
En 2020, l'apprentissage automatique sur les plates-formes mobiles n'est plus révolutionnaire. L'intégration de fonctionnalités intelligentes dans les applications est devenue une pratique courante.
Heureusement, cela ne signifie pas qu'Apple a cessé de développer des technologies innovantes.
Dans cet article, je partagerai brièvement les nouvelles concernant la plate-forme Core ML et d'autres technologies d'intelligence artificielle et d'apprentissage automatique dans l'écosystème Apple.
ML de base
L'année dernière, la plateforme Core ML a fait l'objet d'une mise à jour majeure. Cette année, les choses sont beaucoup plus modestes: plusieurs nouveaux types de couches ont été ajoutés, la prise en charge des modèles de chiffrement et la possibilité de publier des mises à jour des modèles sur CloudKit.
Il semble que la décision a été prise de supprimer les numéros de version. Après la mise à jour de l'année dernière, la plate-forme est devenue Core ML 3, mais elle utilise maintenant le nom Core ML sans numéro de version. Cependant, le package coremltools a été mis à jour vers la version 4.
Remarque . La spécification interne de mlmodel est désormais la version 5, ce qui signifie que de nouveaux modèles apparaîtront dans Netron avec le nom "Core ML v5".
Nouveaux types de calques dans Core ML
Les couches suivantes ont été ajoutées:
Convolution3DLayer, Pooling3DLayer, GlobalPooling3DLayer: — Vision ( Core ML - , ).OneHotLayer: .ClampedReLULayer: ReLU ( ReLU6).- ArgSortLayer: . . , GatherLayer, argsort.
CumSumLayer: .SliceBySizeLayer: Plusieurs types de couches fractionnées sont déjà disponibles dans Core ML. Cette couche permet de passer un tenseur contenant l'index à partir duquel la partition va démarrer. Dans le même temps, la taille du secteur reste toujours fixe.
Ces types de couches peuvent être utilisés à partir de la version 5, c'est-à-dire dans iOS 14 et macOS 11.0 ou version ultérieure.
Autre amélioration utile: opérations quantifiées 8 bits pour les couches suivantes:
InnerProductLayerBatchedMatMulLayer
Dans les versions précédentes de Core ML, les poids étaient quantifiés, mais après le chargement du modèle, ils étaient reconvertis au format à virgule flottante. La nouvelle fonctionnalité
int8DynamicQuantizepermet de stocker les pondérations sous forme de valeurs entières 8 bits et d'effectuer des calculs réels en utilisant également des entiers.
Les calculs utilisant INT8 peuvent être beaucoup plus rapides que les opérations en virgule flottante. Cela offre certains avantages au processeur, mais il n'est pas certain que les performances des GPU s'améliorent, car les opérations en virgule flottante sont très efficaces pour eux. Peut-être que dans une future mise à jour du Neural Engine, la prise en charge intégrée des opérations INT8 sera implémentée (après tout, Apple a récemment acquis Xnor.ai ...).
Côté CPU, Core ML peut désormais également utiliser la virgule flottante 16 bits au lieu de 32 bits sur eux (sur A11 Bionic et supérieur). Comme nous l'avons vu dans la vidéo Explorez le calcul numérique dans Swift , Float16 est désormais le premier type de données de Swift. Avec la prise en charge native des opérations en virgule flottante 16 bits, Core ML peut doubler la vitesse!
Remarque . Dans Core ML, le type de données Float16 était déjà utilisé sur les GPU et le Neural Engine, de sorte que les différences ne seront perceptibles que lorsqu'elles sont utilisées sur le CPU.
Autres changements (mineurs):
UpsampleLayer. BILINEAR ( align-corners). , , .-
ReorganizeDataLayerParamsPIXEL_SHUFFLE. , . , . -
SliceStaticLayerSliceDynamicLayersqueezeMasks, . -
TileLayer, .
Il ne semble y avoir aucun changement en ce qui concerne l'apprentissage local sur les appareils: seules les couches entièrement connectées et convolutives sont toujours prises en charge. La classe
MLParameterKeyde CoreML.framework contient désormais un paramètre de configuration pour l'optimiseur RMSprop , mais cette amélioration n'est pas encore incluse dans NeuralNetwork.proto . Peut-être qu'il sera ajouté dans la prochaine version bêta.
Les nouveaux types de modèles suivants ont été ajoutés :
VisionFeaturePrint.Object- Unité d'extraction de caractéristiques optimisée pour la reconnaissance d'objets.
SerializedModel... Je ne sais pas exactement à quoi cela sert. Il s'agit d'une définition «privée» et «sujette à changement sans préavis ni responsabilité». C'est peut-être ainsi qu'Apple intègre des formats de modèles propriétaires dans mlmodel?
Publication des mises à jour du modèle sur CloudKit

Ce nouveau composant Core ML vous permet de mettre à jour les modèles séparément de l'application.
Au lieu de mettre à jour l'ensemble de l'application, vous pouvez simplement charger les instances déployées avec la nouvelle version du mlmodel. Pour être honnête, cette idée n'est pas nouvelle et certains fournisseurs tiers ont déjà développé des SDK correspondants. En outre, il n'est pas difficile de créer vous-même un tel package. L'avantage de la solution d'Apple dans ce cas est la possibilité d'héberger des modèles dans le Cloud Apple .
Puisqu'une application peut avoir plusieurs modèles, le nouveau concept d'une collection de modèles vous permet de combiner des modèles dans un seul package afin que l'application puisse tous les mettre à jour en même temps. Ces collections peuvent être créées à l'aide du tableau de bord CloudKit.
L'application utilise la classe pour télécharger et gérer les mises à jour du modèle
MLModelCollection. La vidéo WWDC montre les extraits de code pour accomplir cette tâche.
