
L'équipe de Mail.ru Cloud Solutions atraduit un essai abrégé de Kevin Wu , qui traite de ce que l'industrie pharmaceutique et de la santé a déjà réalisé en utilisant l'intelligence artificielle et l'apprentissage automatique, et quand les nouvelles technologies aideront à trouver des médicaments de toutes les maladies.
Pourquoi il peut sembler qu'il n'y a pas de progrès
Certaines personnes expriment leur frustration face à la vie quelque chose comme ceci: "Si c'est l'avenir, alors où est mon jetpack?" À première vue, un tel désir d'un futur rétro semble étrange à une époque d'informatique omniprésente, de cellules programmables et d'une exploration spatiale résurgente . Mais pour certains, ce futurisme nostalgique résiste étonnamment bien. Ils s'accrochent à des prédictions qui semblent étranges rétrospectivement, ignorant une réalité surprenante que personne n'aurait pu prédire.
Qui aurait pensé que grâce à l'apprentissage en profondeur, nous pourrions prédire les propriétés de médicaments qui n'existent pas encore? Ceci est d'une grande importance pour l'industrie pharmaceutique.
En ce qui concerne l'intelligence artificielle, les plaintes peuvent ressembler à ceci: «Près de huit ans se sont écoulés depuis l'invention du réseau neuronal AlexNet [ env. traducteur : en 2012, Aleksey Krizhevsky a publié le design du réseau de neurones convolutifs AlexNet, qui a remporté le concours ImageNet de loin], alors où est ma voiture autonome? " En effet, il peut sembler que les attentes du milieu des années 2010 n'ont pas été satisfaites. Chez les pessimistes, les prévisions de la prochaine stagnation de la recherche sur l'IA prennent de l'ampleur .
Le but de cet essai est de discuter des progrès significatifs réalisés par l'apprentissage automatique dans le défi de la découverte de médicaments dans le monde réel. Je veux vous rappeler un autre vieil adage, cette fois des chercheurs en IA. Pour reformuler légèrement, cela ressemble à ceci: "L'IA s'appelle AI jusqu'à ce qu'elle fonctionne, alors ce n'est qu'un logiciel."
Ce qui jusqu'à il y a quelques années était considéré comme une recherche fondamentale de pointe en apprentissage automatique est maintenant souvent appelé «juste science des données » (ou même analytique) - et révolutionne l'industrie pharmaceutique. Il y a de fortes chances que l'utilisation de l'apprentissage en profondeur pour découvrir des médicaments change radicalement nos vies pour le mieux.
Vision par ordinateur et apprentissage profond en imagerie biomédicale
Dès que les scientifiques ont eu accès aux ordinateurs et ont eu la possibilité d'y télécharger des images, ils ont immédiatement essayé de les traiter. Fondamentalement, nous parlons d'images biomédicales: radiographies, échographies et résultats d'IRM. À l'époque de la bonne vieille IA, le traitement signifiait généralement inférer manuellement des instructions logiques basées sur des attributs simples tels que les contours et la luminosité.
Les années 1980 ont vu un virage vers des algorithmes d'apprentissage automatique supervisé, mais ils s'appuyaient toujours sur des balises définies manuellement. Des modèles d'apprentissage supervisé simples (tels que la régression linéaire ou l'approximation polynomiale) sont entraînés sur des caractéristiques extraites par des algorithmes tels que SIFT (Scale Invariant Feature Transformation) et HOG (Histogram of Directed Gradients). Il n'est pas surprenant que les développements qui ont conduit à l'application pratique de l'apprentissage profond aujourd'hui aient commencé il y a des décennies.
Les réseaux de neurones convolutifs ont été utilisés pour la première fois pour l'analyse d'images biomédicales en 1995, lorsque Law et ses collèguesa présenté un modèle pour la reconnaissance des tumeurs cancéreuses dans les poumons sur des fluorogrammes. Leur méthode était un peu différente de ce à quoi nous sommes habitués aujourd'hui, la dérivation du résultat a pris environ 15 secondes, mais le concept était essentiellement le même - avec un apprentissage par rétropropagation jusqu'aux noyaux convolutifs du réseau neuronal. Leur modèle impliquait deux couches cachées, alors que les architectures de réseaux profonds populaires d'aujourd'hui ont souvent une centaine de couches ou plus.
Avance rapide jusqu'en 2012. Les réseaux de neurones convolutifs ont fait sensation avec l'arrivée du système AlexNet, qui a conduit à un bond dans les performances du désormais célèbre jeu de données ImageNet. Le succès d'AlexNet, un réseau avec cinq couches convolutives et trois couches étroitement couplées formées sur des GPU de jeu, est devenu si célèbre dans l'apprentissage automatique que les gens en parlent maintenant.Moments of ImageNet »dans différentes niches de l'apprentissage automatique et de l'IA.
Par exemple, «le traitement du langage naturel a peut-être survécu à son moment ImageNet avec le développement de gros transformateurs en 2018» ou «l'apprentissage par renforcement attend toujours son moment ImageNet».
Près de dix ans se sont écoulés depuis AlexNet. Les modèles de vision par ordinateur et d'apprentissage en profondeur s'améliorent progressivement. Les demandes sont allées au-delà de la classification. Aujourd'hui, ils ont appris à segmenter les images, à estimer la profondeur et à reconstruire automatiquement des scènes 3D à partir de plusieurs images 2D. Et ce n'est pas une liste complète de leurs capacités.
L'apprentissage en profondeur pour l'analyse d'imagerie biomédicale est devenu un domaine de recherche brûlant. Un effet secondaire est une augmentation inévitable du bruit. Publié en 2019environ 17 000 articles scientifiques sur l'apprentissage profond . Bien sûr, tous ne valent pas la peine d'être lus. Il est probable que de nombreux chercheurs surajustent trop les modèles sur leurs modestes ensembles de données.
La plupart d'entre eux n'ont apporté aucune contribution à la science fondamentale ou à l'apprentissage automatique. Une passion pour l'apprentissage profond a saisi les chercheurs universitaires qui ne s'y étaient auparavant pas intéressés, et pour de bonnes raisons. Il peut faire ce que font les algorithmes classiques de vision par ordinateur (voir le théorème d'approximation universel de Tsybenko et Hornik), et le fait souvent plus rapidement et mieux, évitant ainsi aux ingénieurs la conception manuelle fastidieuse de chaque nouvelle application.
Une rare opportunité de lutter contre les maladies «négligées»
Cela nous amène au sujet de la découverte de médicaments aujourd'hui, une industrie qui va bien bouger. Les sociétés pharmaceutiques et leurs sous-traitants aiment réitérer les coûts énormes de mise sur le marché d'un nouveau médicament. Ces coûts sont en grande partie dus au fait que de nombreux médicaments prennent beaucoup de temps à étudier et à tester avant d'être consommés.
Le coût de développement d'un nouveau médicament peut atteindre 2,5 milliards de dollars ou plus . Parfois, en raison du coût élevé et de la rentabilité relativement faible, un certain nombre de travaux sur certaines classes de médicaments sont relégués au second plan .
Elle conduit également à une poussée dans la catégorie bien nommée des «maladies négligées», y compris un nombre disproportionné de maladies tropicales.qui affectent les populations des pays les plus pauvres et sont considérées comme défavorables au traitement et les maladies rares à faible taux d'incidence. Relativement peu de personnes souffrent de chacun d'eux, mais le nombre total de personnes atteintes de toutes les maladies rares est assez élevé. On estime qu'environ 300 millions de personnes. Et même ce nombre peut être sous-estimé en raison de l'évaluation sombre des experts: environ 30% des personnes souffrant d'une maladie rare ne vivent pas jusqu'à cinq ans.
" Longue queue»Les maladies rares ont un potentiel important pour améliorer la vie d'un grand nombre de personnes, et c'est là que l'apprentissage automatique et le big data viennent à la rescousse. L'angle mort des maladies rares (orphelines) qui n'ont pas de traitement officiellement approuvé ouvre une opportunité d'innovation de la part de petites équipes de biologistes et de développeurs d'apprentissage automatique.
Une telle startup à Salt Lake City, Utah essaie de faire exactement cela. Les fondateurs de Recursion Pharmaceuticals considèrent le manque de médicaments contre les maladies rares comme une lacune dans l'industrie pharmaceutique. Ils reçoivent d'énormes quantités de données en analysant les résultats de la microscopie et des tests de laboratoire. À l'aide de réseaux de neurones, il est possible d'identifier les caractéristiques des maladies et de rechercher des méthodes de traitement.
À la fin de 2019, la société avait mené des milliers d'expériences et collecté plus de 4 pétaoctets d'informations. Ils ont publié un petit sous-ensemble de ces données (46 Go) pour le concours NeurIps 2019, vous pouvez le télécharger sur le site Web de RxRx et jouer par vous- même.
Le flux de travail décrit dans cet article est largement basé sur les informations des livres blancs de Recursion Pharmaceuticals [ pdf ], mais cette approche pourrait bien servir d'inspiration pour d'autres domaines.
Parmi les autres startups du domaine, citons Bioage Labs (maladies du vieillissement), Notable Labs (oncologie) et TwoXAR.(diverses maladies pour lesquelles il n'y a pas d'options de traitement). En règle générale, les jeunes startups sont engagées dans des techniques de traitement de données innovantes et appliquent une variété de méthodes d'apprentissage automatique en plus ou à la place de l'apprentissage en profondeur avec vision par ordinateur.
