Depuis environ un an maintenant, notre division infrastructure migre tous les services exécutés sur GitLab.com vers Kubernetes. Pendant ce temps, nous avons rencontré des problèmes non seulement avec le déplacement des services vers Kubernetes, mais également avec la gestion du déploiement hybride pendant la transition. Les précieuses leçons que nous avons apprises seront discutées dans cet article.
Depuis le tout début de GitLab.com, ses serveurs ont fonctionné dans le cloud sur des machines virtuelles. Ces machines virtuelles sont gérées par Chef et installées à l'aide de notre package Linux officiel . La stratégie de déploiement dans le cas où une application doit être mise à jour consiste simplement à mettre à jour le parc de serveurs d'une manière séquentielle coordonnée à l'aide du pipeline CI. Cette méthode - bien que lente et un peu ennuyeuse - garantit que GitLab.com utilise les mêmes méthodes d'installation et de configuration que les utilisateurs d' installations GitLab autogérées utilisant nos packages Linux.
Nous utilisons cette méthode car il est extrêmement important de vivre toute la tristesse et les joies que les membres ordinaires de la communauté éprouvent lors de l'installation et de la configuration de leurs copies de GitLab. Cette approche a bien fonctionné pendant un certain temps, mais comme le nombre de projets sur GitLab dépassait les 10 millions, nous avons réalisé qu'elle ne répondait plus à nos besoins d'évolutivité et de déploiement.
Premiers pas vers Kubernetes et GitLab cloud natif
En 2017, le projet GitLab Charts a été créé pour préparer GitLab au déploiement dans le cloud, ainsi que pour permettre aux utilisateurs d'installer GitLab sur des clusters Kubernetes. Nous savions alors que déplacer GitLab vers Kubernetes augmenterait l'évolutivité de la plate-forme SaaS, simplifierait les déploiements et améliorerait l'efficacité des calculs. Dans le même temps, de nombreuses fonctionnalités de notre application dépendaient de partitions NFS montées, ce qui ralentissait la transition depuis les machines virtuelles.
La poursuite du cloud natif et de Kubernetes a permis à nos ingénieurs de planifier une transition progressive, au cours de laquelle nous avons abandonné certaines des dépendances NAS de l'application tout en continuant à développer de nouvelles fonctionnalités en cours de route. Depuis que nous avons commencé à planifier la migration à l'été 2019, nombre de ces restrictions ont été supprimées et le processus de migration de GitLab.com vers Kubernetes bat maintenant son plein!
Fonctionnalités de GitLab.com dans Kubernetes
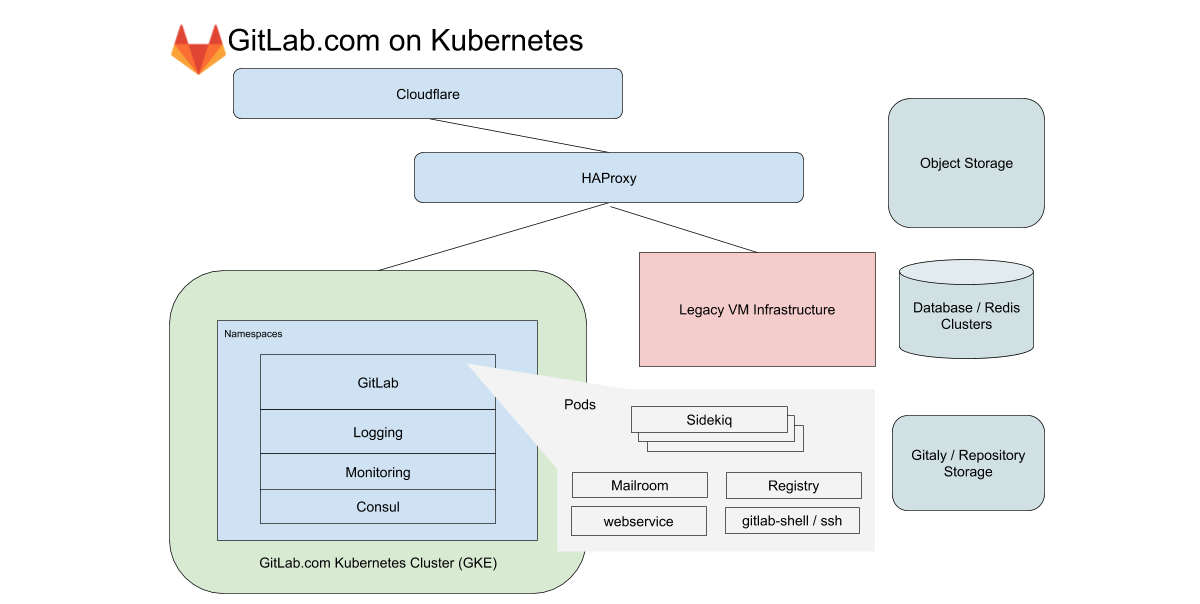
Pour GitLab.com, nous utilisons un seul cluster GKE régional qui gère tout le trafic des applications. Pour minimiser la complexité de la migration (déjà délicate), nous nous concentrons sur les services qui ne reposent pas sur le stockage local ou NFS. GitLab.com utilise une base de code Rails principalement monolithique, et nous acheminons le trafic en fonction des caractéristiques de la charge de travail vers divers points de terminaison isolés dans nos propres pools de nœuds.
Dans le cas du frontend, ces types sont divisés en requêtes vers le Web, API, Git SSH / HTTPS et Registry. Dans le cas du backend, nous mettons en file d'attente les travaux en fonction de différentes caractéristiques en fonction des limites de ressources prédéfinies qui nous permettent de définir des objectifs de niveau de service (SLO) pour différentes charges de travail.
Tous ces services GitLab.com sont configurés à l'aide d'un graphique GitLab Helm non modifié. La configuration se fait dans des sous-graphiques, qui peuvent être activés de manière sélective au fur et à mesure que nous migrons progressivement les services vers le cluster. Même s'il a été décidé de ne pas inclure certains de nos services avec état tels que Redis, Postgres, GitLab Pages et Gitaly dans la migration, Kubernetes réduit considérablement le nombre de VM que Chef gère actuellement.
Gestion de la transparence et de la configuration de Kubernetes
Tous les paramètres sont contrôlés par GitLab lui-même. Pour cela, trois projets de configuration basés sur Terraform et Helm sont utilisés. Nous essayons partout, dans la mesure du possible, d'utiliser GitLab lui-même pour exécuter GitLab, mais pour les tâches opérationnelles, nous avons une installation GitLab séparée. Il doit être indépendant de la disponibilité de GitLab.com pour les déploiements et mises à jour de GitLab.com.
Bien que nos pipelines pour le cluster Kubernetes s'exécutent sur une installation GitLab distincte, les dépôts de code ont des miroirs accessibles au public aux adresses suivantes:
- k8s-workloads / gitlab-com - liaison de configuration GitLab.com pour le graphique GitLab Helm;
- k8s-workloads/gitlab-helmfiles — , GitLab . , PlantUML;
- Gitlab-com-infrastructure — Terraform Kubernetes (legacy) VM-. , , , , , IP-.

Lorsque des modifications sont apportées, un bref résumé accessible au public est affiché avec un lien vers une différence détaillée que SRE analyse avant d'apporter des modifications au cluster.
Pour SRE, le lien pointe vers une différence détaillée dans l'installation de GitLab qui est utilisée pour la production et dont l'accès est limité. Cela permet aux employés et à la communauté sans accès au projet opérationnel (il est ouvert uniquement au SRE) de visualiser les modifications de configuration proposées. En combinant une instance publique de GitLab pour le code avec une instance privée pour les pipelines CI, nous maintenons un flux de travail unique tout en garantissant l'indépendance de GitLab.com pour les mises à jour de configuration.
Ce que nous avons découvert lors de la migration
Pendant le déménagement, l'expérience s'est accumulée, que nous appliquons aux nouvelles migrations et déploiements dans Kubernetes.
1. -

Statistiques de sortie quotidiennes (octets par jour) pour le parc de référentiels Git sur GitLab.com
Google divise son réseau en régions. Ceux-ci, à leur tour, sont divisés en zones de disponibilité (AZ). L'hébergement Git est associé à de grandes quantités de données, il est donc important pour nous de contrôler la sortie du réseau. Pour le trafic interne, la sortie n'est gratuite que si elle reste dans le même AZ. Au moment d'écrire ces lignes, nous donnons environ 100 To de données par jour ouvrable typique (et ce n'est que pour les référentiels Git). Les services qui, dans notre ancienne topologie basée sur les VM, se trouvaient sur les mêmes machines virtuelles, s'exécutent désormais dans différents pods Kubernetes. Cela signifie qu'une partie du trafic qui était auparavant local sur la machine virtuelle peut potentiellement sortir des zones de disponibilité.
Les clusters GKE régionaux vous permettent d'étendre plusieurs zones de disponibilité à des fins de redondance. Nous envisageons de diviser le cluster GKE régional en clusters à zone unique pour les services qui génèrent un trafic important. Cela réduira les coûts de sortie tout en maintenant la redondance du cluster.
2. Limites, demandes de ressources et mise à l'échelle

Le nombre de réplicas traitant le trafic de production sur registry.gitlab.com. Le trafic culmine à ~ 15 h 00 UTC.
Notre histoire de migration a commencé en août 2019, lorsque nous avons porté notre premier service, le GitLab Container Registry, sur Kubernetes. Ce service critique à fort trafic était bien adapté pour la première migration car il s'agit d'une application sans état avec peu de dépendances externes. Le premier problème que nous avons rencontré était le grand nombre de pods préemptés en raison d'une mémoire insuffisante sur les nœuds. Pour cette raison, nous avons dû modifier les demandes et les limites.
Il a été constaté que dans le cas d'une application où la consommation de mémoire augmente avec le temps, de faibles valeurs de request'ov (pour chaque pod'a mémoire redondant) couplées à une limite rigide "généreuse" à utiliser conduisent à des unités de saturation (saturation) et un haut niveau de déplacement. Pour faire face à ce problème, il a été décidé d'augmenter les demandes et d'abaisser les limites . Cela a soulagé les nœuds et assuré un cycle de vie des pods qui n'a pas mis trop de pression sur le nœud. Nous commençons maintenant les migrations avec des demandes et des valeurs limites généreuses (et presque identiques), en les ajustant au besoin.
3. Mesures et journaux

L'infrastructure se concentre sur la latence, les taux d'erreur et la saturation avec des objectifs de niveau de service (SLO) établis liés à la disponibilité globale de notre système .
Au cours de l’année écoulée, l’un des principaux développements dans la division des infrastructures a été l’amélioration de la surveillance et du travail avec les SLO. Les SLO nous ont permis de fixer des objectifs pour des services individuels, que nous avons étroitement surveillés pendant la migration. Mais même avec une telle observabilité améliorée, il n'est pas toujours possible de voir immédiatement les problèmes à l'aide de métriques et d'alertes. Par exemple, en nous concentrant sur la latence et les taux d'erreur, nous ne couvrons pas entièrement tous les cas d'utilisation d'un service en cours de migration.
Ce problème a été découvert presque immédiatement après le déplacement de certaines des charges de travail vers le cluster. Cela devenait particulièrement aigu quand il fallait vérifier des fonctions, dont le nombre de requêtes est faible, mais qui ont des dépendances de configuration très spécifiques. L'une des leçons clés des résultats de la migration était la nécessité de prendre en compte lors de la surveillance non seulement les métriques, mais aussi les journaux et la «longue traîne» (nous parlons de leur distribution sur le graphique - environ Transl.) . Désormais, pour chaque migration, nous incluons une liste détaillée des requêtes de journal et planifions des procédures de restauration claires qui peuvent être passées d'une équipe à l'autre en cas de problème.
Servir les mêmes demandes en parallèle sur l'ancienne infrastructure de VM et la nouvelle basée sur Kubernetes était un défi unique. Contrairement à la migration lift-and-shift (transfert rapide des applications "telles quelles " vers une nouvelle infrastructure; vous pouvez en savoir plus, par exemple, ici - environ Transl.) , Le travail parallèle sur les "anciennes" VM et Kubernetes nécessite des outils pour les systèmes de surveillance étaient compatibles avec les deux environnements et pouvaient combiner les métriques en une seule vue. Il est important que nous utilisions les mêmes tableaux de bord et requêtes de journal pour obtenir une observabilité cohérente pendant la transition.
4. Basculement du trafic vers un nouveau cluster
Pour GitLab.com, certains des serveurs sont alloués pour l' étape Canary . Canary Park répond à nos projets internes et peut également être activé par les utilisateurs . Mais avant tout, il vise à valider les modifications apportées à l'infrastructure et à l'application. Le premier service migré a commencé par accepter une quantité limitée de trafic interne, et nous continuons à utiliser cette méthode pour nous assurer que le SLO est respecté avant de transférer tout le trafic vers le cluster.
Dans le cas de la migration, cela signifie que les premières demandes aux projets internes sont envoyées à Kubernetes, puis nous basculons progressivement le reste du trafic vers le cluster en modifiant le poids du backend via HAProxy. Lors du passage de la VM à Kubernetes, il est devenu clair qu'il était très avantageux de disposer d'un moyen simple de rediriger le trafic entre l'ancienne et la nouvelle infrastructure et, par conséquent, de garder l'ancienne infrastructure prête à être restaurée dans les premiers jours suivant la migration.
5. Réserve de puissance des pods et leur utilisation
Presque immédiatement, le problème suivant a été identifié: les pods du service de registre ont démarré rapidement, mais les pods de Sidekiq ont pris jusqu'à deux minutes pour démarrer . Les pods de longue durée pour Sidekiq sont devenus un problème lorsque nous avons commencé à migrer les charges de travail vers Kubernetes pour les travailleurs qui doivent traiter les tâches rapidement et évoluer rapidement.
Dans ce cas, la leçon était que si l'autoscaler de pod horizontal (HPA) de Kubernetes gère bien la croissance du trafic, il est important de prendre en compte les caractéristiques des charges de travail et d'allouer une capacité de pod de réserve (en particulier dans un environnement de répartition inégale de la demande). Dans notre cas, il y a eu un pic soudain de travaux, entraînant une mise à l'échelle rapide, qui a conduit à une saturation des ressources du processeur avant que nous ayons le temps de faire évoluer le pool de nœuds.
Il y a toujours une tentation de sortir le plus possible du cluster, cependant, nous, initialement confrontés à des problèmes de performances, commençons maintenant avec un budget de pod généreux et le réduisons plus tard, en gardant un œil attentif sur le SLO. Le lancement des pods pour le service Sidekiq s'est considérablement accéléré et prend désormais environ 40 secondes en moyenne.GitLab.com et nos utilisateurs d'installations autogérées, travaillant avec le graphique officiel de GitLab Helm, ont bénéficié de la réduction des temps de lancement des pods .
Conclusion
Après la migration de chaque service, nous nous sommes réjouis des avantages de l'utilisation de Kubernetes en production: déploiement d'application plus rapide et plus sûr, mise à l'échelle et allocation des ressources plus efficace. De plus, les avantages de la migration vont au-delà du service GitLab.com. Chaque amélioration du tableau officiel Helm profite également à ses utilisateurs.
J'espère que vous avez apprécié l'histoire de nos aventures de migration Kubernetes. Nous continuons à migrer tous les nouveaux services vers le cluster. Des informations complémentaires peuvent être obtenues dans les publications suivantes:
- « Pourquoi migrer vers Kubernetes <br> nous? ";
- " GitLab.com sur Kubernetes ";
- Epic sur la migration de GitLab.com vers Kubernetes .
PS du traducteur
Lisez aussi sur notre blog: