
Parlons d'un réseau de neurones qui utilise l'apprentissage en profondeur et l'apprentissage par renforcement pour jouer à Snake. Vous trouverez le code sur Github, l'analyse des erreurs, des démonstrations d'IA et des expériences dessus sous la coupe.
Depuis que j'ai regardé le documentaire Netflix sur AlphaGo, je suis fasciné par l'apprentissage par renforcement. Un tel apprentissage est comparable à un apprentissage humain: vous voyez quelque chose, vous faites quelque chose et vos actions ont des conséquences. Bon ou Mauvais. Vous apprenez des conséquences et des actions correctes. L'apprentissage par renforcement a de nombreuses applications: conduite autonome, robotique, trading, jeux. Si vous êtes familiarisé avec l'apprentissage par renforcement, sautez les deux sections suivantes.
Apprentissage par renforcement
Le principe est simple. L'agent apprend par interaction avec l'environnement. Il choisit une action et reçoit une réponse de l'environnement sous forme d'états (ou d'observations) et de récompenses. Ce cycle se poursuit en continu ou jusqu'à ce qu'il soit interrompu. Puis un nouvel épisode commence. Schématiquement, cela ressemble à ceci:

Le but de l'agent est d'obtenir le maximum de récompenses par épisode. Au début de la formation, l'agent examine l'environnement: tente différentes actions dans le même état. Au fur et à mesure que l'apprentissage progresse, l'agent recherche de moins en moins. Au lieu de cela, il choisit l'action la plus enrichissante en fonction de sa propre expérience.
Apprentissage par renforcement profond
L'apprentissage profond utilise des réseaux de neurones pour générer des sorties à partir d'entrées. Avec une seule couche cachée, l'apprentissage en profondeur peut zoomer sur n'importe quelle fonctionnalité. Comment ça fonctionne? Un réseau neuronal est constitué de couches avec des nœuds. La première couche est la couche de données d'entrée. La deuxième couche masquée transforme les données à l'aide de pondérations et d'une fonction d'activation. La dernière couche est la couche de prévision.

Comme son nom l'indique, l'apprentissage par renforcement profond est une combinaison d'apprentissage profond et d'apprentissage par renforcement. L'agent apprend à prédire la meilleure action pour un état donné en utilisant des états comme entrées, des valeurs d'actions comme sorties et des récompenses pour ajuster les poids dans la bonne direction. Écrivons un serpent en utilisant un apprentissage par renforcement profond.

Définition des actions, récompenses et conditions
Pour préparer le jeu pour l'agent, nous formalisons le problème. La définition des actions est facile. L'agent peut choisir la direction: haut, droite, bas ou gauche. Les récompenses et l'état de l'espace sont un peu plus compliqués. Il existe de nombreuses solutions et l'une fonctionnera mieux et l'autre pire. Je décrirai l'un d'entre eux ci-dessous et essayons-le.
Si Snake ramasse une pomme, sa récompense est de 10 points. Si le serpent meurt, soustrayez 100 points de la récompense. Pour aider l'agent, ajoutez 1 point lorsque le serpent se rapproche de la pomme et soustrayez un point lorsque le serpent s'éloigne de la pomme.
L'État a de nombreuses options. Vous pouvez prendre les coordonnées du serpent et de la pomme ou la direction de la pomme. Il est important d'ajouter l'emplacement des obstacles, c'est-à-dire les murs et le corps du serpent, afin que l'agent apprenne à survivre. Voici un résumé des actions, conditions et récompenses. Nous verrons plus loin comment les ajustements d'état affectent les performances.