Ensuite, je décrirai le processus d'analyse d'image et comment l'apprentissage en profondeur s'intègre dans le flux de travail de découverte de médicaments contre les maladies rares. Nous examinerons un processus de haut niveau applicable à divers autres domaines de la découverte de médicaments.
Par exemple, il peut être facilement utilisé pour cribler les médicaments anticancéreux pour leur effet sur la morphologie des cellules tumorales. Peut-être même pour analyser la réponse de cellules de patients spécifiques à différentes options de médicaments. Cette approche utilise les concepts de l' analyse en composantes principales non linéaires, hachage sémantique [ pdf ] et bonne vieille classification d'image de réseau neuronal convolutif.
Classification en bruit morphologique
La biologie est un gâchis. Par conséquent, la microscopie multiparamétrique à haut débit est une source de frustration constante pour les biologistes cellulaires. Les images qui en résultent diffèrent grandement d'une expérience à l'autre. Les fluctuations de température, de temps d'exposition, de quantité de réactifs et autres conduisent à des changements qui ne sont pas liés au phénotype ou à l'action du médicament étudié, et donc à des erreurs dans les résultats obtenus.
Peut-être que la climatisation dans un laboratoire fonctionne différemment en été et en hiver? Peut-être que quelqu'un a déjeuné à côté des diapositives avant de les insérer dans le microscope? Peut-être que le fournisseur de l'un des ingrédients du milieu de culture a changé? Ou le fournisseur a-t-il changé son propre fournisseur? Un grand nombre de variables affectent le résultat d'une expérience. Le suivi et la mise en évidence du bruit non intentionnel est l'un des principaux défis de la découverte de médicaments basée sur les données.
Les images microscopiques peuvent être très différentes dans les mêmes expériences. La luminosité de l'image, la forme des cellules, la forme des organites et de nombreuses autres caractéristiques changent en raison des effets physiologiques correspondants ou d'erreurs aléatoires.
Ainsi, les images de la figure ci-dessous sont obtenues à partir du mêmeun ensemble accessible au public de micrographies de cellules cancéreuses métastatiques compilées par Scott Wilkinson et Adam Marcus. Les variations de saturation et de morphologie doivent refléter l'incertitude des données expérimentales. Ils sont créés en introduisant des distorsions dans le traitement. C'est une sorte d'analogue de l'augmentation, que les chercheurs utilisent pour régulariser les réseaux de neurones profonds dans les problèmes de classification. Par conséquent, il n'est pas surprenant que la possibilité de généraliser de grands modèles à de grands ensembles de données soit un choix logique pour rechercher des caractéristiques physiologiquement significatives dans une mer de bruit.
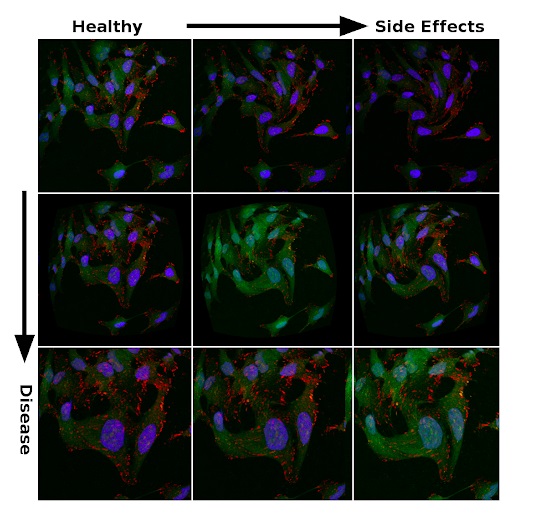
Signes d'efficacité du traitement et effets secondaires dans les données bruyantes
La principale cause des maladies rares est généralement une mutation génétique. Pour construire des modèles pour trouver un remède à ces maladies, il est nécessaire de comprendre les effets d'un large éventail de mutations et leur relation avec différents phénotypes. Pour comparer efficacement les traitements possibles pour une maladie rare spécifique, les réseaux de neurones sont formés sur la base de milliers de mutations différentes.
Ces mutations peuvent être imitées en supprimant l'expression génique à l'aide de petits ARN interférents(siRNA). C'est un peu comme si les bébés vous attrapent les chevilles: même si vous pouvez courir vite, votre vitesse diminuera considérablement avec votre nièce ou votre neveu suspendu à chaque jambe. L'ARNsi fonctionne de la même manière: une petite séquence d'ARN interférents se colle aux parties correspondantes de l'ARN messager de gènes spécifiques, empêchant leur pleine expression.
En apprenant à partir de milliers de mutations au lieu d'un modèle cellulaire singulier d'une maladie spécifique, le réseau neuronal apprend à coder des phénotypes dans un espace caché multidimensionnel. Le code qui en résulte permet d'évaluer les médicaments par leur capacité à rapprocher le phénotype de la maladie d'un phénotype sain, chacun étant représenté par un ensemble multidimensionnel de coordonnées. De même, les effets secondaires des médicaments peuvent être intégrés dans une représentation codée du phénotype, et les médicaments sont évalués non seulement pour la disparition des symptômes de la maladie, mais aussi pour minimiser les effets secondaires nocifs.

Le diagramme montre l'effet du traitement sur le modèle cellulaire de la maladie (représenté par un point rouge). Le traitement est le mouvement du phénotype codé plus proche du phénotype sain (point bleu). Il s'agit d'une représentation 3D simplifiée du codage phénotypique dans un espace caché multidimensionnel.Les
modèles d'apprentissage en profondeur utilisés pour ce flux de travail sont très similaires aux autres problèmes de classification avec un grand ensemble de données, même si vous êtes habitué à travailler avec un petit nombre de catégories, comme dans les ensembles de données CIFAR-10 et CIFAR-100, vous ne vous habituerez pas immédiatement aux milliers de marques de classification différentes.
En outre, cette méthode de découverte de médicaments basée sur l'image fonctionne bien avec la même architecture DenseNet ou ResNet avec des centaines de couches, ce qui offre des performances optimales sur des ensembles de données comme ImageNet.
Les valeurs d'activation des couches, codées dans un espace multidimensionnel, reflètent le phénotype, la pathogenèse de la maladie, la relation entre le traitement, les effets secondaires et d'autres affections. Par conséquent, tous ces facteurs peuvent être analysés par déplacement dans l'espace codé. Ce code phénotypique peut être soumis à une régularisation particulière (par exemple, en minimisant la covariance entre différentes activations de couches) pour réduire les corrélations de codage ou à d'autres fins.
La figure ci-dessous montre un modèle simplifié. Les flèches noires représentent les opérations de convolution + regroupement. Les lignes bleues représentent des connexions étroites. Par souci de simplicité, le nombre de couches a été réduit et les connexions résiduelles ne sont pas représentées.
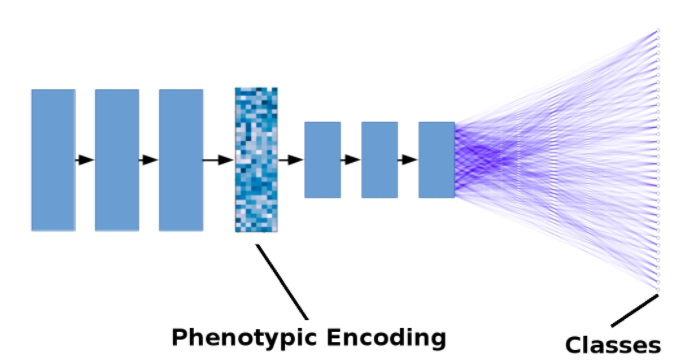
Illustration simplifiée d'un modèle d'apprentissage en profondeur pour la découverte de médicaments
L'avenir de l'apprentissage profond dans la découverte de médicaments et l'industrie pharmaceutique
Le coût élevé de la mise sur le marché de nouveaux médicaments a conduit les sociétés pharmaceutiques à opter souvent pour des succès sur le marché plutôt que de rechercher des médicaments pour des maladies graves. Les équipes d'analyse de données plus petites des startups sont mieux équipées pour innover dans ce domaine, tandis que les maladies négligées et rares offrent la possibilité d'entrer sur le marché et de démontrer la valeur de l'apprentissage automatique.
L'efficacité de cette approche a été prouvée. Nous constatons des progrès importants dans la recherche et plusieurs médicaments sont déjà dans la première phase d'essais cliniques. Par exemple, des équipes de seulement quelques centaines de scientifiques et d'ingénieurs dans des entreprises telles que Recursion Pharmaceuticals y parviennent. D'autres startups sont à proximité: TwoXAR a plusieurs candidats médicaments en cours d'essais précliniques dans d'autres catégories de maladies.
On peut s'attendre à ce que l'approche d'apprentissage en profondeur et de vision par ordinateur du développement de médicaments ait un impact significatif sur les grandes sociétés pharmaceutiques et les soins de santé en général. Nous verrons bientôt comment cela affectera le développement de nouveaux traitements pour les maladies courantes (y compris les maladies cardiaques et le diabète), ainsi que les maladies rares qui sont restées hors de vue à ce jour.
Que lire d'autre sur le sujet: