Environ. trad. : L'auteur de cet article (Luc Perkins) est un développeur défenseur de la CNCF, qui héberge des projets Open Source comme Linkerd, SMI (Service Mesh Interface) et Kuma (au fait, vous êtes-vous également demandé pourquoi Istio ne figure pas sur cette liste?. .). Dans une autre tentative pour apporter une meilleure compréhension du battage médiatique du maillage de services à la communauté DevOps, il cite 16 capacités caractéristiques qui fournissent de telles solutions. Le maillage de service est l'un des sujets les plus brûlants de l'ingénierie logicielle
aujourd'hui(et à juste titre!). Je trouve cette technologie incroyablement prometteuse et mon rêve est d'assister à son adoption généralisée (quand cela a du sens, bien sûr). Cependant, il est toujours entouré d'un halo de mystère pour la plupart des gens. De plus, même ceux quien connaît bien , il est souvent difficile de formuler ses avantages et de quoi il s'agit exactement (y compris votre humble serviteur). Dans cet article, j'essaierai de remédier à la situation en listant différents scénarios d'utilisation des «grilles de service» *.
* Environ. transl.: ci-après dans l'article, nous utiliserons une telle traduction ("service mesh") pour le terme encore nouveau service mesh.
Mais d'abord, je veux faire quelques commentaires:
- , . , service mesh Twitter 2015 ( « ») Linkerd, - .
- — . , , .
- Dans le même temps, toutes les implémentations de service mesh existantes ne prennent pas en charge tous ces cas d'utilisation. Par conséquent, mes expressions comme "service mesh can ..." devraient être lues comme "séparées, et éventuellement toutes les implémentations de service mesh populaires peuvent ...".
- L'ordre des exemples n'a pas d'importance.
Liste courte:
- découverte de services;
- chiffrement;
- Authentification et autorisation;
- l'équilibrage de charge;
- coupure de circuit;
- mise à l'échelle automatique;
- déploiements Canary;
- déploiements bleu-vert;
- Bilan de santé;
- délestage;
- mise en miroir du trafic;
- isolation;
- limitation du débit, tentatives et délais d'expiration;
- télémétrie;
- Audit;
- visualisation.
1. Découverte des services
TL; DR: connectez-vous à d'autres services sur le réseau en utilisant des noms simples.
Les services doivent pouvoir se «découvrir» automatiquement via un nom approprié - par exemple
service.api.production, pets/stagingou cassandra. Les environnements cloud sont résilients et un seul nom peut masquer plusieurs instances d'un service. Il est clair que dans une telle situation, il est physiquement impossible de coder en dur toutes les adresses IP.
De plus, lorsqu'un service en trouve un autre, il devrait être en mesure d'envoyer des requêtes à ce service sans craindre qu'elles se retrouvent à l'entrée de son instance inactive. En d'autres termes, le maillage de service doit surveiller l'intégrité de toutes les instances de service et maintenir la liste des hôtes à jour.
Chaque maillage de service implémente un mécanisme de découverte de service différemment. Pour le moment, le moyen le plus courant consiste à déléguer à des processus externes comme DNS Kubernetes. Dans le passé, sur Twitter, nous utilisions le système de dénomination Finagle à cette fin . De plus, la technologie de maillage de service permet l'émergence de mécanismes de dénomination personnalisés (bien que je n'ai pas encore rencontré d'implémentation SM avec cette fonctionnalité).
2. Chiffrement
TL; DR: éliminez le trafic non chiffré entre les services et rendez le processus automatisé et évolutif.
Il est bon de savoir que les attaquants ne peuvent pas pénétrer votre réseau interne. Les pare-feu font un excellent travail à cet égard. Mais que se passe-t-il si un hacker pénètre à l'intérieur? Peut-il faire ce qu'il veut avec le trafic intra-service? Espérons que cela n'arrive pas. Pour éviter ce scénario, vous devez implémenter un réseau de confiance zéro dans lequel tout le trafic entre les services est chiffré. La plupart des mailles de service modernes y parviennent grâce au TLS mutuel .(TLS mutuel, mTLS). Dans certains cas, mTLS fonctionne dans des nuages et des clusters entiers (je pense que les communications interplanétaires seront un jour organisées de la même manière).
