Ce faisant, ils oublient que les modèles ne sont que des solutions possibles. Les modèles, comme tous les principes, ont des limites d'applicabilité et il est important de les comprendre. La route de l'enfer est pavée d'une adhésion aveugle et religieuse à des paroles même faisant autorité.
Et la présence des motifs nécessaires dans le cadre ne garantit pas leur application correcte et consciente.

L'éclat et la pauvreté d'Active Record
Regardons le modèle Active Record comme un anti-modèle, que certains langages de programmation et frameworks essaient d'éviter de toutes les manières possibles.
L'essence d'Active Record est simple: nous stockons la logique métier avec la logique de stockage d'entité. En d'autres termes, pour le dire très simplement, chaque table de la base de données correspond à une classe d'entité avec un comportement.
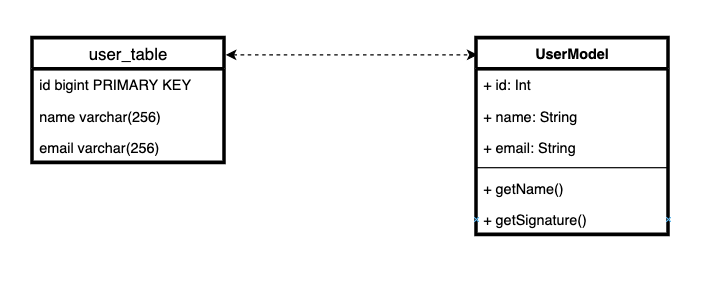
Il y a une opinion assez forte que combiner la logique métier et la logique de stockage dans une classe est un très mauvais modèle inutilisable. Cela viole le principe de la responsabilité exclusive. Et pour cette raison, Django ORM est mauvais par conception.
En effet, il peut ne pas être très bon de combiner la logique de stockage et la logique de domaine dans la même classe.
Prenons par exemple les modèles d'utilisateur et de profil. C'est un modèle assez courant. Il y a une plaque principale, et il y en a une supplémentaire, qui stocke les données pas toujours obligatoires, mais parfois nécessaires.

Il s'avère que l'entité du domaine «utilisateur» est désormais stockée dans deux tables, et dans le code nous avons deux classes. Et chaque fois que nous apportons directement des corrections
user.profile, nous devons nous rappeler qu'il s'agit d'un modèle distinct et que nous y avons apporté des modifications. Et enregistrez-le séparément.
def create(self, validated_data):
# create user
user = User.objects.create(
url = validated_data['url'],
email = validated_data['email'],
# etc ...
)
profile_data = validated_data.pop('profile')
# create profile
profile = Profile.objects.create(
user = user
first_name = profile_data['first_name'],
last_name = profile_data['last_name'],
# etc...
)
return user
Pour obtenir une liste d'utilisateurs, il est impératif de se demander si un attribut sera pris à ces utilisateurs
profileafin de sélectionner immédiatement deux signes avec une jointure et de ne pas l'obtenir SELECT N+1en boucle.
user = User.objects.get(email='example@examplemail.com')
user.userprofile.company_name
user.userprofile.country
Les choses empirent encore si, dans l'architecture du microservice, une partie des données utilisateur est stockée dans un autre service - par exemple, les rôles et les droits dans LDAP.
En même temps, bien sûr, je ne veux vraiment pas que les utilisateurs externes de l'API s'en soucient d'une manière ou d'une autre. Il existe une ressource REST
/users/{user_id}et j'aimerais travailler avec elle sans penser à la façon dont les données sont stockées à l'intérieur. S'ils sont stockés dans différentes sources, il sera alors plus difficile de changer d'utilisateur ou d'obtenir la liste des données.
De manière générale, ORM! = Domain Model!

Et plus le monde réel diffère de l'hypothèse «une table dans la base de données - une entité du domaine», plus il y a de problèmes avec le modèle d'enregistrement actif.
Il s'avère que chaque fois que vous écrivez une logique métier, vous devez vous rappeler comment l'essence du domaine est stockée.
Les méthodes ORM sont le niveau d'abstraction le plus bas. Ils ne supportent aucune limitation du domaine, ce qui signifie qu'ils donnent la possibilité de faire des erreurs. Ils cachent également à l'utilisateur quelles requêtes sont réellement effectuées dans la base de données, ce qui conduit à des requêtes inefficaces et longues. Le classique, lorsque les requêtes sont effectuées en boucles, au lieu d'une jointure ou d'un filtre.
Et quoi d'autre, mis à part la construction de requêtes (la possibilité de créer des requêtes), ORM nous donne-t-il? Ça ne fait rien. Possibilité de passer à une nouvelle base de données? Et qui, sain d'esprit et de mémoire ferme, a migré vers une nouvelle base de données et ORM l'a aidé dans ce domaine? Si vous ne le percevez pas comme une tentative de mapper le modèle de domaine (!) Dans la base de données, mais comme une simple bibliothèque qui vous permet d'effectuer des requêtes dans la base de données de manière pratique, alors tout se met en place.
Et même s'ils sont utilisés dans les noms des classes
Model, et dans les noms des fichiers models, ils ne deviennent pas des modèles. Ne vous trompez pas. Ceci est juste une description des étiquettes. Ils n'aideront à rien encapsuler.
Mais si tout va si mal, que faire? Les modèles d'architectures en couches viennent à la rescousse.
L'architecture en couches contre-attaque!
L'idée derrière les architectures en couches est simple: nous séparons la logique métier, la logique de stockage et la logique d'utilisation.
Il semble tout à fait logique de séparer le stockage du changement d'état. Ceux. créer une couche séparée qui peut recevoir et sauvegarder les données du stockage «abstrait».
Nous laissons toute la logique de stockage, par exemple, dans la classe de stockage
Repository. Et les contrôleurs (ou couche de service) ne l'utilisent que pour obtenir et enregistrer des entités. Ensuite, nous pouvons changer la logique de stockage et de réception à notre guise, et ce sera un seul endroit! Et lorsque nous écrivons du code client, nous pouvons être sûrs que nous n'avons pas oublié un autre endroit où sauvegarder ou à retirer, et nous ne répétons pas le même code plusieurs fois.
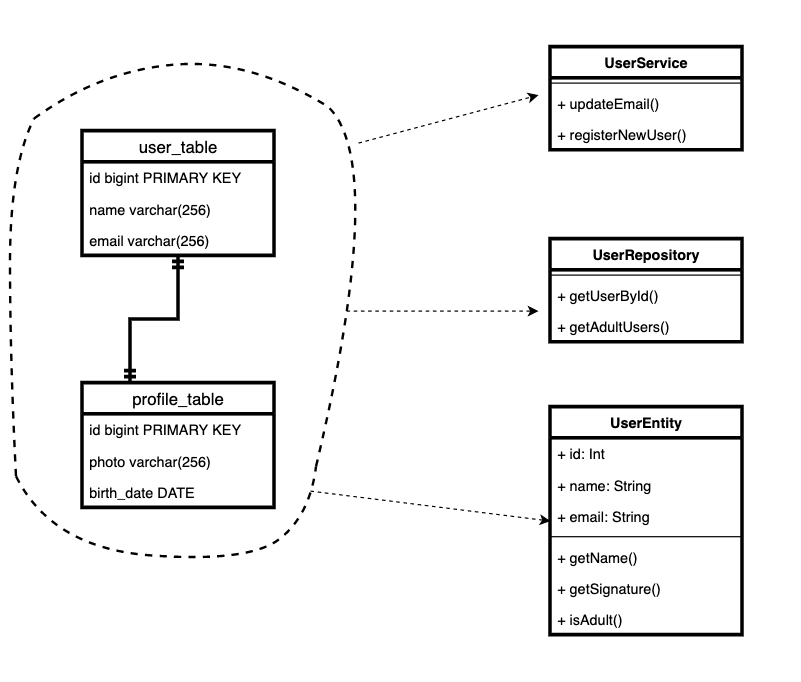
Peu nous importe que l'entité se compose d'enregistrements dans différentes tables ou microservices. Ou si des entités avec un comportement différent selon le type sont stockées dans une table.
Mais cette répartition des responsabilités n'est pas gratuite . Il faut comprendre que des couches supplémentaires d'abstraction sont créées afin d'éviter les «mauvais» changements de code. Évidemment, cela
Repositorycache le fait que l'objet est stocké dans la base de données SQL, il faut donc essayer de ne pas laisser le SQLisme sortir des limites Repository. Et toutes les demandes, même les plus simples et les plus évidentes, devront être glissées à travers la couche de stockage.
Par exemple, s'il devient nécessaire d'obtenir un bureau par nom et par département, vous devrez écrire comme ceci:
#
interface OfficeRepository: CrudRepository<OfficeEntity, Long> {
@Query("select o from OfficeEntity o " +
"where o.number = :office and o.branch.number = :branch")
fun getOffice(@Param("branch") branch: String,
@Param("office") office: String): OfficeEntity?
...
Et dans le cas d'Active Record, tout est beaucoup plus simple:
Office.objects.get(name=’Name’, branch=’Branch’)
Ce n'est pas si simple même si l'entité métier est en fait stockée de manière non triviale (dans plusieurs tables, dans différents services, etc.). Pour bien implémenter ce modèle (et correctement) - pour lequel ce modèle a été créé - vous devez le plus souvent utiliser des modèles tels que des agrégats, des unités de travail et des mappeurs de données.
Il est difficile de sélectionner correctement un agrégat, d'observer correctement toutes les restrictions qui lui sont imposées et d'effectuer correctement le mappage des données. Et seul un très bon développeur peut faire face à cette tâche. Celui qui, dans le cas d'Active Record, pouvait tout faire «bien».
Qu'arrive-t-il aux développeurs réguliers? Ceux qui connaissent tous les modèles et sont fermement convaincus que s'ils utilisent une architecture en couches, leur code devient automatiquement maintenable et bon, contrairement à Active Record. Et ils créent des référentiels CRUD pour chaque table. Et ils fonctionnent dans le concept d'
une plaque - un référentiel - une entité.
Pas:
un référentiel - un objet de domaine.

Ils croient aussi aveuglément que si un mot est utilisé dans une classeEntity, il reflète le modèle de domaine. Comme un motModeldans Active Record.
Le résultat est une couche de stockage plus complexe et moins flexible qui possède toutes les propriétés négatives des mappeurs d'enregistrement actif et de référentiel / données.
Mais l'architecture en couches ne s'arrête pas là. La couche de service est également généralement distinguée.
La mise en œuvre correcte d'une telle couche de service est également une tâche difficile. Et, par exemple, les développeurs inexpérimentés créent une couche de service, qui est un service - proxy vers les référentiels ou ORM (DAO). Ceux. les services sont écrits de manière à ne pas encapsuler la logique métier:
#
@Service
class AccountServiceImpl(val accountDaoService: AccountDaoService) : AccountService {
override fun saveAccount(account: Account) =
accountDaoService.saveAccount(convertClass(account, AccountEntity::class.java))
override fun deleteAccount(id: Long) =
accountDaoService.deleteAccount(id)
Et il existe une combinaison d'inconvénients à la fois de l'enregistrement actif et de la couche de service.
En conséquence, dans les frameworks Java en couches et le code écrit par de jeunes amateurs de modèles inexpérimentés, le nombre d'abstractions par unité de logique métier commence à dépasser toutes les limites raisonnables.
Il y a des couches, mais elles sont toutes triviales et ne sont que des couches pour appeler la couche suivante.
La présence de modèles POO dans le framework ne garantit pas leur application correcte et adéquate.
Il n'y a pas de solution miracle
Il est clair qu'il n'y a pas de solution miracle. Les solutions complexes sont destinées aux problèmes complexes, et les solutions simples concernent les problèmes simples.
Et il n'y a pas de bons et de mauvais modèles. Dans une situation, Active Record est une bonne architecture, dans d'autres, en couches. Et oui, pour la grande majorité des applications de petite et moyenne taille, Active Record fonctionne raisonnablement bien. Et pour la grande majorité des applications de petite et moyenne taille, l'architecture en couches (à la Spring) fonctionne moins bien. Et exactement le contraire pour les applications complexes et les services Web riches en logique.
Plus l'application ou le service est simple, moins vous avez besoin de couches d'abstraction.
Dans les microservices, où il n'y a pas beaucoup de logique métier, il est souvent inutile d'utiliser des architectures en couches. Les scripts transactionnels ordinaires - des scripts dans le contrôleur - peuvent être parfaitement adaptés à la tâche à accomplir.
En fait, un bon développeur diffère d'un mauvais en ce qu'il connaît non seulement les modèles, mais comprend également quand les appliquer.