int main()
{
int n = 500000000;
int *a = new int[n + 1];
for (int i = 0; i <= n; i++)
a[i] = i;
for (int i = 2; i * i <= n; i++)
{
if (a[i]) {
for (int j = i*i; j <= n; j += i) {
a[j] = 0;
}
}
}
delete[] a;
return 0;
}C'est une application simple surtout pour les expériences, elle recherche des nombres premiers à l'aide du tamis d'Eratosthène . Exécutons la solution 20 fois et calculons le temps utilisateur de chaque exécution.
Description du banc d'essai
i7-8750H @ 2,20
32 RAM
O:
Ubuntu 18.04.4
5.3.0-53-generic
32 RAM
O:
Ubuntu 18.04.4
5.3.0-53-generic
Dispersion du temps d'exécution avant optimisations:
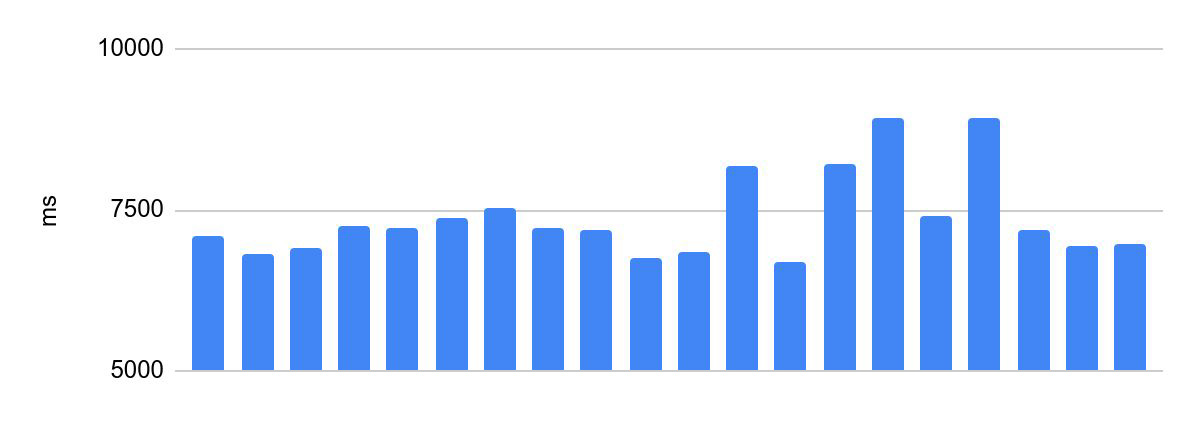
la différence entre l'exécution la plus rapide et la plus lente est de 2230 ms.
Ceci est inacceptable pour la programmation des Olympiades. Le temps d'exécution du code du participant est l'un des critères de réussite de sa solution et l'une des conditions du concours, la distribution des lots en dépend. Par conséquent, il existe une exigence importante pour de tels systèmes - le même temps de vérification pour le même code. Dans ce qui suit, nous appellerons cela la cohérence de l'exécution du code.
Essayons d'aligner le temps d'exécution.
Isolation du noyau
Commençons par l'évidence. Les processus se disputent les cœurs et vous devez en quelque sorte isoler le cœur pour l'exécution de la solution. En outre, lorsque Hyper Threading est activé, le système d'exploitation définit un cœur de processeur physique comme deux cœurs logiques distincts. Pour une isolation du cœur équitable, nous devons désactiver Hyper Threading. Cela peut être fait dans les paramètres du BIOS.
Le noyau Linux prêt à l'emploi prend en charge un indicateur de démarrage pour isoler les noyaux isolcpus. Ajoutez cet indicateur à GRUB_CMDLINE_LINUX_DEFAULT dans les paramètres de grub: / etc / default / grub. Par exemple:
GRUB_CMDLINE_LINUX_DEFAULT="... isolcpus=0,1"
exécutez update-grub et redémarrez le système.
Tout a l'air comme prévu - les deux premiers noyaux ne sont pas utilisés par le système:

Commençons sur un noyau isolé. La configuration CPU Affinity vous permet de lier un processus à un cœur spécifique. Il y a plusieurs moyens de le faire. Par exemple, exécutons la solution dans un conteneur porto (le noyau est sélectionné à l'aide de l'argument cpu_set):
portoctl exec test command='sudo stress.sh' cpu_set=0Offtop: nous utilisons QEMU-KVM pour exécuter des solutions en production. Le conteneur porto est utilisé tout au long de l'article pour le rendre plus facile à afficher.
Lancement avec un noyau dédié à la solution, sans charger les noyaux voisins:

La différence est de 375 ms. Ça s'est amélioré, mais c'est encore trop.
Performances Tyunim
Essayons notre test de résistance. Laquelle? Notre tâche est de charger tous les cœurs avec plusieurs threads. Cela peut être fait de plusieurs manières:
- Écrivez une application simple qui créera de nombreux threads et commencera à compter quelque chose dans chacun d'eux.
- :
cat /dev/zero | pbzip2 -c > /dev/null. pbzip2 — bzip2. - stress
stress --cpu 12.
Lancement avec un cœur dédié à une solution, avec une charge sur les cœurs adjacents:

La différence est de 1354 ms: une seconde de plus que sans charge. Évidemment, la charge a affecté le temps d'exécution, malgré le fait que nous fonctionnions sur un noyau isolé. On peut voir qu'à un certain moment, le temps d'exécution a diminué. À première vue, cela est contre-intuitif: avec une charge croissante, les performances augmentent également.
En production, ce comportement (lorsque le temps d'exécution commence à flotter sous la charge) peut être très pénible à déclencher. Quelle est la charge dans ce cas? Un flux de décisions des participants, le plus souvent lors de grandes compétitions et olympiades.
La raison en est que Intel Turbo Boost est activé sous charge - une technologie pour augmenter la fréquence. Désactivez-le. Pour mon stand, j'ai également désactivé SpeedStep... Pour un processeur AMD, Turbo Core Cool'n'Quiet devrait être désactivé. Tout ce qui précède se fait dans le BIOS, l'idée principale est de désactiver ce qui contrôle automatiquement la fréquence du processeur.
Fonctionnement sur un noyau isolé avec Turbo Boost désactivé et charge sur les cœurs voisins: cela

semble bon, mais la différence est toujours de 252 ms Et c'est encore trop.
Offtop: remarquez comment le temps d'exécution moyen a chuté d'environ 25%. Dans la vie de tous les jours, les technologies handicapées sont bonnes.
Nous avons éliminé la concurrence pour les cœurs, stabilisé la fréquence des cœurs - maintenant plus rien ne les affecte. Alors d'où vient la différence?
NUMA
Accès mémoire non uniforme, ou architecture mémoire non uniforme, «une architecture avec une mémoire inégale». Dans les systèmes NUMA (c'est-à-dire sur n'importe quel ordinateur multiprocesseur moderne), chaque processeur dispose d'une mémoire locale, qui est considérée comme faisant partie du total. Chaque processeur peut accéder à la fois à sa mémoire locale et à la mémoire locale des autres processeurs (mémoire distante). L'inégalité est que l'accès à la mémoire locale est sensiblement plus rapide.
Le temps de représentation «marche» précisément à cause de ces inégalités. Corrigeons le problème en liant notre exécution à un nœud numa spécifique. Pour ce faire, ajoutez le noeud numa à la configuration du conteneur porto:
portoctl exec test command='stress.sh' cpu_set="node 0" cpu_set=0Exécution sur un cœur isolé avec Turbo Boost désactivé, configuration NUMA et charge sur les cœurs voisins:
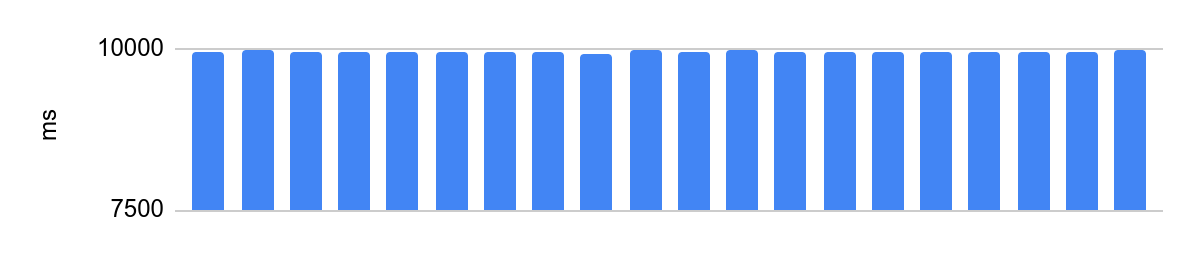
la différence est de 48 ms et le temps d'exécution moyen après la désactivation des optimisations du processeur est de 10 secondes. 48 ms à 10 s équivaut à une erreur de 0,5%, très bien.
Spoiler important
Un peu plus sur isolcpus
L'indicateur isolcpus a un problème: certains threads système peuvent toujours planifier vers un noyau isolé.
Par conséquent, en production, nous utilisons un noyau patché avec des fonctionnalités étendues de cet indicateur. Ainsi, nous choisissons le noyau, en tenant compte du flag, lors de la planification des threads.
, 3.18. kthread_run, . CPU, isolcpus.
— slave_cpus , .
— slave_cpus , .
Projets pour le futur
Pools
Si une machine décisive est plus puissante que l'autre, alors aucune quantité de réglages d'isolation de noyau n'aidera - par conséquent, nous obtiendrons toujours une grande différence dans le temps d'exécution. Par conséquent, vous devez penser aux environnements hétérogènes. Jusqu'à présent, nous ne prenions tout simplement pas en charge l'hétérogénéité - l'ensemble du parc de machines décisionnelles est équipé du même matériel. Mais dans un proche avenir, nous commencerons à diviser du matériel différent en pools homogènes, et chaque compétition se déroulera dans le même pool avec le même matériel.
Passer au cloud
Un nouveau défi pour le système sera la nécessité de se lancer dans Yandex.Cloud. Selon les normes actuelles, les serveurs de fer ne sont pas fiables, un déménagement est nécessaire, mais il est important de maintenir la cohérence dans l'exécution des colis. Ici, les possibilités techniques sont encore à l'étude. Il existe une idée selon laquelle, dans les cas extrêmes, les machines cloud peuvent exécuter des solutions qui ne nécessitent pas de temps d'exécution strict. Ainsi, nous réduirons la charge sur les machines à repasser et elles ne traiteront que des solutions qui demandent juste de la cohérence. Il existe une autre option: vérifiez d'abord le colis dans le cloud et, s'il ne respecte pas le délai, revérifiez-le sur du matériel réel.
Collecte de statistiques
Même après tous les ajustements, les processeurs ralentiront inévitablement. Pour réduire l'effet négatif, nous allons exécuter les solutions en parallèle, comparer les résultats et, s'ils diffèrent, lancer une revérification. De plus, si l'une des machines décisives se dégrade constamment, c'est une excuse pour la mettre hors service et en traiter les raisons.
conclusions
Le concours a une particularité - il peut sembler que tout se résume simplement à exécuter le code et à obtenir le résultat. Dans cet article, je n'ai révélé qu'un petit aspect de ce processus. Il y a quelque chose comme ça sur chaque couche du service.