Pour préparer un modèle Core ML pour le déploiement, le bouton Créer une archive de modèle est désormais disponible dans Xcode. Cliquer dessus écrit dans le fichier .mlarchive . Cette version du modèle peut être envoyée au tableau de bord CloudKit, puis ajoutée à la collection de modèles (mlarchive ressemble à une archive ZIP normale avec le contenu du dossier mlmodelc ajouté).
Il est très pratique que vous puissiez déployer différentes collections de modèles pour différents utilisateurs. Par exemple, la caméra iPhone est différente de la caméra iPad, vous devrez peut-être créer deux versions du modèle et en envoyer une aux utilisateurs d'iPhone et l'autre aux utilisateurs d'iPad.
Vous pouvez définir des règles de personnalisation pour différentes classes d'appareils (iPhone, iPad, TV, Watch), différents systèmes d'exploitation et leurs versions, codes de région, codes de langue et versions d'application.
Il ne semble pas y avoir de mécanisme pour diviser les utilisateurs en groupes en fonction d'autres critères, par exemple pour les tests A / B des mises à jour de modèles ou le réglage pour des types d'appareils spécifiques - iPhone X ou version antérieure. Cependant, cela peut toujours être fait manuellement en créant des collections avec des noms différents, puis en demandant explicitement à
MLModelCollectionfournir la collection appropriée par le nom spécifié au moment de l'exécution.
Le déploiement d'une nouvelle version d'un modèle n'est pas toujours rapide . À un moment donné, l'application détecte un nouveau modèle disponible et le télécharge automatiquement et le place dans l'environnement de test de l'application. Cependant, vous n'avez pas la possibilité de déterminer où et comment cela se produit: Core ML peut télécharger en arrière-plan, par exemple, lorsque vous n'utilisez pas votre téléphone.
Pour cette raison, il est recommandé dans tous les cas d'ajouter un modèle intégré à l'application comme solution de secours - par exemple, un modèle générique prenant en charge à la fois l'iPhone et l'iPad.
Bien que cette solution pratique permette aux utilisateurs de ne pas s'inquiéter des modèles d'auto-hébergement, gardez à l'esprit que votre application utilise désormais CloudKit. Si je comprends bien, les collections de modèles sont comptabilisées dans le quota de stockage total et les charges de modèle sont comptabilisées dans les quotas de trafic réseau.
Voir également:
- Déploiement de modèles et sécurisation de Core ML (vidéo WWDC)
- Créer et déployer une collection de modèles
- Récupération de collections de modèles étendues
Remarque . La nouvelle capacité de mise à jour utilisant CloudKit est malheureusement assez difficile à combiner avec la personnalisation du modèle local. Il n'y a pas de moyen facile de transférer les connaissances acquises par un modèle personnalisé vers un nouveau modèle ou de les combiner d'une manière ou d'une autre.
Crypter le modèle
Jusqu'à présent, n'importe quel attaquant pouvait facilement voler votre modèle Core ML et l'intégrer dans sa propre application. À partir d'iOS 14 / macOS 11.0, Core ML prend en charge le chiffrement et le déchiffrement automatiques des modèles, limitant l'accès des attaquants à vos dossiers mlmodelc. Le chiffrement peut être utilisé conjointement avec le nouveau déploiement via CloudKit ou séparément.

Xcode crypte les modèles compilés ( mlmodelc ), pas le mlmodel d'origine. Le modèle est toujours chiffré sur l'appareil de l'utilisateur. Et ce n'est que lorsque l'application crée une instance du modèle que Core ML la déchiffre automatiquement. La version déchiffrée du modèle n'existe qu'en mémoire et n'est pas stockée sous forme de fichier.
Tout d'abord, vous avez maintenant besoin d'une clé de cryptage. La bonne nouvelle est que vous n'avez pas à gérer vous-même cette clé! Le bouton Créer une clé de chiffrement est maintenant disponible dans la visionneuse de modèle Core ML Xcode(Créer une clé de cryptage). Lorsque vous cliquez sur ce bouton, Xcode génère une nouvelle clé de chiffrement et l'associe à votre compte d'équipe de développement Apple. Vous n'avez pas à gérer les demandes de signature de certificat et les clés d'accès physiques.
Cette procédure crée un nouveau fichier .mlmodelkey . La clé est stockée sur les serveurs Apple, mais vous obtenez également une copie locale pour crypter les modèles dans Xcode. Vous n'avez pas besoin d'intégrer cette clé de cryptage dans l'application, d'autant plus que vous ne devriez pas!
Pour chiffrer un modèle Core ML, vous pouvez ajouter un indicateur de compilateur
--encrypt YourModel.mlmodelkeypour ce modèle. Et si vous prévoyez de déployer le modèle à l'aide de CloudKit, vous devrez spécifier la clé de chiffrement lors de la création de l'archive de modèle.
Pour déchiffrer le modèle une fois que l'application l'a instancié, Core ML devra récupérer la clé de chiffrement des serveurs d'Apple sur le réseau . Ceci, bien sûr, nécessite une connexion réseau. Core ML exécute cette procédure uniquement la première fois que vous utilisez le modèle.
S'il n'y a pas de connexion réseau et que la clé de chiffrement n'a pas encore été chargée, l'application ne pourra pas instancier le modèle Core ML. Pour cette raison, il est recommandé d'utiliser la nouvelle fonction
YourModel.load(). Il contient un gestionnaire final qui vous permet de répondre aux erreurs de téléchargement. Par exemple, le code d'erreur modelKeyFetchindique que Core ML n'a pas pu télécharger la clé de chiffrement à partir des serveurs Apple.
C'est une fonctionnalité très utile si vous craignez que quelqu'un vole votre technologie brevetée. De plus, il est facile à intégrer dans votre application.
Voir également:
- Déploiement de modèles et sécurisation de Core ML (vidéo WWDC)
- Générer une clé de chiffrement modèle
- Crypter le modèle dans l'application
Remarque . Selon les informations fournies dans cet article du forum des développeurs , les modèles chiffrés ne prennent pas en charge la personnalisation locale. Semble raisonnable.
CoreML.framework
L'API iOS pour travailler avec les modèles Core ML n'a pas beaucoup changé. Et pourtant, je voudrais souligner quelques points intéressants.
La seule nouvelle classe ici est
MLModelCollectioncelle qui est destinée à être déployée avec CloudKit.
Comme vous le savez déjà, lorsque vous ajoutez un fichier mlmodel à votre projet, Xcode génère automatiquement un fichier source Swift ou Objective-C qui contient des classes pour faciliter l'utilisation du modèle. Vous pouvez remarquer quelques changements dans ces classes générées:
-
init(). ,let model = YourModel().YourModel(configuration:)YourModel.load(), (, ). - ,
CVPixelBufferYourModelInput,CGImageURL-, PNG- JPG-, . ,cropAndScalecropRect. , , .
Il y a un nouvel avertissement dans la documentation MLModel :
Utilisez une instance MLModel dans un seul thread ou une seule file d'attente d'envoi. Pour ce faire, vous pouvez sérialiser les appels de méthode vers le modèle ou créer une instance distincte du modèle pour chaque thread et file d'attente de distribution.
Oh je suis désolé. Il m'a semblé qu'à l'intérieur du MLModel une file d'attente séquentielle était utilisée pour traiter les demandes, mais je pouvais me tromper - ou quelque chose a changé. Dans tous les cas, il est préférable de s'en tenir à cette recommandation à l'avenir.
Le
MLMultiArraynouvel initialiseur implémentéinit(concatenating:axis:dataType:), qui crée un nouveau multi-baies en combinant plusieurs multi-baies existantes. Ils doivent tous avoir la même forme à l'exception de l'axe spécifié le long duquel l'union est effectuée. Il semble que cette fonctionnalité a été ajoutée spécifiquement pour effectuer des prédictions à partir de données vidéo, comme dans les nouveaux modèles de classificateur d'action de Create ML. Idéalement!
Remarque . L'énumération
MLMultiArrayDataTypecontient désormais des propriétés statiques .floatet .float64. Je ne sais pas exactement à quoi ils servent, car cette énumération a déjà des propriétés .float32et .double. Bug bêta?
Visionneuse de modèle Xcode
Xcode affiche désormais beaucoup plus d'informations sur les modèles, telles que les étiquettes de classe et toutes les métadonnées personnalisées ajoutées. Il affiche également des statistiques sur les types de couches dans le modèle.
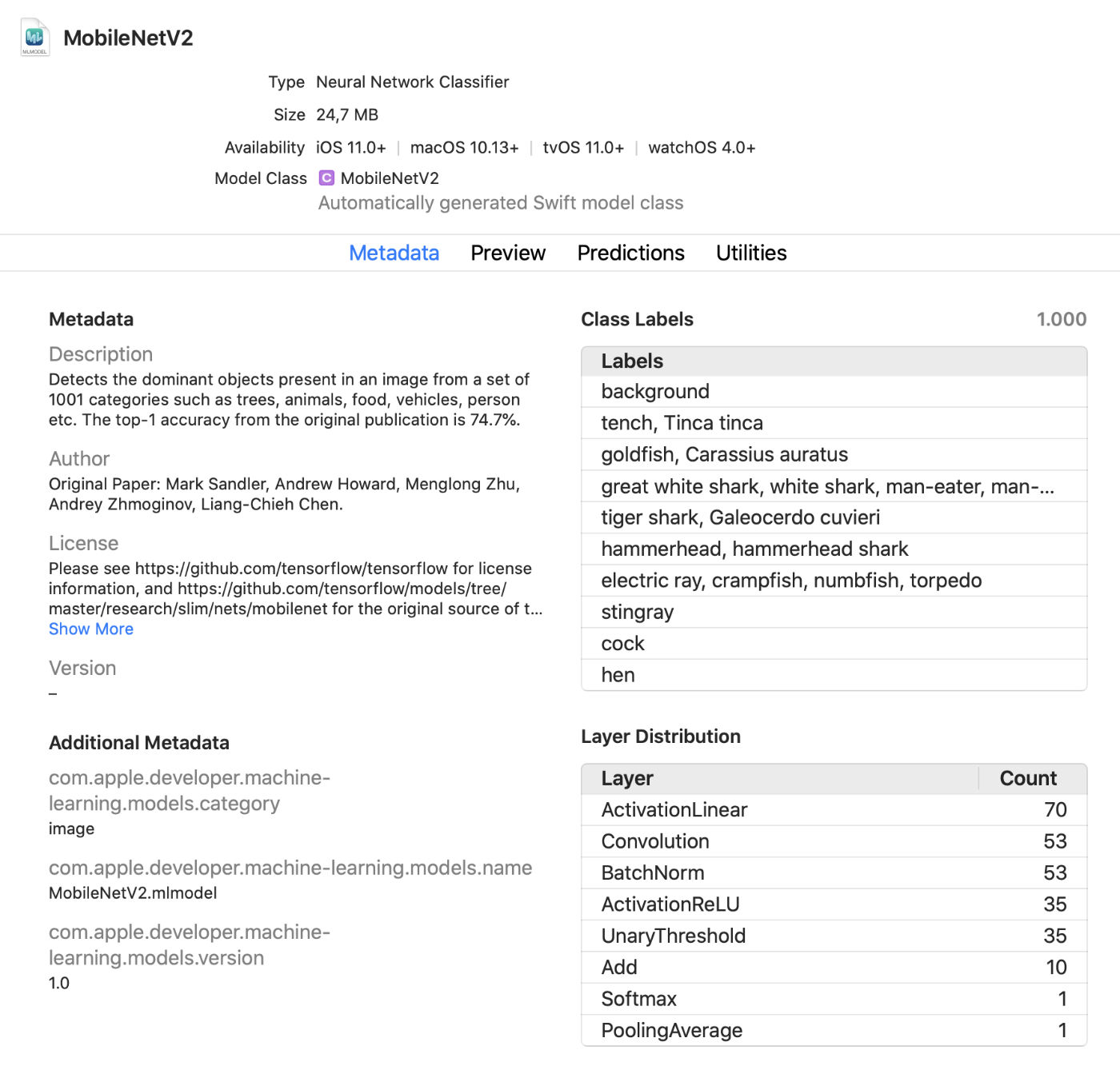
Il s'agit d'un visualiseur en direct pratique qui vous permet d'apporter des modifications au modèle en mode test sans exécuter l'application. Vous pouvez faire glisser des images, des vidéos ou du texte dans cette fenêtre d'aperçu et afficher immédiatement les prédictions du modèle. Super mise à jour!
De plus, vous pouvez désormais utiliser les modèles Core ML dans un environnement interactif . Xcode génère automatiquement une classe pour cela, que vous pouvez utiliser normalement. Il s'agit d'une autre façon de tester de manière interactive les modèles avant de les ajouter à l'application.
coremltools 4
Bien que créer vos propres modèles pour des projets simples soit pratique avec Create ML, TensorFlow et PyTorch sont plus couramment utilisés pour la formation. Pour utiliser un tel modèle dans Core ML, vous devez d'abord le convertir au format mlmodel. C'est à cela que sert la boîte à outils coremltools.
Bonne nouvelle: la documentation est bien meilleure . Je vous recommande de vous familiariser avec cela. Espérons que le manuel d'utilisation sera mis à jour régulièrement car la documentation n'était pas toujours à jour dans le passé.
Remarque . Malheureusement, les exemples de blocs-notes Jupyter ont disparu. Ils sont désormais inclus dans le manuel de l'utilisateur, mais pas en tant que notebooks.
La façon de transformer les modèles a radicalement changé... Les convertisseurs de réseau neuronal précédemment utilisés sont obsolètes et ont été remplacés par des versions plus récentes et plus flexibles.
Il existe aujourd'hui trois types de convertisseurs:
- Convertisseurs modernes pour TensorFlow (à la fois 1.x et 2.x), tf.keras et PyTorch. Tous ces convertisseurs sont basés sur les mêmes technologies et utilisent le langage de modèle dit intermédiaire (MIL). Vous n'avez plus besoin d'utiliser tfcoreml ou onnx-coreml pour de tels modèles.
- Anciens convertisseurs pour les réseaux de neurones Keras 1.x, Caffe et ONNX. Un convertisseur spécialisé est fourni pour chacun d'eux. Leur développement ultérieur a été interrompu et seuls des correctifs sont prévus pour l'avenir. Il n'est plus recommandé d'utiliser ONNX pour convertir les modèles PyTorch.
- Convertisseurs pour les modèles de réseaux non neuronaux tels que scikit-learn et XGBoost.
Une nouvelle API de conversion uniforme est utilisée pour transformer les modèles TensorFlow 1.x, 2.x, PyTorch ou tf.keras . Il est appliqué comme suit:
import coremltools as ct
class_labels = [ "cat", "dog" ]
image_input = ct.ImageType(shape=(1, 224, 224, 3),
bias=[-1, -1, -1],
scale=2/255.)
model = ct.convert(
keras_model,
inputs=[ image_input ],
classifier_config=ct.ClassifierConfig(class_labels)
)
model.save("YourModel.mlmodel")
La fonction
ct.convert()vérifie le fichier modèle pour déterminer son format, puis sélectionne automatiquement le convertisseur approprié. Les arguments sont légèrement différents de ceux utilisés auparavant: les arguments de prétraitement sont passés à l'aide d'un objet ImageType, les étiquettes de classifieur sont passées à l'aide d'un objet , ClassifierConfigetc.
La nouvelle API de transformation convertit le modèle en une représentation intermédiaire - la soi-disant. MIL . Il existe actuellement des convertisseurs disponibles pour convertir TensorFlow 1.x en MIL, TensorFlow 2.x en MIL (y compris tf.keras) et PyTorch en MIL. Si la nouvelle plate-forme d'apprentissage en profondeur gagne en popularité, elle recevra son propre convertisseur MIL.

Après avoir converti le modèle au format MIL, il peut être optimisé selon des règles générales, par exemple, supprimer les opérations inutiles ou combiner plusieurs couches différentes. Le modèle est ensuite converti du format MIL au format mlmodel.
Je n'ai pas encore étudié tout cela en détail, mais la nouvelle approche me donne l'espoir que coremtools 4 sera capable de créer des fichiers mlmodel plus efficaces qu'auparavant - en particulier pour les graphiques TF 2.x.
Dans le MIL, j'aime particulièrement la capacité du convertisseur à gérer des couches qu'il n'a pas encore analysées . Si votre modèle contient une couche qui n'est pas directement prise en charge dans Core ML, vous devrez peut-être la subdiviser en opérations MIL plus simples telles que la multiplication de matrice ou d'autres opérations arithmétiques.
Après cela, le convertisseur pourra utiliser les «opérations composées» pour toutes les couches de ce type. C'est beaucoup plus facile que d'ajouter des opérations non prises en charge à l'aide de couches personnalisées, bien que cela soit possible. La documentation fournit un bon exemple d' utilisation de telles opérations composées.
Voir également:
- Obtenir des modèles sur l'appareil à l'aide de convertisseurs Core ML (vidéo WWDC)
- Documentation Coremltools
Autres plates-formes Apple utilisant l'apprentissage automatique
Plusieurs autres frameworks de haut niveau dans les SDK iOS et macOS sont également utilisés pour les tâches d'apprentissage automatique. Voyons ce qu'il y a de nouveau dans ce domaine.
Vision
La plate-forme de vision par ordinateur Vision a reçu un certain nombre de nouvelles fonctions.
La plateforme Vision a déjà utilisé des modèles pour reconnaître les visages, les traits distinctifs et les corps humains. La nouvelle version ajoute les fonctionnalités suivantes:
Reconnaissance de la position de la main (
VNDetectHumanHandPoseRequest)
Reconnaissance de la pose de plusieurs personnes (
VNDetectHumanBodyPoseRequest)
C'est formidable qu'Apple ait inclus des fonctions de reconnaissance de la pose dans le système d'exploitation. Plusieurs modèles open source prennent en charge cette fonctionnalité, mais ils sont loin d'être aussi efficaces ou rapides. Les solutions commerciales coûtent cher. Des outils de reconnaissance de pose de haute qualité sont désormais disponibles gratuitement!
Désormais, contrairement à la visualisation d'images statiques, une plus grande attention est accordéereconnaissance d'objets sur enregistrement vidéo à la fois hors ligne et en temps réel. Pour plus de commodité, vous pouvez utiliser des objets
CMSampleBufferdirectement depuis la caméra à l'aide de gestionnaires de requêtes.
En outre,
VNImageBasedRequestune sous-classe a été ajoutée à la classe VNStatefulRequest, qui est responsable de la confirmation rapide de la découverte de l'objet souhaité. Contrairement à la classe standard, VNImageBasedRequestelle réutilise une requête avec état qui s'étend sur plusieurs cadres. Cette demande effectue une analyse toutes les N images de la vidéo.
Une fois l'objet de recherche trouvé, le gestionnaire final est appelé, contenant l'objet
VNObservation, qui a maintenant une propriété timeRangequi indique l'heure de début et de fin de l'observation dans la vidéo.
La classe n'est
VNStatefulRequestpas utilisée directement . Il s'agit d'une classe de base abstraite et n'est actuellement sous-classée que par requête VNDetectTrajectoriesRequestà des fins de reconnaissance de chemin. Cela permet de reconnaître les formes se déplaçant le long d'une trajectoire parabolique, comme lors du lancer ou du coup de pied dans une balle (cela semble être la seule tâche liée à la vidéo intégrée pour le moment).
Pour l'analyse vidéo hors ligne, vous pouvez utiliser
VNVideoProcessor.Cet objet ajoute une URL à une vidéo locale et effectue une ou plusieurs requêtes Vision toutes les N images ou N secondes.
L'une des techniques de vision par ordinateur traditionnelles les plus importantes pour l'analyse des enregistrements vidéo est le flux optique... Une requête est désormais disponible dans Vision
VNGenerateOpticalFlowRequestqui calcule la direction dans laquelle chaque pixel se déplace d'une image à une autre (flux optique dense). En conséquence, un objet est créé VNPixelBufferObservationcontenant une nouvelle image dans laquelle chaque pixel correspond à deux valeurs à virgule flottante 32 bits ou 16 bits.
De plus, une nouvelle requête a été ajoutée
VNDetectContoursRequestpour reconnaître les contours des objets dans une image. Ces chemins sont renvoyés sous forme de chemins vectoriels. VNGeometryUtilsfournit des outils auxiliaires pour un traitement ultérieur des contours reconnus, par exemple, en les simplifiant en formes géométriques de base.
Et la dernière innovation de Vision est une nouvelle version de l'extracteur de fonctionnalités intégré VisionFeaturePrint. IOS a déjà implémenté le blocVisionFeaturePrint.Scene , qui est particulièrement pratique pour créer des classificateurs d'images. De plus, un nouveau modèle VisionFeaturePrint.Object est désormais disponible, optimisé pour mettre en évidence les fonctionnalités utilisées dans la reconnaissance d'objets.
Ce modèle prend en charge les images d'entrée 299x299 et renvoie deux multi-matrices de la forme (288, 35, 35) et (768, 17, 17), respectivement. Ce n'est pas encore un cadre limitatif clair, mais uniquement des fonctionnalités «brutes». Pour une reconnaissance d'objets à part entière, vous devez ajouter une logique qui convertit ces fonctionnalités en cadres de délimitation et en étiquettes de classe. Create ML exécute cette tâche si vous entraînez un outil de reconnaissance d'objets à l'aide du transfert d'apprentissage.
Voir également:
- Explorez les API de vision par ordinateur (vidéo WWDC)
- Détecter la pose du corps et de la main avec vision (vidéo WWDC)
- Explorez l'application Action & Vision (vidéo WWDC)
Traitement du langage naturel
Pour les tâches de traitement du langage naturel, vous pouvez utiliser la plateforme Natural Language. Elle utilise activement les modèles formés à Create ML.
Très peu de nouvelles fonctionnalités ont été ajoutées cette année:
NLTaggeretNLModelmaintenant trouver plusieurs balises et prédire leur validité. Auparavant, la validité d'un tag n'était déterminée que par le nombre de points marqués.- Insérer des phrases. L'insertion de mots aurait pu être utilisée auparavant, mais
NLEmbeddingprend désormais en charge des phrases entières.
Lors de l'insertion de phrases, un réseau neuronal intégré est utilisé pour coder la phrase entière dans un vecteur de 512 dimensions. Cela vous permet d'obtenir le contexte dans lequel les mots sont utilisés dans une phrase (l'insertion de mots ne prend pas en charge cette fonctionnalité).
Voir également:
Analyse de la parole et des sons
Il n'y a eu aucun changement dans ce domaine.
Formation modèle
Les modèles de train utilisant les API Apple sont devenus disponibles pour la première fois dans iOS 11.3 et sur la plate-forme Metal Performance Shaders. Au cours des dernières années, de nombreuses nouvelles API pour la formation ont été ajoutées, et cette année n'a pas fait exception: selon mes calculs, nous avons maintenant jusqu'à 7 API différentes pour la formation des réseaux de neurones sur les plates-formes iOS et macOS!
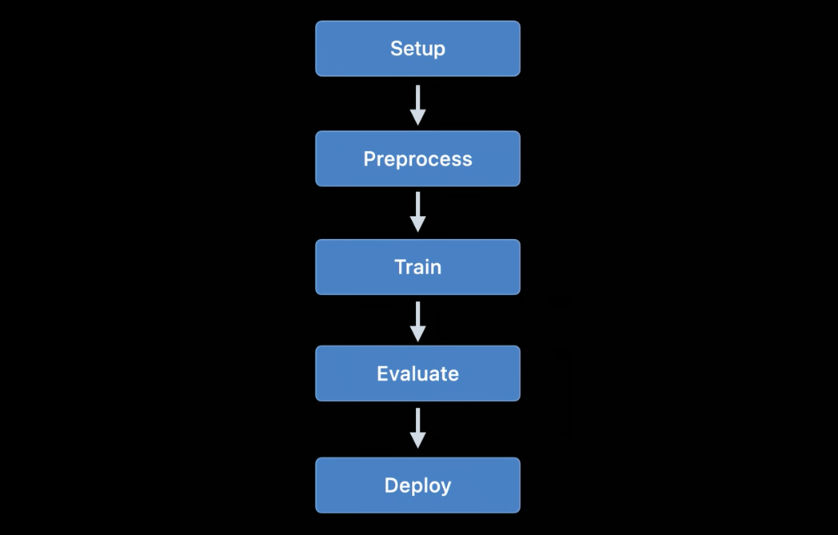
Actuellement, les API Apple suivantes peuvent être utilisées pour former des modèles d'apprentissage automatique - en particulier les réseaux de neurones - sur iOS et macOS:
- Apprentissage local dans Core ML.
- Créer ML : cette interface vous est peut-être connue en tant qu'application, mais c'est aussi une plate-forme disponible sur macOS.
- Metal Performance Shaders : API pour l'inférence et la formation sur un GPU. En fait, ce sont deux API différentes, assez difficiles à utiliser si vous êtes nouveau sur Metal. En outre, un nouveau framework Metal Performance Shaders Graph est également disponible et semble remplacer ces API héritées.
- BNNS : partie de la plateforme Accelerate. Auparavant, seules les routines d'inférence étaient disponibles dans BNNS, mais un soutien à la formation a également été ajouté cette année.
- ML Compute : Une plate-forme fondamentalement nouvelle qui semble très prometteuse.
- Turi Create : Il s'agit en fait de la version Python de Create ML. Récemment, ses créateurs l'ont oublié, bien que le support de la plate-forme n'ait pas encore été interrompu.
Examinons de plus près les innovations de ces API.
Apprentissage local dans Core ML
En fait, il n'y a pas de changements majeurs ici. La prise en charge des mises à jour aurait pu être ajoutée pour plusieurs autres types de couches, mais je n'ai pas encore vu de documentation à ce sujet.
L'une des innovations importantes attendues dans une future version bêta est l'optimiseur RMSprop. Il n'est pas inclus dans la version bêta actuelle.
Créer ML
La plate-forme Create ML n'était initialement disponible que pour macOS. Il peut être exécuté dans Swift Playground afin de pouvoir être utilisé pour entraîner des modèles avec seulement quelques lignes de code.

L'année dernière, Create ML a été transformé en une application assez limitée, et je suis heureux de voir des améliorations significatives cette année. Cela étant dit, Create ML reste une plateforme qui peut toujours être utilisée à partir du code-behind. En fait, l'application n'est qu'une interface graphique pratique pour travailler avec la plate-forme.
Dans la version précédente de Create ML, vous ne pouviez entraîner un modèle qu'une seule fois. Pour changer quelque chose, vous deviez le réentraîner à partir de zéro, et cela a pris beaucoup de temps.
La nouvelle version de Xcode 12 permetinterrompre l'entraînement et reprendre plus tard , enregistrer les points de contrôle du modèle (instantanés) et afficher des aperçus des résultats de l'entraînement du modèle. Nous avons désormais beaucoup plus d'outils à notre disposition pour gérer le processus d'apprentissage. Avec cette mise à jour, Create ML est vraiment utile!
De nouvelles API sont également disponibles sur la plate-forme CreateML.framework pour la configuration des sessions de formation, la gestion des points d'arrêt de modèle, etc. Je suppose que la plupart des gens utiliseront simplement l'application Create ML, mais il est toujours agréable de voir que cette fonctionnalité est désormais disponible sur la plate-forme.
Nouvelles fonctionnalités de Create ML (à la fois sur la plateforme et dans l'application):
- Transfert d'un style pour les images et les vidéos
- Classification des actions humaines dans les enregistrements vidéo
Examinons de plus près le nouveau modèle de classification des actions. Il utilise le modèle de reconnaissance de posture disponible sur la plateforme Vision. Le classificateur d'action est un réseau de neurones qui prend la forme (
window_size, 3, 18) en entrée , avec la première valeur représentant la durée du fragment vidéo, indiquée en nombre d'images (généralement des fragments d'environ 2 secondes sont utilisés), et (3, 18) représentent les points clés de la pose.
Au lieu de répéter des couches, le réseau neuronal utilise des convolutions unidimensionnelles. Il s'agit probablement d'une variante d'un réseau convolutionnel de graphes spatio-temporels (STGCN) - un type de modèle spécialement conçu pour la prévision de séries chronologiques. Ces détails ne devraient pas vous inquiéter lors de l'utilisation de tels modèles dans une application. Cependant, je veux toujours savoir comment tout cela fonctionne.
En ce qui concerne les modèles de reconnaissance d'objets, vous pouvez choisir d'entraîner l'ensemble du réseau sur la base de TinyYOLOv2, ou d'utiliser le nouveau mode de transfert d'apprentissage, qui utilise la nouvelle unité d'extraction de fonctionnalités VisionFeaturePrint.Object . Le reste du modèle ressemble toujours à YOLO et SSD, mais grâce au port, son entraînement sera beaucoup plus rapide que l'entraînement de l'ensemble du modèle basé sur YOLO.
Voir également:
- Construire un classificateur d'action avec Create ML (vidéo WWDC)
- Créer des modèles de transfert de style d'image et de vidéo dans Create ML (vidéo WWDC)
- Control training in Create ML with Swift ( Create ML Swift) ( WWDC)
Metal Performance Shaders
Metal Performance Shaders (MPS) est une plate-forme basée sur les cœurs de calcul de performance de Metal, qui est principalement utilisé pour le traitement d'image, mais depuis 2016, elle offre également un support pour les réseaux de neurones. J'ai déjà beaucoup blogué à ce sujet.
Aujourd'hui, la plupart des utilisateurs choisiront Core ML plutôt que MPS. Bien sûr, Core ML utilise toujours la puissance de MPS lors de l'exécution de modèles sur le GPU. Cependant, MPS peut également être utilisé directement, surtout si l'utilisateur prévoit de mener une formation seul (au fait, une nouvelle plate-forme ML Compute est maintenant disponible, qu'il est recommandé d'utiliser à la place de MPS. Sa description est donnée ci-dessous).
Il y a peu de nouvelles fonctionnalités dans MPSCNN cette année, mais plusieurs améliorations ont été apportées aux fonctionnalités existantes.
Ajout de nouvelles classes
MPSImageCannypour la reconnaissance des bords et MPSImageEDLines pour la reconnaissance des segments de ligne. Ils sont très utiles lorsque vous travaillez sur des problèmes de vision par ordinateur.
Un certain nombre d'autres changements méritent également d'être notés:
- Une
MPSCNNConvolutionDataSourcenouvelle propriété a été ajoutéekernelWeightsDataTypequi vous permet d'utiliser un type de données différent pour les coefficients de pondération de celui utilisé pour la convolution. Il est intéressant de noter que les pondérations ne peuvent pas être du type de données INT8, même si Core ML permet à ce type de données d'être utilisé pour des couches individuelles. - En cas de
kernelWeightsDataTyperetour.float32, les couches convolutives et entièrement connectées sont exécutées en virgule flottante 32 bits au lieu de 16 bits. Auparavant, seul le 16 bits était pris en charge. - Les fonctions de perte peuvent désormais utiliser un paramètre
reduceAcrossBatch.
Vous pouvez toujours utiliser MPSCNN si Metal ne vous fait pas peur. Cependant, une nouvelle plateforme est maintenant disponible qui simplifie grandement la création et l'exécution de tels graphiques: MPS Graph.
Remarque . La vidéo de la WWDC indique que MPSNDArray est une nouvelle API, mais en fait, elle est sortie l'année dernière. Il s'agit d'une structure de données beaucoup plus flexible que MPSImage car tous les tenseurs de votre modèle ne peuvent pas être des images.
Nouveau: Graphique des shaders de performances métalliques

Une API est disponible dans MPS depuis longtemps
MPSNNGraph, mais ces graphiques, en fait, ne décrivent que des réseaux de neurones. Cependant, tous les graphiques ne doivent pas nécessairement être des réseaux de neurones, et dans ce cas, la plate-forme Metal Performance Shaders Graph sera utile.
Cette nouvelle plate-forme peut être utilisée pour créer des graphiques de calcul GPU à usage général. La plate-forme MPS Graph ne dépend pas de Metal Performance Shaders, bien qu'elle ait été construite sur sa base.
Dans la version précédente de l'API obsolète
MPSNNGraph, il était impossible d'ajouter des opérations personnalisées au graphique. La nouvelle plateforme est beaucoup plus flexible à cet égard. Cependant, vous ne pouvez pas ajouter vos propres noyaux métalliques. Vous devrez exprimer tous les calculs en utilisant les primitives existantes.
Heureusement le compilateur
MPSGraphprend en charge l'intégration de ces primitives dans un seul noyau de calcul, ce qui garantit le travail le plus efficace sur le processeur graphique. Cependant, ce schéma ne fonctionnera pas s'il est impossible ou difficile d'utiliser les primitives fournies pour certaines opérations. Je ne comprends tout simplement pas pourquoi Apple, lors de la création d'une nouvelle API comme celle-ci, ne prévoit jamais la possibilité de créer des fonctions personnalisées à part entière! Mais rien ne peut être fait.
La nouvelle plate
MPSGraph- forme est une structure assez simple et logique qui décrit la relation entre les opérations dans un ensemble à l' MPSGraphOperationsaide de tenseursMPSGraphTensorscontenant les résultats des opérations. De plus, vous pouvez définir des dépendances de contrôle pour forcer les nœuds individuels à démarrer avant les autres. Après avoir configuré le graphe, il doit être exécuté ou transféré vers le tampon de commande, puis attendre le résultat.
MPSGraphfournit un ensemble complet de méthodes d'instance qui vous permettent d'ajouter des opérations mathématiques ou de réseau neuronal au graphique.
De plus, la formation est prise en charge, ce qui implique l'ajout d'une opération de traitement des pertes au graphique, puis l'exécution d'opérations de gradient pour toutes les couches dans l'ordre inverse - comme dans l'ancienne
MPSNNGraph. Pour plus de commodité, un mode de différenciation automatique est également disponible, dans lequel il MPSGrapheffectue automatiquement des opérations de gradient pour le graphique. Cela économise beaucoup d'efforts.
J'adore le fait qu'il existe maintenant une nouvelle API simple et directe pour créer de tels graphiques informatiques. Il est beaucoup plus facile à utiliser que les versions précédentes. Et vous n'avez pas besoin d'être un expert en métal pour travailler avec. À propos, il est à bien des égards similaire aux graphiques TensorFlow 1.x, mais en même temps, il présente un gros avantage en termes d'optimisation, ce qui vous permet de minimiser les coûts. Et pourtant, il n'y a pas assez de capacité pour ajouter des cœurs de calcul arbitraires au graphe.
Voir également:
- Créez des modèles ML personnalisés avec le graphique Metal Performance Shaders (vidéo WWDC)
- Ajout de fonctions personnalisées au Shader Graph
BNNS (sous-routines de réseau neuronal de base)
Si Core ML s'exécute sur un processeur, il utilise des routines BNSS qui font partie de la plate-forme Accelerate. J'ai déjà écrit sur BNNS dans cet article . La plupart de ces fonctionnalités BNNS sont désormais en grande partie abandonnées et remplacées par un nouvel ensemble de fonctionnalités.
Auparavant, seules les fonctions de couches, de pliage, de regroupement et d'activation entièrement connectées étaient prises en charge. Cette mise à jour ajoute la prise en charge de BNNS pour les tableaux à n dimensions, presque tous les types de couches Core ML et les versions de compatibilité descendante de ces couches d'entraînement (y compris les couches qui ne prennent actuellement pas en charge la formation Core ML, comme LSTM).
Il convient également de noter la présence d'une couche d' attention multiple.... Ces couches sont souvent utilisées dans les modèles Transformer tels que BERT. Un autre point intéressant concerne les convolutions tensorielles.
Vous n'utilisez peut-être pas ces fonctionnalités BNNS vous-même - tout comme vous n'utiliseriez pas MPS pour la formation GPU. Au lieu de cela, une plate-forme ML Compute de niveau supérieur est désormais disponible qui résume le processeur utilisé. ML Compute est basé sur BNNS et MPS, mais les développeurs n'ont pas à se soucier de si petites choses.
Voir aussi: documentation de la plateforme BNNS
Nouveau: ML Compute
ML Compute est une plate-forme fondamentalement nouvelle pour la formation de réseaux de neurones sur un CPU ou un GPU (mais, apparemment, pas sur des processeurs Neural Engine). Sur un Mac Pro avec plusieurs GPU, cette plateforme peut tous les utiliser automatiquement pour s'entraîner.
J'ai été légèrement surpris par la présence d'une autre plate-forme d'apprentissage, mais cette plate-forme simplifie vraiment tout, car elle vous permet de cacher des composants de bas niveau du BNNS et du MPS, et à l'avenir, peut-être du Neural Engine.
Mieux encore, ML Compute est également pris en charge par les systèmes iOS, pas seulement Mac. C'est drôle que Core ML ne soit mentionné nulle part. ML Compute semblait avoir été créé complètement séparément. Ce framework ne peut pas être utilisé pour créer des modèles Core ML.
D'après ma propre expérience, je peux dire que la tâche de ML Compute est, avant tout, d' accélérer le travail des outils tiers d'apprentissage en profondeur . Vous n'avez pas besoin d'écrire de code pour travailler directement avec ML Compute. On dirait qu'il est supposé (ou les développeurs l'espèrent) que des outils comme TensorFlow commenceront à utiliser cette plate-forme pour prendre en charge l'apprentissage accéléré par le matériel sur Mac.
À peu près le même ensemble de couches disponibles que dans BNNS. Les couches doivent être ajoutées au graphe, puis exécutées (ici, le mode «attente occupée» n'est pas utilisé).
Pour créer un graphique, vous devez d'abord instancier l'objet
MLCGraphet y ajouter des nœuds. Un nœud est une sous-classe MLCLayer. Les nœuds sont connectés les uns aux autres via des objetsMLCTensorqui contiennent la sortie d'autres couches.
Fait intéressant, les opérations de division, de concaténation, de reformatage et de transfert ne sont pas des types de couches séparés, mais des opérations directement sur le graphe.
Grande fonctionnalité de débogage -
summarizedDOTDescription. Il renvoie une description DOT pour un graphique, à partir de laquelle vous pouvez ensuite créer un graphique en utilisant, par exemple, Graphviz ou OmniGraffle (d'ailleurs, Keras génère des graphiques de modèle de cette façon).
ML Compute fait la distinction entre les graphiques d'inférence et les graphiques d'apprentissage. Ce dernier contient des nœuds supplémentaires, par exemple, une couche de perte et un optimiseur.
Il semble qu'il n'y ait aucun moyen de créer des couches personnalisées ici, vous n'avez donc qu'à vous débrouiller avec les types disponibles dans ML Compute.
Il est étrange qu'il n'y ait pas eu de sessions WWDC sur cette nouvelle plate-forme, et la documentation est également assez dispersée. Quoi qu'il en soit, je vais continuer à suivre son développement, car il semble que ce soit exactement l' API qui convient le mieux aux modèles de formation sur les appareils Apple.
Voir aussi: Documentation de la plateforme ML Compute
Conclusion
Le Core ML a ajouté un certain nombre de nouvelles fonctionnalités utiles, telles que la mise à jour automatique des modèles et le chiffrement. Les nouveaux types de couches ne sont vraiment pas vraiment nécessaires, car les couches ajoutées l'année dernière peuvent résoudre presque tous les problèmes. Dans l'ensemble, j'aime cette mise à jour.
Dans coremltools 4 a ajouté des améliorations importantes - la nouvelle architecture de convertisseur et la prise en charge intégrée de TensorFlow 2 et PyTorch. Je suis content que nous n'ayons plus à utiliser ONNX pour transformer les modèles PyTorch.
Dans Visiona ajouté de nombreuses nouvelles fonctionnalités pratiques. Et j'adore qu'Apple ait ajouté une fonctionnalité d'analyse vidéo. Bien que les systèmes d'apprentissage automatique puissent être appliqués à des images individuelles de la vidéo, dans ce cas, le temps n'est pas pris en compte. Étant donné que les appareils mobiles sont suffisamment rapides aujourd'hui pour effectuer un apprentissage automatique basé sur des données vidéo en temps réel, je pense que la vidéo jouera un rôle plus important dans le développement des technologies de vision par ordinateur dans un proche avenir.
Concernant la formation... je ne sais pas si nous avons besoin de sept API différentes pour cette tâche. Je suppose qu'Apple ne voulait tout simplement pas retirer les interfaces obsolètes tant que les nouvelles n'étaient pas entièrement raffinées. On sait peu de choses sur la plate-forme ML Compute. Cependant, au moment d'écrire ces lignes, seule la première version bêta a été publiée. Qui sait ce qui nous attend ...
L'image de la conférence utilise l'icône Freepik de flaticon.com.