Bien entendu, pour mTLS, le service mesh est facultatif . Chaque service peut prendre en charge son propre TLS, mais cela signifie qu'il sera nécessaire de trouver un moyen de générer des certificats, de les répartir entre les hôtes de service, d'inclure du code dans l'application qui chargera ces certificats à partir de fichiers. Oui, pensez également à renouveler ces certificats à intervalles réguliers. Les grilles de service automatisent mTLS avec des systèmes comme SPIFFE , qui à leur tour automatisent le processus d'émission et de rotation des certificats.
3. Authentification et autorisation
TL; DR: déterminez qui a lancé la demande et déterminez ce qu'il est autorisé à faire avant que la demande n'atteigne le service.
Les services veulent souvent savoir qui fait la demande (authentification) et, en utilisant ces informations, décident de ce que le sujet est autorisé à faire (autorisation). Dans ce cas, le pronom "qui" peut cacher:
- Autres services. C'est ce qu'on appelle « l' authentification par les pairs ». Par exemple, un service
websouhaite accéder à un servicedb. Les maillages de service résolvent généralement ces problèmes avec mTLS: les certificats dans ce cas agissent comme un identifiant nécessaire. - -. « ». ,
haxor69. , , JSON Web Tokens.
. ,users, ,permissions.. service mesh , .
Après avoir établi de qui provient la demande, nous devons déterminer ce que ce sujet est autorisé à faire. Certains maillages de service vous permettent de définir des politiques de base (qui peut faire quoi) sous forme de fichiers YAML ou sur la ligne de commande, tandis que d'autres offrent une intégration avec des frameworks comme l' Open Policy Agent . Le but ultime est de garantir que vos services acceptent toutes les demandes, en supposant en toute sécurité qu'elles proviennent d'une source fiable et que cette action est autorisée.
4. Équilibrage de charge
TL; DR: répartition des charges entre les instances de service selon un modèle spécifique.
Un «service» au sein d'une secte de services se compose très souvent de nombreuses instances identiques. Par exemple, aujourd'hui, le service se
cachecompose de 5 exemplaires, et demain leur nombre pourrait augmenter à 11. Les demandes adressées à cachedevraient être distribuées conformément à un objectif précis. Par exemple, minimisez la latence ou maximisez la probabilité d'accéder à une instance saine. L'algorithme round-robin le plus couramment utilisé (Round-robin), mais il en existe beaucoup d'autres - par exemple, la méthode des requêtes pondérées (pondérées) (vous pouvez sélectionner la cible préférée), annulaire (anneau)hachage (en utilisant un hachage cohérent pour les hôtes en amont) ou la méthode de moindre demande (l'instance avec le moins de demandes est préférée).
Les équilibreurs de charge classiques ont d'autres fonctionnalités, telles que la mise en cache HTTP et la protection DDoS, mais ils ne sont pas très pertinents pour le trafic est-ouest (c'est-à-dire pour le trafic circulant dans un centre de données - environ Transl.) (Utilisation typique du service engrener). Bien sûr, vous n'avez pas besoin d'utiliser un maillage de services pour l'équilibrage de charge, mais cela vous permet de définir et de contrôler des politiques d'équilibrage pour chaque service à partir d'une couche de gestion centralisée, éliminant ainsi le besoin d'exécuter et de configurer des équilibreurs de charge séparés dans la pile réseau.
5. coupure de circuit
TL; DR: arrêtez le trafic vers un service problématique et contrôlez les dommages dans les pires scénarios.
Si, pour une raison quelconque, le service est incapable de gérer le trafic, le service mesh fournit plusieurs options pour résoudre ce problème (d'autres seront discutées dans les sections correspondantes). La coupure de circuit est le moyen le plus sévère de déconnecter un service du trafic. Cependant, cela n'a pas de sens en soi - vous avez besoin d'un plan de sauvegarde. Peut fournir une contre-pression (contre- pression ) sur les services qui interrogent (n'oubliez pas de configurer votre service mesh pour cela!), Ou, par exemple, coloration du statut de la page en rouge et rediriger les utilisateurs vers une autre version de la page avec le "baleine qui tombe" («Twitter est éteint ").
