
Aujourd'hui, je vais vous parler un peu de mes réflexions sur le basculement tarantool / cartouche. Tout d'abord, quelques mots sur ce qu'est la cartouche: c'est un morceau de code lua qui fonctionne à l'intérieur de tarantool et combine des tarentules les unes avec les autres dans un "cluster" conditionnel. Cela est dû à deux choses:
- chaque tarentule connaît les adresses réseau de toutes les autres tarentules;
- les tarentules se "ping" régulièrement via UDP pour comprendre qui est vivant et qui ne l'est pas. Ici, je simplifie un peu délibérément, l'algorithme de ping est plus compliqué que la simple requête-réponse, mais ce n'est pas très important pour l'analyse. Si vous êtes intéressé - recherchez l'algorithme SWIM sur Google.
Au sein d'un cluster, tout est généralement divisé en tarentules avec état (maître / réplique) et sans état (routeur). Les tarentules sans état sont responsables du stockage des données et les tarentules sans état sont responsables du routage des demandes.
Voici à quoi cela ressemble dans l'image:
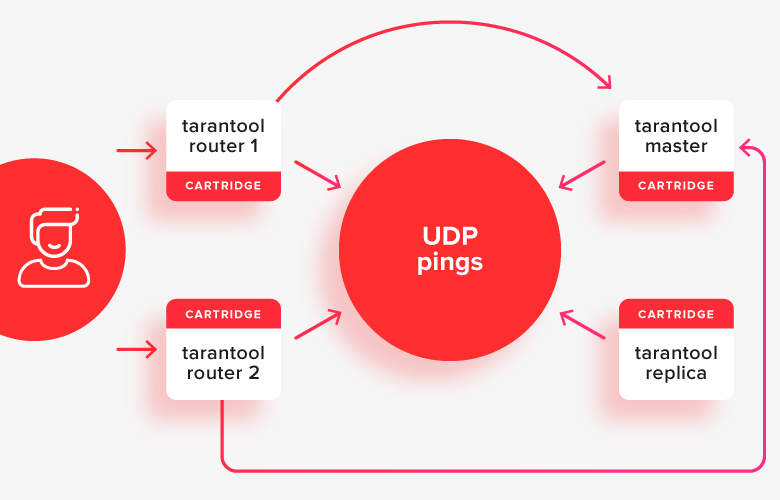
le client fait des demandes à l'un des routeurs actifs, et ils redirigent les demandes vers l'un des magasins, qui est maintenant le maître actif. Dans l'image, ces chemins sont indiqués avec des flèches.
Maintenant, je ne veux pas compliquer et introduire du sharding dans la conversation sur le choix d'un leader, mais la situation avec lui sera un peu différente. La seule différence est que le routeur doit toujours prendre une décision sur le jeu de réplicas à partir du magasin.
Tout d'abord, parlons de la façon dont les nœuds apprennent les adresses des autres. Pour ce faire, chacun d'eux dispose d'un fichier yaml sur le disque avec la topologie du cluster, c'est-à-dire avec des informations sur les adresses réseau de tous les membres et qui d'entre eux est qui (avec ou sans état). Plus une personnalisation potentiellement supplémentaire, mais pour l'instant, laissons cela de côté. Les fichiers de configuration contiennent les paramètres de l'ensemble du cluster et sont les mêmes pour chaque tarentule. Si des modifications leur sont apportées, elles sont effectuées de manière synchrone pour toutes les tarentules.
Désormais, les modifications de configuration peuvent être apportées via l'API de l'une des tarentules du cluster: il se connectera à tout le monde, leur enverra une nouvelle version de la configuration, tout le monde l'appliquera, et partout il y aura une nouvelle version, la même chose.
Scénario - panne de nœud, basculement
Dans une situation où un routeur tombe en panne, tout est plus ou moins simple: le client a juste besoin de se rendre sur n'importe quel autre routeur actif, et il livrera la requête au magasin souhaité. Mais que se passerait-il si, par exemple, le maître de l'un des Storaja tombait?
Pour le moment, nous avons implémenté un algorithme "naïf" pour un tel cas, qui repose sur le ping UDP. Si la réplique ne «voit» pas les réponses du maître au ping pendant une courte période, elle considère que le maître est tombé et devient le maître lui-même, passant en mode lecture-écriture à partir de la lecture seule. Les routeurs agissent de la même manière: s'ils ne voient pas de temps de réponse ping du maître, ils basculent le trafic vers le réplica.
Cela fonctionne relativement bien dans des cas simples, à l'exception d'une situation de cerveau partagé, lorsque la moitié des nœuds sont séparés les uns des autres par une sorte de problème de réseau:
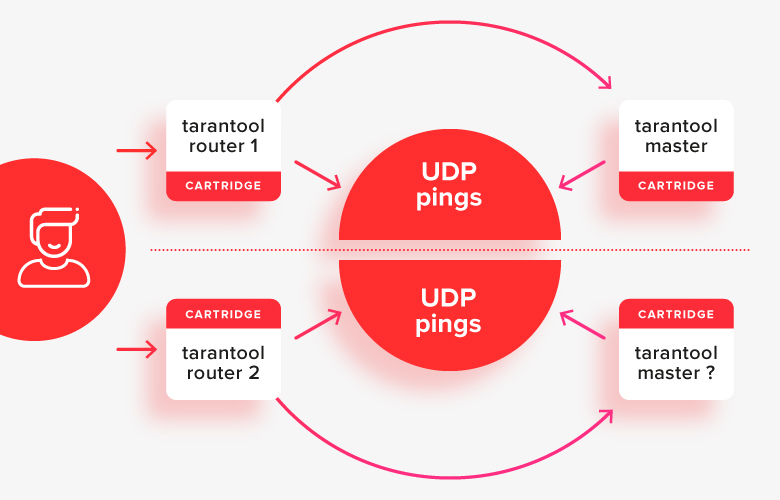
Dans cette situation, les routeurs verront que «l'autre moitié» du cluster n'est pas disponible, et considéreront leur moitié comme la principale, et il s'avère qu'il y a deux maîtres dans le système en même temps. C'est le premier cas important à résoudre.
Script - Modifier la configuration en cas d'échec
Un autre scénario important consiste à remplacer une tarentule défaillante dans un cluster par une nouvelle, ou à ajouter des nœuds au cluster lorsque l'un des réplicas ou routeurs n'est pas disponible.
Pendant le fonctionnement normal, lorsque tout dans le cluster est disponible, nous pouvons nous connecter via l'API à n'importe quel nœud, lui demander de modifier la configuration et, comme je l'ai dit ci-dessus, le nœud "déploiera" la nouvelle configuration sur l'ensemble du cluster.
Mais lorsqu'une personne n'est pas disponible, vous ne pouvez pas appliquer la nouvelle configuration, car lorsque ces nœuds redeviennent disponibles, il sera difficile de savoir lequel d'entre eux dans le cluster a la configuration correcte et lequel ne l'est pas. Cependant, l'inaccessibilité des nœuds les uns aux autres peut signifier qu'il existe un cerveau divisé entre eux. Et la modification de la configuration est tout simplement dangereuse, car vous pouvez par erreur la modifier de différentes manières dans différentes moitiés.
Pour ces raisons, nous interdisons désormais de modifier la configuration via l'API lorsqu'une personne n'est pas disponible. Il ne peut être corrigé que sur disque, via des fichiers texte (manuellement). Ici, vous devez bien comprendre ce que vous faites et être très prudent: l'automatisation ne vous aidera en rien.
Cela rend le fonctionnement peu pratique, et c'est le deuxième cas à résoudre.
Scénario - basculement stable
Un autre problème avec le modèle de basculement naïf est que le passage du maître à la réplique en cas de défaillance du maître n'est enregistré nulle part. Tous les nœuds prennent la décision de basculer d'eux-mêmes, et lorsque le maître prendra vie, le trafic y basculera à nouveau.
Cela peut ou non être un problème. Avant d'allumer le maître, le maître «rattrapera» les journaux transactionnels de la réplique, de sorte qu'il n'y aura probablement pas de décalage de Big Data. Le problème ne sera que dans le cas où il y a des problèmes de réseau, et il y a une perte de paquets: alors très probablement il y aura un "clignotement" périodique du maître (battement).
La solution est un coordinateur "fort" (etcd / consul / tarantool)
Afin d'éviter des problèmes avec un cerveau divisé, et pour permettre d'éditer la configuration lorsque le cluster est partiellement indisponible, nous avons besoin d'un coordinateur fort qui résiste à la segmentation du réseau. Le coordinateur doit être réparti sur 3 centres de données afin qu'en cas de défaillance de l'un d'entre eux, il reste opérationnel.
Il y a maintenant 2 coordinateurs RAFT populaires qui utilisent etcd et consul pour cela. Lorsque la réplication synchrone apparaît dans tarantool, elle peut également être utilisée pour cela.
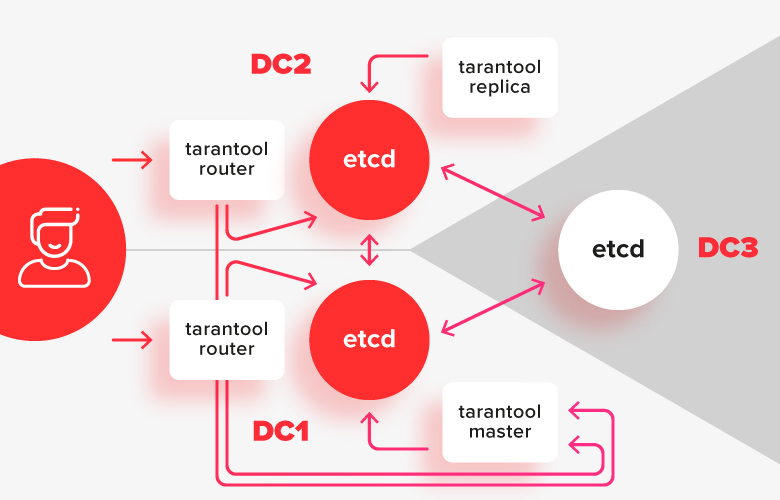
Dans ce schéma, les installations de la tarentule sont divisées en deux centres de données et sont connectées à leur installation etcd locale. Une instance d'etcd dans le troisième centre de données sert d'arbitre de sorte qu'en cas de panne d'un des centres de données, c'est précisément celui d'entre eux qui est resté majoritaire.
Gestion de la configuration avec un coordinateur fort
Comme je l'ai dit plus haut, en l'absence de coordinateur et en cas de défaillance de l'une des tarentules, nous ne pouvions pas éditer la configuration de manière centralisée, car alors il est impossible de dire quelle configuration sur lequel des nœuds est correcte.
Dans le cas d'un coordinateur fort, tout est plus simple: on peut stocker la configuration sur le coordinateur, et chaque instance de la tarentule contiendra un cache de cette configuration sur son système de fichiers. Une fois la connexion réussie au coordinateur, il mettra à jour sa copie de la configuration vers celle du coordinateur.
La modification de la configuration devient également plus facile: cela peut être fait via l'API de n'importe quelle tarentule. Il prendra le verrou dans le coordinateur, remplacera les valeurs souhaitées dans la configuration, attendra que tous les nœuds l'appliquent et relâchera le verrou. Eh bien, ou en dernier recours, vous pouvez modifier la configuration manuellement dans etcd, et elle s'appliquera à l'ensemble du cluster.
Il sera possible d'éditer la configuration même si certaines tarentules ne sont pas disponibles. L'essentiel est que la plupart des nœuds de coordination soient disponibles.
Basculement avec un coordinateur fort
La commutation fiable des nœuds avec un coordinateur est résolue car, en plus de la configuration, nous stockerons dans le coordinateur des informations sur qui est le maître actuel dans la réplique et où les commutateurs ont été effectués.
L'algorithme de basculement change comme suit:
- «» .
- UDP-, - , .
- , .
- .
- , read-only read-write.
- , , .
La protection contre les battements est également possible avec un coordinateur. Dans le coordinateur, vous pouvez enregistrer l'historique complet de la commutation, et si au cours des X dernières minutes le maître est passé à une réplique, la commutation inverse n'est effectuée que explicitement par l'administrateur.
Un autre point important est la soi-disant «clôture». Les tarentules qui sont coupées des autres centres de données (ou connectées à un coordinateur qui a perdu leur majorité) devraient supposer que le reste du cluster, auquel l'accès est perdu, est majoritaire. Et cela signifie que, dans un certain temps, tous les nœuds coupés de la majorité doivent passer en lecture seule.
Problème d'indisponibilité du coordinateur
Pendant que nous discutions des approches de travail avec le coordinateur, nous avons reçu une demande pour nous assurer que si le coordinateur tombe, mais que toutes les tarentules sont intactes, ne traduisez pas l'ensemble du cluster en lecture seule.
Au début, il semblait que ce n'était pas très réaliste de le faire, mais nous nous sommes ensuite souvenus que le cluster lui-même surveille la disponibilité des autres nœuds via des pings UDP. Cela signifie que nous pouvons les cibler et ne pas déclencher la réélection du maître à l'intérieur du jeu de réplicas, s'il est clair par les pings UDP que le jeu de réplicas entier est actif.
Cette approche vous aidera à moins vous soucier de la disponibilité du coordinateur, surtout si vous devez le redémarrer par exemple pour une mise à jour.
Plans de mise en œuvre
Nous recueillons maintenant des commentaires et commençons la mise en œuvre. Si vous avez quelque chose à dire - écrivez dans les commentaires ou dans un message personnel.
Le plan est quelque chose comme ceci:
- Rendre le support etcd dans tarantool [fait]
- Basculement en utilisant etcd comme coordinateur, avec état [terminé]
- Basculement en utilisant la tarentule comme coordinateur, verrouillage [terminé]
- Stockage de la configuration dans etcd [en cours]
- Écriture des outils CLI pour la réparation du cluster [en cours]
- Stocker la configuration dans la tarentule
- Gestion du cluster lorsqu'une partie du cluster n'est pas disponible
- Escrime
- Protection contre les battements
- Basculement en utilisant consul comme coordinateur
- Stockage de la configuration dans consul
À l'avenir, nous abandonnerons presque certainement le cluster sans un coordinateur fort. Cela coïncidera très probablement avec la mise en œuvre basée sur le RAFT de la réplication synchrone dans la tarentule.
Remerciements
Merci aux développeurs et aux administrateurs de Mail.ru pour les commentaires, les critiques et les tests fournis.