
Je m'appelle Ilya Gulyaev, je suis ingénieur en automatisation des tests dans l'équipe de vérification après déploiement chez DINS.
Dans DINS, nous utilisons Jenkins dans de nombreux processus: de la création de builds à l'exécution de déploiements et de tests automatiques. Dans mon équipe, nous utilisons Jenkins comme plate-forme pour lancer uniformément des contrôles de fumée après le déploiement de chacun de nos services, des environnements de développement à la production.
Il y a un an, d'autres équipes ont décidé d'utiliser nos pipelines non seulement pour vérifier un service après sa mise à jour, mais aussi pour vérifier l'état de l'ensemble de l'environnement avant d'exécuter de gros lots de tests. La charge sur notre plate-forme a décuplé et Jenkins a cessé de faire face à la tâche à accomplir et a juste commencé à tomber. Nous avons rapidement réalisé que l'ajout de ressources et la mise au point du ramasse-miettes ne pouvaient que retarder le problème, mais pas le résoudre complètement. Par conséquent, nous avons décidé de trouver les goulots d'étranglement Jenkins et de les optimiser.
Dans cet article, j'expliquerai le fonctionnement du pipeline Jenkins et partagerai mes conclusions qui peuvent vous aider à accélérer vos pipelines. Le matériel sera utile pour les ingénieurs qui ont déjà travaillé avec Jenkins et qui souhaitent mieux connaître l'outil.
What a Beast Jenkins Pipeline
Jenkins Pipeline est un outil puissant qui vous permet d'automatiser divers processus. Jenkins Pipeline est un ensemble de plugins qui vous permettent de décrire des actions sous la forme d'un Groovy DSL, et est le successeur du plugin Build Flow.
Le script du plugin Build Flow a été exécuté directement sur le maître dans un thread Java distinct qui exécutait le code Groovy sans barrières empêchant l'accès à l'API Jenkins interne. Cette approche posait un risque de sécurité, qui devint plus tard l'une des raisons de l'abandon de Build Flow, et servit de condition préalable à la création d'un outil sûr et évolutif pour l'exécution de scripts - Jenkins Pipeline.
Vous pouvez en savoir plus sur l'historique de la création du pipeline Jenkins dans l' article de l' auteur Build Flow ouConférence d'Oleg Nenashev sur Groovy DSL à Jenkins .
Fonctionnement du pipeline Jenkins
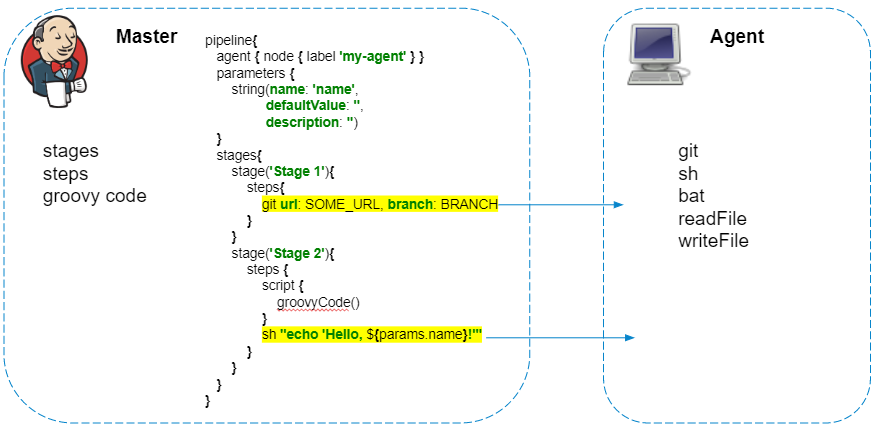
Voyons maintenant comment les pipelines fonctionnent de l'intérieur. Ils disent généralement que Jenkins Pipeline est un type de travail complètement différent dans Jenkins, contrairement aux bons vieux emplois de style libre sur lesquels on peut cliquer dans l'interface Web. Du point de vue de l'utilisateur, cela peut ressembler à ceci, mais du côté de Jenkins, les pipelines sont un ensemble de plugins qui vous permettent de transférer la description des actions dans le code.
Similitudes des emplois de pipeline et de style libre
- La description du poste (et non les étapes) est stockée dans le fichier config.xml
- Les paramètres sont stockés dans config.xml
- Les déclencheurs sont également stockés dans config.xml
- Et même certaines options sont stockées dans config.xml
Alors. Arrêtez. La documentation officielle indique que les paramètres, les déclencheurs et les options peuvent être définis directement dans le pipeline. Où est la vérité?
La vérité est que les paramètres décrits dans le pipeline seront automatiquement ajoutés à la section de configuration de l'interface Web au démarrage du travail. Vous pouvez me faire confiance car j'ai écrit cette fonctionnalité dans la dernière édition , mais plus à ce sujet dans la deuxième partie de l'article.
Différences entre les tâches de pipeline et de style libre
- Au moment du démarrage du job, Jenkins ne sait rien de l'agent pour exécuter le job
- Les actions sont décrites dans un script groovy.
Lancement du pipeline déclaratif Jenkins
Le processus de démarrage de Jenkins Pipeline comprend les étapes suivantes:
- Charger la description du poste à partir du fichier config.xml
- Démarrez un thread séparé (interprète léger) pour terminer la tâche
- Chargement du script de pipeline
- Construire et vérifier une arborescence de syntaxe
- Mises à jour de la configuration des tâches
- Combinaison des paramètres et des propriétés spécifiés dans la description de poste et dans le script
- Enregistrement des descriptions de travail dans le système de fichiers
- Exécuter un script dans un bac à sable groovy
- Demande d'agent pour un travail entier ou une seule étape
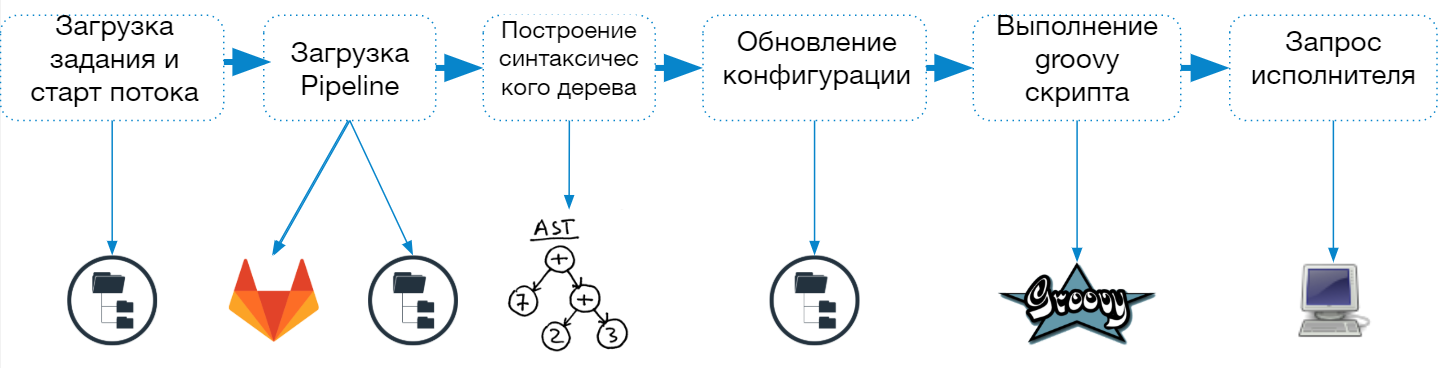
Lorsqu'un travail de pipeline démarre, Jenkins crée un thread distinct et envoie le travail à la file d'attente pour exécution, et après le chargement du script, il détermine quel agent est nécessaire pour terminer la tâche.
Pour prendre en charge cette approche, un pool de threads Jenkins spécial (exécuteurs légers) est utilisé. Vous pouvez voir qu'ils sont exécutés sur le maître, mais n'affectent pas le pool habituel d'exécuteurs: Le
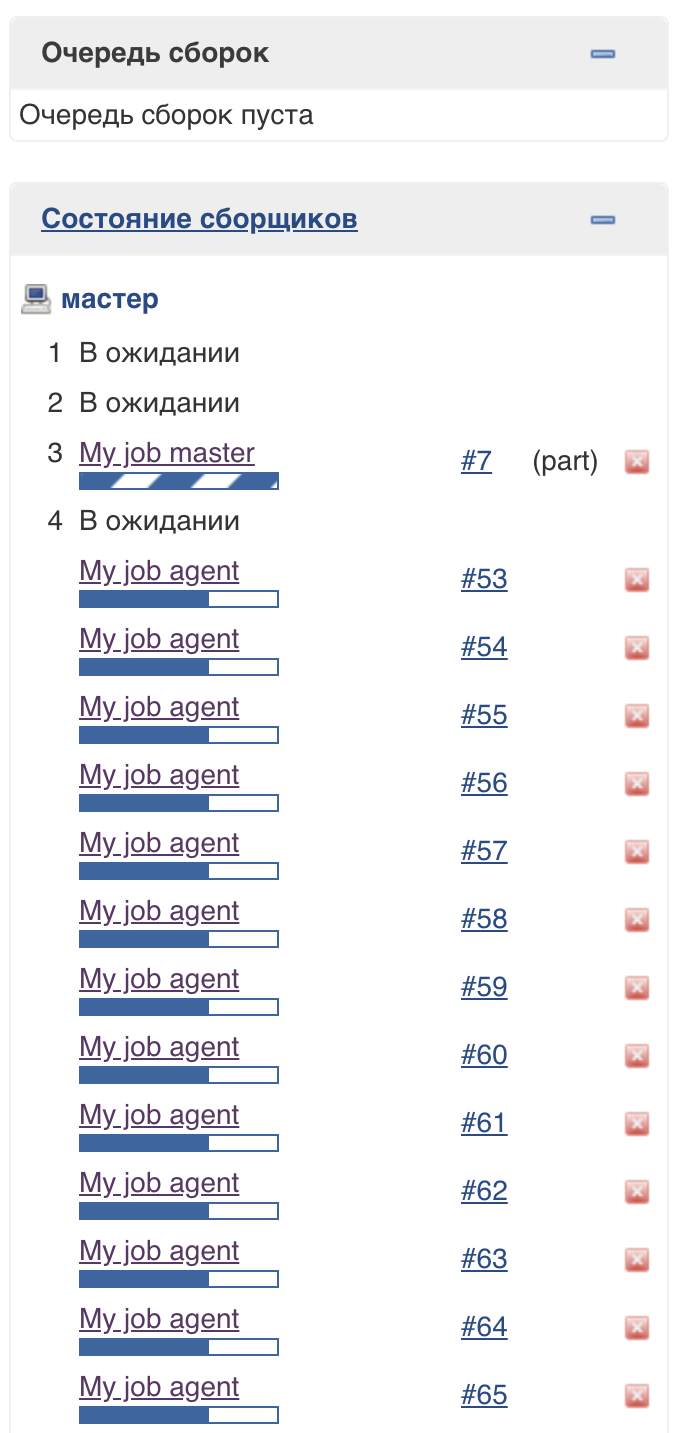
nombre de threads dans ce pool n'est pas limité (au moment de cette écriture).
Paramètres de travail dans le pipeline. Ainsi que des déclencheurs et quelques options
Le traitement des paramètres peut être décrit par la formule:

À partir des paramètres de travail que nous voyons au démarrage, les paramètres du pipeline du lancement précédent sont d'abord supprimés, puis seulement les paramètres spécifiés dans le pipeline du lancement en cours sont ajoutés. Cela permet de supprimer des paramètres du travail s'ils ont été supprimés du pipeline.
Comment ça marche de l'intérieur?
Regardons un exemple config.xml (le fichier qui stocke la configuration du travail):
<?xml version='1.1' encoding='UTF-8'?>
<flow-definition plugin="workflow-job@2.35">
<actions>
<org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobAction plugin="pipeline-model-definition@1.5.0"/>
<org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobPropertyTrackerAction plugin="pipeline-model-definition@1.5.0">
<jobProperties>
<string>jenkins.model.BuildDiscarderProperty</string>
</jobProperties>
<triggers/>
<parameters>
<string>parameter_3</string>
</parameters>
</org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobPropertyTrackerAction>
</actions>
<description></description>
<keepDependencies>false</keepDependencies>
<properties>
<hudson.model.ParametersDefinitionProperty>
<parameterDefinitions>
<hudson.model.StringParameterDefinition>
<name>parameter_1</name>
<description></description>
<defaultValue></defaultValue>
<trim>false</trim>
</hudson.model.StringParameterDefinition>
<hudson.model.StringParameterDefinition>
<name>parameter_2</name>
<description></description>
<defaultValue></defaultValue>
<trim>false</trim>
</hudson.model.StringParameterDefinition>
<hudson.model.StringParameterDefinition>
<name>parameter_3</name>
<description></description>
<defaultValue></defaultValue>
<trim>false</trim>
</hudson.model.StringParameterDefinition>
</parameterDefinitions>
</hudson.model.ParametersDefinitionProperty>
<jenkins.model.BuildDiscarderProperty>
<strategy class="org.jenkinsci.plugins.BuildRotator.BuildRotator" plugin="buildrotator@1.2">
<daysToKeep>30</daysToKeep>
<numToKeep>10000</numToKeep>
<artifactsDaysToKeep>-1</artifactsDaysToKeep>
<artifactsNumToKeep>-1</artifactsNumToKeep>
</strategy>
</jenkins.model.BuildDiscarderProperty>
<com.sonyericsson.rebuild.RebuildSettings plugin="rebuild@1.28">
<autoRebuild>false</autoRebuild>
<rebuildDisabled>false</rebuildDisabled>
</com.sonyericsson.rebuild.RebuildSettings>
</properties>
<definition class="org.jenkinsci.plugins.workflow.cps.CpsScmFlowDefinition" plugin="workflow-cps@2.80">
<scm class="hudson.plugins.filesystem_scm.FSSCM" plugin="filesystem_scm@2.1">
<path>/path/to/jenkinsfile/</path>
<clearWorkspace>true</clearWorkspace>
</scm>
<scriptPath>Jenkinsfile</scriptPath>
<lightweight>true</lightweight>
</definition>
<triggers/>
<disabled>false</disabled>
</flow-definition>
La section des propriétés contient les paramètres, les déclencheurs et les options avec lesquels le travail sera lancé. Une section supplémentaire, DeclarativeJobPropertyTrackerAction, est utilisée pour stocker les paramètres définis uniquement dans le pipeline.
Lorsqu'un paramètre est supprimé du pipeline, il sera supprimé à la fois de DeclarativeJobPropertyTrackerAction et des propriétés , car Jenkins saura que le paramètre a été défini uniquement dans le pipeline.
Lors de l'ajout d'un paramètre, la situation est inversée, le paramètre sera ajouté DeclarativeJobPropertyTrackerAction et propriétés , mais uniquement au moment de l'exécution du pipeline.
C'est pourquoi si vous définissez les paramètres uniquement dans le pipeline, ilsne sera pas disponible lors du premier lancement .
Exécution du pipeline Jenkins
Une fois le script Pipeline téléchargé et compilé, le processus d'exécution commence. Mais ce processus n'implique pas seulement de faire du groovy. J'ai mis en évidence les principales opérations lourdes qui sont effectuées au moment de l'exécution du travail:
Exécution du code Groovy
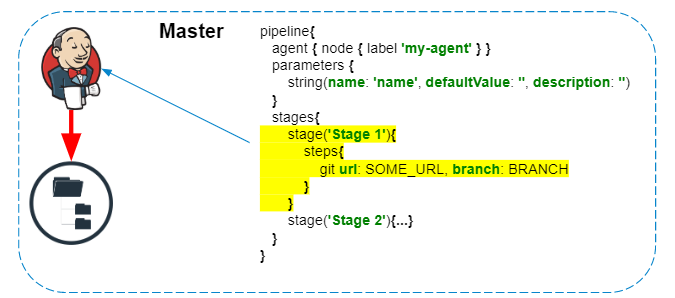
Le script de pipeline est toujours exécuté sur le maître - il ne faut pas oublier cela, afin de ne pas créer de charge inutile sur Jenkins. Seules les étapes qui interagissent avec le système de fichiers de l'agent ou les appels système sont exécutées sur l'agent.
Les pipelines ont un excellent plugin qui vous permet de faire des requêtes HTTP . De plus, la réponse peut être enregistrée dans un fichier.
httpRequest url: 'http://localhost:8080/jenkins/api/json?pretty=true', outputFile: 'result.json'
Au départ, il peut sembler que ce code devrait être complètement exécuté sur l'agent, envoyer une requête de l'agent et enregistrer la réponse dans le fichier result.json. Mais tout se passe dans l'autre sens, et la requête est exécutée depuis Jenkins lui-même, et pour enregistrer le contenu du fichier est copié sur l'agent. Si un traitement supplémentaire de la réponse dans le pipeline n'est pas nécessaire, je vous conseille de remplacer ces demandes par curl:
sh 'curl "http://localhost:8080/jenkins/api/json?pretty=true" -o "result.json"'
Utilisation des journaux et des artefacts
Quel que soit l'agent sur lequel les commandes sont exécutées, les journaux et les artefacts sont traités et enregistrés dans le système de fichiers maître en temps réel.
Si des secrets (informations d'identification) sont utilisés dans le pipeline, avant d'enregistrer les journaux sont en outre filtrés sur le maître .
Enregistrement des étapes (durabilité du pipeline)
Jenkins Pipeline se positionne comme une tâche qui se compose d'éléments séparés qui sont indépendants et peuvent être reproduits lorsque le maître tombe en panne. Mais vous devez payer pour cela avec des écritures supplémentaires sur le disque, car en fonction des paramètres de la tâche, les étapes avec divers degrés de détail sont sérialisées et enregistrées sur le disque.
En fonction de la durabilité du pipeline, les étapes du graphique du pipeline seront stockées dans un ou plusieurs fichiers pour chaque tâche exécutée. Extrait de la documentation :
Le plug-in de prise en charge des flux de travail pour le stockage des étapes (FlowNode) utilise la classe FlowNodeStorage et ses implémentations SimpleXStreamFlowNodeStorage et BulkFlowNodeStorage.
- FlowNodeStorage utilise la mise en cache en mémoire pour regrouper les écritures sur disque. Le tampon est automatiquement écrit lors de l'exécution. En règle générale, vous n'avez pas à vous en soucier, mais gardez à l'esprit que l'enregistrement d'un FlowNode ne garantit pas qu'il sera immédiatement écrit sur le disque.
- SimpleXStreamFlowNodeStorage utilise un petit fichier XML pour chaque FlowNode - bien que nous utilisions un cache en mémoire de référence souple pour les nœuds, cela se traduit par des performances bien pires lors de la première traversée des FlowNodes.
- BulkFlowNodeStorage utilise un fichier XML plus volumineux contenant tous les FlowNodes. Cette classe est utilisée en mode de vivacité PERFORMANCE_OPTIMIZED, qui écrit beaucoup moins fréquemment. C'est généralement beaucoup plus efficace car un gros enregistrement en continu est plus rapide qu'un groupe de petits enregistrements et minimise la charge sur le système d'exploitation pour gérer tous les petits fichiers.
Original
Storage: in the workflow-support plugin, see the 'FlowNodeStorage' class and the SimpleXStreamFlowNodeStorage and BulkFlowNodeStorage implementations.
- FlowNodeStorage uses in-memory caching to consolidate disk writes. Automatic flushing is implemented at execution time. Generally, you won't need to worry about this, but be aware that saving a FlowNode does not guarantee it is immediately persisted to disk.
- The SimpleXStreamFlowNodeStorage uses a single small XML file for every FlowNode — although we use a soft-reference in-memory cache for the nodes, this generates much worse performance the first time we iterate through the FlowNodes (or when)
- The BulkFlowNodeStorage uses a single larger XML file with all the FlowNodes in it. This is used in the PERFORMANCE_OPTIMIZED durability mode, which writes much less often. It is generally much more efficient because a single large streaming write is faster than a bunch of small writes, and it minimizes the system load of managing all the tiny files.
Les étapes enregistrées se trouvent dans le répertoire:
$JENKINS_HOME/jobs/$JOB_NAME/builds/$BUILD_ID/workflow/
Exemple de fichier:
<?xml version='1.1' encoding='UTF-8'?>
<Tag plugin="workflow-support@3.5">
<node class="cps.n.StepStartNode" plugin="workflow-cps@2.82">
<parentIds>
<string>4</string>
</parentIds>
<id>5</id>
<descriptorId>org.jenkinsci.plugins.workflow.support.steps.StageStep</descriptorId>
</node>
<actions>
<s.a.LogStorageAction/>
<cps.a.ArgumentsActionImpl plugin="workflow-cps@2.82">
<arguments>
<entry>
<string>name</string>
<string>Declarative: Checkout SCM</string>
</entry>
</arguments>
<isUnmodifiedBySanitization>true</isUnmodifiedBySanitization>
</cps.a.ArgumentsActionImpl>
<wf.a.TimingAction plugin="workflow-api@2.40">
<startTime>1600855071994</startTime>
</wf.a.TimingAction>
</actions>
</Tag>
Résultat
J'espère que ce matériel était intéressant et a aidé à mieux comprendre ce que sont les pipelines et comment ils fonctionnent de l'intérieur. Si vous avez encore des questions - partagez-les ci-dessous, je me ferai un plaisir d'y répondre!
Dans la deuxième partie de l'article, j'examinerai des cas distincts qui vous aideront à trouver des problèmes avec le pipeline Jenkins et à accélérer vos tâches. Nous allons apprendre à résoudre les problèmes de lancement simultané, examiner les options de survie et expliquer pourquoi Jenkins devrait être profilé.