
Notre monde génère de plus en plus d'informations. Une partie de celui-ci est éphémère et se perd aussi vite qu'elle est collectée. L'autre devrait être stocké plus longtemps, tandis que l'autre est conçu «pour des siècles» - du moins c'est ainsi que nous le voyons à partir du présent. Les flux d'informations s'installent dans les centres de données à une vitesse telle que toute nouvelle approche, toute technologie conçue pour satisfaire cette «demande» sans fin devient rapidement obsolète.
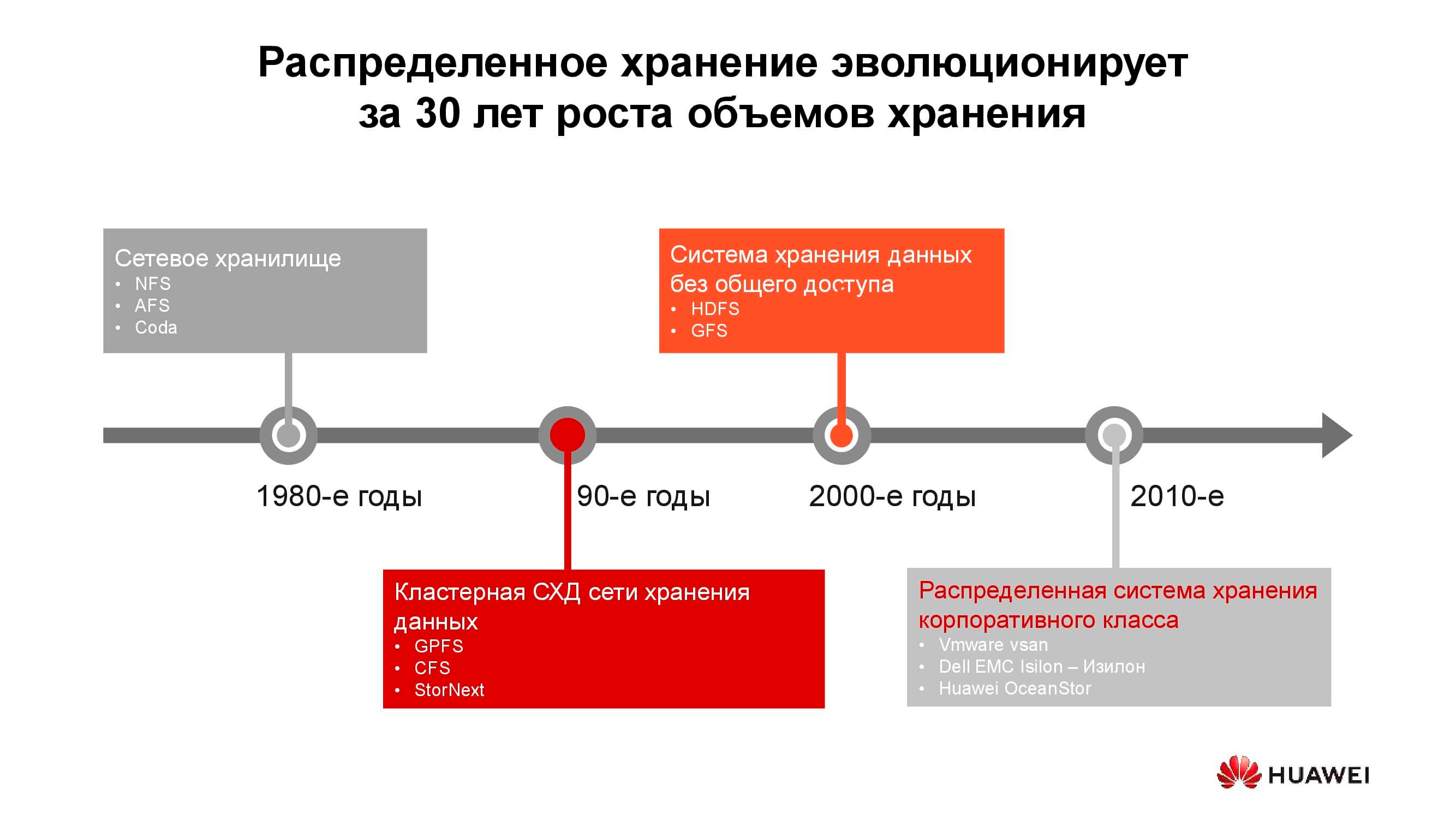
40 ans de développement de systèmes de stockage distribués
Les premiers stockages rattachés au réseau sont apparus sous la forme habituelle dans les années 1980. Beaucoup d'entre vous ont rencontré NFS (Network File System), AFS (Andrew File System) ou Coda. Une décennie plus tard, la mode et la technologie ont changé et les systèmes de fichiers distribués ont cédé la place aux systèmes de stockage en cluster basés sur GPFS (General Parallel File System), CFS (Clustered File Systems) et StorNext. Comme base, des stockages de blocs d'architecture classique ont été utilisés, sur lesquels un système de fichiers unique a été créé à l'aide d'une couche logicielle. Ces solutions et des solutions similaires sont toujours utilisées, occupent leur propre créneau et sont très demandées.
Au tournant du millénaire, le paradigme du stockage distribué a quelque peu changé et les systèmes dotés de l'architecture SN (Shared-Nothing) ont pris la tête. Il y a eu une transition du stockage en cluster au stockage sur des nœuds séparés, qui, en règle générale, étaient des serveurs classiques avec des logiciels qui fournissent un stockage fiable; sur ces principes sont construits, par exemple, HDFS (Hadoop Distributed File System) et GFS (Global File System).
Plus près des années 2010, les concepts du stockage distribué se reflètent de plus en plus dans des produits commerciaux à part entière tels que VMware vSAN, Dell EMC Isilon et notre Huawei OceanStor.... Derrière les plates-formes mentionnées, il n'y a plus une communauté de passionnés, mais des fournisseurs spécifiques qui sont responsables de la fonctionnalité, du support, du service du produit et garantissent son développement ultérieur. Ces solutions sont les plus demandées dans plusieurs domaines.
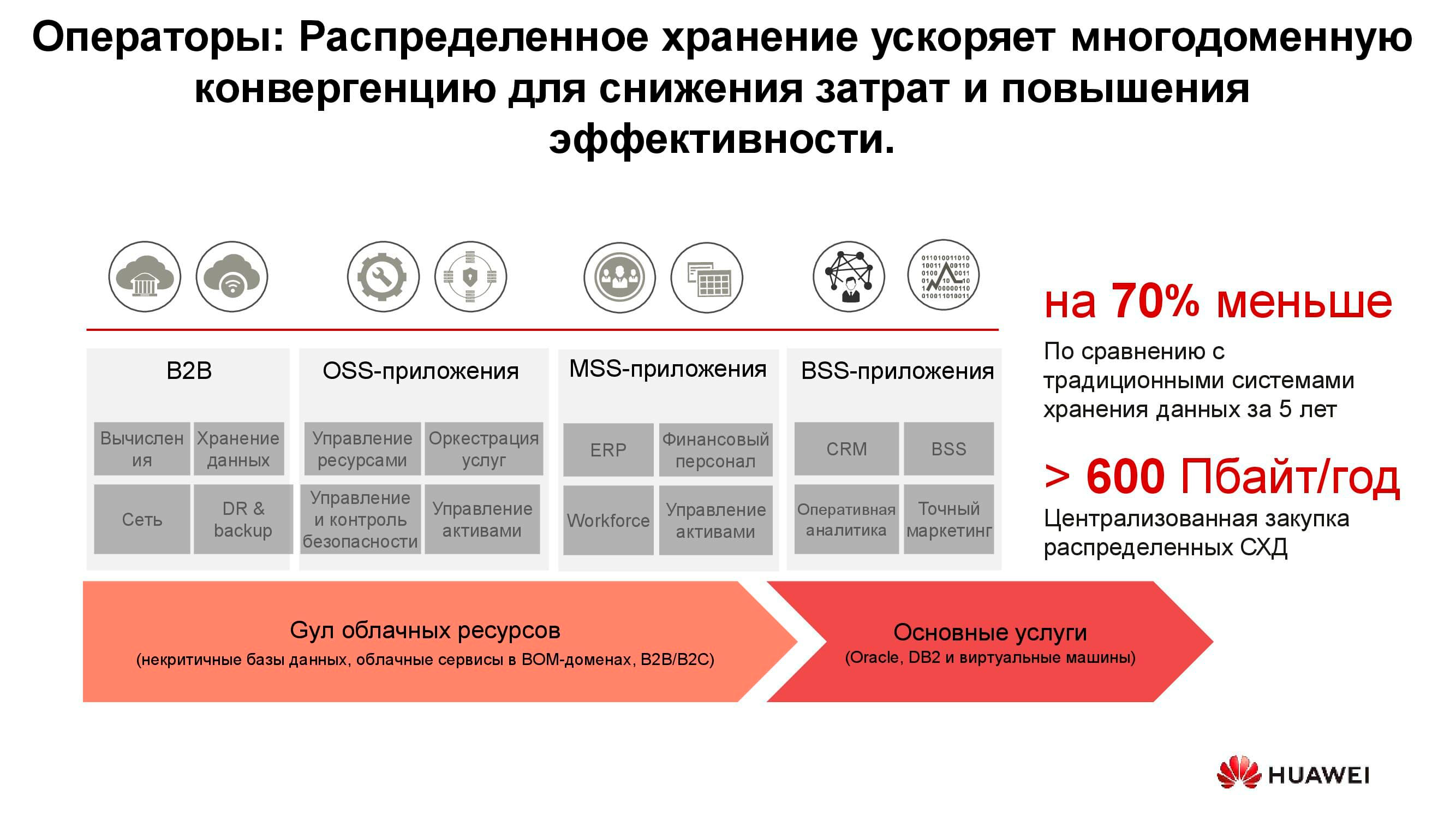
Opérateurs télécoms
Les opérateurs de télécommunications sont peut-être l'un des plus anciens consommateurs de systèmes de stockage distribués. Le diagramme montre quels groupes d'applications produisent la majeure partie des données. OSS (Operations Support Systems), MSS (Management Support Services) et BSS (Business Support Systems) sont trois couches logicielles complémentaires nécessaires pour fournir le service aux abonnés, le reporting financier au fournisseur et le support opérationnel aux ingénieurs de l'opérateur.
Souvent, les données de ces couches sont fortement mélangées les unes aux autres, et afin d'éviter l'accumulation de copies inutiles, des stockages distribués sont utilisés, qui accumulent toute la quantité d'informations provenant du réseau de travail. Les stockages sont regroupés dans un pool commun auquel se réfèrent tous les services.
Nos calculs montrent que le passage des systèmes de stockage classiques aux systèmes de stockage par blocs vous permet d'économiser jusqu'à 70% du budget uniquement en éliminant les systèmes de stockage dédiés de la classe haut de gamme et en utilisant des serveurs conventionnels d'architecture classique (généralement x86) fonctionnant en conjonction avec des logiciels spécialisés. Les opérateurs cellulaires ont depuis longtemps commencé à acheter de telles solutions en gros volumes. En particulier, les opérateurs russes utilisent ces produits de Huawei depuis plus de six ans.
Oui, un certain nombre de tâches ne peuvent pas être effectuées à l'aide de systèmes distribués. Par exemple, avec des exigences de performances accrues ou une compatibilité avec des protocoles plus anciens. Mais au moins 70% des données traitées par l'opérateur peuvent être localisées dans un pool distribué.
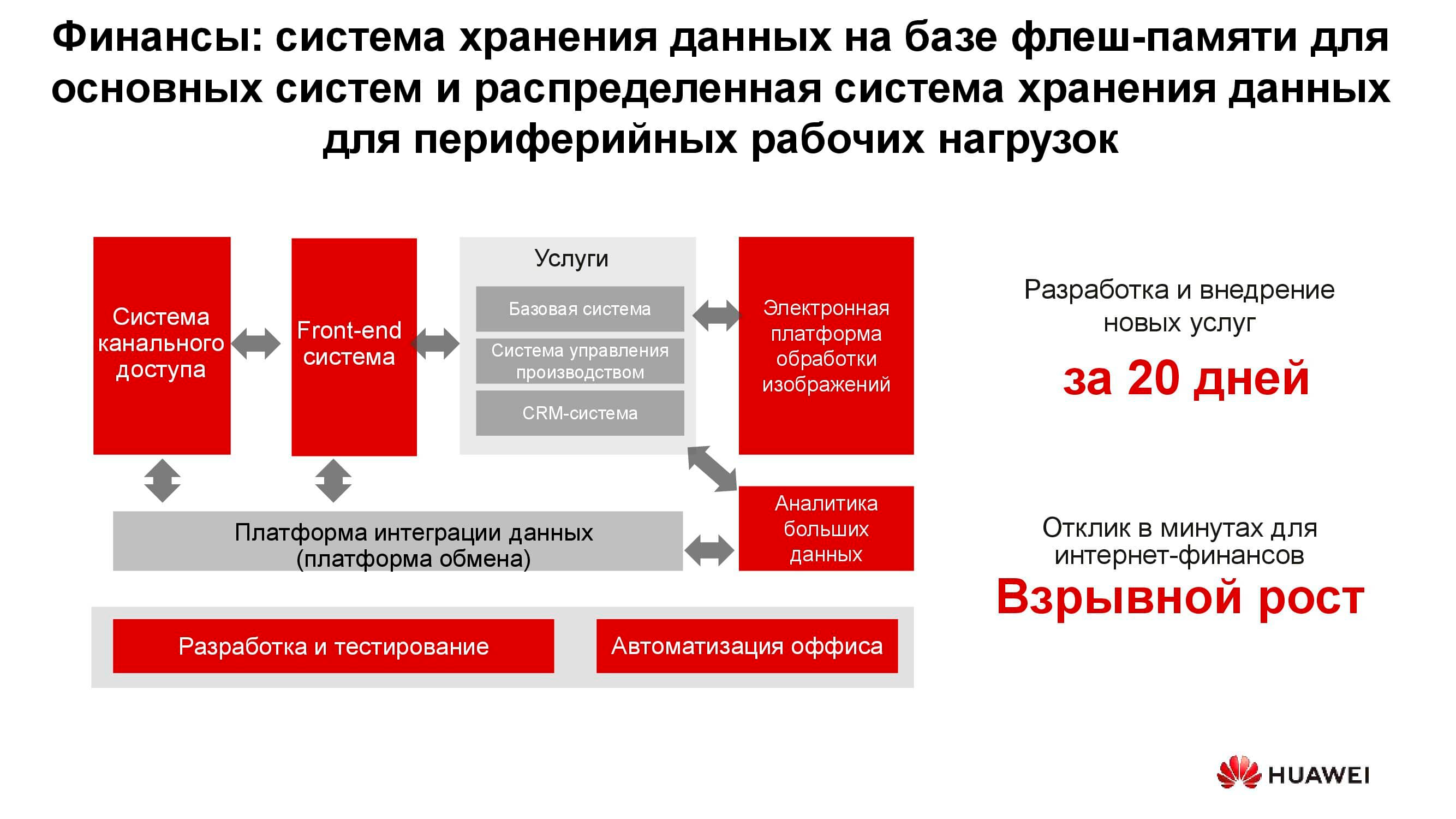
Secteur bancaire
Dans n'importe quelle banque, il existe de nombreux systèmes informatiques différents, du traitement au système bancaire automatisé. Cette infrastructure fonctionne également avec une énorme quantité d'informations, alors que la plupart des tâches ne nécessitent pas une augmentation des performances et de la fiabilité des systèmes de stockage, par exemple, le développement, les tests, l'automatisation des processus bureautiques, etc. Ici, l'utilisation de systèmes de stockage classiques est possible, mais chaque année, elle est de moins en moins rentable. De plus, dans ce cas, il n'y a pas de flexibilité dans l'utilisation des ressources de stockage, dont les performances sont calculées à partir de la charge de pointe.
Lors de l'utilisation de systèmes de stockage distribués, leurs nœuds, qui sont en fait des serveurs ordinaires, peuvent être convertis à tout moment, par exemple, en une ferme de serveurs et utilisés comme plate-forme informatique.
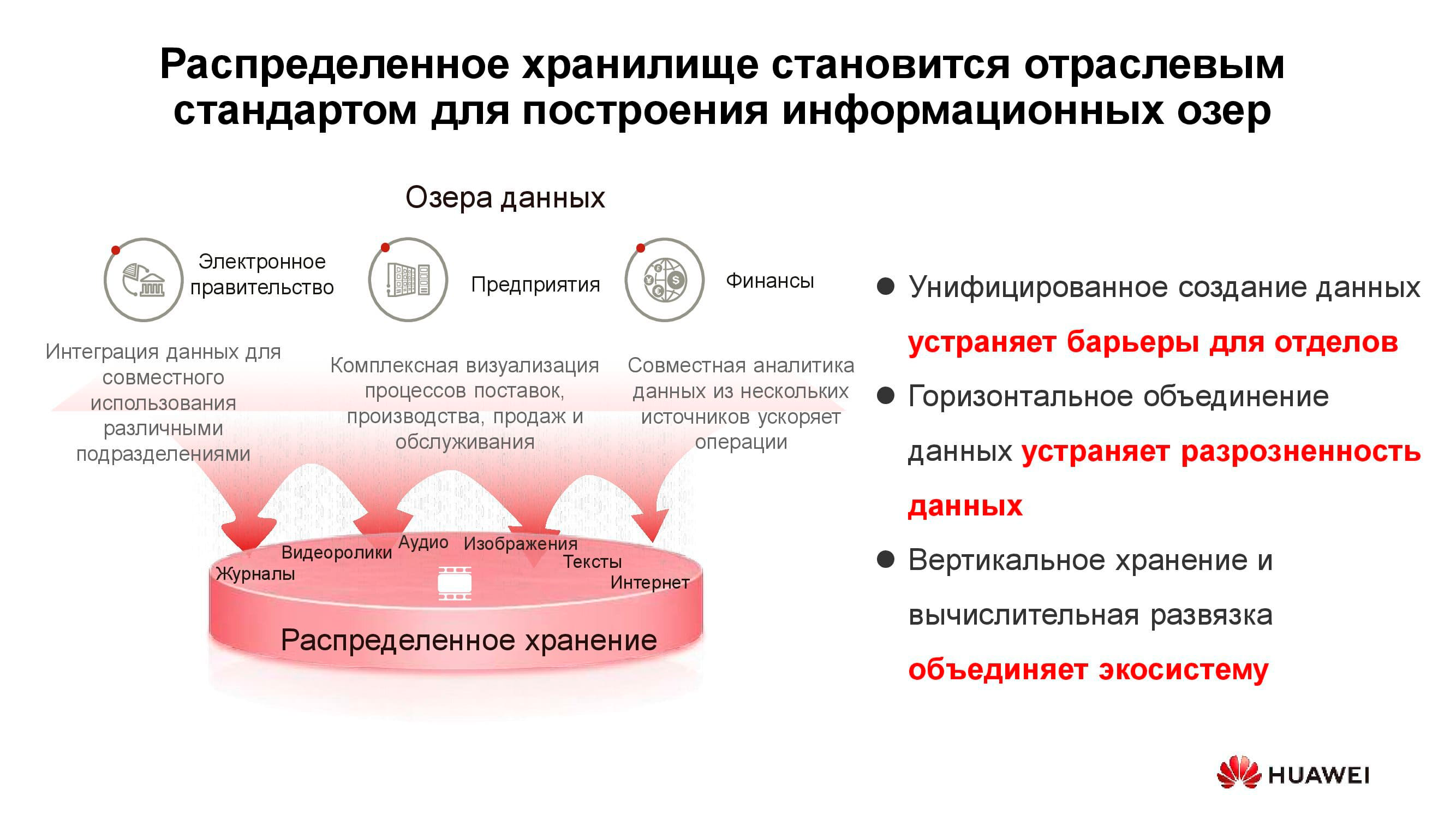
Lacs de données
Le diagramme ci-dessus montre une liste de consommateurs typiques de services de data lake . Il peut s'agir de services d'administration en ligne (par exemple, «Gosuslugi»), d'entreprises numérisées, de structures financières, etc. Ils doivent tous travailler avec de grands volumes d'informations hétérogènes.
Le fonctionnement des systèmes de stockage classiques pour résoudre de tels problèmes est inefficace, car il faut à la fois un accès haute performance aux bases de données de blocs et un accès régulier aux bibliothèques de documents numérisés stockés en tant qu'objets. Par exemple, un système de commande via un portail Web peut être lié ici. Pour mettre en œuvre tout cela sur une plate-forme de stockage classique, vous aurez besoin d'un grand ensemble d'équipements pour différentes tâches. Un système de stockage universel horizontal peut bien couvrir toutes les tâches énumérées précédemment: il vous suffit de créer plusieurs pools avec des caractéristiques de stockage différentes.

Générateurs de nouvelles informations
La quantité d'informations stockées dans le monde augmente d'environ 30% par an. C'est une bonne nouvelle pour les fournisseurs de stockage, mais quelle est et sera la principale source de ces données?
Il y a dix ans, les réseaux sociaux sont devenus de tels générateurs, ce qui a nécessité la création d'un grand nombre de nouveaux algorithmes, solutions matérielles, etc. Il existe désormais trois principaux moteurs de croissance des volumes de stockage. Le premier est le cloud computing. Actuellement, environ 70% des entreprises utilisent les services cloud d'une manière ou d'une autre. Il peut s'agir de systèmes de messagerie, de sauvegardes et d'autres entités virtualisées.
Le deuxième moteur est les réseaux de cinquième génération. Ce sont de nouvelles vitesses et de nouveaux volumes de transfert de données. Nous prévoyons que l'adoption généralisée de la 5G entraînera une baisse de la demande de cartes mémoire flash. Quelle que soit la quantité de mémoire du téléphone, celle-ci est toujours épuisée et s'il existe un canal de 100 mégabits dans le gadget, il n'est pas nécessaire de stocker les photos localement.
Le troisième groupe de raisons de la demande croissante de systèmes de stockage comprend le développement rapide de l'intelligence artificielle, la transition vers l'analyse des mégadonnées et la tendance à l'automatisation universelle de tout ce qui est possible.
La particularité du "nouveau trafic" est sa déstructuration... Nous devons stocker ces données sans spécifier son format. Il n'est requis que pour une lecture ultérieure. Par exemple, un système de notation bancaire pour déterminer le montant du prêt disponible examinera les photos que vous avez publiées sur les réseaux sociaux, déterminera si vous visitez souvent la mer et les restaurants, et étudiera en même temps les extraits de vos documents médicaux à sa disposition. Ces données, d'une part, sont globales et, d'autre part, manquent d'uniformité.

Un océan de données non structurées
Quels sont les problèmes liés à l'émergence de «nouvelles données»? Le plus important d'entre eux, bien sûr, est la quantité d'informations elle-même et la durée de stockage estimée. Une voiture autonome moderne sans conducteur génère à elle seule jusqu'à 60 To de données chaque jour à partir de tous ses capteurs et mécanismes. Pour développer de nouveaux algorithmes de mouvement, ces informations doivent être traitées le même jour, sinon elles commenceront à s'accumuler. De plus, il devrait être stocké très longtemps - des dizaines d'années. Ce n'est qu'alors qu'à l'avenir, il sera possible de tirer des conclusions sur la base de grands échantillons analytiques.
Un dispositif de séquençage génétique génère environ 6 TB par jour. Et les données collectées avec son aide n'impliquent aucune suppression, c'est-à-dire qu'elles devraient être conservées pour toujours.
Enfin, tous les mêmes réseaux de cinquième génération. Outre les informations effectivement transmises, un tel réseau lui-même est un énorme générateur de données: journaux d'actions, enregistrements d'appels, résultats intermédiaires d'interactions machine à machine, etc.
Tout cela nécessite le développement de nouvelles approches et algorithmes de stockage et de traitement des informations. Et de telles approches apparaissent.
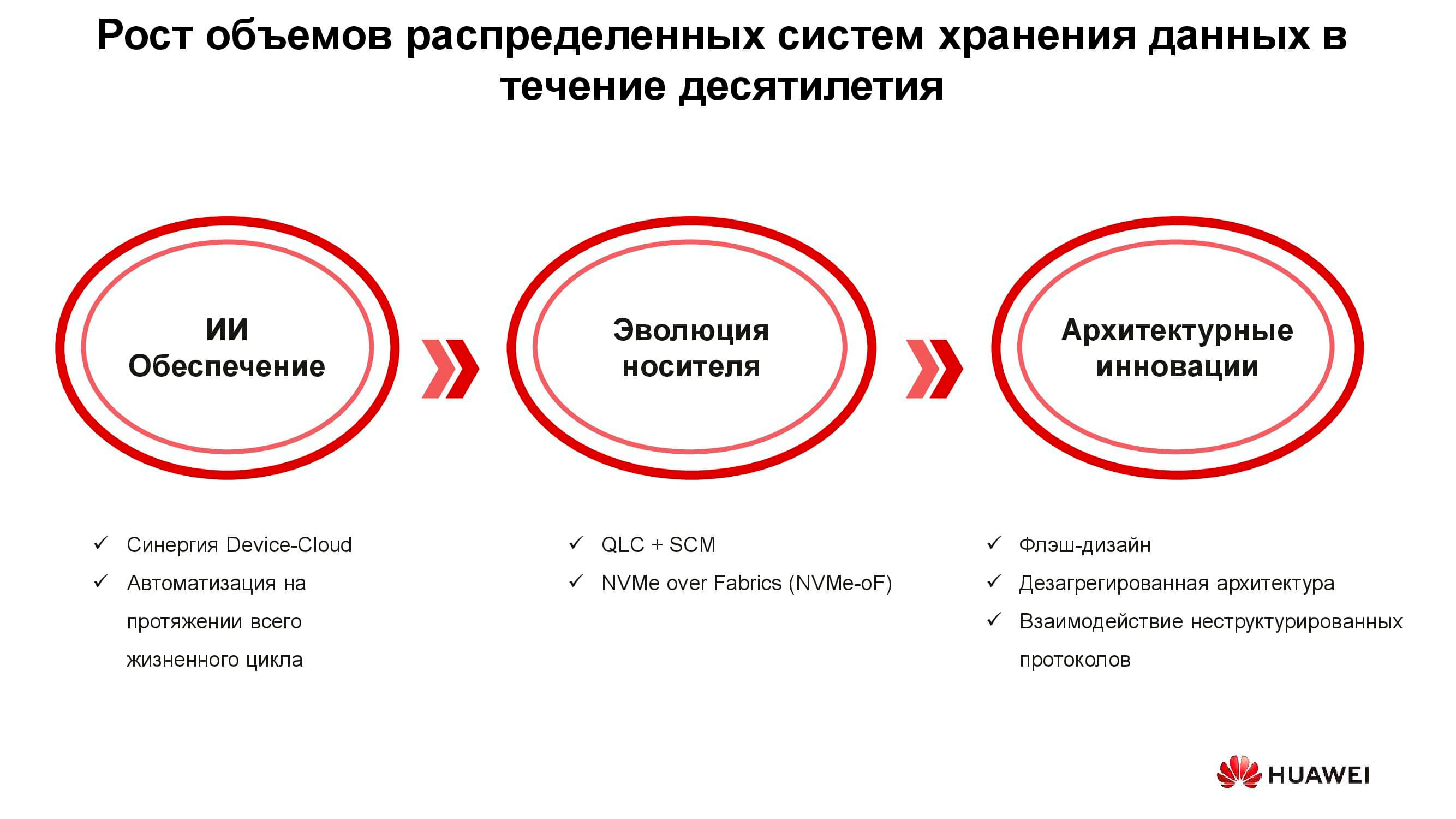
Technologies d'une nouvelle ère
Il existe trois groupes de solutions conçues pour faire face aux nouvelles exigences des systèmes de stockage: l'introduction de l'intelligence artificielle, l'évolution technique des supports de stockage et les innovations dans le domaine de l'architecture des systèmes. Commençons par l'IA.

Dans les nouvelles solutions Huawei, l'intelligence artificielle est déjà utilisée au niveau du stockage lui-même, qui est équipé d'un processeur IA qui permet au système d'analyser indépendamment son état et de prévoir les pannes. Si le système de stockage est connecté à un cloud de services doté de capacités de calcul importantes, l'intelligence artificielle peut traiter plus d'informations et améliorer la précision de ses hypothèses.
En plus des pannes, une telle IA est capable de prédire les charges de pointe futures et le temps restant jusqu'à ce que la capacité soit épuisée. Cela vous permet d'optimiser les performances et de faire évoluer le système avant même que des événements indésirables ne se produisent.

Parlons maintenant de l'évolution des supports de données. Les premiers lecteurs flash ont été fabriqués à l'aide de la technologie SLC (Single-Level Cell). Les appareils basés sur celui-ci étaient rapides, fiables, stables, mais avaient une petite capacité et étaient très chers. L'augmentation du volume et la réduction des prix ont été obtenues grâce à certaines concessions techniques, grâce auxquelles la vitesse, la fiabilité et la durée de vie des variateurs ont été réduites. Néanmoins, la tendance n'a pas affecté les systèmes de stockage eux-mêmes, qui, en raison de diverses astuces architecturales, sont en général devenus à la fois plus productifs et plus fiables.
Mais pourquoi avez-vous besoin de systèmes de stockage 100% Flash? Ne suffisait-il pas simplement de remplacer les anciens disques durs d'un système déjà utilisé par de nouveaux SSD du même facteur de forme? Il a fallu cela pour utiliser efficacement toutes les ressources des nouveaux disques SSD, ce qui était tout simplement impossible dans les anciens systèmes.
Huawei, par exemple, a développé une gamme de technologies pour relever ce défi, dont FlashLink , qui maximise les interactions disque-contrôleur.
L'identification intelligente a permis de décomposer les données en plusieurs flux et de faire face à un certain nombre de phénomènes indésirables tels que WA (amplification d'écriture). Dans le même temps, de nouveaux algorithmes de récupération, en particulier RAID 2.0+, a augmenté la vitesse de reconstruction, réduisant son temps à des valeurs totalement insignifiantes.
Panne, surpeuplement, "garbage collection" - ces facteurs n'affectent plus non plus les performances du système de stockage grâce à une modification spéciale des contrôleurs.
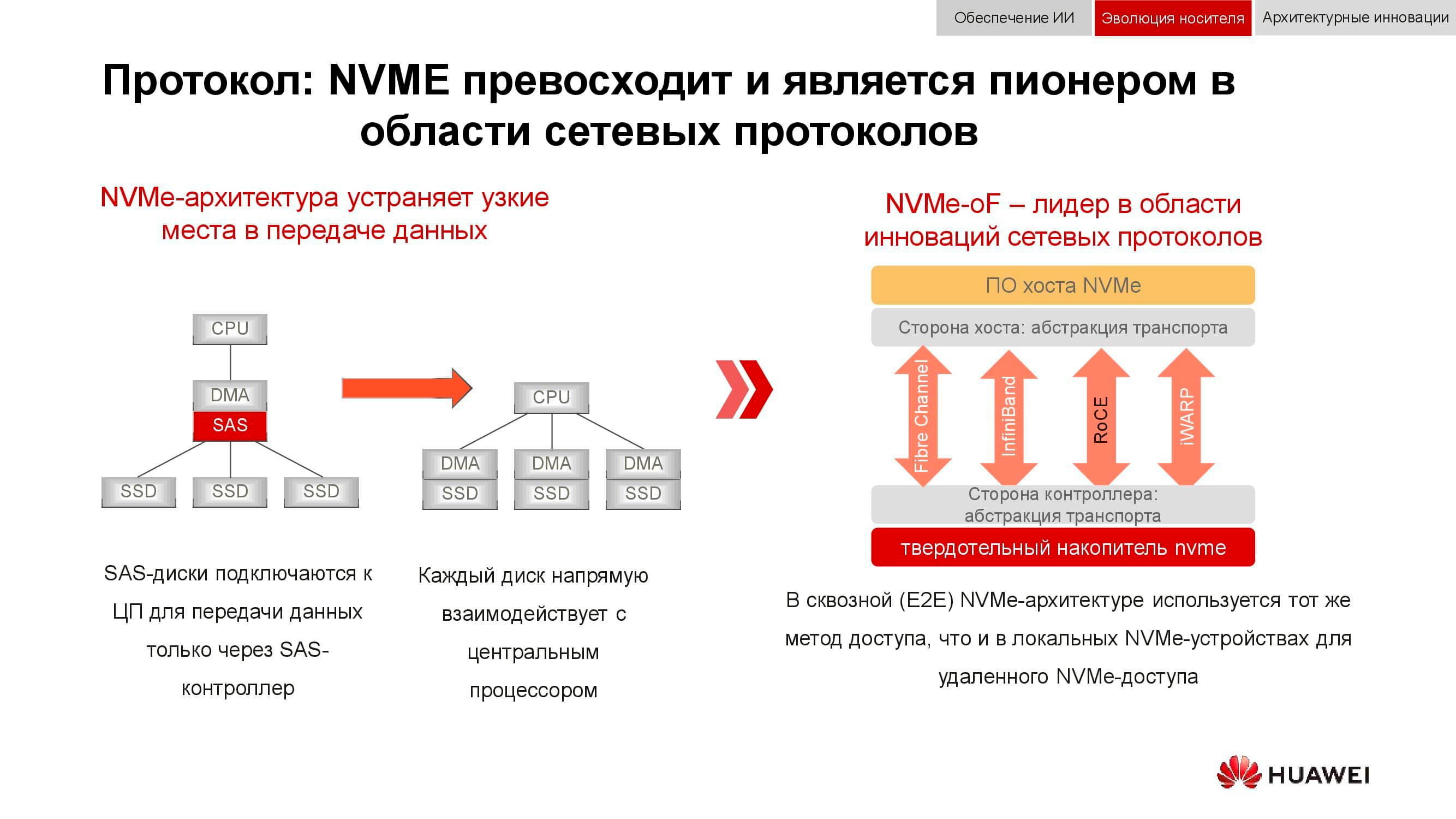
Et le stockage de données par blocs se prépare à répondre à NVMe . Rappelons que le schéma classique d'organisation de l'accès aux données fonctionnait comme suit: le processeur accédait au contrôleur RAID via le bus PCI Express. Cela, à son tour, interagissait avec des disques mécaniques via SCSI ou SAS. L'utilisation de NVMe sur le backend accélérait considérablement l'ensemble du processus, mais il avait un inconvénient: les disques devaient être directement connectés au processeur afin de fournir un accès direct à la mémoire.
La prochaine phase de développement technologique que nous assistons actuellement est l'utilisation de NVMe-oF (NVMe over Fabrics). Quant aux technologies de bloc Huawei, elles prennent déjà en charge FC-NVMe (NVMe sur Fibre Channel), et sur l'approche NVMe sur RoCE (RDMA sur Ethernet convergé). Les modèles de test sont assez fonctionnels, il reste plusieurs mois avant leur présentation officielle. Notez que tout cela apparaîtra également dans les systèmes distribués, où «Ethernet sans perte» sera très demandé.
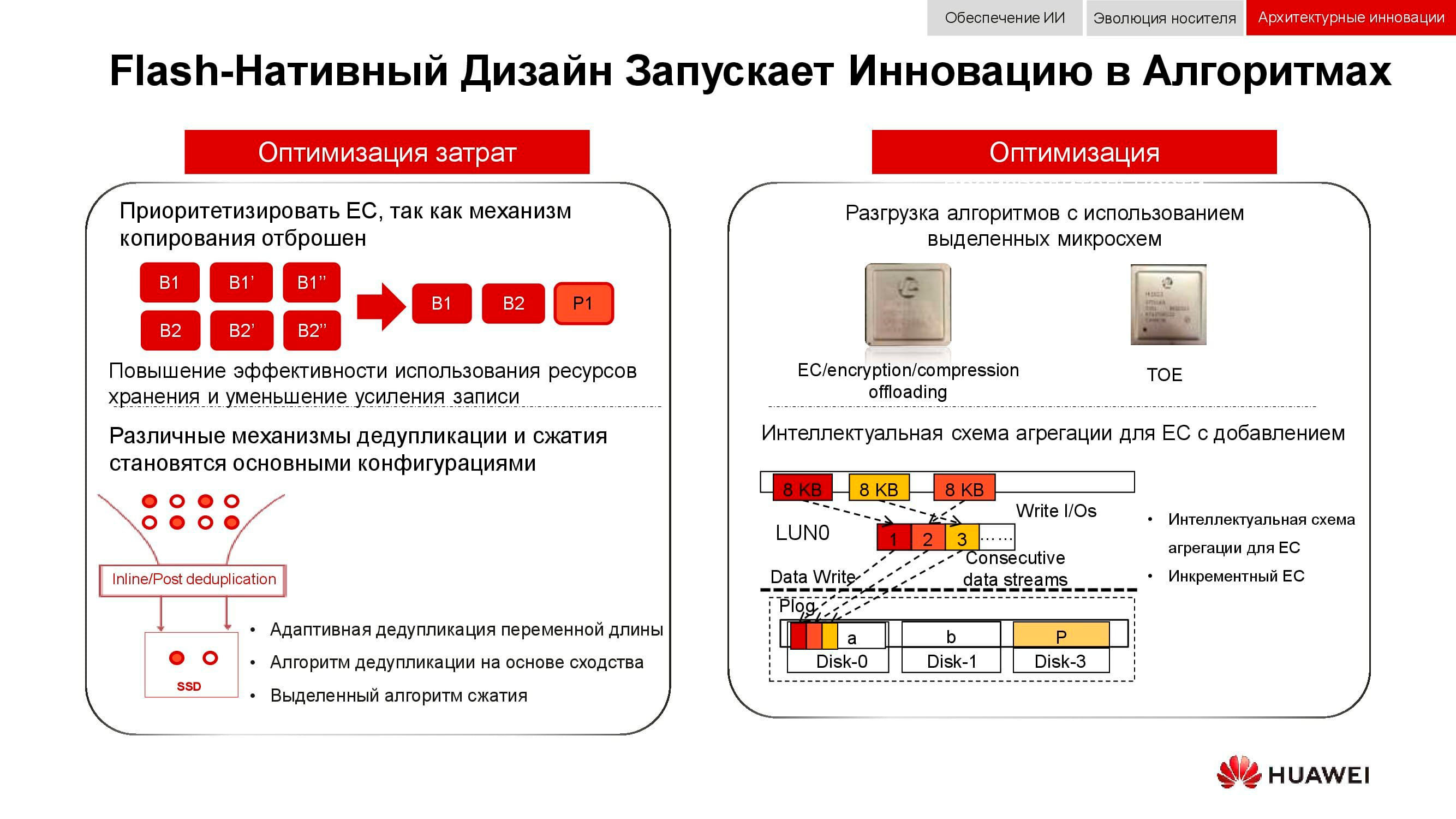
Un autre moyen d'optimiser le travail du stockage distribué est le rejet complet de la mise en miroir des données. Les solutions Huawei n'utilisent plus n copies, comme dans le RAID 1 habituel, et passent complètement au mécanisme EC(Codage d'effacement). Un progiciel mathématique spécial calcule des blocs de contrôle à intervalles réguliers, ce qui vous permet de restaurer des données intermédiaires en cas de perte.
Les mécanismes de déduplication et de compression deviennent obligatoires. Si dans les systèmes de stockage classiques, nous sommes limités par le nombre de processeurs installés dans les contrôleurs, alors dans les systèmes de stockage évolutifs distribués, chaque nœud contient tout ce dont vous avez besoin: disques, mémoire, processeurs et interconnexion. Ces ressources sont suffisantes pour que la déduplication et la compression aient un impact minimal sur les performances.
Et sur les méthodes d'optimisation matérielle. Ici, il était possible de réduire la charge sur les processeurs centraux à l'aide de microcircuits dédiés supplémentaires (ou de blocs dédiés dans le processeur lui-même), qui jouent le rôle de TOE(TCP / IP Offload Engine) ou prendre en charge les problèmes mathématiques d'EC, de déduplication et de compression.
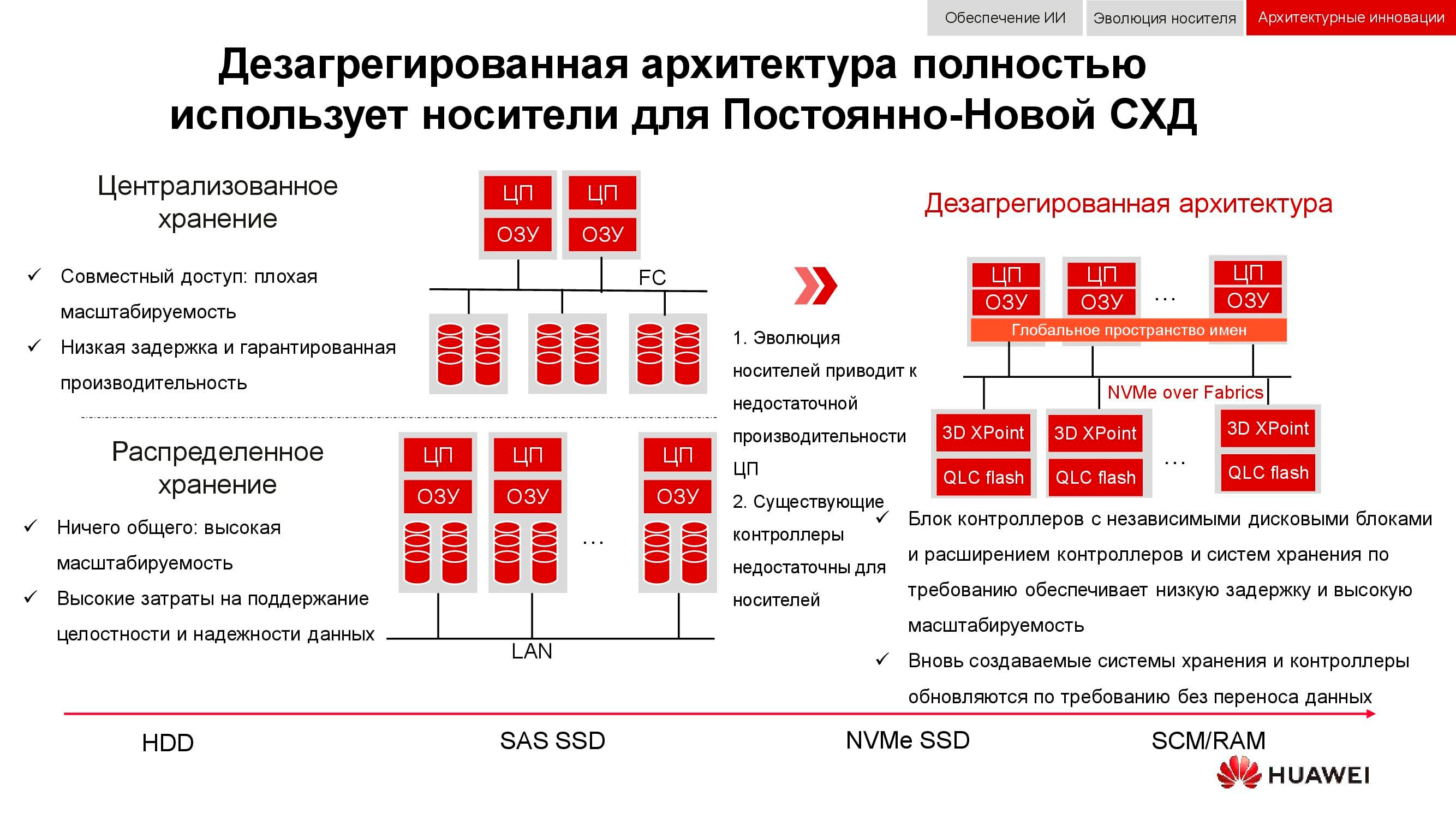
De nouvelles approches du stockage des données sont incorporées dans une architecture désagrégée (distribuée). Dans les systèmes de stockage centralisés, il existe une usine de serveurs qui est connectée via Fibre Channel à un SAN avec un grand nombre de baies. Les inconvénients de cette approche sont la difficulté d'évoluer et de fournir des niveaux de service garantis (performances ou latence). Les systèmes hyperconvergés utilisent les mêmes hôtes pour le stockage et le traitement des informations. Cela offre une évolutivité pratiquement illimitée, mais entraîne des coûts élevés pour maintenir l'intégrité des données.
Contrairement à ce qui précède, l'architecture désagrégée implique la séparation du système en une structure de calcul et un système de stockage horizontal . Cela offre les avantages des deux architectures et vous permet de vous adapter presque indéfiniment uniquement à l'élément qui manque de performances.
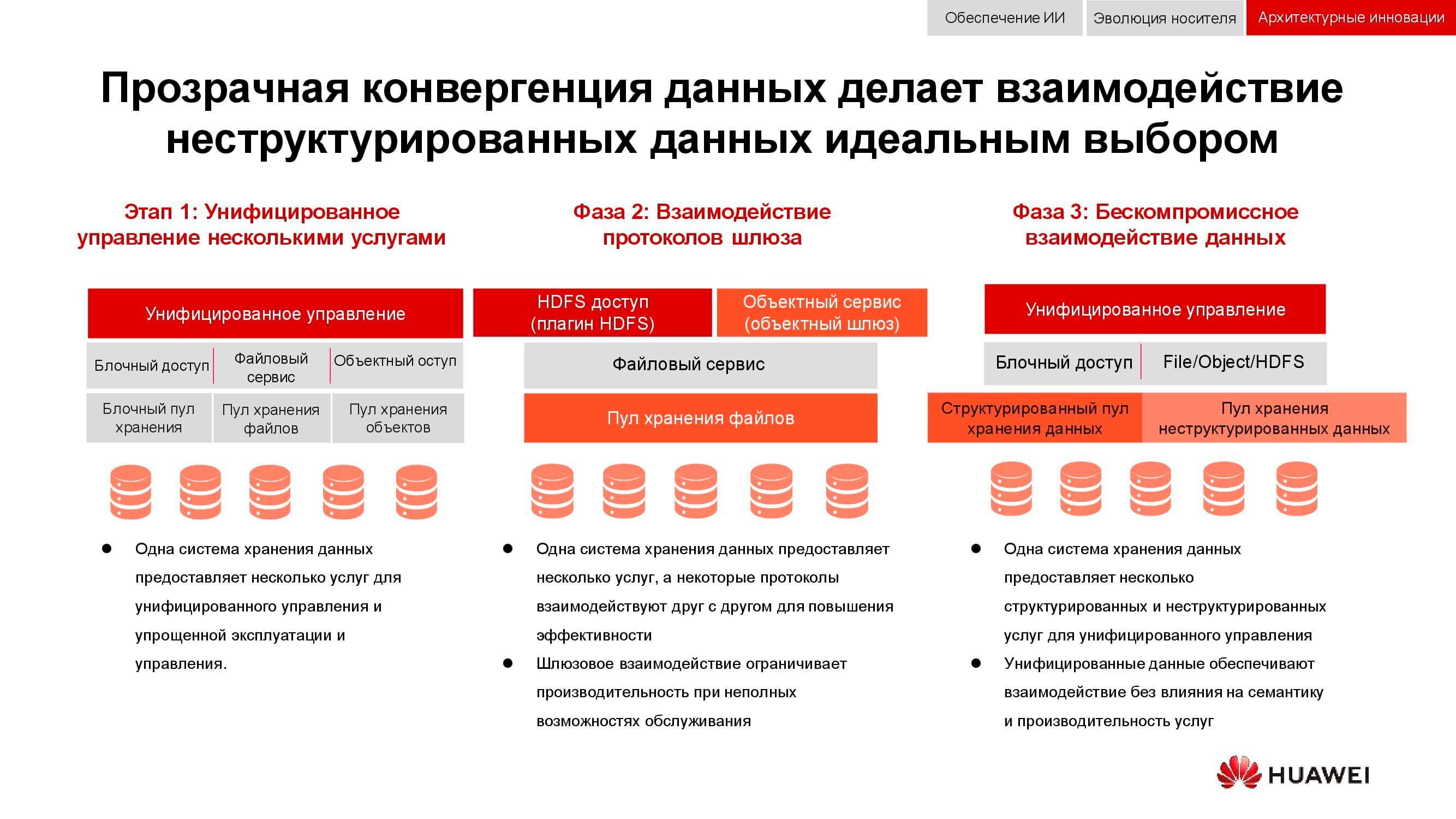
De l'intégration à la convergence
Une tâche classique, dont la pertinence n'a fait que croître au cours des 15 dernières années, est la nécessité de fournir simultanément le stockage en bloc, l'accès aux fichiers, l'accès aux objets, l'exploitation agricole pour le big data, etc. La cerise sur le gâteau peut aussi être, par exemple, un système de sauvegarde sur bande magnétique.
Dans un premier temps, il n'a été possible que d'unifier la gestion de ces services. Les systèmes de stockage de données hétérogènes étaient enfermés dans certains logiciels spécialisés, grâce auxquels l'administrateur allouait des ressources à partir des pools disponibles. Mais comme ces pools étaient différents sur le plan matériel, la migration de la charge entre eux était impossible. À un niveau d'intégration supérieur, la consolidation a eu lieu au niveau de la passerelle. S'il y avait un accès au fichier partagé, il pourrait être donné via différents protocoles.
La méthode de convergence la plus avancée dont nous disposons aujourd'hui implique la création d'un système hybride universel. Exactement ce que devrait être notre OceanStor 100D . L'accessibilité utilise les mêmes ressources matérielles, divisées logiquement en différents pools, mais permettant la migration de la charge de travail. Tout cela peut être fait via une seule console de gestion. De cette manière, nous avons réussi à mettre en œuvre le concept «un centre de données - un système de stockage».
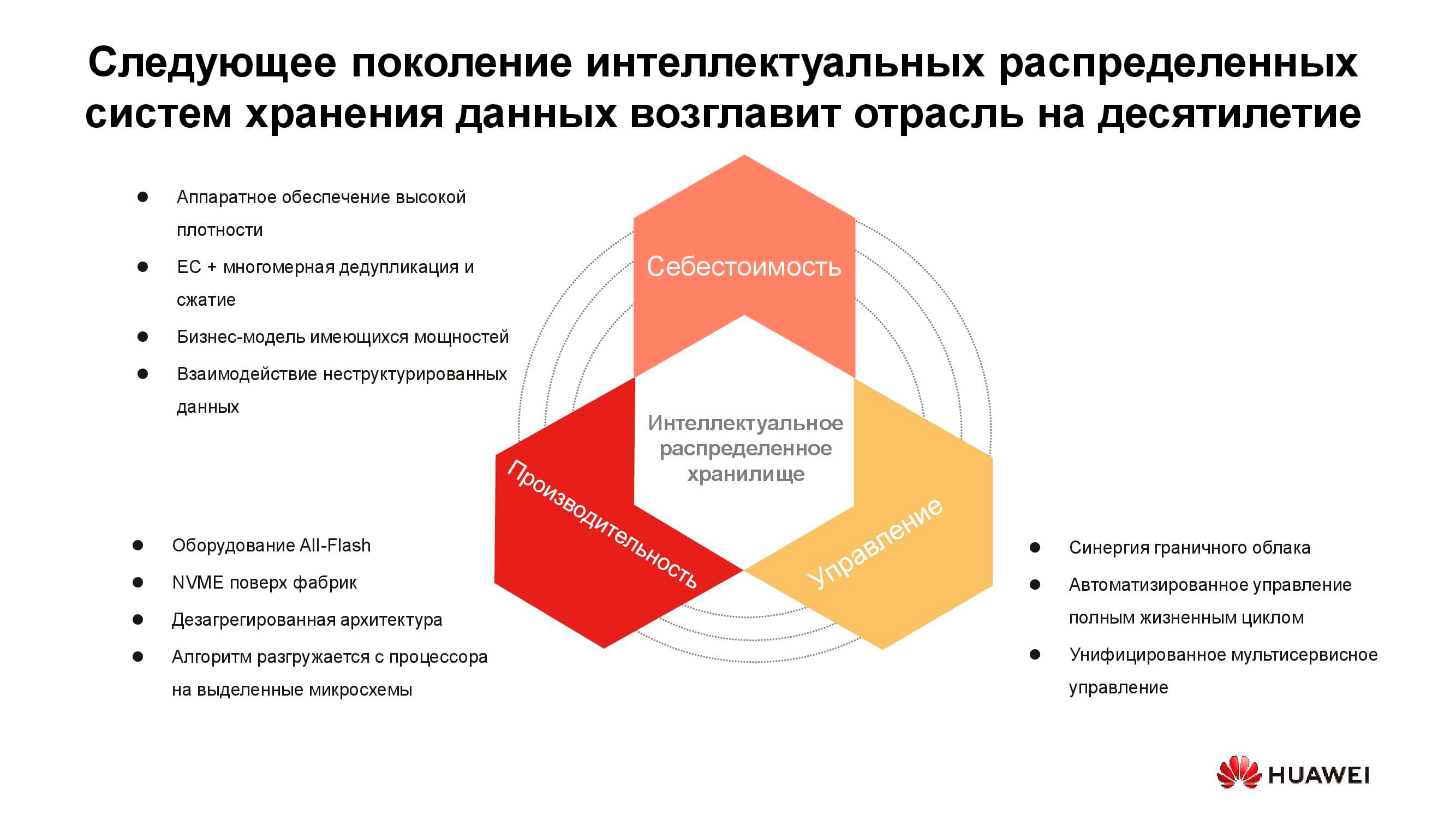
Le coût de stockage des informations détermine désormais de nombreuses décisions architecturales. Et bien qu'il puisse être mis en avant en toute sécurité, nous discutons aujourd'hui du stockage en direct avec accès actif, donc les performances doivent également être prises en compte. Une autre propriété importante des systèmes distribués de nouvelle génération est l'unification. Après tout, personne ne veut avoir plusieurs systèmes disparates contrôlés à partir de différentes consoles. Toutes ces qualités sont incarnées dans la nouvelle série de produits Huawei OceanStor Pacific .
Stockage de masse d'une nouvelle génération
OceanStor Pacific répond aux exigences de fiabilité au niveau de «six neuf» (99,9999%) et peut être utilisé pour créer des centres de données de la classe HyperMetro. Avec une distance allant jusqu'à 100 km entre deux centres de données, les systèmes démontrent un délai supplémentaire de 2 ms, ce qui permet de construire sur leur base toutes les solutions résistantes aux catastrophes, y compris celles avec des serveurs de quorum.
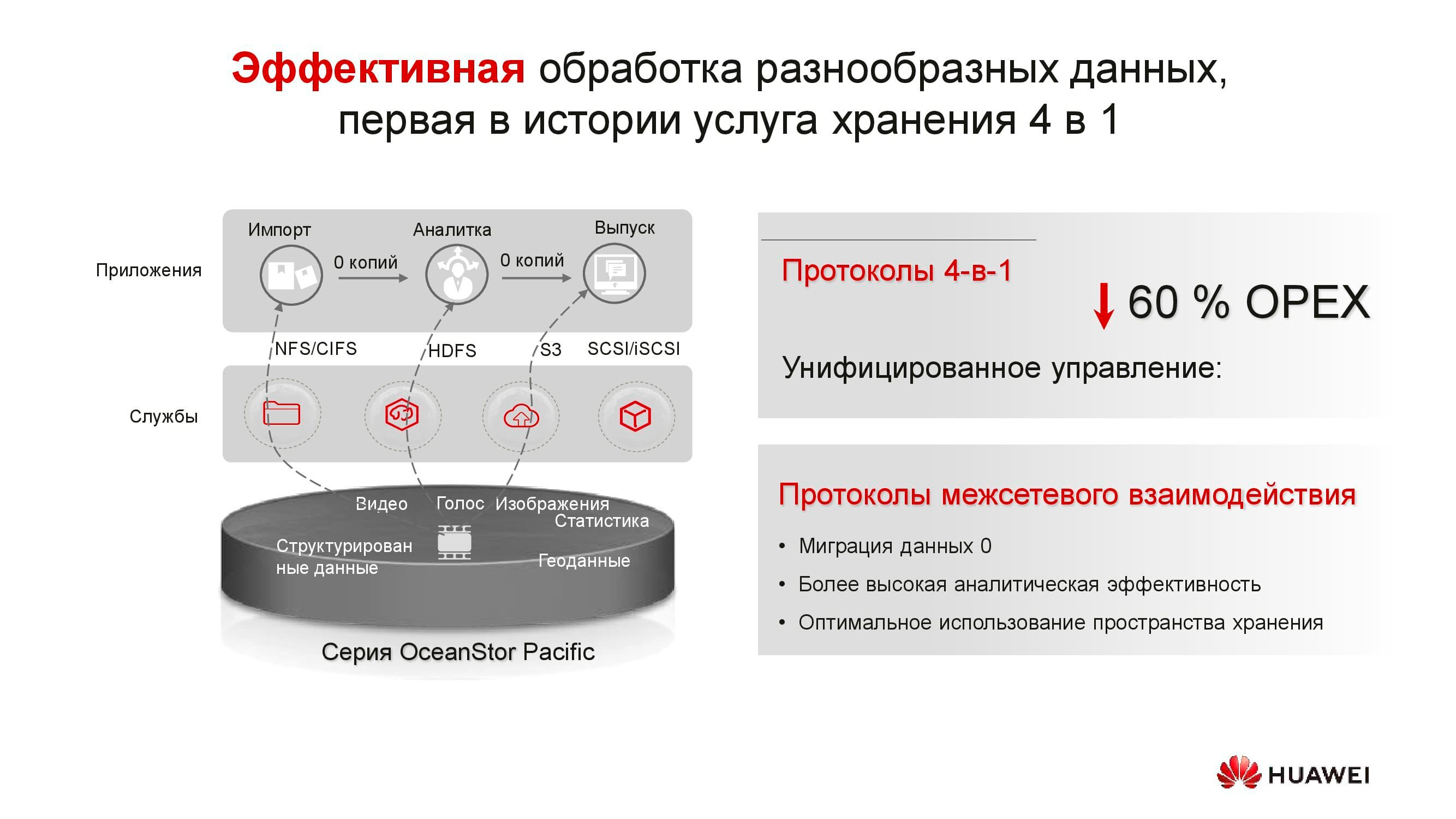
Les produits de la nouvelle série démontrent la polyvalence des protocoles. OceanStor 100D prend déjà en charge l'accès par bloc, l'accès aux objets et l'accès Hadoop. L'accès aux fichiers sera également mis en œuvre dans un proche avenir. Il n'est pas nécessaire de conserver plusieurs copies des données si elles peuvent être livrées via différents protocoles.
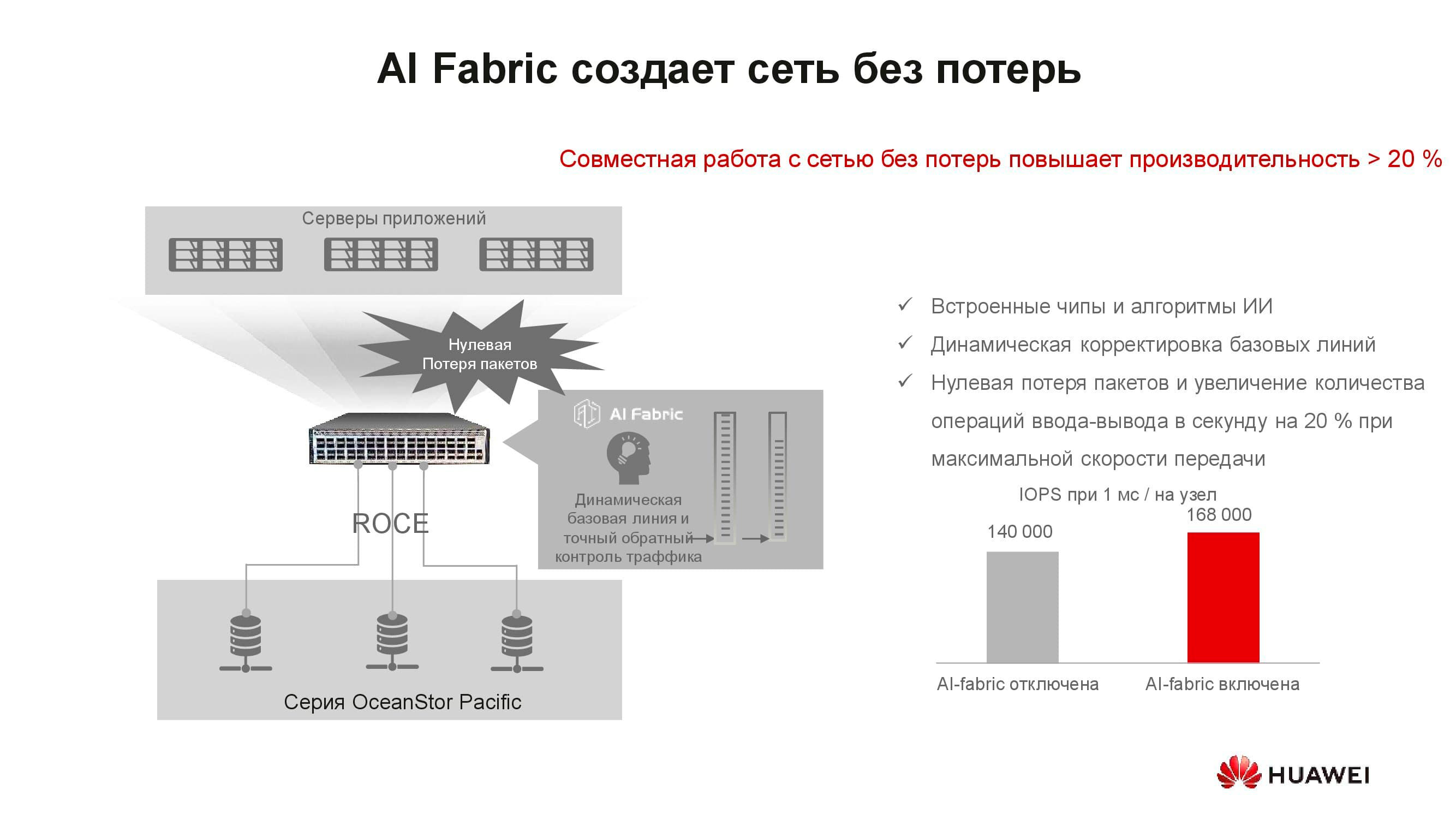
Il semblerait que le concept de «réseau sans perte» ait à voir avec le stockage? Le fait est que les systèmes de stockage distribués sont construits sur la base d'un réseau rapide qui prend en charge les algorithmes correspondants et le mécanisme RoCE. L' AI Fabric pris en charge par nos commutateurs permet d'augmenter encore la vitesse du réseau et de réduire la latence . Les gains de performances de stockage avec l'activation AI Fabric peuvent atteindre 20%.
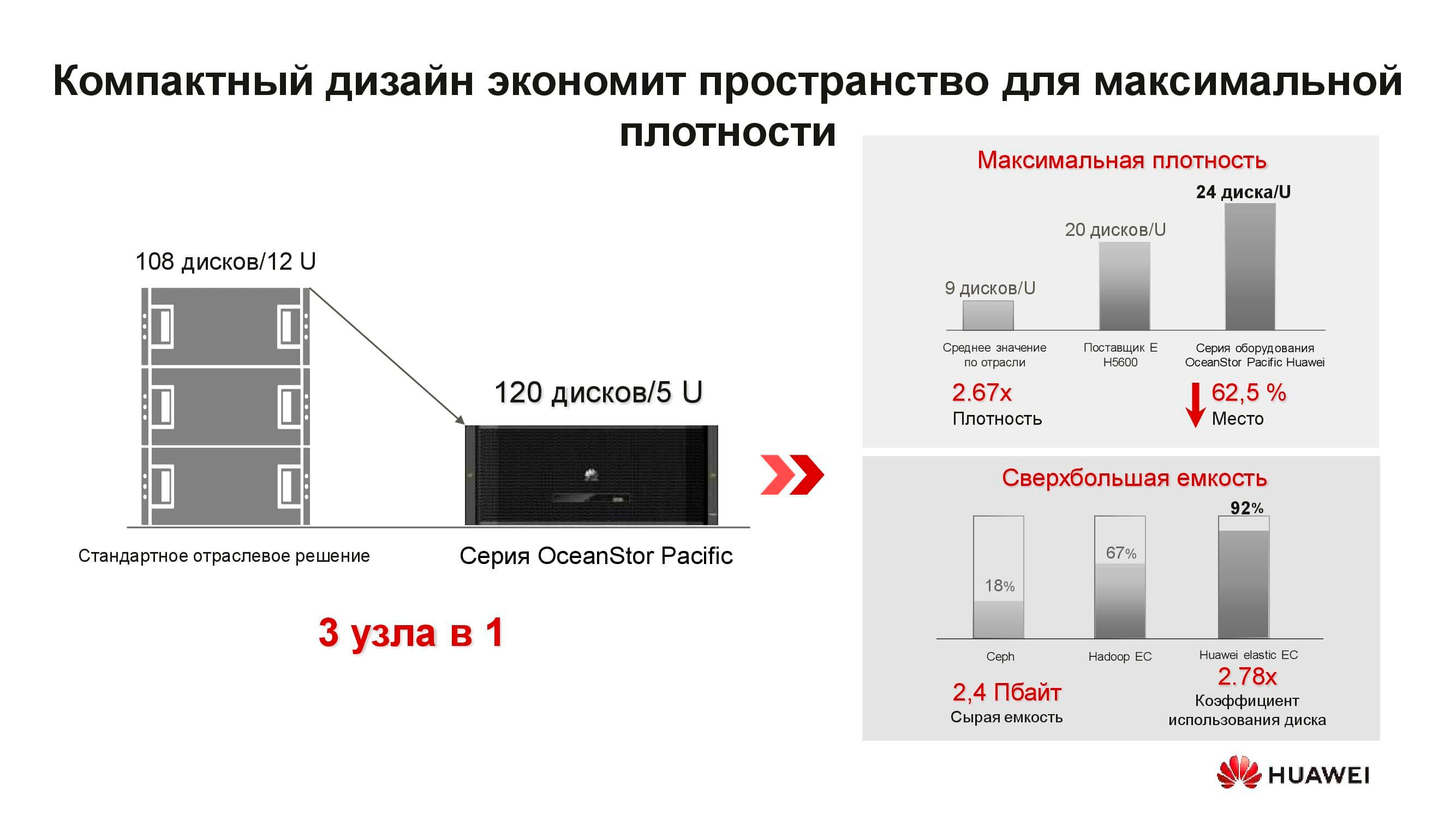
Qu'est-ce que le nouveau nœud de stockage distribué OceanStor Pacific? La solution 5U comprend 120 disques et peut remplacer trois nœuds classiques, ce qui économise plus de 2 fois l'espace de rack. En raison du refus de stocker des copies, l'efficacité des disques augmente considérablement (jusqu'à + 92%).
Nous sommes habitués au fait que le stockage défini par logiciel est un logiciel spécial installé sur un serveur classique. Mais maintenant, pour atteindre des paramètres optimaux, cette solution architecturale nécessite également des nœuds spéciaux. Il se compose de deux serveurs basés sur des processeurs ARM, gérant un ensemble de disques 3 pouces.
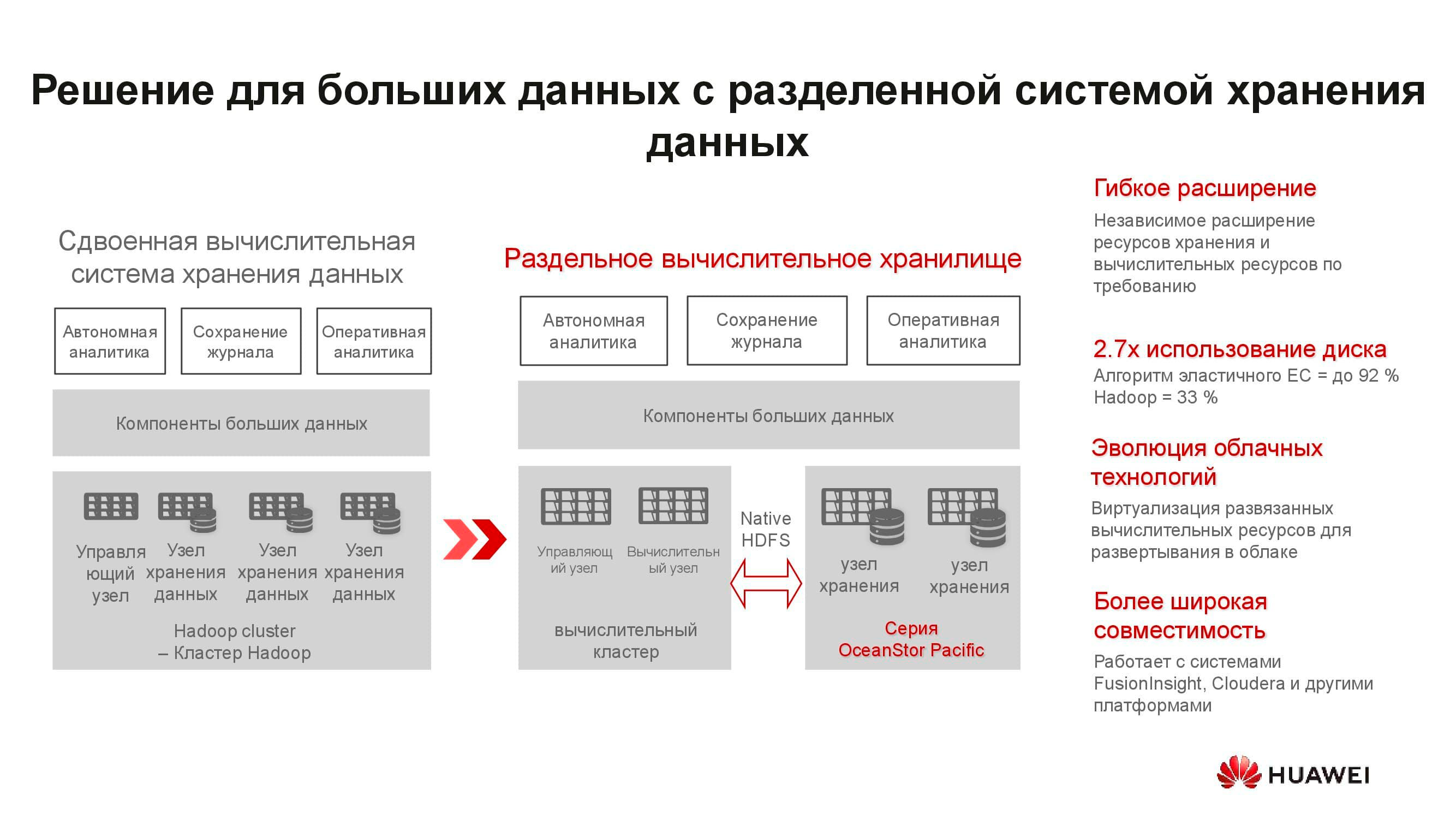
Ces serveurs sont mal adaptés aux solutions hyper-convergées. Premièrement, il existe peu d'applications pour ARM, et deuxièmement, il est difficile de maintenir l'équilibre de la charge. Nous proposons de passer au stockage séparé: un cluster de calcul, représenté par des serveurs classiques ou en rack, fonctionne séparément, mais se connecte aux nœuds de stockage OceanStor Pacific, qui effectuent également leurs tâches directes. Et cela se justifie.
Par exemple, prenez une solution classique de stockage de Big Data hyperconvergée qui occupe 15 racks de serveurs. En séparant la charge de travail entre les serveurs de calcul individuels et les nœuds de stockage OceanStor Pacific, en les séparant les uns des autres, le nombre de racks requis est réduit de moitié! Cela réduit le coût d'exploitation du centre de données et le coût total de possession. Dans un monde où le volume d'informations stockées augmente de 30% par an, ces avantages ne sont pas dispersés.
***
Vous pouvez obtenir plus d'informations sur les solutions et scénarios Huawei pour leur utilisation sur notre site Web ou en contactant directement les représentants de l'entreprise.