Selon la croyance populaire, extraire du texte à partir de PDF ne devrait pas être si difficile. Après tout, le voici, le texte, sous nos yeux, et les gens perçoivent constamment et avec beaucoup de succès le contenu du PDF. D'où viennent les difficultés d'extraction automatique de texte?
Il s'avère que tout comme travailler avec les noms des personnes est difficile pour les algorithmes en raison de nombreux cas extrêmes et d'hypothèses incorrectes, travailler avec PDF est difficile en raison de l'extrême flexibilité du format PDF.
Le principal problème est que le PDF n'a pas été conçu comme un format d'entrée de données - il a été développé comme un canal de sortie, permettant de peaufiner l'apparence du document final.
Fondamentalement, le format PDF consiste en un flux d'instructions décrivant comment une image est créée sur une page. En particulier, les données textuelles ne sont pas stockées sous forme de paragraphes - ni même de mots - mais sous forme de caractères dessinés à des emplacements spécifiques sur la page. En conséquence, lors de la conversion de texte ou de document Word en PDF, la plupart de la sémantique du contenu est perdue. Toute la structure interne du texte se transforme en une soupe amorphe de caractères flottant sur la page.
En remplissant FilingDB, nous avons extrait des données textuelles de dizaines de milliers de documents PDF. Au cours du processus, nous avons observé à quel point toutes nos hypothèses sur la structure des fichiers PDF se sont révélées fausses. Notre mission était particulièrement difficile car nous devions traiter des documents PDF provenant de différentes sources avec des styles, des polices et des apparences complètement différents.
Ce qui suit décrit les caractéristiques des fichiers PDF qui rendent difficile, voire impossible, l'extraction de texte à partir d'eux.
Protection contre la lecture PDF
Vous avez peut-être rencontré des fichiers PDF qui interdisent de copier du contenu texte à partir d'eux. Par exemple, c'est ce que produit le programme SumatraPDF en essayant de copier du texte à partir d'un document protégé contre la copie: il est

intéressant de noter que le texte est visible, mais le spectateur refuse de transférer le texte sélectionné dans le presse-papiers.
Ceci est accompli avec plusieurs indicateurs «autorisations d'accès», dont l'un contrôle l'autorisation de copie. Il est important de comprendre que le fichier PDF lui-même ne force pas cela - son contenu n'en change pas et la tâche de sa mise en œuvre incombe entièrement au spectateur.
Naturellement, cela ne protège pas vraiment contre l'extraction de texte à partir de PDF, car toute bibliothèque suffisamment avancée pour travailler avec PDF permettra à l'utilisateur de modifier ces indicateurs ou de les ignorer.
Caractères en dehors des pages
Souvent, un PDF contient plus de données textuelles que ce qui est affiché sur la page. Prenez cette page du rapport annuel 2010 de Nestlé.
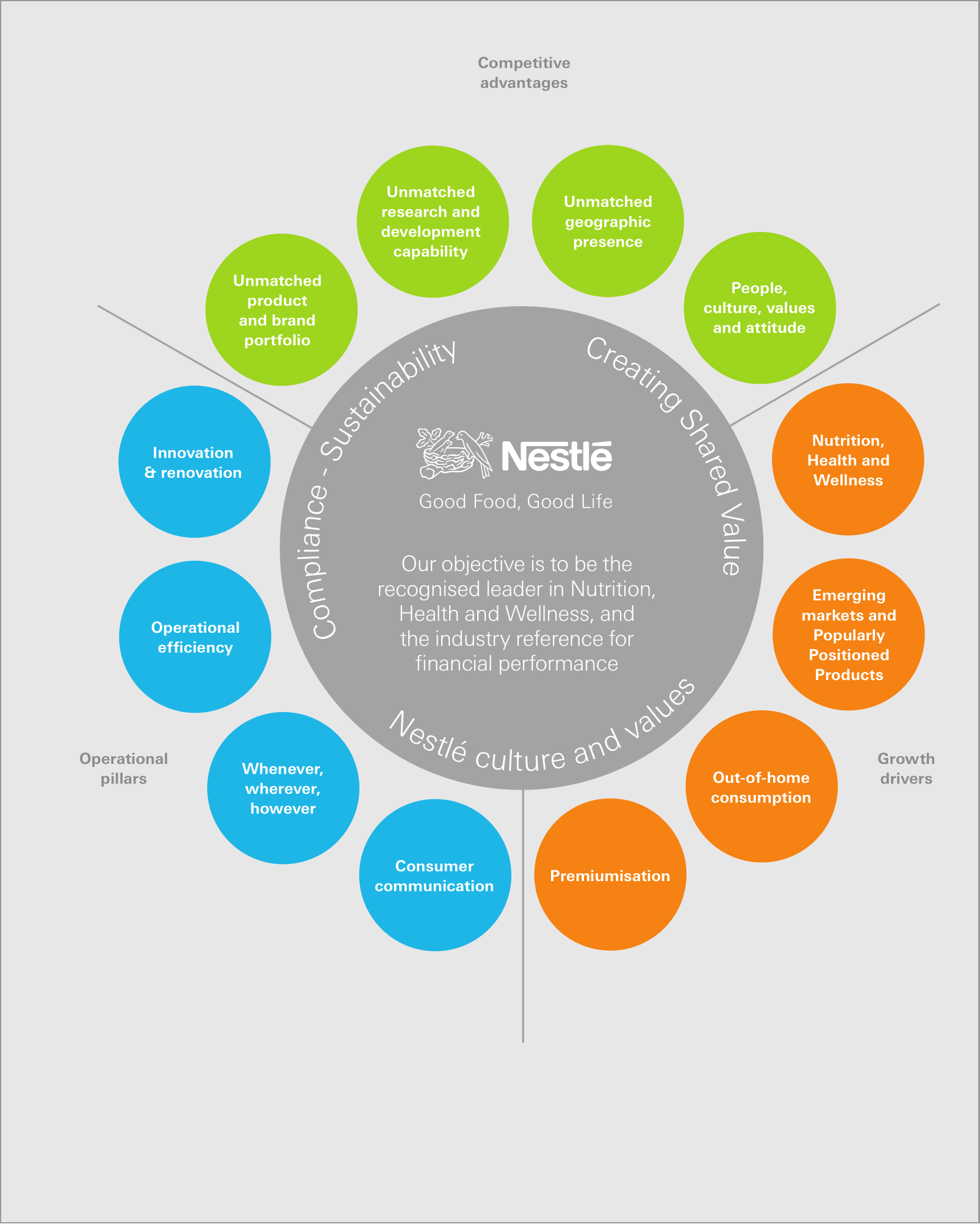
Il y a plus de texte attaché à cette page que visible. En particulier, les éléments suivants peuvent être trouvés dans le contenu qui lui est associé:
KitKat a célébré son 75e anniversaire en 2010, mais reste jeune et tendance avec plus de 2,5 millions de fans sur Facebook. Ses produits sont vendus dans plus de 70 pays et les ventes progressent bien dans les pays développés et les marchés émergents tels que le Moyen-Orient, l'Inde et la Russie. Le Japon est le deuxième marché de l'entreprise.
Ce texte est hors page, donc la plupart des lecteurs PDF ne l'afficheront pas. Cependant, les données sont là et peuvent être récupérées par programme.
Cela se produit parfois en raison de décisions de dernière minute de remplacer ou de supprimer du texte pendant le processus d'approbation.
Caractères petits ou invisibles
Parfois, des caractères très petits ou même invisibles peuvent être trouvés sur la page PDF. Par exemple, voici une page du rapport Nestlé 2012.

La page contient un petit texte blanc sur fond blanc qui dit ce qui suit:
Wyeth Nutrition logo Identity Guidance to market
Vevey Octobre 2012 RCC / CI & D
Ceci est parfois fait pour améliorer l'accessibilité, dans le même but que la balise alt en HTML.
Trop d'espaces
Parfois, des espaces supplémentaires sont insérés entre les lettres des mots dans le PDF. Ceci est probablement fait à des fins de crénage (changement de l'espacement entre les caractères).
Par exemple, le rapport Hikma Pharma 2013 contient le texte suivant:

Si vous le copiez, nous obtenons:
ch a i r m a n ' s s tat em en tEn général, il est difficile de résoudre le problème de la reconstruction du texte original. Notre approche la plus réussie consiste à utiliser la reconnaissance optique de caractères, l'OCR.
Pas assez de places
Parfois, le PDF manque d'espaces ou a été remplacé par un caractère différent.
Exemple 1: L'extrait suivant est tiré du rapport annuel SEB 2017.

Texte extrait:
TenyearsafterthefinancialcrisisstartedExemple 2: Le rapport Eurobank 2013 contient les éléments suivants:

Texte extrait:
On_April_7,_2013,_the_competent_authoritiesEncore une fois, il s'avère être mieux utilisé pour ces pages OCR.
Polices intégrées
Le PDF fonctionne avec les polices de manière complexe, pour le moins dire. Pour comprendre comment les données de texte sont stockées dans PDF, nous devons d'abord comprendre les glyphes, les noms de glyphes et les polices.
- Un glyphe est un ensemble d'instructions décrivant comment dessiner un caractère ou une lettre.
- – , . , « » ™ «» «».
- – . , , , «», .
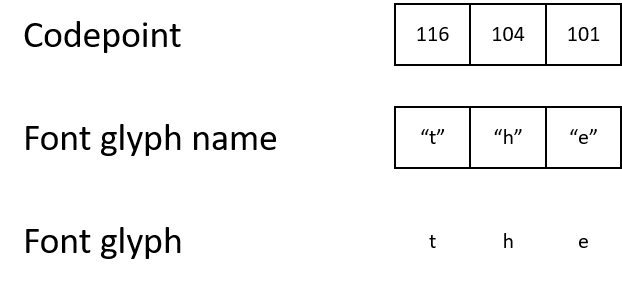
En PDF, les caractères sont stockés sous forme de nombres, de codes de caractères [points de code]. Pour comprendre ce qui doit être affiché à l'écran, le moteur de rendu doit suivre la chaîne du code du caractère au nom du glyphe, puis au glyphe lui-même.
Par exemple, un fichier PDF peut contenir un code de caractère 116, qu'il mappe au nom du glyphe "t", qui à son tour correspond à un glyphe qui décrit comment afficher le caractère "t".
La plupart des PDF utilisent le codage de caractères standard. Un codage de caractères est un ensemble de règles qui attribuent une signification aux codes de caractères eux-mêmes. Par exemple:
- ASCII et Unicode utilisent le code de caractère 116 pour représenter la lettre «t».
- Unicode mappe le code de caractère 9786 au glyphe "smiley blanc", qui est affiché comme ☺, mais ASCII ne définit pas un tel code.
Cependant, un document PDF utilise parfois son propre encodage de caractères et des polices spéciales. Cela peut sembler étrange, mais le document peut désigner la lettre «t» avec le code de caractère 1. Il mappera le code de caractère 1 au nom du glyphe «c1», qui sera mappé à un glyphe qui décrit comment afficher la lettre «t».
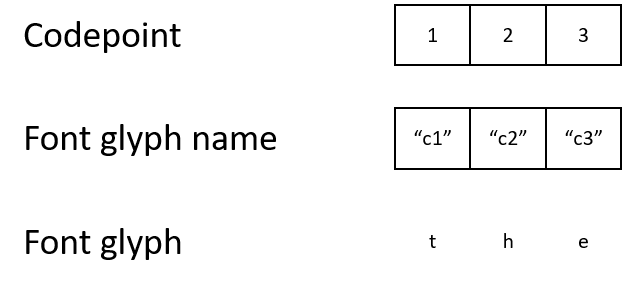
Bien que le résultat final ne soit pas différent de celui d'un humain, la machine sera confuse par ces codes de caractères. Si les codes de caractères ne correspondent pas au codage standard, il est presque impossible de comprendre par programme ce que signifient les codes 1, 2 ou 3.
Pourquoi un PDF comprendrait-il des polices et un codage non standard?
- Une des raisons est de rendre plus difficile l'extraction du texte.
- – . , PDF . PDF , .
Une façon de contourner ce problème consiste à extraire les glyphes de police du document, à les exécuter via l'OCR et à mapper la police sur Unicode. Cela vous permettra de traduire l'encodage lié à la police en Unicode, par exemple: le code de caractère 1 correspond au nom «c1», qui, selon le glyphe, devrait signifier «t», ce qui correspond au code Unicode 116.
La carte d'encodage que vous venez de done - celui qui correspond aux nombres 1 et 116 - est appelé la carte ToUnicode dans la norme PDF. Les documents PDF peuvent contenir leurs propres cartes ToUnicode, mais ce n'est pas obligatoire.
Reconnaissance des mots et des paragraphes
Reconstruire des paragraphes et même des mots à partir de la soupe symbolique amorphe des PDF est une tâche ardue.
Un document PDF contient une liste de caractères sur une page, et c'est au consommateur de reconnaître les mots et les paragraphes. Les humains sont naturellement efficaces dans ce domaine parce que la lecture est une compétence courante.
L'algorithme de regroupement le plus couramment utilisé consiste à comparer la taille, la position et l'alignement des caractères pour déterminer ce qu'est un mot ou un paragraphe.
Les implémentations les plus simples de ces algorithmes peuvent facilement atteindre une complexité O (n²), ce qui peut prendre beaucoup de temps pour traiter des pages densément compactées.
Ordre du texte et des paragraphes
Reconnaître l'ordre du texte et des paragraphes est difficile pour deux raisons.
Premièrement, il n'y a parfois tout simplement pas de bonne réponse. Alors que les documents avec un ensemble typographique régulier avec une colonne ont une séquence de lecture naturelle, les documents avec une disposition d'éléments plus audacieux sont plus difficiles à déterminer. Par exemple, il n'est pas tout à fait clair si l'insert suivant doit venir avant, après ou au milieu de l'article à côté duquel il se trouve:

Deuxièmement, même lorsque la réponse est claire pour une personne, les ordinateurs peuvent être très difficiles à déterminer l'ordre exact des paragraphes - même en utilisant l'IA. Vous pouvez trouver cette déclaration un peu audacieuse, mais dans certains cas, la séquence correcte des paragraphes ne peut être déterminée qu'en comprenant le contenu du texte.
Considérez cette disposition des composants en deux colonnes, qui décrit la préparation d'une salade de légumes.

Dans le monde occidental, il est raisonnable de supposer que la lecture se fait de gauche à droite et de haut en bas. Par conséquent, sans examiner le contenu du texte, nous pouvons réduire toutes les options à deux: ABCD et ACB D.Après
avoir examiné le contenu, compris ce qu'il dit et sachant que les légumes sont lavés avant de trancher, nous pouvons comprendre que le bon ordre serait ACB D. Il est extrêmement difficile de déterminer cela de manière algorithmique.
Dans le même temps, «dans la plupart des cas», une approche qui repose sur l'ordre dans lequel le texte est stocké dans le document PDF fonctionne. Il suit généralement l'ordre dans lequel le texte est inséré au moment de la création. Lorsque de gros morceaux de texte contiennent de nombreux paragraphes, ils suivent généralement l'ordre prévu par l'auteur.
Images intégrées
Souvent, une partie du contenu d'un document (ou du document entier) est l'image numérisée. Dans de tels cas, il n'y a pas de données textuelles et vous devez recourir à l'OCR.
Par exemple, le rapport annuel 2011 de Yell n'est disponible que sous forme de scan:

Pourquoi ne pas tout reconnaître?
Bien que l'OCR puisse résoudre certains des problèmes décrits, elle présente également des inconvénients.
- Long temps de traitement. L'exécution de l'OCR sur une numérisation à partir d'un PDF prend généralement un ordre de grandeur plus long (voire plus) que l'extraction de texte directement à partir d'un PDF.
- Difficultés avec les caractères et les glyphes non standard. Il est difficile pour les algorithmes OCR de travailler avec de nouveaux caractères - émoticônes, astérisques, cercles, carrés (dans les listes), exposants, symboles mathématiques complexes, etc.
- . , PDF-, , . .
Jusqu'à présent, nous n'avons pas encore mentionné à quel point il est difficile de confirmer que le texte a été extrait correctement ou comme prévu. Nous avons constaté qu'il est préférable d'exécuter une large gamme de tests qui étudient à la fois les mesures de base (longueur du texte, longueur de page, rapport mots / espaces) et plus complexes (pourcentage de mots anglais, pourcentage de mots non reconnus, pourcentage de nombres), ainsi que de surveiller avertissements tels que des personnages suspects ou inattendus.
Quels conseils pouvons-nous avoir pour extraire du texte d'un PDF? Tout d'abord, assurez-vous que le texte n'a pas de source plus pratique.
Si les données qui vous intéressent sont uniquement au format PDF, il est important de comprendre que ce problème ne semble simple qu'à première vue et qu'il n'est peut-être pas possible de le résoudre avec une précision de 100%.