
évolutivité est une exigence clé pour les applications cloud. Avec Kubernetes, la mise à l'échelle d'une application est aussi simple que d'augmenter le nombre de réplicas pour un déploiement approprié, ou
ReplicaSet- mais c'est un processus manuel.
Kubernetes permet aux applications de se mettre à l'échelle automatiquement (c'est-à-dire des pods en déploiement ou
ReplicaSet) de manière déclarative à l'aide de la spécification de l'autoscaler de pod horizontal. Le critère par défaut pour la mise à l'échelle automatique est les métriques d'utilisation du processeur (métriques de ressources), mais des métriques personnalisées et des métriques fournies en externe peuvent être intégrées. L'
équipe AAS de Kubernetes de Mail.rutraduit un article sur Comment utiliser des métriques externes pour mettre à l'échelle automatiquement votre application Kubernetes. Pour montrer comment tout fonctionne, l'auteur utilise des métriques de demande d'accès HTTP, elles sont collectées à l'aide de Prometheus.
Au lieu d'autoscaling horizontal des pods, Kubernetes Event Driven Autoscaling (KEDA) est un opérateur Kubernetes open source. Il s'intègre de manière native à l'autoscaler de pod horizontal pour fournir un autoscaling fluide (y compris vers / à partir de zéro) pour les charges de travail basées sur les événements. Le code est disponible sur GitHub .
Présentation du fonctionnement du système
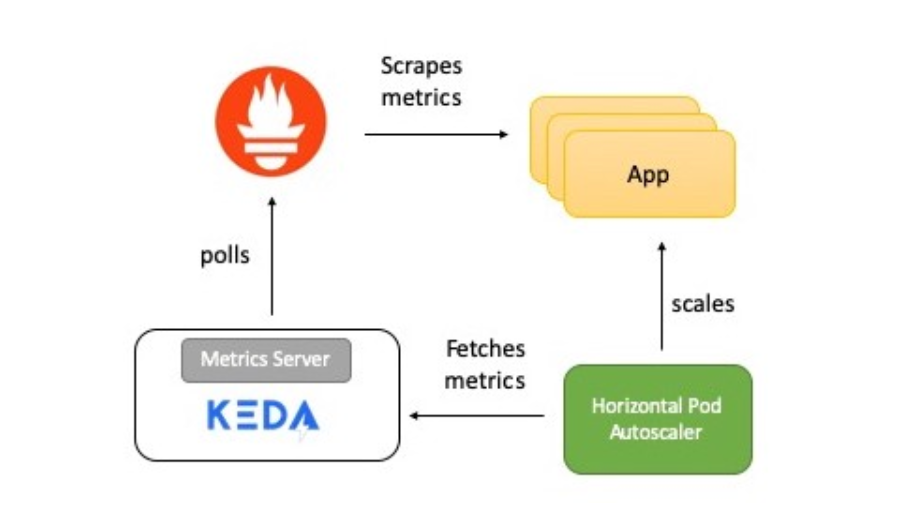
Le diagramme montre une brève description de la façon dont tout fonctionne:
- L'application fournit des métriques pour le nombre de requêtes HTTP au format Prometheus.
- Prometheus est prêt à collecter ces métriques.
- Le scaler Prometheus dans KEDA est configuré pour mettre automatiquement à l'échelle l'application en fonction du nombre de requêtes HTTP.
Maintenant, je vais vous parler en détail de chaque élément.
KEDA et Prométhée
Prometheus est une boîte à outils open source de surveillance et d'alerte du système, qui fait partie de la Cloud Native Computing Foundation . Collecte des métriques à partir de diverses sources et les enregistre en tant que données de séries chronologiques. Pour visualiser les données, vous pouvez utiliser Grafana ou d'autres outils de visualisation qui fonctionnent avec l'API Kubernetes.
KEDA prend en charge le concept de scaler - il agit comme un pont entre KEDA et le système externe. L'implémentation du scaler est spécifique à chaque système cible et en extrait les données. KEDA les utilise ensuite pour contrôler l'autoscaling.
Les scalers prennent en charge plusieurs sources de données telles que Kafka, Redis, Prometheus. Autrement dit, KEDA peut être utilisé pour mettre à l'échelle automatiquement les déploiements Kubernetes en utilisant les métriques Prometheus comme critères.