Créer un environnement et un agent
En ajoutant des méthodes au programme Snake, nous créons un environnement d'apprentissage par renforcement. Les méthodes sont les suivantes:
reset(self), step(self, action)et get_state(self). De plus, vous devez calculer la récompense à chaque étape de l'agent. Jetez un œil à run_game(self).
L'agent travaille avec le réseau Deep Q pour trouver la meilleure action. Paramètres du modèle ci-dessous:
# epsilon sets the level of exploration and decreases over time
params['epsilon'] = 1
params['gamma'] = .95
params['batch_size'] = 500
params['epsilon_min'] = .01
params['epsilon_decay'] = .995
params['learning_rate'] = 0.00025
params['layer_sizes'] = [128, 128, 128]
Si vous souhaitez consulter le code, vous pouvez le trouver sur GitHub .
L'agent joue Snake
Et maintenant - la question clé! L'agent apprendra-t-il à jouer? Voyons comment il interagit avec l'environnement. Voici les premiers jeux. L'agent ne comprend rien:

La première pomme! Mais il semble toujours que le réseau neuronal ne sache pas ce qu'il fait.

Trouve la première pomme ... et touche plus tard le mur. Le début du quatorzième match:

L'agent apprend: son chemin vers la pomme n'est pas le plus court, mais il trouve la pomme. Voici le trentième jeu:

Après seulement 30 parties, Snake évite les collisions avec lui-même et trouve un chemin rapide vers la pomme.
Jouons avec l'espace
Il peut être possible de modifier l'espace d'état et d'obtenir des performances similaires ou meilleures. Voici les options possibles.
- Pas de directions: ne dites pas à l'agent les directions dans lesquelles le serpent se déplace.
- État avec coordonnées: remplacez la position de la pomme (haut, droite, bas et / ou gauche) par les coordonnées de la pomme (x, y) et du serpent (x, y). Les valeurs de coordonnées sont sur une échelle de 0 à 1.
- État de direction 0 ou 1.
- État du mur uniquement: signale uniquement s'il y a un mur. Mais pas de l'endroit où se trouve le corps: en bas, en haut, à droite ou à gauche.

Vous trouverez ci-dessous des graphiques de performances pour différents états:
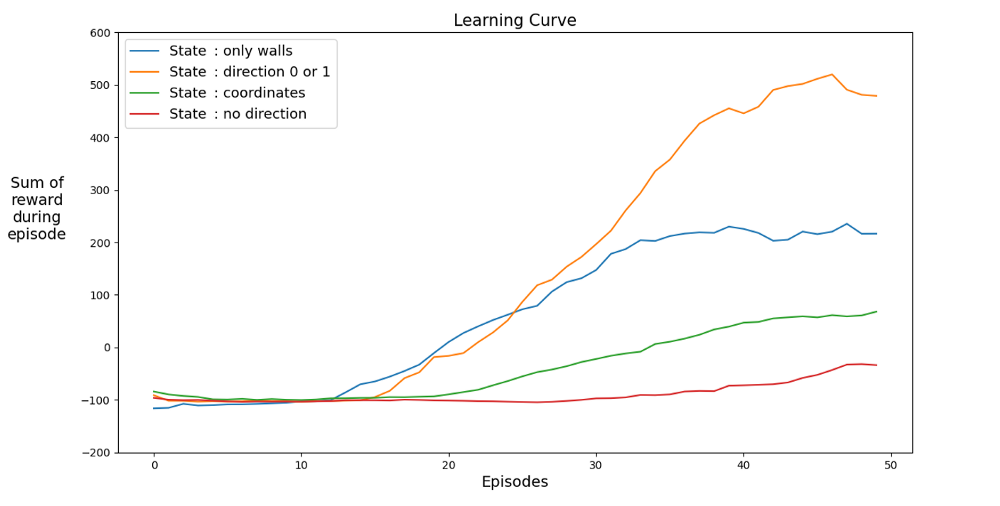
Trouvons un espace qui accélère l'apprentissage. Le graphique montre les réalisations moyennes des 12 derniers jeux avec différents états.
Il est clair que lorsque l'espace d'états a des directions, l'agent apprend rapidement, obtenant les meilleurs résultats. Mais l'espace avec des coordonnées est meilleur. Peut-être pouvez-vous obtenir de meilleurs résultats en entraînant le réseau plus longtemps. La raison de l'apprentissage lent peut être le nombre d'états possibles: 20⁴ * 2⁴ * 4 = 1 024 000. Un parcours de 20 sur 20, 64 options d'obstacles et 4 options de cap actuel. Pour l'espace des variantes d'origine, 3² * 2⁴ * 4 = 576. C'est plus de 1700 fois moins que 1.024.000 et affecte bien sûr l'apprentissage.
Jouons avec les récompenses
Existe-t-il une meilleure logique de récompense interne? Permettez-moi de vous rappeler que le serpent est décerné comme ceci:

Première erreur. Marcher en rond
Et si vous changiez -1 en +1? Cela peut ralentir la courbe d'apprentissage, mais à la fin, le serpent ne meurt pas. Et c'est très important pour le jeu. L'agent apprend rapidement à éviter la mort.

À un intervalle de temps, l'agent reçoit un point de survie.
Deuxième erreur. Frapper le mur
Changeons le nombre de points pour faire le tour de la pomme à -1. Fixons la récompense de la pomme elle-même à 100 points. Que va-t-il se passer? L'agent reçoit une pénalité pour chaque mouvement, il se déplace donc vers la pomme le plus rapidement possible. Cela peut arriver, mais il existe une autre option.

L'IA marche le long du mur le plus proche pour minimiser les pertes.
Expérience
Vous n'avez besoin que de 30 jeux. Le secret de l'intelligence artificielle est l'expérience des jeux précédents, qui est prise en compte pour que le réseau de neurones apprenne plus rapidement. A chaque étape régulière, une série d'étapes de relecture (paramètre
batch_size) est effectuée . Cela fonctionne si bien parce que, pour une paire d'action et d'état donnée, la différence entre la récompense et l'état suivant est faible.
Erreur numéro 3. Aucune expérience L'expérience est-elle
vraiment si importante? Supprimons-le. Et prenez la récompense de 100 points pour la pomme. Ci-dessous, un agent sans expérience qui a joué 2500 parties.

Bien que l'agent ait joué 2500 (!) Parties, il ne joue pas au serpent. Le jeu se termine rapidement. Sinon, 10 000 parties auraient pris des jours. Après 3000 parties, nous n'avons que 3 pommes. Après 10 000 parties, les pommes sont encore 3. Est-ce la chance ou un résultat d'apprentissage?
En effet, l'expérience aide beaucoup. Au moins une expérience qui prend en compte les récompenses et le type d'espace. De combien de rediffusions avez-vous besoin par étape? La réponse peut surprendre. Pour répondre à cette question, jouons avec le paramètre batch_size. Dans l'expérience d'origine, il était défini sur 500. Aperçu des résultats avec différentes expériences:

200 parties avec une expérience différente: 1 partie (sans expérience), 2 et 4. Moyenne pour 20 parties.
Même avec de l'expérience dans 2 jeux, l'agent apprend déjà à jouer. Dans le graphique vous voyez l'impact
batch_size, la même performance est obtenue pour 100 jeux si 4 est utilisé au lieu de 2. La solution dans l'article donne le résultat. L'agent apprend à jouer à Snake et obtient de bons résultats, récoltant 40 à 60 pommes en 50 parties.
Un lecteur attentif peut dire: le nombre maximum de pommes dans un serpent est de 399. Pourquoi l'IA ne gagne-t-elle pas? La différence entre 60 et 399 est, en fait, faible. Et c'est vrai. Et il y a un problème ici: le serpent n'évite pas les collisions lors du bouclage.
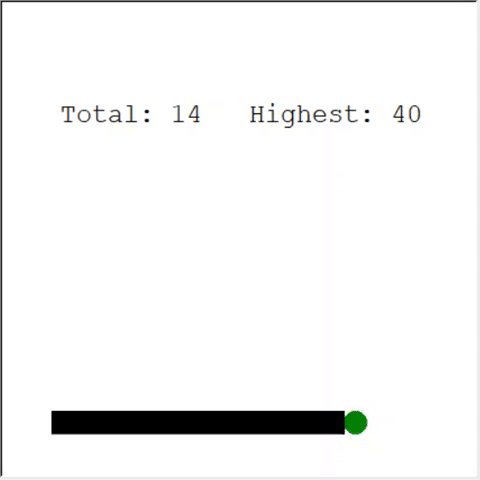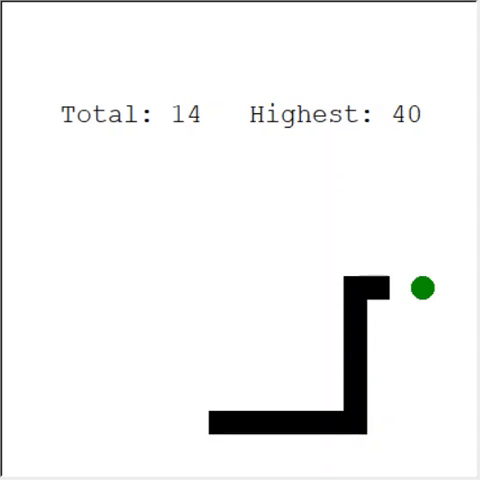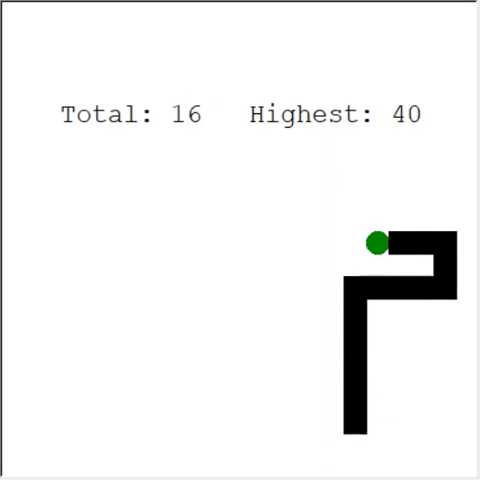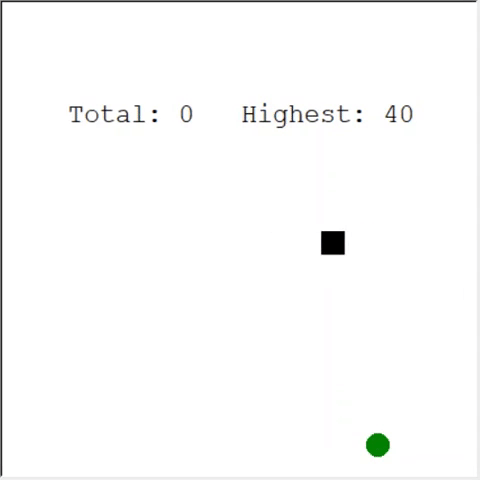
Une façon intéressante de résoudre le problème est d'utiliser CNN pour le terrain de jeu. De cette façon, l'IA peut voir tout le jeu, pas seulement les obstacles à proximité. Il saura reconnaître les endroits à parcourir pour gagner.
Bibliographie
[1] K. Hornik, M. Stinchcombe, H. White, Multilayer feedforward networks are universal approximators (1989), Neural networks 2.5: 359–366
[2] Mnih et al, Playing Atari with Deep Reinforcement Learning (2013)
[2] Mnih et al, Playing Atari with Deep Reinforcement Learning (2013)
, Level Up , - SkillFactory:
- Machine Learning (12 )
- « Machine Learning Data Science» (20 )
- «Machine Learning Pro + Deep Learning» (20 )
- Data Science (12 )
E
- - (8 )
- - Data Analytics (5 )
- (6 )
- (18 )
- «Python -» (9 )
- DevOps (12 )
- Java- (18 )
- JavaScript (12 )
- UX- (9 )
- Web- (7 )
