Tout le monde a son livre préféré sur la magie. Quelqu'un est Tolkien, quelqu'un est Pratchett, quelqu'un, comme moi, c'est Max Fry. Aujourd'hui, je vais vous parler de ma magie informatique préférée - BPF et l'infrastructure moderne qui l'entoure.
BPF est à son apogée en ce moment. La technologie se développe à pas de géant, pénètre dans les endroits les plus inattendus et devient de plus en plus accessible à l'utilisateur moyen. À presque toutes les conférences populaires d'aujourd'hui, vous pouvez entendre un rapport sur ce sujet, et GopherCon Russie ne fait pas exception: je vous présente une version texte de mon rapport .
Il n'y aura pas de découvertes uniques dans cet article. Je vais simplement essayer de vous montrer ce qu'est BPF, ce qu'il peut faire et comment il peut vous aider personnellement. Nous examinerons également les fonctionnalités liées à Go.
Après avoir lu mon article, j'aimerais vraiment que vos yeux s'illuminent de la même manière que les yeux d'un enfant qui a lu le livre Harry Potter pour la première fois, pour que vous rentriez à la maison ou que vous travailliez et que vous essayiez un nouveau «jouet» en action.
Qu'est-ce que eBPF?
Alors, de quel genre de magie un homme barbu de 34 ans aux yeux brûlants va-t-il vous parler?
Nous vivons avec vous en 2020. Si vous ouvrez Twitter, vous lirez les tweets de messieurs grincheux qui prétendent que le logiciel est maintenant écrit d'une qualité si terrible qu'il est plus facile de tout jeter et de recommencer. Certains menacent même de quitter le métier, car ils n'en peuvent plus: tout se décompose constamment, incommode, lent.
Peut-être ont-ils raison: sans mille commentaires, nous ne le saurons pas. Mais ce avec quoi je serai définitivement d'accord, c'est que la pile logicielle moderne est plus complexe que jamais.
BIOS, EFI, système d'exploitation, pilotes, modules, bibliothèques, mise en réseau, bases de données, caches, orchestrateurs comme K8, conteneurs comme Docker, enfin, notre logiciel avec des runtimes et des garbage collector. Un vrai professionnel peut répondre à la question de savoir ce qui se passe après avoir tapé ya.ru dans votre navigateur pendant plusieurs jours.
Il est très difficile de comprendre ce qui se passe dans votre système, surtout si quelque chose ne va pas en ce moment et que vous perdez de l'argent. Ce problème a conduit à l'émergence de lignes métiers conçues pour vous aider à comprendre ce qui se passe à l'intérieur de votre système. Les grandes entreprises ont des départements Sherlock entiers qui savent où marteler et quel écrou serrer pour économiser des millions de dollars.
Dans les entretiens, je demande souvent aux gens comment ils vont résoudre les problèmes s'ils sont réveillés à quatre heures du matin.
Une approche consiste à analyser les journaux . Mais le problème est que seuls ceux que le développeur a mis dans son système sont disponibles. Ils ne sont pas flexibles.
La deuxième approche populaire consiste à étudier les métriques . Les trois systèmes les plus utilisés pour travailler avec des métriques sont écrits en Go. Les métriques sont très utiles, mais elles ne vous aident pas toujours à comprendre les causes en vous permettant de voir les symptômes.
La troisième approche qui gagne en popularité est la soi-disant observabilité: la capacité à poser des questions arbitrairement complexes sur le comportement du système et à y trouver des réponses. Comme la question peut être très complexe, la réponse peut nécessiter une grande variété d'informations, et tant que la question n'est pas posée, nous ne savons pas quoi. Cela signifie que la flexibilité est vitale pour l'observabilité.
Offrez-vous la possibilité de modifier le niveau d'enregistrement à la volée? Se connecter avec un débogueur à un programme en cours d'exécution et y faire quelque chose sans interrompre son travail? Comprendre quelles requêtes arrivent dans le système, visualiser les sources des requêtes lentes, voir sur quelle mémoire est dépensée via pprof et obtenir un graphique de son évolution au fil du temps? Mesurer la latence d'une fonction et la dépendance de la latence aux arguments? Toutes ces approches, je ferai référence à l'observabilité. Il s'agit d'un ensemble d'utilités, d'approches, de connaissances, d'expérience, qui ensemble vous donneront la possibilité de faire, sinon tout, alors beaucoup de «profit», directement dans le système de travail. Couteau informatique suisse moderne.

Mais comment cela peut-il se faire? Il y avait et il y a de nombreux instruments sur le marché: simples, complexes, dangereux, lents. Mais le sujet de l'article d'aujourd'hui est BPF.
Le noyau Linux est piloté par les événements. Presque tout ce qui se passe dans le noyau, et dans le système dans son ensemble, peut être représenté comme un ensemble d'événements. L'interruption est un événement, la réception d'un paquet sur le réseau est un événement, le transfert d'un processeur vers un autre processus est un événement, le lancement d'une fonction est un événement.
Ainsi, BPF est un sous-système du noyau Linux qui permet d'écrire de petits programmes qui seront lancés par le noyau en réponse à des événements. Ces programmes peuvent à la fois éclairer ce qui se passe dans votre système et le contrôler.
C'était une très longue introduction. Rapprochons-nous de la réalité.
1994 a vu la première version de BPF, que certains d'entre vous ont peut-être rencontrée lors de l'écriture de règles simples permettant à l'utilitaire tcpdump de visualiser ou de détecter les paquets réseau. tcpdump pourrait définir des "filtres" pour ne pas voir tous, mais uniquement les paquets qui vous intéressent. Par exemple, "uniquement le protocole TCP et uniquement le port 80". Pour chaque paquet passant, une fonction a été exécutée pour décider de sauvegarder ou non ce paquet particulier. Il peut y avoir beaucoup de packages, ce qui signifie que notre fonction doit être très rapide. Nos filtres tcpdump venaient d'être convertis en fonctions BPF, dont un exemple est montré dans l'image ci-dessous.
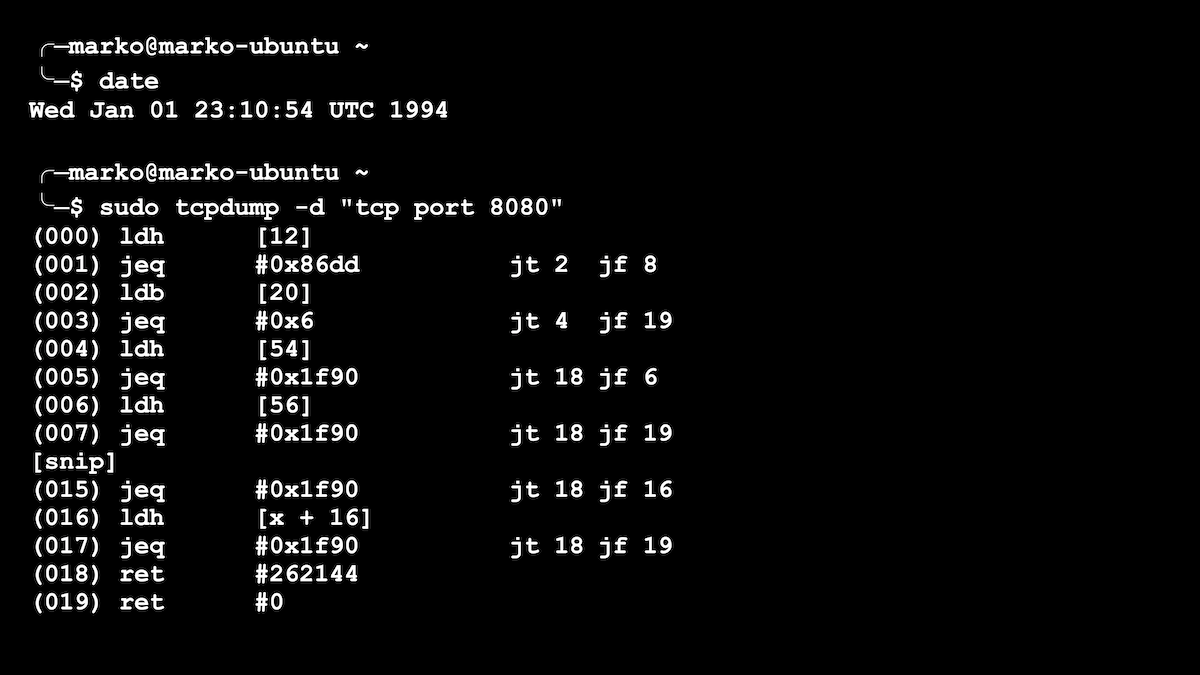
Un simple filtre pour tcpdump est présenté comme un programme BPF
Le BPF original était une machine virtuelle très simple avec plusieurs registres. Mais, néanmoins, BPF a considérablement accéléré le filtrage des paquets réseau. À un moment donné, c'était un grand pas en avant.

En 2014, Alexey Starovoitov a étendu la fonctionnalité BPF. Il a augmenté le nombre de registres et la taille autorisée du programme, ajouté la compilation JIT et créé un vérificateur qui a vérifié la sécurité des programmes. Mais le plus impressionnant était que de nouveaux programmes BPF pouvaient être lancés non seulement lors du traitement des paquets, mais aussi en réponse à de nombreux événements du noyau, et passer des informations dans les deux sens entre le noyau et l'espace utilisateur.
Ces changements ont ouvert la voie à de nouveaux cas d'utilisation pour BPF. Certaines choses qui étaient auparavant effectuées en écrivant des modules de noyau complexes et dangereux sont maintenant relativement faciles à faire via BPF. Pourquoi est-ce cool? Car toute erreur lors de l'écriture d'un module conduit souvent à la panique. Pas à la panique moelleuse de Go-shnoy, mais à la panique du noyau, après quoi - redémarrez seulement.
L'utilisateur Linux moyen a maintenant une capacité surpuissante à regarder sous le capot, auparavant uniquement disponible pour les développeurs de noyau hardcore ou n'importe qui d'autre. Cette option est comparable à la possibilité d'écrire sans effort un programme pour iOS ou Android: sur les téléphones plus anciens, c'était soit impossible, soit beaucoup plus difficile.
La nouvelle version de BPF d'Alexey s'appelle eBPF (du mot étendu - étendu). Mais maintenant, il a remplacé toutes les anciennes versions de BPF et est devenu si populaire que tout le monde l'appelle simplement BPF pour plus de simplicité.
Où BPF est-il utilisé?
Alors, quels sont ces événements, ou déclencheurs, auxquels les programmes BPF peuvent être attachés, et comment les gens ont-ils commencé à exploiter ce nouveau pouvoir?
Il existe actuellement deux grands groupes de déclencheurs.
Le premier groupe est utilisé pour traiter les paquets réseau et pour gérer le trafic réseau. Ce sont XDP, les événements de contrôle du trafic et quelques autres.
Ces événements sont nécessaires pour:
- , . Cloudflare Facebook BPF- DDoS-. ( BPF- ), . .
- , , — , , . . Facebook, , , .
- Construisez des équilibreurs intelligents. L'exemple le plus marquant est le projet Cilium , qui est le plus souvent utilisé dans le cluster K8 en tant que réseau maillé. Cilium gère le trafic: équilibre, redirige et analyse. Et tout cela se fait à l'aide de petits programmes BPF lancés par le noyau en réponse à l'un ou l'autre événement lié aux paquets ou sockets réseau.
Il s'agissait du premier groupe de déclencheurs associés à des problèmes en réseau avec la capacité d'influencer le comportement. Le deuxième groupe est lié à l'observabilité plus générale; les programmes de ce groupe n'ont le plus souvent pas la capacité d'influencer quelque chose, mais peuvent seulement «observer». Elle m'intéresse beaucoup plus.
Ce groupe contient des déclencheurs tels que:
- perf events — , Linux- perf: , , minor/major- . . , , , - . , , , , .
- tracepoints — ( ) , (, ). , — , , , , . - , tracepoints :
- ;
- , ;
- API, , , , , API.
, , , , , pprof .
- ;
- USDT — , tracepoints, user space-. . : MySQL, , PHP, Python. enable-dtrace . , Go . -, , DTrace . , , Solaris: , , GC -, .
Eh bien, alors un autre niveau de magie commence:
- Les déclencheurs ftrace nous donnent la possibilité d'exécuter un programme BPF au début de presque toutes les fonctions du noyau. Entièrement dynamique. Cela signifie que le noyau appellera votre fonction BPF avant que toute fonction du noyau que vous choisissez ne commence à s'exécuter. Ou toutes les fonctions du noyau - peu importe. Vous pouvez vous attacher à toutes les fonctions du noyau et obtenir une belle visualisation de tous les appels dans la sortie.
- kprobes / uprobes donnent presque la même chose que ftrace, seulement nous avons la possibilité de nous accrocher à n'importe quel endroit lors de l'exécution d'une fonction, à la fois dans le noyau et dans l'espace utilisateur. Au milieu de la fonction, il y a une sorte de if sur une variable et vous devez tracer un histogramme des valeurs de cette variable? Pas de problème.
- kretprobes/uretprobes — , user space. , , . , , PID fork.
La chose la plus remarquable à propos de tout cela, je le répète, est que, étant appelé sur l'un de ces déclencheurs, notre programme BPF peut jeter un bon coup d'œil: lire les arguments de fonction, chronométré, lire les variables, les variables globales, prendre une trace de pile, enregistrer cela puis pour plus tard, transférez les données vers l'espace utilisateur pour traitement, récupérez les données de l'espace utilisateur pour filtrage ou certaines commandes de contrôle. Beauté!
Je ne sais pas pour vous, mais pour moi la nouvelle infrastructure est comme un jouet que j’attends anxieusement depuis longtemps.
API, ou comment l'utiliser
Ok, Marco, tu nous as persuadé de regarder vers BPF. Mais comment l'aborder?
Voyons en quoi consiste un programme BPF et comment interagir avec lui.

Tout d'abord, nous avons un programme BPF qui, s'il est vérifié, sera chargé dans le noyau. Là, il sera compilé JIT en code machine et exécuté en mode noyau lorsque le déclencheur auquel il est attaché se déclenche.
Le programme BPF a la capacité d'interagir avec la deuxième partie - le programme d'espace utilisateur. Il y a deux façons de faire ça. Nous pouvons écrire dans un tampon circulaire, et la partie de l'espace utilisateur peut y lire. Nous pouvons également écrire et lire dans le stockage clé-valeur, qui s'appelle la carte BPF, et la partie espace utilisateur, respectivement, peut faire de même et, en conséquence, ils peuvent se transférer des informations.
Chemin droit
Le moyen le plus simple de travailler avec BPF, qui ne doit en aucun cas commencer, est d'écrire des programmes BPF similaires au langage C et de compiler ce code à l'aide du compilateur Clang en code de machine virtuelle. Nous chargeons ensuite ce code à l'aide de l'appel système BPF directement et interagissons avec notre programme BPF en utilisant également l'appel système BPF.
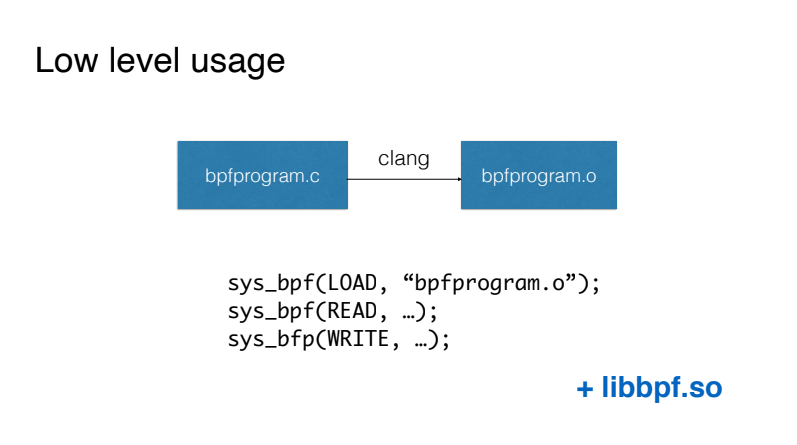
La première simplification disponible consiste à utiliser la bibliothèque libbpf, qui est fournie avec les sources du noyau et vous permet de ne pas travailler directement avec l'appel système BPF. En fait, il fournit des wrappers pratiques pour le chargement de code, fonctionnant avec ce que l'on appelle des cartes pour transférer des données du noyau vers l'espace utilisateur et inversement.
cci
Il est clair qu'une telle utilisation est loin d'être respectueuse de l'homme. Heureusement, sous la marque iovizor, le projet BCC est apparu, ce qui nous simplifie grandement la vie.

En fait, il prépare tout l'environnement d'assemblage et nous donne la possibilité d'écrire des programmes BPF uniques, où la partie C sera automatiquement assemblée et chargée dans le noyau, et la partie de l'espace utilisateur peut être réalisée en Python simple et compréhensible.
bpftrace
Mais BCC semble compliqué pour beaucoup de choses. Pour une raison quelconque, les gens n'aiment surtout pas écrire des parties en C.Les
mêmes gars d'iovizor ont introduit l'outil bpftrace, qui vous permet d'écrire des scripts BPF dans un langage de script simple à la AWK (ou généralement des one-liners).

Brendan Gregg, expert renommé en performance et observabilité, a préparé la visualisation suivante des méthodes disponibles pour travailler avec BPF:

Verticalement, nous avons la simplicité de l'outil, et horizontalement, sa puissance. On peut voir que BCC est un outil très puissant, mais pas super simple. bpftrace est beaucoup plus simple, mais il est moins puissant.
Exemples d'utilisation de BPF
Mais regardons les capacités magiques qui sont devenues disponibles pour nous, avec des exemples spécifiques.
BCC et bpftrace contiennent tous deux un dossier Tools, qui contient un grand nombre de scripts prêts à l'emploi intéressants et utiles. Ils sont également le débordement de pile local à partir duquel vous pouvez copier des morceaux de code pour vos scripts.
Par exemple, voici un script qui montre la latence des requêtes DNS:
╭─marko@marko-home ~
╰─$ sudo gethostlatency-bpfcc
TIME PID COMM LATms HOST
16:27:32 21417 DNS Res~ver #93 3.97 live.github.com
16:27:33 22055 cupsd 7.28 NPI86DDEE.local
16:27:33 15580 DNS Res~ver #87 0.40 github.githubassets.com
16:27:33 15777 DNS Res~ver #89 0.54 github.githubassets.com
16:27:33 21417 DNS Res~ver #93 0.35 live.github.com
16:27:42 15580 DNS Res~ver #87 5.61 ac.duckduckgo.com
16:27:42 15777 DNS Res~ver #89 3.81 www.facebook.com
16:27:42 15777 DNS Res~ver #89 3.76 tech.badoo.com :-)
16:27:43 21417 DNS Res~ver #93 3.89 static.xx.fbcdn.net
16:27:43 15580 DNS Res~ver #87 3.76 scontent-frt3-2.xx.fbcdn.net
16:27:43 15777 DNS Res~ver #89 3.50 scontent-frx5-1.xx.fbcdn.net
16:27:43 21417 DNS Res~ver #93 4.98 scontent-frt3-1.xx.fbcdn.net
16:27:44 15580 DNS Res~ver #87 5.53 edge-chat.facebook.com
16:27:44 15777 DNS Res~ver #89 0.24 edge-chat.facebook.com
16:27:44 22099 cupsd 7.28 NPI86DDEE.local
16:27:45 15580 DNS Res~ver #87 3.85 safebrowsing.googleapis.com
^C%
L'utilitaire affiche le temps d'exécution des requêtes DNS en temps réel afin que vous puissiez détecter, par exemple, des valeurs aberrantes inattendues.
Et c'est un script qui "espionne" ce que les autres tapent sur leurs terminaux:
╭─marko@marko-home ~
╰─$ sudo bashreadline-bpfcc
TIME PID COMMAND
16:51:42 24309 uname -a
16:52:03 24309 rm -rf src/badooCe type de script peut être utilisé pour attraper un mauvais voisin ou auditer la sécurité des serveurs d'une entreprise.
Script pour afficher les appels de flux de langages de haut niveau:
╭─marko@marko-home ~/tmp
╰─$ sudo /usr/sbin/lib/uflow -l python 20590
Tracing method calls in python process 20590... Ctrl-C to quit.
CPU PID TID TIME(us) METHOD
5 20590 20590 0.173 -> helloworld.py.hello
5 20590 20590 0.173 -> helloworld.py.world
5 20590 20590 0.173 <- helloworld.py.world
5 20590 20590 0.173 <- helloworld.py.hello
5 20590 20590 1.174 -> helloworld.py.hello
5 20590 20590 1.174 -> helloworld.py.world
5 20590 20590 1.174 <- helloworld.py.world
5 20590 20590 1.174 <- helloworld.py.hello
5 20590 20590 2.175 -> helloworld.py.hello
5 20590 20590 2.176 -> helloworld.py.world
5 20590 20590 2.176 <- helloworld.py.world
5 20590 20590 2.176 <- helloworld.py.hello
6 20590 20590 3.176 -> helloworld.py.hello
6 20590 20590 3.176 -> helloworld.py.world
6 20590 20590 3.176 <- helloworld.py.world
6 20590 20590 3.176 <- helloworld.py.hello
6 20590 20590 4.177 -> helloworld.py.hello
6 20590 20590 4.177 -> helloworld.py.world
6 20590 20590 4.177 <- helloworld.py.world
6 20590 20590 4.177 <- helloworld.py.hello
^C%Cet exemple montre la pile d'appels d'un programme Python.
Le même Brendan Gregg a fait une image dans laquelle il a rassemblé tous les scripts existants avec des flèches indiquant les sous-systèmes que chaque utilitaire permet "d'observer". Comme vous pouvez le voir, nous avons déjà un grand nombre d'utilitaires prêts à l'emploi disponibles - pour presque toutes les occasions.

N'essayez pas de repérer quelque chose ici. La photo est utilisée comme référence
Et nous avec Go?
Parlons maintenant de Go. Nous avons deux questions principales:
- Pouvez-vous écrire des programmes BPF dans Go?
- Est-il possible d'analyser les programmes écrits en Go?
Allons dans l'ordre.
À ce jour, le seul compilateur capable de compiler dans un format compris par le moteur BPF est Clang. Un autre compilateur populaire, GCC, n'a pas encore de backend BPF. Et le seul langage de programmation qui peut compiler vers BPF est une version très limitée de C.
Cependant, le programme BPF a une deuxième partie, qui se trouve dans l'espace utilisateur. Et cela peut être écrit en Go.
Comme je l'ai mentionné ci-dessus, BCC vous permet d'écrire cette partie en Python, qui est le langage principal de l'outil. Dans le même temps, dans le référentiel principal, BCC prend également en charge Lua et C ++, et dans un référentiel tiers, il prend également en charge Go .

Un tel programme ressemble exactement à un programme Python. Au début, il y a une ligne dans laquelle un programme BPF en C, puis nous disons où attacher ce programme et interagissons d'une manière ou d'une autre avec lui, par exemple, nous obtenons des données de la carte EPF.
En fait, c'est tout. Vous pouvez voir l'exemple plus en détail sur Github .
Le principal inconvénient est probablement que la bibliothèque C libbcc ou libbpf est utilisée pour le travail, et construire un programme Go avec une telle bibliothèque ne ressemble pas du tout à une belle promenade dans le parc.
En plus de iovisor / gobpf, j'ai trouvé trois autres projets en cours qui vous permettent d'écrire une partie userland dans Go.
- https://github.com/dropbox/goebpf
- https://github.com/cilium/ebpf
- https://github.com/andrewkroh/go-ebpf
La version Dropbox ne nécessite aucune bibliothèque C, mais vous devez créer vous-même la partie noyau du programme BPF en utilisant Clang, puis la charger dans le noyau avec le programme Go.
La version Cilium a les mêmes fonctionnalités que la version Dropbox. Mais cela vaut la peine de le mentionner, ne serait-ce que parce que cela est fait par les gars du projet Cilium, ce qui signifie qu'il est voué au succès.
J'ai apporté le troisième projet pour l'exhaustivité de l'image. Comme les deux précédents, il n'a pas de dépendances externes C, nécessite l'assemblage manuel d'un programme BPF C, mais ne semble pas très prometteur.
En fait, il y a une autre question: pourquoi écrire des programmes BPF en Go? Après tout, si vous regardez BCC ou bpftrace, les programmes BPF prennent généralement moins de 500 lignes de code. N'est-il pas plus facile d'écrire un script en bpftrace-language ou de découvrir un peu de Python? Je vois deux raisons ici.
Tout d'abord, vous aimez vraiment Go et préférez tout faire dessus. De plus, les programmes potentiellement Go sont plus faciles à porter d'une machine à l'autre: liaison statique, binaires simples, etc. Mais tout est loin d'être si évident, puisque nous sommes liés à un noyau spécifique. Je vais m'arrêter ici, sinon mon article s'étendra sur 50 pages supplémentaires.
La deuxième option: vous n'écrivez pas un simple script, mais un système à grande échelle qui utilise également BPF en interne. J'ai même un exemple d'un tel système dans Go :

Le projet Scope ressemble à un binaire qui, lorsqu'il est lancé dans l'infrastructure de K8 ou d'un autre cloud, analyse tout ce qui se passe autour, et montre quels sont les conteneurs, les services, comment ils interagissent, etc. Et une grande partie de cela se fait à l'aide de BPF. Un projet intéressant.
Analyse des programmes Go
Si vous vous en souvenez, nous avions encore une question: pouvons-nous analyser des programmes écrits en Go en utilisant BPF? Première pensée - bien sûr! Quelle différence cela fait-il dans la langue dans laquelle le programme est écrit? Après tout, ce n'est qu'un code compilé qui, comme tous les autres programmes, calcule quelque chose sur le processeur, mange de la mémoire comme si ce n'était pas en lui-même, interagit avec le matériel via le noyau et avec le noyau via des appels système. En principe, c'est correct, mais il existe des caractéristiques de différents niveaux de difficulté.
Passer des arguments
L'une des caractéristiques est que Go n'utilise pas l'ABI comme le font la plupart des autres langages. Il se trouve que les pères fondateurs ont décidé de prendre l'ABI du système Plan 9 , qu'ils connaissaient bien.
ABI est comme une API, un accord d'interopérabilité, uniquement au niveau des bits, des octets et du code machine.
Le principal élément ABI qui nous intéresse est la manière dont ses arguments sont passés à la fonction et la manière dont la réponse est renvoyée de la fonction. Alors que l'ABI standard x86-64 utilise des registres de processeur pour transmettre des arguments et des réponses, l'ABI Plan 9 utilise une pile pour cela.
Rob Pike et son équipe n'avaient pas prévu de créer un autre standard: ils disposaient déjà d'un compilateur C presque prêt à l'emploi pour le système Plan 9, aussi simple que deux-deux, qu'ils ont rapidement converti en compilateur pour Go. Approche d'ingénierie en action.
Mais ce n'est en fait pas un problème très critique. Premièrement, nous pourrions bientôt voir Go passer des arguments à travers des registres , et deuxièmement, obtenir des arguments de la pile à partir de BPF n'est pas difficile: l' alias sargX a déjà été ajouté à bpftrace , et la même chose apparaîtra dans BCC , très probablement dans un proche avenir ...
Mise à jour : à partir du moment où j'ai fait le rapport, même une proposition officielle détaillée pour la transition vers l'utilisation des registres dans l'ABI est apparue.
Identificateur de fil unique
La deuxième caractéristique a à voir avec la fonction préférée de Go, les goroutines. Une façon de mesurer la latence d'une fonction est d'économiser le temps nécessaire pour appeler la fonction, le temps de quitter la fonction et de calculer la différence; et enregistrez l'heure de début avec une touche contenant le nom de la fonction et le TID (numéro de filetage). Le numéro de thread est nécessaire, car la même fonction peut être appelée simultanément par différents programmes ou différents threads du même programme.

Mais dans Go, les goroutines marchent entre les threads du système: maintenant un goroutine est exécuté sur un thread, et un peu plus tard sur un autre. Et dans le cas de Go, nous ne mettrions pas le TID dans la clé, mais le GID, c'est-à-dire l'ID du goroutine, mais nous ne pouvons pas l'obtenir. Techniquement, cet identifiant existe. Vous pouvez même le sortir avec des hacks sales, car il se trouve quelque part sur la pile, mais cela est strictement interdit par les recommandations du groupe de développement clé Go. Ils ont estimé que nous n'aurions jamais besoin de telles informations. Ainsi que le stockage local Goroutine, mais je m'éloigne du sujet.
Élargir la pile
Le troisième problème est le plus grave. Si grave que même si nous résolvons en quelque sorte le deuxième problème, cela ne nous aidera en aucun cas à mesurer la latence des fonctions Go.
La plupart des lecteurs comprennent probablement bien ce qu'est une pile. La même pile, où, contrairement au tas ou au tas, vous pouvez allouer de la mémoire pour les variables et ne pas penser à les libérer.
Si nous parlons de C, alors la pile a une taille fixe. Si nous allons au-delà de cette taille fixe, le fameux débordement de pile se produira .
Dans Go, la pile est dynamique. Dans les anciennes versions, il s'agissait de blocs de mémoire concaténés. Il s'agit maintenant d'un morceau de taille dynamique continue. Cela signifie que si la pièce sélectionnée ne nous suffit pas, nous élargirons la pièce actuelle. Et si nous ne pouvons pas développer, nous en sélectionnons un autre plus grand et déplaçons toutes les données de l'ancien emplacement vers le nouveau. C'est une histoire sacrément fascinante qui touche aux garanties de sécurité, cgo, garbage collector, mais c'est un sujet pour un autre article.
Il est important de savoir que pour que Go déplace la pile, il doit parcourir la pile d'appels du programme, tous les pointeurs de la pile.
C'est là que réside le problème principal: les uretprobes, qui sont utilisées pour attacher une fonction BPF, modifient dynamiquement la pile à la fin de l'exécution de la fonction pour insérer un appel à leur gestionnaire, le soi-disant trampoline. Et un tel changement dans sa pile, inattendu pour Go, se termine dans la plupart des cas par un plantage du programme. Oups!

Cependant, cette histoire n'est pas unique. Le démêleur de "pile" C ++ plante également au moment de la gestion des exceptions.
Il n'y a pas de solution à ce problème. Comme d'habitude dans de tels cas, les parties échangent des arguments absolument raisonnables sur la culpabilité de l'autre.
Mais si vous avez vraiment besoin de mettre une sonde urétrale, le problème peut être contourné. Comment? Ne mettez pas de sonde urétrale. Nous pouvons mettre une uprobe à tous les endroits où nous quittons la fonction. Il peut y en avoir un, ou peut-être 50.

Et ici, l'unicité de Go joue entre nos mains.
Normalement, cette astuce ne fonctionnerait pas. Un compilateur assez intelligent peut faire ce que l'on appelle l'optimisation des appels de fin , quand au lieu de revenir d'une fonction et de revenir le long de la pile d'appels, nous sautons simplement au début de la fonction suivante. Ce type d'optimisation est essentiel pour les langages fonctionnels comme Haskell . Sans cela, ils n'auraient pas pu faire un pas sans débordement de pile. Mais avec une telle optimisation, nous ne pouvons tout simplement pas trouver tous les endroits où nous revenons de la fonction.
La particularité est que la version 1.14 du compilateur Go n'est pas encore capable de faire l'optimisation des appels de queue. Donc, l'astuce consistant à attacher à toutes les sorties explicites d'une fonction fonctionne, bien que très fastidieuse.
Exemples de
Ne pensez pas que BPF est inutile pour Go. C'est loin d'être le cas: nous pouvons faire tout le reste qui n'affecte pas les nuances ci-dessus. Et nous allons.
Jetons un coup d'œil à quelques exemples.
Prenons un programme simple pour la préparation. Fondamentalement, il s'agit d'un serveur Web qui écoute sur le port 8080 et dispose d'un gestionnaire de requêtes HTTP. Le gestionnaire obtiendra le paramètre name, le paramètre Go à partir de l'URL et effectuera une sorte de vérification du "site", puis enverra les trois variables (nom, année et état du contrôle) à la fonction prepareAnswer (), qui préparera une réponse sous forme de chaîne.

La validation du site est une requête HTTP qui vérifie si le site de la conférence est opérationnel à l'aide d'un tube et d'un goroutine. Et la fonction de préparation de la réponse transforme tout simplement en une chaîne lisible.
Nous allons déclencher notre programme avec une simple requête curl:

Comme premier exemple, nous utiliserons bpftrace pour imprimer tous les appels de fonction de notre programme. Nous nous attachons ici à toutes les fonctions qui relèvent de main. Dans Go, toutes vos fonctions ont un symbole qui ressemble au nom du package nom-point-fonction. Notre package est principal, et le runtime de la fonction serait runtime.

Quand je fais curl, le gestionnaire, la fonction de validation de site et la sous-fonction goroutine sont lancées, puis la fonction de préparation de réponse. Classe!
Ensuite, je veux non seulement afficher les fonctions en cours d'exécution, mais également leurs arguments. Prenons la fonction prepareAnswer (). Elle a trois arguments. Essayons d'imprimer deux int.
Nous prenons bpftrace, mais maintenant non pas un one-liner, mais un script. Nous nous attachons à notre fonction et utilisons les alias pour les arguments de pile que j'ai mentionnés.
Dans la sortie, nous voyons ce que nous avons passé en 2020, obtenu le statut 200 et une fois passé 2021.
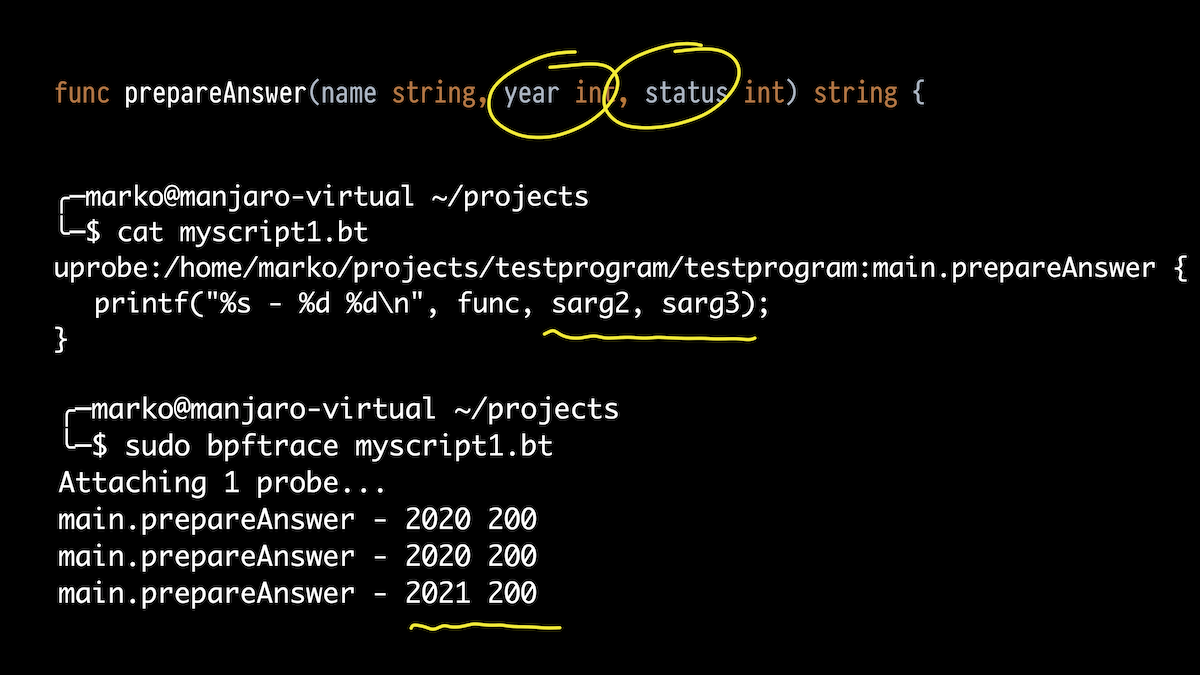
Mais la fonction a trois arguments. Le premier est une chaîne. Qu'en est-il de lui?
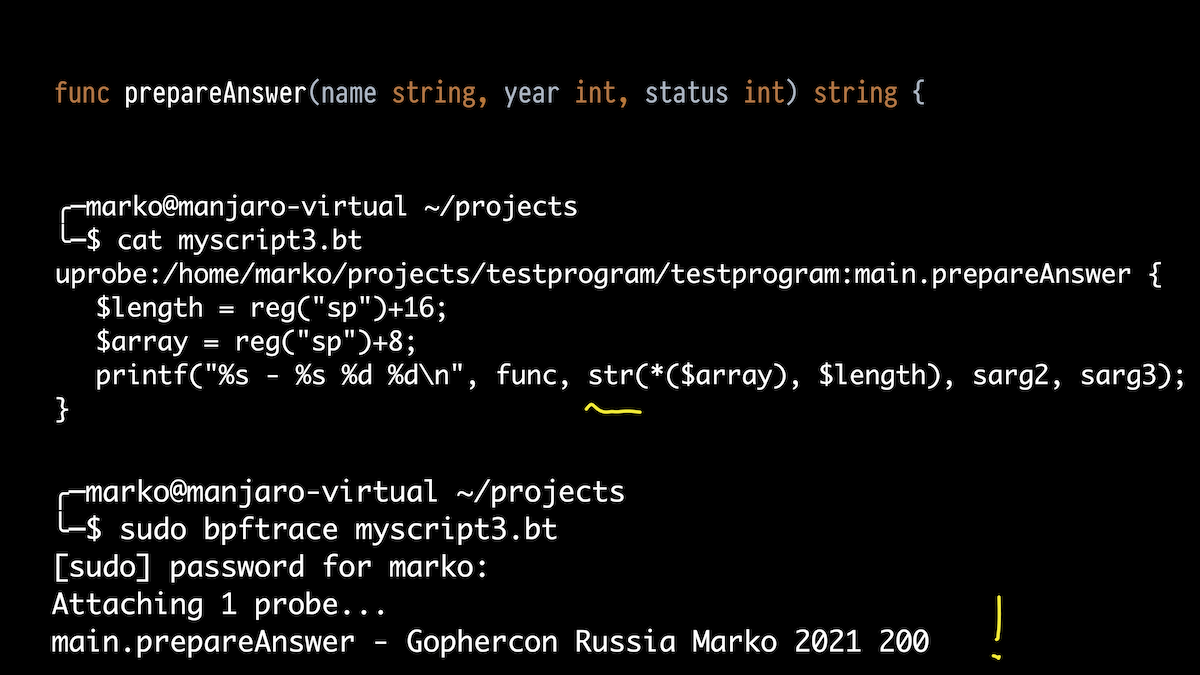
Imprimons simplement tous les arguments de la pile de 0 à 4. Et que voyons-nous? Un gros chiffre, un chiffre plus petit et nos anciens 2021 et 200. Quels sont ces chiffres étranges au début?

C'est là qu'il est utile de connaître l'appareil Go. Si en C une chaîne est juste un tableau de caractères terminé par un nul, alors en Go, une chaîne est en fait une structure composée d'un pointeur vers un tableau de caractères (non terminé par un nul, d'ailleurs) et d'une longueur.

Mais le compilateur Go, lorsqu'il est passé une chaîne comme argument, étend cette structure et la transmet comme deux arguments. Et il s'avère que le premier chiffre étrange n'est qu'un pointeur vers notre tableau, et le second est la longueur.
Et la vérité: la longueur attendue de la chaîne est de 22. En
conséquence, nous corrigeons un peu notre script pour obtenir ces deux valeurs via la pile de registres de pointeurs et le décalage correct, et en utilisant la fonction intégrée str (), nous le produisons sous forme de chaîne. Tout fonctionne:
Eh bien, jetons un coup d'œil à l'exécution. Par exemple, je voulais savoir quelles goroutines notre programme lance. Je sais que les goroutines sont déclenchées par les fonctions newproc () et newproc1 (). Connectons-nous à eux. Le premier argument de la fonction newproc1 () est un pointeur vers la structure funcval, qui n'a qu'un seul champ - un pointeur de fonction:
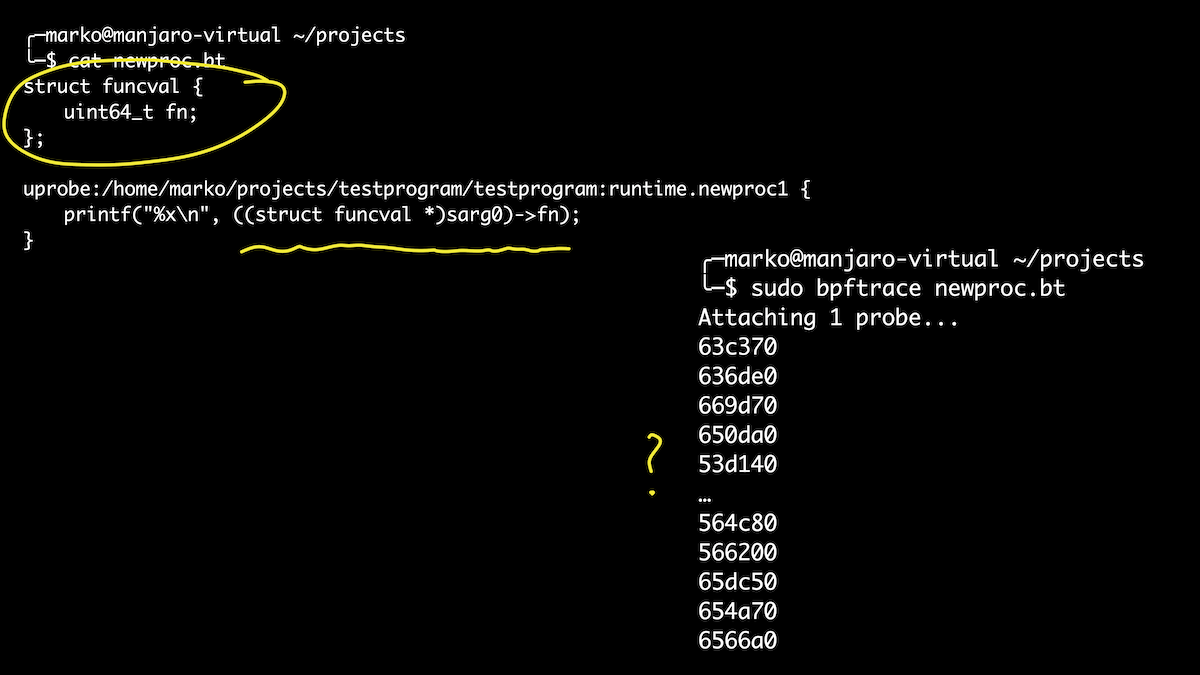
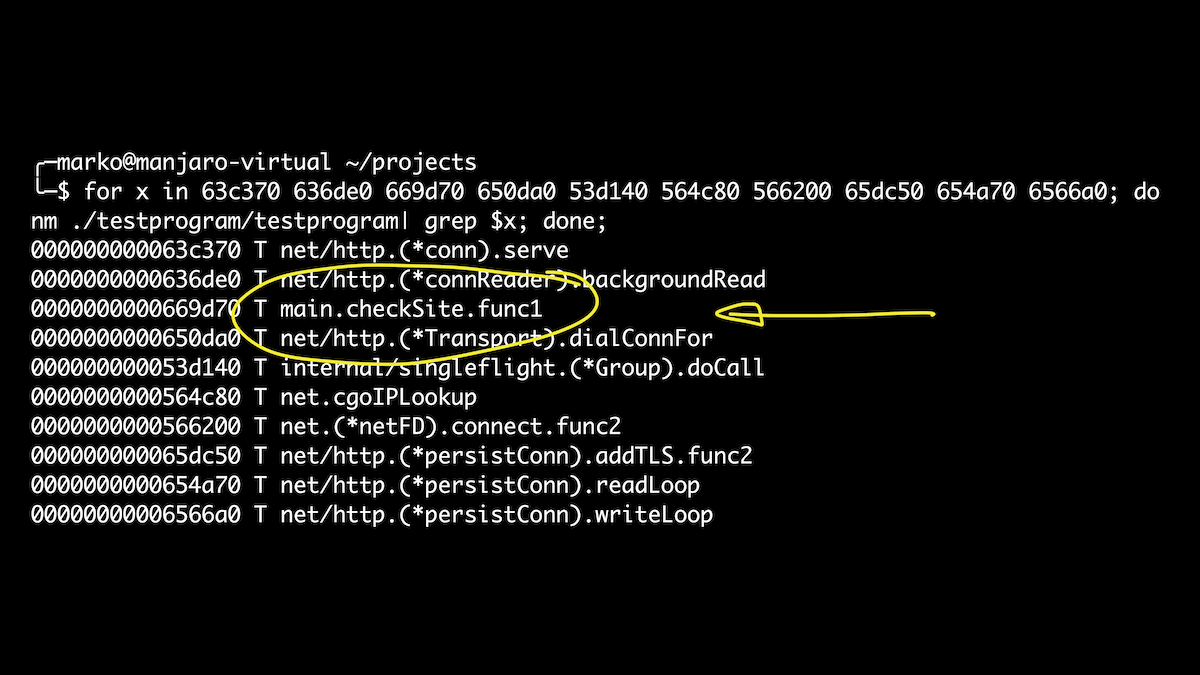
Dans ce cas, nous en profiterons pour définir des structures directement dans le script. C'est un peu plus facile que de jouer avec des sets offset. Ici, nous avons sorti toutes les goroutines qui sont lancées lorsque notre gestionnaire est appelé. Et si après cela nous obtenons les noms des symboles pour nos décalages, alors juste parmi eux, nous verrons notre fonction checkSite. Hourra!
Ces exemples sont une goutte d'eau dans l'océan des capacités BPF, BCC et bpftrace. Avec une bonne connaissance des éléments internes et de l'expérience, vous pouvez obtenir presque toutes les informations d'un programme en cours d'exécution sans l'arrêter ni le modifier.
Conclusion
C'est tout ce que je voulais vous dire. J'espère avoir pu vous inspirer.
BPF est l'une des tendances les plus tendances et les plus prometteuses de Linux. Et je suis sûr que dans les années à venir, nous verrons des choses beaucoup plus intéressantes non seulement dans la technologie elle-même, mais aussi dans les outils et sa distribution.
Avant qu'il ne soit trop tard et que tout le monde ne connaisse pas BPF, jouez avec, devenez magiciens, résolvez des problèmes et aidez vos collègues. Ils disent que les tours de magie ne fonctionnent qu'une seule fois.
Quant à Go, nous nous sommes avérés, comme d'habitude, assez uniques. On a toujours quelques nuances: soit le compilateur est différent, puis l'ABI, il faut une sorte de GOPATH, un nom qui ne peut pas être Google. Mais nous sommes devenus une force avec laquelle il faut compter, et je crois que la vie ne fera que s'améliorer.