Les principes de notre système
Lorsque vous entendez des termes tels que «automatique» et «fraude», vous pensez probablement à l'apprentissage automatique, à Apache Spark, Hadoop, Python, Airflow et à d'autres technologies de l'écosystème Apache Foundation et du domaine de la science des données. Je pense qu'il y a un aspect de l'utilisation de ces outils qui n'est généralement pas mentionné: ils nécessitent certains prérequis dans votre système d'entreprise avant de pouvoir commencer à les utiliser. En bref, vous avez besoin d'une plate-forme de données d'entreprise qui comprend un lac de données et un stockage. Mais que se passe-t-il si vous ne disposez pas d'une telle plate-forme et que vous devez encore développer cette pratique? Les principes suivants, dont je discute ci-dessous, nous ont aidés à atteindre le point où nous pouvons nous concentrer sur l'amélioration de nos idées, plutôt que sur la recherche de celles qui fonctionnent. Cependant, ce n'est pas un «plateau» du projet.Il y a encore beaucoup de choses dans le plan d'un point de vue technologique et produit.
Principe 1: La valeur commerciale avant tout
Nous avons placé la valeur commerciale au centre de tous nos efforts. En général, tout système d'analyse automatique appartient au groupe des systèmes complexes avec un haut niveau d'automatisation et de complexité technique. Il faudra beaucoup de temps pour créer une solution complète si vous la créez à partir de zéro. Nous avons décidé de donner la priorité à la valeur commerciale et à l'exhaustivité de la technologie. Dans la vraie vie, cela signifie que nous n'acceptons pas la technologie de pointe comme un dogme. Nous choisissons la technologie qui nous convient le mieux en ce moment. Au fil du temps, il peut sembler que nous devrons réimplémenter certains modules. Ce compromis que nous avons accepté.
Principe 2: intelligence augmentée
Je parie que la plupart des gens qui ne sont pas profondément impliqués dans le développement de solutions d'apprentissage automatique pourraient penser que le remplacement des personnes est l'objectif. En fait, les solutions d'apprentissage automatique sont loin d'être parfaites et ne peuvent être remplacées que dans certains domaines. Nous avons abandonné cette idée depuis le début pour plusieurs raisons: des données déséquilibrées sur les activités frauduleuses et l'incapacité de fournir une liste exhaustive de fonctionnalités pour les modèles d'apprentissage automatique. En revanche, nous avons choisi l'option d'intelligence améliorée. Il s'agit d'un concept alternatif d'intelligence artificielle qui se concentre sur le rôle de soutien de l'IA, soulignant le fait que les technologies cognitives sont conçues pour améliorer l'intelligence humaine et non pour la remplacer. [1]
Dans cette optique, développer dès le départ une solution complète d'apprentissage automatique demanderait un effort considérable qui retarderait la création de valeur pour notre entreprise. Nous avons décidé de créer un système avec un aspect itératif croissant de l'apprentissage automatique sous la direction de nos experts du domaine. La partie délicate de l'élaboration d'un tel système est qu'il doit fournir à nos analystes des cas non seulement en termes de savoir s'il s'agit d'une activité frauduleuse ou non. En général, toute anomalie dans le comportement des clients est un cas suspect que les spécialistes doivent enquêter et réagir d'une manière ou d'une autre. Seule une fraction de ces cas enregistrés peut vraiment être qualifiée de fraude.
Principe 3: plateforme d'intelligence riche
La partie la plus difficile de notre système est la vérification de bout en bout du flux de travail du système. Les analystes et les développeurs devraient être en mesure de récupérer facilement des ensembles de données historiques avec toutes les métriques utilisées pour leur analyse. En outre, la plate-forme de données devrait fournir un moyen simple de compléter l'ensemble existant d'indicateurs par de nouveaux. Les processus que nous créons, et ce ne sont pas seulement des processus logiciels, devraient faciliter le recalcul des périodes précédentes, ajouter de nouvelles métriques et modifier les prévisions de données. Nous pourrions y parvenir en accumulant toutes les données générées par notre système de production. Dans ce cas, les données deviendraient progressivement un frein. Nous aurions besoin de stocker et de protéger la quantité croissante de données que nous n'utilisons pas. Dans un tel scénario, au fil du temps, les données deviendront de plus en plus inutiles,mais nécessitent encore nos efforts pour les gérer. Pour nous, la thésaurisation des données n'avait pas de sens, et nous avons décidé d'adopter une approche différente. Nous avons décidé d'organiser des magasins de données en temps réel autour des entités cibles que nous voulons classer, et de ne stocker que les données qui nous permettent de vérifier les périodes les plus récentes et à jour. Le défi de cet effort est que notre système est hétérogène avec plusieurs magasins de données et modules logiciels qui nécessitent une planification minutieuse pour fonctionner de manière cohérente.qui vous permettent de vérifier les périodes les plus récentes et les plus récentes. Le défi de cet effort est que notre système est hétérogène avec plusieurs magasins de données et modules logiciels qui nécessitent une planification minutieuse pour fonctionner de manière cohérente.qui vous permettent de vérifier les périodes les plus récentes et les plus récentes. Le défi de cet effort est que notre système est hétérogène avec plusieurs magasins de données et modules logiciels qui nécessitent une planification minutieuse pour fonctionner de manière cohérente.
Concepts constructifs de notre système
Nous avons quatre composants principaux dans notre système: système d'ingestion, calcul, analyse BI et système de suivi. Ils servent des objectifs isolés spécifiques, et nous les gardons isolés en suivant des approches de conception spécifiques.
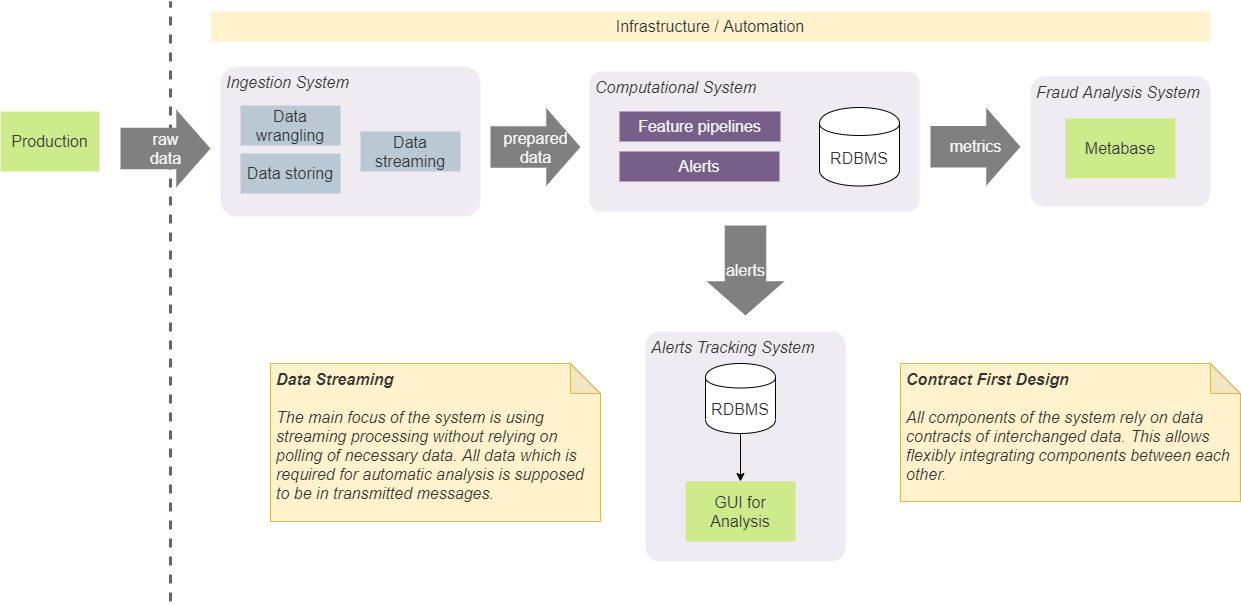
Conception basée sur le contrat
Tout d'abord, nous avons convenu que les composants ne devraient s'appuyer que sur certaines structures de données (contrats) qui sont passées entre eux. Cela permet de s'intégrer facilement entre eux et de ne pas imposer une composition (et un ordre) spécifique des composants. Par exemple, dans certains cas, cela nous permet d'intégrer directement le système de réception au système de suivi des alertes. Dans ce cas, cela se fera conformément au contrat de notification convenu. Cela signifie que les deux composants seront intégrés à l'aide d'un contrat que tout autre composant peut utiliser. Nous n'ajouterons pas de contrat supplémentaire pour ajouter des alertes au système de suivi à partir du système d'entrée. Cette approche nécessite l'utilisation d'un nombre minimum de contrats prédéterminé et simplifie le système et la communication. En réalité,nous utilisons une approche appelée «Contract First Design» et l'appliquons aux contrats de streaming. [2]
Le maintien et la gestion de l'état dans le système entraîneront inévitablement des complications dans sa mise en œuvre. En général, l'état doit être accessible à partir de n'importe quel composant, il doit être cohérent et fournir la valeur la plus à jour pour tous les composants, et il doit être fiable avec les valeurs correctes. De plus, avoir des appels au stockage persistant pour obtenir le dernier état augmentera la quantité d'E / S et la complexité des algorithmes utilisés dans nos pipelines en temps réel. Pour cette raison, nous avons décidé de supprimer le stockage d'état aussi complètement que possible de notre système. Cette approche nécessite l'inclusion de toutes les données nécessaires dans le bloc de données transmis (message). Par exemple, si nous devons calculer le nombre total de certaines observations (le nombre d'opérations ou de cas avec certaines caractéristiques),nous le calculons en mémoire et générons un flux de telles valeurs. Les modules dépendants utiliseront la partition et le lot pour diviser le flux en entités et fonctionner sur les dernières valeurs. Cette approche a éliminé le besoin de disposer d'un stockage sur disque persistant pour ces données. Notre système utilise Kafka comme courtier de messages et peut être utilisé comme base de données avec KSQL. [3] Mais l'utiliser relierait fortement notre solution à Kafka, et nous avons décidé de ne pas l'utiliser. L'approche que nous avons adoptée nous permet de remplacer Kafka par un autre courtier de messages sans modifications majeures du système interne.Cette approche a éliminé le besoin de disposer d'un stockage sur disque persistant pour ces données. Notre système utilise Kafka comme courtier de messages et peut être utilisé comme base de données avec KSQL. [3] Mais l'utiliser relierait fortement notre solution à Kafka, et nous avons décidé de ne pas l'utiliser. L'approche que nous avons adoptée nous permet de remplacer Kafka par un autre courtier de messages sans modifications majeures du système interne.Cette approche a éliminé le besoin de disposer d'un stockage sur disque persistant pour ces données. Notre système utilise Kafka comme courtier de messages et peut être utilisé comme base de données avec KSQL. [3] Mais l'utiliser relierait fortement notre solution à Kafka, et nous avons décidé de ne pas l'utiliser. L'approche que nous avons adoptée nous permet de remplacer Kafka par un autre courtier de messages sans modifications majeures du système interne.
Ce concept ne signifie pas que nous n'utilisons pas de stockage sur disque ni de bases de données. Pour vérifier et analyser les performances du système, nous devons stocker une partie importante des données sur disque, ce qui représente divers indicateurs et états. Le point important ici est que les algorithmes en temps réel sont indépendants de ces données. Dans la plupart des cas, nous utilisons les données enregistrées pour l'analyse hors ligne, le débogage et le suivi des cas spécifiques et des résultats produits par le système.
Les problèmes de notre système
Il y a certains problèmes que nous avons résolus à un certain niveau, mais ils nécessitent des solutions plus réfléchies. Pour l'instant, je voudrais juste les mentionner ici, car chaque point vaut un article séparé.
- , , .
- . , .
- IF-ELSE ML. - : «ML — ». , ML, , . , , .
- .
- (true positive) . — , . , , — . , , .
- , .
- : , () .
- Enfin et surtout. Nous devons créer une plate-forme complète de validation des performances sur laquelle nous pouvons analyser nos modèles. [4]