
L'article traite du problème du nettoyage des images qui s'accumulent dans les registres de conteneurs (Docker Registry et ses analogues) dans les réalités des pipelines CI / CD modernes pour les applications cloud natives livrées à Kubernetes. Les principaux critères de pertinence des images et les difficultés qui en résultent dans l'automatisation du nettoyage, le gain de place et la satisfaction des besoins des équipes sont donnés. Enfin, à l'aide d'un exemple de projet Open Source spécifique, nous vous indiquerons comment surmonter ces difficultés.
introduction
Le nombre d'images dans le registre de conteneurs peut augmenter rapidement, occupant plus d'espace de stockage et, par conséquent, augmentant considérablement son coût. Pour contrôler, limiter ou maintenir une croissance acceptable de l'espace occupé dans le registre, il est accepté:
- utiliser un nombre fixe de balises pour les images;
- nettoyer les images de quelque manière que ce soit.
La première limitation est parfois valable pour les petites équipes. Si les développeurs ont suffisamment étiquette permanente (
latest, main, test, borisetc.), le registre ne gonflera pas en taille et peut être un long temps de ne pas penser à un nettoyage. Après tout, toutes les images non pertinentes sont effilochées et il n'y a tout simplement plus de travail à faire pour le nettoyage (tout est fait par un ramasse-miettes ordinaire).
Cependant, cette approche limite considérablement le développement et est rarement applicable aux projets CI / CD aujourd'hui. L'automatisation fait désormais partie intégrante du développementqui vous permet de tester, déployer et fournir de nouvelles fonctionnalités aux utilisateurs beaucoup plus rapidement. Par exemple, dans tous nos projets, un pipeline CI est automatiquement créé à chaque commit. Il construit une image, la teste, la déploie dans divers circuits Kubernetes pour le débogage et les vérifications restantes, et si tout se passe bien, les modifications parviennent à l'utilisateur final. Et ce n'est pas sorcier depuis longtemps, mais la vie quotidienne pour beaucoup - probablement pour vous, puisque vous lisez cet article.
Étant donné que les bogues sont corrigés et que de nouvelles fonctionnalités sont développées en parallèle, et que les versions peuvent être effectuées plusieurs fois par jour, il est évident que le processus de développement s'accompagne d'un nombre important de commits, ce qui signifie un grand nombre d'images dans le registre... En conséquence, la question de l'organisation d'un nettoyage efficace du registre se pose. suppression des images non pertinentes.
Mais comment pouvez-vous même déterminer si une image est pertinente?
Critères de pertinence de l'image
Dans la grande majorité des cas, les principaux critères seront les suivants:
1. Le premier (le plus évident et le plus critique de tous) concerne les images actuellement utilisées dans Kubernetes . La suppression de ces images peut entraîner des coûts d'arrêt importants pour la production (par exemple, des images peuvent être nécessaires lors de la réplication) ou annuler les efforts de l'équipe engagée dans le débogage sur l'un des circuits. (Pour cette raison, nous avons même créé un exportateur Prometheus spécial qui surveille l'absence de telles images dans n'importe quel cluster Kubernetes.)
2. Le second (moins évident, mais aussi très important et fait à nouveau référence à l'opération) - des images qui sont nécessaires pour la restauration en cas problèmesdans la version actuelle. Par exemple, dans le cas de Helm, ce sont les images qui sont utilisées dans les versions enregistrées de la version. (Au fait, la limite par défaut dans Helm est de 256 révisions, mais presque personne n'a vraiment besoin de sauvegarder un si grand nombre de versions? ..) Après tout, pour cela, en particulier, nous stockons les versions afin que vous puissiez plus tard utiliser, c'est-à-dire "Revenez" à eux si nécessaire.
3. Troisièmement - les besoins des développeurs : toutes les images associées à leur travail actuel. Par exemple, si nous considérons PR, alors il est logique de laisser l'image correspondant au dernier commit et, par exemple, au commit précédent: de cette façon, le développeur peut rapidement revenir à n'importe quelle tâche et travailler avec les dernières modifications.
4. Quatrièmement - des images quicorrespondent aux versions de notre application , c'est-à-dire sont le produit final: v1.0.0, 20.04.01, sierra, etc.
NB: Les critères définis ici ont été formulés sur la base de l'expérience d'interaction avec des dizaines d'équipes de développement de différentes entreprises. Cependant, bien entendu, en fonction des spécificités des processus de développement et de l'infrastructure utilisée (par exemple, Kubernetes n'est pas utilisé), ces critères peuvent différer.
Éligibilité et solutions existantes
En règle générale, les services de registre de conteneurs populaires proposent leurs propres politiques de nettoyage d'image: vous pouvez y définir les conditions dans lesquelles une balise est supprimée du registre. Cependant, ces conditions sont limitées par des paramètres tels que les noms, l'heure de création et le nombre de balises *.
* Dépend des implémentations spécifiques du registre de conteneurs. Nous avons examiné les possibilités des solutions suivantes: Azure CR, Docker Hub, ECR, GCR, GitHub Packages, GitLab Container Registry, Harbor Registry, JFrog Artifactory, Quay.io - à partir de septembre 2020.
Cet ensemble de paramètres est tout à fait suffisant pour satisfaire le quatrième critère - c'est-à-dire sélectionner des images qui correspondent aux versions. Cependant, pour tous les autres critères, il faut choisir une sorte de solution de compromis (politique plus dure ou, au contraire, économe) - en fonction des attentes et des capacités financières.
Par exemple, le troisième critère - lié aux besoins des développeurs - peut être résolu en organisant les processus au sein des équipes: dénomination spécifique des images, maintien de listes d'autorisation spéciales et accords internes. Mais finalement, il doit encore être automatisé. Et si les possibilités de solutions toutes faites ne suffisent pas, vous devez faire quelque chose par vous-même.
La situation est similaire avec les deux premiers critères: ils ne peuvent être satisfaits sans recevoir des données du système externe - celui où les applications sont déployées (dans notre cas, c'est Kubernetes).
Illustration d'un workflow dans Git
Supposons que vous travaillez quelque chose comme ceci dans Git: l'
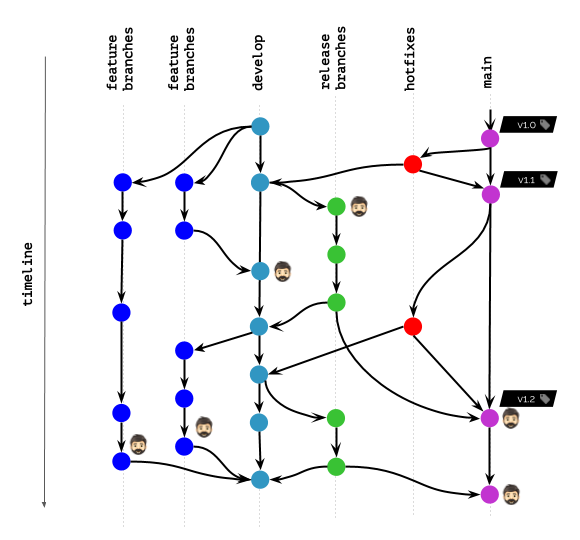
icône avec une tête dans le diagramme marque les images de conteneur qui sont actuellement déployées sur Kubernetes pour tous les utilisateurs (utilisateurs finaux, testeurs, gestionnaires, etc.) ou sont utilisées par les développeurs pour le débogage et des objectifs similaires.
Que se passe-t-il si les politiques de purge vous permettent de conserver (et non de supprimer) les images uniquement pour les noms de balises spécifiés ?

Évidemment, ce scénario ne plaira à personne.
Qu'est-ce qui changera si les politiques vous permettent de ne pas supprimer d'images pendant un intervalle de temps donné / un nombre de validations récentes ?

Le résultat est devenu bien meilleur, mais encore loin d'être idéal. Après tout, nous avons encore des développeurs qui ont besoin d'images dans le registre (ou même déployées en K8) pour déboguer des bogues ... Pour
résumer la situation actuelle sur le marché: les fonctions disponibles dans les registres de conteneurs n'offrent pas une flexibilité suffisante pour le nettoyage, et la raison principale est qu'il n'y a aucune possibilité interagir avec le monde extérieur . Il s'avère que les équipes qui ont besoin de cette flexibilité sont obligées de mettre en œuvre elles-mêmes la suppression d'images «en dehors» en utilisant l'API Docker Registry (ou l'API native de l'implémentation correspondante).
Cependant, nous recherchions une solution universelle qui automatiserait le nettoyage des images pour différentes équipes utilisant différents registres ...
Notre chemin vers le nettoyage d'image universel
D'où vient ce besoin? Le fait est que nous ne sommes pas un groupe distinct de développeurs, mais une équipe qui sert beaucoup d'entre eux à la fois, aidant à résoudre de manière globale les problèmes de CI / CD. Et le principal outil technique pour cela est l'utilitaire open source werf . Sa particularité est qu'il n'effectue pas une seule fonction, mais accompagne les processus de livraison continue à toutes les étapes: de l'assemblage au déploiement.
La publication d'images dans le registre * (immédiatement après leur création) est une fonction évidente d'un tel utilitaire. Et puisque les images sont placées là pour le stockage, alors - si votre stockage n'est pas illimité - vous devez être responsable de leur nettoyage ultérieur. La manière dont nous y sommes parvenus, en répondant à tous les critères spécifiés, sera discutée plus en détail.
* Bien que les registres eux-mêmes puissent être différents (Docker Registry, GitLab Container Registry, Harbor, etc.), leurs utilisateurs sont confrontés aux mêmes problèmes. La solution universelle dans notre cas ne dépend pas de la mise en œuvre du registre, car s'exécute en dehors des registres eux-mêmes et offre le même comportement pour tout le monde.
Malgré le fait que nous utilisons werf comme exemple de mise en œuvre, nous espérons que les approches utilisées seront utiles à d'autres équipes confrontées à des difficultés similaires.
Donc, nous avons pris le externemise en œuvre d'un mécanisme de nettoyage des images - au lieu des capacités déjà intégrées dans les registres des conteneurs. La première étape consistait à utiliser l'API Docker Registry pour créer toutes les mêmes politiques primitives par le nombre de balises et l'heure de leur création (mentionné ci-dessus). Une liste d'autorisation a été ajoutée à ceux-ci en fonction des images utilisées dans l'infrastructure déployée , c.-à-d. Kubernetes. Pour ce dernier, il suffisait de passer par l'API Kubernetes pour parcourir toutes les ressources déployées et obtenir une liste de valeurs
image.
Cette solution triviale a résolu le problème le plus critique (critère n ° 1), mais ce n'était que le début de notre voyage pour améliorer le mécanisme de nettoyage. L'étape suivante - et beaucoup plus intéressante - a été la décision d' associer les images publiées à l'histoire de Git .
Schémas de marquage
Pour commencer, nous avons choisi une approche dans laquelle l'image finale doit stocker les informations nécessaires au nettoyage, et avons construit le processus sur des schémas de marquage. Lors de la publication d'une image, l'utilisateur a sélectionné une option de balisage spécifique (
git-branch, git-commitou git-tag) et a utilisé la valeur correspondante. Dans les systèmes CI, ces valeurs étaient définies automatiquement en fonction des variables d'environnement. Fondamentalement, l' image finale était associée à une primitive Git spécifique , stockant les données nécessaires au nettoyage dans les étiquettes.
Cette approche a abouti à un ensemble de politiques permettant d'utiliser Git comme seule source de vérité:
- Lors de la suppression d'une branche / balise dans Git, les images associées dans le registre étaient également automatiquement supprimées.
- Le nombre d'images associées aux balises et commits Git peut être contrôlé par le nombre de balises utilisées dans le schéma choisi et l'heure à laquelle le commit associé a été créé.
En général, la mise en œuvre qui en a résulté a répondu à nos besoins, mais bientôt un nouveau défi nous attend. Le fait est que lors de l'utilisation de schémas de balisage pour les primitives Git, nous avons rencontré un certain nombre de lacunes. (Étant donné que leur description dépasse le cadre de cet article, tout le monde peut lire les détails ici .) Ainsi, après avoir décidé de passer à une approche plus efficace du balisage (balisage basé sur le contenu), nous avons dû revoir la mise en œuvre du nettoyage d'image.
Nouvel algorithme
Pourquoi? Lorsqu'elle est étiquetée comme basée sur le contenu, chaque balise peut accepter plusieurs commits dans Git. Lors du nettoyage des images, vous ne pouvez plus vous fier uniquement au commit auquel la nouvelle balise a été ajoutée au registre.
Pour le nouvel algorithme de nettoyage, il a été décidé de s'éloigner des schémas de marquage et de construire le processus sur des méta-images , dont chacune stocke un tas de:
- le commit sur lequel la publication a été effectuée (peu importe si l'image a été ajoutée, modifiée ou est restée la même dans le registre des conteneurs);
- et notre identifiant interne correspondant à l'image construite.
En d'autres termes, les balises publiées étaient liées aux commits dans Git .
Configuration finale et algorithme général
Lors de la configuration du nettoyage, les utilisateurs ont désormais accès aux stratégies par lesquelles la sélection d'images réelles est effectuée. Chacune de ces politiques est définie:
- références multiples, i.e. Balises Git ou branches Git utilisées lors de l'exploration;
- et la limite des images requises pour chaque référence de l'ensemble.
Pour illustrer, voici à quoi la configuration de stratégie par défaut a commencé à ressembler:
cleanup:
keepPolicies:
- references:
tag: /.*/
limit:
last: 10
- references:
branch: /.*/
limit:
last: 10
in: 168h
operator: And
imagesPerReference:
last: 2
in: 168h
operator: And
- references:
branch: /^(main|staging|production)$/
imagesPerReference:
last: 10
Cette configuration contient trois stratégies conformes aux règles suivantes:
- Enregistrez une image pour les 10 dernières balises Git (à la date de création de la balise).
- Ne sauvegardez pas plus de 2 images publiées la semaine dernière, pour pas plus de 10 succursales avec activité la semaine dernière.
- Enregistrez 10 images pour chaque branche
main,stagingetproduction.
L'algorithme final est réduit aux étapes suivantes:
- Obtention de manifestes à partir du registre de conteneurs.
- À l'exclusion des images utilisées dans Kubernetes car nous les avons déjà présélectionnés en interrogeant l'API K8s.
- Analyse de l'historique Git et exclusion d'images conformément aux politiques spécifiées.
- Suppression des images restantes.
Pour en revenir à notre illustration, voici ce qui se passe avec werf:
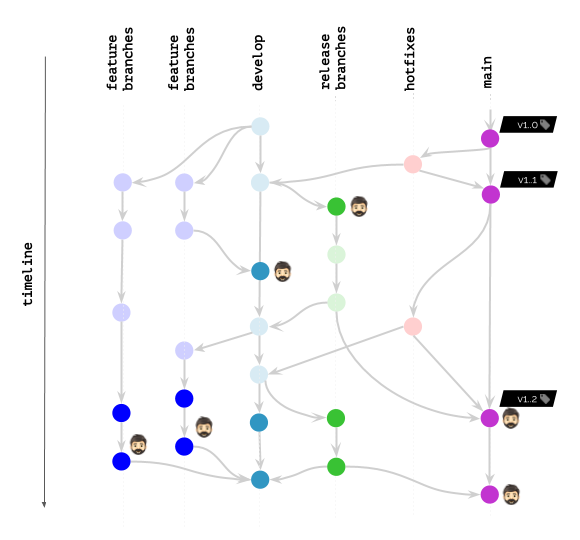
Cependant, même si vous n'utilisez pas werf, une approche similaire de nettoyage avancé des images - dans une implémentation ou une autre (conformément à l'approche préférée pour le marquage des images) - peut également être appliquée dans d'autres systèmes. / utilitaires. Pour ce faire, il suffit de se souvenir des problèmes qui surviennent et de trouver les opportunités dans votre pile qui vous permettent de construire leur solution de la manière la plus fluide. Nous espérons que le chemin que nous avons parcouru vous aidera à examiner votre cas particulier avec de nouveaux détails et réflexions.
Conclusion
- Tôt ou tard, la plupart des équipes sont confrontées au problème du débordement de registre.
- Lors de la recherche de solutions, il faut tout d'abord déterminer les critères de pertinence de l'image.
- Les outils proposés par les services populaires de registre de conteneurs permettent un nettoyage très simple qui ne prend pas en compte le «monde extérieur»: les images utilisées dans Kubernetes et les spécificités des flux de travail d'équipe.
- Un algorithme flexible et efficace doit avoir une compréhension des processus CI / CD, fonctionner non seulement avec les données d'image Docker.
PS
Lisez aussi sur notre blog: