Il existe donc deux types de robots Web: légitimes et malveillants. Les plus légitimes incluent les moteurs de recherche, les lecteurs RSS. Des exemples de robots Web malveillants sont les scanners de vulnérabilité, les scrapers, les spammeurs, les robots d'attaque DDoS et les chevaux de Troie frauduleux par carte de paiement. Une fois le type de web bot identifié, diverses politiques peuvent lui être appliquées. Si le bot est légitime, vous pouvez baisser la priorité de ses requêtes au serveur ou baisser le niveau d'accès à certaines ressources. Si un bot est identifié comme malveillant, vous pouvez le bloquer ou l'envoyer au bac à sable pour une analyse plus approfondie. Il est important de détecter, d'analyser et de classer les robots Web, car ils peuvent nuire, par exemple, la fuite de données critiques pour l'entreprise. Et cela réduira également la charge sur le serveur et réduira le soi-disant bruit dans le trafic, car jusqu'à 66% du trafic des robots Web est exactementtrafic malveillant .
Approches existantes
Il existe différentes techniques pour détecter les robots Web dans le trafic réseau, allant de la limitation de la fréquence des demandes à un hôte, de la liste noire des adresses IP, de l'analyse de la valeur de l'en-tête HTTP User-Agent, de la prise d'empreintes d'un appareil - et se terminant par la mise en œuvre de CAPTCHA et l'analyse comportementale de l'activité du réseau à l'aide de apprentissage automatique.
Mais collecter des informations de réputation sur un site et maintenir les listes noires à jour à l'aide de diverses bases de connaissances et de renseignements sur les menaces est un processus coûteux et laborieux, et lors de l'utilisation de serveurs proxy, ce n'est pas conseillé.
L'analyse du champ User-Agent en première approximation peut sembler utile, mais rien n'empêche un web bot ou un utilisateur de changer les valeurs de ce champ en un champ valide, se déguisant en utilisateur régulier et utilisant un User-Agent valide pour le navigateur, ou en tant que bot légitime. Appelons de tels imitateurs de webbots. L'utilisation de diverses empreintes digitales de l'appareil (suivi du mouvement de la souris ou vérification de la capacité du client à rendre une page HTML) nous permet de mettre en évidence des robots Web plus difficiles à détecter qui imitent le comportement humain, par exemple, demander des pages supplémentaires (fichiers de style, icônes, etc.), analyser JavaScript. Cette approche est basée sur l'injection de code côté client, ce qui est souvent inacceptable, car une erreur lors de l'insertion d'un script supplémentaire peut interrompre l'application Web.
Il est à noter que les robots web peuvent également être détectés en ligne: la session sera évaluée en temps réel. Une description de cette formulation du problème peut être trouvée dans Cabri et al. [1], ainsi que dans les travaux de Zi Chu [2]. Une autre approche consiste à analyser uniquement après la fin de la session. La plus intéressante, évidemment, est la première option, qui vous permet de prendre des décisions plus rapidement.
L'approche proposée
Nous avons utilisé des techniques d'apprentissage automatique et la pile technologique ELK (Elasticsearch Logstash Kibana) pour identifier et classer les robots Web. Les objets de recherche étaient des sessions HTTP. La session est une séquence de requêtes provenant d'un nœud (valeur unique de l'adresse IP et du champ User-Agent dans la requête HTTP) dans un intervalle de temps fixe. Derek et Gohale utilisent un intervalle de 30 minutes pour définir les limites de la session [3]. Iliu et al. Soutiennent que cette approche ne garantit pas l'unicité de session réelle, mais elle est toujours acceptable. Étant donné que le champ User-Agent peut être modifié, plus de sessions peuvent apparaître qu'il n'y en a réellement. Par conséquent, Nikiforakis et ses co-auteurs proposent plus de réglages en fonction de la prise en charge d'ActiveX, de l'activation de Flash, de la résolution de l'écran, de la version du système d'exploitation.
Nous considérerons une erreur acceptable dans la formation d'une session séparée si le champ User-Agent change dynamiquement. Et pour identifier les sessions de bot, nous allons créer un modèle de classification binaire clair et utiliser:
- activité réseau automatique générée par un bot Web (tag bot);
- activité de réseau générée par l'homme (tag human).
Pour classer les robots Web par type d'activité, construisons un modèle multi-classes à partir du tableau ci-dessous.
| Nom | La description | Étiquette | Exemples de |
|---|---|---|---|
| Crawlers | Bots Web
collectant des pages Web |
robot d'exploration | SemrushBot,
360Spider, Heritrix |
| Réseaux sociaux | Bots Web de divers
réseaux sociaux |
réseau social | LinkedInBot,
WhatsApp Bot, Facebook bot |
| Lecteurs RSS | -,
RSS |
rss | Feedfetcher,
Feed Reader, SimplePie |
| -
|
search_engines | Googlebot, BingBot,
YandexBot |
|
| -,
|
libs_tools | Curl, Wget,
python-requests, scrapy |
|
| - | bots | ||
| ,
User-Agent |
unknown |
Nous allons également résoudre le problème de la formation en ligne du modèle.
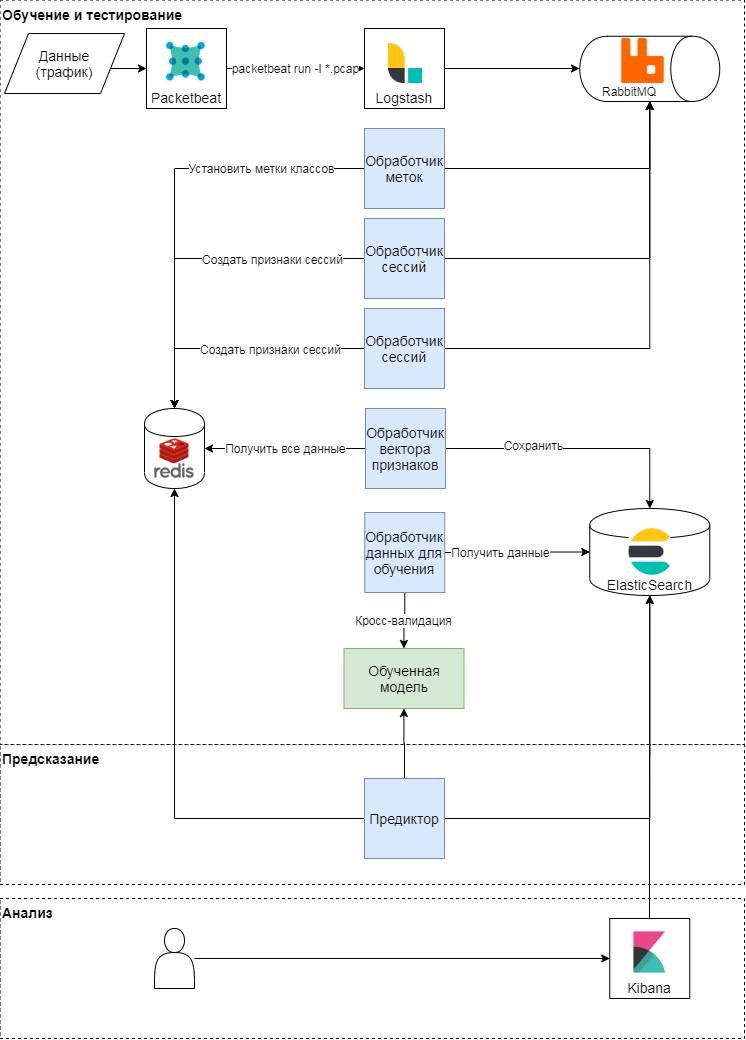
Schéma conceptuel de l'approche proposée
Cette approche comporte trois étapes: formation et tests, prédiction, analyse des résultats. Examinons les deux premiers plus en détail. Conceptuellement, l'approche suit le modèle classique d'apprentissage et d'application de modèles d'apprentissage automatique. Premièrement, les mesures de qualité et les attributs de classification sont déterminés. Après cela, un vecteur de caractéristiques est formé et une série d'expériences (diverses vérifications croisées) sont effectuées pour valider le modèle et sélectionner des hyperparamètres. À la dernière étape, le meilleur modèle est sélectionné et la qualité du modèle est vérifiée sur un échantillon différé.
Formation et tests de modèles
Le module packetbeat est utilisé pour analyser le trafic. Les requêtes HTTP brutes sont envoyées à logstash, où les tâches sont générées à l'aide d'un script Ruby en termes Celery. Chacun d'eux fonctionne avec un identifiant de session, une heure de requête, un corps de requête et des en-têtes. Identifiant de session (clé) - la valeur de la fonction de hachage de la concaténation de l'adresse IP et de l'agent utilisateur. À ce stade, deux types de tâches sont créés:
- sur la formation d'un vecteur de fonctionnalités pour la session,
- en étiquetant la classe en fonction du texte de la requête et de l'agent utilisateur.
Ces tâches sont envoyées à une file d'attente, où les gestionnaires de messages les exécutent. Ainsi, le gestionnaire de l' étiqueteuse effectue la tâche d'étiqueter la classe en utilisant un jugement d'expert et des données ouvertes du service de navigation en fonction de l'agent utilisateur utilisé; le résultat est écrit dans le stockage clé-valeur. Le processeur de session génère un vecteur de caractéristiques (voir le tableau ci-dessous) et écrit le résultat pour chaque clé dans le stockage clé-valeur, et définit également la durée de vie de la clé (TTL).
| Signe | La description |
|---|---|
| len | Nombre de demandes par session |
| len_pages | Nombre de requêtes par session dans les pages
(l'URI se termine par .htm, .html, .php, .asp, .aspx, .jsp) |
| len_static_request | Nombre de requêtes par session dans
les pages statiques |
| len_sec | Durée de la session en secondes |
| len_unique_uri | Nombre de requêtes par session
contenant un URI unique |
| headers_cnt | Nombre d'en-têtes par session |
| has_cookie | Y a-t-il un en-tête de cookie |
| has_referer | Y a-t-il un en-tête Referer |
| mean_time_page | Temps moyen par page par session |
| mean_time_request | Temps moyen par demande par session |
| mean_headers | Nombre moyen d'en-têtes par session |
C'est ainsi que la matrice de caractéristiques est formée et que l'étiquette de classe cible pour chaque session est définie. Sur la base de cette matrice, un entraînement périodique des modèles et une sélection ultérieure d'hyperparamètres ont lieu. Pour la formation, nous avons utilisé: la régression logistique, les machines vectorielles de support, les arbres de décision, le boosting de gradient sur les arbres de décision et un algorithme de forêt aléatoire. Les résultats les plus pertinents ont été obtenus à l'aide de l'algorithme de forêt aléatoire.
Prédiction
Lors de l'analyse du trafic, le vecteur des attributs de session est mis à jour dans le stockage clé-valeur: lorsqu'une nouvelle requête apparaît dans la session, les attributs la décrivant sont recalculés. Par exemple, le nombre moyen d'en-têtes dans une session (mean_headers) est calculé chaque fois qu'une nouvelle demande est ajoutée à la session. Le prédicteur envoie le vecteur de fonction de session au modèle et écrit la réponse du modèle dans Elasticsearch pour analyse.
Expérience
Nous avons testé notre solution sur le trafic du portail SecurityLab.ru . Volume de données - plus de 15 Go, plus de 130 heures. Le nombre de sessions est supérieur à 10 000. Du fait que le modèle proposé utilise des fonctionnalités statistiques, les sessions contenant moins de 10 requêtes n'ont pas été impliquées dans la formation et les tests. Nous avons utilisé les mesures de qualité classiques comme mesures de qualité - précision, exhaustivité et mesure F pour chaque classe.
Test du modèle de détection des robots Web
Nous allons construire et évaluer un modèle de classification binaire, c'est-à-dire que nous allons détecter les bots, puis nous les classerons par type d'activité. Sur la base des résultats d'une validation croisée stratifiée quintuple (c'est exactement ce qui est requis pour les données considérées, car il y a un fort déséquilibre de classe), nous pouvons dire que le modèle construit est assez bon (précision et exhaustivité - plus de 98%) est capable de séparer les classes d'utilisateurs humains et de bots.
| Précision moyenne | Plénitude moyenne | Mesure F moyenne | |
|---|---|---|---|
| bot | 0,86 | 0,90 | 0,88 |
| Humain | 0,98 | 0,97 | 0,97 |
Les résultats du test du modèle sur un échantillon différé sont présentés dans le tableau ci-dessous.
| Précision | Complétude | Mesure F | Nombre d'
exemples |
|
|---|---|---|---|---|
| bot | 0,88 | 0,90 | 0,89 | 1816 |
| Humain | 0,98 | 0,98 | 0,98 | 9071 |
Les valeurs des métriques de qualité sur l'échantillon différé coïncident approximativement avec les valeurs des métriques de qualité lors de la validation du modèle, ce qui signifie que le modèle sur ces données peut généraliser les connaissances acquises lors de la formation.
Considérons les erreurs du premier type. Si ces données sont balisées de manière experte, la matrice d'erreur changera considérablement. Cela signifie que certaines erreurs ont été commises lors du balisage des données pour le modèle, mais que le modèle était toujours capable de reconnaître correctement ces sessions.
| Précision | Complétude | Mesure F | Nombre d'
exemples |
|
|---|---|---|---|---|
| bot | 0,93 | 0,92 | 0,93 | 2446 |
| Humain | 0,98 | 0,98 | 0,98 | 8441 |
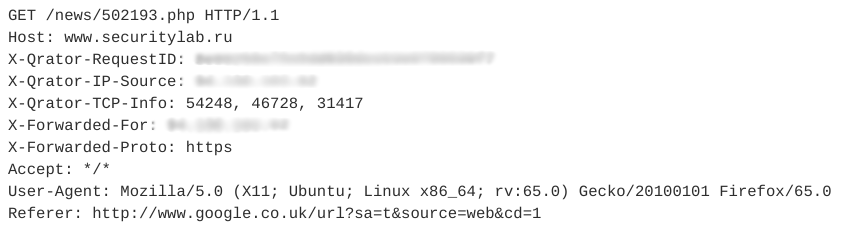
Regardons un exemple d'imitateurs de session. Il contient 12 requêtes similaires. L'une des demandes est illustrée dans la figure ci-dessous.
Toutes les demandes ultérieures de cette session ont la même structure et ne diffèrent que par l'URI.
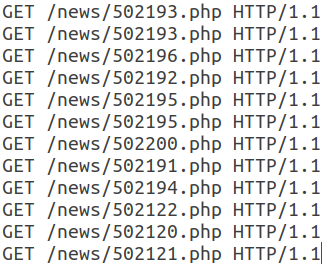
Notez que ce webbot utilise un User-Agent valide, ajoute un champ Referer, généralement utilisé de manière non automatique, et le nombre d'en-têtes dans une session est petit. De plus, les caractéristiques temporelles des requêtes - temps de session, temps moyen par requête - permettent de dire que cette activité est automatique et appartient à la classe des lecteurs RSS. Dans ce cas, le bot lui-même est déguisé en utilisateur ordinaire.
Test du modèle de classification des robots Web
Pour classer les robots Web par type d'activité, nous utiliserons les mêmes données et le même algorithme que dans l'expérience précédente. Les résultats du test du modèle sur un échantillon différé sont présentés dans le tableau ci-dessous.
| Précision | Complétude | Mesure F | Nombre d'
exemples |
|
|---|---|---|---|---|
| bot | 0,82 | 0,81 | 0,82 | 194 |
| robot d'exploration | 0,87 | 0,72 | 0,79 | 65 |
| libs_tools | 0,27 | 0,17 | 0,21 | dix-huit |
| rss | 0,95 | 0,97 | 0,96 | 1823 |
| moteurs de recherche | 0,84 | 0,76 | 0,80 | 228 |
| réseau social | 0,80 | 0,79 | 0,84 | 73 |
| inconnue | 0,65 | 0,62 | 0,64 | 45 |
La qualité de la catégorie libs_tools est faible, mais le volume insuffisant d'exemples pour l'évaluation ne nous permet pas de parler de l'exactitude des résultats. Une deuxième série d'expériences devrait être menée pour classer les robots Web sur plus de données. Nous pouvons dire avec certitude que le modèle actuel avec une précision et une exhaustivité assez élevées est capable de séparer les classes de lecteurs RSS, de moteurs de recherche et de robots en général.
Selon ces expérimentations sur les données considérées, plus de 22% des sessions (avec un volume total de plus de 15 Go) sont créées automatiquement, et parmi elles 87% sont liées à l'activité de bots généraux, de bots inconnus, de lecteurs RSS, de robots Web utilisant diverses bibliothèques et utilitaires. ... Ainsi, si vous filtrez le trafic réseau des robots Web par type d'activité, l'approche proposée réduira la charge sur les ressources serveur utilisées d'au moins 9 à 10%.
Test du modèle de classification des robots Web en ligne
L'essence de cette expérience est la suivante: en temps réel, après analyse du trafic, des entités sont identifiées et des vecteurs de caractéristiques sont formés pour chaque session. Périodiquement, chaque session est envoyée au modèle pour la prédiction, dont les résultats sont enregistrés.
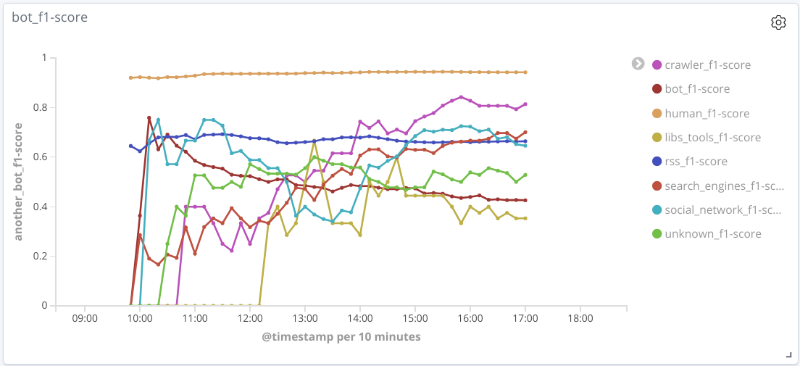
Mesure F du modèle dans le temps pour chaque classe Les
graphiques ci-dessous illustrent l'évolution de la valeur des métriques de qualité dans le temps pour les classes les plus intéressantes. La taille des points sur eux est liée au nombre de sessions dans l'échantillon à un moment donné.

Précision, exhaustivité, mesure F pour la classe des moteurs de recherche

Précision, exhaustivité, mesure F pour la classe outils libs
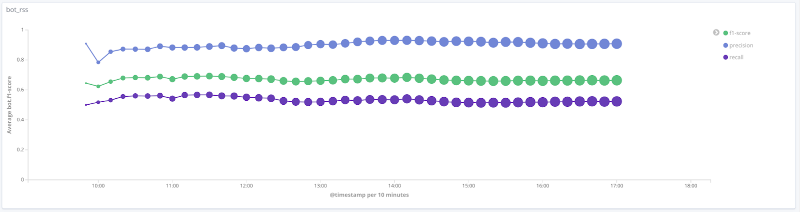
Précision, exhaustivité, mesure F pour la classe rss

Précision, exhaustivité, mesure F pour la classe crawler

Précision, exhaustivité, mesure F pour classe humaine
Pour un certain nombre de classes (humain, rss, moteurs de recherche) sur les données considérées, la qualité du modèle est acceptable (précision et exhaustivité supérieures à 80%). Pour la classe crawler, avec une augmentation du nombre de sessions et un changement qualitatif du vecteur de caractéristiques pour cet échantillon, la qualité du travail du modèle augmente: l'exhaustivité est passée de 33% à 80%. Il est impossible de tirer des conclusions raisonnables pour la classe libs_tools, car le nombre d'exemples pour cette classe est petit (moins de 50); par conséquent, les résultats négatifs (mauvaise qualité) ne peuvent être confirmés.
Principaux résultats et développement ultérieur
Nous avons décrit une approche pour détecter et classer les robots Web à l'aide d'algorithmes d'apprentissage automatique et en utilisant des fonctionnalités statistiques. Sur les données considérées, la précision et l'exhaustivité moyennes de la solution proposée pour la classification binaire sont supérieures à 95%, ce qui indique que l'approche est prometteuse. Pour certaines classes de robots Web, la précision et l'exhaustivité moyennes sont d'environ 80%.
La validation des modèles construits nécessite une réelle évaluation de la session. Comme indiqué précédemment, les performances du modèle sont considérablement améliorées lorsque le balisage correct est disponible pour la classe cible. Malheureusement, il est maintenant difficile de créer automatiquement un tel balisage et vous devez recourir au balisage expert, ce qui complique la construction de modèles d'apprentissage automatique, mais vous permet de trouver des modèles cachés dans les données.
Pour approfondir le problème de la classification et de la détection des robots Web, il convient de:
- attribuer des classes supplémentaires de robots et se recycler, tester le modèle;
- ajoutez des signes supplémentaires pour classer les robots Web. Par exemple, l'ajout d'un attribut robots.txt, qui est binaire et est responsable de la présence ou de l'absence d'accès à une page robots.txt, vous permet d'augmenter le score F moyen pour une classe de robots Web de 3% sans aggraver les autres métriques de qualité pour d'autres classes;
- faire un balisage plus correct pour la classe cible, en tenant compte des méta-fonctionnalités supplémentaires et du jugement d'expert.
Auteur : Nikolay Lyfenko, spécialiste principal, Advanced Technologies Group, Positive Technologies
Sources
[1] Cabri A. et al. Online Web Bot Detection Using a Sequential Classification Approach. 2018 IEEE 20th International Conference on High Performance Computing and Communications.
[2] Chu Z., Gianvecchio S., Wang H. (2018) Bot or Human? A Behavior-Based Online Bot Detection System. In: Samarati P., Ray I., Ray I. (eds) From Database to Cyber Security. Lecture Notes in Computer Science, vol. 11170. Springer, Cham.
[3] Derek D., Gokhale S. An integrated method for real time and offline web robot detection. Expert Systems 33. 2016.
[4] Iliou Ch., et al. Towards a framework for detecting advanced Web bots. Proceedings of the 14th International Conference on Availability, Reliability and Security. 2019.
[5] Nikiforakis N., Kapravelos A., Joosen W., Kruegel C., Piessens F. and Vigna G. Cookieless Monster: Exploring the Ecosystem of Web-Based Device Fingerprinting. 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, 2013, pp. 541—555.
[2] Chu Z., Gianvecchio S., Wang H. (2018) Bot or Human? A Behavior-Based Online Bot Detection System. In: Samarati P., Ray I., Ray I. (eds) From Database to Cyber Security. Lecture Notes in Computer Science, vol. 11170. Springer, Cham.
[3] Derek D., Gokhale S. An integrated method for real time and offline web robot detection. Expert Systems 33. 2016.
[4] Iliou Ch., et al. Towards a framework for detecting advanced Web bots. Proceedings of the 14th International Conference on Availability, Reliability and Security. 2019.
[5] Nikiforakis N., Kapravelos A., Joosen W., Kruegel C., Piessens F. and Vigna G. Cookieless Monster: Exploring the Ecosystem of Web-Based Device Fingerprinting. 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, 2013, pp. 541—555.