Si vous concevez des applications ou des bases de données backend depuis un certain temps, vous avez probablement écrit du code pour exécuter des requêtes paginées. Par exemple - comme ceci:
SELECT * FROM table_name LIMIT 10 OFFSET 40
C'est comme ça?
Mais si c'est ainsi que vous avez fait la pagination, j'ai le regret de dire que vous ne l'avez pas fait de la manière la plus efficace.
Voulez-vous discuter avec moi? Vous n'avez pas à perdre de temps . Slack , Shopify et Mixmax utilisent déjà les astuces dont je veux parler aujourd'hui.
Nommez au moins un backend développeur, qui n'a jamais été utilisé
OFFSETet LIMITpour effectuer des requêtes avec pagination. Dans MVP (Minimum Viable Product, minimum viable product) et dans les projets qui utilisent de petites quantités de données, cette approche est tout à fait applicable. Cela fonctionne, pour ainsi dire.
Mais si vous avez besoin de créer des systèmes fiables et efficaces à partir de zéro, vous devez vous assurer à l'avance de l'efficacité des requêtes sur les bases de données utilisées dans ces systèmes.
Aujourd'hui, nous allons parler des problèmes associés aux implémentations largement utilisées (désolé) de moteurs d'exécution de requêtes paginées, et comment obtenir des performances élevées lors de l'exécution de telles requêtes.
Quel est le problème avec OFFSET et LIMIT?
Comme il a été dit,
OFFSETet se LIMITmontre parfaitement dans des projets qui n'ont pas besoin de travailler avec de grandes quantités de données.
Le problème survient lorsque la base de données atteint une taille telle qu'elle cesse de tenir dans la mémoire du serveur. Cependant, lorsque vous travaillez avec cette base de données, vous devez utiliser des requêtes paginées.
Pour que ce problème se manifeste, il est nécessaire qu'une situation se produise dans laquelle le SGBD recourt à une opération d'analyse complète de la table inefficace lors de l'exécution de chaque requête avec pagination (en même temps, des opérations d'insertion et de suppression de données peuvent se produire , et nous n'avons pas besoin de données obsolètes!).
Qu'est-ce qu'un "balayage complet de la table" (ou "balayage séquentiel de la table", balayage séquentiel)? Il s'agit d'une opération au cours de laquelle le SGBD lit séquentiellement chaque ligne de la table, c'est-à-dire les données qu'elle contient, et les vérifie par rapport à une condition donnée. Ce type d'analyse de table est connu pour être le plus lent. Le fait est que lors de son exécution, de nombreuses opérations d'E / S sont effectuées en utilisant le sous-système de disque du serveur. La situation est aggravée par les retards associés au travail avec des données stockées sur des disques et par le fait que le transfert de données du disque vers la mémoire est une opération gourmande en ressources.
Par exemple, vous avez des enregistrements de 100 000 000 d'utilisateurs et vous exécutez une requête avec la construction
OFFSET 50000000... Cela signifie que le SGBD devra charger tous ces enregistrements (et nous n'en avons même pas besoin!), Les placer en mémoire, et seulement après cela, prenez, disons, 20 résultats rapportés LIMIT.
Supposons que cela ressemble à "sélectionnez les lignes 50 000 à 500 20 sur 100 000". Autrement dit, le système devra d'abord charger 50 000 lignes pour exécuter la requête. Vous voyez combien de travail inutile elle doit faire?
Si vous ne me croyez pas, jetez un œil à l'exemple que j'ai créé en utilisant db-fiddle.com .

Exemple sur db-fiddle.com
Là, à gauche, dans la boîte
Schema SQL, il y a du code pour insérer 100 000 lignes dans la base de données, et à droite, dans la boîteQuery SQL, deux requêtes sont affichées. Le premier, lent, ressemble à ceci:
SELECT *
FROM `docs`
LIMIT 10 OFFSET 85000;
Et le second, qui est une solution efficace au même problème, comme ceci:
SELECT *
FROM `docs`
WHERE id > 85000
LIMIT 10;
Afin de répondre à ces demandes, il vous suffit de cliquer sur le bouton
Runen haut de la page. Cela fait, comparons les informations sur le temps d'exécution de la requête. Il s'avère que l'exécution d'une requête inefficace prend au moins 30 fois plus de temps que l'exécution de la seconde (cette durée diffère d'un lancement à l'autre, par exemple, le système peut signaler que la première requête a pris 37 ms pour se terminer, et exécution de la seconde - 1 ms).
Et s'il y a plus de données, alors tout sera encore pire (pour en être convaincu - jetez un œil à mon exemple avec 10 millions de lignes).
Ce que nous venons de discuter devrait vous donner un aperçu de la manière dont les requêtes de base de données sont réellement traitées.
Gardez à l'esprit que plus la valeur est élevée
OFFSET - plus la demande prendra de temps.
Que faut-il utiliser à la place d'une combinaison de OFFSET et LIMIT?
Au lieu d'une combinaison
OFFSET, LIMITil vaut la peine d'utiliser une structure construite selon le schéma suivant:
SELECT * FROM table_name WHERE id > 10 LIMIT 20
Il s'agit de l'exécution d'une requête de pagination basée sur le curseur.
Au lieu du courant stocké localement
OFFSETet LIMITet les envoyer à chaque demande, il est nécessaire de stocker la dernière clé primaire reçue ( en général - a ID) et LIMIT, en conséquence et sera invité ressemblant au - dessus-indiqué.
Pourquoi? Le fait est qu'en spécifiant explicitement l'identifiant de la dernière ligne lue, vous indiquez à votre SGBD où il doit commencer à rechercher les données dont il a besoin. De plus, la recherche, grâce à l'utilisation de la clé, sera effectuée de manière efficace, le système n'aura pas à être distrait par des lignes qui sont en dehors de la plage spécifiée.
Jetons un coup d'œil à la comparaison de performances suivante de différentes requêtes. Voici une requête inefficace.
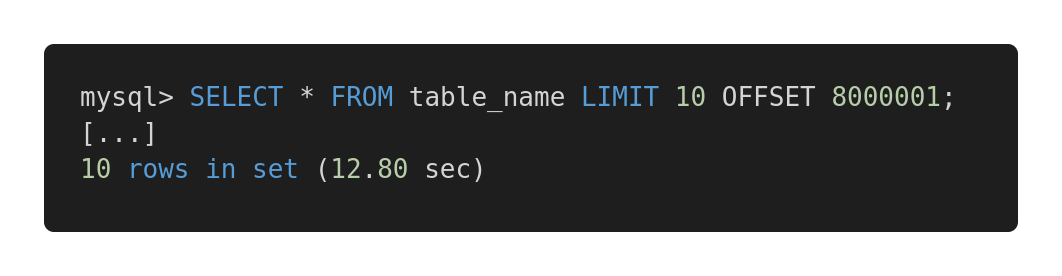
Requête lente
Et voici une version optimisée de cette requête.

Requête rapide
Les deux requêtes renvoient exactement la même quantité de données. Mais le premier prend 12,80 secondes et le second, 0,01 seconde. Sentez-vous la différence?
Problèmes possibles
Pour que la méthode d'exécution de requête proposée fonctionne efficacement, la table doit avoir une colonne (ou des colonnes) contenant des index séquentiels uniques, tels qu'un identifiant entier. Dans certains cas spécifiques, cela peut déterminer le succès de l'utilisation de telles requêtes afin d'augmenter la vitesse de travail avec la base de données.
Naturellement, lors de la conception de requêtes, vous devez prendre en compte les particularités de l'architecture des tables, et choisir les mécanismes qui se montreront le mieux sur les tables existantes. Par exemple, si vous devez travailler dans des requêtes avec de grandes quantités de données associées, vous pourriez trouver cet article intéressant .
Si nous sommes confrontés au problème de l'absence de clé primaire, par exemple, s'il existe une table avec une relation plusieurs-à-plusieurs, alors l'approche traditionnelle consistant à utiliser
OFFSETet LIMITest garantie de fonctionner pour nous. Mais son application peut conduire à l'exécution de requêtes potentiellement lentes. Dans de tels cas, je recommanderais d'utiliser une clé primaire à auto-incrémentation, même si vous n'en avez besoin que pour organiser les requêtes paginées.
Si vous êtes intéressé par ce sujet - ici , ici et ici - quelques matériaux utiles.
Résultat
La principale conclusion que nous pouvons tirer est que toujours, quelle que soit la taille des bases de données dont nous parlons, nous devons analyser la vitesse d'exécution des requêtes. À notre époque, l'évolutivité des solutions est extrêmement importante, et si vous concevez tout correctement dès le début du travail sur un certain système, cela, à l'avenir, peut éviter au développeur de nombreux problèmes.
Comment analysez-vous et optimisez-vous les requêtes de base de données?
