègue Alexei Volkov (face) ici .
Je vais vous parler d'une innovation récente du système: un réseau de neurones pour aider le répartiteur de la première ligne de support. Si vous êtes intéressé, bienvenue au chat.

Clarification de la tâche
Un casse-tête pour tout répartiteur de support est une décision rapide à affecter à une demande client entrante. Voici les demandes:
Bonne après-midi.
Je comprends bien: pour partager un calendrier avec un utilisateur spécifique, vous devez ouvrir l'accès à votre calendrier sur le PC de l'utilisateur qui souhaite partager le calendrier et saisir le courrier de l'utilisateur auquel il souhaite donner accès?
Selon la réglementation, le répartiteur doit répondre dans les deux minutes: enregistrer une demande, déterminer l'urgence et désigner une unité responsable. Dans ce cas, le répartiteur choisit parmi 44 divisions de l'entreprise.
Les instructions des répartiteurs décrivent une solution pour les requêtes les plus courantes. Par exemple, donner accès à un centre de données est une simple demande. Mais les demandes de service comportent de nombreuses tâches: installer un logiciel, analyser une situation ou une activité réseau, connaître les détails de la facturation des solutions, vérifier tous les types d'accès. Parfois, il est difficile de comprendre à partir de la demande à quel responsable envoyer la question:
Hi Team,
The sites were down again for few minutes from 2020-07-15 14:59:53 to 2020-07-15 15:12:50 (UTC time zone), now they are working fine. Could you please check and let us know why the sites are fluctuating many times.
Thanks
Il y a eu des situations où l'application a été envoyée au mauvais service. La demande a été prise au travail, puis réaffectée à d'autres artistes ou renvoyée au répartiteur. Cela a augmenté la vitesse de la solution. Le délai de résolution des demandes est inscrit dans l'accord avec le client (SLA), et nous sommes responsables du respect des délais.
À l'intérieur du système, nous avons décidé de créer un assistant pour les répartiteurs. L'objectif principal était d'ajouter des invites qui aident l'employé à prendre une décision sur l'application plus rapidement.
Surtout, je ne voulais pas succomber à la nouvelle tendance et mettre le chatbot en première ligne de support. Si vous avez déjà essayé d'écrire à un tel support technique (qui ne pèche déjà pas avec ça), vous comprenez ce que je veux dire.
Premièrement, il vous comprend très mal et ne répond pas du tout aux demandes atypiques, et deuxièmement, il est très difficile de joindre une personne vivante.
En général, nous n'avons certainement pas prévu de remplacer les répartiteurs par des robots de discussion, car nous voulons que les clients continuent de communiquer avec une personne en direct.
Au début, j'ai pensé à être bon marché et joyeux et j'ai essayé l'approche par mots clés. Nous avons compilé un dictionnaire de mots-clés manuellement, mais cela ne suffisait pas. La solution ne faisait face qu'à des applications simples, avec lesquelles il n'y avait aucun problème.
Au cours du travail de notre Service Desk, nous avons accumulé une solide histoire de demandes, sur la base de laquelle nous pouvons reconnaître des demandes entrantes similaires et les attribuer immédiatement aux exécuteurs correcteurs. Armé de Google et d'un certain temps, j'ai décidé de plonger plus profondément dans mes options.
Théorie de l'apprentissage
Il s'est avéré que ma tâche est une tâche de classification classique. En entrée, l'algorithme reçoit le texte principal de l'application, en sortie il l'affecte à l'une des classes précédemment connues - c'est-à-dire les divisions de l'entreprise.
Il y avait de nombreuses solutions. Il s'agit d'un "réseau neuronal", d'un "classificateur bayésien naïf", d'un "voisin le plus proche", d'une "régression logistique", d'un "arbre décisionnel", d'un "boosting" et de nombreuses autres options.
Il n'y aurait pas de temps pour essayer toutes les techniques. Par conséquent, je me suis installé sur les réseaux de neurones (j'ai longtemps voulu essayer de travailler avec eux). Comme il s'est avéré plus tard, ce choix était pleinement justifié.
Alors, j'ai commencé ma plongée dans les réseaux de neurones à partir d'ici . A étudié les algorithmes d'apprentissageréseaux de neurones: avec un enseignant (apprentissage supervisé), sans enseignant (apprentissage non supervisé), avec implication partielle d'un enseignant (apprentissage semi-supervisé) ou «apprentissage par renforcement».
Dans le cadre de ma tâche, la méthode d'enseignement avec un enseignant est apparue. Il y a plus qu'assez de données pour la formation: plus de 100 000 applications résolues.
Choix de l'implémentation
J'ai choisi la bibliothèque Encog Machine Learning Framework pour l'implémentation . Il est livré avec une documentation accessible et compréhensible avec des exemples . D'ailleurs, l'implémentation pour Java, qui est proche de moi.
En bref, la mécanique du travail ressemble à ceci:
- Le cadre du réseau de neurones est préconfiguré: plusieurs couches de neurones connectés par des connexions synapse.

- Un ensemble de données d'apprentissage avec un résultat prédéterminé est chargé en mémoire.
- . «». «» .
- «» : , , .
- 3 4 . , . , - .
J'ai essayé divers exemples du framework, je me suis rendu compte que la bibliothèque gère les nombres à l'entrée avec un bang. Ainsi, l' exemple avec la définition d'une classe d'iris par la taille du bol et des pétales ( Fisher's Iris ) a bien fonctionné .
Mais j'ai un texte. Cela signifie que les lettres doivent en quelque sorte être transformées en chiffres. Je suis donc passé à la première étape préparatoire - la "vectorisation".
La première option de vectorisation: par lettre
Le moyen le plus simple de transformer du texte en nombres est de prendre l'alphabet sur la première couche du réseau neuronal. Il s'avère 33 lettres-neurones: ABVGDEOZHZYKLMNOPRSTUFHTSZHSHSCHYEYUYA.
Chacun se voit attribuer un numéro: la présence d'une lettre dans un mot est considérée comme un, et l'absence est considérée comme zéro.
Alors le mot "bonjour" dans ce codage aura un vecteur:

un tel vecteur peut déjà être donné au réseau de neurones pour l'entraînement. Après tout, ce nombre est 001001000100000011010000000000000 = 1216454656 Après avoir fouillé
dans la théorie, je me suis rendu compte qu'il n'y avait pas de point particulier dans l'analyse des lettres. Ils n'ont aucune signification sémantique. Par exemple, la lettre «A» figurera dans chaque texte de la proposition. Considérez que ce neurone est toujours allumé et n'aura aucun effet sur le résultat. Comme toutes les autres voyelles. Et dans le texte de l'application, il y aura la plupart des lettres de l'alphabet. Cette option ne convient pas.
La deuxième variante de la vectorisation: par dictionnaire
Et si vous ne prenez pas des lettres, mais des mots? Disons le dictionnaire explicatif de Dahl. Et pour compter comme 1 déjà la présence d'un mot dans le texte, et l'absence - comme 0.
Mais ici, je suis tombé sur le nombre de mots. Le vecteur s'avérera être très grand. Un neurone avec 200k neurones d'entrée prendra une éternité et nécessitera beaucoup de mémoire et de temps CPU. Vous devez créer votre propre dictionnaire. De plus, il y a une spécificité informatique dans les textes que Vladimir Ivanovitch Dal ne connaissait pas.
Je suis retourné à la théorie. Pour raccourcir le vocabulaire lors du traitement de textes, utilisez les mécanismes de N-grammes - une séquence de N éléments.
L'idée est de diviser le texte d'entrée en certains segments, de composer un dictionnaire à partir d'eux et d'alimenter le réseau de neurones avec la présence ou l'absence d'une phrase dans le texte d'origine comme 1 ou 0. Autrement dit, au lieu d'une lettre, comme dans le cas de l'alphabet, pas seulement une lettre, mais une phrase entière sera considérée comme 0 ou 1.
Les plus populaires sont les unigrammes, les bigrammes et les trigrammes. En utilisant l'expression "Bienvenue dans DataLine" comme exemple, je vais vous parler de chacune des méthodes.
- Unigramme - le texte est divisé en mots: "bon", "bienvenue", "v", "DataLine".
- Bigram - nous le divisons en paires de mots: "bienvenue", "bienvenue à", "à DataLine".
- Trigramme - de même, 3 mots chacun: "bienvenue à", "bienvenue à DataLine".
- N-grammes - vous voyez l'idée. Combien de N, autant de mots d'affilée.
- N-. , . 4- N- : «»,« », «», «» . . .
J'ai décidé de me limiter à l'unigramme. Mais pas seulement un unigramme - les mots sortaient encore trop.
L' algorithme "Porter Stemmer" est venu à la rescousse , qui a été utilisé pour unifier les mots en 1980.
L'essence de l'algorithme: supprimer les suffixes et les fins du mot, ne laissant que la partie sémantique de base. Par exemple, les mots «important», «important», «important», «important», «important», «important» sont ramenés à la base «important». Autrement dit, au lieu de 6 mots, il y en aura un dans le dictionnaire. Et c'est une réduction significative.
De plus, j'ai supprimé du dictionnaire tous les nombres, signes de ponctuation, prépositions et mots rares, afin de ne pas créer de «bruit». En conséquence, pour 100 000 textes, nous avons obtenu un dictionnaire de 3 000 mots. Vous pouvez déjà travailler avec cela.
Formation sur les réseaux neuronaux
Donc j'ai déjà:
- Dictionnaire de 3k mots.
- Représentation de dictionnaire vectorisée.
- Les tailles des couches d'entrée et de sortie du réseau neuronal. Selon la théorie, un dictionnaire est fourni sur la première couche (entrée) et la couche finale (sortie) est le nombre de classes de solution. J'en ai 44 - par le nombre de divisions de l'entreprise.
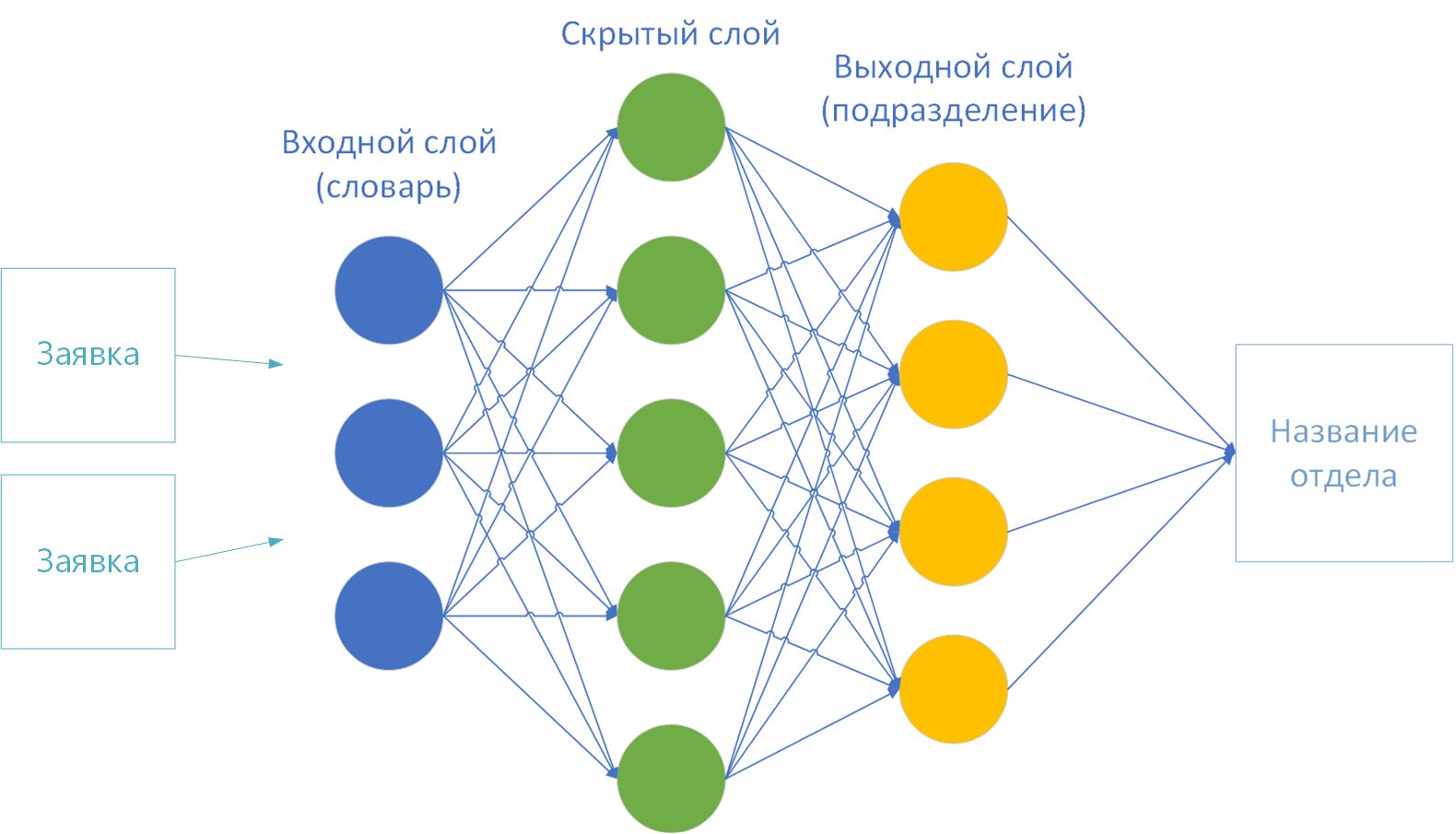
Pour entraîner un réseau de neurones, il reste très peu de choix:
- Méthode d'enseignement.
- Fonction d'activation.
- Le nombre de calques masqués.
Comment j'ai sélectionné les paramètres . Les paramètres sont toujours sélectionnés empiriquement pour chaque tâche spécifique. C'est le processus le plus long et le plus fastidieux, car il nécessite beaucoup d'expérimentation.
J'ai donc pris un échantillon de référence de 11k applications et fait le calcul d'un réseau de neurones avec différents paramètres:
- À 10k, j'ai formé un réseau de neurones.
- À 1k j'ai testé le réseau déjà formé.
Autrement dit, à 10 km, nous construisons un vocabulaire et apprenons. Et puis nous montrons le réseau neuronal formé 1k textes inconnus. Le résultat est le pourcentage d'erreur: le rapport des unités devinées au nombre total de textes.
En conséquence, j'ai atteint une précision d'environ 70% sur des données inconnues.
Empiriquement, j'ai découvert que la formation peut se poursuivre indéfiniment si les mauvais paramètres sont choisis. Plusieurs fois, le neurone est entré dans un cycle de calcul sans fin et a suspendu la machine de travail pour la nuit. Pour éviter cela, pour moi-même, j'ai accepté la limite de 100 itérations ou jusqu'à ce que l'erreur réseau cesse de diminuer.
Voici les paramètres:
Méthode d'enseignement . Encog propose plusieurs options au choix: Rétropropagation, ManhattanPropagation, QuickPropagation, ResilientPropagation, ScaledConjugateGradient.
Ce sont différentes manières de déterminer les poids aux synapses. Certaines méthodes fonctionnent plus rapidement, certaines sont plus précises, il vaut mieux en lire plus dans la documentation. La propagation résiliente a bien fonctionné pour moi .
Fonction d'activation . Il est nécessaire de déterminer la valeur du neurone en sortie, en fonction du résultat de la somme pondérée des entrées et de la valeur seuil.
J'ai choisi parmi 16 options . Je n'ai pas eu assez de temps pour vérifier toutes les fonctions. Par conséquent, j'ai considéré le plus populaire: la tangente sigmoïde et hyperbolique dans diverses implémentations.
En fin de compte, je me suis installé sur ActivationSigmoid .
Nombre de couches cachées... En théorie, plus les couches sont cachées, plus le calcul est long et difficile. J'ai commencé avec une couche: le calcul était rapide, mais le résultat était inexact. Je me suis installé sur deux couches cachées. Avec trois couches, il était considéré comme beaucoup plus long et le résultat ne différait pas beaucoup d'un à deux couches.
Sur ce, j'ai terminé les expériences. Vous pouvez préparer l'outil pour la production.
À la production!
En outre, une question de technologie.
- J'ai foiré Spark pour pouvoir communiquer avec le neurone via REST.
- Enseigné pour enregistrer les résultats du calcul dans un fichier. Pas à chaque fois de recalculer lors du redémarrage du service.
- Ajout de la possibilité de lire les données réelles pour la formation directement depuis le Service Desk. Auparavant formé sur les fichiers csv.
- Ajout de la possibilité de recalculer le réseau neuronal pour attacher le recalcul au planificateur.
- Tout rassemblé dans un pot épais.
- J'ai demandé à mes collègues un serveur plus puissant qu'une machine de développement.
- Zaploil et zadulil racontent une fois par semaine.
- J'ai vissé le bouton au bon endroit dans le Service Desk et j'ai écrit à mes collègues comment utiliser ce miracle.
- J'ai recueilli des statistiques sur ce que le neurone choisit et ce que la personne a choisi (statistiques ci-dessous).
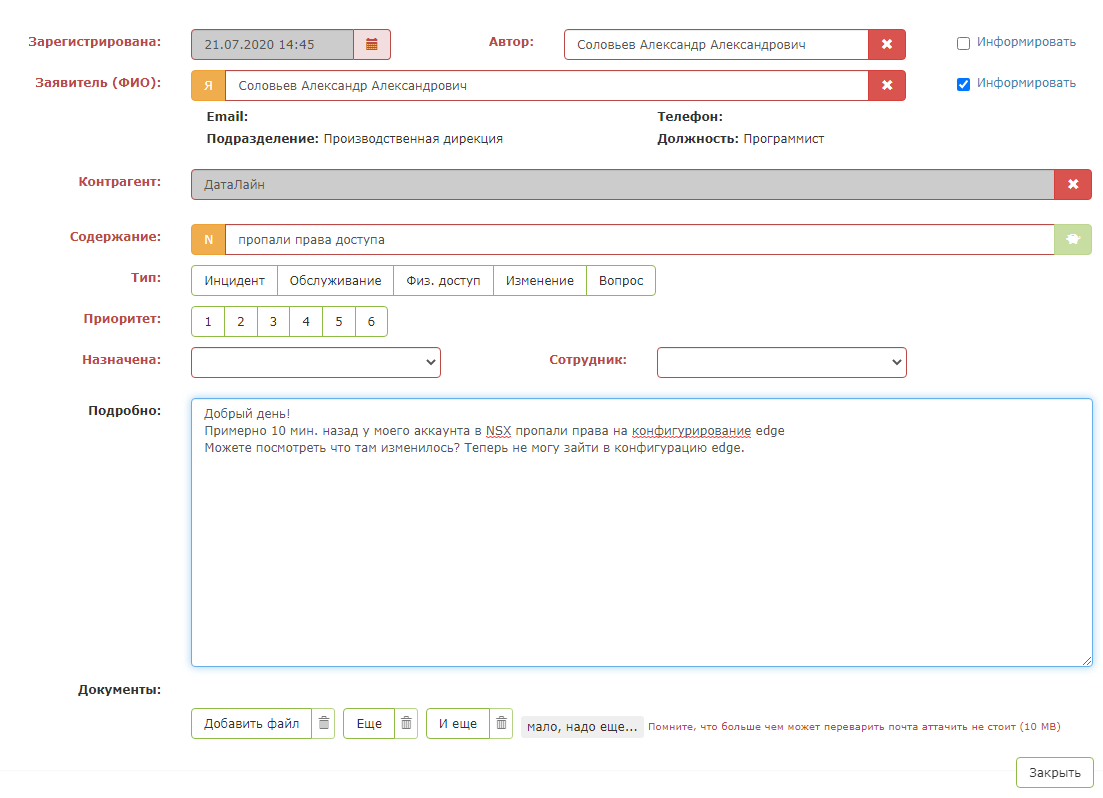
Voici à quoi ressemble une application de test:
Mais dès que vous appuyez sur le "bouton vert magique", la magie opère: les champs de la carte sont remplis. Le répartiteur doit uniquement s'assurer que le système invite correctement et enregistre la demande.
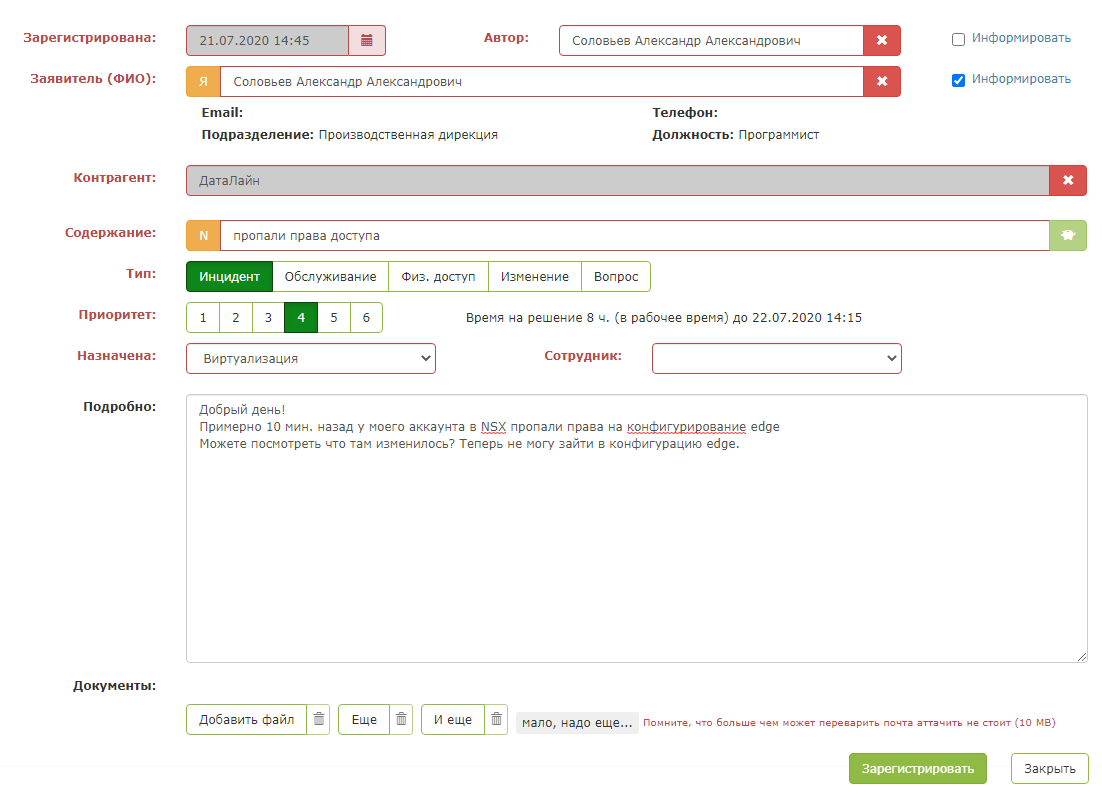
Le résultat est un assistant tellement intelligent pour le répartiteur.
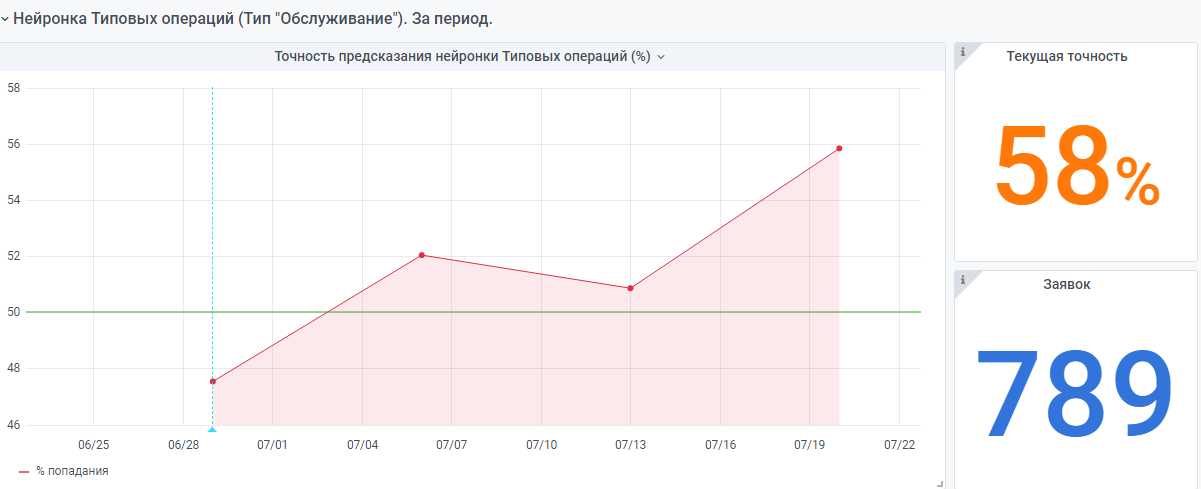
Par exemple, les statistiques du début de l'année.
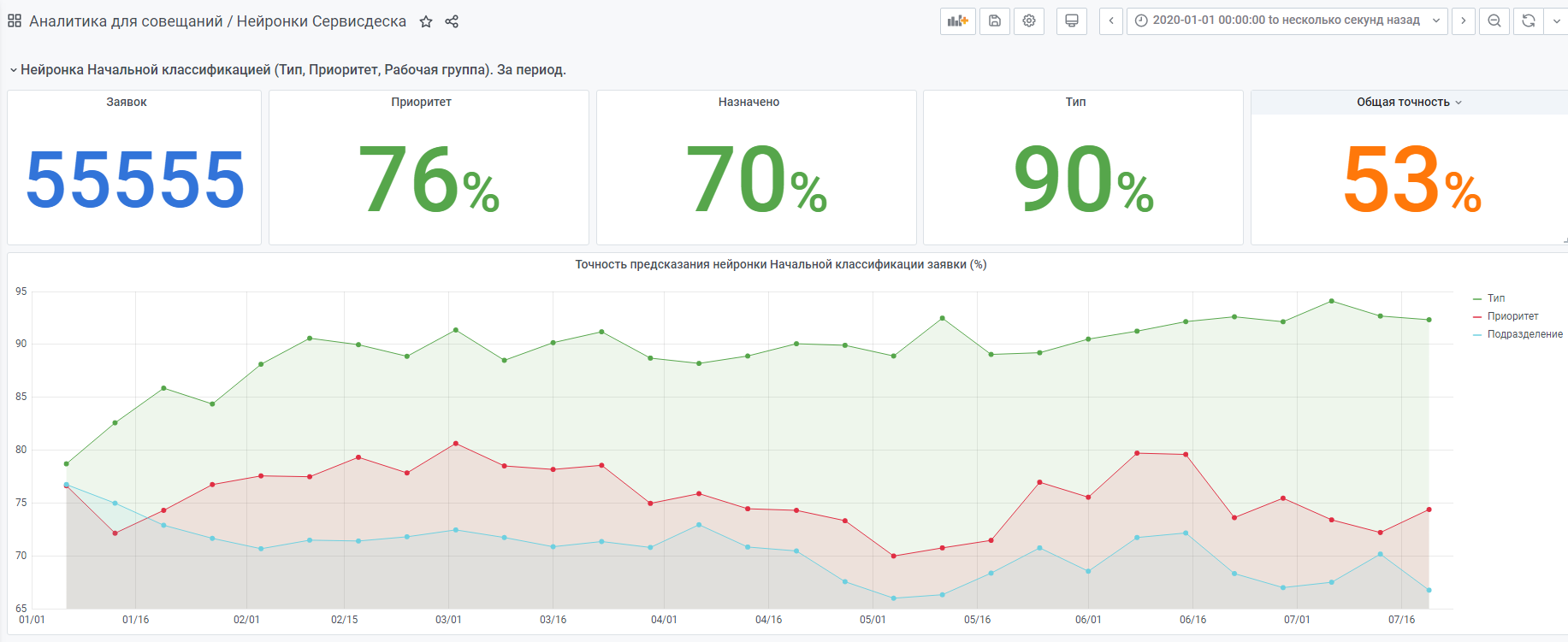
Il existe également un réseau de neurones "très jeune" réalisé selon le même principe. Mais il y a encore peu de données, elle gagne encore en expérience.
Je serai heureux si mon expérience aidera quelqu'un à créer son propre réseau neuronal.
Si vous avez des questions, je serai ravi d'y répondre.