1 Qu'est-ce que le manuscrit de Voynich?
Le manuscrit de Voynich est un manuscrit mystérieux (codex, manuscrit ou juste un livre) dans un bon 240 pages qui nous est parvenu, vraisemblablement, du 15ème siècle. Le manuscrit a été accidentellement acquis d'un antiquaire par le mari du célèbre écrivain carbonarien Ethel Voynich - Wilfred Voynich - en 1912 et est rapidement devenu la propriété du grand public.
La langue du manuscrit n'a pas encore été déterminée. Un certain nombre de chercheurs du manuscrit suggèrent que le texte du manuscrit est crypté. D'autres sont sûrs que le manuscrit a été écrit dans une langue qui n'a pas survécu dans les textes que nous connaissons aujourd'hui. D'autres encore considèrent le manuscrit de Voynich comme un non-sens (voir l'hymne moderne à l'absurdisme Codex Seraphinianus ).
A titre d'exemple, je vais donner un fragment scanné d'un sujet avec du texte et des nymphes:

2 Pourquoi ce manuscrit bizarre est-il si intéressant?
C'est peut-être un faux tardif? Apparemment non. Contrairement au Suaire de Turin, ni l'analyse au radiocarbone ni les autres tentatives de contestation de l'ancienneté du parchemin n'ont encore donné de réponse sans ambiguïté. Mais Voynich n'aurait pas pu prévoir l'analyse isotopique au tout début du XXe siècle ...
Mais que se passerait-il si le manuscrit était un ensemble de lettres dénuées de sens de la plume d'un moine enjoué, d'un noble à la conscience altérée? Non, absolument pas. En tapant sans réfléchir sur les touches, je vais, par exemple, décrire le bruit blanc du clavier QWERTY modulé familier de tout le monde comme « asfds dsf». Un examen graphologique montre que l'auteur a écrit d'une main ferme les symboles de l'alphabet bien connus de lui. De plus, les corrélations de la distribution des lettres et des mots dans le texte du manuscrit correspondent au texte «vivant». Par exemple, dans un manuscrit, conditionnellement divisé en 6 sections, il y a des mots - «endémique», souvent trouvés dans l'une des sections, mais absents dans d'autres.
Mais que se passe-t-il si le manuscrit est un chiffre complexe et que les tentatives de le casser sont théoriquement dénuées de sens? Si nous prenons confiance à l'âge vénérable du texte, la version de cryptage est extrêmement improbable. Le Moyen Âge ne pouvait offrir qu'un chiffre de substitution, qu'Edgar Allan Poe cassait si facilement et avec élégance . Là encore, la corrélation des lettres et des mots du texte n'est pas typique pour la grande majorité des chiffrements.
Malgré le succès colossal dans la traduction de scripts anciens, y compris avec l'utilisation de ressources informatiques modernes, le manuscrit de Voynich défie toujours les linguistes professionnels expérimentés ou les jeunes scientifiques ambitieux des données.
3 Mais que se passe-t-il si la langue du manuscrit nous est connue
... mais l'orthographe est différente? Qui, par exemple, reconnaît le latin dans ce texte ?

Et voici un autre exemple - translittération d'un texte anglais en grec:
in one of the many little suburbs which cling to the outskirts of london
ιν ονε οφ θε μανυ λιττλε συμπυρμπσ whιχ cλιγγ το θε ουτσκιρτσ οφ λονδονBibliothèque Transliterate de Python . NB: il ne s'agit plus d'un chiffrement de substitution - certaines combinaisons multi-lettres sont transmises en une seule lettre et vice versa.
J'essaierai d'identifier (classer) la langue du manuscrit, ou trouver le parent le plus proche à partir des langues connues, en mettant en évidence les traits caractéristiques et en formant le modèle sur celles-ci:
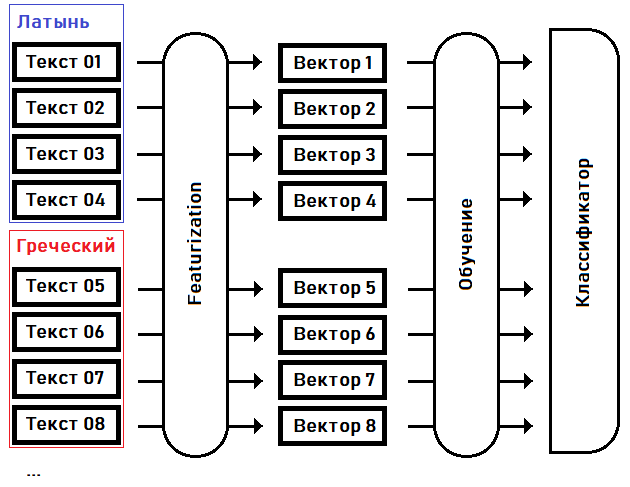
Au premier stade - la caractérisation- nous transformons les textes en vecteurs de caractéristiques: des tableaux de taille fixe de nombres réels, où chaque dimension du vecteur est responsable de sa propre particularité (caractéristique) du texte source. Par exemple, convenons dans la 15ème dimension du vecteur de garder la fréquence du mot le plus courant dans le texte, dans la 16ème dimension - le deuxième mot le plus populaire ... dans la Nème dimension - la séquence la plus longue du même mot répété, etc.
A la deuxième étape - formation - nous sélectionnons les coefficients du classifieur en fonction de la connaissance a priori de la langue de chacun des textes.
Une fois le classificateur formé, nous pouvons utiliser ce modèle pour déterminer la langue du texte qui n'a pas été incluse dans l'échantillon d'apprentissage. Par exemple, pour le texte du manuscrit de Voynich.
4 L'image est si simple - quel est le problème?
La partie la plus délicate est de savoir comment transformer exactement un fichier texte en vecteur. Séparer le bon grain de l'ivraie et ne laisser que les caractéristiques caractéristiques de la langue dans son ensemble, et non chaque texte spécifique.
Si, pour simplifier, transformez les textes sources en encodage (c'est-à-dire en nombres) et «alimentez» ces données telles quelles dans l'un des nombreux modèles de réseaux de neurones, le résultat ne nous plaira probablement pas. Très probablement, un modèle formé sur de telles données sera lié à l'alphabet et c'est sur la base de symboles que, tout d'abord, il tentera de déterminer la langue d'un texte inconnu.
Mais l'alphabet du manuscrit «n'a pas d'analogues». De plus, nous ne pouvons pas nous fier entièrement aux modèles de distribution des lettres. Théoriquement, il est également possible de transférer la phonétique d'une langue par les règles d'une autre (la langue est elfique - et les runes sont du mordor).
Le scribe rusé n'a pas utilisé de signes de ponctuation ou de chiffres tels que nous les connaissons. Le texte entier peut être considéré comme un flux de mots, divisé en paragraphes. Il n'y a même pas de certitude quant à l'endroit où une phrase se termine et une autre commence.
Cela signifie que nous nous éleverons à un niveau supérieur par rapport aux lettres et que nous nous fierons aux mots. Nous compilerons un dictionnaire basé sur le texte du manuscrit et tracerons les modèles déjà au niveau du mot.
5 Texte original du manuscrit
Bien sûr, vous n'avez pas besoin d'encoder les caractères complexes du manuscrit de Voynich dans leurs équivalents Unicode et vice versa vous-même - ce travail a déjà été fait pour nous, par exemple ici . Avec les options par défaut, j'obtiens l'équivalent suivant de la première ligne du manuscrit:
fachys.ykal.ar.ataiin.shol.shory.cth!res.y.kor.sholdy!-Les points et les points d'exclamation (ainsi qu'un certain nombre d'autres symboles de l'alphabet EVA ) ne sont que des séparateurs, qui pour nos besoins peuvent être remplacés par des espaces. Les points d'interrogation et les astérisques sont des mots / lettres non reconnus.
Pour vérification, substituons le texte ici et obtenons un fragment du manuscrit:
6 Programme - classificateur de texte (Python)
Voici un lien vers le référentiel de code avec les conseils README minimum dont vous avez besoin pour tester le code en action.
J'ai rassemblé plus de 20 textes en latin, russe, anglais, polonais et grec, en essayant de maintenir le volume de chaque texte en ± 35 000 mots (le volume du manuscrit de Voynich).
J'ai essayé de sélectionner une datation rapprochée dans les textes, en une seule orthographe - par exemple, dans les textes en russe, j'ai évité la lettre Ѣ, et les variantes d'écriture de lettres grecques avec des signes diacritiques différents ont conduit à un dénominateur commun. J'ai également supprimé les numéros, les spéciaux des textes. caractères, espaces supplémentaires, lettres converties en une seule casse.
L'étape suivante consiste à créer un «dictionnaire» contenant des informations telles que:
- fréquence d'utilisation de chaque mot dans le texte (textes),
- La "racine" d'un mot - ou plutôt une partie commune immuable pour un ensemble de mots,
- "préfixes" et "fins" communs - ou plutôt, le début et la fin des mots, ainsi que la "racine" constituant les mots réels,
- séquences communes de 2 et 3 mots identiques et la fréquence de leur apparition.
J'ai pris la «racine» du mot entre guillemets - un algorithme simple (et parfois moi-même) n'est pas capable de déterminer, par exemple, quelle est la racine du mot support? En devenant ka? Sous le tarif ?
D'une manière générale, ce vocabulaire est constitué de données à moitié préparées pour la construction d'un vecteur d'entités. Pourquoi ai-je choisi cette étape - compiler et mettre en cache des dictionnaires pour des textes individuels et pour un ensemble de textes pour chacune des langues? Le fait est qu'un tel dictionnaire prend beaucoup de temps à construire, environ une demi-minute pour chaque fichier texte. Et j'ai déjà plus de 120 fichiers texte.
7 Présentation
L'obtention d'un vecteur de caractéristiques n'est qu'une étape préliminaire à la poursuite de la magie du classificateur. En tant que monstre de la POO, bien sûr, j'ai créé une classe abstraite BaseFeaturizer pour la logique amont, afin de ne pas violer le principe d' inversion de dépendance . Cette classe lègue aux descendants de pouvoir transformer un ou plusieurs fichiers texte à la fois en vecteurs numériques.
Et la classe héritière doit donner un nom à chaque entité individuelle (la coordonnée i du vecteur d'entités). Ceci est utile si nous décidons de visualiser la logique machine de la classification. Par exemple, la dimension 0 du vecteur sera marquée CRw1 - autocorrélation de la fréquence d'utilisation des mots tirés du texte à la position adjacente (avec un décalage de 1).
De la classe BaseFeaturizer, j'ai hérité de la classeWordMorphFeaturizer , dont la logique est basée sur la fréquence d'utilisation des mots dans tout le texte et dans une fenêtre glissante de 12 mots.
Un aspect important est que le code d'un héritier spécifique de BaseFeaturizer, en plus des textes eux-mêmes, a également besoin de dictionnaires préparés sur leur base (la classe CorpusFeatures ), qui sont probablement déjà mis en cache sur le disque au moment du début de la formation et du test du modèle.
8 Classement
La classe abstraite suivante est BaseClassifier . Cet objet peut être entraîné puis classer les textes par leurs vecteurs de caractéristiques.
Pour l'implémentation (la classe RandomForestLangClassifier ), j'ai choisi l'algorithme Random Forest Classifier de la bibliothèque sklearn . Pourquoi ce classificateur particulier?
- Random Forest Classifier me convenait avec ses paramètres par défaut,
- il ne nécessite pas de normalisation de l'entrée,
- offre une visualisation simple et intuitive de l'algorithme de prise de décision.
Puisque, à mon avis, le classificateur de forêt aléatoire s'est acquitté de sa tâche, je n'ai écrit aucune autre implémentation.
9 Formation et tests
80% des fichiers - gros fragments des opus de Byron, Aksakov, Apuleius, Pausanias et autres auteurs, dont j'ai pu trouver les textes au format txt - ont été choisis au hasard pour former le classificateur. Les 20% restants (28 fichiers) sont déterminés pour des tests hors échantillon.
Alors que j'ai testé le classificateur sur ~ 30 textes anglais et 20 textes russes, le classificateur a donné un grand pourcentage d'erreurs: dans presque la moitié des cas, la langue du texte a été mal déterminée. Mais quand j'ai commencé ~ 120 fichiers texte en 5 langues (russe, anglais, latin, ancien hellénique et polonais), le classificateur a cessé de faire des erreurs et a commencé à reconnaître correctement la langue de 27 à 28 fichiers provenant de 28 cas de test.
Puis j'ai compliqué un peu le problème: j'ai transcrit en grec le roman irlandais du 19ème siècle "Rachel Gray" et l'ai soumis à un classificateur qualifié. La langue du texte en translittération a de nouveau été correctement définie.
10 L'algorithme de classification est clair
Voici à quoi ressemble l'un des 100 arbres du classificateur de forêt aléatoire entraîné (pour rendre l'image plus lisible, j'ai coupé 3 nœuds du sous-arbre droit):
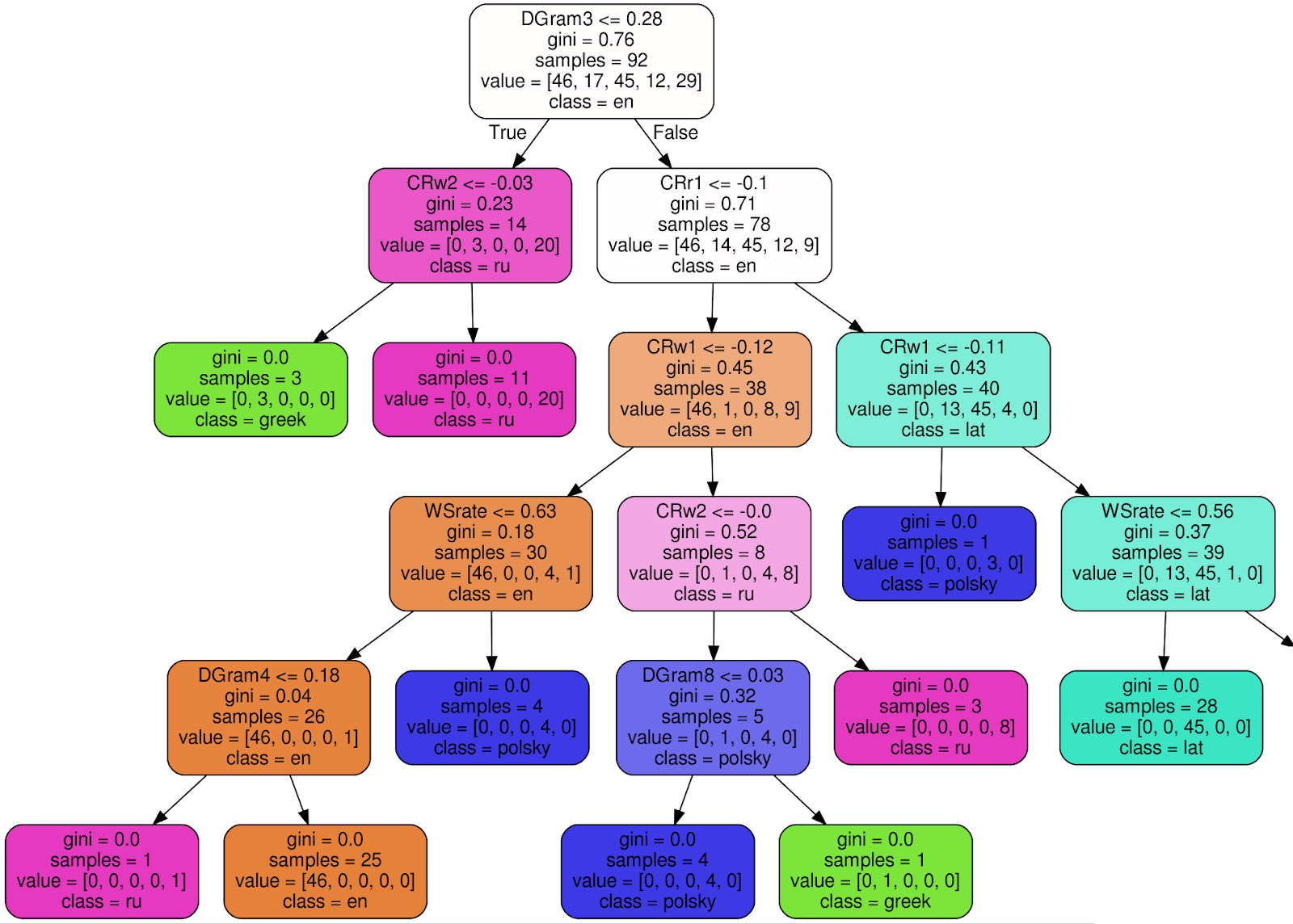
En utilisant le nœud racine comme exemple , j'expliquerai la signification de chaque signature:
- DGram3 <= 0,28 - critère de classification. Dans ce cas, DGram3 est une dimension spécifique d'un vecteur de caractéristiques nommé par la classe WordMorphFeaturizer, à savoir, la fréquence du troisième mot le plus courant dans une fenêtre glissante de 12 mots,
- gini = 0.76 — , Gini impurity, , , . , , - . . , gini, , 0 ( ),
- samples = 92 — , ,
- value = [46, 17, 45, 12, 29] — , (46 , 17 , 45 ..),
- class = en ( ) — .
Si le critère (DGram3 <= 0,28 pour le nœud racine) est satisfait, allez dans le sous-arbre de gauche, sinon - vers la droite. Dans chaque feuille, tous les textes doivent être affectés à une classe (langue) et au critère d'incertitude de Gini ≡ 0. La
décision finale est prise par un ensemble de 100 arbres similaires construits pendant la formation du classificateur.
11 Et comment le programme a-t-il défini la langue du manuscrit?
Latin , estimation de probabilité 0,59. Et, bien entendu, ce n'est pas encore la solution au problème du siècle.
Une correspondance univoque entre le dictionnaire manuscrit et la langue latine n'est pas facile, voire impossible. Par exemple, voici dix des mots les plus fréquemment utilisés: manuscrits de Voynich, latin,

grec ancien et russe: l'
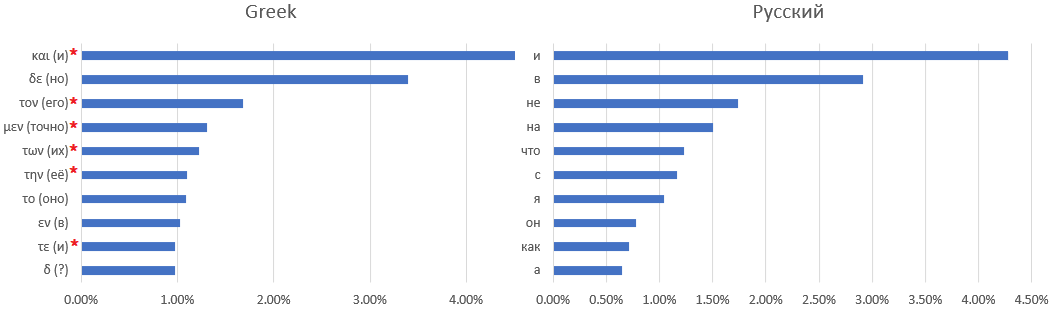
astérisque marque les mots pour lesquels il est difficile de trouver un équivalent russe - par exemple, des articles ou des prépositions qui changent de sens en fonction du contexte.
Un match évident comme
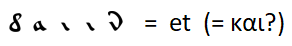
avec l'extension des règles de remplacement des lettres par d'autres mots fréquemment utilisés, je n'ai pas pu trouver. Vous ne pouvez faire que des hypothèses - par exemple, le mot le plus courant est la conjonction "et" - comme dans toutes les autres langues considérées sauf l'anglais, dans lequel la conjonction "et" a été poussée à la deuxième place par l'article défini "le".
Et après?
Tout d'abord, il vaut la peine d'essayer de compléter l'échantillon de langues avec des textes en français moderne, espagnol, ..., langues du Moyen-Orient, si possible - vieil anglais, langues françaises (avant le XVe siècle) et autres. Même si aucune de ces langues n'est la langue du manuscrit, la précision de la définition des langues connues augmentera encore, et un équivalent plus proche sera probablement sélectionné à la langue du manuscrit.
Un défi plus créatif consiste à essayer de définir une partie du discours pour chaque mot. Pour un certain nombre de langues (bien sûr, tout d'abord - anglais), les tokenizers PoS (Part of Speech) dans le cadre de packages disponibles au téléchargement font bien cette tâche. Mais comment déterminer les rôles des mots dans une langue inconnue?
Des problèmes similaires ont été résolus par le linguiste soviétique B.V. Sukhotin - par exemple, il a décrit les algorithmes:
- séparation des caractères d'un alphabet inconnu en voyelles et consonnes - malheureusement pas fiable à 100%, en particulier pour les langues à phonétique non triviale, comme le français,
- sélection de morphèmes dans le texte sans espaces.
Pour la tokenisation PoS, nous pouvons nous appuyer sur la fréquence d'utilisation des mots, l'occurrence dans des combinaisons de 2/3 mots, la distribution des mots à travers les sections du texte: les unions et les particules doivent être plus uniformément réparties que les noms.
Littérature
Je ne laisserai pas ici des liens vers des livres et des tutoriels sur la PNL - cela suffit sur le net. Au lieu de cela, je vais énumérer des œuvres d'art qui sont devenues une belle trouvaille pour moi étant enfant, où les héros ont dû travailler dur pour démêler les textes cryptés:
- E. A. Poe: Le Golden Beetle est un classique intemporel
- V. Babenko: «Meeting» est un roman policier tordu et visionnaire de la fin des années 80,
- K. Kirita: «Les chevaliers de la rue Chereshnevaya, ou le château de la fille en blanc» est un roman fascinant pour adolescents, écrit sans réduction pour l'âge du lecteur.