( PNL) par Tim Dettmers, Ph.D. L'apprentissage profond (DL) est un domaine avec une forte demande en puissance de calcul, donc votre choix de GPU déterminera fondamentalement votre expérience dans ce domaine. Mais quelles propriétés sont importantes à considérer lors de l'achat d'un nouveau GPU? Mémoire, noyaux, noyaux tensoriels? Comment faire le meilleur choix en termes de rapport qualité / prix? Dans cet article, je vais analyser en détail toutes ces questions, idées fausses courantes, vous donner une compréhension intuitive du GPU, ainsi que quelques conseils pour vous aider à faire le bon choix.
Cet article est écrit pour vous donner plusieurs niveaux de compréhension du GPU, incl. nouvelle série Ampere de NVIDIA. Tu as le choix:
- Si vous n'êtes pas intéressé par les détails du GPU, ce qui rend exactement le GPU rapide et ce qui est unique dans les nouveaux GPU de la série NVIDIA RTX 30 Ampères, vous pouvez sauter le début de l'article, jusqu'aux graphiques sur la vitesse et la vitesse pour 1 $ de coût, ainsi que la section des recommandations. C'est le cœur de cet article et le contenu le plus précieux.
- Si vous êtes intéressé par des questions spécifiques, j'ai abordé les plus fréquentes d'entre elles dans la dernière partie de l'article.
- Si vous avez besoin d'une compréhension approfondie du fonctionnement des GPU et des cœurs Tensor, le mieux est de lire cet article du début à la fin. En fonction de vos connaissances sur des sujets spécifiques, vous pouvez sauter un chapitre ou deux.
Chaque section est précédée d'un bref résumé pour vous aider à décider de la lire dans son intégralité ou non.
Contenu
GPU?
GPU,
/ L1 /
Ampere
Ampere
Ampere
Ampere / RTX 30
GPU
GPU
GPU
11 ?
11 ?
GPU-
GPU
GPU?
PCIe 4.0?
PCIe 8x/16x?
RTX 3090, 3 PCIe?
4 RTX 3090 4 RTX 3080?
GPU ?
NVLink, ?
. ?
?
?
Intel GPU?
?
AMD GPU + ROCm - NVIDIA GPU + CUDA?
, – GPU?
,
Cet article est structuré comme suit. J'explique d'abord ce qui rend un GPU rapide. Je décrirai la différence entre les processeurs et les GPU, les cœurs de tenseurs, la bande passante de la mémoire, la hiérarchie de la mémoire du GPU et comment tout cela est lié aux performances dans les tâches GO. Ces explications peuvent vous aider à mieux comprendre les paramètres GPU dont vous avez besoin. Ensuite, je donnerai des estimations théoriques des performances du GPU et leur correspondance avec certains tests de vitesse NVIDIA pour obtenir des données de performances fiables sans biais. Je décrirai les caractéristiques uniques des GPU NVIDIA RTX 30 Ampères à prendre en compte lors de l'achat. Ensuite, je donnerai des recommandations de GPU pour 1-2 clusters de puces, 4, 8 et GPU. Ensuite, il y aura une section de réponses aux questions fréquemment posées qui m'ont été posées sur Twitter.Cela dissipera également les idées fausses courantes et mettra en évidence divers problèmes tels que les nuages par rapport aux ordinateurs de bureau, le refroidissement, AMD contre NVIDIA, etc.
Comment fonctionnent les GPU?
Si vous utilisez beaucoup les GPU, il est utile de comprendre comment ils fonctionnent. Cette connaissance vous sera utile pour comprendre pourquoi dans certains cas les GPU sont plus lents et dans d'autres plus rapides. Et vous comprendrez peut-être si vous avez besoin d'un GPU et quelles options matérielles peuvent lui concurrencer à l'avenir. Vous pouvez ignorer cette section si vous voulez juste des informations de performances et des arguments utiles pour choisir un GPU particulier. La meilleure explication générale du fonctionnement des GPU est dans la réponse sur Quora .
C'est une explication générale, et cela explique bien la question de savoir pourquoi les GPU sont mieux adaptés pour GO que les processeurs. Si nous étudions les détails, nous pouvons comprendre en quoi les GPU diffèrent les uns des autres.
Les principales caractéristiques du GPU affectant la vitesse de traitement
Cette section vous aidera à réfléchir plus intuitivement aux performances dans le domaine du GO. Cette compréhension vous aidera à évaluer vous-même les futurs GPU.
Noyaux de tension
Résumé:
- Les noyaux de tenseurs réduisent le nombre de cycles d'horloge nécessaires pour compter les multiplications et les additions par 16 fois - dans mon exemple pour une matrice 32 × 32 de 128 à 8 cycles d'horloge.
- Les noyaux Tensor réduisent la dépendance aux accès répétés à la mémoire partagée en économisant les cycles d'accès à la mémoire.
- Les noyaux Tensor sont si rapides que le calcul n'est plus un goulot d'étranglement. Le seul goulot d'étranglement est le transfert de données vers eux.
Il existe tellement de GPU bon marché aujourd'hui que presque tout le monde peut se permettre un GPU avec des cœurs tensoriels. Par conséquent, je recommande toujours les GPU avec Tensor Cores. Il est utile de comprendre leur fonctionnement afin d'apprécier l'importance de ces modules de calcul, spécialisés dans la multiplication matricielle. En utilisant un exemple simple de multiplication matricielle A * B = C, où la taille de toutes les matrices est 32 × 32, je vais vous montrer à quoi ressemble la multiplication avec et sans noyaux tensoriels.
Pour comprendre cela, vous devez d'abord comprendre le concept de barres. Si le processeur fonctionne à 1 GHz, il fait 10 9tiques par seconde. Chaque horloge est l'occasion de calculs. Mais pour la plupart, les opérations prennent plus d'un cycle d'horloge. Il s'agit d'un pipeline - pour commencer à effectuer une opération, vous devez d'abord attendre autant de cycles d'horloge que nécessaire pour terminer l'opération précédente. Ceci est également appelé fonctionnement retardé.
Voici quelques durées ou retards importants d'une opération en ticks:
- Accès à la mémoire globale jusqu'à 48 Go: ~ 200 cycles d'horloge.
- Accès à la mémoire partagée (jusqu'à 164 Ko par multiprocesseur de streaming): ~ 20 horloges.
- Multiplication-addition combinée (SUS): 4 mesures.
- Multiplication matricielle dans les noyaux tensoriels: 1 cycle d'horloge.
En outre, vous devez savoir que la plus petite unité de threads dans un GPU - un paquet de 32 threads - est appelée une chaîne. Les warps fonctionnent généralement de manière synchrone - tous les threads à l'intérieur du warp doivent attendre les uns les autres. Toutes les opérations de la mémoire GPU sont optimisées pour les warps. Par exemple, le chargement à partir de la mémoire globale prend 32 * 4 octets - 32 nombres à virgule flottante, un de ces nombres pour chaque thread dans la chaîne. Dans un multiprocesseur en streaming (l'équivalent d'un cœur de processeur pour un GPU), il peut y avoir jusqu'à 32 warps = 1024 threads. Les ressources multiprocesseurs sont partagées entre toutes les déformations actives. Par conséquent, nous avons parfois besoin de moins de warps pour fonctionner, de sorte qu'un warp ait plus de registres, de mémoire partagée et de ressources de base de tensor.
Pour les deux exemples, supposons que nous ayons les mêmes ressources informatiques. Dans ce petit exemple de multiplication matricielle 32 × 32, nous utilisons 8 multiprocesseurs (~ 10% du RTX 3090) et 8 warps sur un multiprocesseur.
