- De quoi allons-nous parler exactement? Pas sur les sélections et les jointures primitives - je pense que la plupart d'entre vous les connaissent déjà.
Nous parlerons de l'utilisation réelle des bases de données, des difficultés auxquelles vous pouvez faire face et de ce que vous devez savoir en tant que développeur backend. Il y aura beaucoup d'informations, voici le contenu. Vous n'avez pas besoin de connaître directement à fond les détails de chacun de ces points, mais vous devez savoir que ce point existe.

Et vous devez savoir comment les problèmes sont résolus afin que lorsque vous avez une tâche pour construire une structure, enregistrer des données, vous savez quel modèle de données choisir et comment l'enregistrer. Ou supposons que vous ayez un problème, que vous voyez que la base de données est en panne, qu'elle est lente ou que vous avez des problèmes de données, des incohérences. Ensuite, vous devez comprendre où creuser. Autrement dit, vous devez savoir quels concepts existent et de quel côté aborder les problèmes.

Tout d'abord, nous parlerons des données. Qu'est-ce que c'est que ça? Il y a beaucoup de faits autour de nous, beaucoup d'informations, mais tant qu'ils n'ont pas été recueillis de quelque manière que ce soit, ils sont inutiles pour nous. Nous les collectons, les structurons et les stockons. Et c'est cette structuration stockée qui s'appelle les données, et ce qui les stocke s'appelle la base de données. Mais tant que ces données sont simplement collectées quelque part, elles sont également fondamentalement inutiles pour nous. Par conséquent, il existe une couche au-dessus des bases de données - le SGBD. C'est ce qui nous permet de récupérer des données, de les stocker et de les analyser. Ainsi, nous transformons les données que nous recevons en informations que nous pouvons déjà afficher à l'utilisateur. L'utilisateur acquiert des connaissances et les applique.

Nous discuterons comment structurer les informations et les faits, les stocker, sous quelle forme de données, dans quel modèle. Et comment les obtenir afin que de nombreux utilisateurs puissent simultanément accéder aux données et obtenir le résultat correct, afin que nos connaissances finales que nous appliquerons soient vraies et correctes.

Tout d'abord, nous parlerons des bases de données relationnelles. Je pense que le modèle relationnel est familier à beaucoup d'entre vous. C'est un modèle du type de tables et des relations entre les tables. Imaginez que nous ayons un messager dans lequel nous écrivons des données et des messages entre les utilisateurs. Nous pouvons tous les écrire dans un si grand tableau volumineux, large, où nous aurons beaucoup de données répétitives - de qui, qui, à qui, dans quelle conversation. Et nous pouvons écrire tout cela dans différentes tables, c'est-à-dire normaliser nos données, les amener dans la troisième forme normale.
Il y a des notes et des liens sur les diapositives. Nous n'entrerons pas dans chaque concept maintenant. J'essaierai de ne pas parler de concepts techniques qui ne vous sont peut-être pas familiers. Mais tout ce que je dis, vous le trouverez dans les notes des diapositives. Notamment la normalisation, il y aura aussi une référence, vous pouvez la lire si vous n'êtes pas familier avec ce concept.

En termes généraux, la normalisation est la décomposition des données en tableaux dans le but de rendre les données plus structurées. Par exemple, il existe maintenant un tableau des utilisateurs, du chat et des messages. Cette structure garantit que les messages des utilisateurs que nous connaissons exactement et des chats que nous connaissons seront enregistrés ici. Autrement dit, nous garantissons l'intégrité des données. Nous veillons à ce que nous puissions toujours avoir une vue d'ensemble. Mais en même temps, nous stockons, par exemple, dans la table des messages uniquement les identifiants, uniquement les identifiants. Ainsi, nous réduisons la taille globale de la base de données, la rendant plus petite. En conséquence, nous facilitons l'écriture dans cette base de données. Nous n'avons pas besoin d'écrire constamment dans de nombreuses tables. Nous écrivons simplement à la même table avec le spécialiste de l'ID.

Si nous parlons de normalisation, en général, cela simplifie grandement la vision du système, car il est très graphique, et il nous devient immédiatement clair quelles relations nous avons entre quelles tables.
Nous réduisons le nombre d'erreurs lors de l'écriture des données, car si nous écrivons un message dans le messager et que nous n'avons pas encore un tel utilisateur, nous devrons en créer un. Mais l'image finale, les données générales, resteront complètes.
J'ai déjà parlé de la réduction de la taille de la base de données. Nous n'avons pas à écrire toutes les données sur l'utilisateur dans la table des messages à chaque fois. Pour visualiser le profil, nous pouvons simplement aller dans la table des utilisateurs.
J'ai également mis en garde contre la dépendance incohérente. Ce ne sont que des liens vers des identifiants d'autres tables, les identifiants sont des valeurs uniques dans une table. D'une autre manière, elles sont appelées clés primaires, et lorsque nous avons un lien vers ces clés primaires, le lien lui-même dans une autre table s'appelle une clé étrangère.
Cette structure protège également nos données d'une suppression accidentelle. Nous ne pouvons pas supprimer un utilisateur, car, par exemple, il a un message. Il s’agit d’un filet de sécurité si petit.
Il semblerait que nous ayons fait une excellente structure, tout est clair, tout dépend, tout est intégral. Avec quoi d'autre avez-vous besoin pour travailler?

Imaginons qu'on le mette réellement en service, on a beaucoup d'utilisateurs et, par conséquent, beaucoup de messages. Ils communiquent constamment entre eux. Que se passe-t-il dans notre table de messages? Il ne cesse de croître. Et pour rechercher dans les non-données, nous devons constamment trier absolument tous les messages, vérifier s'ils proviennent de cet utilisateur ou non, dans ce chat ou non, et ensuite seulement les afficher.
Naturellement, plus il y a d'utilisateurs, plus il y a de messages, plus les demandes de recherche prendront de temps. Nous avons besoin d'une solution qui nous permette de rechercher rapidement des messages dans le tableau.
Dans un tel cas, des index sont utilisés pour accélérer la recherche. L'association la plus simple avec les index est le contenu d'un livre. Si vous avez besoin de trouver des informations dans un livre, vous pouvez simplement feuilleter le livre ou aller à la table des matières. Les index sont en quelque sorte une table des matières.
Il y a aussi un bon exemple avec un annuaire téléphonique. Vous pouvez cliquer sur une lettre de votre téléphone, et vous serez immédiatement renvoyé par référence aux noms commençant par cette lettre. Les index de base de données fonctionnent de manière très similaire. Voyons notre tableau avec des messages et comment nous allons obtenir ces données.

Veuillez faire attention à la manière dont nous travaillerons avec les données. Pas avec les lignes que nous avons dans le tableau, mais en général. Les index sont construits sur la base des requêtes que vous faites.
Imaginons que nous fassions principalement des requêtes par chat, c'est-à-dire que nous découvrions quels messages se trouvent dans ce chat. Construisons l'index exactement sur la colonne de discussion. Les index de base de données constituent une structure distincte. La table en est indépendante. Autrement dit, vous pouvez supprimer et reconstruire l'index à tout moment, et la table n'en souffrira pas.
Ici vous pouvez voir ce que nous avons sélectionné, mettre l'index sur la colonne, et nous avons une structure distincte qui a déjà légèrement réduit le nombre d'entrées, car le chat 11 a déjà plusieurs messages. Le SGBD permet une recherche rapide dans cette petite table de discussion. Comment c'est fait? Naturellement, la recherche n'est pas une simple recherche. Il existe de nombreux algorithmes de recherche rapide, nous allons jeter un oeil à l'un des algorithmes les plus populaires qui sont utilisés par défaut dans la plupart des bases de données. C'est un arbre équilibré.

Comment ça marche? Nous avons un numéro de chat, c'est une valeur entière, et l'arborescence est construite selon le principe suivant: ce qui est moins à gauche du nœud, plus de valeurs à droite du nœud. Que nous donne cette structure? Si vous regardez les feuilles récapitulatives de cet arbre, toutes les valeurs du bas sont classées. C'est un énorme avantage en termes de gains de productivité. Maintenant, je vais vous montrer pourquoi.
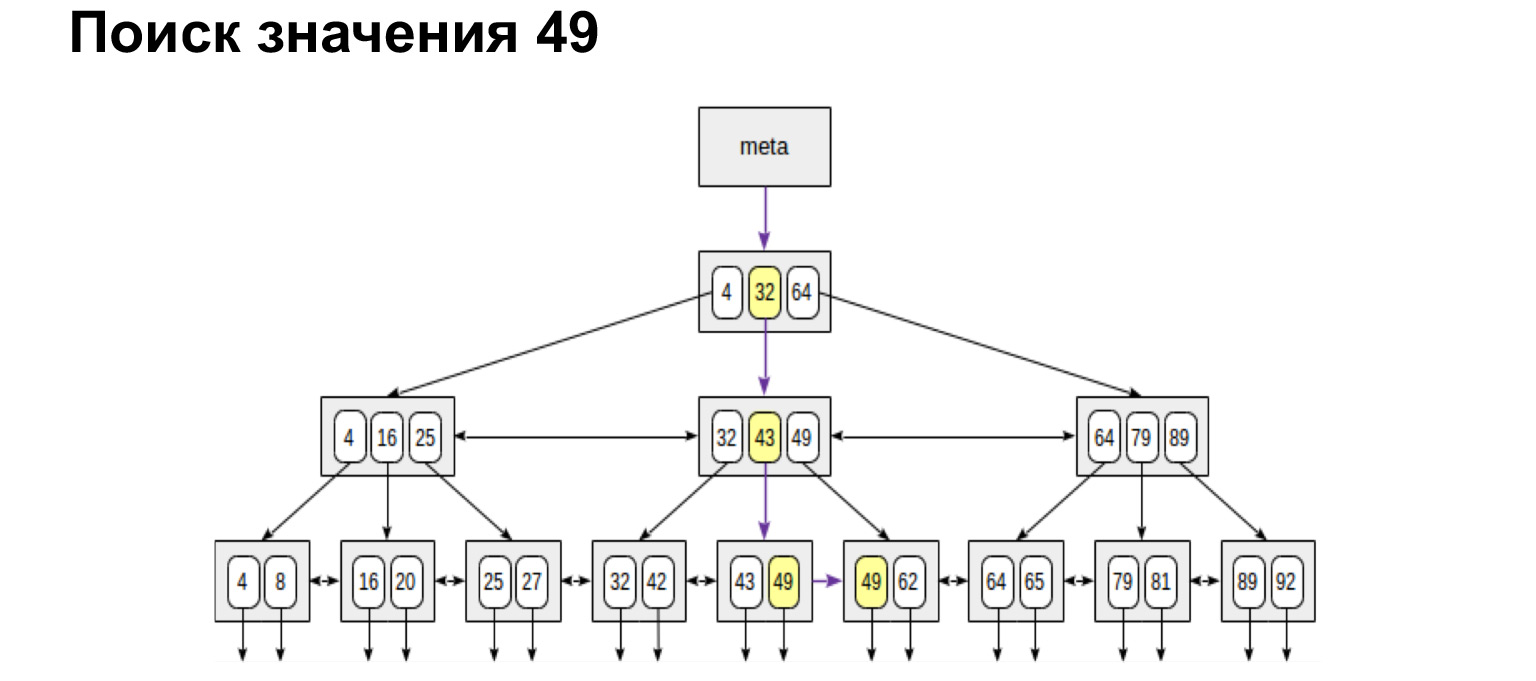
Par exemple, nous recherchons une valeur. Il est très facile de rechercher un sens. Nous descendons dans l'arbre ou vers la gauche, vers la droite - selon que cette valeur est supérieure ou inférieure.
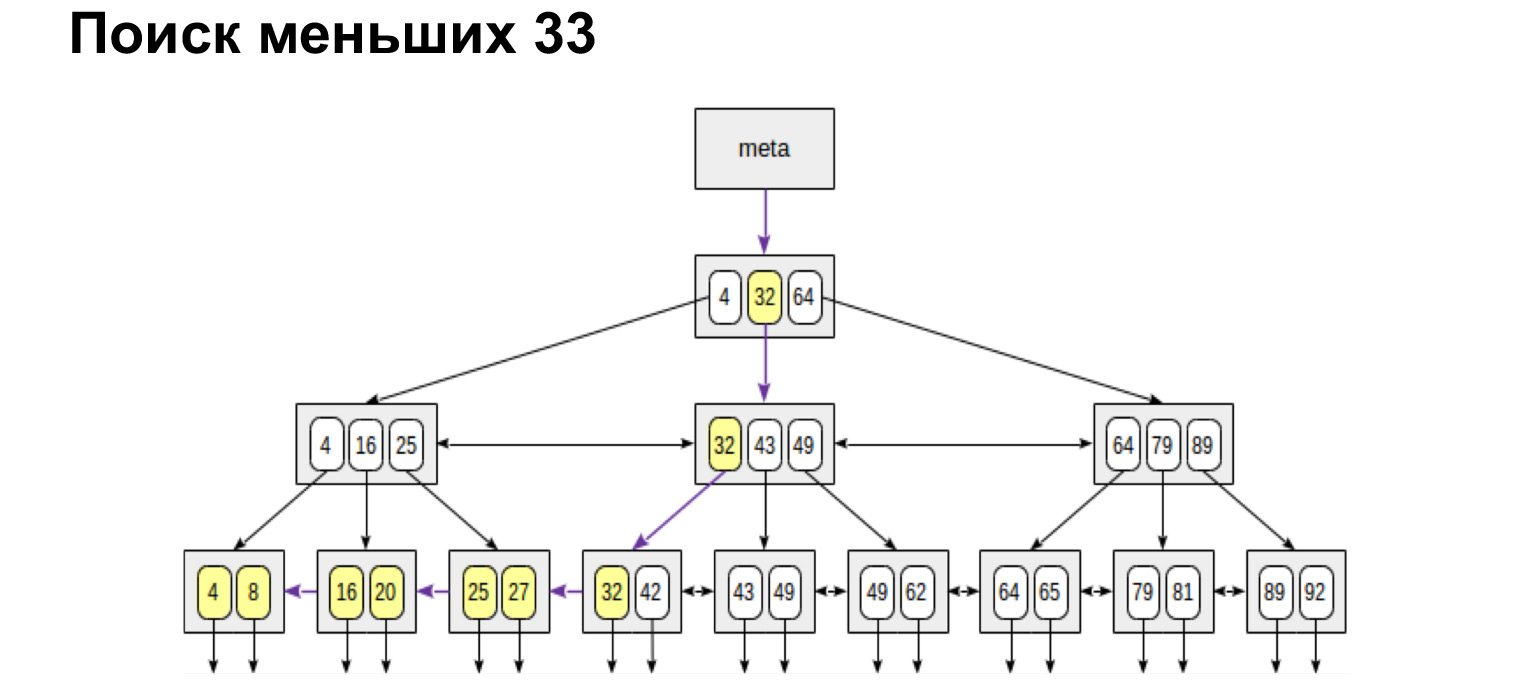
Et si nous voulons trouver, par exemple, une gamme, alors regardez à quel point cela s'avère simple et rapide. Nous atteignons la valeur puis suivons les liens dans les feuilles, déjà le long des valeurs ordonnées, allons simplement à la fin.
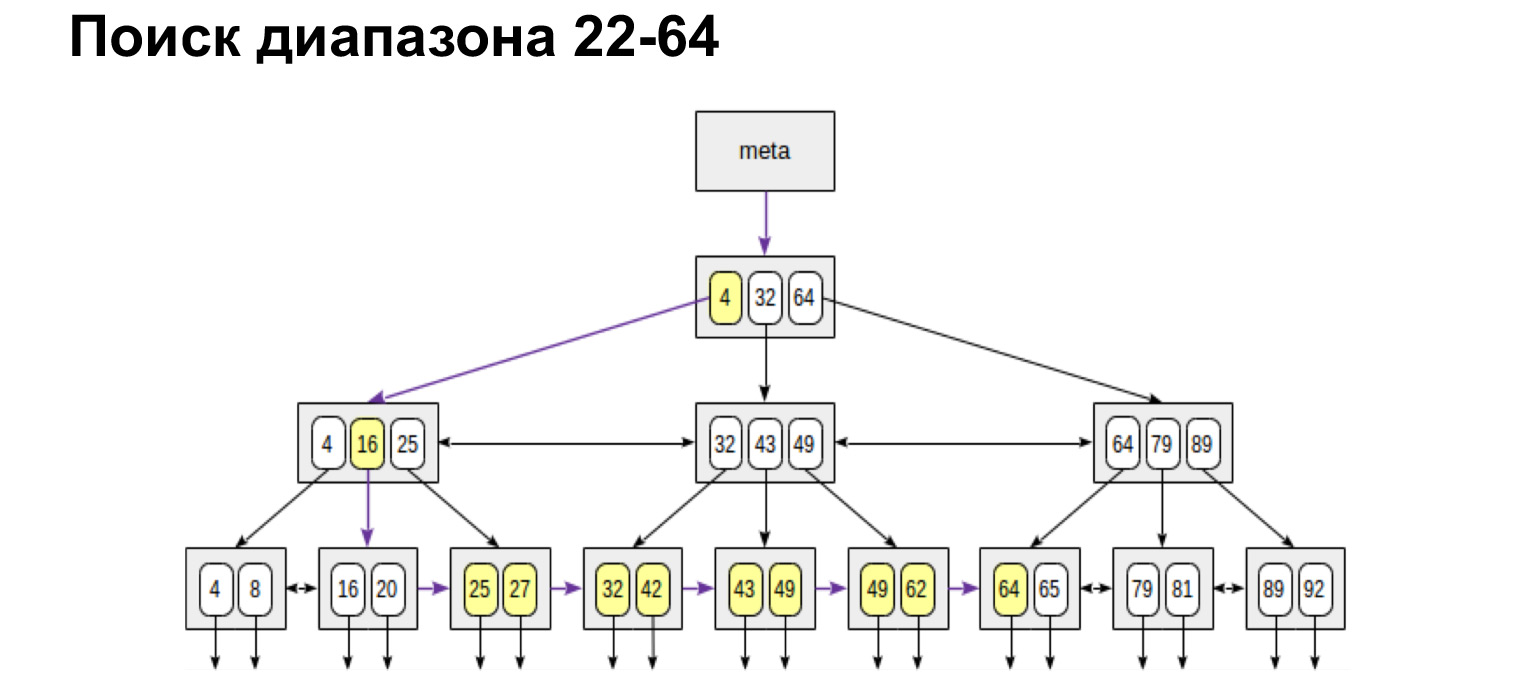
Si nous avons besoin d'une plage définie de et à, nous faisons exactement la même chose. Trouvez la valeur initiale et suivez les liens de feuille jusqu'à la valeur maximale. Nous n'avons marché qu'une seule fois dans l'arbre. C'est très pratique, très rapide.
De la même manière, nous rechercherons les valeurs maximum et minimum. Marchez complètement à gauche, complètement à droite. Nous recevrons également une liste ordonnée. Autrement dit, si nous avons juste besoin d'obtenir tous les chats de manière ordonnée, nous atteignons le premier et passons les feuilles à la valeur la plus à droite, nous obtenons une liste ordonnée. C'est par ce principe que la base de données recherche très rapidement dans la table d'index les lignes que nous devons sélectionner et les renvoie.
Qu'est-ce qu'il est important de savoir ici? Cela semblerait une structure cool - maintenant nous allons construire pour chaque colonne en fonction d'un tel arbre et rechercherons. Pourquoi pensez-vous que cela ne fonctionnera pas? Pourquoi n'augmenterons-nous pas la vitesse si nous construisons un arbre pour chaque colonne? (...)
Nos sélections vont vraiment s'accélérer. Chaque fois que nous avons besoin de passer par une valeur, nous allons à l'index, y trouvons un lien vers les valeurs elles-mêmes. Les index contiennent généralement exactement les références de ligne, pas les lignes elles-mêmes. Et pour sélectionner cela fonctionne parfaitement. Mais dès que nous voulons définir des données de table, mettre à jour ou supprimer des données, tous ces arbres devront être reconstruits.
En fait, la suppression ne reconstruira pas, mais fragmentera simplement cet arbre, et nous nous retrouverons avec de nombreuses valeurs vides. Il y aura un énorme arbre avec des valeurs vides. Mais c'est avec update et avec create que ces arbres seront reconstruits à chaque fois. En conséquence, nous aurons une énorme surcharge sur toute cette structure. Et au lieu de récupérer rapidement les données et d'accélérer la base de données, nous ralentirons nos requêtes.
Que faut-il savoir d'autre? Lorsque vous travaillez avec une base de données, regardez et lisez les index qui s'y trouvent, car chaque base de données a ses propres implémentations, ses propres index différents. Il y a des index pour accélérer, il y a des index pour assurer l'intégrité. L'un des plus simples est simplement la clé primaire. C'est aussi un index unique. Et concernant votre base de données, voyez comment cela fonctionne, comment l'utiliser, car c'est le type de connaissances qui vous aidera à rédiger les requêtes les plus optimales.
Nous avons discuté de ce qu'il faut garder à l'esprit la surcharge de la maintenance des index lors de l'insertion de données. J'ai oublié de dire que lorsque vous construisez un index, il doit être très sélectif. Qu'est-ce que ça veut dire?
Regardons cet arbre. Nous comprenons que si l'indice est défini sur true false, alors nous obtenons simplement deux énormes morceaux de bois à gauche et à droite. Et nous parcourons au mieux 50% de la table, ce qui n'est en fait pas très efficace. Il est préférable d'indexer exactement ces colonnes avec les valeurs les plus différentes. Cela accélérera nos sélections.
J'ai dit à propos de la fragmentation; lors de la suppression de données, vous devez le garder à l'esprit. Si nous avons souvent des suppressions sur les données contenues dans l'index, il peut être nécessaire de le défragmenter, et cela doit également être surveillé. Il est également important de comprendre que vous créez un index non pas basé sur les colonnes dont vous disposez, mais sur la manière dont vous utilisez ces données. Et les requêtes qui incluent des index doivent être écrites très soigneusement. Que signifie net? Lorsque vous écrivez une demande, envoyez-la à la base de données, elle n'est pas envoyée directement à la base de données, mais à une sorte de couche logicielle appelée le planificateur de requêtes.
L'ordonnanceur a une certaine table de correspondance des coûts de l'opération et de son coût. Dans l'exemple PostgreSQL, il existe des tables techniques spéciales qui collectent des informations sur vos données, sur vos tables. Le planificateur regarde quelle requête vous avez, quelles données sont stockées dans la table pg_stat. Ceci est juste une table qui stocke des informations générales sur la quantité de données dont vous disposez et les colonnes de votre table, les index qui s'y trouvent. Sur cette base, il examine les plans pour l'exécution de votre requête, calcule le temps en fonction du plan qu'il faudra pour la requête et sélectionne le plus optimal.

