
L'un des premiers avertissements qu'un jeune Padawan reçoit avec l'accès aux dépôts git est: "ne
git push -f." Étant donné que c'est l'une des centaines de maximes qu'un ingénieur logiciel novice doit apprendre, personne ne prend le temps de clarifier pourquoi cela ne devrait pas être fait. C'est comme les bébés et le feu: "les allumettes ne sont pas des jouets pour enfants" et c'est tout. Mais nous grandissons et nous nous développons en tant que personnes et en tant que professionnels, et un jour la question "pourquoi, en fait?" monte en pleine croissance. Cet article est rédigé sur la base de notre rencontre interne, sur le thème: "Quand pouvez-vous et devez-vous réécrire l'historique des commits?"

J'ai entendu dire que la capacité de répondre à cette question lors d'une entrevue dans certaines entreprises est un critère pour les entrevues pour des postes de direction. Mais pour mieux comprendre la réponse, vous devez comprendre pourquoi la réécriture de l'histoire est mauvaise du tout?
Pour ce faire, nous avons besoin d'une excursion rapide dans la structure physique du référentiel git. Si vous êtes sûr de tout savoir sur le périphérique de repo, vous pouvez ignorer cette partie, mais même en cours de recherche, j'ai appris beaucoup de nouvelles choses par moi-même, et quelque chose de vieux s'est avéré pas tout à fait pertinent.
Au niveau le plus bas, un dépôt git est une collection d'objets et de pointeurs vers eux. Chaque objet a son propre hachage unique de 40 caractères (20 octets hexadécimaux), qui est calculé en fonction du contenu de l'objet.
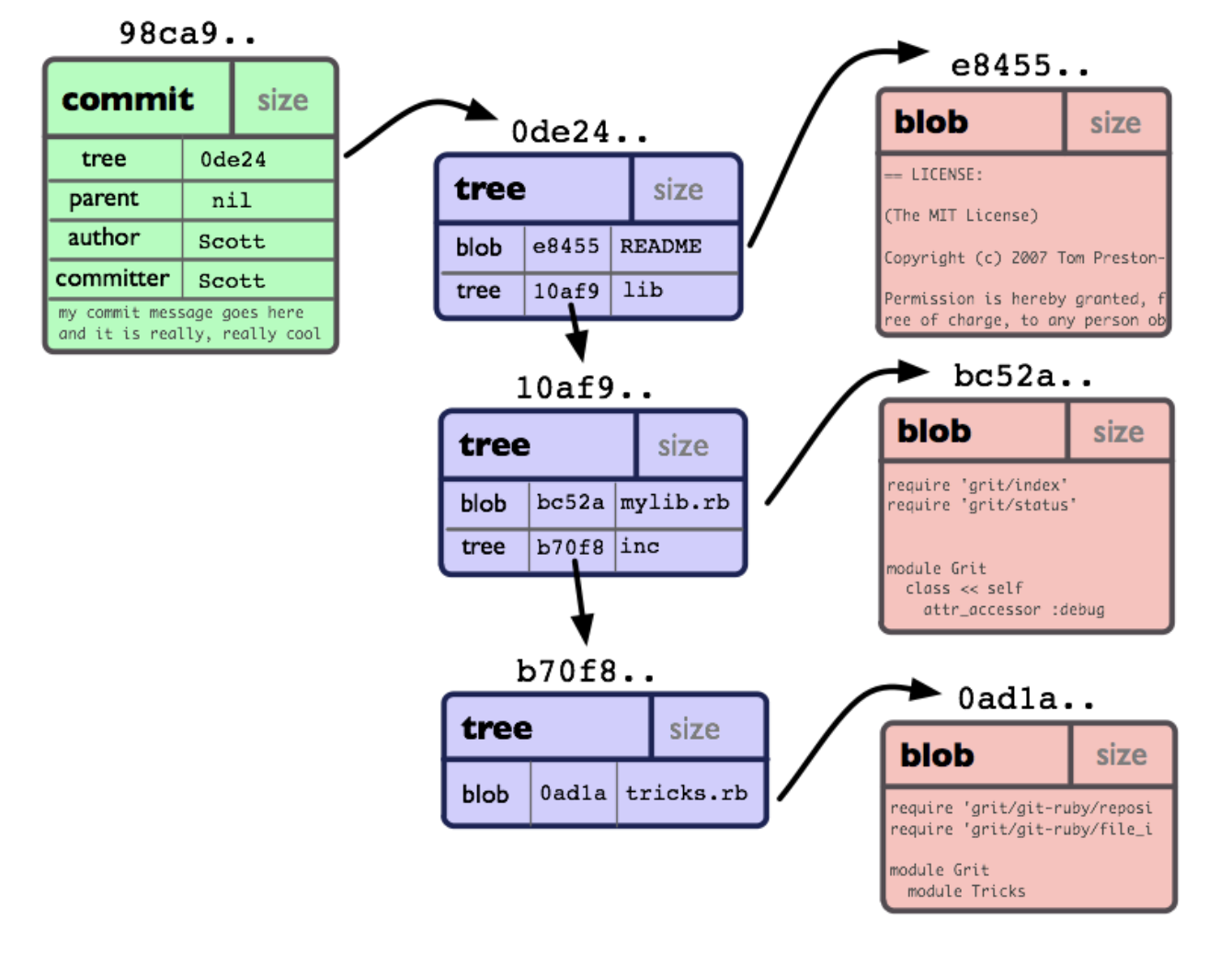
Illustration tirée du livre de la communauté Git
Les principaux types d'objets sont blob (juste le contenu d'un fichier), tree (une collection de pointeurs vers des blobs et autres arbres) et commit. Un objet de type commit n'est qu'un pointeur vers l'arborescence, vers le commit précédent et les informations de service: date / heure, auteur et commentaire.
Où sont les branches et les balises avec lesquelles nous travaillions? Et ce ne sont pas des objets, ce ne sont que des pointeurs: une branche pointe vers le dernier commit, une balise pointe vers un commit arbitraire dans le dépôt. C'est-à-dire que lorsque nous voyons des branches magnifiquement dessinées avec des cercles de validation sur elles dans l'IDE ou le client GUI, elles sont construites à la volée, courant le long des chaînes de validation depuis les extrémités des branches jusqu'à la «racine». Le tout premier commit du dépôt n'a pas de précédent, au lieu d'un pointeur, il est nul.
Un point important à comprendre: le même commit peut apparaître dans plusieurs branches en même temps. Les commits ne sont pas copiés lorsqu'une nouvelle branche est créée, elle commence simplement à "croître" à partir de l'endroit où HEAD était au moment où la commande a été émise
git checkout -b <branch-name>.
Alors pourquoi la réécriture de l'histoire d'un référentiel est-elle nuisible?

Tout d'abord, et cela est évident, lorsque vous téléchargez une nouvelle histoire dans le référentiel avec lequel l'équipe d'ingénierie travaille, d'autres personnes risquent de perdre leurs modifications. La commande
git push -f supprime de la branche sur le serveur tous les commits qui ne sont pas dans la version locale et en écrit de nouveaux.
Pour une raison quelconque, peu de gens savent que depuis longtemps l'équipe
git pusha une clé «de sécurité»--force-with-leasece qui provoque l'échec de la commande si des validations sont ajoutées par d'autres utilisateurs au référentiel distant. Je recommande toujours de l'utiliser à la place -f/--force.
La deuxième raison pour laquelle la commande
git push -fest considérée comme nuisible est que lorsque vous essayez de fusionner une branche avec l'historique réécrit avec les branches où elle a été conservée (plus précisément, les commits supprimés de l'historique réécrit ont été préservés), nous obtiendrons un enfer d'un certain nombre de conflits (par le nombre s'engage, en fait). Il y a une réponse simple à cela: si vous suivez attentivement Gitflow ou Gitlab Flow , de telles situations ne se produiront probablement même pas.
Et enfin, il y a un côté désagréable de la réécriture de l'histoire: ces commits qui sont, pour ainsi dire, retirés de la branche, en fait, ne disparaissent nulle part et restent simplement à jamais suspendus dans le repo. Une bagatelle, mais désagréable. Heureusement, les développeurs git ont également résolu ce problème, avec la commande garbage collection
git gc --prune. La plupart des hôtes git, au moins GitHub et GitLab, le font en arrière-plan de temps en temps.
Ainsi, après avoir dissipé les craintes de changer l'histoire du référentiel, nous pouvons enfin passer à la question principale: pourquoi est-il nécessaire et quand est-il justifié?
En fait, je suis sûr que presque tous les utilisateurs git plus ou moins actifs ont changé l'historique au moins une fois, quand il s'est soudainement avéré que quelque chose s'est mal passé dans le dernier commit: une faute de frappe ennuyeuse s'est glissée dans le code, a fait un commit pas à partir de ça utilisateur (de l'e-mail personnel au lieu du travail ou vice versa), a oublié d'ajouter un nouveau fichier (si vous, comme moi, aimez utiliser
git commit -a). Même changer la description d'un commit conduit à la nécessité de le réécrire, car le hachage est également compté à partir de la description!
Mais c'est un cas trivial. Jetons un coup d'œil à ceux plus intéressants.
Disons que vous avez créé une fonctionnalité importante que vous avez sciée pendant plusieurs jours, en envoyant les résultats quotidiens du travail au référentiel sur le serveur (4-5 commits), et en envoyant vos modifications pour examen. Deux ou trois critiques infatigables vous ont donné de grandes et petites recommandations de modifications, ou même trouvé des jambages (4 à 5 autres commits). Ensuite, QA a trouvé plusieurs cas extrêmes qui nécessitent également des correctifs (2-3 commits supplémentaires). Et enfin, lors de l'intégration, des incompatibilités ont été découvertes ou des autotests sont entrés, qui doivent également être corrigés.
Si maintenant vous appuyez sur le bouton Fusionner sans regarder, alors une douzaine et demie de commits comme "Ma fonctionnalité, jour 1", "Jour 2", "Corriger les tests", "Corriger la révision" seront ajoutés à la branche principale (pour beaucoup, cela s'appelle maître à l'ancienne) etc. Ceci, bien sûr, aide le mode squash, qui est maintenant à la fois dans GitHub et GitLab, mais vous devez faire attention: premièrement, il peut remplacer la description du commit par quelque chose d'imprévisible, et deuxièmement, remplacer l'auteur de la fonctionnalité sur celui qui a appuyé sur le bouton Fusionner (dans notre pays, il s'agit généralement d'un robot aidant l'ingénieur de publication à construire le déploiement d'aujourd'hui). Par conséquent, le plus simple sera, avant l'intégration finale dans la version, de réduire tous les commits de la branche en un seul utilisant
git rebase.
Mais il arrive aussi que vous ayez déjà abordé la revue de code avec un historique de repo qui rappelle la salade d'Olivier. Cela se produit si une fonctionnalité scie depuis plusieurs semaines, parce qu'elle était mal décomposée ou, bien que des équipes décentes soient battues avec un candélabre pour cela, les exigences ont changé au cours du processus de développement. Par exemple, voici une vraie demande de fusion qui m'est venue pour un examen il y a deux semaines:
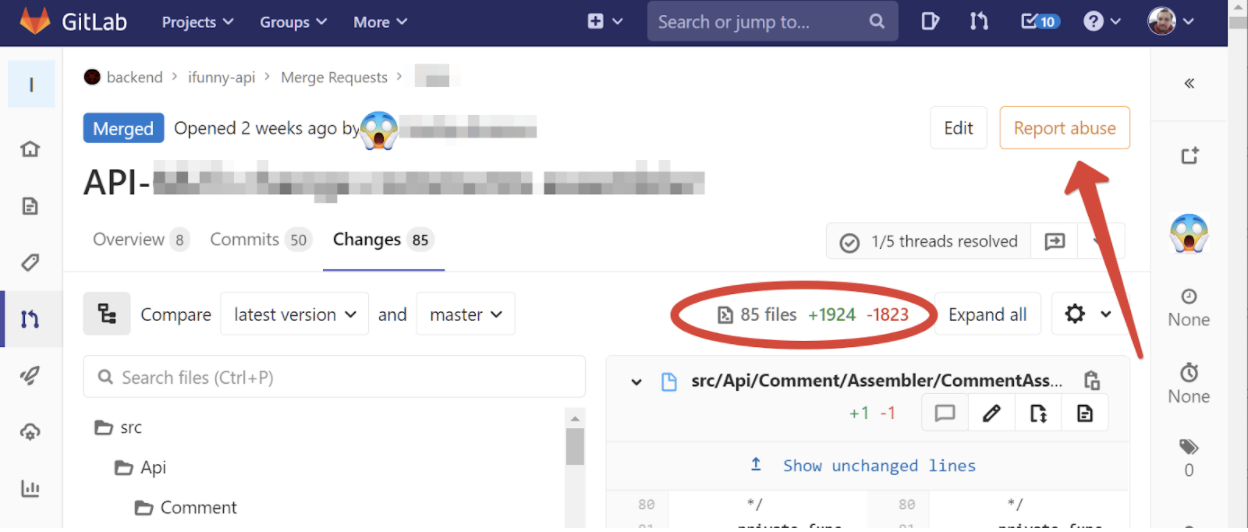
Ma main a automatiquement atteint le bouton "Signaler un abus", car comment caractériser autrement une demande avec 50 commits avec près de 2000 lignes modifiées? Et comment, se demande-t-on, le revoir?
Pour être honnête, il m'a fallu deux jours pour me forcer à commencer cet examen. Et c'est une réaction normale pour un ingénieur; quelqu'un dans une situation similaire, juste sans regarder, appuie sur Approuver, se rendant compte que dans un délai raisonnable, il ne pourra toujours pas faire le travail de révision de ce changement avec une qualité suffisante.
Mais il existe un moyen de faciliter la vie d'un ami. En plus des travaux préliminaires sur une meilleure décomposition du problème, une fois l'écriture du code principal terminée, vous pouvez amener l'historique de son écriture sous une forme plus logique, en le divisant en commits atomiques avec des tests verts dans chacun: "créé un nouveau service et une couche de transport pour lui", "construit des modèles et écrit vérification des invariants "," ajout de la validation et de la gestion des exceptions "," tests écrits ".
Chacun de ces commits peut être examiné séparément (GitHub et GitLab peuvent le faire) et le faire en raids lors du basculement entre les tâches ou pendant les pauses.
Le même
git rebaseavec la clé nous aidera à faire tout cela --interactive. En tant que paramètre, vous devez lui transmettre le hachage du commit, à partir duquel vous devrez réécrire l'historique. Si nous parlons des 50 derniers commits, comme dans l'exemple de l'image, vous pouvez écrire git rebase --interactive HEAD~50(remplacez votre nombre par «50»).
À propos, si vous avez ajouté la branche master à vous-même dans le processus de travail sur une tâche, vous devrez d'abord rebaser cette branche afin que les validations de fusion et les validations du maître ne soient pas confondues sous vos pieds.
Armé de la connaissance des éléments internes d'un référentiel git, il devrait être facile de comprendre comment rebase fonctionne sur master. Cette commande prend tous les commits de notre branche et remplace le parent du premier par le dernier commit de la branche master. Voir le diagramme: Les
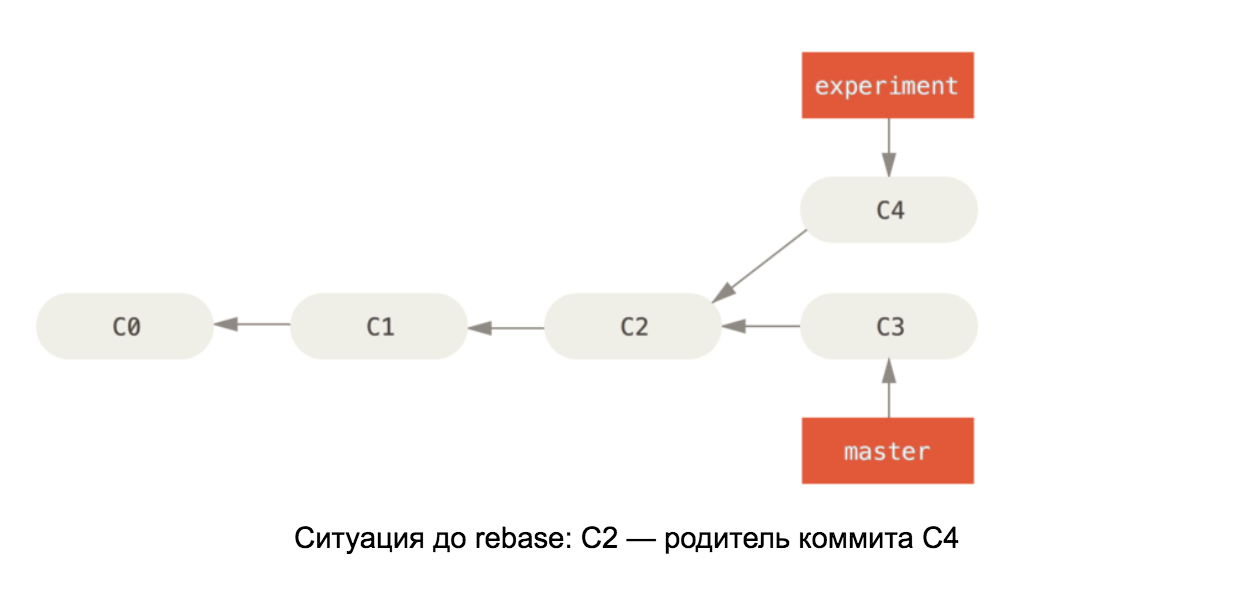
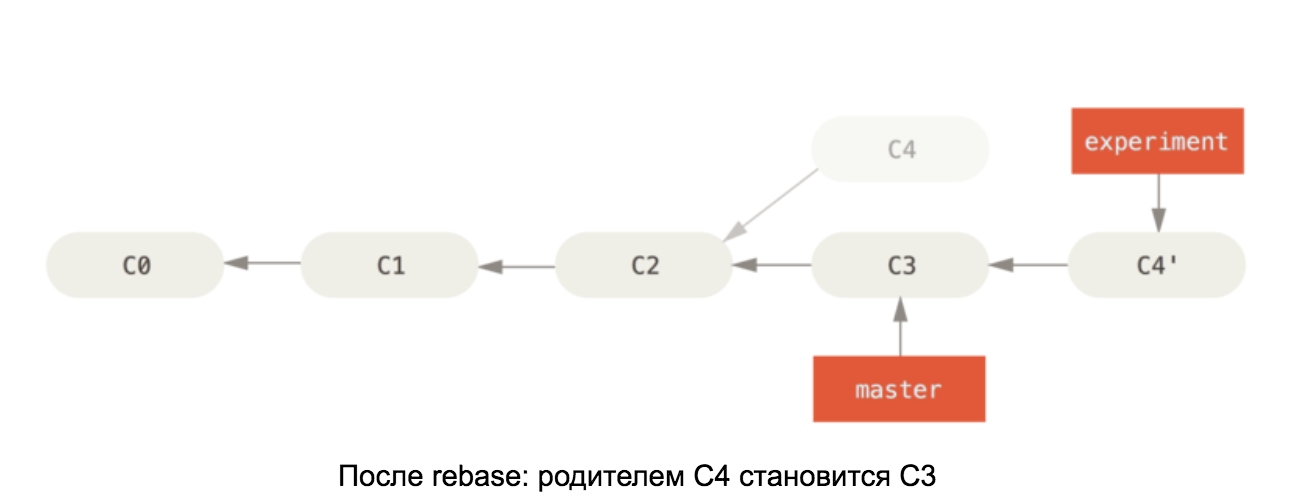
illustrations sont tirées du livre Pro Git
Si les changements en C4 et C3 sont en conflit, alors après avoir résolu les conflits, le commit C4 changera son contenu, il sera donc renommé dans le deuxième diagramme en C4 '.
De cette façon, vous vous retrouverez avec une branche composée uniquement de vos modifications et grandissant à partir du sommet du master. Bien sûr, le maître doit être à jour. Vous pouvez simplement utiliser la version du serveur:
git pull --rebase origin/master(comme vous le savez, c'est git pulléquivalent git fetch && git merge, et la clé --rebaseforcera git à rebaser au lieu de fusionner).
Revenons enfin à
git rebase --interactive... Il a été créé par des programmeurs pour des programmeurs, et en réalisant le stress que les gens vont subir au cours du processus, nous avons essayé de préserver le plus possible les nerfs de l'utilisateur et de le sauver du besoin de se fatiguer excessivement. Voici ce que vous verrez à l'écran:
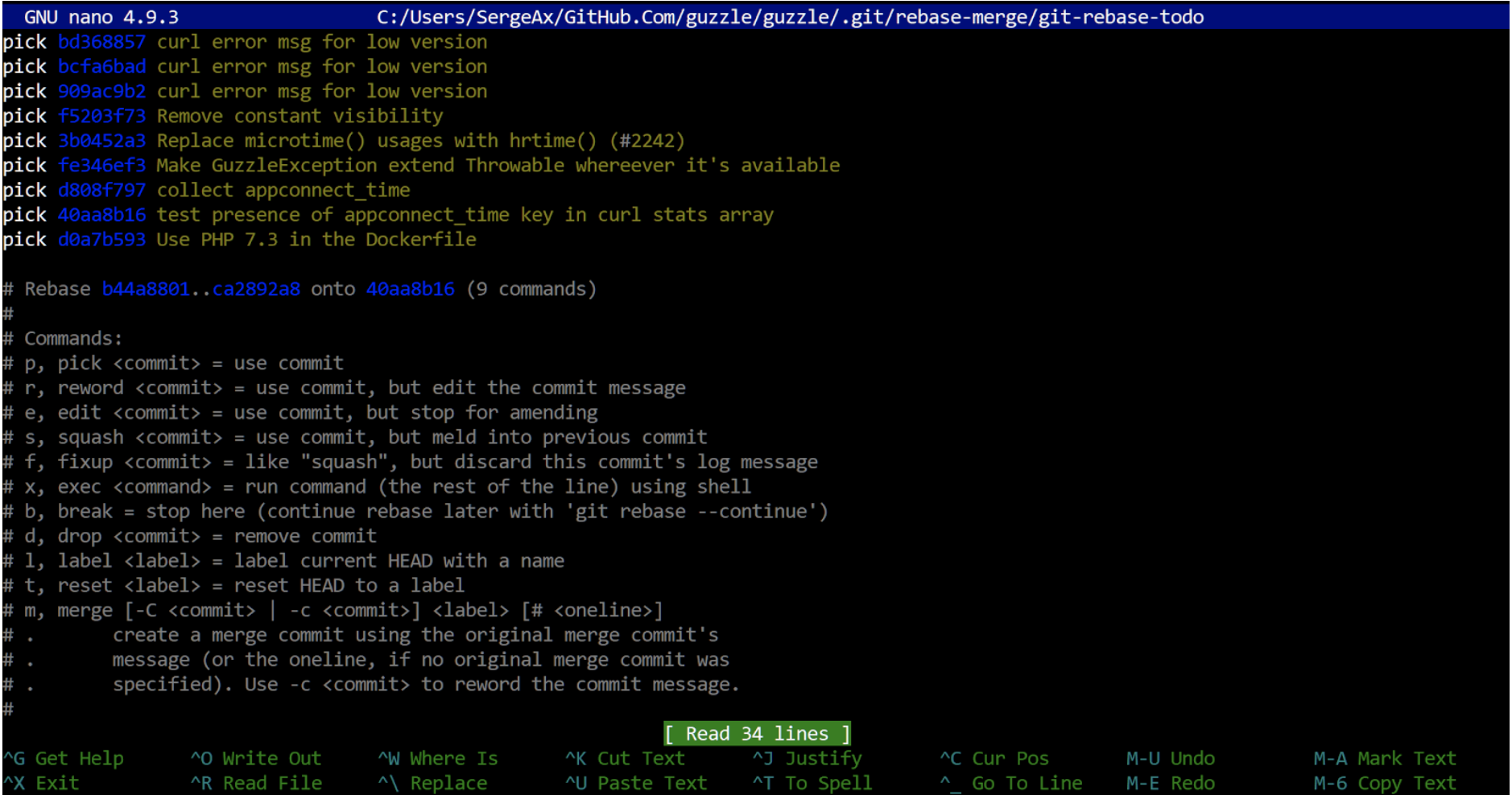
Il s'agit du référentiel du populaire package Guzzle. On dirait qu'un rebase lui serait utile ...
Le fichier généré s'ouvre dans un éditeur de texte. Vous trouverez ci-dessous des informations détaillées sur ce qu'il faut faire ici. Ensuite, en mode d'édition facile, vous décidez quoi faire des commits dans votre branche. Tout est aussi simple qu'un bâton: choisissez - laissez-le tel quel, reformulez - changez la description du commit, écrasez - fusionnez avec le précédent (le processus fonctionne de bas en haut, c'est-à-dire que le précédent est la ligne ci-dessous), déposez - supprimez complètement, éditez - et c'est la chose intéressante est de s'arrêter et de geler. Une fois que git rencontre la commande d'édition, il prendra la position où les modifications du commit ont déjà été ajoutées au mode par étapes. Vous pouvez changer quoi que ce soit dans ce commit, en ajouter quelques autres, puis commander
git rebase --continuede continuer le processus de rebase.
Oh, et au fait, vous pouvez échanger des commits. Cela peut créer des conflits, mais en général, le processus de rebase est rarement complètement sans conflit. Comme on dit, ayant enlevé la tête, ils ne pleurent pas pour leurs cheveux.
Si vous êtes confus et qu'il semble que tout est parti, vous disposez d'un bouton d'éjection d'urgence
git rebase --abortqui ramènera immédiatement tout à ce qu'il était.
Vous pouvez répéter le rebase plusieurs fois, en ne touchant que des parties de l'histoire et en laissant le reste intact avec le choix, donnant à votre histoire un aspect de plus en plus fini, comme une cruche de potier. C'est une bonne pratique, comme je l'ai écrit ci-dessus, de s'assurer que les tests de chaque commit seront verts (pour cela, éditer aide parfaitement et lors de la prochaine passe - squash).
Une autre voltige, utile au cas où vous auriez besoin de décomposer plusieurs changements dans le même fichier en différents commits -
git add --patch. Cela peut être utile en soi, mais en combinaison avec la directive edit, cela vous permettra de diviser un commit en plusieurs, et de le faire au niveau de lignes individuelles, ce qui, si je ne me trompe pas, aucun client GUI et aucun IDE ne le permettent.
Encore une fois en vous assurant que tout est en ordre, vous pouvez enfin en toute tranquillité d'esprit à faire quelque chose, ce qui a commencé ce tutoriel:
git push --force. Oh, bien sûr --force-with-lease!

Au début, vous passerez probablement une heure sur ce processus (y compris le rebase initial sur le maître), voire deux si la fonctionnalité se propage vraiment. Mais même cela est bien mieux que d'attendre deux jours que le critique se force à enfin répondre à votre demande, et encore quelques jours jusqu'à ce qu'il la fasse. À l'avenir, vous serez probablement en forme dans 30 à 40 minutes. Les produits IntelliJ avec un outil de résolution de conflits intégré (divulgation complète: FunCorp paie ces produits à ses employés) sont particulièrement utiles à cet égard.
La dernière chose contre laquelle je veux vous mettre en garde est de ne pas réécrire l'historique de la branche pendant la révision du code. N'oubliez pas qu'un réviseur consciencieux peut cloner votre code localement afin de pouvoir le consulter via l'EDI et exécuter des tests.
Merci à tous ceux qui ont lu jusqu'au bout! J'espère que cet article sera utile non seulement pour vous, mais aussi pour les collègues qui reçoivent votre code pour examen. Si vous avez des hacks git sympas, partagez-les dans les commentaires!