
L'une des tâches d'un examen phonoscopique est d'établir l'authenticité et l'authenticité d'un enregistrement audio - en d'autres termes, d'identifier les signes de montage, de distorsion et d'altération de l'enregistrement. Nous avions la tâche de le conduire afin d'établir l'authenticité des documents - pour déterminer qu'il n'y avait aucune influence sur les documents. Mais comment analyser des milliers, voire des centaines de milliers d'enregistrements audio?
Les méthodes IA viennent à notre secours, ainsi qu'un utilitaire pour travailler avec l'audio, dont nous avons parlé dans un article sur le site Web de NewTechAudit "TRAITEMENT DE L'AUDIO AVEC FFMPEG" .
Comment apparaissent les modifications audio? Comment pouvez-vous distinguer un fichier modifié d'un fichier intact?
Il existe plusieurs de ces signes, et le plus simple est d'identifier les informations sur l'édition d'un fichier et d'analyser la date de sa modification. Ces méthodes sont facilement implémentées au moyen du système d'exploitation lui-même, nous ne nous attarderons donc pas sur ces méthodes. Mais les modifications peuvent être apportées par un utilisateur plus qualifié qui peut masquer ou modifier les informations d'édition, auquel cas des méthodes plus complexes sont utilisées, par exemple:
- décalage des contours;
- changer le profil spectral de l'audio enregistré;
- l'apparition de pauses;
- et plein d'autres.
Et toutes ces méthodes de sondage complexes sont effectuées par des experts spécialement formés - des phonoscopistes utilisant des logiciels spécialisés tels que Praat, Speech Analyzer SIL, ELAN, dont la plupart sont payés et nécessitent des qualifications suffisamment élevées pour utiliser et interpréter les résultats.
Les experts analysent l'audio à l'aide d'un profil spectral, notamment en analysant ses coefficients cepstraux. Nous utiliserons l'expérience d'experts et en même temps utiliserons le code prêt à l'emploi, en l'adaptant à notre tâche.
Il y a donc beaucoup de changements qui peuvent être apportés, comment choisir?
Parmi les types de modifications possibles qui peuvent être apportées aux fichiers audio, nous souhaitons découper une partie de l'audio, ou découper une partie, puis remplacer la partie d'origine par une partie de la même durée - les soi-disant changements de coupe / copie. l'édition de fichiers en termes de réduction du bruit, la modification de la fréquence de tonalité et autres ne présentent pas le risque de cacher des informations.
Et comment identifierons-nous ces mêmes coupes / copies? Devraient-ils être comparés à quelque chose?
C'est très simple - avec l'aide de l'utilitaire FFmpeg, nous allons découper une partie d'une durée aléatoire du fichier et dans un endroit aléatoire, après quoi nous comparerons les spectrogrammes petits-cepstral de l'original et du fichier "coupé".
Code pour les afficher:
import numpy as np
import librosa
import librosa.display
import matplotlib.pyplot as plt
def make_spek(audio):
n_fft = 2048
y, sr = librosa.load(audio)
ft = np.abs(librosa.stft(y[:n_fft], hop_length = n_fft+1))
spec = np.abs(librosa.stft(y, hop_length=512))
spec = librosa.amplitude_to_db(spec, ref=np.max)
mel_spect = librosa.feature.melspectrogram(y=y, sr=sr, n_fft=2048, hop_length=1024)
mel_spect = librosa.power_to_db(mel_spect, ref=np.max)
librosa.display.specshow(mel_spect, y_axis='mel', fmax=8000, x_axis='time');
plt.title('Mel Spectrogram');
plt.colorbar(format='%+2.0f dB');
plt.show();
make_spek('./audio/original.wav')# './audio/original.wav' Nous préparons un ensemble de données à partir de la source et coupons les fichiers à l'aide de la commande de l'utilitaire FFmpeg:
ffmpeg -i oroginal.wav -ss STARTTIME -to ENDTIME -acodec copy cut.wav où STARTTIME et ENDTIME sont le début et la fin du fragment coupé. Et en utilisant la commande:
ffmpeg -iconcat:"part_0.wav|part_1.wav |part_2.wav" -codeccopyconcat.wavjoindre la partie du fichier pour insérer part_1.wav avec les parties d'origine (pour encapsuler les commandes FFmpeg en python, voir notre article sur FFmpeg).
Voici les fichiers originaux dont le spectrogramme à la craie a été découpé dans l'audio de 0,2 à 2,5 secondes, et le spectrogramme à la craie des fichiers qui ont été découpés dans l'audio de 0,2 à 2,5 secondes, puis insérés dans les fragments audio d'une durée similaire de ce fichier audio:
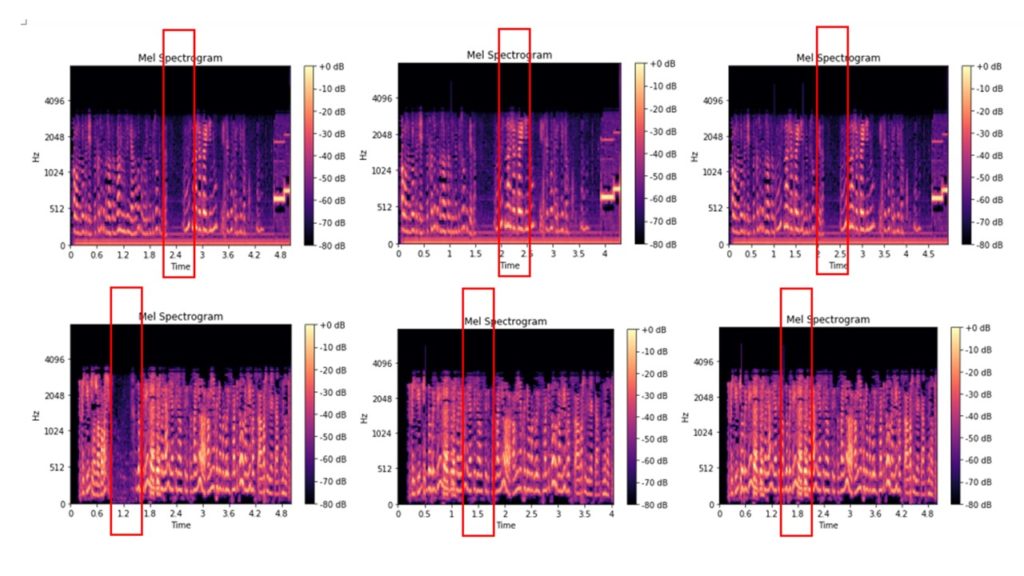
Certains les images se distinguent même visuellement, d'autres se ressemblent presque. Nous distribuons les images résultantes dans des dossiers et les utilisons comme données d'entrée pour entraîner le modèle pour la classification des images. Structure des dossiers:
model.py #
/input/train/original/ #
/input/train/cut_copy/ # Pour nous, cela ne fait aucune différence que le fichier audio modifié ait été ajouté ou raccourci - nous divisons tous les résultats en bons, c'est-à-dire en fichiers sans modifications et en mauvais. Ainsi, nous résolvons le problème classique de la classification binaire. Nous classerons à l'aide de réseaux de neurones, nous prendrons le code pour travailler avec un réseau de neurones prêt à l'emploi à partir d'exemples de travail avec le package Keras.
#
from keras.models import Sequential
from keras.layers import Flatten
from keras.layers import Dense
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
#
classifier = Sequential()
classifier.add(Conv2D(32, (3, 3), input_shape = (64, 64, 3), activation = 'relu'))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Conv2D(32, (3, 3), activation = 'relu'))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Flatten())
classifier.add(Dense(units = 128, activation = 'relu'))
classifier.add(Dense(units = 1, activation = 'sigmoid'))
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
#
from keras.preprocessing.image import ImageDataGenerator as img
train_datagen = img(rescale = 1./255,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True)
test_datagen = img(rescale = 1./255)
training_set = train_datagen.flow_from_directory('input/train',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
test_set = test_datagen.flow_from_directory('input/test',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
classifier.fit_generator(
training_set,
steps_per_epoch = 8000,
epochs = 25,
validation_data = test_set,
validation_steps = 2000)De plus, une fois le modèle formé, nous effectuons la classification avec son aide
import numpy as np
from keras.preprocessing import image
test_image = image.load_img('dataset/prediction/original_or_corrupt.jpg', target_size = (64, 64))
test_image = image.img_to_array(test_image)
test_image = np.expand_dims(test_image, axis = 0)
result = classifier.predict(test_image)
training_set.class_indices
ifresult[0][0] == 1:
prediction = 'original'
else:
prediction = 'corrupt'À la sortie, nous obtenons la classification du fichier audio - 'original' / 'corrompu', c'est-à-dire le fichier inchangé et les fichiers sur lesquels les modifications ont été apportées.
Nous avons prouvé une fois de plus que des choses d'apparence complexe peuvent être faites simplement - nous n'avons pas utilisé le mécanisme le plus difficile des méthodes d'IA, des solutions toutes faites et avons vérifié l'audio pour les changements. Eh bien, nous étions les experts du détective.