Le langage Go a été annoncé pour la première fois à la fin de 2009 et officiellement sorti en 2012, mais ce n'est qu'au cours des dernières années qu'il a commencé à être sérieusement reconnu. Go était l'un des langages à la croissance la plus rapide en 2018 et le troisième langage de programmation le plus populaire en 2019 .
Étant donné que le langage Go lui-même est relativement nouveau, la communauté des développeurs n'est pas très stricte sur la façon d'écrire du code. Si nous regardons des conventions similaires dans les communautés de langages plus anciens, tels que Java, il s'avère que la plupart des projets ont une structure similaire. Cela peut être très pratique lors de l'écriture de bases de code volumineuses, cependant, beaucoup pourraient soutenir que cela serait contre-productif dans les contextes pratiques modernes. Alors que nous passons à l'écriture de microsystèmes et au maintien de bases de code relativement compactes, la flexibilité de Go dans la structuration de projets devient très attrayante.
Tout le monde connaît un exemple avec hello world http sur Golang , et il peut être comparé à des exemples similaires dans d'autres langages, par exemple en Java... Il n'y a pas de différence significative entre le premier et le second, ni en complexité ni en quantité de code à écrire pour implémenter l'exemple. Mais il y a une différence d'approche fondamentale. Go nous encourage à « écrire du code simple chaque fois que possible ». Mis à part les aspects orientés objet de Java, je pense que le point le plus important à retenir de ces extraits de code est le suivant: Java nécessite une instance distincte pour chaque opération (instance
HttpServer), alors que Go nous encourage à utiliser le singleton global.
De cette façon, vous devez conserver moins de code et y passer moins de liens. Si vous savez que vous ne devez créer qu'un seul serveur (et cela se produit généralement), alors pourquoi vous en soucier trop? Cette philosophie semble plus convaincante à mesure que votre base de code se développe. Néanmoins, la vie vous réserve parfois des surprises :(. Le fait est que vous avez encore plusieurs niveaux d'abstraction à choisir, et si vous les combinez mal, vous pouvez vous faire de sérieux pièges.
C'est pourquoi je veux attirer votre attention sur trois approches d'organisation et de structuration du code Go. Chacune de ces approches implique un niveau d'abstraction différent. En conclusion, je vais comparer les trois et vous dire dans quels cas d'application chacune de ces approches est la plus appropriée.
Nous allons implémenter un serveur HTTP qui contient des informations sur les utilisateurs (désigné sous le nom de DB principal dans la figure suivante), où chaque utilisateur se voit attribuer un rôle (par exemple, de base, modérateur, administrateur), et également implémenter une base de données supplémentaire (dans la figure suivante, notée Configuration DB), qui spécifie l'ensemble des droits d'accès attribués à chacun des rôles (par exemple lire, écrire, éditer). Notre serveur HTTP doit implémenter un point de terminaison qui renvoie l'ensemble des droits d'accès dont dispose l'utilisateur avec l'ID donné.
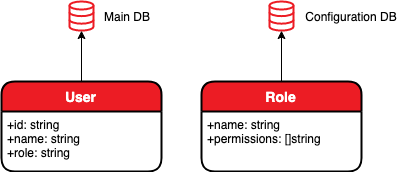
Ensuite, supposons que la base de données de configuration change rarement et prend beaucoup de temps à se charger, nous allons donc la conserver dans la RAM, la charger au démarrage du serveur et la mettre à jour toutes les heures.
Tout le code est dans le référentiel de cet article situé sur GitHub.
Approche I: paquet unique
L'approche de package unique utilise une hiérarchie de frères où le serveur entier est implémenté dans un seul package. Tout le code .
Attention: les commentaires dans le code sont informatifs, importants pour comprendre les principes de chaque approche.
/main.go
package main
import (
"net/http"
)
// ,
// , -,
// , .
var (
userDBInstance userDB
configDBInstance configDB
rolePermissions map[string][]string
)
func main() {
// ,
// ,
// .
//
// , , ,
// .
userDBInstance = &someUserDB{}
configDBInstance = &someConfigDB{}
initPermissions()
http.HandleFunc("/", UserPermissionsByID)
http.ListenAndServe(":8080", nil)
}
// , , .
func initPermissions() {
rolePermissions = configDBInstance.allPermissions()
go func() {
for {
time.Sleep(time.Hour)
rolePermissions = configDBInstance.allPermissions()
}
}()
}
/database.go
package main
// ,
// .
type userDB interface {
userRoleByID(id string) string
}
// `someConfigDB`.
//
// , MongoDB,
// `mongoConfigDB`.
// `mockConfigDB`.
type someUserDB struct {}
func (db *someUserDB) userRoleByID(id string) string {
// ...
}
type configDB interface {
allPermissions() map[string][]string //
}
type someConfigDB struct {}
func (db *someConfigDB) allPermissions() map[string][]string {
//
}
/handler.go
package main
import (
"fmt"
"net/http"
"strings"
)
func UserPermissionsByID(w http.ResponseWriter, r *http.Request) {
id := r.URL.Query()["id"][0]
role := userDBInstance.userRoleByID(id)
permissions := rolePermissions[role]
fmt.Fprint(w, strings.Join(permissions, ", "))
}Remarque: nous utilisons toujours des fichiers différents, c'est pour la séparation des préoccupations. Cela rend le code plus lisible et plus facile à maintenir.
Approche II: paquets jumelés
Dans cette approche, apprenons ce qu'est le traitement par lots. Le colis doit être seul responsable de certains comportements spécifiques. Ici, nous permettons aux packages d' interagir les uns avec les autres - nous devons donc maintenir moins de code. Cependant, nous devons nous assurer de ne pas violer le principe de la responsabilité exclusive et donc de garantir que chaque élément de logique est pleinement mis en œuvre dans un ensemble distinct. Une autre directive importante pour cette approche est que comme Go n'autorise pas les dépendances circulaires entre les packages, vous devez créer un package neutre qui ne contient que des définitions d' interface nues et des instances de singleton . Cela éliminera les dépendances en anneau. Le code entier...
/main.go
package main
// : main – ,
// .
import (
"github.com/myproject/config"
"github.com/myproject/database"
"github.com/myproject/definition"
"github.com/myproject/handler"
"net/http"
)
func main() {
// , ,
// , ,
// .
definition.UserDBInstance = &database.SomeUserDB{}
definition.ConfigDBInstance = &database.SomeConfigDB{}
config.InitPermissions()
http.HandleFunc("/", handler.UserPermissionsByID)
http.ListenAndServe(":8080", nil)
}
/definition/database.go
package definition
// , ,
// .
// , ;
// , , ,
// .
var (
UserDBInstance UserDB
ConfigDBInstance ConfigDB
)
type UserDB interface {
UserRoleByID(id string) string
}
type ConfigDB interface {
AllPermissions() map[string][]string //
}
/definition/config.go
package definition
var RolePermissions map[string][]string
/database/user.go
package database
type SomeUserDB struct{}
func (db *SomeUserDB) UserRoleByID(id string) string {
//
}
/database/config.go
package database
type SomeConfigDB struct{}
func (db *SomeConfigDB) AllPermissions() map[string][]string {
//
}
/config/permissions.go
package config
import (
"github.com/myproject/definition"
"time"
)
// ,
// config.
func InitPermissions() {
definition.RolePermissions = definition.ConfigDBInstance.AllPermissions()
go func() {
for {
time.Sleep(time.Hour)
definition.RolePermissions = definition.ConfigDBInstance.AllPermissions()
}
}()
}
/handler/user_permissions_by_id.go
package handler
import (
"fmt"
"github.com/myproject/definition"
"net/http"
"strings"
)
func UserPermissionsByID(w http.ResponseWriter, r *http.Request) {
id := r.URL.Query()["id"][0]
role := definition.UserDBInstance.UserRoleByID(id)
permissions := definition.RolePermissions[role]
fmt.Fprint(w, strings.Join(permissions, ", "))
}Approche III: packages indépendants
Avec cette approche, le projet est également organisé en packages. Dans ce cas, chaque package doit intégrer toutes ses dépendances localement , via des interfaces et des variables . Ainsi, il ne sait absolument rien des autres packages . Avec cette approche, le package avec les définitions mentionnées dans l'approche précédente sera en fait réparti entre tous les autres packages; chaque package déclare sa propre interface pour chaque service. À première vue, cela peut sembler une duplication ennuyeuse, mais en réalité ce n'est pas le cas. Chaque package qui utilise un service doit déclarer sa propre interface, qui spécifie uniquement ce dont il a besoin de ce service et rien d'autre. Le code entier...
/main.go
package main
// : – ,
// .
import (
"github.com/myproject/config"
"github.com/myproject/database"
"github.com/myproject/handler"
"net/http"
)
func main() {
userDB := &database.SomeUserDB{}
configDB := &database.SomeConfigDB{}
permissionStorage := config.NewPermissionStorage(configDB)
h := &handler.UserPermissionsByID{UserDB: userDB, PermissionsStorage: permissionStorage}
http.Handle("/", h)
http.ListenAndServe(":8080", nil)
}
/database/user.go
package database
type SomeUserDB struct{}
func (db *SomeUserDB) UserRoleByID(id string) string {
//
}
/database/config.go
package database
type SomeConfigDB struct{}
func (db *SomeConfigDB) AllPermissions() map[string][]string {
//
}
/config/permissions.go
package config
import (
"time"
)
// , ,
// , ,
// `AllPermissions`.
type PermissionDB interface {
AllPermissions() map[string][]string //
}
// ,
// , , ,
//
type PermissionStorage struct {
permissions map[string][]string
}
func NewPermissionStorage(db PermissionDB) *PermissionStorage {
s := &PermissionStorage{}
s.permissions = db.AllPermissions()
go func() {
for {
time.Sleep(time.Hour)
s.permissions = db.AllPermissions()
}
}()
return s
}
func (s *PermissionStorage) RolePermissions(role string) []string {
return s.permissions[role]
}
/handler/user_permissions_by_id.go
package handler
import (
"fmt"
"net/http"
"strings"
)
//
type UserDB interface {
UserRoleByID(id string) string
}
// ... .
type PermissionStorage interface {
RolePermissions(role string) []string
}
// ,
// , .
type UserPermissionsByID struct {
UserDB UserDB
PermissionsStorage PermissionStorage
}
func (u *UserPermissionsByID) ServeHTTP(w http.ResponseWriter, r *http.Request) {
id := r.URL.Query()["id"][0]
role := u.UserDB.UserRoleByID(id)
permissions := u.PermissionsStorage.RolePermissions(role)
fmt.Fprint(w, strings.Join(permissions, ", "))
}C'est tout! Nous avons examiné trois niveaux d'abstraction, dont le premier est le plus fin, contenant un état global et une logique étroitement couplée, mais fournissant la mise en œuvre la plus rapide et le moins de code à écrire et à maintenir. La deuxième option est un hybride léger, et la troisième est complètement autonome et adaptée à une utilisation répétée, mais avec un effort maximal avec un soutien.
Avantages et inconvénients
Approche I: Paquet unique
pour
- Moins de code, une implémentation beaucoup plus rapide, moins de travaux de maintenance
- Aucun paquet, ce qui signifie que vous n'avez pas à vous soucier des dépendances en anneau
- Facile à tester car les interfaces de service existent. Pour tester un morceau de logique, vous pouvez spécifier n'importe quelle implémentation de votre choix (concrète ou simulée) pour le singleton, puis exécuter la logique de test.
Contre
- Le seul package ne prévoit pas non plus d'accès privé, tout est ouvert de partout. En conséquence, la responsabilité du développeur augmente. Par exemple, rappelez-vous que vous ne pouvez pas instancier directement une structure lorsqu'une fonction constructeur est requise pour exécuter une logique d'initialisation.
- L'état global (instances de singleton) peut créer des hypothèses non satisfaites, par exemple, une instance de singleton non initialisée peut déclencher une panique de pointeur nul au moment de l'exécution.
- Étant donné que la logique est étroitement couplée, rien dans ce projet ne peut être facilement réutilisé et il sera difficile d'en extraire des composants.
- Lorsque vous n'avez pas de packages qui gèrent indépendamment chaque élément de logique, le développeur doit être très prudent et placer correctement tous les éléments de code, sinon des comportements inattendus peuvent se produire.
Approche II: paquets jumelés
par
- Lors de l'empaquetage d'un projet, il est plus pratique de garantir la responsabilité d'une logique spécifique dans le package, et cela peut être appliqué à l'aide du compilateur. De plus, nous pourrons utiliser un accès privé et contrôler quels éléments du code nous sont ouverts.
- L'utilisation d'un package avec des définitions vous permet de travailler avec des instances singleton tout en évitant les dépendances circulaires. De cette façon, vous pouvez écrire moins de code, éviter de passer des références lors de la gestion des instances et éviter de perdre du temps sur des problèmes susceptibles de survenir lors de la compilation.
- Cette approche est également propice aux tests, car il existe des interfaces de service. Avec cette approche, le test interne de chaque package est possible.
Contre
- Il y a des frais généraux lors de l'organisation d'un projet dans des packages - par exemple, la mise en œuvre initiale devrait prendre plus de temps qu'avec une approche de package unique.
- L'utilisation de l'état global (instances singleton) avec cette approche peut également poser des problèmes.
- Le projet est divisé en packages, ce qui facilite grandement l'extraction et la réutilisation d'éléments individuels. Cependant, les packages ne sont pas complètement indépendants car ils interagissent tous avec un package de définition. Avec cette approche, l'extraction et la réutilisation de code ne sont pas complètement automatiques.
Approche III: Packages de
pros indépendants
- Lors de l'utilisation de packages, nous nous assurons qu'une logique spécifique est implémentée dans un seul package et nous avons un contrôle d'accès complet.
- Il ne doit y avoir aucune dépendance circulaire potentielle car les packages sont complètement autonomes.
- Tous les packages sont hautement récupérables et réutilisables. Dans tous les cas où nous avons besoin d'un package dans un autre projet, nous le transférons simplement dans un espace partagé et l'utilisons sans rien y changer.
- S'il n'y a pas d'état global, il n'y a pas de comportements involontaires.
- Cette approche est la meilleure pour les tests. Chaque package peut être entièrement testé sans craindre de dépendre d'autres packages via des interfaces locales.
Contre
- Cette approche est beaucoup plus lente à mettre en œuvre que les deux précédentes.
- Il faut maintenir beaucoup plus de code. Étant donné que les liens sont transmis, de nombreux emplacements doivent être mis à jour après des modifications majeures. De plus, lorsque nous avons plusieurs interfaces qui fournissent le même service, nous devons mettre à jour ces interfaces chaque fois que nous apportons des modifications à ce service.
Conclusions et exemples d'utilisation
Étant donné le manque de directives pour écrire du code dans Go, il prend de nombreuses formes et formes différentes, et chaque option a ses propres mérites intéressants. Cependant, mélanger différents modèles de conception peut poser des problèmes. Pour vous en donner une idée, j'ai couvert trois approches différentes de l'écriture et de la structuration du code Go.
Alors, quand doit-on utiliser chaque approche? Je suggère cet arrangement:
Approche I : L'approche mono-package est peut-être la plus appropriée lorsque vous travaillez en petites équipes très expérimentées sur de petits projets où des résultats rapides sont nécessaires. Cette approche est plus simple et plus fiable pour un démarrage rapide, bien qu'elle nécessite une attention et une coordination sérieuses au stade de l'appui au projet.
Approche II: L'approche par paquets appariés peut être qualifiée de synthèse hybride des deux autres approches: parmi ses avantages, un démarrage relativement rapide et une facilité de prise en charge, tout en créant les conditions d'un strict respect des règles. Il convient aux projets relativement importants et aux grandes équipes, mais il a une réutilisabilité limitée du code et il y a certaines difficultés à maintenir.
Approche III : L'approche des packages indépendants est la plus appropriée pour les projets complexes en eux-mêmes, à long terme, développés par de grandes équipes, et pour les projets dans lesquels des éléments de logique sont créés dans le but de les réutiliser davantage. Cette approche prend du temps à mettre en œuvre et est difficile à maintenir.