
Bonjour, Khabrovites! Nous avons décodé pour vous une partie du tutoriel MongoDB d'Evgeny Aristov, un développeur de 20 ans et auteur du cours en ligne "Bases de données non relationnelles" . Le matériel, comme le cours lui-même, sera utile pour les spécialistes qui rencontrent NoSQL et qui souhaitent apprendre à optimiser leurs bases de données et à travailler avec elles.
Pourquoi répliquer?
- La haute disponibilité. Une sauvegarde, c'est bien, mais son déploiement prend du temps.
- Mise à l'échelle horizontale. Dans le cas où le serveur manque de cœurs physiques et de mémoire.
- Il est préférable de faire une sauvegarde à partir d'une réplique et non à partir d'un maître.
- Chargez la géo-distribution.
Dans MongoDB, il n'y a pas beaucoup de types de réplication prêts à l'emploi: le plus pertinent pour le moment est Replicaset, et le second est Master-slave, qui est limité à la version 3.6 et ne sera pas abordé en détail dans cet article.
# 1. Écriture et lecture depuis le serveur principal
Nous avons un pilote d'application client qui lit et écrit sur le nœud principal. En outre, selon le protocole de réplication, les informations qui sont écrites sur le nœud primaire sont envoyées aux nœuds secondaires.

# 2. Lire à partir d'un signal
Une alternative à la lecture et à l'écriture depuis le primaire est lorsque le pilote peut lire les informations depuis le secondaire. Dans ce cas, les paramètres peuvent être différents, par exemple "il est préférable de lire les informations depuis le secondaire, puis depuis le primaire" ou "lire les informations depuis le nœud le plus proche sur la carte du réseau", etc. Ces options de configuration sont utilisées plus souvent que la première option de réplication, où tout passe par le primaire.

3 façons de rendre une réplique lisible:
- Spécifier
db.slaveOk() - Spécifiez les paramètres requis dans la chaîne de connexion du pilote
- Spécifiez tout, puis écrivez plus précisément dans la requête elle-même, par exemple, lisez à partir de Secondaire dans la région Sud:
db.collection.find({}).readPref( “secondary”, [ { “region”: “South”} ] )
Problèmes de lecture de réplique
- Comme l'enregistrement est asynchrone, il peut déjà être effectué sur le primaire, mais pas sur le secondaire, de sorte que les anciennes données du secondaire seront lues.
- , , .
, . MongoDB , , , . - , () — «».
A) Les nœuds "écoutent" les uns les autres, cette connexion s'appelle Heartbeat. Autrement dit, chaque nœud est constamment vérifié par d'autres pour le sujet "vivant / non-vivant", afin de prendre des mesures si quelque chose se produit.

B) Un nœud secondaire est changé en Arbiter. Il s'agit d'une application très légère, s'exécute comme Mongo, ne consomme pratiquement pas de ressources et est chargée de déterminer quel nœud au moment du vote pour reconnaître le nœud principal. Et c'est généralement la configuration recommandée.
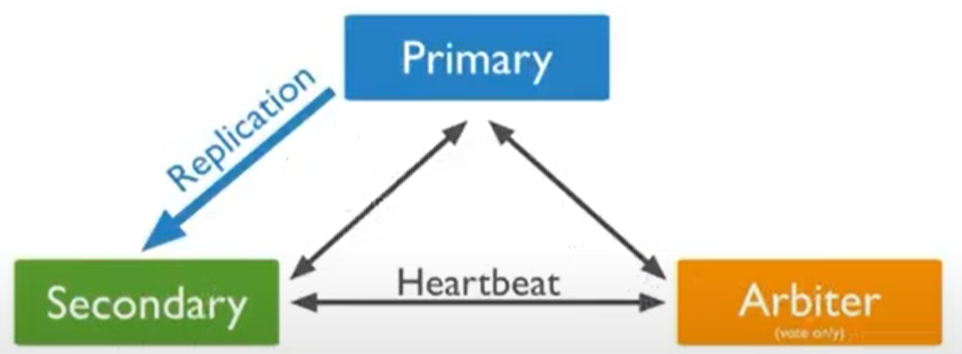
Les principales caractéristiques de cette configuration
- Réplication asynchrone
- L'arbitre est sans données et donc très léger
- Le primaire peut devenir secondaire et vice versa. L'arbitre ne peut devenir ni primaire ni secondaire
- Le nombre maximum de réponses est de 50 et seulement 7 d'entre elles ont le droit de vote
- Arbiter Primary Secondary, , .. , Arbiter .
Si vous souhaitez en savoir plus sur les capacités de clustering de MongoDB, vous pouvez regarder un enregistrement de l'intégralité de la leçon de démonstration ici . Dans la leçon, Evgeny Aristov démontre les différences entre Replicaset et Master-slave, explique le processus de quorum, la mise à l'échelle, le partitionnement et la sélection correcte de la clé de partitionnement.
Explorer les capacités de MongoDB fait partie du cours en ligne sur les bases de données non relationnelles. Le cours est destiné aux développeurs, administrateurs et autres professionnels qui rencontrent NoSQL. En classe, les étudiants maîtrisent aujourd'hui les outils les plus pertinents: Cassandra, MongoDB, Redis, ClickHouse, Tarantool, Kafka, Neo4j, RabbitMQ.
Le début est déjà le 30 septembre, mais pendant le premier mois, vous pouvez rejoindre le groupe. Étudiez le programme, passez partest d'entrée et rejoignez!