Si vous souhaitez voir l'heure d'exécution prévue pour votre requête, vous pouvez utiliser l'opération Explain. Si vous voulez l'exécution réelle, vous pouvez utiliser l'analyse Explain. Quelle est la différence? Comme je l'ai dit, le planificateur calcule initialement le temps d'exécution en fonction du temps estimé pour chaque opération. Par conséquent, l'heure réelle peut différer en fonction de la machine et de la nature de vos données. Donc, si vous voulez l'exécution réelle, il est bien sûr préférable d'utiliser Explain analyser.
Vous pouvez voir un exemple sur cette diapositive. Cela montre que parfois les requêtes basées sur votre colonne qui ont des index peuvent ne pas utiliser l'index d'analyse, mais juste une analyse complète sur toute la table. Cela se produit si nous avons une faible sélectivité d'index et si le planificateur pense qu'une requête d'analyse complète sur la table sera plus rentable.
Imaginons que nous ayons notre messager et que nous voulions dans la liste de discussion, par exemple, afficher le nom du chat ou le nombre de messages non lus. Si à chaque fois que nous ouvrons un chat, nous recalculons toutes les données pour tous les chats, ce ne sera pas rentable.
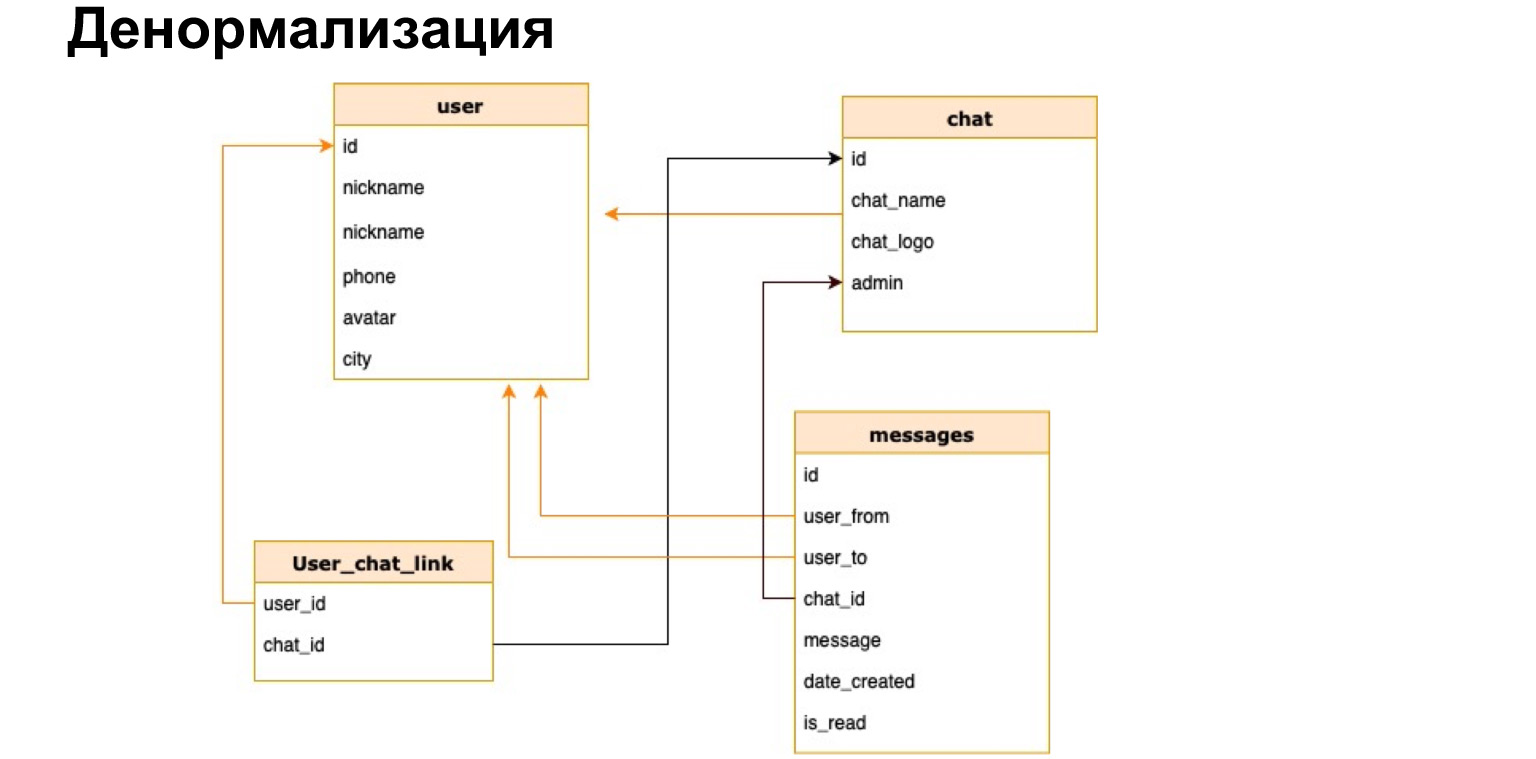
Il existe une telle chose - la dénormalisation. Il s'agit d'une copie des données les plus chaudes utilisées ou d'un pré-calcul des données requises et de les enregistrer dans une table.
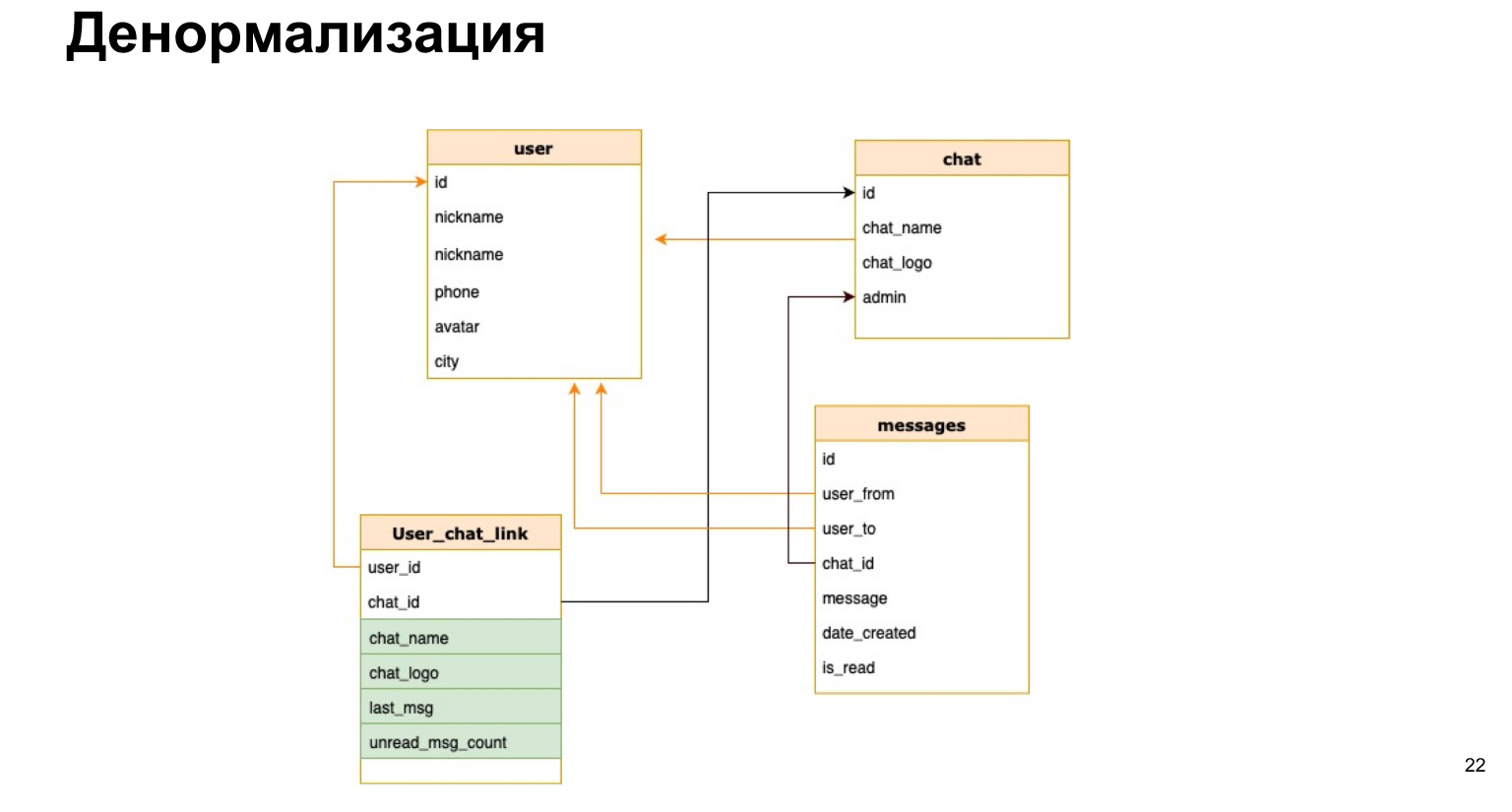
Voici à quoi pourrait ressembler la relation entre l'utilisateur et le chat. Autrement dit, en plus de l'ID utilisateur et de l'ID de discussion, nous enregistrerons brièvement le nom de la discussion, le journal de discussion et le nombre de messages non lus. Ainsi, à chaque fois, nous n'aurons pas besoin de charger toutes nos tables, de faire des sélections et de recalculer tout cela.

Quel est le plus de la dénormalisation? Nous accélérons le processus d'échantillonnage des données. Autrement dit, nos sélections sont effectuées le plus rapidement possible, nous donnons aux utilisateurs une réponse le plus rapidement possible.
La difficulté est que chaque fois que nous ajoutons de nouvelles données, nous devons recalculer toutes ces colonnes et la probabilité d'erreur est très élevée. Autrement dit, si nos sélections deviennent beaucoup plus simples et que nous n'avons pas besoin de nous rejoindre tout le temps, alors notre mise à jour et notre création deviennent très lourdes, car nous devons y accrocher les déclencheurs, recalculer et ne rien oublier.
Par conséquent, vous ne devez utiliser la dénormalisation que lorsque vous en avez vraiment besoin. Et comme nous avons maintenant suivi toute cette logique, vous devez d'abord normaliser les données, voir comment vous allez les utiliser, ajuster les index. Si vous pensez que vous avez des requêtes qui ne fonctionnent pas bien, jetez un œil à Expliquer avant de dénormaliser. Découvrez comment ils sont réellement exécutés, comment le planificateur les fait. Et alors seulement, lorsque vous êtes déjà parvenu à la conclusion que la dénormalisation est encore nécessaire, alors vous pouvez le faire. Mais il existe une telle pratique et la dénormalisation des données est souvent utilisée dans de vrais projets.
Allons plus loin. Même si vous avez bien structuré les données, choisi un modèle de données, collecté, tout dénormalisé, créé des index, encore beaucoup dans le monde informatique peuvent mal tourner.
Le logiciel peut échouer, l'alimentation peut être coupée, le matériel ou le réseau peut échouer. Il existe une deuxième classe de problèmes: nos bases de données sont utilisées simultanément par de nombreux utilisateurs. Ils peuvent mettre à jour les mêmes données en même temps. Nous devons pouvoir résoudre tous ces problèmes.
Jetons un coup d'œil à des exemples spécifiques de ce dont il s'agit.

Imaginons qu'il y ait deux utilisateurs qui souhaitent réserver une salle de réunion. L'utilisateur 1 voit que la salle de réunion est libre à ce moment et commence à la réserver. Sa fenêtre s'ouvre et il pense lequel de mes collègues je vais appeler. Pendant qu'il réfléchit, l'utilisateur 2 voit également que la salle de réunion est libre et ouvre une fenêtre d'édition pour lui-même.
En conséquence, lorsque l'utilisateur 1 a enregistré ces données, il est parti et pense que tout va bien, la salle de réunion est réservée. Mais à ce moment, l'utilisateur 2 écrase ses données et il s'avère que la salle de discussion est attribuée à l'utilisateur 2. C'est ce qu'on appelle un conflit de données. Et nous devons être capables de montrer ces conflits aux gens et de les résoudre d'une manière ou d'une autre. C'est à cet endroit que nous aurons un réenregistrement.

Comment faire? Nous pouvons simplement bloquer la salle de réunion pendant un moment pendant que l'utilisateur 1 réfléchit. S'il a sauvegardé les données, nous n'autoriserons pas l'utilisateur 2 à le faire. S'il a publié les données et n'a pas sauvegardé, l'utilisateur 2 pourra réserver une salle de conférence. Vous pouvez voir une image similaire lorsque vous achetez des billets de cinéma. Vous avez 15 minutes pour payer les billets, sinon ils sont à nouveau fournis à d'autres personnes qui peuvent également les prendre et les payer.
Voici un autre exemple qui nous montrera à quel point il est important de s'assurer que nos opérations sont menées complètement. Disons que je veux transférer de l'argent du compte bancaire 1 au compte 2. En ce moment, j'ai trois opérations. Je vérifie que j'ai suffisamment de fonds, je déduis les fonds de mon premier compte et les dépose sur le deuxième compte. Il est clair que si à l'un de ces moments j'ai un échec, alors quelque chose va mal tourner.
Par exemple, si à ce stade une autre transaction se produit qui lit des données, alors les fonds de mon compte ne seront plus suffisants, je ne pourrai pas effectuer d'autres opérations. Si un problème survient au deuxième moment, nous avons, par exemple, retiré de l'argent d'un compte, mais n'avons pas mis d'argent sur le second. Il s'avère qu'en conséquence, mon compte bancaire, tous mes comptes, seront réduits d'un certain montant. Cet argent ne peut en aucun cas être retourné.
Pour résoudre de tels problèmes, il y a le concept de transaction - une exécution atomique intégrale des trois opérations simultanément.
Comment fait la base de données? Il écrit toutes ces modifications dans un journal spécifique et ne les applique que lorsque notre transaction est validée. Ainsi, nous garantissons que toutes ces opérations seront effectuées dans leur ensemble ou ne seront pas exécutées du tout.
Si, à tout moment de cette période, nous avons un échec, l'argent ne sera pas déduit du premier compte et, par conséquent, nous ne le perdrons pas.
Les transactions ont quatre propriétés, quatre exigences pour elles. Il s'agit de l'atomicité, de la cohérence, de l'isolement et de la durabilité - atomicité des données, cohérence, isolement et persistance. Quelles sont ces propriétés?
- L'atomicité ou l'atomicité est une garantie que l'opération que vous effectuez sera pleinement exécutée, qu'elle ne sera pas partiellement exécutée. Ainsi, nous nous assurons que la cohérence globale des données de notre base de données sera à la fois avant et après l'opération.
- Consistency — -, . (Integrity). - , , Integrity Error, : , . . — , .
, , , , . . .
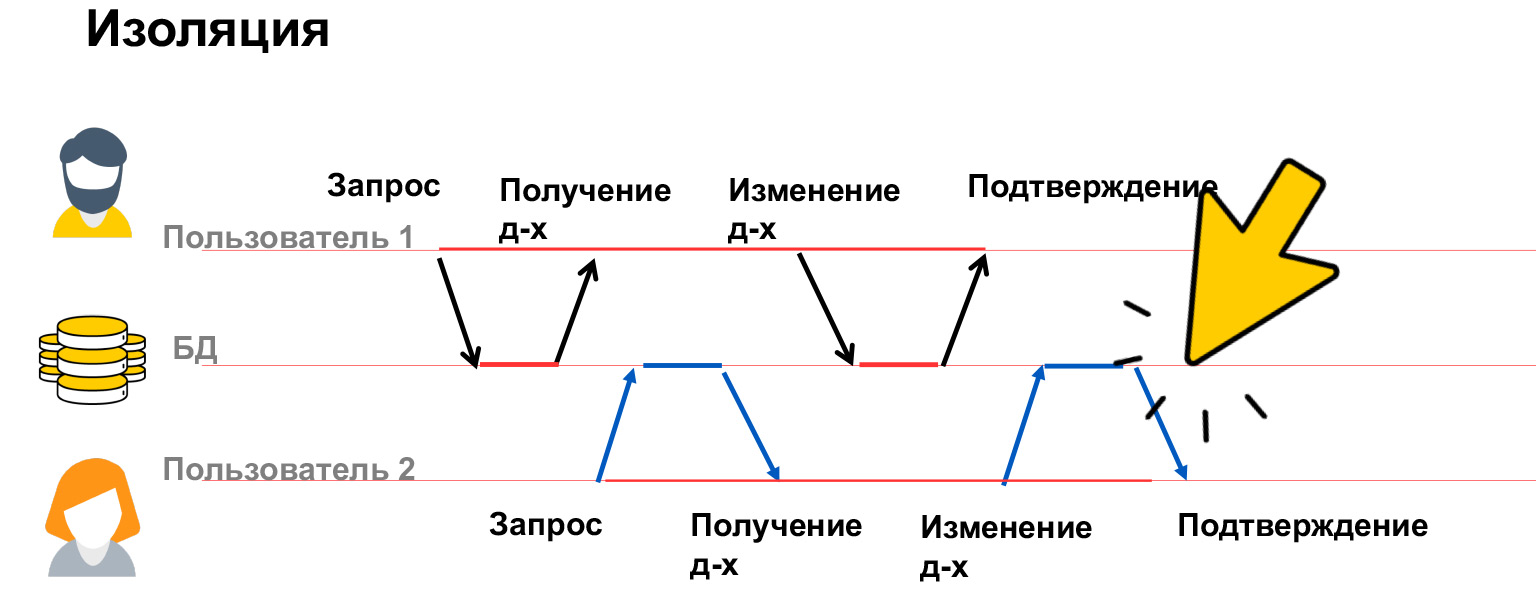
- Isolation — , . . , .
- Durability — , , , , .
Parlons un peu plus de l'isolation. L'isolement des transactions est une propriété très coûteuse, beaucoup de ressources y sont consacrées, c'est pourquoi nous avons plusieurs niveaux d'isolement dans nos bases de données. Voyons quels problèmes peuvent être, et sur cette base, nous discuterons déjà de la manière de les résoudre.
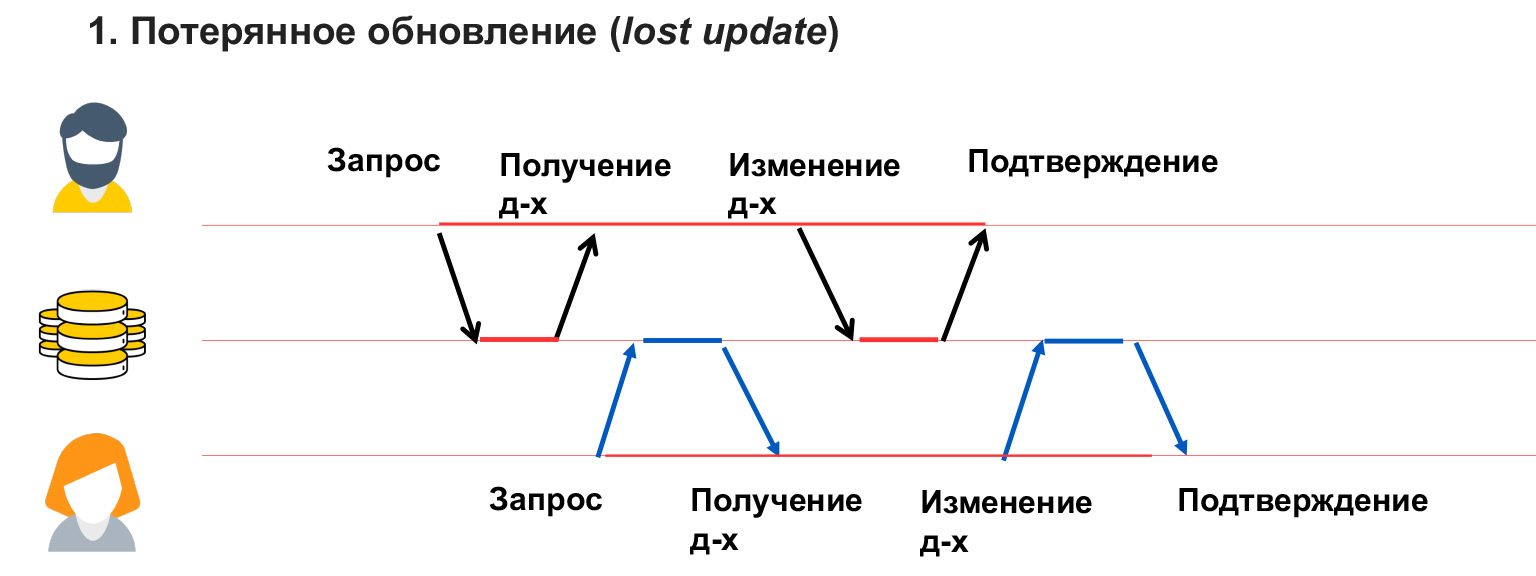
Il existe quatre classes principales de problèmes: mise à jour perdue, lecture incorrecte, lecture non répétable et lecture fantôme. Regardons de plus près.
Une mise à jour perdue est comme dans l'exemple avec les salles de chat, lorsque l'utilisateur 1 a écrasé des données et qu'il ne le sait pas. Autrement dit, nous n'avons pas bloqué les données modifiées par cet utilisateur et, par conséquent, avons reçu leur écrasement.
Un problème de lecture incorrecte se produit lorsqu'un utilisateur voit des modifications temporaires d'un autre utilisateur, qui peuvent ensuite être annulées ou simplement apportées temporairement.

Dans ce cas, l'utilisateur 1 a écrit quelque chose dans la base de données. À ce moment-là, l'utilisateur 2 calculait quelque chose à partir de là et construisait des analyses sur ces données. Et l'utilisateur 1 a rencontré une erreur, une incohérence, et annule ces données. Ainsi, les analyses que l'utilisateur 2 a notées seront fausses, incorrectes, car les données à partir desquelles il les a calculées ne sont plus là. Vous devez également être en mesure de résoudre ce problème.
Une lecture non répétable est lorsque nous avons un utilisateur avec 1 longue transaction. Il récupère les données de la base de données et à ce moment l'utilisateur 2 modifie une partie des mêmes données.
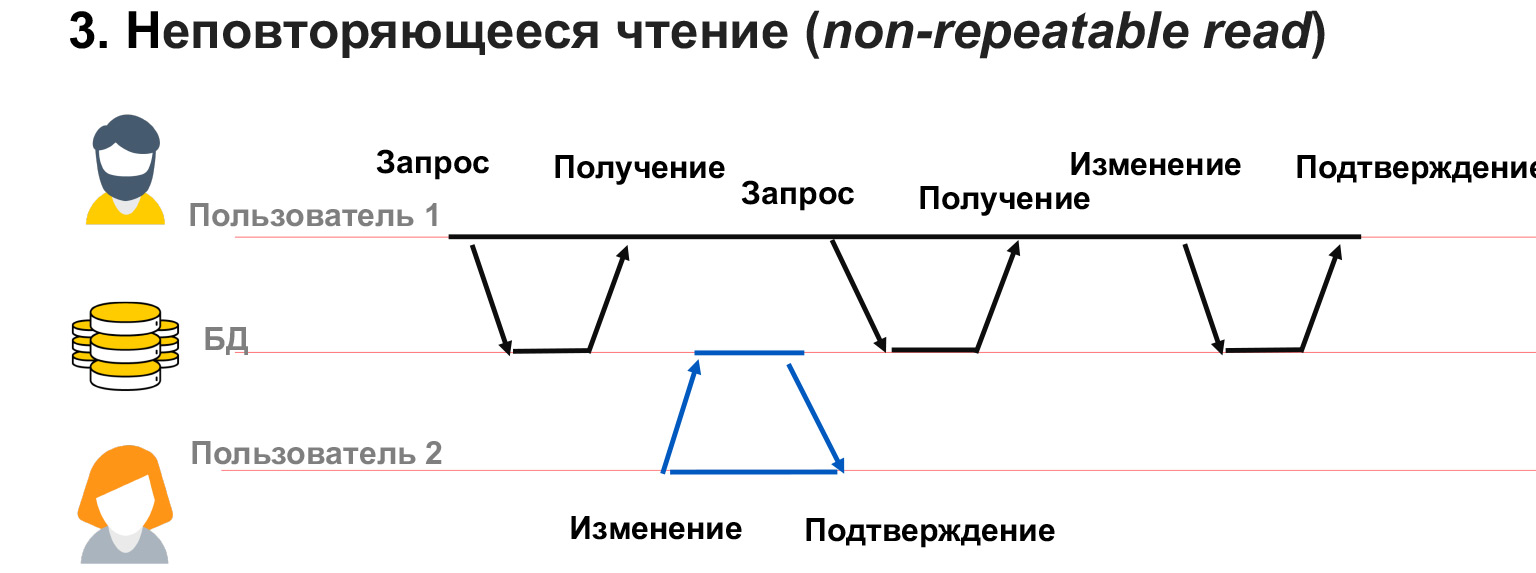
Dans ce cas, il s'avère que l'utilisateur 1 n'a pas bloqué les modifications des données dont il dispose. Et malgré le fait qu'il ait lui-même reçu un instantané des données, lorsqu'il est demandé à plusieurs reprises pour la même sélection, il peut obtenir des valeurs différentes dans ces lignes. Ainsi, il aura un conflit, une discordance dans les données qu'il écrit.

Un problème similaire peut se produire si l'utilisateur 2 a ajouté ou supprimé des données. C'est-à-dire que l'utilisateur 1 a fait une demande, puis, après une deuxième demande pour les mêmes données, il avait ou a disparu des lignes. Dans ce cas, dans le cadre d'une transaction, il est très difficile de comprendre quoi en faire, comment les traiter du tout.

Pour résoudre ces problèmes, il existe quatre niveaux d'isolement. Le premier et le plus bas niveau est Lecture non validée. C'est ce que PostgreSQL décrit comme aucun verrou. Lorsque nous lisons ou écrivons des données, nous n'empêchons pas les autres utilisateurs de lire ou d'écrire ces données. Il s'avère que nous ne bloquons aucun changement. Ces quatre problèmes peuvent toujours survenir. Mais contre quoi ce niveau d'isolement protège-t-il? Il garantit que toutes les transactions qui arrivent dans la base de données seront exécutées. Si deux utilisateurs commencent simultanément à exécuter des requêtes avec les mêmes données, ces deux transactions seront exécutées séquentiellement.
À quoi cela sert-il? Ce niveau d'isolement est très rarement utilisé en pratique, mais il peut être utile, par exemple, lorsqu'il y a une grande requête analytique et que vous souhaitez lire dans la deuxième requête et voir à quel stade se trouve votre analyste, quelles données ont déjà été enregistrées et lesquelles ne le sont pas. Et puis la deuxième demande - qui est pour le débogage, le débogage, la vérification - vous exécutez juste dans ce niveau d'isolement. Et il voit tous les changements dans votre première requête analytique, qui peut éventuellement être annulée. Ou pas annulé, mais pour le moment, vous pouvez voir l'état du système.

Lire les données validées, lire les données validées. Ce niveau d'isolement est utilisé par défaut dans la plupart des bases de données relationnelles, y compris PostgreSQL et Oracle. Cela garantit que vous ne lisez jamais de données sales. Autrement dit, une autre transaction ne voit jamais les étapes intermédiaires de la première transaction. L'avantage est qu'il fonctionne très bien pour les petites requêtes courtes. Nous garantissons que nous n'aurons jamais une situation où nous voyons certaines parties des données, des données incomplètes. Par exemple, on augmente le salaire de tout un département et on ne voit pas quand seule une partie des gens a reçu une augmentation, et la deuxième partie est assise avec un salaire non indexé. Car si nous avons une telle situation, il est logique que notre analyste «s'en aille» immédiatement.
Contre quoi ce niveau d'isolement ne protège-t-il pas? Il ne protège pas contre le fait que les données que vous avez sélectionnées peuvent être modifiées. Pour les petites requêtes, ce niveau d'isolation est suffisant, mais pour les requêtes longues et volumineuses, les analyses complexes, bien sûr, vous pouvez utiliser des niveaux plus complexes qui verrouillent vos tables.
Le niveau d'isolement de lecture répétable protège contre les trois premiers problèmes dont nous avons discuté avec vous. Ceci et une mise à jour perdue lorsque nous avons réenregistré notre salle de discussion; Lecture sale - lecture de données non validées; et ces données non répétables en lecture-lecture mises à jour par d'autres transactions.

Comment est-il fourni? En verrouillant la table, c'est-à-dire en verrouillant notre sélection. Lorsque nous prenons la sélection dans notre transaction, cela ressemble à un instantané des données. Et pour le moment, nous ne voyons pas les changements des autres utilisateurs, tout le temps que nous travaillons avec cet instantané de données. L'inconvénient est que nous bloquons les données et que, par conséquent, nous avons moins de requêtes parallèles pouvant fonctionner avec des données. C'est un aspect très important. Et en général, pourquoi y a-t-il autant de niveaux d'isolement?
Plus le niveau est élevé, plus il y a de blocs et moins d'utilisateurs pouvant travailler avec la base de données en parallèle. Chaque transaction voit un instantané spécifique des données qui ne peuvent pas être modifiées. Mais de nouvelles données peuvent apparaître. Ce niveau d'isolement ne nous sauve donc pas de l'émergence de nouvelles données adaptées à la sélection.
Il existe un autre niveau d'isolement: la sérialisation. Ceci est souvent appelé commande. Il s'agit d'un verrou de données complet sur la table. Cela évite la lecture fantôme, c'est-à-dire la lecture uniquement des données que nous avons ajoutées ou supprimées, car nous verrouillons la table, nous n'autorisons pas d'y écrire. Et nous répondons à nos demandes de manière globale.

Ceci est très utile pour les requêtes analytiques complexes et volumineuses où la précision et l'intégrité des données sont essentielles. Il ne s'avérera pas qu'à un moment donné, nous lisions les données utilisateur, puis de nouvelles statistiques sont apparues dans une autre table et il s'est avéré être désynchronisé.
C'est le niveau d'isolement le plus élevé. Il a le plus grand nombre de verrous et la plus petite parallélisation possible des requêtes.
Que devez-vous savoir sur les transactions? Qu'ils nous facilitent la vie, car ils sont implémentés au niveau du SGBD et il suffit de faire correctement nos requêtes, de les former correctement, pour que les données soient finalement cohérentes. Et pour bloquer exactement les données avec lesquelles nos utilisateurs travaillent. Il faut garder à l'esprit qu'il est mauvais de tout bloquer, partout. En fonction du système dont vous disposez et de la personne qui lit / écrit combien, vous aurez un niveau d'isolement différent. Si vous voulez le système le plus rapide possible qui commet des erreurs, vous pouvez choisir le niveau d'isolement minimum. Si vous disposez d'un système bancaire qui doit garantir la cohérence des données, tout est fait et rien n'est perdu - alors, bien sûr, vous devez choisir le niveau d'isolement maximal.
Nous avons déjà fait d'assez bons progrès pour comprendre comment structurer la base de données et ce qui peut arriver. Allons plus loin.
Dans quelle mesure le stockage d'une base de données est-il sécurisé? Certainement pas sûr. Si quelque chose lui arrive, nous perdons toutes les données. S'il y a une sauvegarde, nous pouvons la lancer, mais il y aura alors un temps d'arrêt du système. Si notre réseau tombe en panne ou si le nœud devient indisponible, le système sera également inactif pendant un certain temps, en cas d'indisponibilité.
Comment cela peut-il être résolu? Il existe une telle chose - la réplication. Il s'agit d'une duplication de la base de données vers d'autres nœuds et serveurs.

C'est exactement une duplication complète, une copie de la base de données. Comment utiliser ce mécanisme?
Premièrement, si quelque chose arrivait à la base de données, nous pouvons rediriger les requêtes vers une autre copie de la base de données, ce qui est logique en principe. Ceci est l'application principale. Comment pouvons-nous utiliser cela autrement?
Imaginons que l'utilisateur soit loin du serveur. Nous pouvons distribuer des serveurs de manière à couvrir le maximum d'utilisateurs et leur envoyer des demandes dans les plus brefs délais. Chacun de ces serveurs aura la même copie que les autres, mais les requêtes reviendront plus rapidement aux utilisateurs.

L'équilibrage de charge est une autre utilisation très répandue. Puisque nous avons des copies identiques des données, nous ne pouvons pas lire de notre tête, pas d'une base de données, mais de différentes. Ainsi, nous déchargons notre serveur.

Nous avons également le concept des requêtes OLTP et des requêtes OLAP. Ce que c'est? OLTP - requêtes transactionnelles courtes. OLAP est une analyse à long terme. C'est à ce moment-là que nous prenons une énorme jointure, une énorme sélection, nous fusionnons tout et il est très important pour nous qu'en ce moment toutes les données soient verrouillées, de sorte qu'il n'y ait aucun changement et que la base de données soit complète.
Dans de telles situations, vous pouvez effectuer des analyses sur une copie distincte de la base de données. Donc, nous n'affecterons pas nos utilisateurs, ils peuvent également faire des entrées dans la base de données, juste alors ces entrées viendront à notre copie.
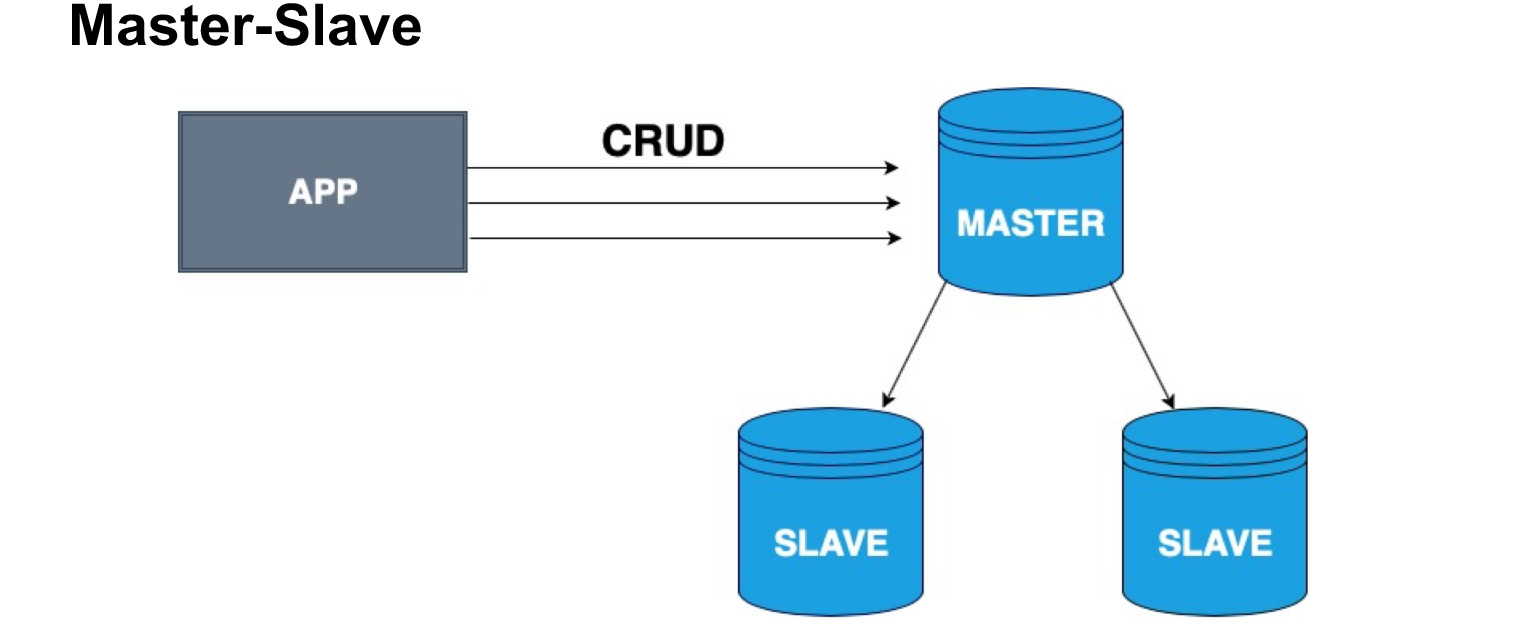
Pour distribuer correctement les copies de base de données, le concept de nœud maître et de nœud esclave, maître et esclave, est introduit. L'esclave est très souvent appelé réplique ou suiveur. Master - le nœud sur lequel notre utilisateur, notre application écrit. Le maître applique toutes les modifications, tient un journal des modifications et envoie ce journal à l'esclave. L'esclave n'accepte pas les modifications des utilisateurs, mais applique uniquement les modifications au journal du maître. Veuillez noter que Master n'envoie pas de copie à chaque fois, mais envoie les modifications. L'esclave survole ces modifications et reçoit la même copie des données que dans le maître.
Un paramètre très important du système répliqué est que les demandes sont exécutées de manière synchrone ou asynchrone. Qu'est-ce qu'une requête synchrone? C'est à ce moment que le maître envoie une requête à une réplique synchrone, à un esclave synchrone, et attend que l'esclave dise "Oui, j'ai accepté", et renvoie la confirmation au maître. Ce n'est qu'alors que le maître retournera la réponse à l'utilisateur. Si la réplique est asynchrone, alors le maître envoie une demande à la réplique, mais dit immédiatement à l'utilisateur que "C'est ça, je l'ai noté." Voyons voir comment ça fonctionne.
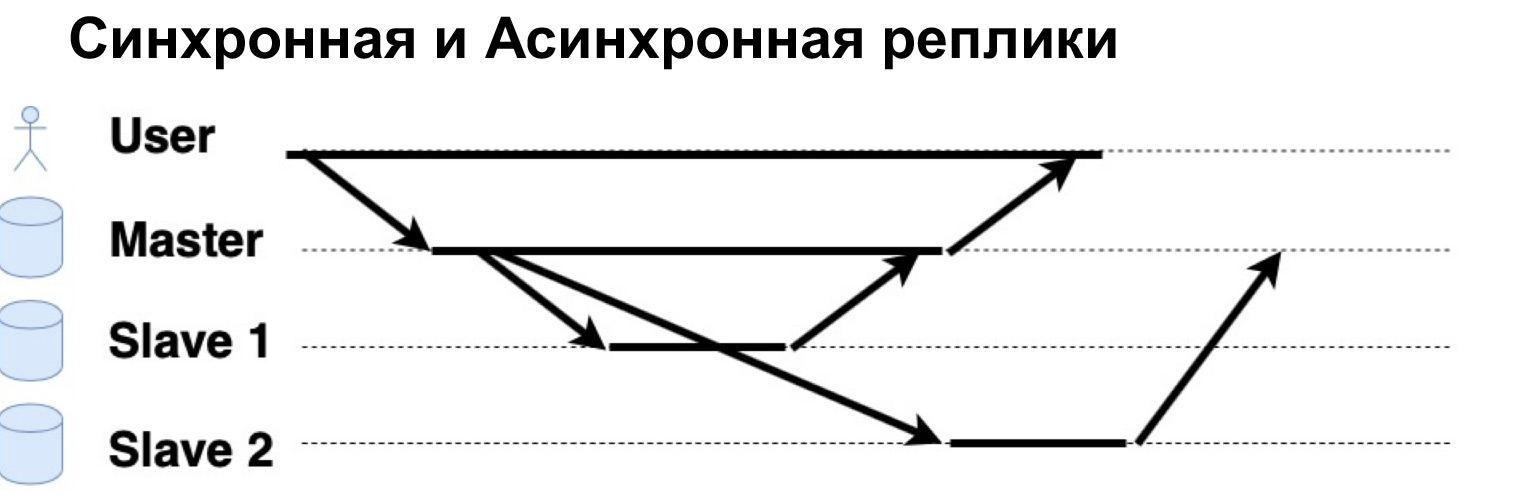
Il y a un utilisateur qui a écrit des données dans Master. Le maître les a envoyés à deux répliques, a attendu une réponse d'une réplique synchrone et a immédiatement donné une réponse à l'utilisateur. Une réplique asynchrone enregistrée et dit au Maître: "Oui, c'est bon, les données sont écrites."
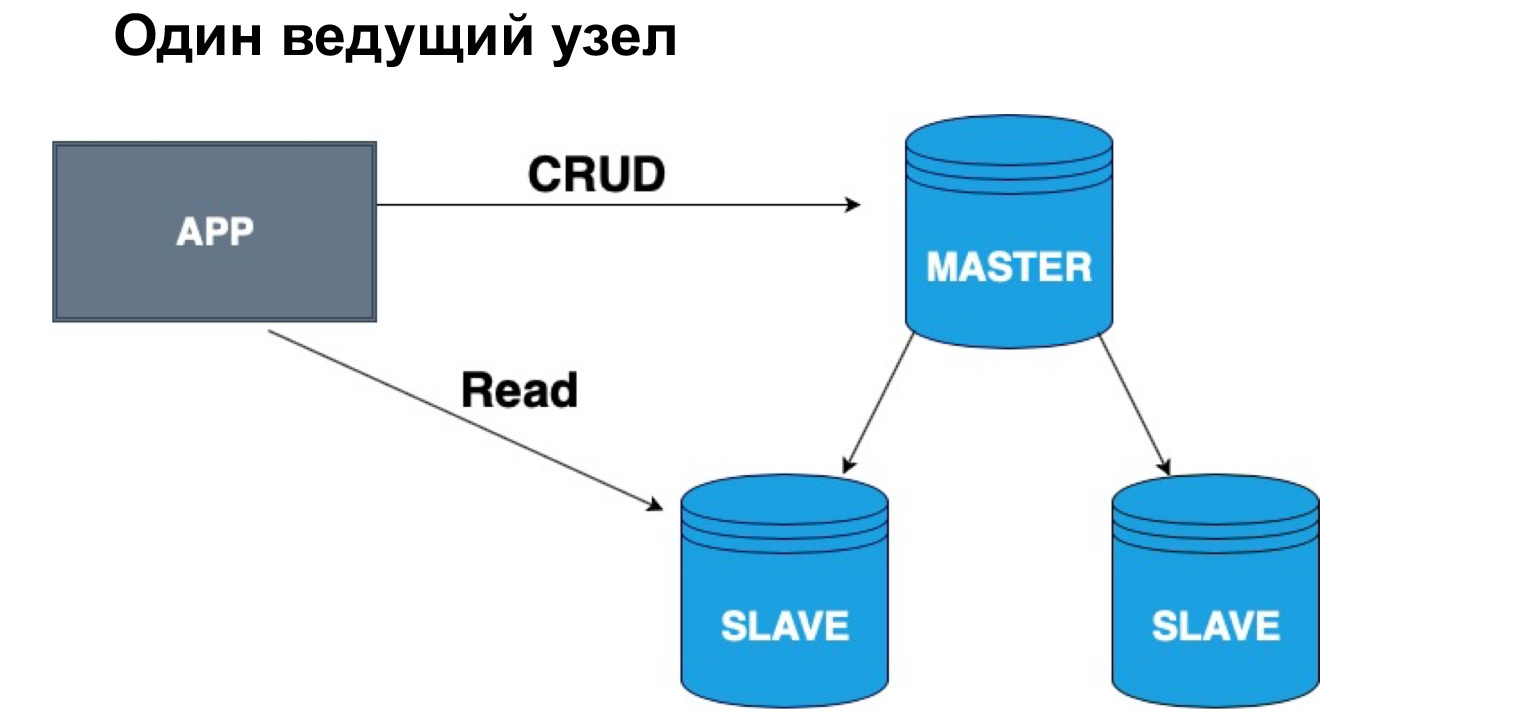
En termes d'une telle hiérarchie, maître et esclave, on peut avoir une ou plusieurs têtes. Si nous avons un nœud maître, il est très pratique d'y écrire, mais vous pouvez lire à partir d'une réplique synchrone. Pourquoi exactement de synchrone? Parce qu'une réplique synchrone garantit que les données sont à jour avec une précision maximale.
Lorsqu'une requête est appliquée à des données, une opération du journal, cela prend également du temps. Par conséquent, si l'exactitude à cent pour cent des données que vous souhaitez recevoir est importante pour vous, vous devriez aller pour la lecture, pour une sélection dans le Master. Si vous n'êtes pas critique que les données arrivent avec un léger retard, vous pouvez lire à partir de l'esclave synchrone. Si vous n'êtes absolument pas critique de la pertinence des données, vous pouvez lire, y compris à partir du réplica asynchrone, déchargeant ainsi le maître et le réplica synchrone des demandes.
La réplication peut également avoir plusieurs maîtres. Différentes applications peuvent écrire dans différentes têtes, et ces maîtres résolvent alors les conflits les uns avec les autres.
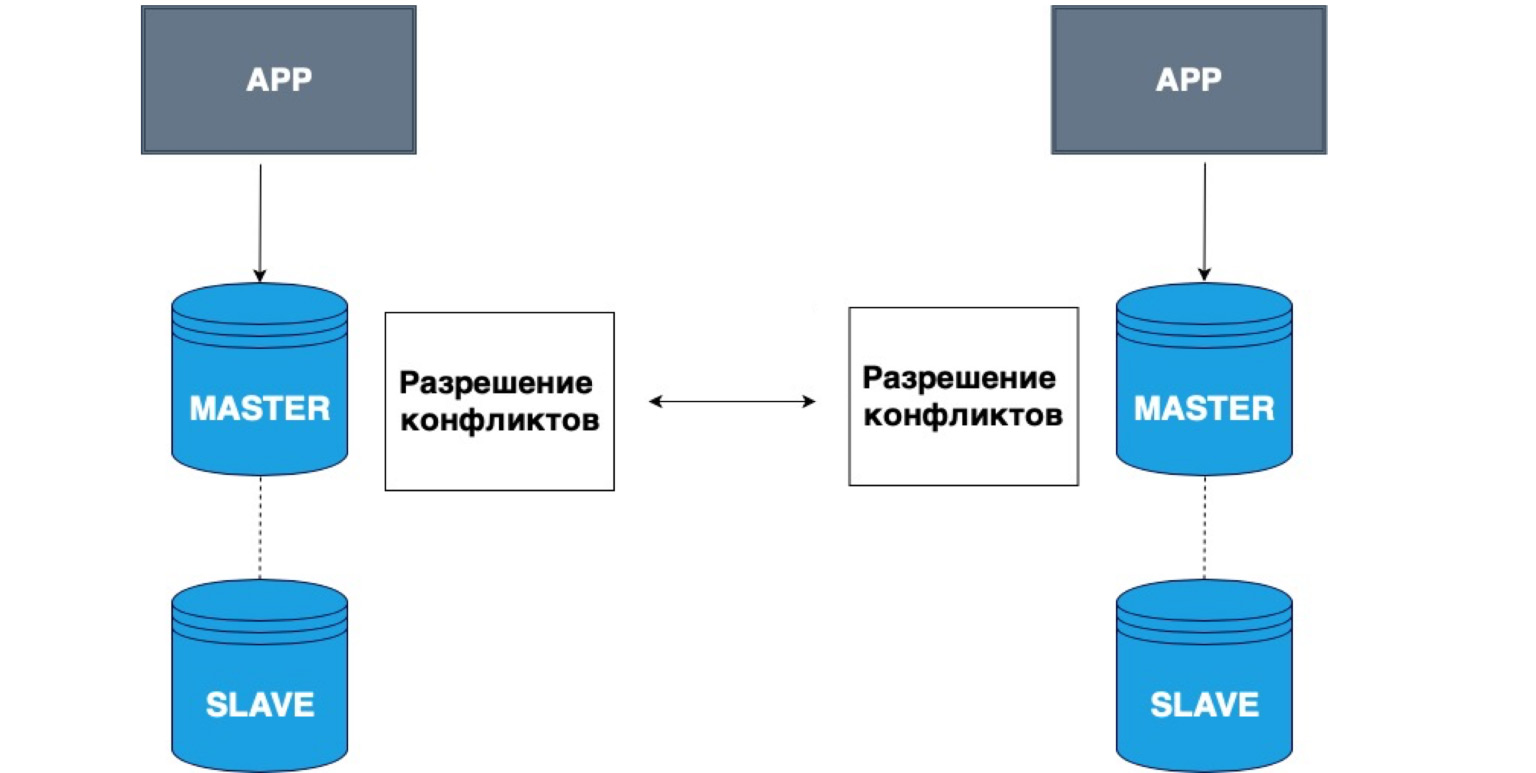
Un exemple très simple d'utilisation de telles données est toutes sortes d'applications hors ligne. Par exemple, vous avez un calendrier sur votre téléphone. Vous vous êtes déconnecté du réseau et avez enregistré un événement dans le calendrier. Dans ce cas, votre stockage local, votre téléphone, est maître. Il a stocké les données en lui-même, et lorsque le réseau maître apparaît, votre copie locale et la copie sur le serveur résoudront les conflits et combineront ces données.
Ceci est un exemple très simple d'une telle réplication. Il est souvent utilisé pour l'édition collaborative de documents en ligne, ou lorsqu'il y a une très forte probabilité de perdre le réseau.
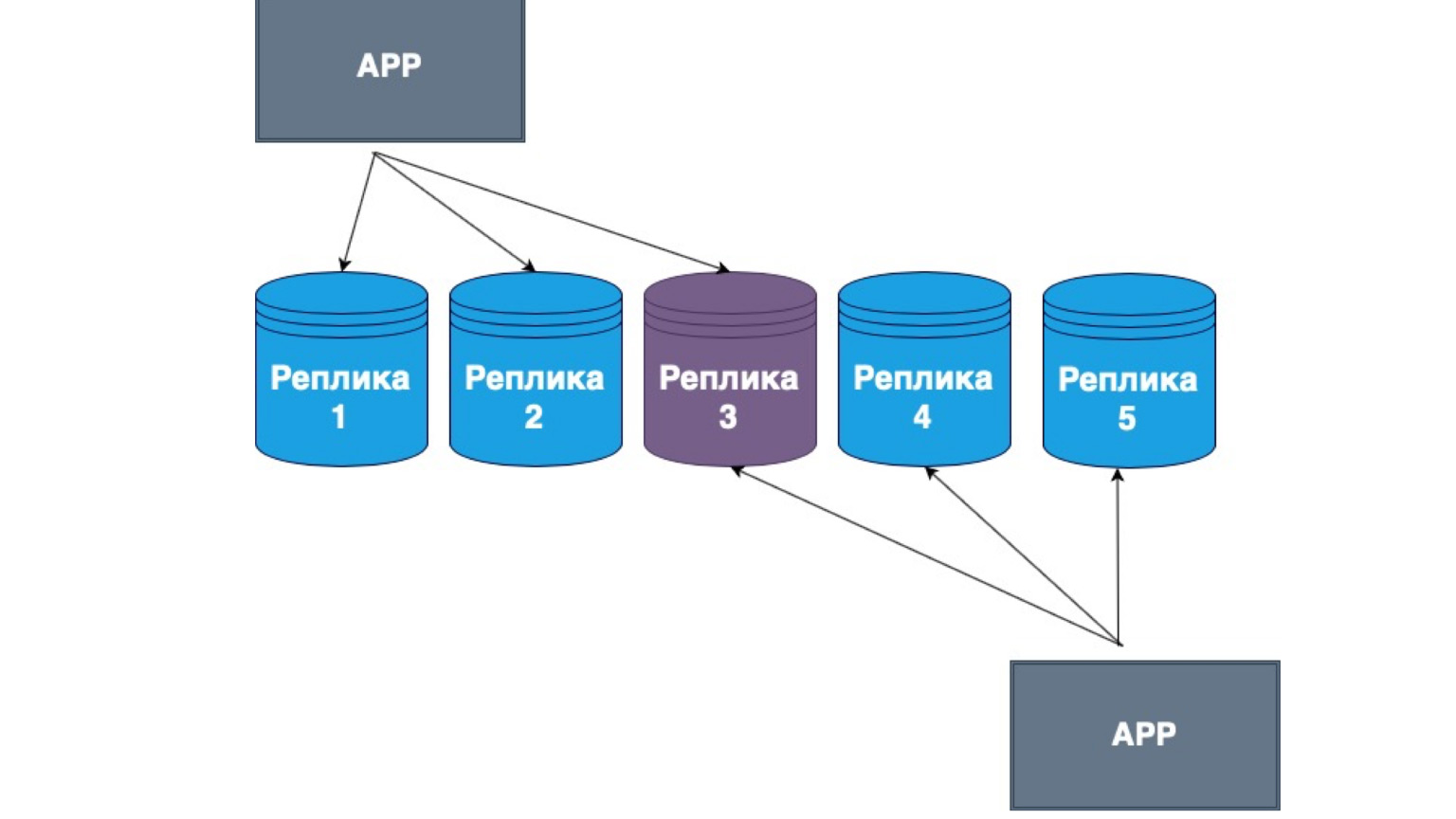
Des réplications sans maître existent également. Ce que c'est? Il s'agit de la réplication, dans laquelle le client lui-même envoie des données à la plupart des répliques et les lit également à partir de la plupart des répliques. Ici, vous pouvez voir que notre réplique du milieu est l'intersection de notre lecture et mise à jour.
Autrement dit, nous garantissons qu'à chaque fois que nous lirons les données, nous entrerons dans au moins une des répliques, dans laquelle les données sont les plus pertinentes. Et entre eux, les répliques construisent un mécanisme d'échange d'informations avec le journal principal des modifications et des conflits entre les répliques. Dans ce cas, c'est très souvent le gros client qui est implémenté. S'il a reçu des données d'une réplique contenant des modifications plus récentes qu'une autre, il envoie simplement les données à une autre réplique ou résout le conflit.

Que faut-il savoir sur la réplication? Le principal point de réplication est la tolérance aux pannes du système, la haute disponibilité de votre serveur. Quoi qu'il arrive à la base de données, le système sera disponible, vos utilisateurs pourront écrire des données, et lorsque la connexion avec le maître ou avec une autre réplique sera rétablie, toutes les données seront également restaurées.
La réplication est très utile pour décharger les serveurs et redistribuer les demandes de lecture du maître vers les répliques. Nous pouvons faire évoluer cette lecture, créer plus de répliques de lecture et rendre notre système encore plus rapide. Vous pouvez également créer une réplique de requêtes analytiques complexes à long terme qui nécessitent un grand nombre de verrous et peuvent affecter la disponibilité du système.
En utilisant des applications hors ligne comme exemple, nous avons examiné comment stocker ces données et résoudre les conflits. Dans le cas d'une réplique synchrone, il peut y avoir un décalage de réplication, c'est-à-dire un décalage dans le temps. Dans le cas d'une réplique asynchrone, elle est presque toujours là. Autrement dit, lorsque vous lisez des données à partir d'un réplica asynchrone, vous devez comprendre que cela peut ne pas être pertinent.
Selon la hiérarchie, j'ai oublié de dire que lorsqu'il y a un maître en attente d'une réponse d'une réplique synchrone, il est logique de supposer que si nous avons toutes les répliques synchrones, et que certaines deviennent soudainement indisponibles, notre système ne pourra pas enregistrer la demande. Ensuite, le maître nous écrira au premier esclave synchrone, recevra une réponse, demandera le deuxième esclave, ne recevra aucune réponse et devra finalement annuler la transaction entière.
Par conséquent, dans de tels systèmes, en règle générale, une réplique est rendue synchrone et le reste asynchrone. Le réplica synchrone garantit que vos données sont enregistrées ailleurs. Autrement dit, en plus du maître, avec lequel quelque chose peut arriver, nous garantissons qu'il y a au moins un autre nœud qui contient une copie complète d'exactement le même journal de transactions, les mêmes données.
La réplique asynchrone, en revanche, ne garantit pas l'intégrité des données. Si nous n'avons que des réplicas asynchrones et que le maître s'est déconnecté, ils peuvent être à la traîne, les données ne sont peut-être pas encore arrivées là-bas. Dans de tels cas, en règle générale, ils construisent une hiérarchie telle que soit nous avons Master, un réplica synchrone et le reste sont asynchrones, soit nous avons Master et tous les réplicas sont asynchrones, si la persistance des données n'est pas importante pour nous.
Il y a un "mais": toutes les répliques doivent avoir la même configuration. Si nous parlons de PostgreSQL à titre d'exemple, ils doivent avoir la même version de PostgreSQL lui-même, car différentes versions de la base de données peuvent avoir des formats de journal différents. Et si le réplica provient d'une version différente, il se peut qu'il ne lise tout simplement pas les opérations écrites par l'autre base.
Qu'est-ce qu'une réplique? Ceci est une copie complète de toutes les données. Disons qu'il y a tellement de données que le serveur ne peut pas les gérer. Quelle est la première solution?
La première décision est d'acheter une machine plus chère avec plus de mémoire, avec un processeur plus gros, avec un disque plus grand. Cette décision sera correcte pour la plupart, tant que vous ne serez pas confronté au problème du coût élevé du fer. Un jour, il sera trop cher d'acheter une nouvelle voiture, ou il n'y aura tout simplement nulle part où se développer. Il existe une énorme quantité de données qu'il est tout simplement impossible de mettre physiquement sur une seule machine.
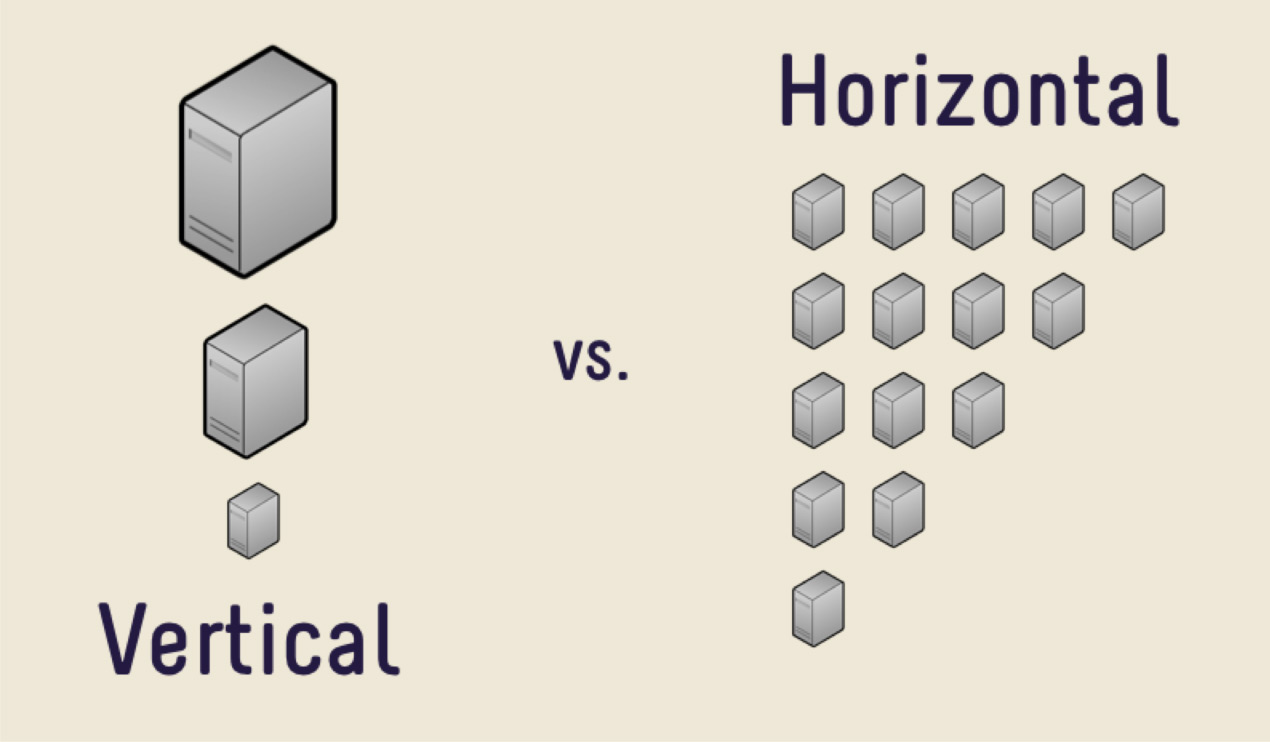
Dans de tels cas, vous pouvez utiliser la mise à l'échelle horizontale. Ce que nous avons vu plus tôt, l'augmentation des performances par machine, c'est la mise à l'échelle verticale. L'augmentation du nombre de machines est une mise à l'échelle horizontale.
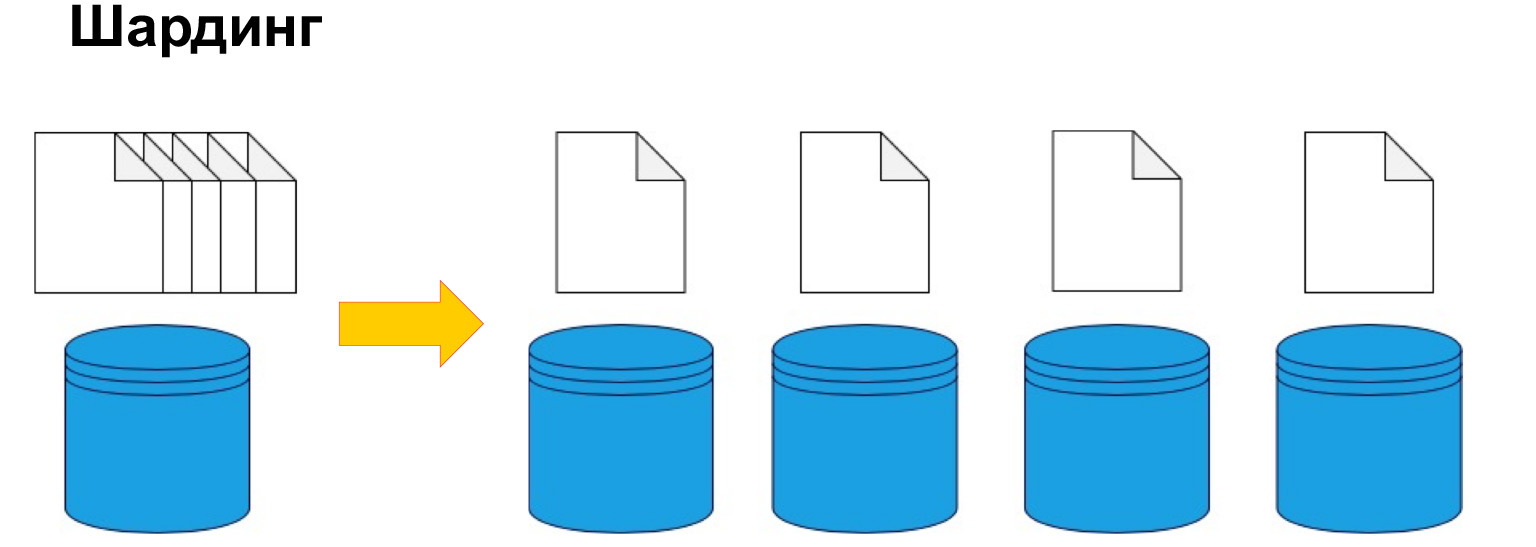
Pour diviser les données par machine, le sharding est utilisé, ou, en d'autres termes, le partitionnement. Autrement dit, diviser les données en sections et en blocs par clé, par ID, par date. Nous en reparlerons plus loin, c'est l'un des paramètres clés, mais il s'agit précisément de diviser les données selon un certain critère et de les envoyer à différentes machines. Ainsi, nos machines peuvent devenir moins efficaces, mais le système peut toujours fonctionner et recevoir des données de différentes machines.
Afin de comprendre de manière générale où se trouvent les données, vous avez besoin d'une certaine table de correspondance du fragment, de notre copie et des données.
Il y a des moments où un magasin de données spécial n'est pas utilisé et le client parcourt simplement chaque partition à son tour et vérifie s'il existe des données qui correspondent à sa demande.
Il existe une couche logicielle spéciale qui stocke certaines connaissances sur quelle partition se trouve dans quelle plage de données. Et, en conséquence, il va exactement là, au nœud même où se trouvent les données nécessaires.

Il y a un gros client. C'est à ce moment-là que nous ne cousons pas le client lui-même dans une couche séparée, mais que nous lui cousons les données sur la façon dont nos données sont partagées.
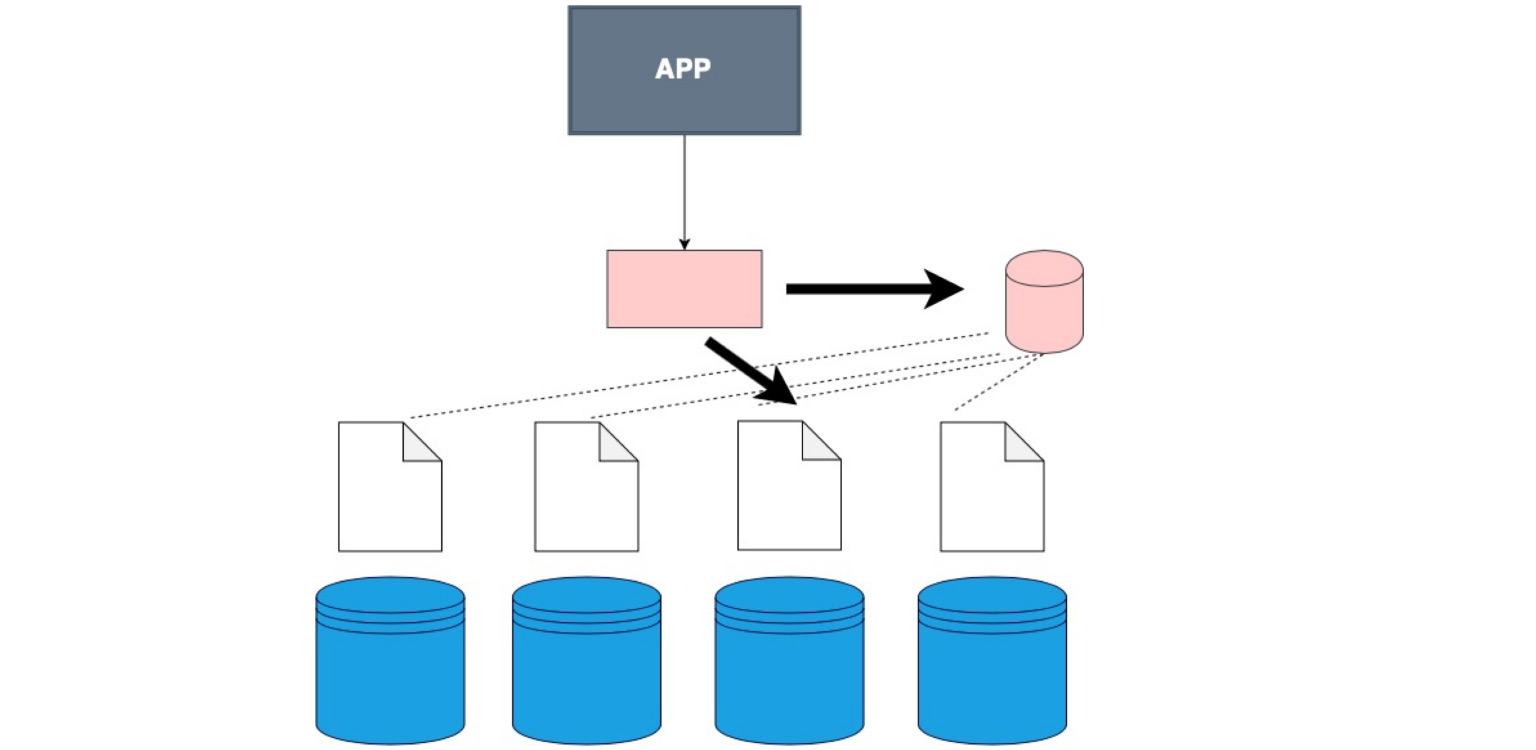
C'est le cas. Soit dit en passant, c'est le plus utilisé. La bonne chose est que notre application, notre client, même le code que vous écrivez, ne sait pas que la table est partitionnée, bien que nous l'indiquions dans la configuration, dans la base de données elle-même. Nous lui disons simplement - sélectionnez, et déjà dans la base de données elle-même, il y a une division en fragments et une compréhension de l'endroit où choisir. Ici, dans le code lui-même, vous définissez où lire les données.
Il existe des services spéciaux qui aident à structurer et à mettre à jour généralement les informations. Il est difficile de le maintenir cohérent et pertinent. Nous avons sélectionné quelque chose, enregistré de nouvelles données. Ou quelque chose a changé et nous devons acheminer nos demandes très correctement. Il existe des services spéciaux pour coordonner les demandes. L'un d'eux est Zookeper. Vous pouvez voir comment ils fonctionnent en général. Une structure très intéressante. Ils ont sauvé beaucoup de nerfs et de temps pour les développeurs.
Qu'est-ce qui est important, quels aspects garder à l'esprit lorsque vous partitionnez? Il est important de comprendre quelle clé nous utiliserons pour nous diviser en fragments. Recueillir toutes ces données coûte assez cher, il est donc très important de ne pas se tromper sur la manière dont les données seront potentiellement utilisées à l'avenir. Si nous avons bien et correctement partitionné, alors avec les requêtes les plus fréquemment utilisées, nous saurons toujours vers quelle réplique aller.
Par exemple, si nous, selon les identifiants de l'utilisateur, stockons toutes leurs données sur certaines répliques, alors nous comprenons que nous pouvons arriver à cette réplique et y effectuer toutes les jointures. Mais le garder par ID n'est pas l'idée la plus cool. Maintenant je vais vous dire pourquoi.
Si nous avons mal identifié la clé lors du partitionnement, si nous avons une requête très complexe, nous devons vraiment accéder à différents fragments, combiner toutes les données et les donner ensuite à l'application. Heureusement, la plupart des SGBD le font pour nous. Mais quel genre de frais généraux résulterait de requêtes mal écrites? Ou sous le sharding, qui est cassé sur le mauvais nœud?
À propos des identifiants. Si le système ne fonctionne qu'avec de nouveaux utilisateurs et que nous avons une augmentation des ID, toutes les demandes iront au dernier nœud.
Ce qui se produit? Les trois autres machines en cours d'exécution resteront inactives. Et cette voiture brûlera simplement - le soi-disant point chaud. C'est le goulot d'étranglement de votre système potentiel, l'endroit qui peut même refuser les connexions.
Par conséquent, lorsque nous définissons la clé de partitionnement, il est très important de comprendre à quel point ces nœuds seront équilibrés. Les hachages sont très souvent utilisés, il s'agit d'un agencement de données plus ou moins neutre et équilibré. Mais si vous avez une fonction de hachage sur une clé, vous ne pourrez pas sélectionner, par exemple, par plages. C'est logique, car les plages ne peuvent pas être réparties en différents fragments.
Par date - le même. Si, par exemple, nous dispersons les analyses et faisons des fragments par date, alors, bien sûr, un fragment d'il y a dix ans ne sera pas du tout utilisé. Ce n'est pas rentable pour nous. Et il est toujours très coûteux de reconstruire les données et de les surcharger.
Je vais répondre à la question qui précède. Vaut-il mieux définir des indices ou créer des fragments? Des indices, bien sûr.
Regardez, les fragments sont des machines séparées avec toute une infrastructure surélevée. Et ce composant central contient quelque chose qui ressemble à des index. Il y a une recherche rapide par paramètres - où, où aller. Voici le ratio. Mais s'il y a du sharding, l'image finale sera comme ceci:

il y a des applications, une sorte de tête qui sait où aller. Et il y a des fragments, sur chacun desquels une réplique est configurée. Il s'agit d'une surcharge très importante s'il n'y a pas beaucoup de données. Autrement dit, vous ne devez recourir au sharding que lorsque vous avez vraiment atteint la limite de mise à l'échelle verticale, lorsque l'achat d'une machine plus chère n'est pas pertinent pour vos données ou vos revenus. Ensuite, vous pouvez acheter plusieurs voitures différentes et moins chères et y construire une telle architecture.
À mon avis, à quoi servent les répliques est clair: parce que les fragments sont cassés, ce sont des morceaux de bases de données, mais ils sont en quelque sorte uniques. Ils ne se trouvent que dans ces endroits. Nous les décomposons également en copies, ce qui rend nos nœuds tolérants aux pannes et les protège contre les problèmes.

Le plus important: le sharding est utilisé exactement là où vous ne voulez pas seulement diviser les données en classification, mais exactement là où il y a vraiment beaucoup de données.
Passons maintenant davantage aux modèles de données et voyons comment les données peuvent être stockées.
Les bases de données relationnelles que nous avons examinées auparavant présentent un grand nombre d'avantages, car, tout d'abord, elles sont très communes et compréhensibles par tout le monde. Ils montrent visuellement la relation entre les objets et assurent l'intégrité.
Mais il y a un inconvénient: ils nécessitent une structure claire. Il y a une table dans laquelle nous devons pousser toutes les données. Si vous regardez toutes les informations et faits que nous collectons en général, ils sont très différents. Autrement dit, nous pouvons travailler avec des données produit, avec des données utilisateur, des messages, etc. Ces données nécessitent vraiment une structure et une intégrité claires. Une base de données relationnelle est idéale pour eux.
Mais supposons que nous ayons, par exemple, un journal des opérations ou une description des objets, où chaque objet a des caractéristiques différentes. Nous pouvons, bien sûr, l'écrire dans un jason dans une base de données relationnelle et être heureux que cela grandisse avec nous à l'infini.
Et nous pouvons regarder d'autres schémas, d'autres systèmes de stockage. NoSQL est une abréviation très flashy, voire directement provocante - "no SQL". Comment est-ce arrivé?
Lorsque les gens ont été confrontés au fait que les bases de données relationnelles ne réussissaient pas partout, ils ont organisé une conférence qui avait besoin d'un hashtag, et ils ont donc proposé #NoSQL. Cela a pris racine. Plus tard, ils ont commencé à dire non pas «pas de SQL», mais «pas seulement SQL». C'est tout ce qui n'est pas relationnel: une énorme famille de bases de données différentes qui ne sont pas aussi rigoureusement structurées, schématiques et tabulaires que les bases de données relationnelles.
La famille des modèles de données non relationnelles est divisée en quatre types: bases de données de valeurs-clés, orientées document, colonnes et graphiques. Examinons chacun de ces points, découvrons quelles données il est préférable de stocker dans lequel d'entre eux et à quoi elles servent.

Valeur clé. C'est le plus simple. Voici le dictionnaire, voici le ratio. Il s'agit d'une base de données dans laquelle les données sont stockées par clés, et peu importe ce qui se trouve sous une clé particulière. Nous avons à la fois la clé elle-même et les données peuvent être des structures à la fois simples et beaucoup plus complexes. L'avantage d'une telle base de données est que, comme un index, elle recherche des données très rapidement. C'est pourquoi la valeur-clé est très souvent utilisée pour le cache. L'avantage est que notre valeur peut être différente selon les clés.
Nous pouvons utiliser la clé, par exemple, pour stocker les sessions utilisateur. L'utilisateur a cliqué, nous avons écrit ceci en valeur. C'est un modèle sans schéma, un modèle de données sans schéma spécifique, structure de valeur. Parce qu'il s'agit d'une structure très simple, elle est rapide et facile à mettre à l'échelle. Nous avons déjà les clés, et nous pouvons très facilement les fragmenter, faire leurs hachages. C'est l'une des bases de données les plus évolutives.
Les exemples sont Redis, Memcached, Amazon DynamoDB, Riak, LevelDB. Vous pouvez voir les fonctionnalités d'implémentation des stockages clé-valeur.

Les bases de données de documents sont très similaires aux valeurs-clés dans certaines de leurs utilisations. Mais leur unité est un document. C'est une structure tellement complexe par laquelle nous pouvons sélectionner certaines données, faire des opérations en bloc: insertion en bloc, mise à jour en bloc.
Chaque document peut stocker en soi, en règle générale, XML, JSON ou BSON - JSON stocké en binaire. Mais maintenant, c'est presque toujours JSON ou BSON. C'est aussi comme une paire clé-valeur, vous pouvez l'imaginer comme une table dans laquelle chaque ligne a certaines caractéristiques, et nous pouvons en tirer quelque chose en utilisant ces clés.
L'avantage des bases de données orientées document est qu'elles offrent une disponibilité et une flexibilité des données très élevées. Dans n'importe quel document, dans n'importe quel JSON, vous pouvez écrire absolument n'importe quel ensemble de données. Et ils sont très souvent utilisés - par exemple, lorsque vous devez créer un catalogue et lorsque chaque produit du catalogue peut avoir des caractéristiques différentes.
Ou, par exemple, des profils d'utilisateurs. Quelqu'un a indiqué son film préféré, quelqu'un - son plat préféré. Afin de ne pas tout coller dans un seul champ, qui stockera on ne sait pas quoi, on peut tout écrire en JSON d'une base de documents.
Les bases de données en colonnes constituent un autre modèle pratique pour stocker des données. Ils sont également appelés bases de données en colonnes.

C'est une structure très intéressante qui est utilisée, me semble-t-il, dans presque tous les grands projets complexes. Une telle base de données implique que nous stockons les données sur le disque non pas en lignes, mais en colonnes. Utilisé pour des recherches très rapides sur une énorme quantité de données. En règle générale - pour l'analyse, lorsque vous devez sélectionner des valeurs uniquement à partir de certaines colonnes.
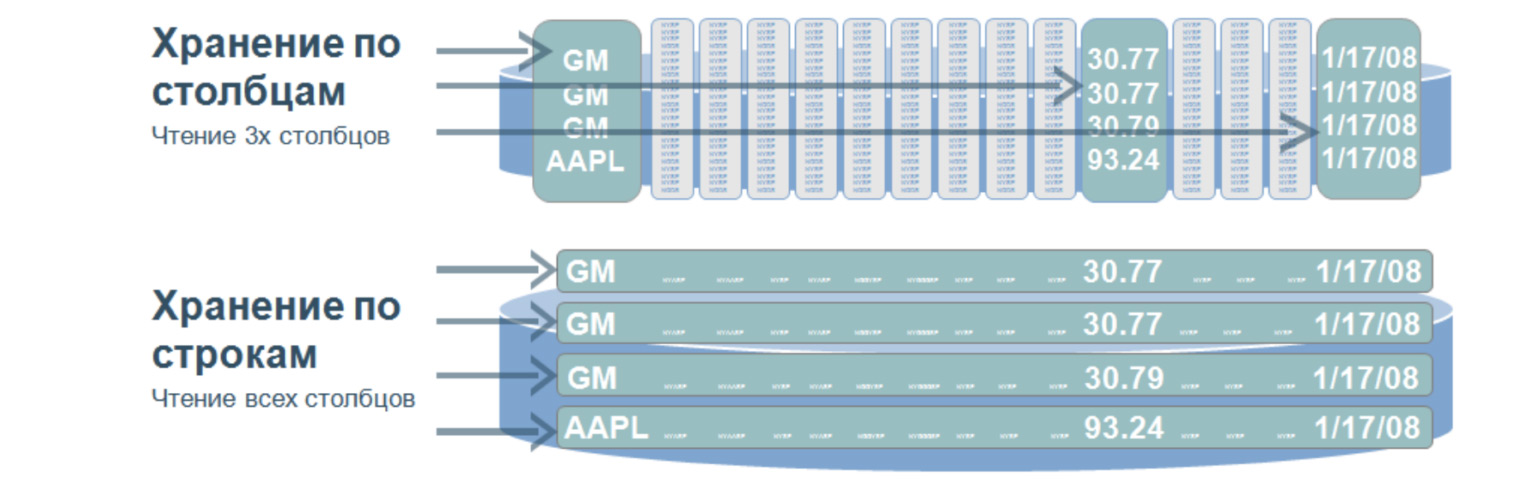
Imaginons que nous ayons une immense table. Et si nous stockions les données en lignes, ce serait ce qui se trouve en dessous: un nombre énorme de lignes. Pour sélectionner ne serait-ce que trois paramètres de ce tableau, nous devons parcourir le tableau entier. Et lorsque nous stockons des valeurs par colonnes, lors de la sélection par trois valeurs, nous devons parcourir seulement trois lignes de ce type, en gros, car nos colonnes sont écrites comme ceci. En passant par ces trois lignes, nous obtenons immédiatement le nombre ordinal de la valeur dont nous avons besoin et l'obtenons à partir des autres colonnes.
Quel est l'avantage de telles bases de données? En raison du fait qu'ils recherchent une petite quantité de données, ils ont une vitesse de traitement des requêtes très élevée et une grande flexibilité des données, car nous pouvons ajouter n'importe quel nombre de colonnes sans changer la structure. Ici, pas comme dans les bases de données relationnelles, nous n'avons pas besoin de forcer nos données dans certains cadres.
Les colonnes les plus populaires sont probablement Cassandra, HBase et ClickHouse. Testez-les. Il est très intéressant d'inverser le rapport des lignes et des colonnes dans votre tête. Et c'est un accès vraiment efficace et rapide à de grandes quantités de données.

Il existe également une famille de bases de données graphiques. Ils contiennent également des nœuds et des arêtes. Les bords sont utilisés pour montrer les relations, tout comme dans les bases de données relationnelles. Mais les bases de graphes peuvent croître à l'infini dans différentes directions. Par conséquent, il est plus flexible. Il a une vitesse de recherche très élevée, car il n'est pas nécessaire de sélectionner et de joindre toutes les tables. Notre nœud a immédiatement des arêtes qui montrent la relation avec tous les différents objets.
À quoi servent ces bases de données? Le plus souvent - juste pour montrer la relation. Par exemple, dans les réseaux sociaux, vous pouvez répondre à la question de savoir qui suit qui. Nous avons immédiatement des liens vers tous les adeptes de la bonne personne. Encore très souvent, ces bases de données sont utilisées pour identifier des stratagèmes de fraude, car cela est également associé à la démonstration de la relation des transactions entre elles. Par exemple, vous pouvez suivre quand la même carte bancaire a été utilisée dans une autre ville ou quand quelqu'un d'autre a entré le compte d'un autre utilisateur à partir de la même adresse IP.
Ce sont ces relations complexes qui aident à résoudre des situations inhabituelles qui sont souvent utilisées pour analyser ces interactions et relations.
Les bases de données non relationnelles ne remplacent pas les bases de données relationnelles. Ils sont simplement différents. Différents formats de données et différentes logiques de leur travail, ni pire ni meilleur. C'est juste une approche différente des autres données. Et oui, les bases de données non relationnelles sont beaucoup utilisées. Vous n'avez pas besoin d'en avoir peur, au contraire, vous devez les essayer.
Si vous créez un cache, prenez bien sûr une sorte de Redis, une valeur-clé simple et rapide. Si vous avez un grand nombre de journaux à analyser, vous pouvez le déposer dans ClickHouse ou dans une base en colonnes, ce qui sera alors très pratique à rechercher. Ou écrivez-le dans la base de documents, car il peut y avoir différentes significations des documents. Cela peut également être utile pour la sélection.
Choisissez un modèle de données en fonction des données que vous utiliserez. Soit relationnel ou non relationnel. Décrivez les données. De cette façon, vous pouvez trouver le stockage le plus approprié que vous pourrez faire évoluer à l'avenir.

Aujourd'hui, vous avez beaucoup appris sur divers problèmes et méthodes de stockage des données. Je vais répéter encore une fois ce que j’ai dit au tout début: vous n’avez pas besoin de tout savoir en détail, vous n’avez pas besoin de vous plonger dans une seule chose. Si vous êtes intéressé - bien sûr que vous le pouvez. Mais il est important de savoir qu'il existe, quelles sont les approches et comment vous pouvez penser du tout. Si vous avez besoin d'une tolérance aux pannes, il est logique de créer une réplique. Supposons que j'écrive les données, mais que je ne les ai pas vues. Puis, probablement, ma remarque a donné un décalage. Il n'est pas nécessaire de réinventer la roue - il existe déjà de nombreuses solutions toutes faites pour différentes tâches. Élargissez vos horizons, et si un bug ou tout autre problème apparaît, vous comprendrez exactement où la panne s'est produite par les caractéristiques du bug, et vous pourrez trouver une solution grâce à un moteur de recherche. Merci de votre attention.