Application de test
L'application de test Golang fournit un accès HTTP et remplit deux fonctions importantes:
- Utilise la bibliothèque cliente Prometheus Go pour instrumenter l'application et fournir la métrique http_requests qui contient un compteur d'accès. Le point de terminaison pour lequel les métriques Prometheus sont disponibles est localisé par l'URI
/metrics.
var httpRequestsCounter = promauto.NewCounter(prometheus.CounterOpts{ Name: "http_requests", Help: "number of http requests", }) - L'
GETapplication incrémente la valeur key (access_count) dans Redis en réponse à la demande . C'est un moyen simple de faire le travail dans le cadre d'un gestionnaire HTTP et de vérifier également les métriques Prometheus. La valeur de la métrique doit être la même que la valeuraccess_countdans Redis.
func main() { http.Handle("/metrics", promhttp.Handler()) http.HandleFunc("/test", func(w http.ResponseWriter, r *http.Request) { defer httpRequestsCounter.Inc() count, err := client.Incr(redisCounterName).Result() if err != nil { fmt.Println("Unable to increment redis counter", err) os.Exit(1) } resp := "Accessed on " + time.Now().String() + "\nAccess count " + strconv.Itoa(int(count)) w.Write([]byte(resp)) }) http.ListenAndServe(":8080", nil) }
L'application est déployée sur Kubernetes via
Deployment. Un service est également créé ClusterIPqui permet au serveur Prometheus de recevoir des métriques d'application.
Voici le manifeste de déploiement de l'application .
Serveur Prometheus
Le manifeste de déploiement Prometheus comprend:
ConfigMap- pour transférer la configuration Prometheus;Deployment- pour le déploiement de Prometheus dans un cluster Kubernetes;ClusterIP- service d'accès à UI Prometheus;ClusterRole,ClusterRoleBindingetServiceAccount- pour la détection automatique des services dans Kubernetes (détection automatique).
Voici le manifeste pour exécuter Prometheus .
KEDA Prometheus ScaledObject
Le scaler agit comme un pont entre KEDA et le système externe à partir duquel les métriques doivent être obtenues.
ScaledObjectEst une ressource personnalisée, elle doit être déployée pour synchroniser le déploiement avec la source d'événement, dans ce cas Prometheus.
ScaledObjectcontient des informations sur la mise à l'échelle du déploiement, les métadonnées de la source d'événement (par exemple, les secrets de connexion, le nom de la file d'attente), l'intervalle d'interrogation, la période de récupération et d'autres données. Il en résulte la ressource d'autoscaling appropriée (définition HPA) pour faire évoluer le déploiement.
Lorsqu'un objet
ScaledObjectest supprimé, sa définition HPA correspondante est effacée.
Voici la définition
ScaledObjectde notre exemple, il utilise un scaler Prometheus:
apiVersion: keda.k8s.io/v1alpha1
kind: ScaledObject
metadata:
name: prometheus-scaledobject
namespace: default
labels:
deploymentName: go-prom-app
spec:
scaleTargetRef:
deploymentName: go-prom-app
pollingInterval: 15
cooldownPeriod: 30
minReplicaCount: 1
maxReplicaCount: 10
triggers:
- type: prometheus
metadata:
serverAddress:
http://prometheus-service.default.svc.cluster.local:9090
metricName: access_frequency
threshold: '3'
query: sum(rate(http_requests[2m]))
Considérez les points suivants:
- Il pointe du doigt
Deploymentavec un nomgo-prom-app. - Type de déclencheur -
Prometheus. L'adresse du serveur Prometheus est mentionnée avec le nom de la métrique, le seuil et la requête PromQL à utiliser. Demande PromQL -sum(rate(http_requests[2m])). - Selon
pollingIntervalKEDA, il demande une cible à Prometheus toutes les quinze secondes. Au moins un pod (minReplicaCount) est pris en charge et le nombre maximal de pods ne dépasse pasmaxReplicaCount(dans cet exemple, dix).
Peut être mis
minReplicaCountà zéro. Dans ce cas, KEDA active un déploiement zéro à un, puis fournit HPA pour une mise à l'échelle automatique supplémentaire. L'ordre inverse est également possible, c'est-à-dire une mise à l'échelle de un à zéro. Dans l'exemple, nous n'avons pas sélectionné zéro car il s'agit d'un service HTTP et non d'un système à la demande.
La magie de l'autoscaling
Le seuil est utilisé comme déclencheur pour mettre à l'échelle le déploiement. Dans notre exemple, la requête PromQL
sum(rate (http_requests [2m]))renvoie la valeur agrégée du taux de requêtes HTTP (requêtes par seconde), mesuré sur les deux dernières minutes.
Puisque le seuil est de trois, il y en aura un sous tant que la valeur est
sum(rate (http_requests [2m]))inférieure à trois. Si la valeur augmente, un sous supplémentaire est ajouté chaque fois qu'elle sum(rate (http_requests [2m]))augmente de trois. Par exemple, si la valeur est comprise entre 12 et 14, le nombre de pods est de quatre.
Essayons maintenant de configurer!
Préréglage
Tout ce dont vous avez besoin est un cluster Kubernetes et un utilitaire personnalisé
kubectl. Cet exemple utilise un cluster minikube, mais vous pouvez en utiliser un autre. Il existe un guide pour l'installation du cluster .
Installez la dernière version sur Mac:
curl -Lo minikube
https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 \
&& chmod +x minikube
sudo mkdir -p /usr/local/bin/
sudo install minikube /usr/local/bin/
Installez kubectl pour accéder à votre cluster Kubernetes.
Installez la dernière version sur Mac:
curl -LO
"https://storage.googleapis.com/kubernetes-release/release/$(curl -s
https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/darwin/amd64/kubectl"
chmod +x ./kubectl
sudo mv ./kubectl /usr/local/bin/kubectl
kubectl version
Installation de KEDA
Vous pouvez déployer KEDA de plusieurs manières, elles sont répertoriées dans la documentation . J'utilise YAML monolithique:
kubectl apply -f
https://raw.githubusercontent.com/kedacore/keda/master/deploy/KedaScaleController.yaml
KEDA et ses composants sont installés dans l'espace de noms
keda. Commande à vérifier:
kubectl get pods -n keda
Attendez, quand sous KEDA Operator démarre - va à
Running State. Et puis continuez.
Installation de Redis avec Helm
Si Helm n'est pas installé, utilisez ce didacticiel . Commande à installer sur Mac:
brew install kubernetes-helm
helm init --history-max 200
helm initinitialise la CLI locale et s'installe également Tillerdans le cluster Kubernetes.
kubectl get pods -n kube-system | grep tiller
Attendez que la nacelle Tiller entre en état de marche.
Note du traducteur : l'auteur utilise Helm @ 2, qui nécessite l'installation du composant serveur Tiller. Helm @ 3 est actuellement pertinent, il n'a pas besoin d'une partie serveur.
Après avoir installé Helm, une seule commande suffit pour démarrer Redis:
helm install --name redis-server --set cluster.enabled=false --set
usePassword=false stable/redis
Vérifiez que Redis a démarré avec succès:
kubectl get pods/redis-server-master-0
Attendez que sous Redis entre en état
Running.
Déployer l'application
Commande de déploiement:
kubectl apply -f go-app.yaml
//output
deployment.apps/go-prom-app created
service/go-prom-app-service created
Vérifiez que tout a commencé:
kubectl get pods -l=app=go-prom-app
Attendez que Redis passe à l'état
Running.
Déploiement du serveur Prometheus
Le manifeste Prometheus utilise Kubernetes Service Discovery pour Prometheus . Il vous permet de découvrir dynamiquement les pods d'application en fonction d'une étiquette de service.
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_service_label_run]
regex: go-prom-app-service
action: keep
Pour le déploiement:
kubectl apply -f prometheus.yaml
//output
clusterrole.rbac.authorization.k8s.io/prometheus created
serviceaccount/default configured
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
configmap/prom-conf created
deployment.extensions/prometheus-deployment created
service/prometheus-service created
Vérifiez que tout a commencé:
kubectl get pods -l=app=prometheus-server
Attendez que sous Prométhée entre en état
Running.
