
Le but de cet article est de partager notre première expérience avec MLflow .
Nous allons commencer notre examen de MLflow à partir de son serveur de suivi et continuer à travers toutes les itérations de l'étude. Ensuite, nous partagerons notre expérience de connexion de Spark à MLflow en utilisant UDF.
Le contexte
Chez Alpha Health, nous utilisons l'apprentissage automatique et l'intelligence artificielle pour permettre aux gens de prendre soin de leur santé et de leur bien-être. C'est pourquoi les modèles d'apprentissage automatique sont au cœur des produits de données que nous développons, c'est pourquoi notre attention a été attirée sur MLflow, une plate-forme open source qui couvre tous les aspects du cycle de vie de l'apprentissage automatique.
MLflow
L'objectif principal de MLflow est de fournir une couche supplémentaire en plus de l'apprentissage automatique qui permettrait aux scientifiques des données de travailler avec presque toutes les bibliothèques d'apprentissage automatique ( h2o , keras , mleap , pytorch , sklearn et tensorflow ), en l'amenant au niveau supérieur.
MLflow fournit trois composants:
- Suivi - enregistrement et interrogation des expériences: code, données, configuration et résultats. Il est très important de suivre le processus de création du modèle.
- Projets - Format d'emballage à exécuter sur n'importe quelle plate-forme (par exemple, SageMaker )
- Modèles est un format courant pour soumettre des modèles à divers outils de déploiement.
MLflow (alpha au moment de la rédaction de cet article) est une plate-forme open source qui vous permet de gérer le cycle de vie du machine learning, y compris l'expérimentation, la réutilisation et le déploiement.
Configurer MLflow
Pour utiliser MLflow, vous devez d'abord configurer l'ensemble de l'environnement Python, pour cela nous utiliserons PyEnv (pour installer Python sur Mac, jetez un œil ici ). Nous pouvons donc créer un environnement virtuel dans lequel nous installerons toutes les bibliothèques nécessaires pour fonctionner.
```
pyenv install 3.7.0
pyenv global 3.7.0 # Use Python 3.7
mkvirtualenv mlflow # Create a Virtual Env with Python 3.7
workon mlflow
```Installez les bibliothèques requises.
```
pip install mlflow==0.7.0 \
Cython==0.29 \
numpy==1.14.5 \
pandas==0.23.4 \
pyarrow==0.11.0
```Remarque: nous utilisons PyArrow pour exécuter des modèles tels que les UDF. Les versions PyArrow et Numpy devaient être corrigées car les dernières versions étaient en conflit.
Lancer l'interface utilisateur de suivi
MLflow Tracking nous permet de consigner et de faire des demandes d'expériences à l'aide de Python et de l' API REST . De plus, vous pouvez définir où stocker les artefacts de modèle (localhost, Amazon S3 , Azure Blob Storage , Google Cloud Storage ou serveur SFTP ). Comme nous utilisons AWS chez Alpha Health, S3 sera utilisé comme stockage pour les artefacts.
# Running a Tracking Server
mlflow server \
--file-store /tmp/mlflow/fileStore \
--default-artifact-root s3://<bucket>/mlflow/artifacts/ \
--host localhost
--port 5000MLflow recommande d'utiliser le stockage de fichiers persistant. Le stockage de fichiers est l'endroit où le serveur stockera les métadonnées d'exécution et d'expérimentation. Lors du démarrage du serveur, assurez-vous qu'il pointe vers un stockage de fichiers persistant. Ici, nous allons simplement l'utiliser pour l'expérimentation
/tmp.
N'oubliez pas que si nous voulons utiliser le serveur mlflow pour exécuter d'anciennes expériences, elles doivent être présentes dans le magasin de fichiers. Cependant, même sans cela, nous pourrions les utiliser dans l'UDF, car nous n'avons besoin que du chemin d'accès au modèle.
Remarque: gardez à l'esprit que l'interface utilisateur de suivi et le client modèle doivent avoir accès à l'emplacement de l'artefact. Autrement dit, indépendamment du fait que l'interface utilisateur de suivi se trouve dans l'instance EC2, lorsque MLflow est lancé localement, la machine doit avoir un accès direct à S3 pour écrire des modèles d'artefacts.
L'interface utilisateur de suivi stocke les artefacts dans un compartiment S3
Modèles en cours d'exécution
Une fois que le serveur de suivi est en cours d'exécution, vous pouvez commencer à entraîner les modèles.
À titre d'exemple, nous utiliserons la modification wine de l'exemple MLflow dans Sklearn .
MLFLOW_TRACKING_URI=http://localhost:5000 python wine_quality.py \
--alpha 0.9
--l1_ration 0.5
--wine_file ./data/winequality-red.csvComme nous l'avons déjà dit, MLflow vous permet de consigner les paramètres, les métriques et les artefacts des modèles afin que vous puissiez suivre leur développement au cours de votre itération. Cette fonctionnalité est extrêmement utile, car de cette manière, nous pouvons reproduire le meilleur modèle en contactant le serveur de suivi ou en comprenant quel code a effectué l'itération requise à l'aide des journaux de validation de git hash.
with mlflow.start_run():
... model ...
mlflow.log_param("source", wine_path)
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
mlflow.set_tag('domain', 'wine')
mlflow.set_tag('predict', 'quality')
mlflow.sklearn.log_model(lr, "model")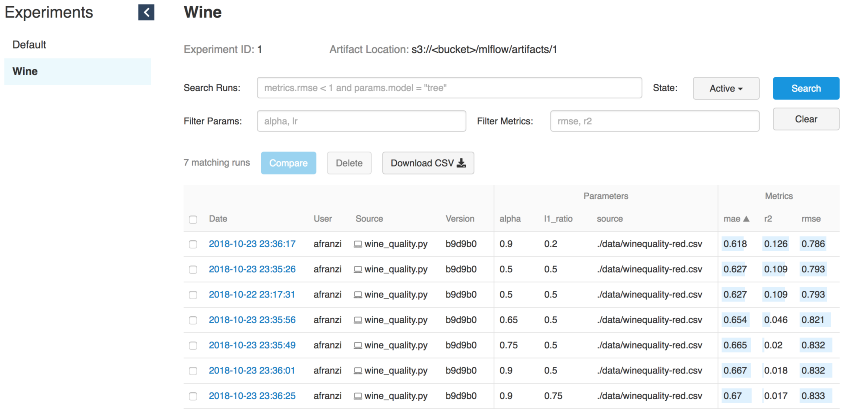
Itérations de vin
Partie serveur pour le modèle
Le serveur de suivi MLflow, lancé avec la commande «mlflow server», dispose d'une API REST pour le suivi des lancements et l'écriture des données dans le système de fichiers local. Vous pouvez spécifier l'adresse du serveur de suivi à l'aide de la variable d'environnement "MLFLOW_TRACKING_URI" et l'API de suivi MLflow contactera automatiquement le serveur de suivi à cette adresse pour créer / obtenir des informations de lancement, des métriques de journalisation, etc.Pour fournir au modèle un serveur, nous avons besoin d'un serveur de suivi en cours d'exécution (voir l'interface de lancement) et d'un ID d'exécution du modèle.
Source: Docs // Exécution d'un serveur de suivi

ID d'exécution
# Serve a sklearn model through 127.0.0.0:5005
MLFLOW_TRACKING_URI=http://0.0.0.0:5000 mlflow sklearn serve \
--port 5005 \
--run_id 0f8691808e914d1087cf097a08730f17 \
--model-path modelPour servir des modèles à l'aide de la fonctionnalité de service MLflow, nous devons accéder à l'interface utilisateur de suivi pour obtenir des informations sur le modèle simplement en le spécifiant
--run_id.
Une fois que le modèle communique avec le serveur de suivi, nous pouvons obtenir le nouveau point de terminaison du modèle.
# Query Tracking Server Endpoint
curl -X POST \
http://127.0.0.1:5005/invocations \
-H 'Content-Type: application/json' \
-d '[
{
"fixed acidity": 3.42,
"volatile acidity": 1.66,
"citric acid": 0.48,
"residual sugar": 4.2,
"chloridessssss": 0.229,
"free sulfur dsioxide": 19,
"total sulfur dioxide": 25,
"density": 1.98,
"pH": 5.33,
"sulphates": 4.39,
"alcohol": 10.8
}
]'
> {"predictions": [5.825055635303461]}Modèles en cours d'exécution de Spark
Malgré le fait que le serveur de suivi soit suffisamment puissant pour servir les modèles en temps réel, les former et utiliser la fonctionnalité de service (source: mlflow // docs // models # local ), l'utilisation de Spark (batch ou streaming) est une solution encore plus puissante pour compte de distribution.
Imaginez que vous venez de suivre une formation hors ligne, puis d'appliquer le modèle de sortie à toutes vos données. C'est là que Spark et MLflow montreront leur meilleur.
Installez PySpark + Jupyter + Spark
Source: Commencer PySpark - Jupyter
Pour montrer comment nous appliquons des modèles MLflow aux dataframes Spark, nous devons configurer les notebooks Jupyter pour qu'ils fonctionnent avec PySpark.
Commencez par installer la dernière version stable d' Apache Spark :
cd ~/Downloads/
tar -xzf spark-2.4.3-bin-hadoop2.7.tgz
mv ~/Downloads/spark-2.4.3-bin-hadoop2.7 ~/
ln -s ~/spark-2.4.3-bin-hadoop2.7 ~/spark̀Installez PySpark et Jupyter dans un environnement virtuel:
pip install pyspark jupyterConfigurez les variables d'environnement:
export SPARK_HOME=~/spark
export PATH=$SPARK_HOME/bin:$PATH
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS="notebook --notebook-dir=${HOME}/Projects/notebooks"Une fois déterminés
notebook-dir, nous pouvons stocker nos cahiers dans le dossier souhaité.
Lancement de Jupyter depuis PySpark
Puisque nous avons pu configurer Jupiter comme pilote PySpark, nous pouvons désormais exécuter des blocs-notes Jupyter dans le contexte PySpark.
(mlflow) afranzi:~$ pyspark
[I 19:05:01.572 NotebookApp] sparkmagic extension enabled!
[I 19:05:01.573 NotebookApp] Serving notebooks from local directory: /Users/afranzi/Projects/notebooks
[I 19:05:01.573 NotebookApp] The Jupyter Notebook is running at:
[I 19:05:01.573 NotebookApp] http://localhost:8888/?token=c06252daa6a12cfdd33c1d2e96c8d3b19d90e9f6fc171745
[I 19:05:01.573 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 19:05:01.574 NotebookApp]
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
http://localhost:8888/?token=c06252daa6a12cfdd33c1d2e96c8d3b19d90e9f6fc171745
Comme mentionné ci-dessus, MLflow fournit une fonction de journalisation des artefacts de modèle dans S3. Dès que nous avons le modèle sélectionné entre nos mains, nous avons la possibilité de l'importer sous forme d'UDF à l'aide du module
mlflow.pyfunc.
import mlflow.pyfunc
model_path = 's3://<bucket>/mlflow/artifacts/1/0f8691808e914d1087cf097a08730f17/artifacts/model'
wine_path = '/Users/afranzi/Projects/data/winequality-red.csv'
wine_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = spark.read.format("csv").option("header", "true").option('delimiter', ';').load(wine_path)
columns = [ "fixed acidity", "volatile acidity", "citric acid",
"residual sugar", "chlorides", "free sulfur dioxide",
"total sulfur dioxide", "density", "pH",
"sulphates", "alcohol"
]
df.withColumn('prediction', wine_udf(*columns)).show(100, False)
PySpark - Sortie de prévisions de qualité du vin
Jusqu'à présent, nous avons expliqué comment utiliser PySpark avec MLflow en exécutant des prédictions de qualité du vin sur l'ensemble de données sur le vin. Mais que faire si vous devez utiliser les modules Python MLflow de Scala Spark?
Nous avons également testé cela en divisant le contexte Spark entre Scala et Python. Autrement dit, nous avons enregistré MLflow UDF en Python et l'avons utilisé à partir de Scala (oui, peut-être pas la meilleure solution, mais ce que nous avons).
Scala Spark + MLflow
Pour cet exemple, nous allons ajouter le noyau Toree au Jupiter existant.
Installez Spark + Toree + Jupyter
pip install toree
jupyter toree install --spark_home=${SPARK_HOME} --sys-prefix
jupyter kernelspec list
```
```
Available kernels:
apache_toree_scala /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/apache_toree_scala
python3 /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/python3
```Comme vous pouvez le voir sur le bloc-notes joint, UDF est partagé entre Spark et PySpark. Nous espérons que cette partie sera utile pour ceux qui aiment Scala et souhaitent déployer des modèles d'apprentissage automatique en production.
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.{Column, DataFrame}
import scala.util.matching.Regex
val FirstAtRe: Regex = "^_".r
val AliasRe: Regex = "[\\s_.:@]+".r
def getFieldAlias(field_name: String): String = {
FirstAtRe.replaceAllIn(AliasRe.replaceAllIn(field_name, "_"), "")
}
def selectFieldsNormalized(columns: List[String])(df: DataFrame): DataFrame = {
val fieldsToSelect: List[Column] = columns.map(field =>
col(field).as(getFieldAlias(field))
)
df.select(fieldsToSelect: _*)
}
def normalizeSchema(df: DataFrame): DataFrame = {
val schema = df.columns.toList
df.transform(selectFieldsNormalized(schema))
}
FirstAtRe = ^_
AliasRe = [\s_.:@]+
getFieldAlias: (field_name: String)String
selectFieldsNormalized: (columns: List[String])(df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrame
normalizeSchema: (df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrame
Out[1]:
[\s_.:@]+
In [2]:
val winePath = "~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv"
val modelPath = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"
winePath = ~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv
modelPath = /tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model
Out[2]:
/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model
In [3]:
val df = spark.read
.format("csv")
.option("header", "true")
.option("delimiter", ";")
.load(winePath)
.transform(normalizeSchema)
df = [fixed_acidity: string, volatile_acidity: string ... 10 more fields]
Out[3]:
[fixed_acidity: string, volatile_acidity: string ... 10 more fields]
In [4]:
%%PySpark
import mlflow
from mlflow import pyfunc
model_path = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"
wine_quality_udf = mlflow.pyfunc.spark_udf(spark, model_path)
spark.udf.register("wineQuality", wine_quality_udf)
Out[4]:
<function spark_udf.<locals>.predict at 0x1116a98c8>
In [6]:
df.createOrReplaceTempView("wines")
In [10]:
%%SQL
SELECT
quality,
wineQuality(
fixed_acidity,
volatile_acidity,
citric_acid,
residual_sugar,
chlorides,
free_sulfur_dioxide,
total_sulfur_dioxide,
density,
pH,
sulphates,
alcohol
) AS prediction
FROM wines
LIMIT 10
Out[10]:
+-------+------------------+
|quality| prediction|
+-------+------------------+
| 5| 5.576883967129615|
| 5| 5.50664776916154|
| 5| 5.525504822954496|
| 6| 5.504311247097457|
| 5| 5.576883967129615|
| 5|5.5556903912725755|
| 5| 5.467882654744997|
| 7| 5.710602976324739|
| 7| 5.657319539336507|
| 5| 5.345098606538708|
+-------+------------------+
In [17]:
spark.catalog.listFunctions.filter('name like "%wineQuality%").show(20, false)
+-----------+--------+-----------+---------+-----------+
|name |database|description|className|isTemporary|
+-----------+--------+-----------+---------+-----------+
|wineQuality|null |null |null |true |
+-----------+--------+-----------+---------+-----------+
Prochaines étapes
Même si MLflow est en Alpha au moment de la rédaction, cela semble assez prometteur. La simple capacité d'exécuter plusieurs frameworks d'apprentissage automatique et de les utiliser à partir d'un point de terminaison fait passer les systèmes de recommandation au niveau supérieur.
De plus, MLflow rapproche les ingénieurs de données et les scientifiques des données en créant une couche commune entre eux.
Après avoir effectué cette recherche sur MLflow, nous sommes convaincus que nous allons continuer et l'utiliser pour nos pipelines Spark et nos systèmes de recommandation.
Ce serait bien de synchroniser le stockage de fichiers avec la base de données au lieu du système de fichiers. De cette façon, nous devons obtenir plusieurs points de terminaison qui peuvent utiliser le même stockage de fichiers. Par exemple, utilisez plusieurs instances de Prestoet Athéna avec le même métastore Glue.
Pour résumer, j'aimerais remercier la communauté MLFlow d'avoir rendu notre travail avec les données plus intéressant.
Si vous jouez avec MLflow, n'hésitez pas à nous écrire et à nous dire comment vous l'utilisez, et plus encore si vous l'utilisez en production.
En savoir plus sur les cours:
Machine Learning. Cours d' apprentissage automatique de base
. Cours avancé
Lire la suite: