Nous vous expliquerons pourquoi cet outil est apparu et ce qu'il peut faire.

Manque d'algorithmes
L'un des principaux défis de l'apprentissage automatique est la réduction de la dimensionnalité des données. Les Data Scientists réduisent le nombre de variables en isolant parmi elles les valeurs qui ont le plus d'impact sur le résultat. Après cette opération, le modèle d'apprentissage automatique nécessite moins de mémoire, fonctionne plus vite et mieux. L'exemple ci-dessous montre que l'élimination des entités en double augmente la précision de classification de 0,903 à 0,943.
>>> from sklearn.linear_model import SGDClassifier
>>> from ITMO_FS.embedded import MOS
>>> X, y = make_classification(n_samples=300, n_features=10, random_state=0, n_informative=2)
>>> sel = MOS()
>>> trX = sel.fit_transform(X, y, smote=False)
>>> cl1 = SGDClassifier()
>>> cl1.fit(X, y)
>>> cl1.score(X, y)
0.9033333333333333
>>> cl2 = SGDClassifier()
>>> cl2.fit(trX, y)
>>> cl2.score(trX, y)
0.9433333333333334Il existe deux approches pour la réduction de la dimensionnalité: la conception des fonctions et la sélection des fonctions. Dans des domaines comme la bioinformatique et la médecine, cette dernière est souvent utilisée, car elle permet de mettre en évidence des caractéristiques significatives tout en préservant la sémantique, c'est-à-dire qu'elle ne change pas la signification originale des caractéristiques. Cependant, les bibliothèques d'apprentissage automatique Python les plus courantes - scikit-learn, pytorch, keras, tensorflow - ne disposent pas d'un ensemble complet de méthodes de sélection de fonctionnalités.
Pour résoudre ce problème, les étudiants et les étudiants de troisième cycle de l'Université ITMO ont développé une bibliothèque ouverte - ITMO_FS. Une équipe y travaille sous la direction d'Ivan Smetannikov, professeur agrégé de la Faculté des technologies de l'information et de la programmation, Directeur adjoint du laboratoire d'apprentissage automatique. Développeur principal - Nikita Pilnenskiy, est diplômée de la maîtrise en apprentissage automatique et analyse de données . Maintenant, il va à l'école supérieure.
« , . , , , (-) .
, , , . , , , ».
—
ITMO_FS est implémenté en Python et est compatible avec scikit-learn, qui est considéré comme le principal outil d'analyse de données de facto. Ses sélecteurs de fonctionnalités prennent les mêmes paramètres:
data: array-like (2-D list, pandas.Dataframe, numpy.array);
targets: array-like (1-D list, pandas.Series, numpy.array).La bibliothèque prend en charge toutes les approches classiques de la sélection des fonctionnalités - filtres, wrappers et méthodes en ligne. Parmi eux figurent des algorithmes tels que des filtres basés sur les corrélations de Spearman et Pearson, le critère d'ajustement, le QPFS, le filtre d'escalade et autres .

La bibliothèque prend également en charge les ensembles de formation en combinant des algorithmes de sélection de caractéristiques basés sur les mesures de signification qui y sont utilisées. Cette approche vous permet d'obtenir des résultats prédictifs plus élevés avec un investissement en temps réduit.
Quels sont les analogues
Il n'y a pas beaucoup de bibliothèques d'algorithmes de sélection de fonctionnalités, en particulier en Python. L'un des plus importants est considéré comme le développement des ingénieurs de l'Arizona State University (ASU). Il prend en charge un grand nombre d'algorithmes, mais n'a guère été mis à jour récemment.
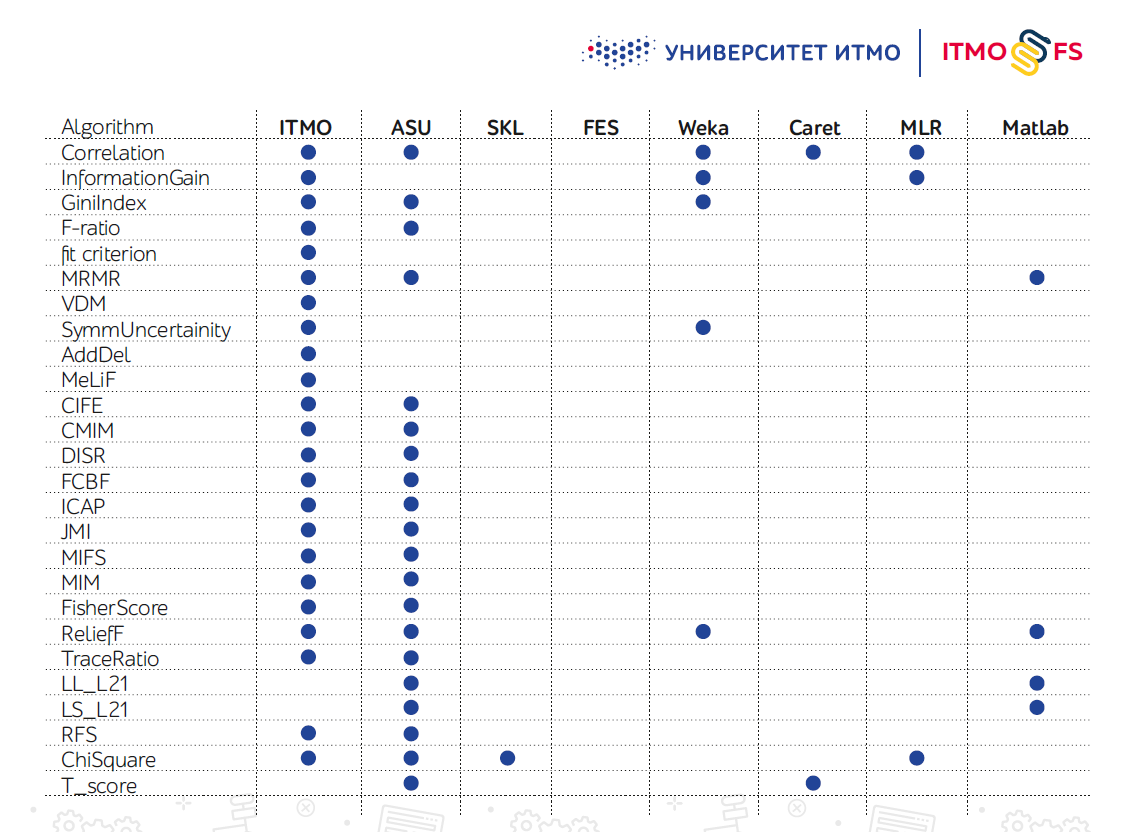
Scikit-learn lui-même dispose également de plusieurs mécanismes de sélection de fonctionnalités, mais en pratique, ils ne suffisent pas.
"En général, au cours des cinq à sept dernières années, l'accent s'est déplacé vers les algorithmes d'ensemble pour la sélection des fonctionnalités, mais ils ne sont pas particulièrement représentés dans ces bibliothèques, ce que nous voulons également corriger."
- Ivan Smetannikov
Perspectives du projet
Les auteurs d'ITMO_FS prévoient d'intégrer leur produit à scikit-learn en l'ajoutant à la liste des bibliothèques officiellement compatibles. Pour le moment, la bibliothèque contient déjà le plus grand nombre d'algorithmes de sélection de fonctionnalités parmi toutes les bibliothèques, mais leur ajout se poursuit. Plus loin sur la feuille de route, il y a l'ajout de nouveaux algorithmes, y compris nos propres développements.
Dans des plans plus éloignés, il existe des tâches pour introduire la bibliothèque dans le système de méta-apprentissage, ajouter des algorithmes pour un travail direct avec des données matricielles (combler les lacunes, générer des données spatiales de méta-attribut, etc.), ainsi qu'une interface graphique. En parallèle, des hackathons auront lieu à l'aide de la bibliothèque afin d'intéresser davantage de développeurs au produit et d'obtenir des commentaires.
On s'attend à ce que ITMO_FS trouve une application dans les domaines de la médecine et de la bioinformatique - dans des problèmes tels que le diagnostic de divers cancers, la construction de modèles prédictifs des caractéristiques phénotypiques (par exemple, l'âge d'une personne) et la synthèse de médicaments.
Où puis-je télécharger
Si le projet ITMO_FS vous intéresse, vous pouvez télécharger la bibliothèque et l'essayer en pratique - voici le référentiel sur GitHub . Une première version de la documentation est disponible sur readthedocs . Là, vous pouvez également voir les instructions d'installation (prises en charge par pip). Nous apprécions vos commentaires.
Matériel supplémentaire de notre blog sur Habré:
- Podcast: ce qui attend les scientifiques en herbe dans le domaine du ML
- Podcast: piratage quantique et partage de clés