Les grilles de service font plus que simplement déterminer quand et ce qui va se passer ensuite. Dans ce cas, "quand" peut inclure toute combinaison des paramètres spécifiés: le nombre total de requêtes pour une certaine période, le nombre de connexions parallèles, les requêtes en attente, les tentatives actives, etc.
Vous ne voulez probablement pas abuser de la coupure de circuit, mais il est bon de savoir qu'il existe un plan d'urgence pour les urgences.
6. Zoom automatique
TL; DR: Augmentez ou diminuez le nombre d'instances de service en fonction des critères spécifiés.
Les maillages de service ne sont pas des planificateurs, ils ne se développent donc pas d' eux-mêmes. Cependant, ils peuvent fournir des informations sur la base desquelles les planificateurs prendront des décisions. Les maillages de services ayant accès à tout le trafic entre les services, ils disposent d'une mine d'informations sur ce qui se passe: quels services rencontrent des problèmes, qui sont très faiblement chargés (la capacité allouée est gaspillée), etc.
Par exemple, Kubernetes met à l'échelle les services en fonction de l'utilisation du processeur et de la mémoire des pods (voir notre présentation " Autoscaling et gestion des ressources dans Kubernetes " - environ Transl.), mais si vous décidez de mettre à l'échelle en fonction de toute autre métrique (dans notre cas, liée au trafic), vous aurez besoin d'une métrique spéciale. Un tutoriel comme celui -ci vous montre comment faire cela avec Envoy , Istio et Prometheus , mais le processus lui-même est assez complexe. Nous aimerions que le maillage de services le simplifie en autorisant simplement des conditions telles que «augmenter le nombre d'instances de service
authsi le nombre de demandes en attente dépasse le seuil pendant une minute».
7. Déploiements Canary
TL; DR: essayez de nouvelles fonctionnalités ou versions de service sur un sous-ensemble d'utilisateurs.
Disons que vous développez un produit SaaS et que vous avez l'intention d'en déployer une nouvelle version sympa. Vous l'avez testé en mise en scène et cela a très bien fonctionné. Mais encore, il y a certaines inquiétudes concernant son comportement dans des conditions réelles. En d'autres termes, il est nécessaire de tester la nouvelle version sur des tâches réelles, sans risquer la confiance des utilisateurs. Les déploiements Canary sont parfaits pour cela. Ils vous permettent de présenter une nouvelle fonctionnalité à un sous-ensemble d'utilisateurs. Ce sous-ensemble peut être les utilisateurs les plus fidèles, ou ceux qui utilisent la version gratuite du produit, ou ceux qui ont exprimé le désir d'être des cobayes.
Les maillages de service le font en vous permettant de spécifier des critères qui déterminent qui voit quelle version de votre application et achemine le trafic en conséquence. En même temps, rien ne change pour les services eux-mêmes. La version 1.0 du service estime que toutes les demandes proviennent d'utilisateurs qui devraient le voir, et la version 1.1 suppose la même chose pour ses utilisateurs. En attendant, vous pouvez modifier le pourcentage de trafic entre l'ancienne et la nouvelle version, en redirigeant un nombre croissant d'utilisateurs vers la nouvelle, si cela fonctionne de manière stable et que votre "expérimental" donne le feu vert.
8. Déploiements bleu-vert
TL; DR: déployez la nouvelle fonctionnalité intéressante, mais soyez prêt à la réintégrer immédiatement.
Le but des déploiements bleu-vert est de déployer un nouveau service bleu en l'exécutant en parallèle avec l'ancien service vert. Si tout se passe bien et que le nouveau service fait ses preuves, l'ancien peut être progressivement désactivé. (Hélas, un jour, ce nouveau service "bleu" répétera le sort du "vert" et disparaîtra ...) Les déploiements bleu-vert diffèrent des déploiements canaris en ce que la nouvelle fonction couvre tous les utilisateurs à la fois (pas seulement une partie); le point ici est d'avoir un "refuge de rechange" prêt au cas où quelque chose ne va pas.
Les maillages de service offrent un moyen très pratique de tester un service bleu et de passer instantanément à un vert fonctionnel en cas de problème. Sans parler du fait qu'en cours de route, ils donnent beaucoup d'informations (voir l'élément "Télémétrie" ci-dessous) sur le travail du "bleu", ce qui permet de comprendre s'il est prêt pour une exploitation à part entière.
Environ. trad. : En savoir plus sur les différentes stratégies de déploiement de Kubernetes (y compris le canari mentionné, le bleu / vert et autres) dans cet article .
9. Bilan de santé
TL; DR: Gardez une trace des instances de service actives et réagissez à celles qui ne le sont plus.
Une vérification de l'état vous aide à décider si les instances de service sont prêtes à recevoir et à traiter le trafic. Par exemple, dans le cas des services HTTP, une vérification de l'état peut ressembler à une requête GET adressée à un point de terminaison
/health. La réponse 200 OKsignifiera que l'instance est saine, toute autre - qu'elle n'est pas prête à recevoir du trafic. Les maillages de service vous permettent de spécifier à la fois la manière dont la santé sera vérifiée et la fréquence à laquelle cette vérification sera effectuée. Ces informations peuvent ensuite être utilisées à d'autres fins, telles que l'équilibrage de charge et la coupure de circuit.
Ainsi, le bilan de santé n'est pas un cas d'utilisation indépendant, mais est généralement utilisé pour atteindre d'autres objectifs. En outre, en fonction des résultats des vérifications de l'état, des actions externes (par rapport à d'autres cibles des grilles de service) peuvent être nécessaires: par exemple, actualiser la page d'état, créer un problème sur GitHub ou remplir un ticket JIRA. Et le service mesh offre un mécanisme pratique pour automatiser tout cela.
10. Délestage de charge
TL; DR: redirige le trafic en réponse à des pics d'utilisation temporaires.
Si un service est surchargé de trafic, vous pouvez temporairement rediriger une partie de ce trafic vers un autre emplacement (c'est-à-dire «vider», « jeter» là-bas). Par exemple, vers un service de sauvegarde ou un centre de données, ou vers un sujet Pulsar permanent . En conséquence, le service continuera à traiter une partie des demandes au lieu de planter et d'arrêter de tout traiter. Il est préférable de vider la charge plutôt que de couper le circuit, mais il n'est toujours pas souhaitable d'en abuser. Cela permet d'éviter les pannes en cascade qui provoquent le blocage des services en aval.
11. Parallélisation / mise en miroir du trafic
TL; DR: envoyez une demande à plusieurs emplacements à la fois.
Parfois, il devient nécessaire d'envoyer une demande (ou un échantillon de demandes) à plusieurs services à la fois. Un exemple typique est l'envoi d'une partie du trafic de production vers un service intermédiaire. Le serveur Web de production principal envoie une demande
products.productionuniquement au service en aval . Et le service mesh copie intelligemment cette demande et l'envoie à products.staging, ce dont le serveur Web n'est même pas au courant.
Un autre cas d'utilisation de grille de service connexe qui peut être implémenté en plus de la parallélisation du trafic est le test de régression.... Il s'agit d'envoyer les mêmes demandes à différentes versions d'un service et de vérifier si toutes les versions se comportent de la même manière. Je n'ai pas encore rencontré d'implémentation de service mesh avec un système de test de régression intégré comme Diffy , mais l'idée elle-même semble prometteuse.
12. Isolation
TL; DR: Divisez votre maillage de service en mini-mailles.
Également connu sous le nom de segmentation , l'isolement est l'art de diviser une grille de services en segments logiquement distincts qui ne se connaissent pas. L'isolement, c'est un peu comme créer des réseaux privés virtuels. La différence fondamentale est que vous pouvez toujours profiter de tous les avantages du maillage de services (comme la découverte de services), mais avec une sécurité accrue. Par exemple, si un attaquant parvient à pénétrer un service sur l'un des sous-réseaux, il ne pourra pas voir quels services s'exécutent sur d'autres sous-réseaux ou intercepter leur trafic.
De plus, les avantages peuvent être d'ordre organisationnel. Vous souhaiterez peut-être créer un sous-réseau de vos services en fonction de la structure de votre organisation et soulager les développeurs du fardeau cognitif lié à la prise en compte de l'ensemble du maillage de services.
13. Limitation de débit, tentatives et délais d'expiration
TL; DR: Plus besoin d'inclure les tâches urgentes de gestion des demandes dans la base de code.
Tous ces éléments peuvent être considérés comme des cas d'utilisation distincts, mais j'ai décidé de les combiner pour un point commun: ils prennent en charge les tâches de gestion du cycle de vie des demandes généralement gérées par les bibliothèques d'applications. Si vous développez un serveur Web Ruby on Rails (non intégré au service mesh) qui fait des demandes aux services backend via gRPC, l'application devra décider quoi faire si N requêtes échouent. Vous devrez également connaître le trafic que ces services pourront gérer et coder en dur ces paramètres à l'aide d'une bibliothèque spéciale. De plus, l'application devra décider du moment où abandonner et laisser la demande mal tourner (avant l'expiration du délai). Et pour modifier l'un des paramètres ci-dessus, le serveur Web devra être arrêté, reconfiguré et redémarré.
Le transfert de ces tâches vers la grille de services signifie non seulement que les développeurs de services n'ont pas besoin d'y penser, mais aussi qu'ils peuvent être visualisés de manière plus globale. Si vous utilisez une chaîne complexe de services, disons A -> B -> C -> D -> E, le cycle de vie complet de la demande doit être pris en compte. Si la tâche consiste à prolonger les délais d'expiration dans le service C, il est logique de tout faire en même temps, et non par parties: en mettant à jour le code de service et en attendant que la pull request soit acceptée et que le système CI déploie le service mis à jour.
14. Télémétrie
TL; DR: Collectez toutes les informations nécessaires (et pas tout à fait) auprès des services.
La télémétrie est un terme générique qui inclut les métriques, le traçage distribué et la journalisation. Les grilles de services offrent des mécanismes de collecte et de traitement des trois types de données. C'est là que les choses deviennent un peu floues car il y a tellement d'options disponibles. Pour les mesures collectons, il y a Prométhée et d' autres outils, aux journaux virés vous pouvez utiliser fluentd , Loki , vecteur , etc. (par exemple, ClickHouse avec notre loghouse pour K8S -. Approx.transl) , pour le suivi distribué il y a Jaegeretc. Chaque service mesh peut prendre en charge certains outils et pas d'autres. Il sera curieux de voir si le projet Open Telemetry peut fournir une certaine convergence.
Dans ce cas, l'avantage de la technologie de maillage de service est que les conteneurs side-car peuvent, en principe, collecter toutes les données ci-dessus à partir de leurs services. En d'autres termes, vous disposez d'un système de collecte de télémétrie unifié et le service mesh peut traiter toutes ces informations de différentes manières. Par exemple:
- tail 'les journaux d'un certain service dans la CLI;
- suivre le volume des demandes à partir du tableau de bord du maillage de service;
- collectez les traces distribuées et redirigez-les vers un système comme Jaeger.
Attention, jugement subjectif: De manière générale, la télémétrie est un domaine où une forte interférence de maillage de service n'est pas souhaitable. Rassembler des informations de base et suivre à la volée certaines des "mesures en or" comme les taux de réussite et les latences est bien, mais espérons que nous ne verrons pas émerger des piles de Frankenstein qui tentent de remplacer des systèmes spécialisés, dont certains se sont déjà avérés excellents. et bien étudié.
15. Audit
TL; DR: Ceux qui oublient les leçons de l'histoire sont voués à les répéter.
L'audit est l'art d'observer les événements importants du système. Dans le cas d'un maillage de services, cela peut signifier garder une trace de qui a fait des demandes à des points de terminaison spécifiques de certains services, ou combien de fois au cours du mois dernier il y a eu un événement lié à la sécurité.
Il est clair que l'audit est très étroitement lié à la télémétrie. La différence est que la télémétrie est généralement associée à des éléments tels que les performances et l'exactitude technique, tandis que l'audit peut être lié à des problèmes juridiques et autres qui vont au-delà du domaine strictement technique (par exemple, le respect des exigences du RGPD - Règlement général de l'UE pour la protection des données).
16. Visualisation
TL; DR: vive React.js - une source inépuisable d'interfaces sophistiquées.
Il y a peut-être un meilleur terme, mais je ne le connais pas. Je veux simplement dire une représentation graphique du maillage de service ou de certains de ses composants. Ces visualisations peuvent inclure des indicateurs tels que les latences moyennes, les informations de configuration du side-car, les résultats de la vérification de l'état et les alertes.
Travailler dans un environnement axé sur les services comporte une charge cognitive beaucoup plus élevée que Sa Majesté le Monolithe. Par conséquent, la pression cognitive doit être réduite à tout prix. Une interface graphique ringarde pour un maillage de services avec la possibilité de cliquer sur un bouton et d'obtenir le résultat souhaité peut être essentielle à la croissance de la popularité de cette technologie.
Non inclus dans la liste
J'avais initialement l'intention d'inclure quelques autres cas d'utilisation dans la liste, mais j'ai ensuite décidé de ne pas le faire. Les voici, ainsi que les raisons de ma décision:
- Centre de données multiples . À mon avis, il ne s'agit pas tant d'un cas d'utilisation que d'un domaine d'application étroit et spécifique des grilles de services ou d'un ensemble de fonctions comme la découverte de services.
- Entrée et sortie . C'est un domaine connexe, mais je me suis limité (peut-être artificiellement) au scénario de trafic est-ouest. L'entrée et la sortie méritent un article séparé.
Conclusion
C'est tout pour le moment! Encore une fois, cette liste est très provisoire et très probablement incomplète. Si vous pensez que je manque quelque chose ou que je me trompe, veuillez me contacter sur Twitter ( @lucperkins ). Veuillez observer les règles de décence.
PS du traducteur
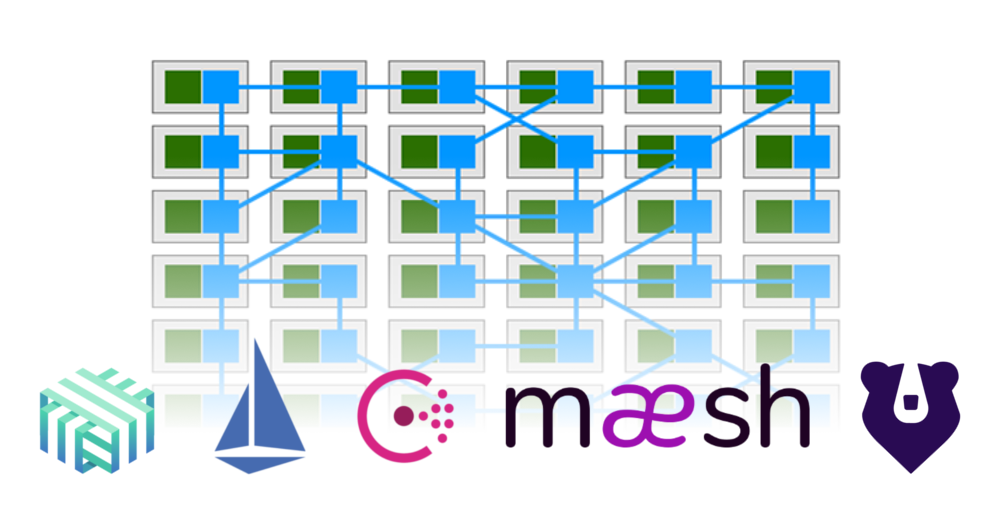
Comme base pour l'illustration du titre de l'article, une image de l'article « Qu'est-ce qu'un Service Mesh (et quand en utiliser un)? "(Par Gregory MacKinnon). Il montre comment une partie des fonctionnalités des applications (en vert) s'est déplacée vers le maillage de service, qui fournit les relations entre elles (en bleu).
Lisez aussi sur notre blog: