
introduction
Il existe de nombreuses compétitions en apprentissage automatique, ainsi que les plateformes sur lesquelles elles se déroulent, pour tous les goûts. Mais le thème du concours n'est pas si souvent la langue humaine et son traitement, encore moins souvent un tel concours est associé à la langue russe. J'ai récemment participé à un concours de traduction automatique du chinois vers le russe sur la plateforme ML Boot Camp de Mail.ru. N'ayant pas beaucoup d'expérience en programmation compétitive, et ayant passé, grâce à la quarantaine, toutes les vacances de mai chez moi, j'ai réussi à prendre la première place. J'essaierai d'en parler, ainsi que des langues et de la substitution d'une tâche par une autre dans l'article.
Chapitre 1. Ne jamais parler chinois
Les auteurs de ce concours ont proposé de créer un système de traduction automatique à usage général, car la traduction même des grandes entreprises dans une paire chinois-russe est loin derrière les paires plus populaires. Mais comme la validation a eu lieu sur l'actualité et la fiction, il est devenu clair qu'il était nécessaire d'apprendre des corpus d'actualités et des livres. La métrique pour évaluer les transferts était le BLEU standard . Cette métrique compare la traduction humaine à la traduction automatique et, grosso modo, sur la base du nombre de correspondances trouvées, estime la similitude des textes sur une échelle de 100 points. La langue russe est riche dans sa morphologie, par conséquent, cette métrique est toujours nettement inférieure lorsqu'elle est traduite dans celle-ci que dans les langues avec moins de moyens de formation des mots (par exemple, les langues romanes - français, italien, etc.).
Quiconque traite de l'apprentissage automatique sait qu'il s'agit principalement de données et de leur nettoyage. Commençons par chercher des corpus et en même temps, nous comprendrons les aspects sauvages de la traduction automatique. Alors, dans un manteau blanc ...
Chapitre 2. Pon Tiy Pi Lat
Dans un manteau blanc avec une doublure sanglante, une démarche de cavalerie traînante, nous montons dans un moteur de recherche derrière un corps parallèle russo-chinois. Comme nous le comprendrons plus tard, ce que nous avons trouvé ne suffit pas, mais pour l'instant jetons un coup d'œil à nos premières découvertes (j'ai rassemblé les jeux de données que j'ai trouvés et nettoyés et mis dans le domaine public [1] ):
OPUS est un corpus assez volumineux et linguistiquement diversifié, regardons-en des exemples:
"Ce qu'elle et moi avons vécu est encore plus inhabituel que ce que vous avez vécu ..."
我 与 她 的 经历 比 你 的 经历 离奇 多 了
"Je vais vous en parler."
我 给 你 讲讲 这段 经历…
" La petite ville où je suis né ... »
我 出生 那座 小镇 ...
Comme son nom l'indique, il s'agit principalement de sous-titres de films et de séries télévisées. Les sous-titres TED appartiennent au même type , qui, après analyse et nettoyage, se transforment également en un corpus complètement parallèle:
Voici comment notre expérience historique de la punition s'est avérée: les jeunes ont peur qu'à tout moment ils puissent être arrêtés, fouillés, détenus. 年轻人 总是 担心 随时 会 被WikiMatrix est composé de textes alignés au LASER provenant de pages Internet (ce que l'on appelle l'exploration commune ) dans différentes langues, mais pour notre tâche, ils sont peu nombreux et ils semblent étranges:
的 的 不为人知 的 一面、 搜身 和 逮捕 Et pas seulement dans la rue, mais aussi chez eux, 无论 是 在 街上 还是 在
Zbranki (ukrainienAprès la première étape de récupération des données, une question se pose avec notre modèle. Quels sont les outils et comment aborder la tâche?
但 被 其 否认。
Mais tu ferais mieux de vite, si tu savais!
斋戒 对于 你们 更好 , 如果 你们 知道。
Il a rejeté cette affirmation.
后来 这个 推论 被 否认。
Il y a un cours de PNL que j'ai beaucoup aimé du MIPT sur Stepic [2] , qui est particulièrement utile pour le suivre en ligne, où les systèmes de traduction automatique sont également compris dans les séminaires, et vous les écrivez vous-même. Je me souviens de la joie que le réseau, écrit de toutes pièces, après une formation chez Colab, ait produit une traduction russe adéquate en réponse au texte allemand. Nous avons construit nos modèles sur l'architecture des transformateurs avec un mécanisme d'attention, qui à un moment donné est devenu une idée de rupture [3] .
Naturellement, la première pensée a été de «donner simplement au modèle des données d'entrée différentes» et de gagner déjà. Mais, comme tout écolier chinois le sait, il n'y a pas d'espaces dans le script chinois et notre modèle accepte des ensembles de jetons en entrée, qui sont des mots. Les bibliothèques comme jieba peuvent décomposer le texte chinois en mots avec une certaine précision. En incorporant la tokenisation de mot dans le modèle et en l'exécutant sur les corpus trouvés, j'ai obtenu un BLEU d'environ 0,5 (et l'échelle est de 100 points).
Chapitre 3. La traduction automatique et son exposition
Une base de référence officielle (solution d'exemple simple mais fonctionnelle) a été proposée pour le concours, basée sur OpenMNT . C'est un outil d'apprentissage de la traduction open source avec de nombreux hyper-paramètres pour la torsion. Dans cette étape, formons et déduisons le modèle à travers celui-ci. Nous nous formerons sur la plate-forme kaggle, puisqu'elle donne gratuitement 40 heures de formation GPU [4] .
Il convient de noter qu'à cette époque, il y avait si peu de participants au concours que, une fois inscrit, on pouvait immédiatement entrer dans les cinq premiers, et il y avait des raisons à cela. Le format de la solution était un conteneur de docker, dans lequel les dossiers étaient montés pendant le processus d'inférence, et le modèle devait lire à partir de l'un et mettre la réponse dans un autre. Comme la ligne de base officielle n'a pas commencé (personnellement je ne l'ai pas assemblé tout de suite) et était sans poids, j'ai décidé de collecter la mienne et de la mettre dans le domaine public [5]. Après cela, les participants ont commencé à postuler en demandant d'assembler correctement la solution et d'aider généralement avec le docker. Moral, les conteneurs sont la norme dans le développement d'aujourd'hui, utilisez-les, orchestrez et simplifiez votre vie (tout le monde n'est pas d'accord avec la dernière affirmation).
Ajoutons maintenant quelques autres aux corps trouvés à l'étape précédente:
- Corpus parallèle des Nations Unies (3M + rangées)
- UM-Corpus: Un grand corpus parallèle anglo-chinois (sous-corporation de nouvelles) (450K lignes)
Le premier est un énorme corpus de documents juridiques issus des réunions de l'ONU. Il est d'ailleurs disponible dans toutes les langues officielles de cette organisation et est aligné sur les propositions. Le second est encore plus intéressant, car il s'agit directement d'un corpus d'actualités avec une particularité - il est chinois-anglais. Ce fait ne nous dérange pas, car la traduction automatique moderne de l'anglais vers le russe est de très haute qualité et Amazon Translate, Google Translate, Bing et Yandex sont utilisés. Pour être complet, nous montrerons des exemples de ce qui s'est passé.
Documents de l'ONU
.
它是一个低成本平台运转寿命较长且能在今后进一步发展。
.
报告特别详细描述了由参加者自己拟订的若干与该地区有关并涉及整个地区的项目计划。
UM-Corpus
Facebook a conclu l'accord pour acheter Little Eye Labs début janvier.
1 月初 脸 书 完成 了 对 Little Eye Labs 的 收购 ,
Quatre ingénieurs de Bangalore ont lancé Little Eye Labs il y a environ un an et demi
一年 半 以前 四位 工程师 在 班加罗尔 创办 了 L'
entreprise crée des outils logiciels pour les applications mobiles, traite coûtera entre 10 et 15 millions de dollars.
该 公司 开发 移动 应用 软件 工具 , 这次 交易 价值 1000 到 1500 万 一元 ,
Donc, nos nouveaux ingrédients: OpenNMT + boîtiers de haute qualité + BPE (vous pouvez en savoir plus sur la tokenisation BPE ici ). Nous formons, assemblons dans un conteneur, et après le débogage / nettoyage et les astuces standard, nous obtenons BLEU 6.0 (l'échelle est toujours de 100 points).
Chapitre 4. Les manuscrits parallèles ne brûlent pas
Jusqu'à présent, nous avons amélioré notre modèle étape par étape, et le plus gros gain est venu de l'utilisation du corpus d'actualités, l'un des domaines de validation. Outre les nouvelles, ce serait bien d'avoir un corpus de littérature. Après avoir passé une quantité considérable de temps , il est devenu clair que les traductions automatiques de livres chinois sans système populaire ne peut pas fournir - Nastasia devient quelque chose comme Nostosi Filipauny et Rogojine - Rogo Wren . Les noms des personnages représentent généralement un pourcentage assez important de l'ensemble du travail et souvent ces noms sont rares, par conséquent, si le modèle ne les a jamais vus, il ne sera probablement pas en mesure de les traduire correctement. Nous devons apprendre des livres.
Ici, nous remplaçons la tâche de traduction par la tâche d'alignement de texte. Je dois dire tout de suite que j'ai le plus aimé cette partie, car j'aime moi-même étudier les langues et les textes parallèles de livres et d'histoires, à mon avis, c'est l'une des méthodes d'apprentissage les plus productives. Il y avait plusieurs idées d'alignement, la plus productive s'est avérée être de traduire des phrases en espace vectoriel et de calculer la distance cosinus entre les candidats pour une correspondance. Traduire quelque chose en vecteurs s'appelle l'intégration, dans ce cas, c'est une incorporation de phrase . Il existe plusieurs bonnes bibliothèques à cet effet [6] . En visualisant le résultat, on peut voir que le texte chinois glisse un peu du fait que les phrases complexes en russe sont souvent traduites en deux ou trois en chinois.
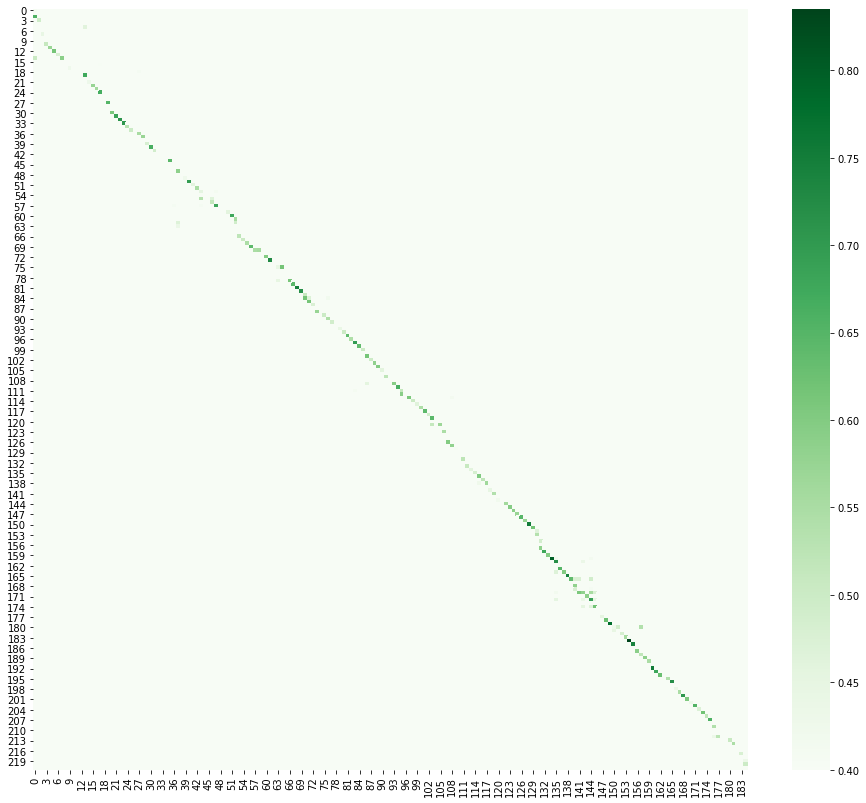
Après avoir trouvé tout ce qui est possible sur Internet et nivelé nous-mêmes les livres, nous les ajoutons à notre corpus.
Il portait un costume gris cher et étrangers, dans les chaussures de couleur costume.
他的穿一身昂贵灰色西装,脚上外国皮鞋的也与颜色西装十分协调.
Gris prend célèbre salle sur l'oreille, sous le bras, portant une canne avec un noir avec un bouton en
forme de caniche .
Elle a l'air d'avoir plus de quarante ans.
看 模样 年纪 在 四十 开外。
Après une formation sur le nouveau bâtiment, BLEU est passé à 20 sur un ensemble de données public et à 19,7 sur un ensemble privé. Cela a également joué un rôle dans le fait que les travaux de validation entraient évidemment dans la formation. En réalité, cela ne devrait jamais être fait, cela s'appelle une fuite et la métrique cesse d'être indicative.
Conclusion
La traduction automatique a parcouru un long chemin depuis les méthodes heuristiques et statistiques jusqu'aux réseaux de neurones et aux transformateurs. Je suis content d'avoir pu trouver le temps de me familiariser avec ce sujet, il mérite certainement une attention particulière de la part de la communauté. Je tiens à remercier les auteurs du concours et les autres participants pour la communication intéressante et les nouvelles idées!
[1] Corpus parallèles russe-chinois
[2] Cours sur le traitement du langage naturel du MIPT
[3] Article révolutionnaire Tout ce dont vous avez besoin
[4] Ordinateur portable avec un exemple d'apprentissage sur kaggle
[5] Base de base du docker public
[6] Bibliothèque de phrases multilingues plongements