Multiplication matricielle sans noyau tenseur
Si nous devons multiplier les matrices A * B = C, dont chacune a une taille de 32 × 32, nous devons charger les données de la mémoire, auxquelles nous accédons constamment, dans la mémoire partagée, car les délais d'accès sont environ 10 fois moins 200 bars et 20 bars). Un bloc de mémoire dans la mémoire partagée est souvent appelé vignette mémoire ou simplement vignette. Le chargement de deux nombres à virgule flottante 32x32 dans une tuile de mémoire partagée peut être effectué en parallèle en utilisant 2 * 32 warps. Nous avons 8 multiprocesseurs avec 8 warps chacun, donc grâce à la parallélisation, nous devons effectuer un chargement séquentiel de la mémoire globale vers la mémoire partagée, ce qui prendra 200 cycles d'horloge.
Pour multiplier les matrices, il faut charger un vecteur de 32 nombres à partir de la mémoire partagée A et de la mémoire partagée B, et effectuer le CMS, puis stocker la sortie dans les registres C.Nous divisons ce travail afin que chaque multiprocesseur traite 8 produits scalaires (32 × 32 ) pour calculer 8 données de sortie pour C. Pourquoi il y en a exactement 8 (dans les anciens algorithmes - 4), c'est une caractéristique purement technique. Pour le comprendre, je recommande de lire l' article de Scott Gray . Cela signifie que nous aurons 8 accès à la mémoire partagée, coûtant 20 cycles chacun, et 8 opérations SLS (32 parallèles), coûtant 4 cycles chacune. Au total, le coût sera:
200 ticks (mémoire globale) + 8 * 20 ticks (mémoire partagée) + 8 * 4 ticks (CMS) = 392 ticks
Regardons maintenant ce coût pour les cœurs de tenseurs.
Multiplication matricielle avec des noyaux tenseur
Les noyaux de tenseurs peuvent être utilisés pour multiplier des matrices 4 × 4 en un cycle. Pour ce faire, nous devons copier de la mémoire sur des cœurs tensoriels. Comme ci-dessus, nous devons lire les données de la mémoire globale (200 ticks) et les stocker dans la mémoire partagée. Pour multiplier les matrices 32 × 32, nous devons effectuer 8 × 8 = 64 opérations dans les noyaux tensoriels. Un multiprocesseur contient 8 cœurs de tenseur. Avec 8 multiprocesseurs, nous avons 64 cœurs de tenseur - autant que nous en avons besoin! Nous pouvons transférer des données de la mémoire partagée vers des cœurs de tenseurs en 1 transfert (20 cycles d'horloge), puis effectuer toutes ces 64 opérations en parallèle (1 cycle d'horloge). Cela signifie que le coût total de la multiplication matricielle dans les cœurs de tenseur sera:
200 cycles d'horloge (mémoire globale) + 20 cycles d'horloge (mémoire partagée) + 1 cycle d'horloge (cœurs de tenseur) = 221 cycles d'horloge
Ainsi, en utilisant des noyaux tensoriels, nous réduisons considérablement le coût de la multiplication matricielle, de 392 à 221 cycles d'horloge. Dans notre exemple simplifié, les noyaux tensoriels ont réduit le coût de l'accès à la mémoire partagée et des opérations SNS.
Bien que cet exemple suive à peu près la séquence des étapes de calcul avec et sans noyau tensoriel, veuillez noter qu'il s'agit d'un exemple très simplifié. Dans les cas réels, la multiplication matricielle implique un peu comme de grandes tuiles de mémoire et des séquences d'actions légèrement différentes.
Cependant, il me semble que cet exemple montre clairement pourquoi l'attribut suivant, la bande passante mémoire, est si important pour les GPU avec des cœurs de tenseur. Étant donné que la mémoire globale est la chose la plus chère lors de la multiplication des matrices avec des cœurs de tenseurs, nos GPU seraient beaucoup plus rapides si nous pouvions réduire la latence d'accès à la mémoire globale. Cela peut être fait soit en augmentant la vitesse d'horloge de la mémoire (plus d'horloges par seconde, mais plus de chaleur et de consommation d'énergie), soit en augmentant le nombre d'éléments qui peuvent être transférés à la fois (largeur du bus).
Bande passante mémoire
Dans la section précédente, nous avons vu la vitesse des noyaux tensoriels. Ils sont si rapides qu'ils restent inactifs la plupart du temps, attendant l'arrivée des données de la mémoire globale. Par exemple, lors de la formation sur le projet BERT Large, où de très grandes matrices ont été utilisées - le plus grand, le meilleur pour les noyaux tensoriels - l'utilisation des noyaux tensoriels dans TFLOPS était d'environ 30%, ce qui signifie que 70% du temps, les noyaux tensoriels étaient inactifs.
Cela signifie que lors de la comparaison de deux GPU avec des cœurs de tenseur, l'un des meilleurs indicateurs de performance pour chacun est la bande passante mémoire. Par exemple, le GPU A100 a une bande passante de 1,555 Go / s, tandis que le V100 a 900 Go / s. Un simple calcul indique que l'A100 sera plus rapide que le V100 de 1555/900 = 1,73 fois.
Mémoire partagée / cache L1 / registres
Puisque le facteur limitant la vitesse est le transfert de données vers la mémoire des noyaux tensoriels, nous devons nous tourner vers d'autres propriétés du GPU, nous permettant d'accélérer le transfert des données vers eux. La mémoire partagée, le cache L1 et le nombre de registres sont associés. Pour comprendre comment la hiérarchie de la mémoire accélère les transferts de données, il est utile de comprendre comment la matrice se multiplie dans le GPU.
Pour la multiplication matricielle, nous utilisons une hiérarchie de mémoire qui va de la mémoire globale lente à la mémoire partagée locale rapide, puis aux registres ultra-rapides. Cependant, plus la mémoire est rapide, plus elle est petite. Par conséquent, nous devons diviser les matrices en plus petites, puis multiplier ces plus petites tuiles dans la mémoire partagée locale. Ensuite, cela se produira rapidement et plus près du multiprocesseur de streaming (PM) - l'équivalent du cœur du processeur. Les noyaux de tenseurs nous permettent de faire un pas de plus: nous prenons toutes les tuiles et en chargeons certaines dans des noyaux de tenseurs. La mémoire partagée traite les tuiles matricielles 10 à 50 fois plus rapidement que la mémoire GPU globale, et les registres du noyau du tenseur la traitent 200 fois plus vite que la mémoire GPU globale.
Augmenter la taille des tuiles nous permet de réutiliser plus de mémoire. J'ai écrit à ce sujet en détail dans mon article TPU vs GPU . En TPU, il y a une très, très grande tuile pour chaque noyau tenseur. Les TPU peuvent réutiliser beaucoup plus de mémoire à chaque nouveau transfert depuis la mémoire globale, ce qui les rend un peu plus efficaces pour gérer la multiplication matricielle par rapport aux GPU.
Les tailles de tuiles sont déterminées par la quantité de mémoire pour chaque PM - l'équivalent d'un cœur de processeur sur un GPU. Selon les architectures, ces volumes sont:
- Volta: 96 Ko de mémoire partagée / 32 Ko L1
- Turing: 64 Ko de mémoire partagée / 32 Ko L1
- Ampère: mémoire partagée de 164 Ko / 32 Ko L1
Vous pouvez voir qu'Ampère a beaucoup plus de mémoire partagée, ce qui permet d'utiliser des tuiles plus grandes, ce qui réduit le nombre d'accès à la mémoire globale. Par conséquent, Ampere utilise plus efficacement la bande passante de la mémoire du GPU. Cela augmente les performances de 2 à 5%. L'augmentation est particulièrement perceptible sur les énormes matrices.
Les noyaux de tenseurs ampères ont un autre avantage: ils ont une plus grande quantité de données communes à plusieurs threads. Cela réduit le nombre d'appels de registre. La taille des registres est limitée à 64 k par PM ou 255 par thread. Par rapport à Volta, les cœurs Tensor Ampère utilisent 3 fois moins de registres, il y a donc plus de cœurs Tensor actifs par tuile dans la mémoire partagée. En d'autres termes, nous pouvons charger 3 fois plus de cœurs tensoriels avec le même nombre de registres. Cependant, comme la bande passante reste un goulot d'étranglement, l'augmentation du TFLOPS dans la pratique sera négligeable par rapport à la théorie. Les nouveaux noyaux tenseurs ont amélioré les performances d'environ 1 à 3%.
Dans l'ensemble, on peut voir que l'architecture Ampère a été optimisée pour utiliser plus efficacement la bande passante mémoire grâce à une hiérarchie améliorée - de la mémoire globale aux tuiles de mémoire partagée en passant par les registres de tenseur de noyau.
Évaluation de l'efficacité d'Ampère dans GO
Résumé:
- Les estimations théoriques basées sur la bande passante mémoire et l'amélioration de la hiérarchie de la mémoire pour les GPU Ampere prédisent une accélération de 1,78 à 1,87 fois.
- NVIDIA a publié des données sur les mesures de vitesse pour les GPU Tesla A100 et V100. Ils sont plus marketing, mais vous pouvez construire un modèle impartial basé sur eux.
- Le modèle non biaisé suggère que par rapport au V100, le Tesla A100 est 1,7 fois plus rapide en traitement du langage naturel et 1,45 fois plus rapide en vision par ordinateur.
Cette section est destinée à ceux qui cherchent à approfondir les détails techniques de la façon dont j'ai obtenu les scores de performance du GPU Ampere. Si vous n'êtes pas intéressé, vous pouvez l'ignorer en toute sécurité.
Estimations de la vitesse théorique en ampère
Compte tenu des arguments ci-dessus, on pourrait s'attendre à ce que la différence entre les deux architectures GPU avec des cœurs tensoriels ait été principalement dans la bande passante mémoire. Les avantages supplémentaires proviennent de l'augmentation de la mémoire partagée et du cache L1, ainsi que de l'utilisation efficace des registres.
La bande passante du GPU Tesla A100 augmente de 1555/900 = 1,73 fois par rapport au Tesla V100. Il est également raisonnable de s'attendre à une augmentation de la vitesse de 2 à 5% en raison de la mémoire totale plus grande et de 1 à 3% en raison de l'amélioration des cœurs de tenseur. Il s'avère que l'accélération devrait être de 1,78 à 1,87 fois.
Ampere
Disons que nous avons un seul score GPU pour une architecture comme Ampère, Turing ou Volta. Il est facile d'extrapoler ces résultats à d'autres GPU de la même architecture ou série. Heureusement, NVIDIA a déjà effectué des tests de performances comparant l'A100 et le V100 sur diverses tâches liées à la vision par ordinateur et à la compréhension du langage naturel. Malheureusement, NVIDIA a fait tout son possible pour que ces chiffres ne puissent pas être comparés directement - les tests ont utilisé différentes tailles de paquets de données et différents nombres de GPU afin que l'A100 ne puisse pas gagner. Donc, dans un sens, les indicateurs de performance obtenus sont en partie honnêtes, en partie publicitaires. Dans l'ensemble, on peut faire valoir que l'augmentation de la taille des paquets de données est justifiée car l'A100 a plus de mémoire - cependantpour comparer les architectures GPU, nous devons comparer des données de performance non biaisées sur des tâches avec la même taille de paquet de données.
Pour obtenir des estimations non biaisées, vous pouvez mettre à l'échelle les mesures V100 et A100 de deux manières: prendre en compte la différence de taille des paquets de données, ou tenir compte de la différence du nombre de GPU - 1 contre 8. Nous avons de la chance et pouvons trouver des estimations similaires pour les deux cas dans les données fournies par NVIDIA.
Le doublement de la taille du paquet augmente le débit de 13,6% en images par seconde (pour les réseaux de neurones convolutifs, CNN). J'ai mesuré la vitesse de la même tâche avec l'architecture Transformer sur mon RTX Titan et, étonnamment, j'ai obtenu le même résultat - 13,5%. Cela semble être une estimation fiable.
En augmentant la parallélisation des réseaux, en augmentant le nombre de GPU, nous perdons des performances en raison de la surcharge associée aux réseaux. Mais le GPU A100 8x fonctionne mieux en réseau (NVLink 3.0) que le GPU V100 8x (NVLink 2.0) - un autre facteur déroutant. Si vous regardez les données de NVIDIA, vous pouvez voir que pour le traitement du SNS, le système avec le 8ème A100 a 5% de frais généraux en moins que le système avec le 8ème V10000. Cela signifie que si la transition du 1er A10000 au 8ème A10000 vous donne une accélération de, disons, 7,0 fois, alors la transition du 1er V10000 au 8ème V10000 vous donne une accélération de seulement 6,67 fois. Pour les transformateurs, ce chiffre est de 7%.
En utilisant ces informations, nous pouvons estimer l'accélération de certaines architectures GO spécifiques directement à partir des données fournies par NVIDIA. Le Tesla A100 présente les avantages de vitesse suivants par rapport au Tesla V100:
- SE-ResNeXt101: 1,43 fois.
- Masked-R-CNN: 1,47 fois.
- Transformateur (12 couches, traduction automatique, WMT14 en-de): 1,70 fois.
Par conséquent, pour la vision par ordinateur, les nombres sont obtenus en dessous de l'estimation théorique. Cela peut être dû à des mesures de tenseur plus petites, à la surcharge des opérations nécessaires pour préparer une multiplication matricielle comme img2col ou FFT, ou à des opérations qui ne peuvent pas saturer le GPU (les couches résultantes sont souvent relativement petites). Il peut également s'agir d'artefacts de certaines architectures (convolution groupée).
L'évaluation pratique de la vitesse du transformateur est très proche de l'évaluation théorique. Probablement parce que les algorithmes pour travailler avec de grandes matrices sont très simples. J'utiliserai des estimations pratiques pour calculer la rentabilité du GPU.
Imprécisions possibles dans les estimations
Les cotes ci-dessus sont comparatives pour A100 et V100. Dans le passé, NVIDIA a secrètement dégradé les performances des GPU RTX «gaming»: utilisation réduite des cœurs de tenseur, ajout de ventilateurs de jeu pour le refroidissement et transfert de données interdit entre les GPU. Il est possible que la série RT 30 ait également causé des dégradations inconnues sur l'Ampère A100.
Que considérer d'autre dans le cas de l'Ampère / RTX 30
Résumé:
- Ampere vous permet de former des réseaux sur la base de matrices clairsemées, ce qui accélère le processus de formation jusqu'à deux fois.
- La formation réseau éparse est encore rarement utilisée, mais grâce à elle, Ampère ne deviendra pas bientôt obsolète.
- Ampere a de nouveaux types de données de faible précision qui facilitent beaucoup l'utilisation de la faible précision, mais cela n'augmentera pas nécessairement la vitesse par rapport aux GPU précédents.
- La nouvelle conception du ventilateur est bonne si vous disposez d'un espace libre entre les GPU - cependant, il n'est pas clair si les GPU proches les uns des autres refroidiront efficacement.
- La conception à 3 emplacements du RTX 3090 sera un défi pour 4 versions de GPU. Les solutions possibles consistent à utiliser des options à 2 emplacements ou des extensions PCIe.
- Les quatre RTX 3090 auront besoin de plus de puissance que n'importe quel bloc d'alimentation standard du marché peut offrir.
Le nouveau NVIDIA Ampere RTX 30 présente des avantages supplémentaires par rapport au NVIDIA Turing RTX 20 - un apprentissage clairsemé et un traitement de réseau neuronal amélioré. Le reste des propriétés, comme les nouveaux types de données, peut être considéré comme une simple amélioration de la commodité - ils accélèrent les choses de la même manière que la série Turing, sans nécessiter de programmation supplémentaire.
Apprentissage clairsemé
Ampere vous permet de multiplier des matrices clairsemées à grande vitesse et automatiquement. Cela fonctionne comme ceci - vous prenez une matrice, vous la coupez en morceaux de 4 éléments, et le noyau tenseur supportant des matrices clairsemées permet à deux de ces quatre éléments d'être nuls. Il en résulte une accélération 2x car les besoins en bande passante lors de la multiplication de la matrice sont divisés par deux.
