Approche de motivation
L'approche généralement acceptée des tâches de vision par ordinateur consiste à utiliser les images sous forme de tableau 3D (hauteur, largeur, nombre de canaux) et à leur appliquer des convolutions. Cette approche présente plusieurs inconvénients:
- tous les pixels ne sont pas créés égaux. Par exemple, si nous avons une tâche de classification, l'objet lui-même est plus important pour nous que l'arrière-plan. Il est intéressant de noter que les auteurs ne disent pas que Attention est déjà utilisé dans les problèmes de vision par ordinateur;
- Les convolutions ne fonctionnent pas assez bien avec des pixels éloignés. Il existe des approches avec des circonvolutions dilatées et une mise en commun moyenne globale, mais elles ne résolvent pas le problème lui-même;
- Les convolutions ne sont pas assez efficaces dans les réseaux de neurones très profonds.
En conséquence, les auteurs proposent ce qui suit: convertir des images en une sorte de jetons visuels et les soumettre au transformateur.

- Tout d'abord, une épine dorsale régulière est utilisée pour obtenir des cartes de caractéristiques
- Ensuite, la carte des caractéristiques est convertie en jetons visuels
- Les jetons sont envoyés aux transformateurs
- La sortie du transformateur peut être utilisée pour des problèmes de classification
- Et si vous combinez la sortie du transformateur avec une carte des caractéristiques, vous pouvez obtenir des prédictions pour les tâches de segmentation
Parmi les travaux dans des directions similaires, les auteurs mentionnent encore Attention, mais notent que généralement Attention est appliquée aux pixels, par conséquent, augmente considérablement la complexité de calcul. Ils parlent également de travaux sur l'amélioration de l'efficacité des réseaux de neurones, mais ils estiment qu'au cours des dernières années, ils ont apporté de moins en moins d'améliorations, donc d'autres approches doivent être recherchées.
Transformateur visuel
Examinons maintenant de plus près le fonctionnement du modèle.
Comme mentionné ci-dessus, la dorsale récupère les cartes d'entités et elles sont transmises aux couches du transformateur visuel.
Chaque transformateur visuel se compose de trois parties: un tokenizer, un transformateur et un projecteur.
Tokenizer

Le tokenizer récupère les jetons visuels. En fait, nous prenons une carte de caractéristiques, faisons un remodelage en (H * W, C) et à partir de là, nous obtenons des jetons. La

visualisation des coefficients pour les jetons ressemble à ceci:

Codage de position
Comme d'habitude, les transformateurs ont besoin non seulement de jetons, mais également d'informations sur leur position.

Tout d'abord, nous faisons un sous-échantillon, puis nous multiplions par les poids d'entraînement et nous concaténons avec des jetons. Pour régler le nombre de canaux, vous pouvez ajouter une convolution 1D.
Transformateur
Enfin, le transformateur lui-même.

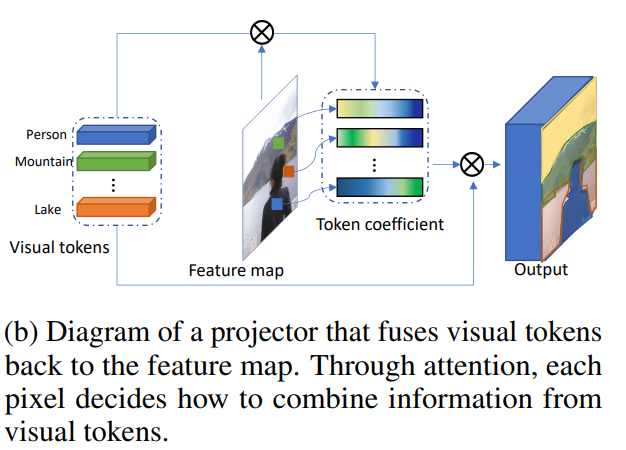
Combinaison de jetons visuels et de carte des fonctionnalités
Cela rend le projecteur.

Tokenisation dynamique
Après la première couche de transformateurs, nous pouvons non seulement extraire de nouveaux jetons visuels, mais également utiliser ceux extraits des étapes précédentes. Des poids entraînés sont utilisés pour les combiner:

Utilisation de transformateurs visuels pour créer des modèles de vision par ordinateur
En outre, les auteurs décrivent comment le modèle est appliqué aux problèmes de vision par ordinateur. Les blocs de transformateur ont trois hyperparamètres: le nombre de canaux dans la carte des caractéristiques C, le nombre de canaux dans le jeton visuel Ct et le nombre de jetons visuels L.Si
le nombre de canaux s'avère inapproprié lors de la transition entre les blocs du modèle, les convolutions 1D et 2D sont utilisées pour obtenir le nombre de canaux requis.
Pour accélérer les calculs et réduire la taille du modèle, utilisez des convolutions de groupe.
Les auteurs attachent des blocs ** pseudocode ** dans l'article. Le code complet est promis d'être publié à l'avenir.
Classification des images
Nous prenons ResNet et créons des visual-transformer-ResNets (VT-ResNet) sur cette base.
Nous quittons l'étape 1 à 4, mais au lieu de la dernière, nous mettons des transformateurs visuels.
Sortie de la dorsale - Carte des caractéristiques 14 x 14, nombre de canaux 512 ou 1024 selon la profondeur de VT-ResNet. 8 jetons visuels pour 1024 canaux sont créés à partir de la carte des caractéristiques. La sortie du transformateur va à la tête pour la classification.

Segmentation sémantique
Pour cette tâche, les réseaux pyramidaux de caractéristiques panoptiques (FPN) sont pris comme modèle de base.
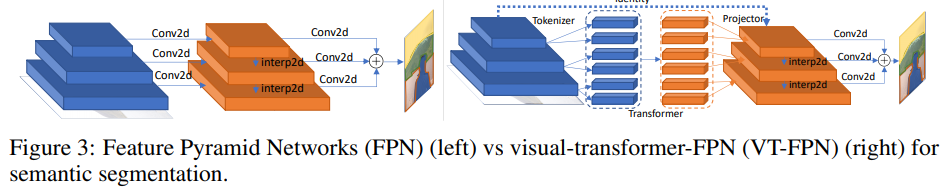
Dans FPN, les convolutions fonctionnent sur des images haute résolution, donc le modèle est lourd. Les auteurs remplacent ces opérations par un transformateur visuel. Encore une fois, 8 jetons et 1024 canaux.
Expériences
Classification ImageNet
Entraînez 400 époques avec RMSProp. Ils commencent avec un taux d'apprentissage de 0,01, augmentent à 0,16 pendant 5 périodes d'échauffement, puis multiplient chaque époque par 0,9875. On utilise la normalisation des lots et la taille des lots 2048. Lissage des étiquettes, AutoAugment, probabilité de survie en profondeur stochastique 0,9, abandon 0,2, EMA 0,99985.
C'est le nombre d'expériences que j'ai dû faire pour trouver tout cela ...
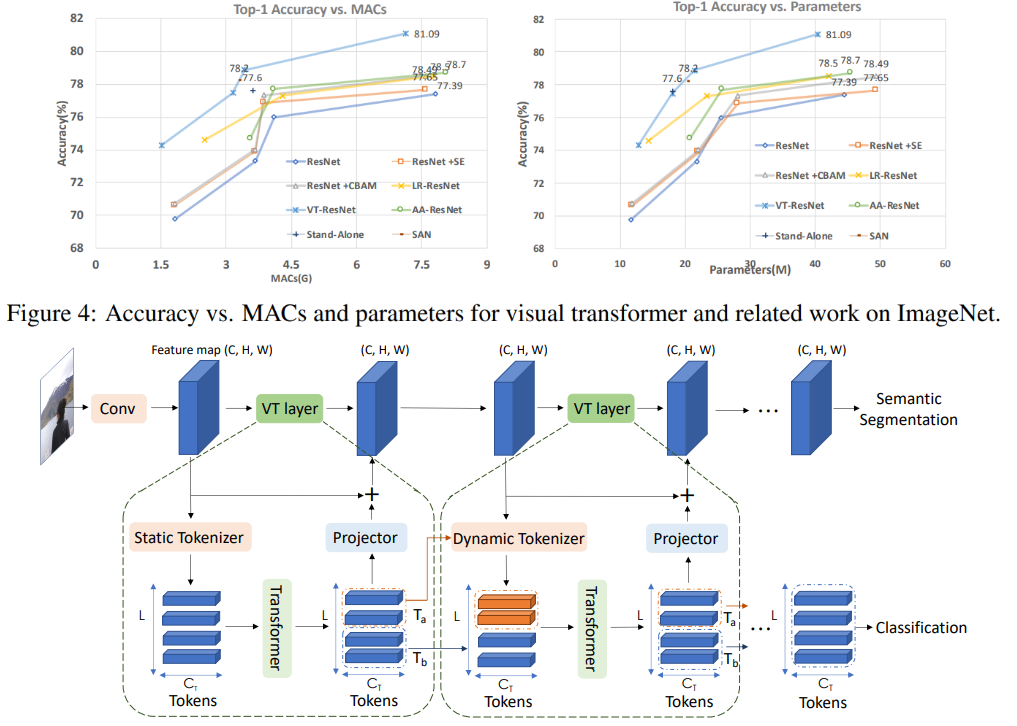
Sur ce graphique, vous pouvez voir que l'approche donne une meilleure qualité avec un nombre de calculs réduit et la taille du modèle.
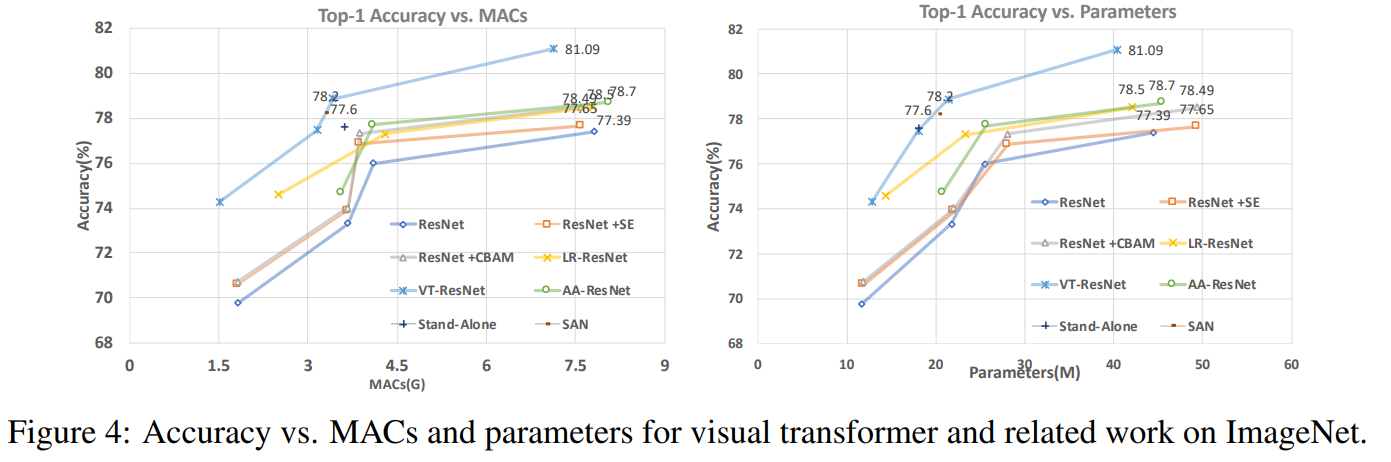
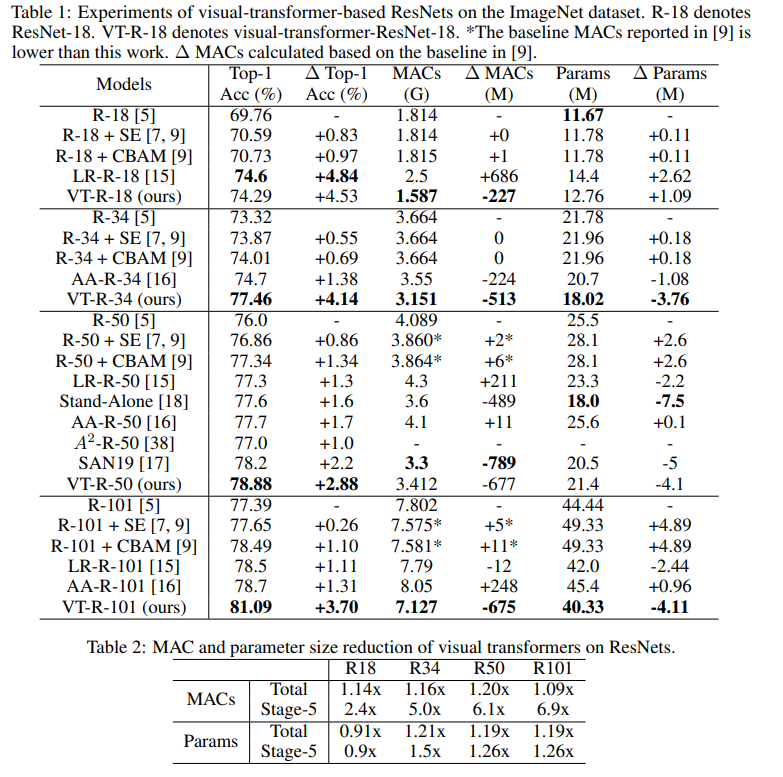
Titres d'articles pour les modèles comparés:
ResNet + CBAM - Module d'attention de bloc par convolution
ResNet + SE - Réseaux de compression et d'excitation
LR-ResNet - Réseaux de relations locales pour la reconnaissance d'images
Autonome - Auto-attention autonome dans les modèles de vision
AA-ResNet - Attention augmentée réseaux convolutifs
SAN - Explorer l'auto-attention pour la reconnaissance d'image
Etude d'ablation
Pour accélérer les expériences, nous avons utilisé VT-ResNet- {18, 34} et formé 90 époques.
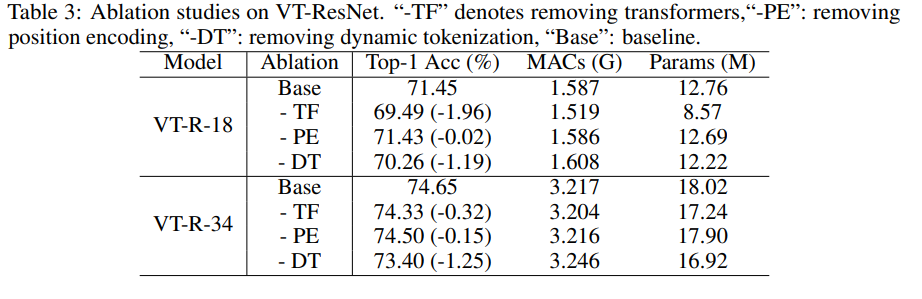
L'utilisation de transformateurs au lieu de convolutions donne le plus grand gain. La tokenisation dynamique au lieu de la tokenisation statique donne également un gros coup de pouce. Le codage de position n'apporte qu'une légère amélioration.
Résultats de segmentation

Comme vous pouvez le voir, la métrique n'a augmenté que légèrement, mais le modèle consomme 6,5 fois moins de MAC.
Futur potentiel de l'approche
Des expériences ont montré que l'approche proposée permet de créer des modèles plus efficaces (en termes de coûts de calcul), qui en même temps atteignent une meilleure qualité. L'architecture proposée fonctionne avec succès pour diverses tâches de vision par ordinateur, et on espère que son application contribuera à améliorer les systèmes utilisant la vision par ordinateur - AR / VR, voitures autonomes, etc.
La revue a été préparée par Andrey Lukyanenko, le principal développeur de MTS.