
Je raconte par expérience personnelle ce qui a été utile où et quand. Sondage et thèse, pour qu'il soit clair quoi et où creuser plus loin - mais ici j'ai une expérience personnelle exclusivement subjective, peut-être que tout est complètement différent avec vous.
Pourquoi est-il important de connaître et de pouvoir gérer les langages de requête? À la base, dans la science des données, il y a plusieurs étapes de travail les plus importantes et la toute première et la plus importante (sans elle, rien ne fonctionnera, bien sûr!) Est l'acquisition ou la récupération de données. Le plus souvent, les données sous une forme ou une autre se trouvent quelque part et vous devez les «récupérer» à partir de là.
Les langages de requête vous permettent simplement d'extraire ces mêmes données! Et aujourd'hui, je vais vous parler de ces langages de requête qui m'ont été utiles et je vais vous dire où et comment exactement - pourquoi il est nécessaire d'étudier.
Au total, il y aura trois principaux blocs de types de requêtes aux données, que nous analyserons dans cet article:
- Les langages de requête "standard" sont ce qu'ils comprennent généralement lorsqu'ils parlent d'un langage de requête tel que l'algèbre relationnelle ou SQL.
- Langages de requête de script: par exemple, les astuces pandas de Python, numpy ou les scripts shell.
- Langages de requête pour les graphiques de connaissances et les bases de données de graphiques.
Tout ce qui est écrit ici n'est qu'une expérience personnelle, ce qui s'est avéré utile, avec une description des situations et "pourquoi c'était nécessaire" - tout le monde peut essayer comment des situations similaires peuvent vous rencontrer et essayer de s'y préparer à l'avance, après avoir traité ces langues avant de devoir pour postuler (de toute urgence) sur un projet ou même pour obtenir un projet là où ils sont nécessaires.
Langages de requête "standard"
Les langages de requête standard sont précisément dans le sens où nous pensons généralement à eux lorsque nous parlons de requêtes.
Algèbre relationnelle
Pourquoi l'algèbre relationnelle est-elle nécessaire aujourd'hui? Afin d'avoir une bonne idée de la raison pour laquelle les langages de requête sont organisés d'une certaine manière et de les utiliser délibérément, vous devez comprendre le noyau sous-jacent.
Qu'est-ce que l'algèbre relationnelle?
La définition formelle est la suivante: l'algèbre relationnelle est un système fermé d'opérations sur les relations dans un modèle de données relationnel. Plus humainement, il s'agit d'un système d'opérations sur les tables, de sorte que le résultat est aussi toujours une table.
Voir toutes les opérations relationnelles dans cet article de Habr - nous décrivons ici pourquoi vous devez savoir et où cela est utile.
Pourquoi?
Vous commencez à comprendre pour quoi les langages de requête sont généralement utilisés et quelles opérations se cachent derrière les expressions de langages de requête spécifiques - donne souvent une compréhension plus approfondie de ce qui et comment fonctionne dans les langages de requête.
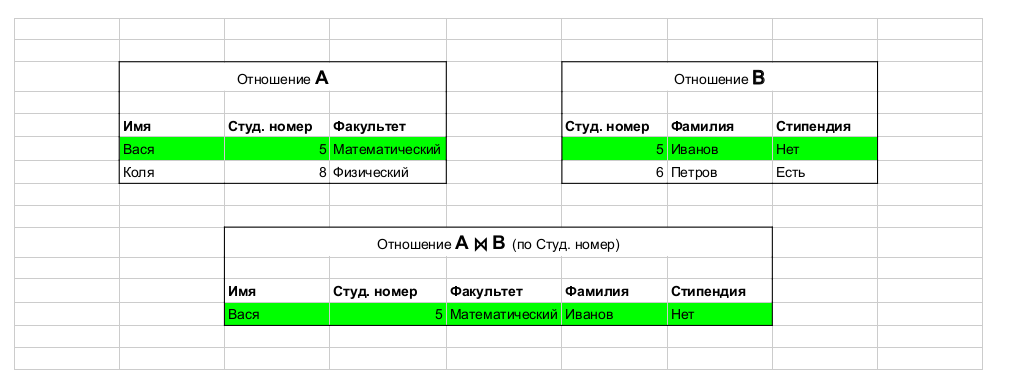
Tiré de cet article. Exemple d'opération: join, qui joint des tables.
Matériel d'étude:
Un bon cours d'introduction de Stanford . En général, il existe de nombreux matériaux sur l'algèbre relationnelle et la théorie - Coursera, Udacity. Il existe également une énorme quantité de documents en ligne, y compris de bons cours académiques . Mon conseil personnel est de bien comprendre l'algèbre relationnelle - c'est le fondement.
SQL

Tiré de cet article.
SQL est, en fait, une implémentation de l'algèbre relationnelle - avec une mise en garde importante, SQL est déclaratif! Autrement dit, en écrivant une requête dans le langage de l'algèbre relationnelle, vous dites en fait comment compter - mais avec SQL, vous spécifiez ce que vous voulez extraire, puis le SGBD génère déjà des expressions (efficaces) dans le langage de l'algèbre relationnelle (leur équivalence nous est connue sous le théorème de Codd ) ...
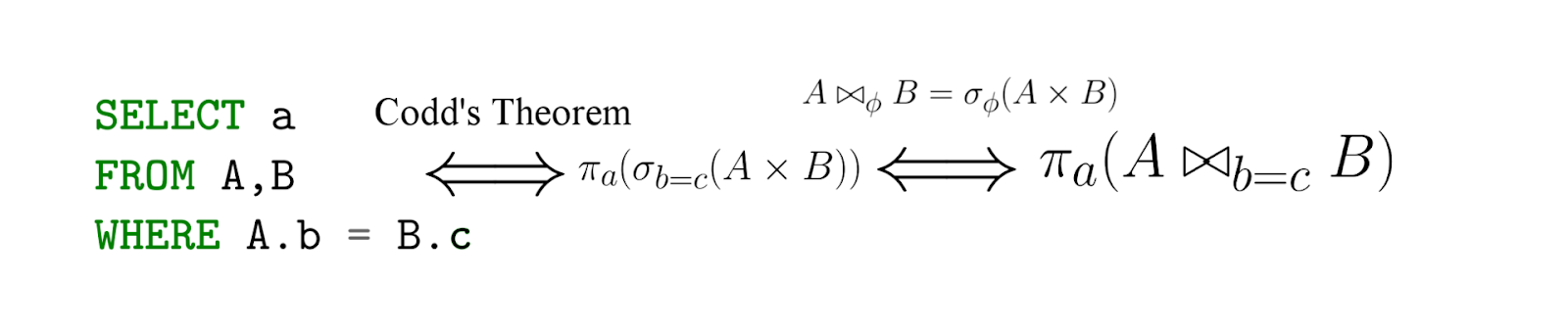
Tiré de cet article.
Pourquoi?
Les SGBD relationnels: Oracle, Postgres, SQL Server, etc. sont toujours pratiquement partout et il y a de fortes chances que vous ayez à interagir avec eux, ce qui signifie que vous devrez soit lire SQL (ce qui est très probable) soit y écrire ( également pas improbable).
Que lire et apprendre
À partir des mêmes liens ci-dessus (sur l'algèbre relationnelle), il existe une quantité incroyable de matériel, comme celui-ci .
Au fait, qu'est-ce que NoSQL?
"Il convient de souligner une fois de plus que le terme" NoSQL "a une origine complètement spontanée et n'a pas de définition généralement acceptée ou d'institution scientifique derrière lui." L' article correspondant sur Habré.
En fait, les gens ont réalisé qu'un modèle relationnel complet n'est pas nécessaire pour résoudre de nombreux problèmes, en particulier pour ceux où, par exemple, les performances sont fondamentales et certaines requêtes simples avec agrégation dominent - il est essentiel de lire rapidement les métriques et de les écrire dans la base de données, et la plupart des fonctionnalités sont relationnelles. s'est avéré non seulement inutile, mais aussi nuisible - pourquoi normaliser quelque chose si cela gâche la chose la plus importante pour nous (pour une tâche spécifique) - les performances?
De plus, il fallait souvent des schémas flexibles au lieu des schémas mathématiques fixes du modèle relationnel classique - et cela simplifie incroyablement le développement d'applications, lorsqu'il est essentiel de déployer le système et de commencer à travailler rapidement, en traitant les résultats - ou le schéma et les types de données stockées ne sont pas si importants.
Par exemple, nous créons un système expert et nous voulons stocker des informations sur un certain domaine avec des méta-informations - nous ne connaissons peut-être pas tous les champs et il est ridicule de stocker JSON pour chaque enregistrement - cela nous donne un environnement très flexible pour étendre le modèle de données et une itération rapide - donc, dans un tel le cas de NoSQL serait même préférable et lisible. Un exemple d'entrée (d'un de mes projets, où NoSQL était exactement là où il était nécessaire).
{"en_wikipedia_url":"https://en.wikipedia.org/wiki/Johnny_Cash",
"ru_wikipedia_url":"https://ru.wikipedia.org/wiki/?curid=301643",
"ru_wiki_pagecount":149616,
"entity":[42775," ","ru"],
"en_wiki_pagecount":2338861}
Vous pouvez en savoir plus sur NoSQL ici .
Quoi étudier?
Au contraire, vous devez juste être bon dans l'analyse de votre tâche, de ses propriétés et des systèmes NoSQL disponibles qui correspondent à cette description - et déjà étudier ce système.
Langages de requête de script
Au début, il semble que Python a à voir avec cela - c'est un langage de programmation, et pas du tout des requêtes.

- Pandas est un couteau suisse direct de la Data Science, une énorme quantité de transformation de données, d'agrégation, etc. y a lieu.
- Numpy est le calcul vectoriel, les matrices et l'algèbre linéaire.
- Scipy contient beaucoup de mathématiques dans ce package, en particulier les statistiques.
- Jupyter lab - de nombreuses analyses de données exploratoires s'intègrent bien dans les ordinateurs portables - c'est bien de pouvoir le faire.
- Demandes - réseautage.
- Les Pysparks sont très populaires auprès des ingénieurs de données, vous devrez probablement interagir avec ce ou et spark, simplement en raison de leur popularité.
- * Le sélénium est très utile pour collecter des données à partir de sites et de ressources, parfois il n'y a tout simplement pas d'autre moyen d'obtenir les données.
Mon meilleur conseil: apprenez Python!
Pandas
Prenons le code suivant comme exemple:
import pandas as pd
df = pd.read_csv(“data/dataset.csv”)
# Calculate and rename aggregations
all_together = (df[df[‘trip_type’] == “return”]
.groupby(['start_station_name','end_station_name'])\
.agg({'trip_duration_seconds': [np.size, np.mean, np.min, np.max]})\
.rename(columns={'size': 'num_trips',
'mean': 'avg_duration_seconds',
'amin': min_duration_seconds',
‘amax': 'max_duration_seconds'}))En fait, nous pouvons voir que le code s'inscrit dans le modèle SQL classique.
SELECT start_station_name, end_station_name, count(trip_duration_seconds) as size, …..
FROM dataset
WHERE trip_type = ‘return’
GROUPBY start_station_name, end_station_nameMais la partie importante est que ce code fait partie du script et du pipeline, en fait, nous intégrons des requêtes dans le pipeline Python. Dans cette situation, le langage de requête nous vient de bibliothèques telles que Pandas ou pySpark.
En général, dans pySpark, nous voyons un type similaire de transformation de données via le langage de requête dans l'esprit de:
df.filter(df.trip_type = “return”)\
.groupby(“day”)\
.agg({duration: 'mean'})\
.sort()Où et quoi lire
Ce n'est pas un problème de trouver des matériaux à étudier sur python lui-même . Il existe un grand nombre de tutoriels sur les pandas , pySpark et les cours sur Spark (ainsi que sur DS lui-même ) sur le net . En général, les matériaux ici sont excellents sur Google et si je devais choisir un package sur lequel me concentrer, ce serait des pandas, bien sûr. Il y a aussi beaucoup de matériaux sur le bundle DS + Python .
Shell comme langage de requête
Beaucoup de projets de traitement et d'analyse de données avec lesquels j'ai dû travailler sont en fait des scripts shell qui appellent du code en Python, en java et les commandes shell elles-mêmes. Par conséquent, en général, vous pouvez considérer les pipelines dans bash / zsh / etc, comme une requête de haut niveau (vous pouvez, bien sûr, pousser des boucles là-bas, mais ce n'est pas typique pour le code DS dans les langages shell), nous donnerons un exemple simple - j'avais besoin de mapper le Wikidata QID et un lien complet vers le wiki russe et anglais, pour cela j'ai écrit une requête simple à partir des commandes dans le bash et pour la sortie j'ai écrit un script simple en Python, que j'ai assemblé comme ceci:
pv “data/latest-all.json.gz” |
unpigz -c |
jq --stream $JQ_QUERY |
python3 scripts/post_process.py "output.csv"
Où
JQ_QUERY = 'select((.[0][1] == "sitelinks" and (.[0][2]=="enwiki" or .[0][2] =="ruwiki") and .[0][3] =="title") or .[0][1] == "id")' C'était, en fait, tout le pipeline qui a créé le mappage nécessaire, comme nous le voyons tout, cela fonctionnait en mode flux:
- pv filepath - donne une barre de progression basée sur la taille du fichier et transmet son contenu
- unpigz -c lit une partie de l'archive et donne jq
- jq avec la clé - stream a immédiatement produit le résultat et l'a passé au postprocesseur (comme avec le tout premier exemple) en Python
- en interne, le post-processeur est une simple machine à états qui a formaté la sortie
Au total, un pipeline complexe fonctionnant en mode flux sur du big data (0,5 To), sans ressources importantes et constitué d'un simple pipeline et de quelques outils.
Un autre conseil important: soyez bon et efficace dans le terminal et écrivez dans bash / zsh / etc.Où est-ce utile? Oui, presque partout - il y a, encore une fois, BEAUCOUP de matériel à étudier sur le net. En particulier, c'est mon article précédent.
Script R
Encore une fois, le lecteur peut s'exclamer - eh bien, c'est tout un langage de programmation! Et bien sûr, il aura raison. Cependant, je devais généralement traiter R dans un contexte tel qu'en fait, il était très similaire au langage de requête.
R est un cadre de calcul statistique et un langage de calcul et de visualisation statique (selon cela ).
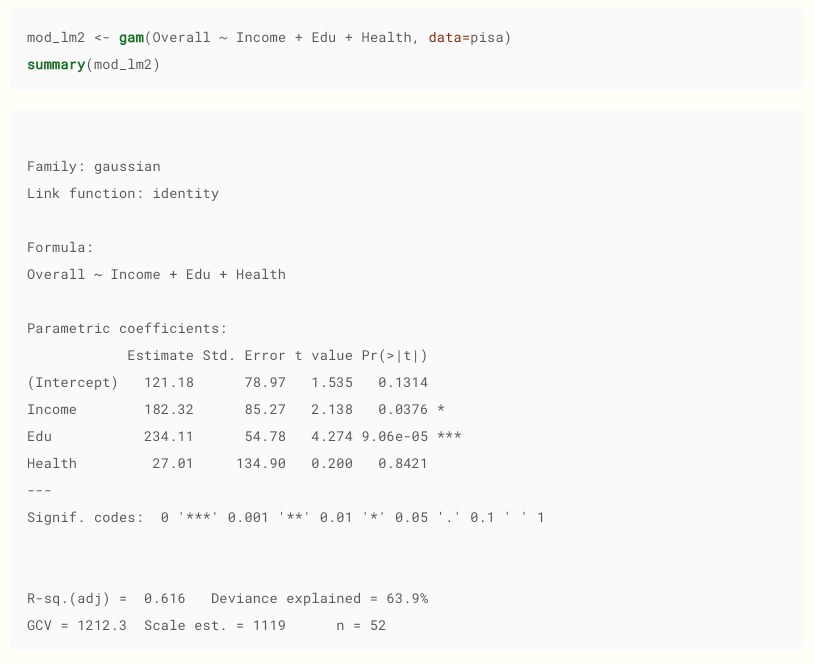
Pris d'ici . Au fait, je recommande, du bon matériel.
Pourquoi sortir avec un scientifique pour connaître R? Du moins, parce qu'il y a une énorme couche de non-informaticiens qui sont engagés dans l'analyse de données dans R. Je me suis rencontré aux endroits suivants:
- Secteur pharmaceutique.
- Biologistes.
- Secteur financier.
- Les gens avec une éducation purement mathématique, traitant des statistiques.
- Modèles statistiques et d'apprentissage automatique spécialisés (qui ne se trouvent souvent que dans la version amont en tant que package R).
Pourquoi est-ce en fait un langage de requête? Dans la forme dans laquelle il se trouve souvent, il s'agit en fait d'une demande de création d'un modèle, comprenant la lecture de données et la correction des paramètres de requête (modèle), ainsi que la visualisation de données dans des packages tels que ggplot2 - c'est aussi une forme d'écriture de requêtes.
Exemples de requêtes pour le rendu
ggplot(data = beav,
aes(x = id, y = temp,
group = activ, color = activ)) +
geom_line() +
geom_point() +
scale_color_manual(values = c("red", "blue"))En général, de nombreuses idées de R ont migré vers des packages python tels que pandas, numpy ou scipy, comme les dataframes et la vectorisation des données - par conséquent, en général, beaucoup de choses dans R vous sembleront familières et pratiques.
Il existe de nombreuses sources pour étudier, par exemple celle-ci .
Graphique de connaissances
Ici, j'ai une expérience un peu inhabituelle, car je dois encore assez souvent travailler avec des graphiques de connaissances et des langages de requête pour les graphiques. Par conséquent, passons brièvement en revue les bases, car cette partie est un peu plus exotique.
Dans les bases de données relationnelles classiques, nous avons un schéma fixe - ici, le schéma est flexible, chaque prédicat est en fait une «colonne» et même plus.
Imaginez que vous modélisiez une personne et que vous souhaitiez décrire des choses clés, par exemple, prenons une personne spécifique de Douglas Adams, nous prendrons cette description comme base.
www.wikidata.org/wiki/Q42
Si nous utilisions une base de données relationnelle, nous aurions à créer une ou plusieurs tables énormes avec un grand nombre de colonnes, dont la plupart seraient NULL ou remplies avec une valeur False par défaut, par exemple, peu probable beaucoup d'entre nous ont une entrée dans la bibliothèque nationale coréenne - bien sûr, nous pourrions les mettre dans des tableaux séparés, mais ce serait finalement une tentative de modéliser une logique flexible avec des prédicats en utilisant une relation relationnelle fixe.
Par conséquent, imaginez que toutes les données sont stockées sous forme de graphique ou d'expressions logiques binaires et unaires.
Où pouvez-vous même rencontrer cela? Tout d'abord, travailler avec des données wiki et avec toutes les bases de données graphiques ou données connectées.
Voici les principaux langages de requête que j'ai utilisés et avec lesquels j'ai travaillé.
SPARQL
Wiki:
SPARQL ( . SPARQL Protocol and RDF Query Language) — , RDF, . SPARQL W3C .
Mais en réalité c'est un langage de requêtes aux prédicats logiques unaires et binaires. Vous indiquez simplement conditionnellement ce qui est fixé dans une expression booléenne et ce qui ne l'est pas (très simpliste).
La base RDF (Resource Description Framework) elle-même, sur laquelle les requêtes SPARQL sont exécutées, est un triplet
object, predicate, subject- et la requête sélectionne les triplets nécessaires en fonction des contraintes spécifiées dans l'esprit de: trouver un X tel que p_55 (X, q_33) soit vrai - où, bien sûr, p_55 est ce -cette relation avec l'ID 55 et q_33 est un objet avec l'ID 33 (c'est toute l'histoire, en omettant à nouveau toutes sortes de détails).
Exemple de présentation des données:
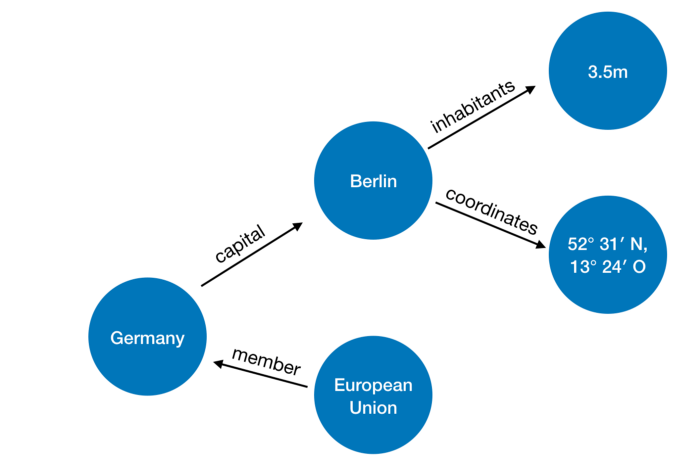
Des photos et un exemple avec les pays sont d'ici .
Exemple de requête de base

En fait, nous voulons trouver la valeur de la variable? Country, telle que pour le prédicat
member_of, il est vrai que member_of (? Country, q458) et q458 est l'ID de l'Union européenne.
Un exemple d'une vraie requête SPARQL dans le moteur python:
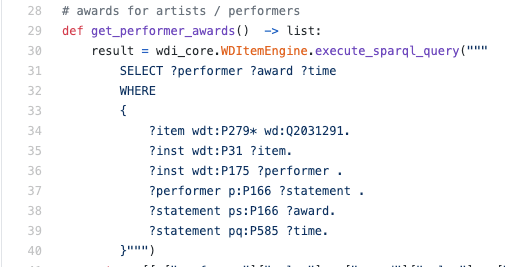
En règle générale, je devais lire SPARQL, pas écrire - dans une telle situation, ce sera très probablement une compétence utile pour comprendre la langue au moins à un niveau de base afin de comprendre exactement comment les données sont récupérées.
Il y a beaucoup de matériel d'étude en ligne, comme celui-ci et celui-ci . Je cherche moi-même généralement des constructions et des exemples spécifiques sur Google, et jusqu'à présent, j'en ai assez.
Langages de requête logique
Vous pouvez en savoir plus sur le sujet dans mon article ici . Ici, nous allons simplement expliquer brièvement pourquoi les langages logiques sont bien adaptés à l'écriture de requêtes. En fait, RDF est juste un ensemble d'instructions logiques de la forme p (X) et h (X, Y), et une requête logique ressemble à ceci:
output(X) :- country(X), member_of(X,“EU”).
Ici, nous parlons de créer une nouvelle sortie de prédicat / 1 (/ 1 signifie unaire), lorsque à condition qu'il soit vrai pour X ce pays (X) - c'est-à-dire que X est le pays et aussi membre_de (X, «UE»).
Autrement dit, nous avons à la fois les données et les règles dans ce cas sont généralement présentées de la même manière, ce qui rend très facile et efficace la modélisation des tâches.
Où vous êtes-vous rencontrés dans l'industrie: tout un grand projet avec une entreprise qui écrit des requêtes dans un tel langage, ainsi que sur le projet en cours au cœur du système - il semblerait que ce soit une chose plutôt exotique, mais parfois cela se produit.
Un exemple d'extrait de code dans des wikidata de traitement de langage logique:
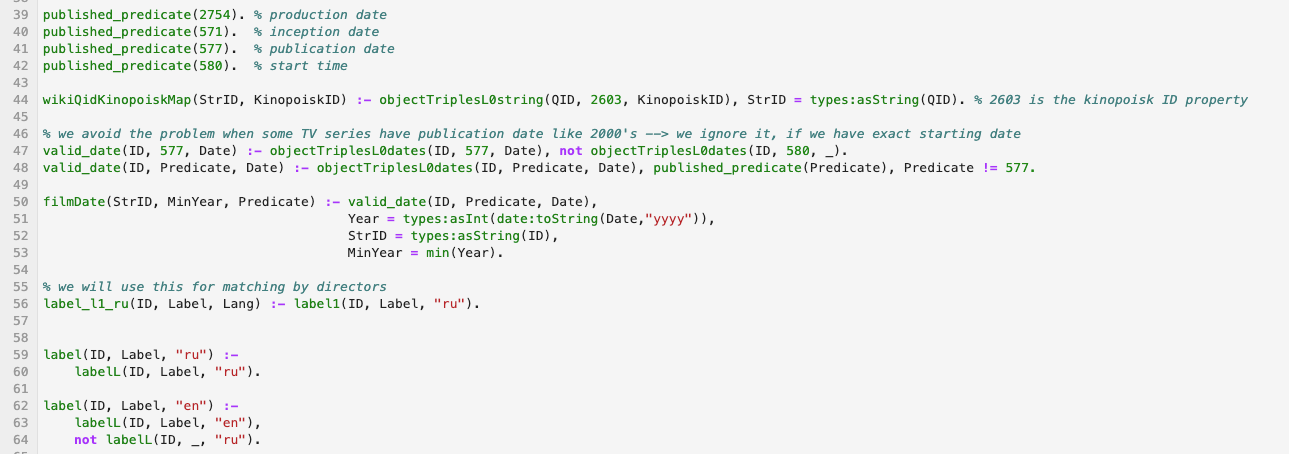
Matériel: Je vais donner ici quelques liens vers le langage de programmation logique moderne Answer Set Programming - je recommande de l'étudier:
- http://peace.eas.asu.edu/aaai12tutorial/asp-tutorial-aaai.pdf
- http://ceur-ws.org/Vol-1145/tutorial1.pdf
- https://www.youtube.com/watch?v=gVQ0bP8zyHw
- https://www.youtube.com/watch?v=kdcd7Je2glc
- https://potassco.org/book/
- http://potassco.sourceforge.net/teaching.html
- https://www.cs.uni-potsdam.de/~torsten/Potassco/Tutorials/fmcad12.pdf