Dans mes recherches, j'ai travaillé avec des réseaux d'apprentissage clairsemés. Le travail a été critiqué, notamment, pour le fait que je "réduisais les FLOPS nécessaires au réseau, mais n'augmentais pas la vitesse à cause de cela, car les GPU ne peuvent pas multiplier rapidement les matrices clairsemées". Eh bien - la prise en charge de la multiplication matricielle éparse est apparue dans les noyaux tensoriels, et mon algorithme, ou tout autre algorithme ( lien, link , link , link ), fonctionnant avec des matrices clairsemées, peuvent désormais fonctionner deux fois plus vite pendant l'entraînement.
Bien que cette propriété soit actuellement considérée comme expérimentale et qu'une formation réseau clairsemée ne soit pas appliquée universellement, si votre GPU prend en charge cette technologie, vous êtes prêt pour l'avenir de la formation clairsemée.
Calculs de faible précision
J'ai déjà démontré comment de nouveaux types de données peuvent améliorer la stabilité de la rétropropagation basse fidélité dans mon travail. Jusqu'à présent, le problème avec une rétropropagation stable avec des nombres à virgule flottante de 16 bits est que les types de données normaux ne supportent que le span [-65,504, 65,504]. Si votre dégradé dépasse cet écart, il explosera, produisant des valeurs NaN. Pour éviter cela, nous mettons généralement les valeurs à l'échelle en les multipliant par un petit nombre avant de procéder à une rétropropagation pour éviter l'explosion du gradient.
Le format Brain Float 16 (BF16) utilise plus de bits pour l'exposant, de sorte que la plage de valeurs possibles est la même que dans FP32: [-3 * 10 ^ 38, 3 * 10 ^ 38]. Le BF16 a moins de précision, c.-à-d. moins de chiffres significatifs, mais la précision du gradient lors de la formation des réseaux n'est pas si importante. Par conséquent, BF16 garantit que vous n'avez pas à faire de mise à l'échelle ou à vous soucier de l'explosion du gradient. Avec ce format, on devrait voir une augmentation de la stabilité de l'entraînement au détriment d'une petite perte de précision.
Ce que cela signifie pour vous: la précision du BF16 peut être plus cohérente que la précision du FP16, mais la vitesse est la même. Avec la précision TF32, vous obtenez une stabilité presque comme FP32 et une accélération presque comme FP16. L'avantage est que lorsque vous utilisez ces types de données, vous pouvez changer FP32 en TF32 et FP16 en BF16, sans rien changer dans le code!
En général, ces nouveaux types de données peuvent être considérés comme paresseux, dans le sens où vous pourriez obtenir tous leurs avantages en utilisant les anciens types de données et un peu de programmation (mise à l'échelle correctement, initialisation, normalisation, utilisation d'Apex). Par conséquent, ces types de données ne fournissent pas d'accélération, mais facilitent l'utilisation de la basse fidélité dans la formation.
Nouvelle conception du ventilateur et problèmes de dissipation thermique
Le nouveau design du ventilateur de la série RTX 30 comprend un ventilateur soufflant et un ventilateur extracteur d'air. La conception elle-même est ingénieuse et fonctionnera très efficacement s'il y a de l'espace libre entre les GPU. Cependant, le comportement des GPU n'est pas clair s'ils sont forcés l'un à l'autre. Le ventilateur soufflant sera capable de souffler l'air des autres GPU, mais il est impossible de dire comment cela fonctionnera car sa forme est différente de ce qu'elle était auparavant. Si vous prévoyez de mettre 1 ou 2 GPU là où il y a 4 slots, vous ne devriez pas avoir de problème. Mais si vous souhaitez utiliser 3-4 GPU RTX 30 côte à côte, j'attendrais d'abord les rapports sur les conditions de température, puis je décidais si j'avais besoin de plus de ventilateurs, d'extensions PCIe ou d'autres solutions.
Dans tous les cas, le refroidissement par eau peut aider à résoudre le problème du dissipateur thermique. De nombreux fabricants proposent de telles solutions pour les cartes RTX 3080 / RTX 3090, et elles ne chaufferont pas, même s'il y en a 4. Cependant, n'achetez pas de solutions GPU prêtes à l'emploi si vous souhaitez construire un ordinateur avec 4 GPU, car ce sera très difficile dans la plupart des cas distribuer des radiateurs.
Une autre solution au problème de refroidissement consiste à acheter des extensions PCIe et à distribuer les cartes à l'intérieur du boîtier. C'est très efficace - moi et d'autres étudiants diplômés de l'Université de Vanington avons utilisé cette option avec beaucoup de succès. Cela n'a pas l'air très soigné, mais les GPU ne chauffent pas! En outre, cette option vous aidera au cas où vous ne disposez pas de suffisamment d'espace pour accueillir le GPU. Si vous avez de la place dans votre boîtier, vous pouvez, par exemple, acheter un RTX 3090 standard avec trois emplacements et les distribuer à l'aide d'extensions dans tout le boîtier. Ainsi, il est possible de résoudre simultanément le problème de l'encombrement et du refroidissement de 4 RTX 3090.

Fig. GPU 1: 4 avec extensions PCIe
Cartes à trois emplacements et problèmes d'alimentation
Le RTX 3090 occupe 3 emplacements, ils ne peuvent donc pas être utilisés 4 chacun avec les ventilateurs par défaut de NVIDIA. Cela n'est pas surprenant car il nécessite 350W TDP. Le RTX 3080 n'est que légèrement inférieur, nécessitant un TDP de 320 W, et le refroidissement d'un système avec quatre RTX 3080 sera très difficile.
Il est également difficile d'alimenter un système avec 4 cartes de 350W = 1400W. Il existe des blocs d'alimentation (PSU) de 1600 W, mais 200 W pour le processeur et la carte mère peuvent ne pas suffire. La consommation électrique maximale se produit uniquement à pleine charge, et pendant HE, le processeur est généralement légèrement chargé. Par conséquent, un bloc d'alimentation de 1600W peut convenir à 4 RTX 3080, mais pour 4 RTX 3090, il est préférable de rechercher un bloc d'alimentation de 1700W ou plus. Il n'y a pas de telles PSU sur le marché aujourd'hui. Les PSU de serveur ou les blocs spéciaux pour les cryptomineurs peuvent fonctionner, mais ils peuvent avoir un facteur de forme inhabituel.
Efficacité GPU dans le Deep Learning
Le test suivant comprenait non seulement des comparaisons de Tesla A100 et Tesla V100 - j'ai construit un modèle qui s'inscrit dans ces données et quatre tests différents, où Titan V, Titan RTX, RTX 2080 Ti et RTX 2080 ont été testés ( lien , lien , lien , lien ).
J'ai également mis à l'échelle les résultats de référence pour les cartes de milieu de gamme telles que RTX 2070, RTX 2060 ou Quadro RTX en interpolant les points de données de test. En règle générale, dans l'architecture GPU, ces données sont mises à l'échelle de manière linéaire par rapport à la multiplication de la matrice et à la bande passante mémoire.
Je n'ai collecté que des données de tests d'entraînement FP16 avec une précision mitigée car je ne vois aucune raison d'utiliser l'entraînement avec des nombres FP32.

Figure: 2: Performances normalisées par RTX 2080 Ti
Par rapport au RTX 2080 Ti, le RTX 3090 fonctionne 1,57 fois plus vite avec les réseaux convolutifs, 1,5 fois plus rapide avec les transformateurs et coûte 15% de plus. Il s'avère que l'Ampère RTX 30 montre une amélioration significative depuis la série Turing RTX 20.
Taux d'apprentissage profond GPU par coût
Quel GPU serait le meilleur rapport qualité / prix? Tout dépend du coût total du système. Si cela coûte cher, il est logique d'investir dans des GPU plus chers.
Vous trouverez ci-dessous des données sur trois assemblages sur PCIe 3.0, que j'utilise comme référence pour le coût des systèmes avec 2 ou 4 GPU. Je prends ce coût de base et j'y ajoute le coût du GPU. Je calcule ce dernier comme le prix moyen entre les offres d'Amazon et d'eBay. Pour le nouvel Ampère, je n'utilise qu'un seul prix. Pris avec les données de performance ci-dessus, cela donne les valeurs de performance par dollar. Pour un système avec 8 GPU, je considère le barebone Supermicro comme un standard de l'industrie pour les serveurs RTX. Les graphiques affichés n'incluent pas les besoins en mémoire. Vous devez d'abord réfléchir à la mémoire dont vous avez besoin, puis rechercher les meilleures options sur les graphiques. Exemples de conseils pour la mémoire:
- Utilisation de transformateurs pré-entraînés ou formation d'un petit transformateur à partir de zéro> = 11 Go.
- Formation d'un gros transformateur ou d'un réseau convolutif en recherche ou en production:> = 24 Go.
- Prototypage de réseaux de neurones (transformateur ou réseau convolutif)> = 10 Go.
- Participation aux concours Kaggle> = 8 Go.
- Vision par ordinateur> = 10 Go.
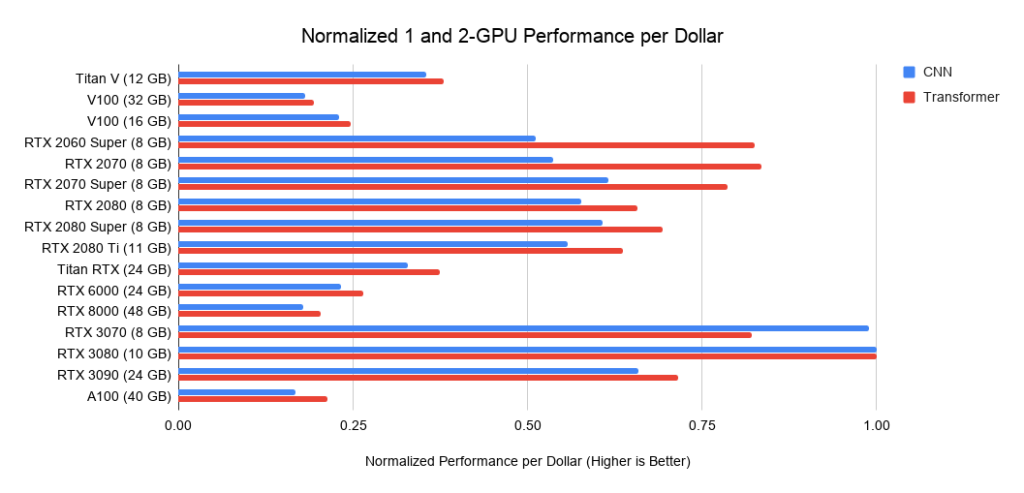
Figure:

Figure 3: performances du dollar normalisées par rapport au RTX 3080 . Figure 4: performances en dollars normalisées par rapport au RTX 3080
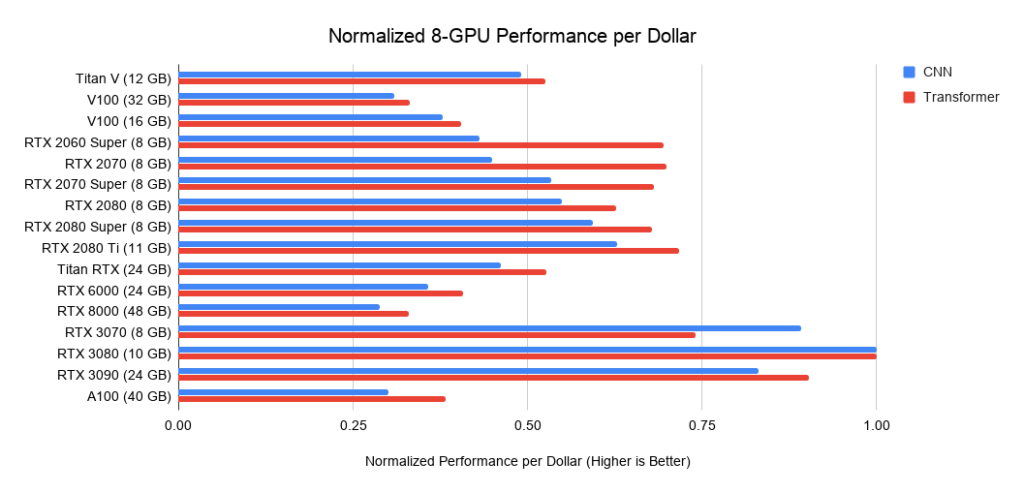
. 5: performances en dollars normalisées par rapport au RTX 3080.
Recommandations GPU
Encore une fois, je tiens à souligner: lors du choix d'un GPU, assurez-vous d'abord qu'il dispose de suffisamment de mémoire pour vos tâches. Les étapes pour choisir un GPU doivent être les suivantes:
- , GPU: Kaggle, , , , - .
- , .
- GPU, .
- GPU - ? , RTX 3090, ? GPU? , GPU?
Certaines des étapes vous obligent à réfléchir à ce que vous voulez et à faire un peu de recherche sur la quantité de mémoire que d'autres personnes utilisent pour faire de même. Je peux donner quelques conseils, mais je ne peux pas répondre pleinement à toutes les questions dans ce domaine.
Quand aurai-je besoin de plus de 11 Go de stockage?
J'ai déjà mentionné que lorsque vous travaillez avec des transformateurs, vous aurez besoin d'au moins 11 Go, et lors de la recherche dans ce domaine, d'au moins 24 Go. La plupart des modèles pré-entraînés précédents ont des exigences de mémoire très élevées et ont été formés sur un GPU RTX 2080 Ti ou supérieur avec au moins 11 Go de mémoire. Par conséquent, si vous disposez de moins de 11 Go de mémoire, le lancement de certains modèles peut devenir difficile, voire impossible.
L'imagerie médicale, les modèles avancés de vision par ordinateur et tous avec de grandes images sont d'autres domaines qui nécessitent une grande quantité de mémoire.
Dans l'ensemble, si vous cherchez à développer des modèles qui peuvent surpasser la concurrence - qu'il s'agisse de recherche, d'applications industrielles ou de la concurrence Kaggle - la mémoire supplémentaire peut vous donner un avantage concurrentiel.
Quand pouvez-vous vous en tirer avec moins de 11 Go de mémoire?
Les cartes RTX 3070 et RTX 3080 sont puissantes, mais manquent de mémoire. Cependant, pour de nombreuses tâches, cette quantité de mémoire peut ne pas être requise.
Le RTX 3070 est idéal pour l'entraînement GO. Les compétences de base en réseau pour la plupart des architectures peuvent être acquises en réduisant les réseaux ou en utilisant des images plus petites. Si je devais apprendre GO, je choisirais le RTX 3070, ou même quelques-uns si je pouvais me le permettre.
La RTX 3080 est la carte la plus rentable aujourd'hui et est donc idéale pour le prototypage. Le prototypage nécessite une grande quantité de mémoire et la mémoire est peu coûteuse. Par prototypage, j'entends le prototypage dans n'importe quel domaine - recherche, concours Kaggle, essai d'idées pour une startup, expérimentation de code de recherche. Pour toutes ces applications, le RTX 3080 est le mieux adapté.
Si, par exemple, je dirigeais un laboratoire de recherche ou une startup, je dépenserais 66 à 80% du budget total sur des machines RTX 3080 et 20 à 33% sur des machines RTX 3090 avec un refroidissement par eau fiable. RTX 3080 est plus rentable et est accessible via Slurm... Étant donné que le prototypage doit être effectué en mode agile, il doit être effectué avec des modèles et des ensembles de données plus petits. Et le RTX 3080 est parfait pour cela. Une fois que les étudiants / collègues ont construit un excellent modèle de prototype, ils peuvent le déployer sur le RTX 3090, en passant à des modèles plus grands.
Recommandations générales
Dans l'ensemble, les modèles de la série RTX 30 sont très puissants et je les recommande vivement. Tenez compte des besoins en mémoire comme indiqué précédemment, ainsi que des exigences en matière d'alimentation et de refroidissement. Si vous avez un emplacement libre entre les GPU, il n'y aura aucun problème de refroidissement. Sinon, fournissez aux cartes RTX 30 un refroidissement par eau, des extensions PCIe ou des cartes efficaces avec ventilateurs.
Dans l'ensemble, je recommanderais le RTX 3090 à tous ceux qui peuvent se le permettre. Cela ne vous conviendra pas seulement maintenant, mais il restera très efficace pour les 3-7 prochaines années. Il est peu probable que dans les trois prochaines années, la mémoire HBM devienne beaucoup moins chère, donc le prochain GPU ne sera que 25% meilleur que le RTX 3090. Dans 5 à 7 ans, nous verrons probablement une mémoire HBM bon marché, après quoi vous devrez certainement mettre à jour la flotte ...
Si vous construisez un système à partir de plusieurs RTX 3090, fournissez-leur suffisamment de refroidissement et d'alimentation.
Sauf si vous avez des exigences strictes pour un avantage concurrentiel, je recommanderais le RTX 3080. Il s'agit d'une solution plus rentable et fournira une formation rapide pour la plupart des réseaux. Si vous faites les astuces de mémoire que vous voulez et que cela ne vous dérange pas d'écrire du code supplémentaire, il existe de nombreuses astuces pour entasser un réseau de 24 Go dans un GPU de 10 Go.
Le RTX 3070 est également une excellente carte pour la formation GO et le prototypage, et coûte 200 $ moins cher que le RTX 3080. Si vous ne pouvez pas vous permettre le RTX 3080, alors le RTX 3070 est votre choix.
Si votre budget est serré et que le RTX 3070 est trop cher pour vous, vous pouvez trouver un RTX 2070 d'occasion sur eBay pour environ 260 $. On ne sait pas encore si le RTX 3060 sortira, mais si votre budget est serré, cela vaut peut-être la peine d'attendre. Si son prix correspond à celui du RTX 2060 et de la GTX 1060, il devrait se situer entre 250 et 300 dollars, et il devrait bien fonctionner.
Recommandations pour les clusters GPU
La disposition du cluster GPU dépend fortement de son utilisation. Pour un système avec 1024 GPU ou plus, l'essentiel sera la présence d'un réseau, mais si vous n'utilisez pas plus de 32 GPU à la fois, il ne sert à rien d'investir dans la construction d'un réseau puissant.
En général, les cartes RTX ne peuvent pas être utilisées dans les centres de données dans le cadre de l'accord CUDA. Cependant, les universités peuvent souvent faire exception à cette règle. Si vous souhaitez obtenir une telle autorisation, contactez un représentant NVIDIA. Si vous pouvez utiliser des cartes RTX, je recommanderais le système standard 8 GPU RTX 3080 ou RTX 3090 de Supermicro (si vous pouvez les garder au frais). Un petit ensemble de 8 nœuds A10000 assure une utilisation efficace des modèles après le prototypage, en particulier si le refroidissement des serveurs avec 8 RTX 3090 n'est pas possible. Dans ce cas, je recommanderais l'A10000 plutôt que le RTX 6000 / RTX 8000 car les A10000 sont assez rentables et ne vieilliront pas rapidement.
Si vous avez besoin de former de très grands réseaux sur un cluster GPU (256 GPU ou plus), je recommanderais le système NVIDIA DGX SuperPOD avec A10000. à partir de 256 GPU, la mise en réseau devient essentielle. Si vous souhaitez étendre au-delà de 256 GPU, vous aurez besoin d'un système hautement optimisé pour lequel les solutions standard ne fonctionneront plus.
Surtout à 1 024 échelles GPU et au-delà, les seules solutions concurrentes sur le marché restent Google TPU Pod et NVIDIA DGX SuperPod. À cette échelle, je préférerais le Google TPU Pod, car leur infrastructure réseau dédiée est meilleure que le NVIDIA DGX SuperPod - bien qu'en principe, les deux systèmes soient assez proches. Dans les applications et le matériel, le système GPU est plus flexible que le TPU, tandis que les systèmes TPU prennent en charge des modèles plus grands et évoluent mieux. Par conséquent, les deux systèmes ont leurs avantages et leurs inconvénients.
Quel GPU vaut mieux ne pas acheter
Je ne recommande pas d'acheter plusieurs éditions RTX Founders ou RTX Titans à la fois, sauf si vous avez des extensions PCIe pour résoudre leurs problèmes de refroidissement. Ils vont juste s'échauffer et leur vitesse diminuera considérablement par rapport à ce qui est indiqué dans les graphiques. Les quatre éditions Founders RTX 2080 Ti chaufferont rapidement jusqu'à 90 ° C, réduiront la vitesse d'horloge et fonctionneront plus lentement qu'un RTX 2070 normalement refroidi.
Je recommande d'acheter un Tesla V100 ou A100 uniquement dans les cas extrêmes, car il est interdit de les utiliser dans les centres de données des entreprises. Ou achetez-les si vous avez besoin de former de très grands réseaux sur d'énormes clusters de GPU - leur rapport prix / performances n'est pas idéal.
Si vous pouvez vous offrir quelque chose de mieux, n'optez pas pour les cartes de la série GTX 16. Ils n'ont pas de noyau tenseur, donc leurs performances dans GO sont médiocres. Je prendrais plutôt un RTX 2070 / RTX 2060 / RTX 2060 Super d'occasion. Ils peuvent être empruntés si votre budget est très limité.
Quand vaut-il mieux ne pas acheter de nouveaux GPU?
Si vous possédez déjà un RTX 2080 Ti ou supérieur, la mise à niveau vers un RTX 3090 est presque inutile. Vos GPU sont déjà bons et les avantages de vitesse seront négligeables par rapport aux problèmes d'alimentation et de refroidissement acquis - cela n'en vaut pas la peine.
La seule raison pour laquelle je voudrais passer de quatre RTX 2080 Ti à quatre RTX 3090 est si je faisais des recherches sur de très gros transformateurs ou d'autres réseaux qui dépendent fortement de la puissance de calcul. Cependant, si vous rencontrez des problèmes de mémoire, vous devez d'abord envisager diverses astuces pour entasser de gros modèles dans la mémoire existante.
Si vous possédez un ou plusieurs RTX 2070, j'y réfléchirais à deux fois si j'étais à votre place avant la mise à niveau. Ce sont de très bons GPU. Il peut être judicieux de les vendre sur eBay et d'acheter un RTX 3090 si 8 Go ne vous suffisent pas - comme c'est le cas avec de nombreux autres GPU. S'il n'y a pas assez de mémoire, une mise à jour est en cours de préparation.
Réponses aux questions et idées fausses
Résumé:
- Les voies PCIe et PCIe 4.0 ne sont pas pertinentes pour les systèmes à double GPU. Pour les systèmes avec 4 GPU, ils n'en ont pratiquement pas.
- Le refroidissement des RTX 3090 et RTX 3080 sera difficile. Utilisez des refroidisseurs d'eau ou des extensions PCIe.
- NVLink n'est nécessaire que pour les clusters GPU.
- Différents GPU peuvent être utilisés sur le même ordinateur (par exemple, GTX 1080 + RTX 2080 + RTX 3090), mais une parallélisation efficace ne fonctionnera pas.
- Pour exécuter plus de deux machines en parallèle, vous avez besoin d'Infiniband et d'un réseau 50 Gbps.
- Les processeurs AMD sont moins chers que les processeurs Intel, et ces derniers n'ont pratiquement aucun avantage.
- Malgré les efforts héroïques des ingénieurs, AMD GPU + ROCm ne pourra guère rivaliser avec NVIDIA en raison du manque de communauté et de cœurs de tenseurs équivalents dans les 1 à 2 prochaines années.
- Les GPU cloud sont avantageux s'ils sont utilisés pendant moins d'un an. Après cela, la version de bureau devient moins chère.
Ai-je besoin de PCIe 4.0?
Généralement pas. PCIe 4.0 est idéal pour un cluster GPU. Utile si vous avez une machine à 8 GPU. Dans d'autres cas, cela n'a pratiquement aucun avantage. Il améliore la parallélisation et transfère les données un peu plus rapidement. Mais le transfert de données n'est pas un goulot d'étranglement. Dans la vision par ordinateur, le goulot d'étranglement peut être le stockage des données, mais pas le transfert de données PCIe du GPU au GPU. Il n'y a donc aucune raison pour que la plupart des gens utilisent PCIe 4.0. Cela améliorera éventuellement la parallélisation de quatre GPU de 1 à 7%.
Ai-je besoin de voies PCIe 8x / 16x?
Comme avec PCIe 4.0, généralement pas. Des voies PCIe sont nécessaires pour la parallélisation et le transfert rapide des données, ce qui n'est presque jamais un goulot d'étranglement. Si vous avez 2 GPU, 4 lignes leur suffisent. Pour 4 GPU, je préférerais 8 lignes par GPU, mais s'il y a 4 lignes, cela diminuera les performances de seulement 5-10%.
Comment installez-vous quatre RTX 3090 lorsqu'ils occupent chacun 3 emplacements PCIe?
Vous pouvez acheter l'une des deux options pour un emplacement ou les distribuer à l'aide d'extensions PCIe. En plus de l'espace, vous devez immédiatement penser au refroidissement et à une alimentation adaptée. Apparemment, la solution la plus simple serait d'acheter 4 x RTX 3090 EVGA Hydro Coppers avec une boucle de refroidissement par eau dédiée. EVGA fabrique des versions de cartes en cuivre refroidies à l'eau depuis de nombreuses années et vous pouvez faire confiance à la qualité de leurs GPU. Il existe peut-être des options moins chères.
Les extensions PCIe peuvent résoudre les problèmes d'espace et de refroidissement, mais votre boîtier doit avoir suffisamment de place pour toutes les cartes. Et assurez-vous que les rallonges sont suffisamment longues!
Comment refroidir 4 RTX 3090 ou 4 RTX 3080?
Voir la section précédente.
Puis-je utiliser plusieurs types de GPU différents?
Oui, mais vous ne serez pas en mesure de paralléliser efficacement le travail. J'imagine un système fonctionnant avec 3 RTX 3070 + 1 RTX 3090. Par contre, la parallélisation entre quatre RTX 3070 fonctionnera très rapidement si vous fourrez votre modèle dessus. Et une autre raison pour laquelle vous pourriez en avoir besoin est l'utilisation d'anciens GPU. Cela fonctionnera, mais la parallélisation sera inefficace, car les GPU les plus rapides attendront les GPU les plus lents aux points de synchronisation (généralement sur une mise à jour en gradient).
Qu'est-ce que NVLink et en ai-je besoin?
Vous n'avez généralement pas besoin de NVLink. Il s'agit d'une communication à haut débit entre plusieurs GPU. Il est nécessaire si vous disposez d'un cluster de 128 GPU ou plus. Dans d'autres cas, il n'a pratiquement aucun avantage par rapport au transfert de données PCIe standard.
Je n’ai pas l’argent pour vos recommandations les moins chères. Que faire?
Acheter définitivement un GPU d'occasion. RTX 2070 (400 $) et RTX 2060 (300 $) d'occasion feront très bien l'affaire. Si vous ne pouvez pas vous le permettre, la meilleure option suivante serait une GTX 1070 d'occasion (220 $) ou une GTX 1070 Ti (230 $). Si c'est trop cher, trouvez une GTX 980 Ti d'occasion (6 Go 150 $) ou GTX 1650 Super (190 $). Si c'est cher aussi, il vaut mieux utiliser les services cloud. Ils fournissent généralement aux GPU une limite de temps ou de puissance, après quoi vous devez payer. Échangez les services jusqu'à ce que vous puissiez vous permettre votre propre GPU.
Que faut-il pour paralléliser un projet entre deux machines?
Pour accélérer le travail grâce à la parallélisation entre deux machines, vous avez besoin de cartes réseau de 50 Gbit / s ou plus. Je recommande d'installer au moins EDR Infiniband - c'est-à-dire une carte réseau avec une vitesse d'au moins 50 Gbps. Deux cartes EDR avec câble sur eBay vous coûteront 500 $.
Dans certains cas, vous pouvez vous en tirer avec Ethernet 10 Gbps, mais cela ne fonctionne généralement que pour certains types de réseaux neuronaux (certains réseaux convolutifs) ou pour certains algorithmes (Microsoft DeepSpeed).
Les algorithmes de multiplication de matrice clairsemée conviennent-ils à toute matrice clairsemée?
Apparemment non. Puisqu'une matrice doit avoir 2 zéros pour 4 éléments, les matrices clairsemées doivent être bien structurées. Il est probablement possible de modifier légèrement l'algorithme en traitant 4 valeurs comme une représentation compressée de deux valeurs, mais cela signifiera que la multiplication exacte des matrices clairsemées par Ampère ne sera pas disponible.
Ai-je besoin d'un processeur Intel pour exécuter plusieurs GPU?
Je ne recommande pas d'utiliser un processeur Intel, à moins que vous ne mettiez beaucoup de stress sur le processeur dans les concours Kaggle (où le processeur est chargé de calculs d'algèbre linéaire). Et même pour de telles compétitions, les processeurs AMD sont excellents. Les processeurs AMD sont en moyenne moins chers et meilleurs pour GO. Pour une version à 4 GPU, Threadripper est mon choix définitif. Dans notre université, nous avons rassemblé des dizaines de systèmes basés sur de tels processeurs, et ils fonctionnent tous parfaitement, sans aucune plainte. Pour les systèmes avec 8 GPU, je prendrais le processeur avec lequel votre fabricant a de l'expérience. La fiabilité des processeurs et PCIe dans les systèmes à 8 cartes est plus importante que les performances ou la rentabilité.
La forme du boîtier est-elle importante pour le refroidissement?
Non. Habituellement, les GPU refroidissent parfaitement s'il y a même de petits écarts entre les GPU. Différents boîtiers peuvent vous donner une différence de 1 à 3 ° C et un espacement de carte différent peut vous donner une différence de 10 à 30 ° C. En général, s'il y a des espaces entre vos cartes, il n'y a pas de problème de refroidissement. S'il n'y a pas de lacunes, vous avez besoin des bons ventilateurs (ventilateur soufflant) ou d'une autre solution (refroidissement par eau, extensions PCIe). Dans tous les cas, le type de boîtier et ses ventilateurs importent peu.
AMD GPU + ROCm rattrapera-t-il un jour le GPU NVIDIA + CUDA?
Pas dans les prochaines années. Il y a trois problèmes: les noyaux tensoriels, les logiciels et la communauté.
Les cristaux GPU eux-mêmes d'AMD sont bons: excellentes performances sur FP16, excellente bande passante mémoire. Mais l'absence de cœurs tensoriels ou de leur équivalent conduit au fait que leurs performances en pâtissent par rapport au GPU de NVIDIA. Et sans la mise en œuvre de cœurs de tenseurs dans le matériel, les GPU AMD ne seront jamais compétitifs. Selon les rumeurs, une sorte de carte pour les centres de données avec un analogue des cœurs de tenseur est prévue pour 2020, mais il n'y a pas encore de données exactes. S'ils ne disposent que d'une carte équivalente Tensor Core pour les serveurs, cela signifierait que peu de gens peuvent se permettre des GPU AMD, ce qui donnerait à NVIDIA un avantage concurrentiel.
Disons qu'AMD introduira à l'avenir du matériel avec quelque chose comme des cœurs de tenseurs. Ensuite, beaucoup diront: «Mais il n'y a pas de programmes fonctionnant avec les GPU AMD! Comment puis-je les utiliser? " C'est surtout une idée fausse. Le logiciel AMD exécutant ROCm est déjà bien développé et le support dans PyTorch est bien organisé. Et bien que je n'ai pas vu beaucoup de rapports sur le travail d'AMD GPU + PyTorch, toutes les fonctions logicielles y sont intégrées. Apparemment, vous pouvez choisir n'importe quel réseau et l'exécuter sur un GPU AMD. Par conséquent, AMD est déjà bien développé dans ce domaine et ce problème a été pratiquement résolu.
Cependant, avec le logiciel et le manque de cœurs de tenseurs résolus, AMD sera confronté à un autre: un manque de communauté. Lorsque vous rencontrez un problème avec les GPU NVIDIA, vous pouvez rechercher une solution sur Google et la trouver. Cela renforce la confiance dans les GPU NVIDIA. Une infrastructure émerge pour faciliter l'utilisation des GPU NVIDIA (toute plate-forme pour GO fonctionne, toute tâche scientifique est prise en charge). Il existe un tas de hacks et astuces qui facilitent l'utilisation des GPU NVIDIA (par exemple, apex). Des experts et programmeurs de GPU NVIDIA se trouvent sous tous les buissons, mais je connais beaucoup moins d'experts en GPU AMD.
Au niveau de la communauté, la situation AMD est similaire à celle de Julia vs Python. Julia a beaucoup de potentiel, et beaucoup souligneront à juste titre que ce langage de programmation est mieux adapté aux travaux scientifiques. Cependant, Julia est rarement utilisée par rapport à Python. C'est juste que la communauté Python est très grande. Il y a des tonnes de gens qui se rassemblent autour de packages puissants comme Numpy, SciPy et Pandas. Cette situation est similaire à celle de NVIDIA vs AMD.
Par conséquent, il est très probable qu'AMD ne rattrapera pas NVIDIA tant qu'il n'aura pas introduit l'équivalent des cœurs tensoriels et une communauté solide construite autour de ROCm. AMD aura toujours sa part de marché dans des sous-groupes spécifiques (extraction de crypto-monnaie, centres de données). Mais NVIDIA détiendra probablement le monopole pendant encore deux ans.
Quand est-il préférable d'utiliser les services cloud et quand est-il un ordinateur GPU dédié?
Une règle de base simple: si vous prévoyez de faire GO pendant plus d'un an, il est moins cher d'acheter un ordinateur avec un GPU. Sinon, il est préférable d'utiliser les services cloud, à moins que vous n'ayez une vaste expérience de la programmation cloud et que vous souhaitiez profiter de la mise à l'échelle du nombre de GPU à volonté.
Le point de basculement exact auquel les GPU cloud deviennent plus chers que votre propre ordinateur dépend fortement des services utilisés. Il vaut mieux le calculer vous-même. Vous trouverez ci-dessous un exemple de calcul pour un serveur AWS V100 avec un V100 et le comparant au coût d'un ordinateur de bureau avec un RTX 3090, dont les performances sont proches. Un PC RTX 3090 coûte 2200 $ (barebone 2 GPU + RTX 3090). Si vous êtes aux États-Unis, ajoutez 0,12 $ par kWh pour l'électricité. Comparez cela à 2,14 USD par heure et par serveur sur AWS.
À 15% de recyclage par an, l'ordinateur utilise
(350 W (GPU) + 100 W (CPU)) * 0,15 (recyclage) * 24 heures * 365 jours = 591 kWh par an.
591 kWh par an donnent 71 $ supplémentaires.
Le point de basculement, lorsque le prix de l'ordinateur et du cloud se compare à 15% d'utilisation, arrive au 300e jour (2311 $ vs 2270 $):
2,14 $ / h * 0,15 (recyclage) * 24 heures * 300 jours = 2311 $
Si vous calculez, que vos modèles GO dureront plus de 300 jours, il vaut mieux acheter un ordinateur que d'utiliser AWS.
Des calculs similaires peuvent être effectués pour n'importe quel service cloud afin de décider d'utiliser votre ordinateur ou le cloud.
Les chiffres courants d'utilisation de la puissance de calcul sont les suivants:
- Ordinateur de doctorat: <15%;
- Cluster GPU sur PhD Slurm:> 35%
- Cluster de recherche d'entreprise sur Slurm:> 60%.
En général, les taux de recyclage sont plus faibles dans les domaines où la réflexion sur des idées innovantes est plus importante que le développement de solutions pratiques. Dans certaines régions, le taux d'utilisation est plus faible (études d'interprétabilité), tandis que dans d'autres, il est beaucoup plus élevé (traduction automatique, modélisation du langage). En général, le recyclage des voitures personnelles est toujours surestimé. En règle générale, la plupart des systèmes personnels sont recyclés de 5 à 10%. Par conséquent, je recommande vivement aux équipes de recherche et aux entreprises d'organiser des clusters GPU sur Slurm au lieu de postes de travail séparés.
Conseils pour ceux qui sont trop paresseux pour lire
Meilleurs GPU dans l'ensemble : RTX 3080 et RTX 3090.
GPU à éviter (en tant que chercheur) : cartes Tesla, Quadro, Founders Edition, Titan RTX, Titan V, Titan XP.
Bon rapport performance / prix, mais cher : RTX 3080.
Bon rapport performance / prix, moins cher : RTX 3070, RTX 2060 Super.
J'ai peu d'argent : achetez des cartes d'occasion. Hiérarchie: RTX 2070 (400 $), RTX 2060 (300 $), GTX 1070 (220 $), GTX 1070 Ti (230 $), GTX 1650 Super (190 $), GTX 980 Ti (6 Go 150 $).
Je n'ai presque pas d'argent : de nombreuses startups annoncent leurs services cloud. Utilisez des crédits gratuits dans les nuages, changez-les en cercle jusqu'à ce que vous puissiez acheter un GPU.
Je participe à des compétitions Kaggle: RTX 3070. J'essaye
de gagner le concours en vision par ordinateur, pré-formation ou traduction automatique : 4 pièces RTX 3090. Mais attendez que les experts confirment qu'il existe des assemblages avec un bon refroidissement et une puissance suffisante.
J'apprends le traitement du langage naturel : si vous n'êtes pas dans la traduction automatique, la modélisation du langage ou le pré-apprentissage, le RTX 3080 fera l'affaire.
J'ai commencé à faire du GO et je me suis vraiment intéressé: commencez par le RTX 3070. Si vous ne vous ennuyez pas dans 6 à 9 mois, vendez et achetez quatre RTX 3080. En fonction de ce que vous choisissez ensuite (démarrage, Kaggle, recherche, GO appliqué), années en trois, vendez vos GPU et achetez quelque chose de mieux (GPU RTX nouvelle génération).
Je veux essayer GO, mais je n'ai aucune intention sérieuse : RTX 2060 Super sera un excellent choix, cependant, il peut nécessiter le remplacement du bloc d'alimentation. Si vous avez un slot PCIe x16 sur votre carte mère et que le bloc d'alimentation produit environ 300 watts, la GTX 1050 Ti sera une excellente option, car elle ne nécessite pas d'autres investissements.
Cluster GPU pour simulation parallèle avec moins de 128 GPU : si vous êtes autorisé à acheter du RTX pour le cluster: 66% 8x RTX 3080 et 33% 8x RTX 3090 (uniquement si vous pouvez bien refroidir l'assemblage). Si le refroidissement ne suffit pas, achetez un GPU 33% RTX 6000 ou 8x Tesla A100. Si vous ne pouvez pas acheter un GPU RTX, j'opterais pour 8 nœuds Supermicro A100 ou 8 nœuds RTX 6000.
Cluster GPU pour la simulation parallèle avec plus de 128 GPU: Pensez aux voitures avec 8 Tesla A100. Si vous avez besoin de plus de 512 GPU, pensez au système DGX A100 SuperPOD.