Permet
kubectl port-forwardd'accéder à l'interface utilisateur de Prometheus (ou au serveur API) à l' adresse http: // localhost: 9090 .
kubectl port-forward service/prometheus-service 9090
Déploiement de la configuration d'autoscaling KEDA
Commande pour créer
ScaledObject:
kubectl apply -f keda-prometheus-scaledobject.yaml
Vérifiez les logs de l'opérateur KEDA:
KEDA_POD_NAME=$(kubectl get pods -n keda
-o=jsonpath='{.items[0].metadata.name}')
kubectl logs $KEDA_POD_NAME -n keda
Le résultat ressemble à ceci:
time="2019-10-15T09:38:28Z" level=info msg="Watching ScaledObject:
default/prometheus-scaledobject"
time="2019-10-15T09:38:28Z" level=info msg="Created HPA with
namespace default and name keda-hpa-go-prom-app"
Vérifiez sous applications. Une instance doit être en cours d'exécution car elle
minReplicaCountvaut 1:
kubectl get pods -l=app=go-prom-app
Vérifiez que la ressource HPA a été créée avec succès:
kubectl get hpa
Vous devriez voir quelque chose comme:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-go-prom-app Deployment/go-prom-app 0/3 (avg) 1 10 1 45s
Bilan de santé: accès à l'application
Pour accéder au point de terminaison REST de notre application, exécutez:
kubectl port-forward service/go-prom-app-service 8080
Vous pouvez désormais accéder à l'application Go en utilisant l'adresse http: // localhost: 8080 . Pour ce faire, exécutez la commande:
curl http://localhost:8080/test
Le résultat ressemble à ceci:
Accessed on 2019-10-21 11:29:10.560385986 +0000 UTC
m=+406004.817901246
Access count 1
Découvrez également Redis à ce stade. Vous verrez que la clé est
access_countaugmentée à 1:
kubectl exec -it redis-server-master-0 -- redis-cli get access_count
//output
"1"
Assurez-vous que la valeur de la métrique
http_requestsest la même:
curl http://localhost:8080/metrics | grep http_requests
//output
# HELP http_requests number of http requests
# TYPE http_requests counter
http_requests 1
Création de charge
Nous allons utiliser hey , un utilitaire pour générer la charge:
curl -o hey https://storage.googleapis.com/hey-release/hey_darwin_amd64
&& chmod a+x hey
Vous pouvez également télécharger l'utilitaire pour Linux ou Windows .
Exécuter:
./hey http://localhost:8080/test
Par défaut, l'utilitaire envoie 200 requêtes. Vous pouvez le vérifier en utilisant les métriques Prometheus ainsi que Redis.
curl http://localhost:8080/metrics | grep http_requests
//output
# HELP http_requests number of http requests
# TYPE http_requests counter
http_requests 201
kubectl exec -it redis-server-master-0 -- redis-cli get access_count
//output
201
Confirmez la valeur réelle de la métrique (renvoyée par la requête PromQL):
curl -g
'http://localhost:9090/api/v1/query?query=sum(rate(http_requests[2m]))'
//output
{"status":"success","data":{"resultType":"vector","result":[{"metric":{},"value":[1571734214.228,"1.686057971014493"]}]}}
Dans ce cas, le résultat réel est égal
1,686057971014493et affiché dans le champ value. Cela ne suffit pas pour la mise à l'échelle car le seuil que nous avons défini est de 3.
Plus de charge!
Dans le nouveau terminal, suivez le nombre de modules d'application:
kubectl get pods -l=app=go-prom-app -w
Augmentons la charge en utilisant la commande:
./hey -n 2000 http://localhost:8080/test
Après un certain temps, vous verrez HPA faire évoluer le déploiement et lancer de nouveaux pods. Vérifiez le HPA pour vous assurer:
kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-go-prom-app Deployment/go-prom-app 1830m/3 (avg) 1 10 6 4m22s
Si la charge n'est pas constante, le déploiement sera réduit au point où un seul pod fonctionne. Si vous souhaitez vérifier la métrique réelle (renvoyée par la requête PromQL), utilisez la commande:
curl -g
'http://localhost:9090/api/v1/query?query=sum(rate(http_requests[2m]))'
Nettoyage
//Delete KEDA
kubectl delete namespace keda
//Delete the app, Prometheus server and KEDA scaled object
kubectl delete -f .
//Delete Redis
helm del --purge redis-server
Conclusion
KEDA vous permet de mettre à l'échelle automatiquement vos déploiements Kubernetes (vers / à partir de zéro) en fonction des données de métriques externes. Par exemple, basé sur les métriques Prometheus, la longueur de la file d'attente dans Redis, la latence du consommateur dans le thème Kafka.
KEDA s'intègre à une source externe et fournit également des métriques via le serveur de métriques pour l'autoscaler de pod horizontal.
Bonne chance!
Quoi d'autre à lire: