Les Data Scientists découvrent ce qui intéresse les gens et à quoi ils dépensent leur argent
Au cours de leurs recherches sur différents publics, les Data Scientists observent des faits à la fois naturels et surprenants qui caractérisent vivement la société qui nous entoure. Dans cet article, je parlerai de ces curiosités et cas inhabituels que j'ai remarqués lors de l'exécution de tâches liées à l'analyse d'audit, à la recherche des intérêts des internautes et au comportement d'achat de divers groupes sociaux.
Quelles caractéristiques sociologiques ont été identifiées grâce à l'utilisation de modèles d'apprentissage automatique? Que savons-nous des clients?

Profil client de son chèque? Facile!
Je travaille en tant qu'analyste de données chez CleverDATA et suis généralement confronté aux tâches suivantes: classification des données brutes, analyse d'audit et construction de modèles de ressemblance (LaL) lorsque le client a son propre public et qu'il souhaite en trouver un similaire. Il est très demandé pour diverses campagnes de publicité en ligne.
Nous avons 1DMC DATA Exchange où les membres peuvent enrichir et monétiser leurs données. Il contient des données dépersonnalisées de deux types, agrégées dans les attributs de notre taxonomie - achats en ligne et parcours de clics, c'est-à-dire la séquence de visites de pages que nous avons pu suivre. Le format de données répond à la norme européenne GDPR pour la protection des données personnelles.
Les attributs de notre taxonomie sont les faits de propriété d'une chose ou la présence d'un certain intérêt dans une personne. Ce sont des informations binaires - que ce soit là ou pas.
Voici quelques exemples de nos attributs de taxonomie:

L'une des tâches les plus importantes est l'agrégation des données brutes des fournisseurs en attributs de taxonomie, c'est-à-dire la tâche de classification.
Je dois tirer des conclusions sur les achats des gens concernant leur style de vie et s'ils ont certaines choses (sous condition, un contrôle pour une lampe Street Rod de marque indique probablement que l'acheteur est le propriétaire d'une moto Harley-Davidson) ou identifier un intérêt potentiel pour les achats auprès via les pages Internet qu'ils visitent. Ces informations seront ensuite utilisées pour des publicités ciblées.

Au cours de mon travail, les chaînes suivantes apparaissent:
- vérifier - mes modèles d'IA - profil d'acheteur;
- flux de clics - mes modèles d'IA - profil de visiteur du site.
L'outil que nous utilisons dans CleverDATA construira automatiquement un classificateur binaire pour n'importe quel attribut de notre taxonomie. À partir du nom même de l'attribut taxonomie (le propriétaire de l'attribut moto chopper), nous nous retrouvons avec un classificateur binaire déjà évalué automatiquement (si le modèle est bon ou l'analyse doit être améliorée), qui est capable de déterminer la présence ou l'absence d'un tel élément chez une personne par chèque. Vous pouvez en savoir plus à ce sujet dans notre article sur Habré .

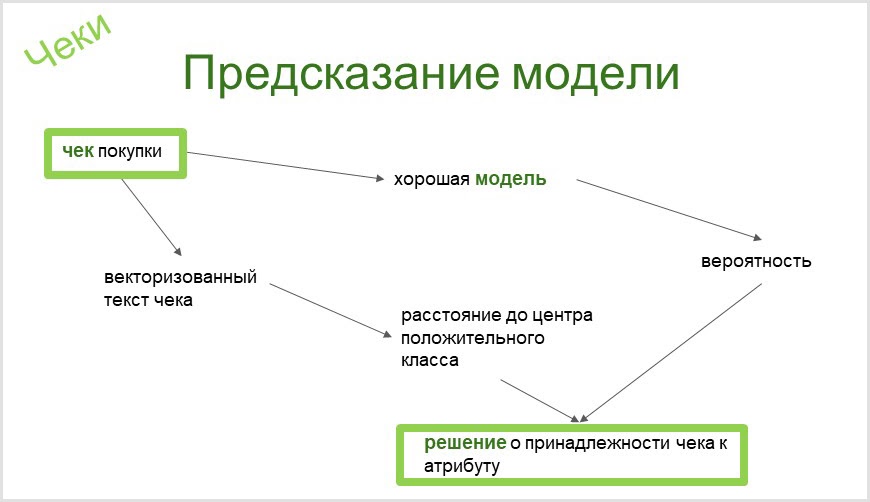
Lors de la classification des chèques, vous avez besoin d'un outil qui vous permettra de séparer les chèques dont les mots sont similaires de ceux qui ont un sens similaire. Donc, j'ai en quelque sorte construit un modèle pour capter l'intérêt pour les cours de recyclage professionnel. Et elle a identifié le chèque pour l'achat du livre pour enfants de Paolo Cossi "Un cours de leçons de magie pour un chat ordinaire" comme un intérêt pour le sujet. C'est, bien sûr, une drôle d'erreur. Au fait, j'ai appris l'existence du livre grâce à ce chèque.

Pour éviter de telles curiosités, nous avons utilisé des modèles de langage pour évaluer les classificateurs binaires résultants et avons coupé les exemples qui sont similaires dans les mots, mais pas dans le sens.
De temps en temps, je dois regarder les reçus avec mes yeux afin de trouver de fausses correspondances et ensuite automatiser la recherche de telles connexions construites par erreur. Il peut être utile d'aller au fond des choses, car peut-être qu'un seul cas incompréhensible me permettra d'améliorer l'ensemble du processus.
Au cours de toute ma pratique, j'ai accumulé toute une série de vérifications d'énigmes que je pourrais non seulement classer, mais même déchiffrer ce que l'acheteur a acheté exactement. Je partage régulièrement ces cas amusants avec des collègues et j'ai même lancé la rubrique "Blagues AI".
L'indice le plus courant est l'indication dans la vérification du titre du livre sans le nom du produit. C'est exactement ce que nous voyons dans le cas de la "magie pour un chat ordinaire". Et quels achats sont enregistrés dans le chèque "Clôture Novosibirsk 1029 roubles." et "Contrat-boîte 5000 roubles." Je ne comprends toujours pas. J'accepte vos versions dans les commentaires de cet article.
Ensuite, passons à la classification du flux de clics.
Profil du client par ses déplacements sur le site
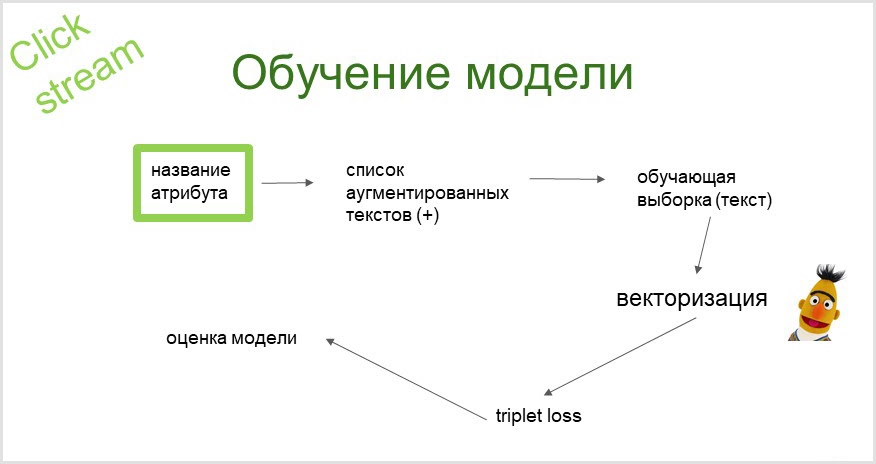
Le système de classification des clics a été introduit par nous en 2019, riche en avancées dans le domaine de la PNL (traitement du langage naturel). L'une des inventions les plus connues et les plus réussies dans ce domaine est le réseau BERT ( Bidirectional Encoder Representations from Transformers ). Il y aura donc un peu de bertologie à venir.

À partir du nom de l'attribut, en utilisant un modèle de langage probabiliste, nous obtenons une liste augmentée (étendue avec des synonymes) de requêtes que nous explorons (envoyons à un moteur de recherche et collectons les résultats de la recherche), d'où notre échantillon de formation est obtenu. Vectorisons-le en utilisant le modèle de langage BERT pré-entraîné. En utilisant les plongements obtenus (vecteurs), nous entraînons le classificateur (avec la fonction de perte de triplet).
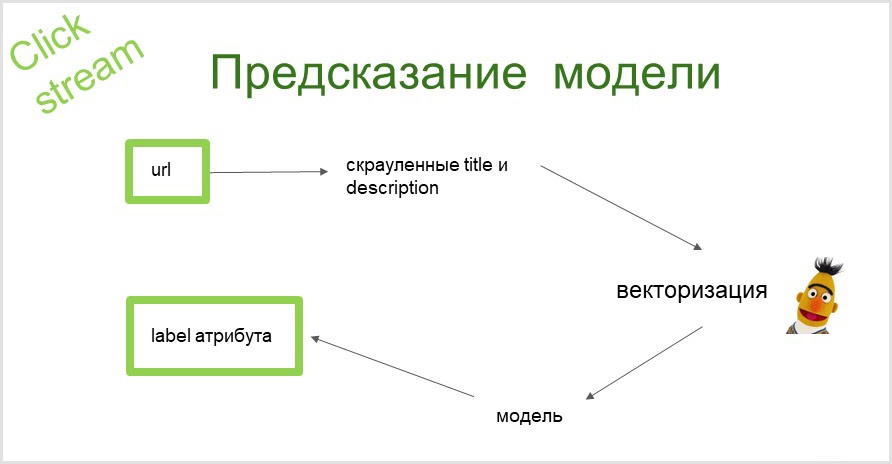
Comment fonctionne la prédiction?
Nous prenons l'url de la page, collectons des informations textuelles (titre et description de la page). Avec l'aide de BERT, nous obtenons une représentation vectorielle de ces textes. Ensuite, ces vecteurs sont introduits dans le modèle et en sortie, nous obtenons un attribut auquel nous pouvons renvoyer la page.
En général, ce système est très réussi, tous les cas drôles que j'ai rencontrés sont plutôt des exceptions que la règle. Mais j'essaie de leur prêter une grande attention, car une petite erreur peut entraîner de grandes conséquences désagréables, car une énorme quantité de données transite par le système.
Les données en ligne que j'ai recherchées ont montré que les gens lisent davantage sur Internet. Il s'est avéré que c'était l'un des sujets les plus populaires - l'astrologie, la bonne aventure, etc.

Ces pages spécifiques (URL et non domaines) ont été visitées par plus de 5 000 000 personnes (identifiants uniques) par jour. J'ai été particulièrement frappé par le site dédié à l'astrologie féline et révélant le lien entre le caractère de l'animal et son signe du zodiaque.

Tout le monde connaît les mots vides et généralement ils connectent des dictionnaires ou filtrent par fréquences sans entrer dans les détails des textes. Au début, j'ai également connecté mes dictionnaires. Le résultat n'a pas été agréable: le site de recettes sans utilisation de produits de boulangerie a été classé comme un attribut d'intérêt en boulangerie (pâtisserie maison). Et cela est dû au fait que toutes les particules négatives étaient présentes dans mon dictionnaire de mots vides.

En utilisant mon exemple, j'exhorte mes collègues à lire attentivement les dictionnaires avec lesquels vous filtrez vos données.
Un autre problème courant est que les gens utilisent souvent un langage sarcastique, ce qui, pendant la phase d'exploration, conduit à des phrases amusantes dans le titre et la description des pages liées à certaines requêtes sur Internet. Par exemple, le modèle peut lier les pâtés et l'intérêt pour un régime végétarien. Il me semble que cela peut s'expliquer par l'abondance de commentaires sur les articles sur le thème du végétarisme dans l'esprit "Comment vivez-vous sans pasties?"

Et maintenant une minute d'humour noir dans notre section "blagues sur l'IA": le modèle a lié la discussion sur la légalisation de l'euthanasie avec un intérêt pour l'achat d'une maison, et le rappeur Timati - avec un cirque. J'ai dû ramper dans les données et re-marquer manuellement la classe.
Il y a des configurations que nous ne pouvons pas contrôler, elles dépendent de la société dans laquelle nous vivons. Et puis le crime se mêle aux comédies et aux relations familiales.

Et il y a aussi des cas controversés où vous ne savez même pas s'il vaut la peine de gronder le modèle et de reconcevoir quelque chose, de lutter contre les erreurs ou de tout laisser tel quel.
Il est possible que la réception de colis comporte un risque commercial.
Tout peut être trouvé sur le babillard.

Rechercher une audience similaire
Le prochain bloc de tâches que je dois, en tant qu'analyste, à résoudre est Audiene Research / Look-alike model. En règle générale, le client veut de nouvelles connaissances sur le public, ce qui devrait l'aider à établir une communication avec elle. Mais même si sa demande n'est pas clairement formulée, nous essayons toujours de l'aider, et dans la plupart des cas, nous réussissons.
Ici, vous avez le choix de vous concentrer sur la recherche d'audience, c'est-à-dire sur des insights internes (analyse intelligente de l'audience), ou sur un modèle similaire, qui vous permettra ensuite d'accélérer l'audience de notre échange et de trouver des clients potentiels en fonction des données internes du client sur le public cible. Une audience est comprise comme un ensemble d'identifiants codés (numéros de téléphone, adresses e-mail ou identifiant en ligne). Je vous rappelle que nous ne travaillons pas avec des données sous une forme ouverte, nous respectons toutes les règles de la loi.
Ainsi, nous pouvons croiser de nombreux identifiants encodés avec l'échange et voir le comportement d'achat ou leur flux de clics. Nous faisons du clustering pour tout public cible et toute tâche. Après que le modèle ait regroupé les gens en fonction de leur comportement d'achat, j'ai en quelque sorte vu un groupe composé uniquement de personnes qui parient sur le sport et n'achètent plus rien en ligne. Cependant, il est possible qu'ils aient une sorte de comptes séparés à des fins de création de livres.
Voici une capture d'écran de ce cluster.

Cas "Bonne maternité"
Pour une campagne publicitaire pour une marque de couches bien connue, il était nécessaire de mener une étude d'audience et de trouver des femmes au troisième trimestre de la grossesse - la cliente a suggéré que c'était à partir du troisième trimestre que le produit devrait être annoncé afin que la plupart du public l'achète.
Au début de l'analyse, la description des circonstances de la vie des femmes enceintes ressemblait à un tableau idyllique: une jeune famille avec des animaux domestiques, à la veille de la naissance d'un enfant, équipe le logement.

Les femmes de différents clusters possèdent des gadgets de différentes marques, préfèrent différentes marques de produits d'hygiène et, en général, tout va bien. Voir par vous-même.
25,5% des ID
Les acheteurs de Huggies Elite Soft sont trois fois moins susceptibles d'acheter des Pampers et 7 fois moins susceptibles d'acheter des produits Lovular. Ils utilisent des produits de marque Peligrin. Avec une probabilité élevée (0,6) sont les parents de filles. Ils ont tendance à payer les services publics via Internet.
25,5% des identifiants sont
enclins à payer des services de communication et d'assurance via Internet. Avec une probabilité élevée (0,6) sont des propriétaires de chiens. Achetez des produits Helen Harper. Parmi l'électronique grand public, la marque Xiaomi s'exprime.
17,5% des identifiants
Utilisateurs Ozon Premium. Ils achètent du matériel de puériculture Philips Avent et s'intéressent au matériel et aux installations de repassage.
Attention, conseil pour le futur: attention aux promotions / marques qui créent du bruit dans la quantité totale de données.
Le statut Ozon Premium dans plusieurs de nos clusters s'est avéré être l'un des attributs déterminants. Mais cibler le public des acheteurs potentiels de couches uniquement pour Ozon Premium est au-delà du bon sens. J'ai donc dû supprimer l'état de toutes les données. Oui, j'ai donc abaissé les métriques, mais en même temps augmenté l'adéquation du modèle. La première place a été occupée par les produits destinés aux nouveau-nés et non par le statut populaire promu. C'est une expérience qui m'a appris à couper les marchandises trop importantes pour le modèle.
Pour la modélisation de sosie, l'idée de construire plusieurs classificateurs simples du public cible (classe 1) et généralisés (classe 0) se trouve à la surface afin de mettre en évidence le public cible.
Par exemple, prenons les achats du public cible et dix fois le volume de profils aléatoires. Nous apportons ces informations dans l'ordre, les achats. Ensuite, nous travaillons avec les textes résultants (prétraitement): nous supprimons tous les mots à haute fréquence et non informatifs, et apportons le reste à la forme initiale. Ensuite, nous construisons des classificateurs simples de plusieurs familles différentes - linéaires (SVC linéaire, régression logistique), «en bois» (RandomForest), etc. - et mesurons l'importance des caractéristiques, c'est-à-dire l'importance de tous les mots selon les modèles. J'ai trouvé des valeurs seuils, au-dessus desquelles l'importance de ces signes est insuffisante, c'est-à-dire que le signe est trop bruyant. Avant de construire quelque chose d'automatique, vous devez appliquer le bon sens et la méthode du regard attentif à plusieurs reprises pour collecter des statistiques internes et comprendre quelles méthodes fonctionnent et lesquelles ne fonctionnent pas.
Nous avons examiné des grappes avec une image idyllique à la veille de la naissance d'un enfant, mais d'autres histoires de vie ont également été retracées. Par exemple, dans l'un des groupes, les acheteurs potentiels de couches pour nouveau-nés sont très susceptibles (0,65) d'avoir un compte sur un site de rencontres. Ce n'est pas une déclaration sans fondement, ils paient pour des services sur de tels sites.
Pour que les insights «fonctionnent», il faut toujours interpréter les nouvelles connaissances, mais cette fois je ne veux pas du tout chercher l'histoire intérieure - tout le monde connaît le mal-être social et le désordre quotidien de la vie dans notre pays.

Permettez-moi de vous rappeler que dans le cadre de cette affaire, nous avons effectué des recherches sur l'ensemble du public intéressé par l'achat de couches pour nouveau-nés. Et il s'est avéré que non seulement les femmes au troisième trimestre de la grossesse.
J'ai appelé un groupe distinct "Sunday Dads" - ses représentants sont des fans de football, des passionnés de voitures, achètent des composants pour les voitures Sparco et achètent de temps en temps des produits Chupa Chups.
Et maintenant attention, la question: vaut-il la peine de supprimer les «papas du dimanche» s'ils ne concernent pas le public cible initialement désigné? Je pose souvent cette question à mes chefs de projet, et la tâche est repensée. Peut-être n'avons-nous pas vraiment besoin d'un public cible spécifique, mais de tous ceux qui peuvent devenir acheteurs du produit. Dans notre cas, ce sont les papas, les grands-parents, les frères-sœurs et les copines d'une femme en travail, prêts à s'occuper du bébé. La réponse à laquelle le public devrait être considéré comme la cible est pour les représentants d'entreprises.
Cas "entrepreneurs individuels"

Le cas suivant, dont je vais vous parler, est la recherche d'audience pour le public cible «entrepreneurs individuels» qui ont ouvert un compte courant dans une banque bien connue.
Les principales différences entre ces personnes et le public de l'échange sont clairement visibles dans leurs achats. Le plus évident est le paiement des redevances (10-15% des profils), des services de sécurité et des factures de services publics pour les locaux non résidentiels. Parmi les signes indirects pointant vers les entrepreneurs, il y a l'achat d'un bagage supplémentaire pendant les vols (dans 15 à 20% des cas). Dans l'ensemble du volume des contrôles, une part importante est constituée de livres sur la psychologie, la connaissance de soi et le développement de soi, des ateliers de communication avec les subordonnés et de la littérature sur le coaching.
Avec l'aide de l'importance de la fonctionnalité LaL, nous avons obtenu des signes indirects de public cible: transport aérien, achat d'un robot aspirateur, machine à café, smartphone Honor, livraison de fleurs, paiement des primes d'assurance. Ce cas est l'un de ces merveilleux cas où les machines nous donnent un résultat facilement interprétable.
Les gens occupés achètent des robots domestiques. Aucun bureau ne peut se passer de machines à café. La livraison de fleurs et les vols fréquents peuvent également être liés =).
Cas "Propriétaires de voitures"
Une marque automobile bien connue dans le segment de prix «au-dessus de la moyenne» était absolument convaincue que ses clients étaient des gens tout à fait exceptionnels et souhaitaient connaître leurs habitudes et leurs préférences.
Ce public cible chevauche considérablement le cas précédent («entrepreneurs individuels»). Mais tous les entrepreneurs individuels n'achètent pas cette marque de voiture.

Il s'est avéré que l'idée que se fait le client de l'unicité des clients est grandement exagérée. Oui, le public ne coïncide pas avec la moyenne, mais seulement dans certains détails, par exemple, les automobilistes préfèrent acheter du thé d'élite (300 roubles de plus) et dépensent généralement plus pour du beau et de l'esthétique que pour du fonctionnel et pratique.
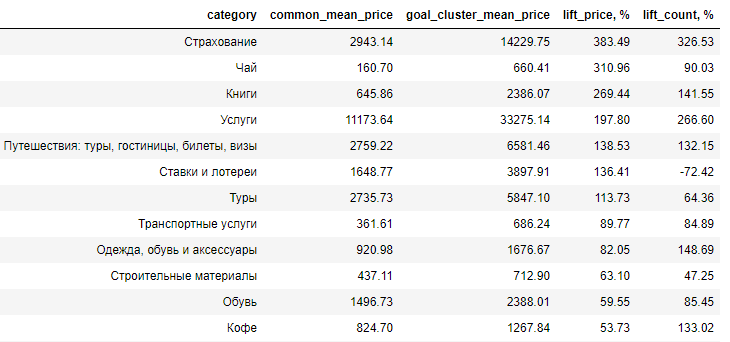
Ici, la différence entre le public cible et le public moyen des acheteurs en termes de lift est présentée, c'est-à-dire de quel pourcentage le prix moyen d'un produit dans le public étudié dépasse la même valeur dans le public moyen (lift_price). Comme vous pouvez le voir, les principales dépenses sont consacrées au plaisir.
Nous testons toujours les hypothèses de manière juste et impartiale. Il est tout à fait normal que parfois l'hypothèse du client sur l'exclusivité de son audience ne soit pas étayée par les données obtenues. Il n'y a pas de quoi s'inquiéter, il faut juste une nouvelle hypothèse et de nouvelles recherches.

En conclusion, je dirai que dans mon travail je suis guidé par le principe "La routine calme". Et je vous conseille.
Avec une telle variété de données, il est impératif d'être très prudent et attentif aux petites choses, car toute exception à première vue peut s'avérer plus tard être la règle et nous pouvons obtenir de nombreux résultats erronés.
Donc, si je n'avais pas vu ce que mon modèle «sans cuisson» désigne par «cuisson», le système «qui fuit» serait entré en production. Alors ne négligez pas la routine: si vous passez une demi-heure à vérifier avec vos yeux, vous pouvez bien dormir - le mannequin ne fera pas d'erreur.
